基于TDOA的双曲型蜂窝定位技术
2018-04-27汪涛国家新闻出版广电总局724台
汪涛 国家新闻出版广电总局724台
1 前言
现阶段,伴随移动通信技术的持续完善,其遭受地面发射源干扰情况也变得日益普遍,这些干扰除了会对正常的广播通信造成威胁,还会对整个通信业务的正常运作产生严重不良影响。为了能够有效克服此些干扰,利用遭受的相关卫星,能够比较快速并且准确的明确地面干扰源的具体位置,因而能够较好的满足实际需求。
针对同一信号来讲,当其经历过2颗卫星转发时,在最终传送至接收站的具体路径乃是存在差异的,所以,在具体的传送至接收站的时间上,也是有具体的时间差值,这一差值就是业内所提的TDOA。现阶段,针对TDOA而言,通常情况下,有两种估计方法,其一,将2个基站所传送的信号所送达的具体TOA差计算出来,从中得到TDOA;其二,互相关技术,从本质上来讲,就是基于相邻基站,由其所接收到的同一信号,通过彼此之间的紧密运算,从中获得所需要的TDOA值。针对第一种方法来讲,因其在两基站同步方面有着比较高的要求,所以,基于实用层面来考究,本文最终选择采用第二种方法,来对双曲型蜂窝定位技术开展系统化研究,以此来最大限度的达到定位精度提升的目的。
针对移动通信定位系统而言,其在定位精度方面准确云否,起到决定作用的是所采用的定位技术,而定位技术在整个蜂窝网络当中的应用情况,乃是决定定位精度的核心所在,但需指出的是,对于蜂窝移动通信系统而言,其处于一种比较复杂、多变的信号环境,乃是不可回避的、难以避免的,受此影响,实际的移动定位精度便会出现大幅降低的情况。针对TDOA定位来讲,其在整个移动电话定位当中,处于核心地位,其能准确的将信号传送至各基站所存在的时间差检测出来,因而可以比较准确的估算出信号源的具体位置。针对通信基站而言,其能够对移动电话不断传输的信号进行实时、不间断监测,并且还能对信号传送至相邻基站所需要的时间(TOA),以及之间所存在的时间差(TDOA)给计算出来,针对同一信号而言,其传送至两个基站所存在的实际时间差,在某种程度上对一条移动电话相应双曲线起到决定作用,因此,针对两条轨迹双曲线,将其监测出来,能够明确移动电话的具体位置。依据既往所制定的TDOA定位原理,若可以比较准确且详细的将信号到达的具体时间差测定出来,那么便能够比较准确的将移动电话的相应位置给计算出来,所以,针对信号传送至各个基站之间所存在的时间差,将其估算出来,乃是整个TDOA定位技术的核心所在。
2 双曲型蜂窝定位技术基本原理
针对双曲线定位来讲,其主要原理即为:已经知晓基站BS1、基站BS2另外,还知晓各个移动台MS见所存在的实际距离差R21=R2-R1,那么由此便可得知,移动台的位置一定2基站处,而且还以其为焦点,还需指出的是,其与2个焦点之间所存在的相应距离差,均为R21相应实线双曲线上。与此同时,基站BS1与BS3之间,以及其与移动台间,所存在的距离差用公式表示为R31=R3-R1,根据此公式,便能够将另外一组移动台的各个焦点之间的距离差恒计算出来,得出R31位于虚线双曲线上。见图1:
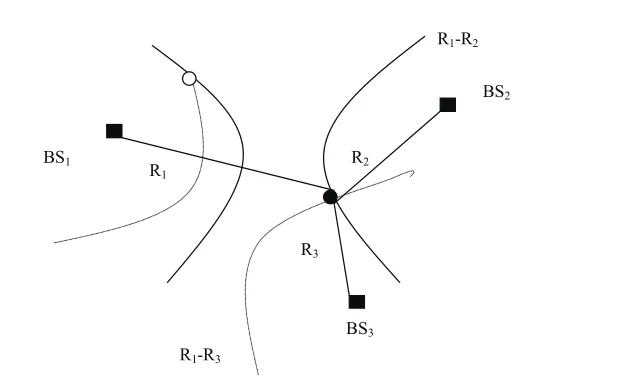
图1 双曲线定位
基于2个基站,测量其同时发出信号,传送至目标移动终端所用时间之间的差值t21。能够比较准确的将基站BS1与BS2,以及其与移动台间所存在的相应距离差给求出来。因此,两个基站到对应的移动台见所存在的相应距离差值可表示为R21=c×t21,相同原理,还能得出R31=c×t31,其中,c在公式中所代表的是空中电磁波所具有的传播速度。而在整个双曲线定位当中,移动台的具体坐标值为,而基站的具体坐标值为,(i=1,2,3),由此便可得出下列关系:
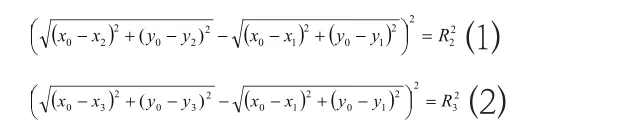
通过对上面的方程进行求解,便能够得出最后的2个解,这两个解便是与2对双曲线呈对应状态的2个交点。针对所得出的这2个解而言,因其中一个解所代表的是移动台的具体位置,因此,在进行实际操作时,需要先获得部分先验信息,比如小区的半径等,并运用这些信息,将真实解给分辨出来,运用此种方式将模糊解消除掉。
3 用遗传算法改进的TDOA算法
3.1 遗传算法介绍
针对遗传算法而言,从本质上来讲,其就是一种通过进化策略的应用,在整个解空间架构当中,找寻最优解的一种算法。对于染色体向量来考量,其就是通过浮点数编码的系统化运用;借助于所给出的自适应交叉率以及变异率等,而将各项结果求出来,伴随当今代龄的日益改变与更新,在实际搜索过程中,要想获得快速速度以及较准确的精度,并且在此过程中,不会对高适应度的相应个体造成破坏;针对非均匀变异算子来讲,其伴随着代龄的持续增加,同样会以一种动态的方式,从之前的全空间变异,向局部微调逐渐转变。图2为其流程。

图2 遗传算法流程图
自适应交叉率和变异率定义为:
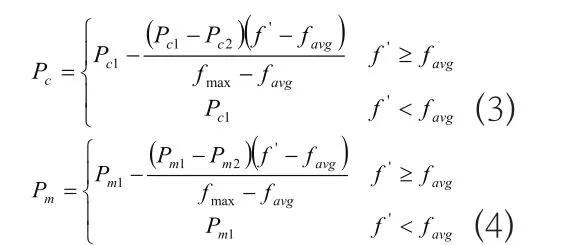
在此公式当中,fmax所表示的是整个群体当中的最大化的适应度值;favg所代表的是平均适应度值;针对而言,其所代表的是处于交叉状态的2个个体当中,一项比较大的适应度值。针对适应度值而言,如果其相比与平均适应度值,存在偏低情况时,表明此个体在整体性能方面并不佳;另外,如果适应度值相比与平均值,存在高出的情况,那么表明此个体在整体性能上比较好。因此,通过以动态的方式对个体适应度值进行优化,最终所得到的交叉率、变异率等,能够比较准确的得到准确信息,此外,对性能不好的个体,当御用的交叉率、变异率比较大时,那么对于那些优良个体,需要采取与之相适应、相符合的交叉率、变异率。
非均匀变异算子定义为
(3)保兑仓模式(预付类)-采购阶段。参与的对象包括:金融机构、上游供应商、下游制造商、仓储监管方(物流企业)。前两者表现为合作关系,金融机构给下游企业提供融资,中间两个研究对象表现供求关系,全链都表现为合作关系。
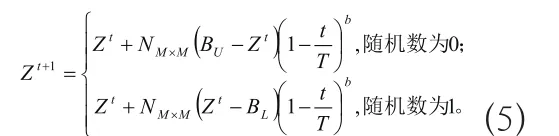
在整个公式当中,z所代表的是染色体向量;t所代表的时迭代数;而zt所代表的是第t次迭代时相应染色体向量;针对T来讲,其所表示的是最大迭代数;针对NM×M而言,其所表示的是对角矩阵,针对其对角线元素而言,如果处于[0,1]区间内,与均匀分布相应随机数相符,针对公式中的M而言,其所表示的是染色体向量的维数;而对于BU而言,其所表示的是染色体分量最大取值范围;另外,对于公式中的b而言,其所代表的是对迭代数依赖程度的相关系统参数。
为了能够将方程式(2)~(4)求解出来,对于本算法而言,则可取如下适应值:
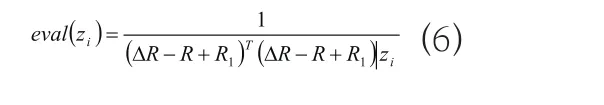
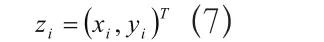
(3)无需额外的辅助信息,利用固有信息,便能获得良好的计算能力;
(4)其随机搜索特性乃是内在启发式的,在实际搜索时,遗传算法不容易混入到局部最优当中;
3.2 遗传算法搜索移动台的具体坐标
将约束函数极大值求出来:

在所列出的公式中,min(1)所表示的是x1上的阈值,而max(1)则表示的是x1下的阈值;同理,min(2)所表示的是x2上的阈值,而max(2)即为x2下的阈值。
运用遗传算法,将式(7)求解出来的具体步骤为:
(1)对决策变量加以明确,另对相应约束条件加以明确;(2)构建更佳的优化模型;
(3)对编码方法加以明确:可以运用10位长的二进制编码串,用于代表2个决策变量,即x1,x2。而针对10位二进制编码串来讲,其所表示的是,基于0~1023间,所存在的1024个数,因此,把x1,x2的定义域实施离散化处理,使之成为1023个比较均等的区域,包含2个端点在内,共有离散点1024个。基于离散点min至max,分别使其基于0000000000(0)~1111111111(1023)区间内,实施相应的二进制编码。
(4)对解码方法加以明确:在进行解码时,需将二进制编码串(20位长)进行切断处理,使之成为2个均为10位长的二进制编码串,然后,对其进行相应转换,使之成为更为实用的十进制整数代码,其一一个记作y1,另外一个记作y2。结合个体编码法和,把代码yi向变量xi进行系统化转换,从中便可得到解码公式:
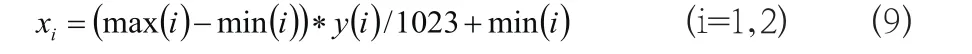
(5)对个体评价方法加以明确:把个体所具有的适应度,以一种比较直接的方式,当作目标函数值,也就是F(X)=f(x1,x2),然后,根据实际需要,从中选择个体适应度的倒数,并将其当做相应目标函数:J(X)=1/F(X)
(6)遗传算子设计:在对运算算子进行实际选择时,针对交叉运算而言,其运用的是单点交叉算子,而对于变异运算而言,其所选用的是最为基本的变异算子。
(7)对遗传算法相应运行参数加以明确:M表示的是群体大小,终止进化代数G,Pc所表示的是交叉概率,而Pm则表示的是变异概率。
基于上述步骤,便能够将此约束函数的极大优化值给求出来。将(x1,x2)求出,使此约束函数获得极大值。针对移动台来讲,其具体的位置坐标为(x1,x2),可将其当作Taylor算法的初始值。
3.3 函数优化仿真与对比
为了能够比较准确的对算法的性能进行验算,运用相应测试函数,对其实施系统化测试。针对此函数而言,其乃是比较典型的变峰、多极值点函数,在具体的定义域中,其极值点不止一个,当采用的是测试优化算法时,较难保证能够将此函数的最优解求出来,
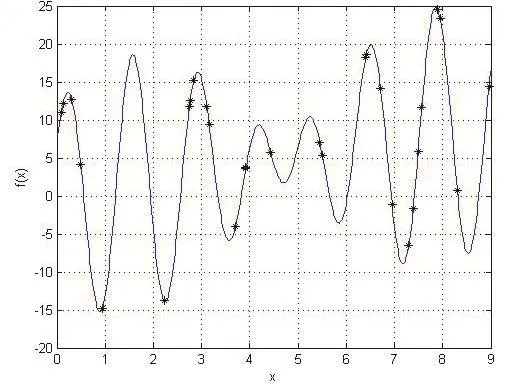
图3 染色体初始位置分布图
基于此图可知,横轴是染色体的初始位置的作标点,而对于纵轴而言,是曲线对应的函数。
针对遗传算法而言,其能够以一种比较好的方式,将全局的最优点找出。


图6 函数最优个体适应度值变化曲线
上图是最优个体适应度值的变化曲线,由此可得出,遗传算法在具体的收敛速度方面,还是比较快的,另外,经过一定过程的推进后,其趋向于平稳。由此可知,通过遗传算法的运用,不仅在既定的适应度函数中,其乃是以一种非规则的形式而呈现,而在非不连续状态下,也也能比较较好的将全局最优解给求出来。
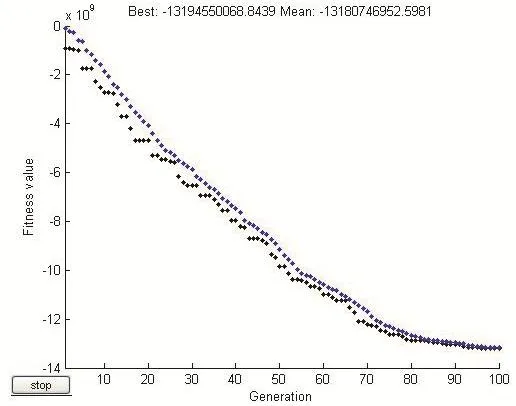
图7 遗传算法的最优解(1) 基点(0,0)
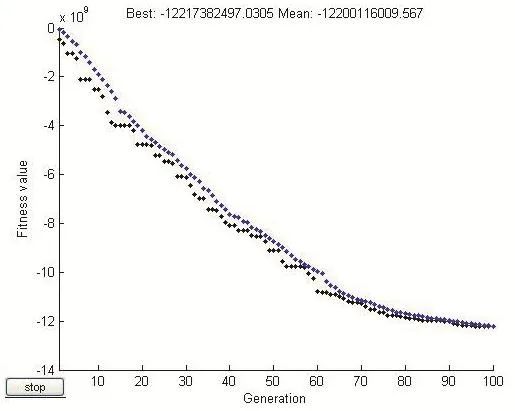
图8 遗传算法的最优解(2) 基点(1,2.5)
当对适应度函数所持有的基点位置加以改变时,便能从中获得遗传算法的最优解,但是会有不同的结果。
4 TDOA算法实际应用
用户从始发点到2个基站之间所存在的距离差,可以通过对用户到这2个基站之间的TOA差来来明确。其中所存在的关系是
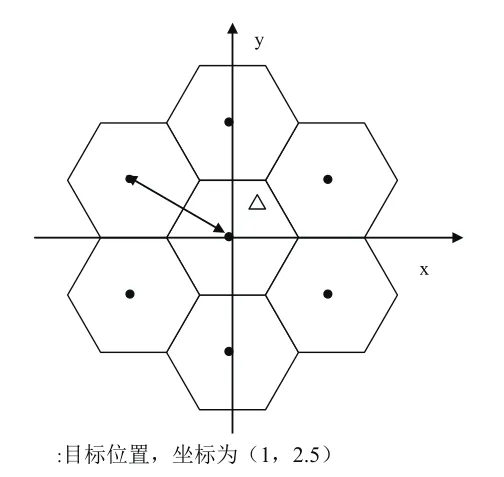
图9 接收机与目标位置示意图
将种群数设定为100,那么可得出T=140,b=6,Pc1=0.40,Pm2=0.05。另外,在具体的评价指标方面:MV所表示的是平均估计坐标,也就是说,E[(x,y)];都是方误差:通过独立运算,次数为10000次。那么可以得到如下仿真结果:表1中,Taylor栏所列出的就是采用Taylor算法所得到的相应仿真结果;而针对遗传算法栏而言,其就是采用遗传算法所得到的相应仿真结果,为更加方便的进行对比,可以选择如下参数:将种群数设定为100,而将迭代次数设定为T=200,另外,在杂交率方面,则设定为Pc=0.15,针对变异率而言,即Pm=0.25,b=6,进行独立的运算,运算次数为10000次。在上表中,第1栏10lg(cσ)就是依据蜂窝网通信系统等因素来加以明确的。
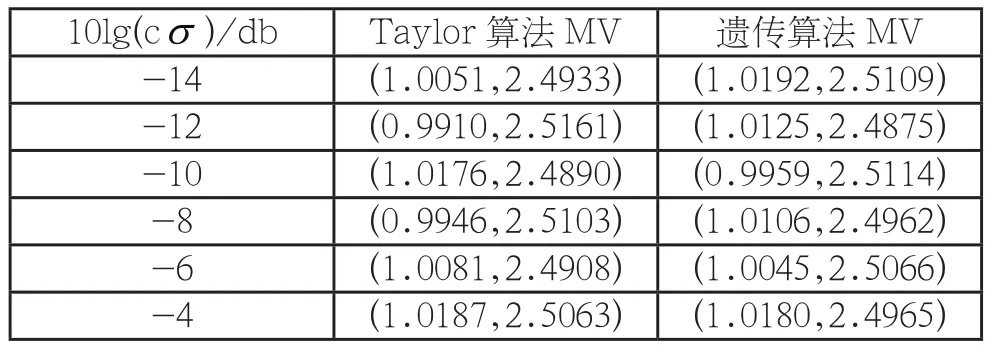
表1 Taylor算法和遗传算法MV比较
5 结论
综上,通过开展系统化的仿真实验,最终结果表米昂,以遗传算法为基础所开发的TDOA估计算法,有着比较稳定且优异的性能,可以获得解的精度高,特别是在有较大噪声的环境中,其相比于Taylor算法,在稳定性上更为突出,在搜索速度上更快,在精度上也更高。
[1]郭华.TDOA定位技术的基本原理和算法[J].西安邮电学院,2007,12(1):19~24;
[2]陈积明,林瑞仲,孙优贤.无线传感器网络通信体系研究[J].传感技术学报, 2006,19(4):1290~1295;
[3]王洪雁,宋玉,裴炳南.基于数据融合的TDOA定位方法研究[J].微计算机信息, 2007,(24):207~209;
