一种基于K-shell和半局部信息的节点重要性排序方法
2018-04-24谢越
谢越
(四川大学计算机学院,成都610065)
0 引言
随着信息技术的快速发展,人类的社会活动在越来越多的方面表现出网络化的特征。目前,我们的生活中已经充满了各种各样的网络[1],例如生物信息网络、交通运输网络、电力系统网络以及在最近几年迅猛发展的在线社交网络等。研究者们通过对各种不同类型的网络进行统计分析,对这些网络在传播动力学等方面表现出来的特性有了更进一步的了解[2]。
近些年,网络科学在信息技术的帮助下取得了快速发展,对网络中的节点按重要性进行排序成为研究者们日益关注的问题。孙睿等[3]对在网络舆论中对节点的重要性进行排序的研究现状进行了介绍,并分别对基于网络拓扑结构和基于节点属性进行节点重要性排序的方法进行了总结。但是,近几年有越来越多的研究者开始从更多新的角度对节点排序问题进行研究,例如Kitsak等人[4]于2010年首次提出了K-shell分解方法,并且通过该方法得到了比度指标、介数中心性等方法更为准确的排序结果,该方法的主要思想是认为节点的重要性取决于节点在网络中所处的位置。这个方法提出后,受到了研究者们的广泛关注,因此有必要对该方法进行更加深入和广泛的研究。
1 相关工作
1.1 网络的表示方法
设网络由图G=(V,E)表示,则网络中节点的数量为|V|,边的数量为|E|,该网络的邻接矩阵记为AN×N=(aij),无向网络中aij=1当且仅当节点vi和vj之间有连边,否则aij=0;有向网络中,aij=1当且仅当存在一条从节点vi指向vj的有向边,否则aij=0。将网络中与节点直接相连的节点的个数记为节点的度(de⁃gree)ki,具体表示为
多年以来,针对网络中的节点排序问题,已经提出了许多的方法,如度中心性[4]、介数中心性[5]、接近中心性[6]和基于特征向量的中心性[7]方法。度中心性方法是一种简单有效的局部性方法,忽略了网络的全局结构;介数中心性和接近中心性方法能够得到很好的排序结果,但是由于具有较高的计算复杂度,不能很好地应用到大规模网络中。
1.2 K-shell分解方法
由于度指标仅考虑了节点的邻居节点的情况,所以是一种反映节点局部特征的方法,并且认为如果两个节点的度数相同,那么这两个节点也具有相同的重要性[8]。然而,近些年有些研究发现,通过分析节点在网络中所处的位置,对于判断节点的重要性也具有至关重要的作用。如果一个节点位于网络的中心位置,那么即使这个节点的度数较小,该节点仍然具有较高的重要性;反之,如果一个节点处于网络的边缘位置,那么即使该节点具有较大的度数,这个节点对网络产生的影响也是有限的。Kitsak等人[9]基于这个思想,提出了K-shell分解方法,对节点的重要性进行了一种较粗粒度的划分。K-shell分解方法通过将网络中的节点通过递归的剥离,将节点划分为不同的层次,具体过程如下:首先,去掉网络中度为1的节点及其连边,剩下一个子图,检查子图中是否存在度为1的节点,如果存在,则继续进行删除操作。重复以上的操作,直到在子图中找不到度数为1的节点为止。至此,这些被删除的节点构成Ks=1的壳。在剩下的网络中,所有节点的度都不小于2,重复上面的操作,删除网络中度为2的节点,得到构成Ks值为2的第二层。依次类推,直到网络中所有的节点都被划分到某一个层次。
图1为K-shell分解的示例[9],图中,节点6和节点12的拥有相同的度数,但是它们在网络中处于不同的层。由此可以发现,单纯使用节点的度来对节点进行排序,并不能十分准确地将节点排到正确的位置。
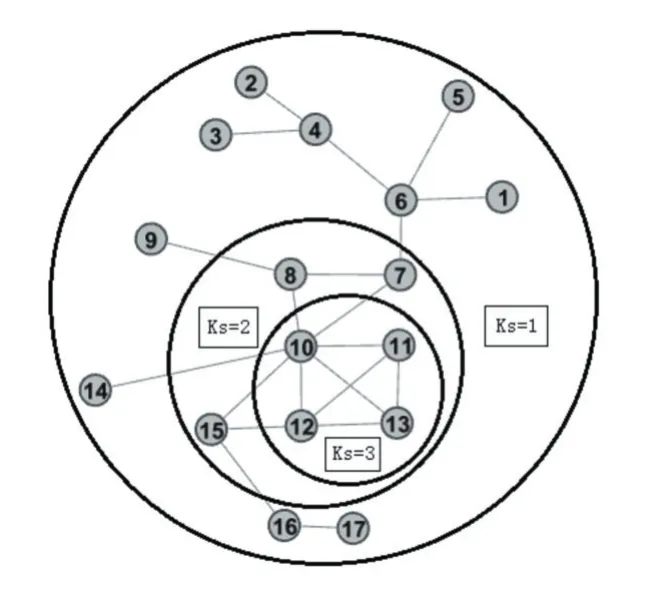
图1 K-shell分解示例网络
K-shell方法具有较低的时间复杂度,仅为O(m),非常适合用于对大规模网络进行分析,但是K-shell方法存在着一定的缺陷,即排序的结果太过于粗粒化,导致节点之间的重要性区分度不大[8]。针对K-shell方法中存在的这个问题,本文利用K-shell方法分解过程中节点被删除时迭代的层数并结合节点的半局部信息,对具有相同排序值的节点的进行进一步区分,从而提高排序结果的区分度。
2 结合半局部信息的改进K-shell方法
对图1的网络进行K-shell分解,整个K-shell分解过程如表1所示:
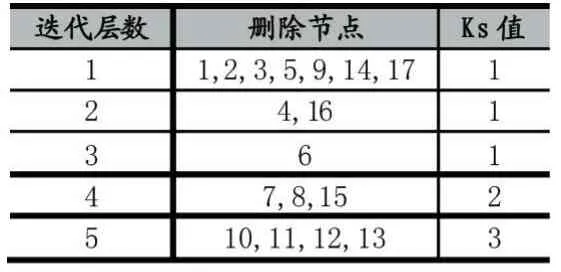
表1 K-shell分解过程
从表1的数据中可以发现,节点2与节点6具有相同的Ks值,但是通过对图1的网络进行观察可以发现,节点2与节点6对网络产生的影响是不同的,这是由于K-shell方法的排序结果具有较低的分别率导致的。从表1的第一列中可以发现,节点2与节点6在不同的迭代层数中被删除。因此将节点在删除操作中的迭代层数融入到Ks值中,并结合节点的度,从而进一步区分相同Ks值的节点的重要性。
定义1:给定一个网络G=(V,E),网络中节点i的度记为d,Ks值记为k,删去节点i时的迭代层数记为n,则融合节点的度和迭代层数的Ks值表示为:

对于图1示例的网络中的节点6来说,其Ks=1,n=3,d=4,因此 Ksd(6)=1*3+4=7;对于节点 2 来说,其Ks=1,n=1,d=1,因此 Ksd(2)=1*1+1=2。可以发现,通过将节点的度及删除该节点时的迭代层数相融合,能够得到更加准确的划分结果。
Bae等人[10]同时考虑节点的度数与Ks值,认为如果一个节点位于网络的中心位置,并且同时拥有较多的邻居,那么这个节点也就能对网络产生较大的影响。本文通过将Ksd值与节点的半局部信息进行结合,最终得到扩展的EKsd值。
定义2:给定一个网络G=(V,E),网络中节点i的Ksd值记为Ksd(i),i的邻居集合记为N(i),则扩展的Eksd值表示为:

对图1中的示例网络分别使用不同的方法进行节点排序,所得的结果如表2所示。通过对表2进行观察可以发现,单纯的使用度指标和Ks值得到的排序结果,都会出现许多节点拥有相同的排序值的情况,而通过使用结合半局部信息和Ksd值的方法对节点进行排序,得到的结果则具有更高的区分度。使用EKsd值得到的排序结果之所以能够得到更好的排序结果,是因为在该方法中同时使用了表现节点全局特征的Ksd值和表现节点局部特征的半局部信息。
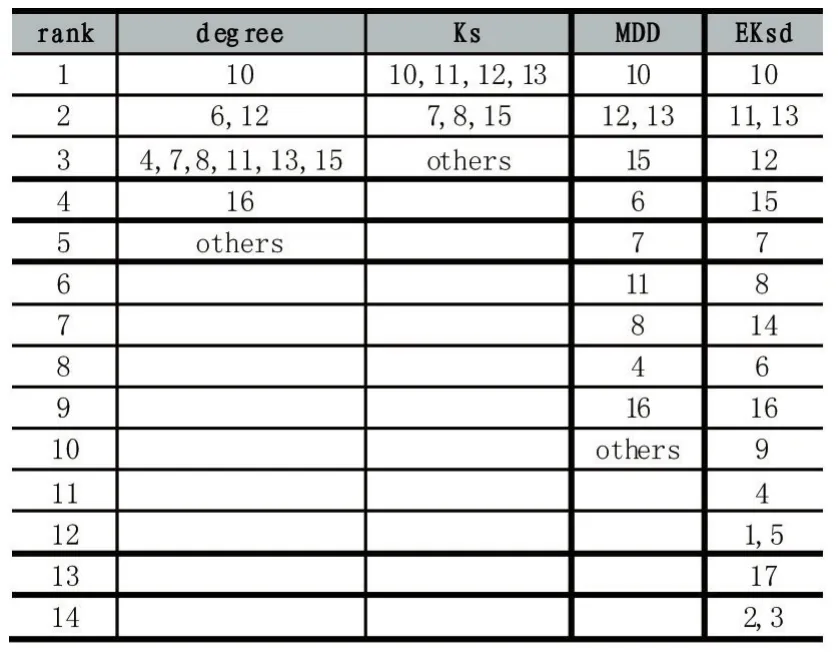
表2 不同度量指标对示例网络的排序结果
3 实验结果与分析
本文选取degree、Ks值、MDD三个指标与EKsd值进行比较,通过实验验证EKsd值方法对节点进行排序的结果的效果。首先对EKsd值度量结果的分辨率进行测试,即测试在排序结果中是否出现大量节点具有相同度量值的情况;接着对EKsd值度量结果的正确性进行测试,将通过ESkd值度量排序的结果与通过SIR模型得到的结果相比较,如果所得结果与通过SIR模型得到的结果越相近,则说明排序结果的正确性越高。本文选取三个不同类型的现实网络,通过进行实验验证所提方法的有效性。数据集的具体数据如表3所示。

表3 实验数据集
其中,Netscience[11]网络是科研合作网络,该网络中包含都是从事科学研究的人员及其相互关系;Email[12]网络来源于是西班牙罗维拉维尔吉利大学的Email网络;Blogs[13]网络来源于MSN社交网络,网络中包含各节点之间的相互关系。
3.1 分辨率指标
文献[10]中提出了一种用来进行评价不同方法排序所得结果的分辨率的指标,即Monotonicity。在排序结果中,如果具有相同的排序值的节点的数量越少,那么排序结果的区分度和分辨率也就越高。Monotonicity指标的定义如下:
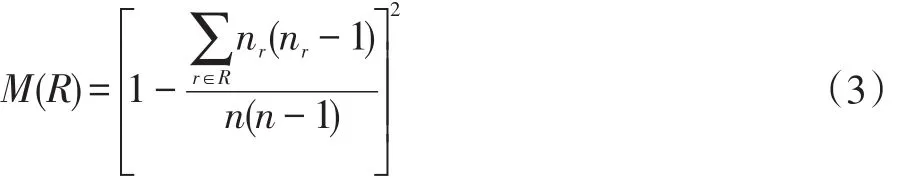
其中,R通过排序算法得到的排序结果向量;nr表示在排序结果中具有相同排序值的节点的数目;n表示排序结果向量中所有元素的数量;M(R)表示的是在最终的排序结果中具有相同排序值的节点在总节点中所占的比例。如果M(R)的值为1,意味着排序结果中所有节点的排序值都不相同;如果M(R)的值为0,则说明所有节点具有相同的排序值。表4展示了degree、Ks值、MDD、EKsd四种度量方法的Monotonicity指标值。

表4 不同度量方法的Monotonicity指标值
通过对表4中的数据观察可以发现,通过使用Ks值方法在3个网络中进行排序得到的结果分辨率最差,这是因为K-shell方法得到的排序结果是一种粗粒度的划分方法,导致最终结果中有大量的节点具有相同的排序值;degree指标稍好于Ks值,但是degree指标只考虑了节点的最局部信息,MDD方法的分辨率上有所提升,但是该方法存在参数的选择的问题,不同的参数值对排序结果有较大的影响。EKsd值在不同的实验数据集上的排序结果都具有最高的分辨率。
3.2 正确性指标
利用文献[10]中介绍的τ指标来对排序结果的正确性进行验证。首先,使用经典的SIR模型模拟网络中的传播过程,并按照节点的传播效率对节点进行排序,然后将不同排序方法得到的排序结果与SIR模型所得结果进行对比,得到的不同排序结果之间的相关系数。排序相关系数τ的定义如下:

其中:r和σ分别表示通过不同的排序方法得到的排序结果;nc和nd分别表示通过不同排序方法得到的结果生成的所有的序列对(rn,σn)中,具有相同排列顺序和不同排列顺序的序列对的数量;n代表排序结果中元素的数量;τ表示的是通过不同的排序方法得到的排序结果之间的相似度。
分别将degree、Ks值、MDD和本文提出的EKsd值四种方法的排序结果与通过SIR模型得到的排序结果进行比较,结果记录在表5中。表中的第二行和第三行分别表示在SIR模型中进行模拟时传染概率的阈值和本文所选取的传染概率,后面的各行分别是不同方法与SIR模型得到的传染效率σ的排序相关系数值。

表5 不同度量方法的τ指标值
从表5数据可以发现,根据EKsd值对节点进行排序得到的排序结果与通过SIR模型得到的仿真结果更加接近,这是因为EKsd值不仅考虑了节点的全局特征,同时将节点的半局部信息融入进来,从而提高了排序结果的正确性。
4 结语
针对传统K-shell方法具有的缺陷,本文提出了一种新的节点重要性计算指标EKsd,该指标基于K-shell方法和节点的半局部信息,考虑了节点在K-shell分解过程中被删除时的迭代层数,并综合节点的半局部信息来对具有相同排序值的节点的重要性进行进一步的区分,从而获得了具有更高的分辨率和准确性的排序结果。最后,通过在三个真实的数据集上分别进行分辨率和正确性的实验验证,验证了方法可以得到更好的排序结果。
本文综合考虑了节点的全局特性和局部特性进行节点重要性的排序,但是全局特性和局部特性在节点排序的结果分别具有何种程度的影响,目前尚没有明确的结论,未来将从这方面出发进行进一步的研究。
参考文献:
[1]刘建国,任卓明,郭强,等.复杂网络中节点重要性排序的研究进展[J].物理学报,2013,62(17):000001-10.
[2]李翔,刘宗华,汪秉宏.网络传播动力学[J].复杂系统与复杂性科学,2010,07(2):33-37.
[3]孙睿,罗万伯.网络舆论中节点重要性评估方法综述[J].计算机应用研究,2012,29(10):3606-3608.
[4]Phillip Bonacich.Factoring andWeighting Approaches to Status Scores and Clique Identification[J].Journal of Mathematical Sociology,1972,2(1):113-120.
[5]Freeman LC.Centrality in SocialNetworksConceptual Clarification[J].Social Networks,1978,1(3):215-239.
[6]SabidussiG.The Centrality Index ofa Graph[J].Psychometrika,1966,31(4):581-603.
[7]Katz L.ANew Status Index Derived from Sociometric Analysis[J].Psychometrika,1953,18(1):39-43.
[8]任晓龙,吕琳媛.网络重要节点排序方法综述[J].科学通报,2014(13):1175-1197.
[9]Kitsak M,Gallos LK,Havlin S,etal.Identification of Influential Spreaders in Complex Networks[J].Nature Physics,2010,6(11):888-893.
[10]Bae J,Kim S.Identifying and Ranking Influential Spreaders in Complex Networks by Neighborhood Coreness[J].Physica A Statistical Mechanics&Its Applications,2014,395(4):549-559.
[11]Newman ME.Finding Community Structure in Networks Using the Eigenvectors of Matrices[J].Physical Review.E,Statistical,Nonlinear,and Soft Matter Physics,2006,74(3 Pt2):036-104.
[12]Guimerà R,Danon L,Díaz-Guilera A,etal.Self-Similar Community Structure in a Network of Human Interactions[J].Physical Review EStatistical Nonlinear&Soft Matter Physics,2003,68(6Pt2):065-103.
[13]Hu Q,Gao Y,Ma P,etal.A New Approach to Identify Influential Spreaders in Complex Networks[M].Web-Age Information Management.Springer Berlin Heidelberg,2013:99-104.
