基于内存的临时文件中转系统研究与设计
2018-05-03夏林峰
冯 静 夏林峰 刘 峰
(武汉理工大学计算机科学与技术学院 湖北 武汉 430070)
0 引 言
超级计算机是一个国家科研实力的体现,是国家科技发展水平和综合国力的重要标志。从世界的范围来看,超级计算机的应用目前几乎已涉及科学技术、工业设计、金融和经济管理以及军事国防等相关的各种领域[1]。
目前,大多数实际应用在超级计算机上的运行效率较低,基本都低于10%,有的甚至低于1%。随着处理器和存储器之间性能差距越来越大,特别是处理器和外存之间的巨大差距使得I/O瓶颈问题日益突出,因此在内存上直接建立内存文件系统的方法应运而生[2]。本文研究的意义即实现一个基于内存的临时文件中转系统来改进“天河二号”超级计算机采用集中式存储而导致的对大量小文件I/O的瓶颈问题,从而改善运行于“天河二号”超级计算机上的一套大规模并行漏洞挖掘系统的性能问题。
Ramdisk是最早利用内存虚拟一部分成硬盘分区来加速文件读取的方法。Ramdisk的优点是简单易行,利用现有的文件系统将内存格式化成虚拟磁盘即可。缺点是空间大小固定且不易更改,调整时需要修改内核配置参数并重新编译内核。另一个更严重的不足是未能充分利用内存直接快速访问的特性[2]。
Ramfs是一个将Linux的磁盘缓冲机制(page cache和dentry cache)作为一个基于ram的动态可扩展的虚拟文件系统。Ramfs的优点是数据直接存储在页缓存里,写性能有显著的提高,而且空间大小是自动扩展的,因为可以不断地申请缓存[2]。Ramfs的缺点是“脏页”既不会写回也不会被回收。如果持续写入数据,最终将消耗完内存从而使系统崩溃。
tmpfs是在Ramfs的基础上发展而来的。它依赖于虚拟内存子系统VMS(Virtual Memory Subsystem)构建。它继承了Ramfs的优点并从监控空间大小和使用交换分区两方面进行了改进。交换分区的数据实际上是存储在外存上的,这无形中就影响了访问速度。
“天河二号”超级计算机采用了集中式存储,使用全局的Lustre并行文件系统,该文件系统对于大尺寸、连续读写的文件操作性能较好。但是天河的集中式存储对那些会产生大量的临时小文件的系统会严重影响到系统读取性能,并且用户无法获取“天河二号”上计算节点的管理员权限,无法建立上文所说的Ramfs等内存文件系统。针对此类问题,本文拟采用用户级内存文件访问方法设计一个基于内存的临时文件中转系统来替换原来进程间的文件数据传递,以提升系统的整体性能。
1 系统相关技术
DCR是一个分布式并行计算运行框架,同时也是一种编程模型。从编程模型的角度来看,D代表了分解,表示需要将一个大的问题分解为若干个子问题;C是计算,表示对分解出来的子问题进行计算并得出子问题的结果;R是规约,表示对子问题的结果进行规约,最后得到总的问题的结果。从运行框架的角度来看,用户可以利用DCR框架来编写出符合DCR的编程模型的应用程序。DCR框架屏蔽了节点通信,网络传输等实现细节,而为用户提供了符合DCR——“分解,计算,规约”这三个步骤的相关接口。
DCR这个编程模型目前适用于易于并行,易于分解的问题。假设我们有原始问题:
R=C(S)
式中:结果用R来表示,S表示问题的输入,C表示问题的计算过程。则DCR编程模型要求该原始问题具有以下的特点:
1) 原始问题的输入S可以分解为n个子集{S1,S2,…,Sn},其中各个子集互不相关。
2) 对于分解出来的每个子集,他们能够同时进行计算,即子集间的计算没有相关性:
Ri=C′(Si)
式中:Ri是原始问题输入S的子集经过计算之后得出的结果。
3) 对于S的子集计算出来的结果,可以通过简单的规约得到最终的结果:
R=R′(R1,R2,…,Rn)
以上的几点条件中,特别需要注意的是输入S的子集的计算,只依赖于该子集的数据,而不依赖于其他的子集,也不需要和其他子集进行信息的交换。
DCR框架的程序主要包括调度节点程序,计算节点程序和管理节点程序。系统的总体架构如图1所示。

图1 DCR分布式并行计算框架总体架构图
目前DCR的应用场景分为两种:普通应用场景和迭代式应用场景。根据应用场景的不同,DCR 的计算流程也会有个别地方是有差异的。DCR在普通应用场景中的计算流程如图2所示。

图2 DCR普通场景计算流程图
2 基于内存的临时文件中转系统设计与实现
基于内存的临时文件中转系统又可称为临时文件内存交换TFEM(Temporary File Exchange in Memory),它由四个部分组成:生产者进程P、消费者进程C、中转进程E和注册管理进程R。操作的顺序为:
P: 打开文件F,写入文件F,关闭文件F;
C:打开文件F,读出文件F,关闭文件F。
在本文中,生产者的操作严格先于消费者。当消费者关闭文件后,临时文件内容消失 。
系统运行时流程为:
1) R和E初始化。
2) P(或者C)初始化,向R通过消息队列发送注册请求,R为其分配网络端口号(P_PORT或者C_PORT),并告知E的IP地址和端口号
3) P(或者C)向E发送请求,并完成操作。
4) P(或者C)向R发送注销请求,释放端口。
天河二号计算节点上的用户态内存文件中转系统总体结构如图3所示。

图3 天河二号计算节点上的用户态内存文件中转系统总体结构图
在DCR运行进程中将产生一个用于管理和控制内存文件中转的线程。该线程分为文件名管理和数据交换缓冲等两个部分。其中文件名管理主要是通过Socket连接接收来自目标进程的文件打开、关闭请求,注册临时文件的路径名等信息。数据交换缓冲则是在内存中建立数据缓冲,通过Socket连接接收来自外部进程的数据读写请求。图4给出了两个交替运行进程通过内存文件中转系统进行数据交换的流程图。
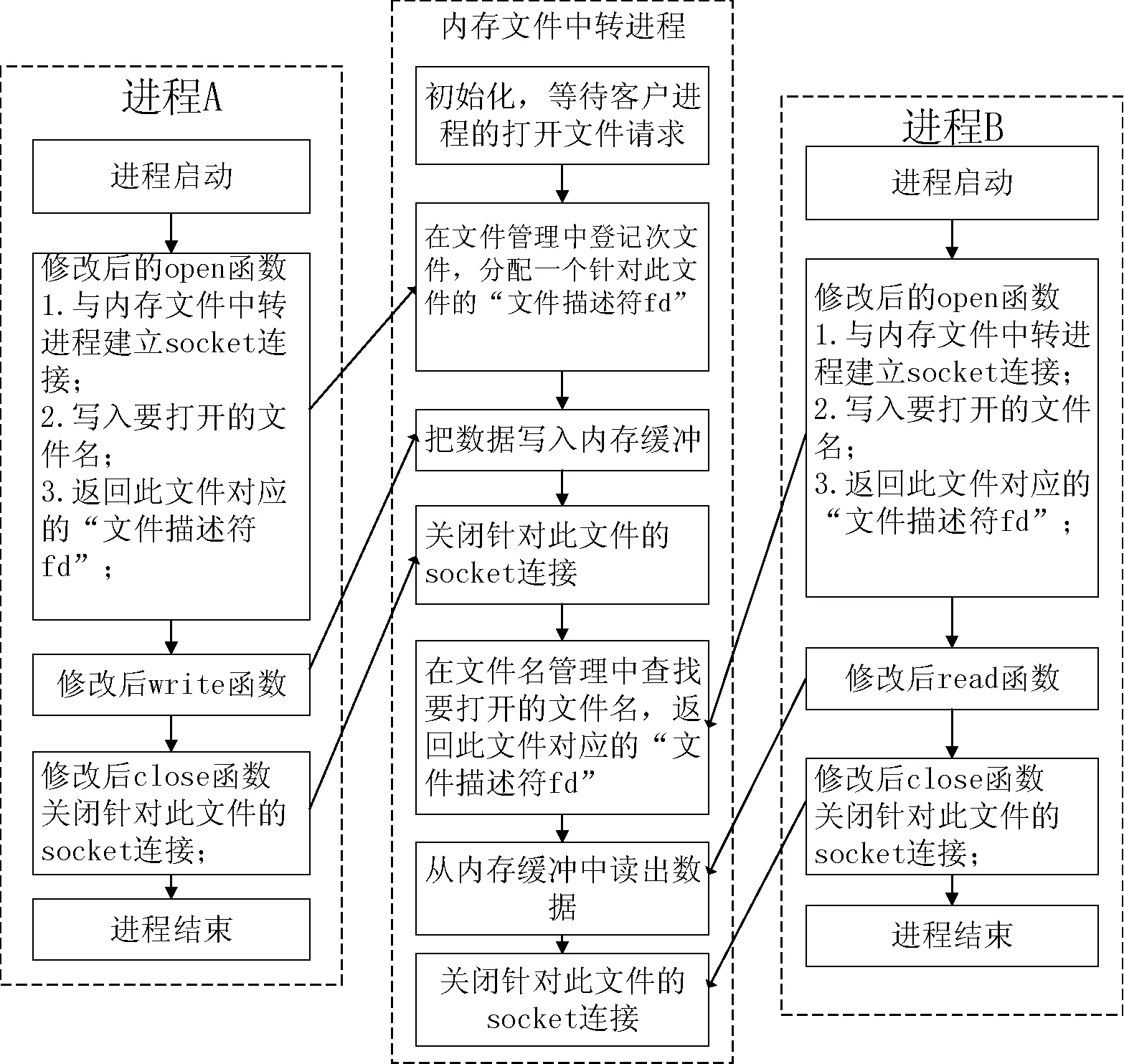
图4 内存文件中转流程
2.1 注册管理进程的设计与实现
注册管理进程实现算法描述:
1. 利用ftok产生唯一的key值;
2. 利用第一步生成的key值和msgget函数创建一个消息队列;
3. while (1)
3.1 利用msgrcv接收P/C的注册/注销请求结构体data;
3.2 if (data.action == 0)
用msgsend发送中转进程E的IP和port等信息;
else (data.action == 1)
//TODO
执行注销操作;
消息队列发送或接收的消息需要设置消息类型,在这里P和C的消息类型都设置为1。而把注册进程的消息类型设置为注册进程的进程号,把注册进程中msgrcv函数要接收的消息类型设置为1,这样注册进程只接收P/C的消息,避免注册进程在运行过程中接收自己发送的消息而导致错误使程序崩溃。
2.2 临时文件对象模型的设计与实现
2.2.1 临时文件对象状态转移
中转系统的中转进程E对临时文件对象的操作都必须先对临时文件对象的状态进行判断,然后才能做出最终的处理。因而引出了对临时文件对象的状态变化的设计。临时文件对象的状态转移图如图5所示。

图5 临时文件对象状态转移图
2.2.2 临时文件对象的实现
1) init函数 文件对象的init成员函数用来完成一个文件对象创建时的初始化和关闭时的清理工作,上层文件操作接口通过调用这个函数来实现类似于open和close系统调用的作用。
2) tfem_write函数 可将数据写入文件中,如文件尺寸大于文件对象默认的缓冲大小buf_size,则需要创建外部文件,句柄记录在long_temp_file_handle变量中,并把超过文件对象缓冲大小的部分写入外部文件中。生产者调用这个函数来实现类似于系统调用write的作用,tfem_write函数的算法略。
3) tfem_read 函数 被消费者调用,根据文件当前位置指针来将文件对象中的数据读出。如果要读取的数据长度大于文件缓冲的大小,需要根据存于长文件句柄变量中的文件描述符读取存于磁盘临时文件中的数据。消费者调用这个函数来实现类似于系统调用read的作用,tfem_read函数的算法描述略。
4) tfem_lseek函数 用在第一次使用函数tfem_read函数之前,用来将文件指针定位到文件头,来让tfem_read函数从文件头读取数据。消费者调用这个函数来实现类似于系统调用lseek(int fd,0,SEEK_SET)的作用。
5) tfem_stat函数 用在调用tfem_read函数之前,来获知要读取的文件的大小。消费者调用这个函数来实现类似于系统函数stat的获得文件信息的作用。
2.3 中转进程的设计与实现
在本文基于内存的临时文件中转系统中,文件是以文件对象的形式存储于一个文件对象数组中的。系统会预设一个常量TEMP_FILE_NUM定义进程E中支持的最大临时文件数。类似于磁盘中通过一个文件描述符来寻址一个特定文件,本系统会通过文件对象数组的下标来寻址临时文件。
为了实现文件名的注册与注销,本系统在中转进程E中设置两个映射:
1:map1
2:map2
第一个映射是临时文件名称到临时文件对象数组下标的映射,作用是在用open()函数打开一个文件时,判断临时文件系统中是否已经存在同名的文件。如果是生产者打开一个已经存在的文件,就会使open()函数调用失败。
第二个映射是临时文件对象数组下标到临时文件名称的映射,作用是在用close()函数关闭一个文件时,根据临时文件在临时文件对象数组下标得到该文件的文件名。然后在第一个映射中删除该文件,再调用init()函数,将该文件从中转系统中清除。
中转进程E在收到文件打开请求open()时的处理算法描述如下:
1.根据文件名filename查找map1,判断文件是否已经存在,如果存在,则
1.1用get_state()得到该文件的状态s;
1.2如果s == WAIT,则用set_state()设置文件状态为READ;
1.3返回文件描述符temp_file_index;
2. 如果不存在,则
2.1在文件对象数组temp_files中分配一个新的表项,并用init()初始化;
2.2用set_state()将该新文件状态设置为WRITE;
2.3将新元素
2.4将新元素
2.5返回此文件的文件描述符temp_file_index;
2.6将文件对象数组当前位置下标更新为(++file_index) % TEMP_FILE_NUM;
中转进程E在收到文件关闭请求close()时的处理算法描述如下:
1. 根据fd和get_state()得到该文件的状态s;
2. switch(s)
2.1 case WRITE:
2.1.1设置文件状态为WAIT;
2.1.2填写正确处理结果返回;
2.1.3break;
2.2 case READ:
2.2.1设置文件状态为INVALID,从文件对象数组中释放该元素;
2.2.2在map2中根据fd得到文件名;
2.2.3在map1中根据这个文件名删除对应的这个文件映射;
2.2.4在map2中删除fd这个文件映射;
2.2.5break;
2.3 case INVALID:
case WAIT:
2.3.1报错;
2.3.2 break;
3 在漏洞挖掘软件系统上的应用测试
将本文设计的基于内存的临时文件中转系统应用在一个漏洞挖掘项目中。该项目基于DCR分布式并行计算框架和“天河二号”超级计算机,它用到的几个开源软件模块包括Pipeline、Valgrind、Covgrind、Tracegrind和STP等。其中,Covgrind、Tracegrind是基于Valgrind内核提供服务的插件,Pipeline则用于管理Valgrind和STP的执行。
3.1 实验环境
本次实验采用的服务器K10和“天河二号”超级计算机系统硬件参数如表1所示。

表1 硬件平台参数表
3.2 性能测试
本文的所有实验测试均是在210=1 024个测试用例的情况下进行,中转进程的连接数约为17 400,而每个文件都有2个连接,推测出1 024个任务数大概产生的临时小文件总数约为8 700个。而每个文件都有几次到几十次的读写,导致系统存在频繁的I/O,从而影响系统的整体性能。其中,每执行一个测试用例所产生的临时文件读写情况如表2所示。
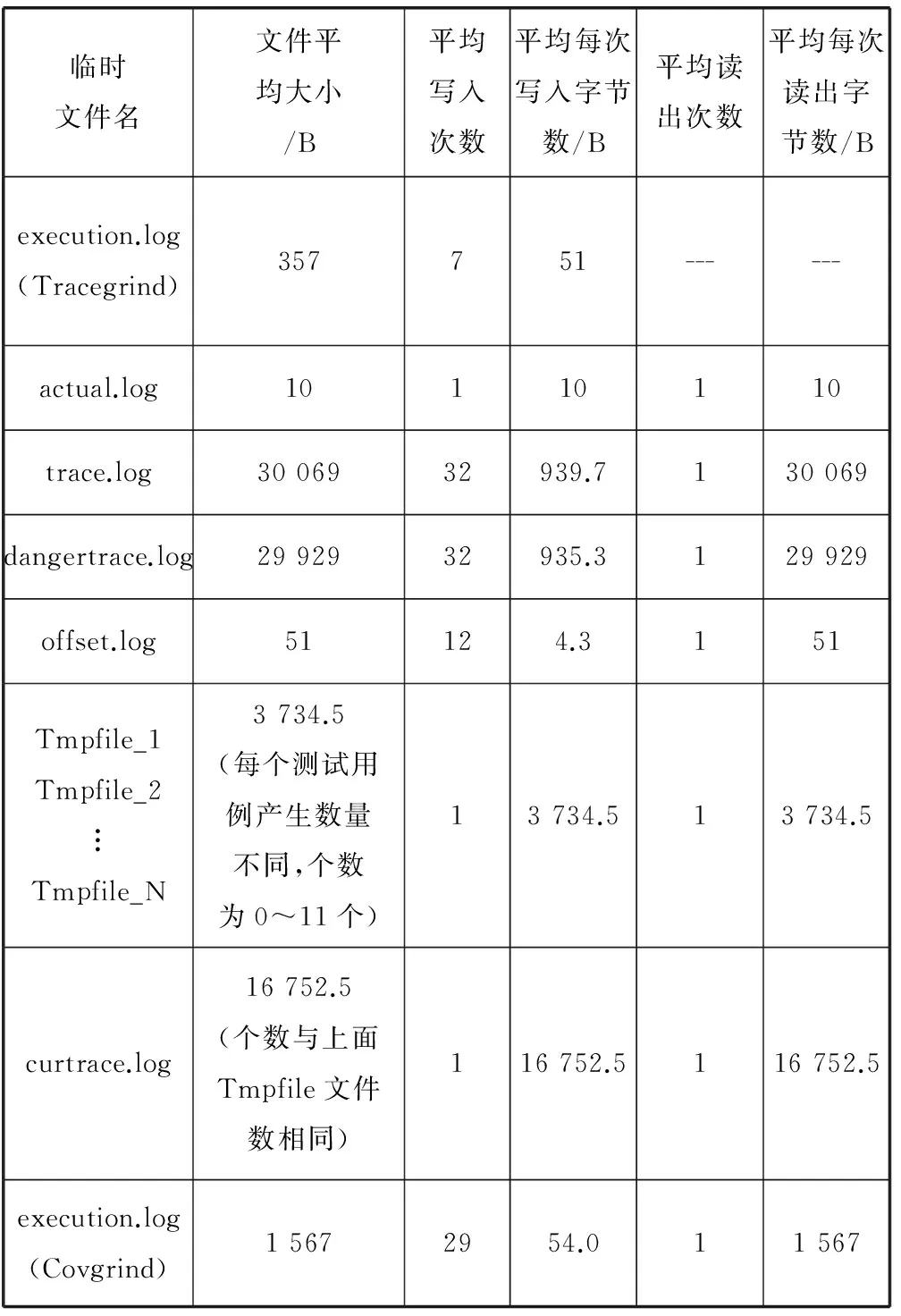
表2 一个测试用例产生临时文件的读写情况表
首先,本设计方法在实验室的服务器K10上进行了应用中转系统的单节点多线程的测试,证明中转系统在多线程情况下运行良好,且在单节点情况下,线程数越多,所用时间越少。具体数据见图6。

图6 在K10服务器上的单节点多线程测试
其次,将系统移植到“天河二号”超级计算机,进行测试。每次测试用的均是12个线程。在没用中转系统时,由图7数据可知,随着节点数增多,“天河二号”的Lustre并行文件系统I/O瓶颈开始体现,在2个以上的节点上,系统跑完的时间基本维持恒定,而不再增加。应用中转系统,目前单个节点的性能暂时还不如原来的系统,这是下一步去检查的问题所在。不过在应用中转系统后,受到原来I/O瓶颈的影响较小,随着节点的增多,在误差允许的范围下,系统跑完的时间基本呈线性减少,最后时间会少于原始系统跑完的时间。具体数据见图7。

图7 在“天河二号”计算节点上的多节点多线程测试
4 结 语
本文在对“天河二号”超级计算机的集中式存储的I/O瓶颈问题进行研究的情况下,根据实际情况,提出了采用用户级内存数据交换的方法形成一个基于内存的临时文件中转系统。借此来替换原来进程间的文件数据传递,来改善“天河二号”在大量小文件频繁I/O下的整体性能。
[1] 彭绍亮.研制发展超级计算机对国家意义重大[N].解放军报,2016-11-24(8).
[2] 张学成,肖侬,刘芳,等.内存文件系统综述[J].计算机研究与发展,2015,52(S2):9-17.
[3] The Linux Kernal Archives.RAM disk[DB/OL].2017-04-12.https://www.kernel.org/doc/Documentation/blockdev/
ramdisk.txt.
[4] The Linux Kernal Archives.ramfs[DB/OL].2017-04-12.https://www.kernel.org/doc/Documentation/filesystems/ramfs-rootfs-initramfs.txt.
[5] The Linux Kernal Archives.ramfs[DB/OL].2017-04-12.https://www.kernel.org/doc/Documentation/filesystems/tmpfs.txt.
[6] Matthew N,Stones R.Linux程序设计[M].陈健,宋健建,译.4版.北京:人民邮电出版社,2010:502.
[7] 杜毅,杨金生,吴震华.Linux消息队列分析及应用[J].计算机工程,2004,30(S1):175-177.
[8] Stevens W R,Fenner B,Rudoff A M.UNIX网络编程卷1:套接字联网API[M].3版.北京:人民邮电出版社,2015:78.
[9] 王枫,罗家融.Linux下多线程Socket通讯的研究与应用[J].计算机工程与应用,2004,40(16):106-109.
[10] Stevens W R,Rago S A.UNIX环境高级编程[M].尤晋元,张亚英,戚正伟,译.3版.北京:人民邮电出版社,2014:474.
[11] Hadoop 1.2.1 Documentation.MapReduce Tutorial[DB/OL].2013-04-08.http://hadoop.apache.org/doc/r1.2.1/mapred_tutorial.html.
[12] Lippman S B,Lajoie J.C++ Primer中文版[M].王刚,杨巨峰,译.5版.北京:电子工业出版社,2013:228.
[13] Linux Programmer’s Manual.FMEMOPEN[DB/OL].2017-05-03.http://www.man7.org/linux/man-pages/man3/fmemopen.3.html.
[14] Linux Programmer’s Manual.OPEN_MEMSTREAM[DB/OL].2017-05-03.http://www.man7.org/linux/man-pages/man3/open_memstream.3.html.
[15] ValgrindTMDevelopers.Valgrind[DB/OL].2016-10-20.http://valgrind.org/.
