分布式平台等值连接优化技术分析
2018-04-24陈军
陈军
(四川大学计算机学院,成都610065)
0 引言
随着大数据时代的到来,以MapReduce和Spark为代表的分布式计算框架在大数据处理中发挥了重要作用。连接与过滤、排序、聚合等都是常用的数据库查询操作,相比外连接等非等值连接,等值连接更为常用。针对分布式平台分布式存储和计算的特点,对等值连接无关连接元组占用shuffle资源、等值连接数据倾斜等问题进行优化具有重要意义。
1 常见等值连接方法
1.1 M ap-sid e Join
在大表和小表等值连接操作中,若小表可以加载到内存中,则可将小表广播到各个分布式节点中,从而避免shuffle、reduce等过程,效率较高。在Map Reduce上借助Distributed Cache实现的了Map-side Join。在Spark中的BroadcastJoin提供了与此类似的功能,通常情况下表广播的默认阈值为10M,可通过spark.sql.au⁃to Broadcast Join Threshold进行设置,若设为-1表示禁用Broadcast Join。
1.2 Reduce-sid e Join
当两表均较大时,两表均无法放入内存,这就需要map端根据连接key值的hash值进行分区,将key值相同的点存放到同一节点中,然后在reduce端对收到的数据进行等值连接操作。该方法实现简单,适用场景较广,但由于中间涉及大量的shuffle操作,还存在着数据倾斜等问题,效率不高。在Spark中的HashJoin实现方法与之类似。
2 元组过滤技术
2.1 问题描述
在两表进行等值连接时,两表中都可能存在着大量无最终连接结果的元组,它们也参与到shuffle过程中,从造成网络资源的浪费。传统数据库中提取连接属性进行过滤的方法,也存在着在分布式环境中连接属性数据量较大,无法放入所有节点内存中的问题。采用元组过滤技术事先将无最终连接结果的元组过滤掉,将极大提高等值连接操作的效率。
2.2 位图(B itmap)
大数据处理中所说的位图技术不同于图像学中的概念,它用一个比特位表示一个整型数的存在与否,1表示存在,0表示不存在,对于一个int数字通常需要占用32位,而位图仅需占用1位,所以极大地节省了存储空间。文献[1]在Map Reduce中运用位图技术将两表的连接属性压缩生成“背景文件”,然后利用Hadoop的Distributed Cache传输到各个节点,并载入内存,在map阶段实现了部分无最终连接结果的元组的过滤,但过滤效果不够好。
适用场景:在判断整型数是否存在时,位图能极大节省存储空间,但不适用于对字符串等的操作,且过滤判断情况分类较少,应用范围窄。
2.3 布隆过滤器(Bloom F ilter)
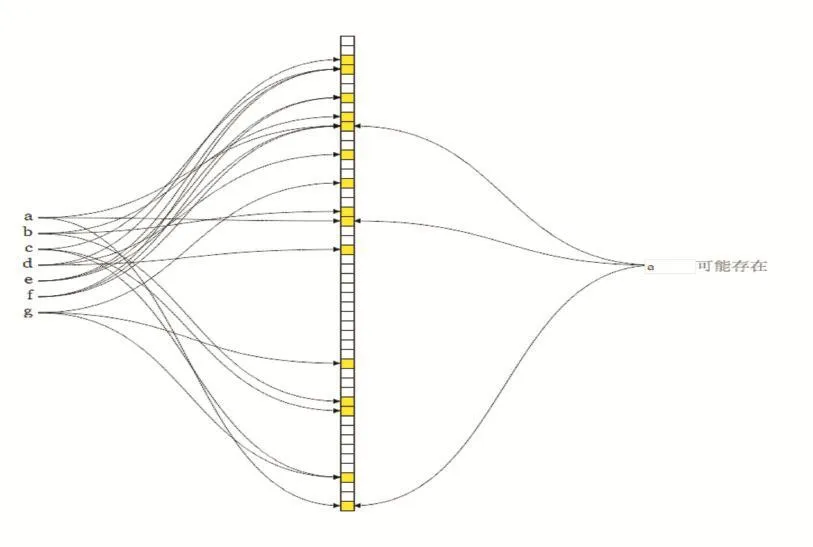
图1 布隆过滤器示例
布隆过滤器可以看成位图的扩展,它是1970年由布隆提出来的一种空间效率很高的随机数据结构,它利用位数组很简洁地表示一个集合,并能判断一个元素是否属于这个集合。但这个判断有一定误差的。这个误差体现为假阳性(false negative),即属于这个集合的元素,一定会被判为属于,但有可能会把本不属于这个集合的元素误判为属于。如图1中所示,用a到g生成的布隆过滤器中,a的3个哈希值均为1,则判定a可能在其中,若x的3个哈希值不全为1,则x必定不在其中。在分布式平台等值连接中如果将布隆过滤器用作连接属性的过滤,那么误判的元组虽然会参与到shuffle中,但不影响最终结果的正确性。文献[2]在Map Reduce中,采用两阶段和三阶段两种方法,对两表的连接属性进行去重,然后分别生成两个布隆过滤器,再将二者进行与操作,合并生成最终的布隆过滤器。再将布隆过滤器广播到各个节点,取得了较好的过滤效果。文献[3]在Spark平台下,运用Spark本身自带的RDD相关操作生成了用于过滤的布隆过滤器,并广播到各节点内存当中,实现了较好的过滤效果。
适合场景:当表连接属性非外键(重复率较高)、宽表(所含的列较多不便于进行广播操作)、符合连接要求的元组数较少时过滤效果好,但用两表共有连接属性生成布隆过滤器需要一定预处理时间,bloomfilter本身的广播也会战用一定的网络资源。
3 数据倾斜处理
3.1 问题描述
一个任务的最终完成时间,是由完成时间最长的子任务所决定的。根据帕内托法则(又称80-20法则)现实生活中的数据大多是不均衡的。在等值连接中,如果采用简单的哈希分区方法,值相同的数据将分配到同一节点,造成最终完成时间的延长。
3.2 基于采样或统计的重分区
在采样或统计的基础上,针对数值分布特点进行重新分区可有效解决数据倾斜问题。文献[3]提出了简单分区和虚拟节点分区。简单分区在倾斜数据周边划分更多的分区,但无法解决单一数值极度倾斜,数量超过分区大小的情形,虚拟节点分区可有效解决这个问题。
适用场景:采样速度快,精度低,统计成本高,精度好,要依据需求选择合理的方法为分区提供依据。
3.3 统计直方图(H ist ogram)
图2 直方图示例
直方图,又被称为质量分布图,是由一系列高度不等的纵向条表示数据分布的情况的统计报告图。统计直方图可以使我们了解等值连接属性的键值分布情况,从而为下一步的倾斜处理打下基础。文献[5]在获取了连接属性的统计直方图的基础上,将两表的连接属性划分为三组相互对应的集合,分别采用随机分发、广播复制、Hash分发的策略,避免了数据倾斜。
适用场景:当两表中倾斜值不同时,可有效减少数据广播复制量,但对两表中倾斜值相同的情况广播复制数据量较大,实现效果较差。
4 结语
本文介绍了基于当前主流分布式计算框架Map Reduce和Spark的常见等值连接方法BroadcastJoin、Reduce-side Join。针对元组过滤技术介绍了BitMap和Bloom filter在获取等值连接相关表的连接属性并过滤掉无最终连接结果元组时的运用。针对数据倾斜问题分别介绍了基于采样或统计的重分区和基于直方图的数据倾斜处理等方法。等值连接元组过滤和数据倾斜问题比较复杂,没有完全通用的方案,应根据数据特点,结合各种技术的优缺点,综合衡量,选择适合的等值连接方法。
参考文献:
[1]孙惠.基于Hadoop框架的大数据集连接优化算法[D].南京邮电大学,2013.
[2]Zhang C,Wu L,Li J.Efficient Processing Distributed Joins with Bloom filter Using Mapreduce[J].International Journal of Grid&Distributed Computing,2013,6:43-58.
[3]周思伟.Spark大表等值连接的优化及其在网络流量数据分析的应用研究[D].华南理工大学,2015.
[4]Atta F,Viglas SD,NiaziS.SAND Join—ASkew Handling Join Algorithm for Google'sMap Reduce Framework[C].Multitopic Conference.IEEE,2011:170-175.
[5]梁俊杰,何利民.基于Map Reduce的数据倾斜连接算法[J].计算机科学,2016,43(9):27-31.
