一种识别表情序列的卷积神经网络
2018-05-08张金刚王书振
张金刚, 方 圆, 袁 豪, 王书振
(1. 中国科学院 西安光学精密机械研究所,陕西 西安 710119; 2. 中国科学院大学,北京 100094; 3. 中国科学院 光电研究院,北京100094; 4. 西安电子科技大学 计算机学院,陕西 西安 710071)
一种识别表情序列的卷积神经网络
张金刚1,2,3, 方 圆4, 袁 豪4, 王书振4
(1. 中国科学院 西安光学精密机械研究所,陕西 西安 710119; 2. 中国科学院大学,北京 100094; 3. 中国科学院 光电研究院,北京100094; 4. 西安电子科技大学 计算机学院,陕西 西安 710071)
传统的人脸表情识别方法需要人为指定特征训练方向,卷积神经网络方法虽然可以自动训练分类特征,但是存在无法识别表情序列的弊端.针对此问题,运用一种多网络融合技术,使构建的网络能够对表情序列进行识别.网络构建方法为:首先构建多个卷积神经网络,使每个网络处理一帧图片;然后将处理结果在融合层进行融合;最后通过一个分类器输出识别结果.在CK+人脸表情数据库上,分别对3帧、4帧和5帧表情序列进行实验,均获得了较高的识别率.
人脸表情识别;卷积神经网络;深度学习;多网络融合
人脸表情中蕴藏着丰富的情感信息,是人与人之间信息交流的一种重要手段.人脸表情识别技术作为一个涉及心理学、机器视觉、图像处理、模式识别等领域的交叉性课题,一直以来都是一个研究热点,并且在人机交互、虚拟现实、安防监控、身份认证等领域有着广泛的应用前景.
目前的人脸表情识别方法主要是在静态图片上分析表情,并且需要人为指定特征提取方向.常用的有基于人脸几何特征的方法[1],也有一些基于频域、像素的方法,如Haar小波[2]、Gabor小波变换[3]、局部二值模式(Local Binary Patterns, LBP)[4]等.还有一些基于模型匹配的方法,如活动外观模型(Active Appearance Models, AAM)[5].这些方法有两个不足之处:需要使用一组人工设计特征提取方向,这会在一定程度上丢失人为设定外的特征信息;以单一静态图片作为输入,从而忽略了帧间信息,未能结合运动时序下的表情变化给出分类决策.
卷积神经网络(Convolutional Neural Networks, CNN)方法[6-8]以其局部感受野和权值共享的特点,再加上池化方法的应用,大大降低了神经网络中参数的个数,使得该方法非常适合处理图像数据.2012年,文献[9]中构造了一个8层的卷积网络AlexNet,并在ImageNet竞赛上以绝对的优势获得冠军,Top-5的错误率为15.3%,相比于第2名使用的非卷积网络方法,将分类错误率降低了近10%; 2014年,Google运用22层的卷积网络GoogleNet[10]把ImageNet上的识别错误率降低到6.67%; 2015年,微软研究院[11]使用152层的残差网络,将识别的错误率进一步降低到3.57%,而人类在这一数据集上的错误率约为5.1%.这些足以体现出卷积神经网络在图片识别领域的强势.卷积神经网络的优势在于,该方法无须人为显示设定特征,可以通过网络的训练自动获取特征,并直接通过网络给出识别结果.这样获取的特征更具有推广特性和表征能力,并且某些在主观上认为不可行的特征也能发挥效用.然而,传统的卷积神经网络的方法却存在仅仅只能处理单一帧图片的弊端,笔者在原有网络的结构上进行了创新,运用了多网络融合技术,使得新构建的网络可以对人脸表情序列进行识别.
1 人脸表情识别网络模型
1.1 处理单一帧的卷积神经网络
如果仅处理单一帧,并对相应的表情进行识别,可以设计一个简单的卷积网络结构,如图1所示.
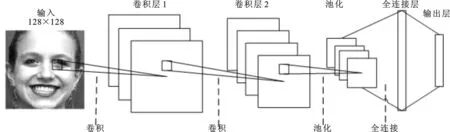
图1 处理单一帧的卷积神经网络结构图
该网络含有2个卷积层、1个下采样层和1个全连接层,最后接一个输出层.输出层函数即激活函数,这里选择softmax函数,其表达式为
(1)
其本质就是将一个K维的任意实数向量压缩(映射)成另一个K维的实数向量,向量中的每个元素取值都介于(0,1)之间,其中j=1,2,…,k.式(1)中的z表示全连接层的输出,即输出层的输入.
将神经网络的输出转换为概率向量,通过该向量可以看出对不同类别分类概率的大小.该层含有6个神经元,表示对6种不同表情进行分类.
网络的输入是一张128×128像素的图片,输出是一个6维概率向量,每一个维度代表了一种表情分类的概率.在图像识别领域,这种结构已经被证明可以取得非常好的效果,但同时也存在局限性,它只能以单一帧图片作为输入.人脸表情是一个连续的、动态的过程,若仅以一帧作为输入,则会丢失帧间信息,而这些信息反映着表情的变化过程,是重要的分类依据.
1.2 多卷积神经网络融合
针对传统卷积网络只能以单一图片作为输入的弊端,提出一种多卷积网络融合技术,使每个卷积网络处理一帧图片,然后将它们的处理结果融合起来,共同决策分类.网络结构如图2所示.
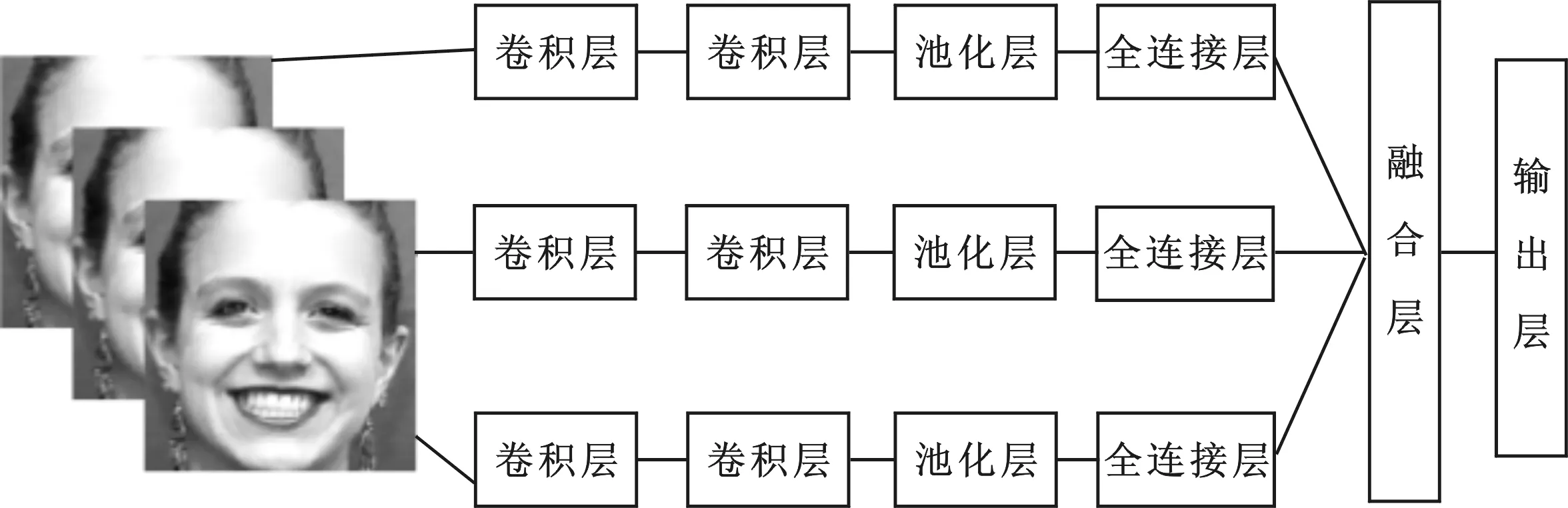
图2 多层次、3帧卷积神经网络结构图
该模型由3个单独的卷积网络组合而成,可以同时处理3帧图片的输入.若要处理更多图片,需增加卷积网络的个数.文中分别对3帧、4帧和5帧的表情序列进行了实验,将对应的网络结构分别命名为3帧卷积神经网络、4帧卷积神经网络和5帧卷积神经网络.
现就3帧卷积神经网络中的单个卷积网络结构进行说明.第1层是一个卷积层,分别对卷积核大小为 5× 5、11× 11和 17× 17进行实验,输出8个特征图; 第2层也是一个卷积层,分别对卷积核大小为 3× 3、9× 9和 15× 15进行实验,输出16个特征图; 第3层是采样窗口大小为 2×2 的下采样层,使用最大池化方式进行采样操作; 第4层是一个全连接层,含有64个神经元.1帧输入图片先后经过两次卷积操作,然后执行一次下采样操作,最后通过全连接层输出一个64维的向量.3帧图片会同时进行上述处理,因此在经过前4层之后,会得到3个64维的输出向量.接着将这3个向量通过一个融合层进行融合.最后通过一个输出层输出分类概率向量.
1.3 融 合 层
融合层完成的功能是将多个网络在其输出层进行融合,使之构成一个网络.融合的方式有连接、求和以及求积3种.设两个网络具有同维度的输出向量,分别为
x=(x1,x2,…,xn) ,y=(y1,y2,…,yn) ,
(2)
则在融合层会使用如下方式将其融合成一个向量.
(1) 连接方式.将2个向量进行拼接,拼接公式如下:
c(x,y)=(x1,x2,…,xn,y1,y2,…,yn) .
(3)
(2) 求和方式.将2个向量按元素相加,求和公式如下:
s(x,y)=(x1+y1,x2+y2,…,xn+yn) .
(4)
(3) 求积方式.将2个向量按元素相乘,求积公式如下:
m(x,y)=(x1×y1,x2×y2,…,xn×yn) .
(5)
2 人脸表情数据及预处理
实验数据来自CK+(extended Cohn-Kanade dataset)数据库[12],该数据库由卡耐基梅隆大学于2010年发布,主要用于人脸表情分类识别的研究.CK+数据库包含了123个成年人的总共593个表情序列,每个表情序列都由至少6帧图片组成,展现了一个人从自然到高峰的表情变化.
实验中取生气(Angry)、厌恶(Disgust)、害怕(Fear)、高兴(Happy)、难过(Sadness)和惊讶(Surprise)6种人脸表情进行分类识别,如图3所示.为了比较帧数多少与识别率的关系,分别取序列中后3帧、后4帧和后5帧图片进行对比实验.每帧图片还需经一系列预处理工序,从而得到最终实验数据集.

图3 人脸表情示例
首先将非灰度图片进行灰度处理,转换为灰度图片; 然后使用haar特征从图片中提取出人脸;最后将图片归一化为 128× 128像素.同时,为了增加训练集和测试集的数量,在原有的数据上做顺时针15°和逆时针15°的旋转变换,以生成新的数据加入训练集.整个扩展后的实验数据集共包含927个表情序列,约含 4 600 多张图片.为了提高实验结果的可靠性,采用5次交叉验证方法,将每类表情平均分成5份,每次取其中4份组成训练集,剩下的1份作为测试集,最终结果取5次实验的平均识别率.
3 网络训练
3.1 网络搭建环境
实验使用Keras框架搭建网络.Keras是一个基于python的神经网络框架,支持theano和tensorflow的无缝切换.使用Keras框架搭建网络十分简单,只需要数十行代码就可以完成一个网络的构建,并且支持在图形处理器上运行代码.实验的硬件平台为Inter(R) Core(TM) i5-4460 CPU 主频 3.2 GHz,16 GB 内存,NVIDIA GeForce GTX 1060 GPU 显存 6 GB.
3.2 损失函数及训练算法
实验使用交叉熵函数(Cross Entropy Function,CEF)作为训练网络的损失函数,即
(6)
其中,θ为神经网络的训练参数,y为期望输出,a为神经元的实际输出,n是训练样本的个数.神经网络训练的目的是要最优化这个损失函数.在训练过程中首先尝试了随机梯度下降(Stochastic Gradient Descent, SGD)算法,公式如下:
其中,θt表示t时刻的训练参数,Δθt表示t时刻θt的修正量,η是学习率,gt为x在t时刻的梯度.该式沿着负梯度方向更新训练参数θ.但是,随机梯度下降算法并未取得理想结果,随后选用动量算法进行训练,公式如下:
Δθt=ρΔθt-1-ηgt,
(9)
其中,ρ是衰减系数,表示要在多大程度上保留原来的更新方向,这个值在0~1之间.
动量算法的思路是模拟物体运动的惯性,在更新的时候在一定程度上保留了之前的更新方向.这样一来,可以在一定程度上增加稳定性,从而学习得更快,并且还有一定摆脱局部最优的能力.该方法较随机梯度下降算法在本实验上取得了更好的效果,但依旧不太理想.最后选用了Adadelta算法进行训练,其效果显著,公式如下:
其中,gt为x在t时刻的梯度,ρ是衰减系数.通过衰减系数ρ令每一个时刻的gt随着时间按照ρ指数衰减,相当于仅使用离当前时刻比较近的gt信息,从而使得在很长时间之后,参数仍然可以得到更新.
4 实验结果及分析
笔者做了3组实验,分别从帧数量、卷积核的大小和融合形式方面探究与识别率的关系.实验中统一将卷积层第1层的特征图数量设为8,卷积层第2层的特征图数量设为16,全连接层神经元数设为64.

表1 不同识别算法间的对比
表1中每个卷积网络的卷积层第1层的卷积核大小设置为17×17,卷积层第2层的卷积核大小设置为 15× 15,融合层使用连接方式.从表1中可以看到,多层次卷积网络方法相较于传统的方法,在识别率上有了较大幅度的提升.在多层次卷积网络方法中,随着输入帧数的增加,识别率也有小幅度提高.
图4(a)展示的是3帧卷积神经网络训练过程的识别率曲线,方形节点曲线表示训练集的识别率,三角节点曲线表示测试集的识别率.图4(b)展示的是3帧卷积神经网络训练过程中损失值曲线,方形节点曲线表示训练集的损失值,三角节点曲线表示测试集的损失值.

图4 3帧卷积神经网络训练结果
表2使用3帧卷积神经网络结构,融合层使用连接方式,分别设置了4种不同的卷积核大小.从表中可以看出,随着卷积核的增大,识别率逐步提升,但会有一个阈值.若将卷积核设置过大,则反而会使识别率大幅降低.

表2 卷积核大小与识别率的关系

表3 不同融合方式下的识别率融合方式识别率/%连接92.15求和91.94求积79.03
表3使用3帧卷积神经网络结构,每个卷积网络的卷积层第1层的卷积核大小设置为 17× 17,卷积层第2层的卷积核大小设置为 15× 15.从实验结果上看,使用连接或求和的融合方式,均可取得较高的识别率,但是求积的融合方式在此结构下并未取得理想效果.
5 结 束 语
参考文献:
[1] GHIMIRE D, LEE J. Geometric Feature-based Facial Expression Recognition in Image Sequences Using Multi-class AdaBoost and Support Vector Machines[J]. Sensors, 2013, 13(6): 7714-7734.
[2] PANNING A, AL-HAMADI A K, NIESE R, et al. Facial Expression Recognition Based on Haar-like Feature Detection[J]. Pattern Recognition and Image Analysis, 2008, 18(3): 447-452.
[3] GU W, XIANG C, VENKATESH Y V, et al. Facial Expression Recognition Using Radial Encoding of Local Gabor Features and Classifier Synthesis[J]. Pattern Recognition, 2012, 45(1): 80-91.
[4] SHAN C, GONG S, MCOWAN P W. Facial Expression Recognition Based on Local Binary Patterns: a Comprehensive Study[J]. Image and Vision Computing, 2009, 27(6): 803-816.
[5] MARTIN C, WERNER U, GROSS H M. A Real-time Facial Expression Recognition System Based on Active Appearance Models Using Gray Images and Edge Images[C]//Proceedings of the 2008 8th IEEE International Conference on Automatic Face and Gesture Recognition. Piscataway: IEEE, 2008: 4813412.
[6] LECUN Y, BOTTOU L, BENGIO Y, et al. Gradient-based Learning Applied to Document Recognition[J]. Proceedings of the IEEE, 1998, 86(11): 2278-2324.
[7] 刘如意, 宋建锋, 权义宁, 等. 一种自动的高分辨率遥感影像道路提取方法[J]. 西安电子科技大学学报, 2017, 44(1): 100-105.
LIU Ruyi, SONG Jianfeng, QUAN Yining, et al. Automatic Road Extraction Method for High-resolution Remote Sensing Images[J]. Journal of Xidian University, 2017, 44(1): 100-105.
[8] 史鹤欢, 许悦雷, 马时平, 等. PCA预训练的卷积神经网络目标识别算法[J]. 西安电子科技大学学报, 2016, 43(3): 161-166.
SHI Hehuan, XU Yuelei, MA Shiping, et al. Convolutional Neural Networks Recognition Algorithm Based on PCA[J]. Journal of Xidian University, 2016, 43(3): 161-166.
[9] KRIZHEVSKY A, SUTSKEVER I, HINTON G E. ImageNet Classification with Deep Convolutional Neural Networks[C]//Proceedings of the Advances in Neural Information Processing Systems. Vancouver: Neural Information Processing System Foundation, 2012:1097-1105.
[10] SZEGEDY C, LIU W, JIA Y, et al. Going Deeper with Convolutions[C]//Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2015: 1-9.
[11] HE K, ZHANG X, REN S, et al. Deep Residual Learning for Image Recognition[C]//Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 770-778.
[12] LUCEY P, COHN J F, KANADE T, et al. The Extended Cohn-Kanade Dataset (CK+): a Complete Dataset for Action Unit and Emotion-specified Expression[C]//Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2010: 94-101.
Multipleconvolutionalneuralnetworksforfacialexpressionsequencerecognition
ZHANGJingang1,2,3,FANGYuan4,YUANHao4,WANGShuzhen4
(1. Xi’an Institute of Optics and Precision Mechanics of the Chinese Academy of Sciences, Xi’an 710119, China; 2. University of the Chinese Academy of Sciences, Beijing 100094, China; 3. Chinese Academy of Sciences, Academy of Opto-Electronics, Beijing 100094, China; 4. School of Computer Science and Technology, Xidian Univ., Xi’an 710071, China)
As an important part of the human-computer interaction system, facial expression recognition has been a hot research field. The convolutional neural network cannot recognize expression sequence although it can train the classification features automatically for the reason that the direction of feature training need to be specified manually. In order to solve this problem, this paper improves the network structure, and proposes a multi convolutional network fusion method that can be used to identify the expression sequences containing multiple frames. First, we construct a number of convolutional neural networks, so that each network processes one frame, and then merge the results in the merge layer, and finally pass the softmax classifier to give the identity result. On the CK+facial expression database, experiments are carried out on the 3rd, 4th and 5th frames of expression sequences, and a high recognition rate is obtained for all experiments.
facial expression recognition; convolutional neural network; deep learning; multi network convergence
2017-05-22
时间:2017-07-17
国家自然科学基金资助项目(61640422,61775219,61771369,61540028);中央高校基本科研业务费专项资金资助项目(NSIY221418)
张金刚(1982-),男,副研究员,E-mail: zhjg007@126.com.
王书振(1978-),男,副教授,E-mail: shuzhenwang@xidian.edu.cn.
http://kns.cnki.net/kcms/detail/61.1076.TN.20170717.2102.002.html
10.3969/j.issn.1001-2400.2018.01.027
TP391
A
1001-2400(2018)01-0150-06
(编辑: 郭 华)
