基于机器学习对优质股的选择
2018-05-03王智
王智
(重庆市第八中学校,重庆,401120)
0 引言
机器学习中最关键的概念是学习,而机器的学习过程就是从无到有,自我不断修复更正的一个过程。该领域具有良好的市场应用前景。机器学习能够拥有今天的地位,也不是一帆风顺的,同样是经过漫长的摸索。从20世纪50年代到20世纪70年代初,人类对于人工智能的研究才刚刚起步,处于一个探索的阶段。20世纪70年代中期,人类对人工智能的研究到达了一个迅猛发展的时期,大量优秀的专家涌现,为人工智能注入了大量的知识和蓬勃的生机,例如E.A.Feigenbaum 作为“知识工程”之父在 1994 年获得了图灵奖。20世纪六七十年代,多种关于人工智能的学习技术出现并得到了进步,随后大量关于机器学习的周刊创办,使20世纪80年代的机器学习快速成长,其盛况不亚于先秦时期的百家争鸣。如今机器学习已经与多门学科领域相互交叉,在多家高校也开设了这个学科。它综合应用数学、自动化和计算机科学等。机器学习的应用宽度在不断扩张,更能与其他领域结合,如本文所探讨的优质股的选择;甚至一部分应用成果已经转化为商品。与其相关的竞赛活动也空前活跃。
股票投资已有相当长的时间。如何炒股,选择优质股也成为了国内股民心中疑惑。但在国外这个问题已经被新的方案:量化投资所解决。在国外量化投资已经有将近40年的发展历程,但在国内仍能算新鲜事物。相比于靠个人的经验和背景知识的投资,量化投资已经在国外取得了优异的成绩。在1971年时,美国巴克莱投资管理公司发行世界上第一只指数基金,标志量化投资的建立。如今,量化投资已经成为美国投资方式的根本之一。近年来,国内股市极不稳定,既有时势造英雄,同时不乏存在失败的典型案例。夸张而言一将功成万骨枯。为了使股民得到长期稳定的投资,通过参考国外量化投资的经验,结合机器学习的量化投资手段,从而达到获取稳定收益目的的新型交易方式无疑是国内人民的首选[1]量化投资也必然成为国内投资的新趋势并与世界接轨。
量化投资和传统的定性投资在理论基础上并没有不同,都是建立在能够掌控市场,产生超出已经付出的额外收益的特异组合。但量化投资与传统投资理念进行对比,不同的是,传统投资依靠人的主观进行选股;而量化投资却是人的投资的理念和经验通过算法建立数学模型,并利用计算机的强大运算能力来处理庞大的数据,只有通过大量运算后,确认数据是否符合模型,才会进一步投入交易中。同时伴随机器学习在各领域大显身手,量化投资这种新型投资方式必然能够走进历史的大舞台并且大放光彩。
1 机器学习
人工智能的关键内容是机器学习,机器学习的经典定义“计算机利用经验改善系统自身性能行为”。[2]简而言之,机器模拟人的行为,对已有的经验进行自动改进。
伴随人工处理成本高、人工处理困难这两大难题,而机器学习具备降低企业成本,提高投入产出比等优点,人类对机器学习的依赖也日益增长。
机器学习的主要内容是模拟从而实现自我学习。机器学习由分为两大步骤:一是不断探索人类的学习方式;而另一种是研究如何有效从海量数据中挖掘有效信息。学习形式又可以分成四类:有监督学习(通过历史输入和历史数据之间形成对应关系,生成映射函数)、半监督学习(直接对输入数据集进行建模,对应的输出数据)、无监督学习(综合利用少量标注样本和大量未标注样本进行训练)、增强学习(学习从环境状态到行为的映射)。而我们所探讨的随机森林算法属于有监督学习一类。机器学习能力的增强也便是通过某一程序解决问题的能力增强。
接下来我们将着重讨论随机森林怎样对选择优质股起到关键作用。
2 随机森林的构建
■2.1 决策树的构建
随机森林算法本就是一片茂盛的森林,发挥巨大作用,但倘若真正想要了解它,那便不得不从它身体中的一棵树,也就是决策树开始。
决策树是一种树形的分类结构,它的优点是分类效果明显,速度快,可读性强。
假设我们采用决策树来选取优质股票,该逻辑便可以用图1来解释。
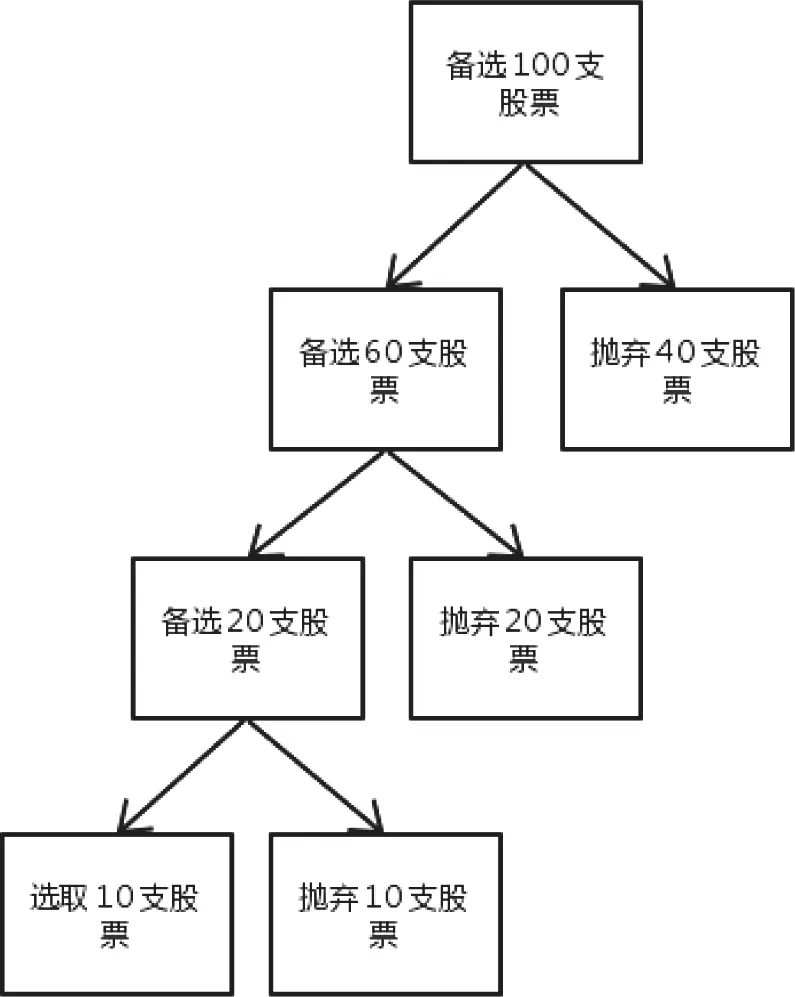
图1
首先我们对100支备选股票进行选择,根据因子,放弃不满足条件的40支股票,筛选出满足条件的60支股票。然后继续对这60支股票采用其他因子继续进行判断。重复采取这样的操作,直到满足所有条件即最后10支股票就是我们想要的股票组合。
■2.2 决策树的算法
ID3算法
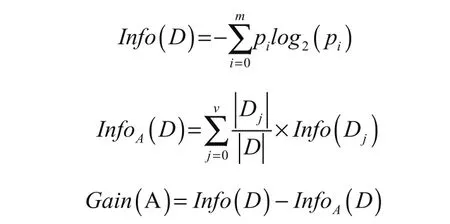
Gini系数
Gini系数指标的计算过程如下:
计算要的Gini系数
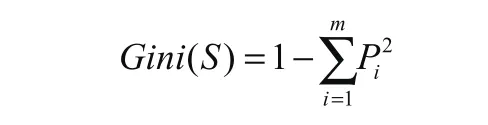
其中,i代表类别iP在样本集S中出现的概率。
计算每个划分的Gini系数
如果S被分隔成两个子集S1与S2则此次划分的Gini系数为
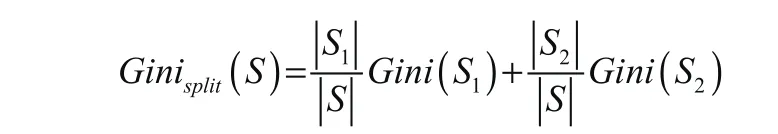
在节点分裂时,将每个属性的所有划分按照他们Gini系数来进行排序,节点分裂时,选择Gini系数最小的属性作为分裂属性,并按照其划分实现数据的分类。
通过两种方法均可计算出优质股。不过通过实验,Gini系数更佳。
■2.3 决策树的缺点
(1)因为决策树的构建是一个递归的过程,所以需要确定停止条件,否则过程将不会结束。每个子节点只有一种类型的记录时停止是一种最直观的方式,但是这样往往会使得树的节点过多,导致过拟合问题。
(2)决策树因为被限制在节点上,所以只能检验单个属性。(3)无法删除带噪声的不相关属性。
■2.4 随机森林
即使把决策树看成是一个专家,但它也有出错的时候。常言道:三个臭皮匠顶个诸葛亮;诸葛亮纵然神机妙算,也有七星续命失败之传说。决策树也不例外,也有失误之时,随机森林即是构建多个臭皮匠从而达到超越决策树这个单人大师的算法。
构建随机森林的关键是对特征值与数据的随机处理,使得生成的每个决策树都是随机的,不相同的,而到在最后采用“以少服多”表决的时候,可信度更高。
随机森林中的特征值就是股票中的因子,我们一开始选取大量的因子,然后随机抽取部分因子用来建树。对建好的树,在用数据进行训练的时候,该数据也是从全部数据中随机抽取的部分数据。这样生成的决策树之间的相容性就很低,可以避免由于相同错误带来的错误判断,进而提高判断结果的可靠性。最后我们在对所有决策树的结果进行统计的时候,采用简单的“多数优先”原则,来作为我们判断的整个结果。
■2.5 随机森林的优点
① 准确率与决策树相比增强。
② 其强壮性更强。
③ 随机森林的出现,使过拟合问题得以解决。
④ 速度更快效率更高。
也因此可以将随机森林运用在量化选股上。
3 量化选股
选股即为了解资金动向,增强自身的判断能力,从而对流动趋势有更深入的见解;其次是对自己选择的股票进行评级,来判断自己选择股票优劣的过程。恰当投资选股指标体系无疑就是量化选股,通过对数量化分析工具的使用来达到选取优质股的目的,其最重要的部分就是对数据的深入探讨。
通俗而言,量化选股是量化投资的一个分支,使选取股票组合数量化。传统的选股基于两个方面:基本面分析和技术面分析,有字面上的意思即可得知基本面分析侧重于股票的内在投资价值、各种因素于价格之间的内在联系和逻辑;技术面则是从股票变动的历史中探寻股票波动的规律。简单而言,基本面从本质探究股票、技术面从现有的规律预判未来的走向。量化选股并不与之矛盾,相反,它建立在其之上,并通过计算机的计算,采用一些数学模型来实现该种投资理念。
■ 3.1 因子
在本文中因子即为影响选股的成分或因素。
因子净利润增长率市值净资产收益率市场率净利润率流通市值工值市净率公司工作环境
■3.2 因子库的构建
构建因子如下,规模:市值、流通市值。盈利能力:净资产收益率、总资产净利率、净利润率。偿债能力:流动比率、速动比率、资产负债率。股东获利能力:市盈率、市净率、每股净收益、上市以来分红率。成长能力:营业收入增长率、净利润增长率、资产增长率、固定资产扩张增长率、wind一致预期净利润同比。营运能力:存货周转率、总资产周转率。以及其他因子,不过在挑选因子的过程中应该采纳更多因子,使其在挑选股票时更全面,同时也应该注意满足不过拟合[4]这个原则。
同时我认为在选取因子时,可以尝试考虑公司的环境这个因子,良好的公司环境营造出良好的工作氛围,也会吸引一批优秀人才来自工作,公司的潜力自然也非同一般。
■3.3 结合随机森林挑选因子
① 随机森林是一个组合分类器,能用于股票的筛选。
② 训练集的随机挑选:算法从所选择的因子中随机抽取子集,每次抽样均为随机。
③ 随机森林的构建:每一个子集生成一颗是决策树,并在其中挑选部分决策树进行分裂,从而达到随机性的目的。
④ 节点分裂:每棵树的分支的生成都是按照节点Gini系数最小原则选择分支进行生长。
⑤ 最终选多处得票得出结论
4 总结与展望
当下的时代背景也因为他的飞速发展,那个曾经一度追求精确高效率的金融界也悄然发生变化,主观证券投资这个行业也在被量化投资所取代。通过本文对机器学习乃至随机森林算法的简要介绍以及探讨它在量化选股中起到的作用无疑使更过人了解它并运用它去创造财富,同时领略新时代科技的魅力。量化选股也同样是一个需要不断充实的研究领域,本文的内容同样有待进一步地深入与探究。机器学习这个曾经幻想中的事物,已经在迅猛发展并结合其他领域焕发出蓬勃的生命力。
因为作者学术水平的低下,许多东西人只是猜测,并没有进行相关试验来证明,希望将来可以根据市场的真实情况来进行试验和深度的探索。
* [1]冯少荣,决策树算法的研究与改进[J],厦门大学学报,2007(04): 496—500.
* [2] Tom Mitchell,卡内基梅隆大学教授,“Machine Learni ng”,1997
* [3] 张润,王永滨,机器学习及其算法和发展研究[J],中国传媒大学学报,2016
* [4] 张建军,基于数据挖掘的股票数据分析[D],山东中国石油大学(华东),2010
* [5]孙娇,多音字量化投资策略及实证检验[D],南京大学,2016
* [6]陈健,宋文达,量化投资的特点、策略和发展研究[J],时代金融,2016(29)
* [7] 胡谦,基于机器学习的量化选股研究[D],山东大学,2016
* [8]方匡南,吴见彬,朱建平,谢邦昌,随机森林方法研究综述[J],统计与信息论坛,2011(3)
