基于文档词典的文本关联关键词推荐技术
2018-04-24邱利茂刘嘉勇
邱利茂,刘嘉勇
(1.四川大学电子信息学院,成都610065;2.四川大学网络空间安全学院,成都610065)
0 引言
在信息爆炸的时代,为了快速找到人们想要的文档,先后出现了门户网站、分类网站、搜索引擎,这三类产品在很大程度上解决了信息过载问题[1]。其中,搜索引擎使用最为便捷高效,在当今被广泛的使用,国外的搜索引擎如Google、Bing搜索引擎,在国内有百度、搜狗等搜索引擎。人们在搜索引擎当中输入关键词,搜索引擎在短时间内找到和关键词相关性最强的网页,往往这就是用户期待的结果。搜索引擎利用关键词匹配在很大程度上解决了海量数据的查找问题,但是搜索引擎最原始的功能是通过关键词匹配,难以发现用户潜在的搜索关键词[2-3]。例如某位成都科技大学校友输入“成都科技大学”进行搜索,但其实成都科技大学是四川大学的前生,因为搜索引擎根据关键词仅仅匹配到和成都科技大学有关的文档,不能通过“成都科技大学”一词发现用户的潜在和关键词“四川大学”相关的文档。另外一种情况是用户并不知道自己要找的文档的关键词,例如用户很想知道和罗斯福总统在第二届任期搭班的副总统的资料,但是他又只知道罗斯福总统的名字,如果直接搜索“罗斯福”那么绝大多数文档都不会包含相应副总统的资料。为了解决这个问题,可以使用关联关键词推荐技术。关联关键词推荐技术根据用户输入的词语,推荐与该词语关系紧密的关键词,这些关键词有很大可能是用户的潜在兴趣点,解决了使用搜索引擎中难以发现用户潜在兴趣点的问题。
崔婉秋[4]等在2016年提出的耦合关系分析下的Top-k关键字推荐方法,文章通过分析关系型数据中的词条与用户初始化查询所提供的关键词之间的语义相关性,为用户提供语义相关关联关键词推荐。但这种方法严重依赖于数据库中存在的体条,并且更新困难,如果关系型数据中存在的词条数量不足,或者不是同一个领域的词条,将很难做到有效的关联推荐。
温有奎[5]在2016年针对用户的搜索词匹配,以关联关键词匹配组合的方式进行推荐,解决了信息检索的透明性问题[5],但是推荐的词汇是系统词汇库中的子集,词汇需要人工维护,词汇的质量和数据某种程度上决定了推荐效果的优劣。
依靠用户提供反馈的方法实现为用户推荐词条将增加用户的使用时间成本,另外所推荐的关键词受到用户行为记录影响较大,新加入的推荐语料不容易被系统所使用。另外,以关键词匹配组合方式的推荐方法对原始词库的依赖性强,针对不同领域需要建立不同的词库。为了解决以上不足,本文提出基于文档词典的文本关联词条推荐技术,以用户输入的关键词在语料库中根据词频向量模型算法检索出评分最高的N篇文档,将选出的文档使用TextRank算法提取出的关键词反馈给用户,本技术不考虑用户搜索的历史记录,根据语料库来向用户推荐关键词,使得推荐结果更为客观,新加入的预料将有同等被推荐概率,并且更多的语料加入系统将获得更好的推荐效果。另外本算法对不是针对特定领域的关键词推荐,选择不同领域的语料,能够针对不同领域做关键词推荐。
1 关键词推荐算法
1.1 推荐算法流程图
本文所设计的推荐算法步骤如图1。算法根据用户指定的关键词做关联关键词推荐,算法首先使用TF-IDF算法根据关键词在语料库中选取与关键词相对相关度高的文档,然后用TextRank关键词提取算法对筛选出的文档提取关联关键词,最后选取评分最高的N个关联关键词推荐给用户,完成推荐。
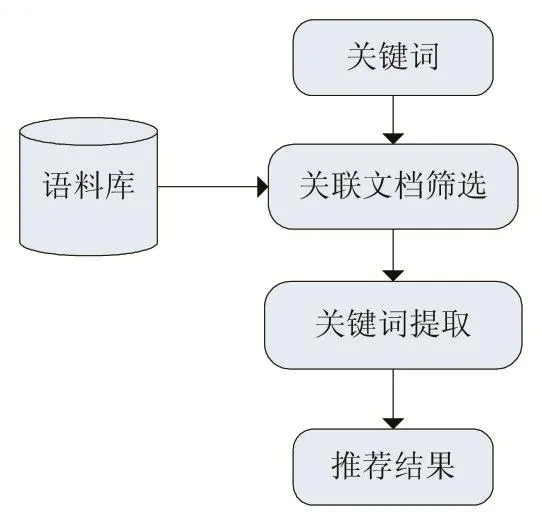
图1 关键词推荐算法流程图
1.2 T F-IDF算法以及关联文档筛选
在一篇文档中,一个词语在其中的权重越高,那么可以认为这篇文档与这个关键词关联性强,本文采用TF-IDF算法根据关键词筛选与之关联性强的文档。TF-IDF的主要思想是在一篇文章中,某个词语的重要性与该词语中出现次数成正比,同时与整个语料库中出现该词语的文章数成负相关[6]。TF-IDF中,TF表示词频(Term Frequency),表示一个词语在给定文档集中出现的频率,IDF表示逆向文档频率(Inverse Document Frequency),该指标评判一个词的普遍重要程度。TFIDF值的计算公式如公式(1):
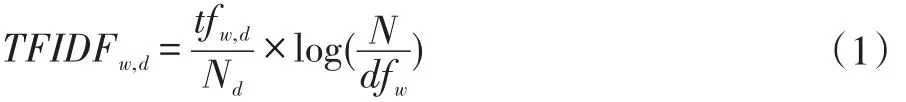
其中w为待检索的关键词,d表示一篇文章,tfw,d表示关键词w在文档d中出现的次数,Nd表示文档d当中关键词总数,N表示文档集的数量,dfw表示文档集中出现过w关键词的文档数量。
从公式中可以看出,针对某一个文档集,对于某个关键词,如果该关键词在其中一个文当中出现的次数多(tfw,d较大),但是含有该词语文档数目较低(dfw较小),就可以得到一个高TF-IDF值的词语,因此,TFIDF算法有效地过滤了常用词,并提升了重要词语的权重,同时一个关键词在一篇文章当中权重越高,表明该文档与关键词的关联性也越强。
本算法中的语料为普通文本文档,例如新闻文档。为了根据用户的输入关键词推荐词条,首先要在语料库当中筛选出与关键词相关的文档。首先通过TF-IDF算法筛选关联文档,步骤如下:
①将语料库中所有文档做中文分词处理,并出去文档当中的停用词,例如“的”、“了”以及标点等字符。
②计算各个词语在每篇文档出现的次数并统计得出一篇文档中词语总个数,记为Nd,对于文档中出现过的词语,对其在文档集中出现的次数增加计数,记为dfw。
③对于一个给定输入的关键词w0,对每一篇文章采用公式(1)计算改词在文档中的TFIDF值,根据推荐精度需求,选取TFIDF值最大的前m篇文档。
通过计算TFIDF值计算,筛选出和用户给定关键词相关的文档,这些从语料库中筛选出的文档中很大概率包含了和用户指定的关键词的关联词条。下一步从这些关联性很强的文档中提取出与给定关键词关联性强的词条。
TextRank算法提取文档关键词的方法如下:
对于词语与词语之间的关联,本算法基于这样的假设:如果文档当中确定了某一主题,那么该文档当中所出现的关键词与该主题相对关联度较高。在上一节,已经通过TF-IDF算法获取到与关键词关联紧密的文档,可以认为这些文档的主题与该关键词贴近。通过提取这些文档的关键词即可找出对应的关联关键词。本文采用TextRank算法和下文的关键词提取步骤提取文档关键词。
TextRank是一种基于图论的算法,该算法基于谷歌的PageRank算法改造演化而来[7]。PageRank的思想主要是:如果很多网页同时指向某一个网页,那么被引用的网页占据比较重要的位置,如果一个很重要的网页引用了另外的一个网页,那么另外一个网页的权重也应当提升[8-9]。TextRank算法将关键词类比于PageR⁃ank算法中的网页,进而计算关键词权重。
对于一篇文档的一个词语,定义某个词语前一个词为该词前驱,后一个词为该词的后继。对于一篇文章的词语来说,TextRank基于两个假设:
①数量假设:在一篇文档中,如果一个词语的前驱越多,那么这个词语也就越重要。
②质量假设:在一篇文档中,拥有高权值前驱的词语将传递更多的权值给后继词语。如果一个词语权值越高,则它的后继词语的权值也会相应的提高。
其计算公式为公式(2):
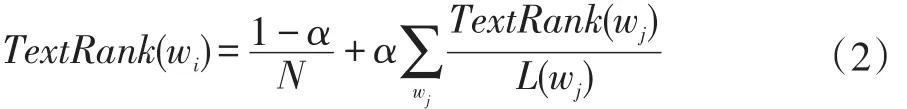
其中wi表示待计算的词语,α表示权值,取经验值0.85,N表示该文档中拥有的词语总数。wj表示后继为wi的词语。
关键词提取的目的是在文档当中自动抽取出若干个能够表征该文档的一组关键词。TextRank算法利用词语之间的局部位置关联关系,从文本提取关键词。计算一篇文档的关键词采用以下步骤:
①把文档进行中文分次,本文采用python开源分词库jieba,分词后,文档采用向量表示为T=[w1,w2,w3,w4,….,wm]。
②对于每篇文档中的词语wi∈T,进行词性标注处理,并过滤到停用词,只保留指定词性的词向量,例如在推荐单词中,一般保留名词。即D=[c1,c2,c3,c4,….cn],其中 ci∈T 且 n<m。
③构建候选关键词图G=(V,E),其中V为节点集合,由D中的关键词组成。然后根据关键词的位置关系,词语对应点Vi的入边节点为该词的前驱节点,同理对应的出边出节点为该词的后记节点。
④根据公式(2)迭代计算节点权重,直到TextRank值收敛。
⑤根据节点值的大小,取前N个关键词即为所推荐。
通过以上5个步骤可以从文档中提取出关键词。本步骤所使用的文档为第一节通过用户关键词预筛选的文档,从而这个步骤所得到的文本集和用户所搜索的关键词比较相关。然后将这些文档合并成为一个文档,并通过以上TextRank方法步骤提取这个组合文档的关键词,最终得到给用户推荐的关键词。
2 实验结果分析
2.1 实验方法
选用用语更加规范的文档作为语料,可以避免语料当中的简写、新词等干扰,因此实验分别采用人民日报财经版和人民日报科普版的新闻作为推荐系统的语料。指定200个待测试关键词,让不同的人阅读这些新闻,结合自身的知识针对这200个关键词给出对应的关联关键词,对于人工标记给出的关联关键词记为T(u)。最后将200个待测试关键词输入本文的推荐系统,推荐系统计算出的关联关键词记为R(u),如果推荐系统给出的关键词在人工给出的关联关键词库中记为正确,否则记为错误。
本文选取张丽颖在2016年提出的基于聚类的关键词推荐研究[13],作为对比试验,以下称为参考文献[13]。张丽颖在实验中通过与用户交互,让用户对一些文档做人工打分处理,这样获得到高价值的文档,然后根据这些文档做分词处理,形成文档-词项矩阵,然后将其聚类,取对应类别的前N个词作为推荐。
2.2 实验结果
实验结果本文推荐系统的评价指标主要准确率和召回率,这两个指标是推荐算法最重要的基础指标[14]。准确率用于表征系统能够准确的向用户推荐相关的关键词的概率,而召回率用于评价用户期望的关键词能够得到推荐的概率。其中准确率如公式(3):
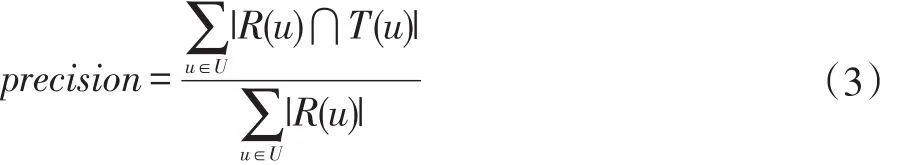
其中R(u)为用户推荐的关键词列表,T(u)为用户在测试集上预期的关联关键词列表。
召回率计算公式如公式(4):
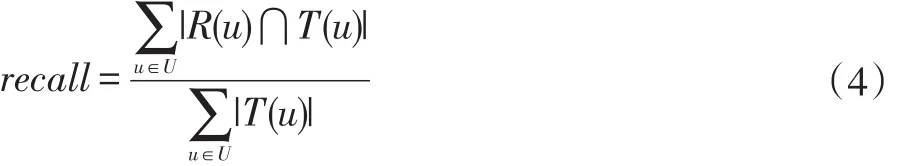
其中R(u)为用户推荐的关键词列表,T(u)为用户在测试集上预期的关联关键词列表。最终实验结果两项评价指标与参考文献[13]对比表1:
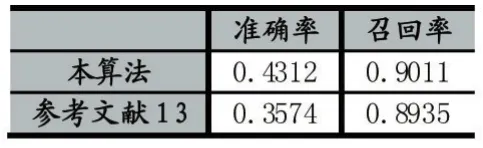
表1 实验准确率与召回率
从表1可以看出,关联关键词准确的准确率相对较低,但是有较高的召回率,这是由于在关联关键词推荐的场景当中,一个词语的在不同的场景中关联关键词有所不同,而在本次实验中,没有将近义词做等同处理,因此准确率低。但算法有较高的召回率,在本场景的推荐中,用户不过多关心推荐是否每个都是自己想要的,但关心潜在需要找到的关联关键词能够被推荐出来。本算法在准确率和召回率两个指标上都有提高,这是因为相对于文献[13],本算法不需要人工的对文档进行评分,推荐的结果更为客观,而通过用户评分选出的文档再做关联关键词推荐,选出的文档有限,而且可能用户评分不客观,因此准确率和召回率上不如本算法。
对于推荐算法运行速度上,实现分别选取不同数量的文档集,采用VirtualBox虚拟机将配置调到相同的配置,对比算法运行速度,对比结果如图2。
从图2可以得出,本算法的总体运行时间明显比参考文献[13]的运行速度要快,而且随着被推荐的文档集的数量增长,本算法的运行时间相对于参考文献[13]更有优势。这是因为新加入推荐语料,文献[13]会对所有语料重新做聚类操作,而本算法可以使得在大量的文档中,只选取与之相关度最高的前N篇文章做后续的推荐,虽然会丢失掉大部分的信息,但是这大部分文档与要推荐的关键词关联不大。因此节约了大量运行时间。
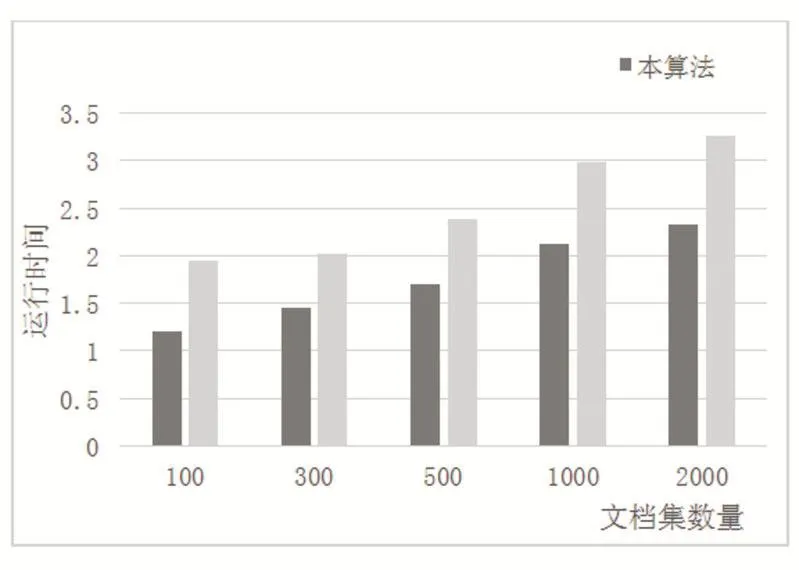
图2 文档数量-算法运行时间图
3 结语
本文提出的基于文档词典的新闻关联关键词推荐能够针对不同领域为用户推荐关联关键词。在语料删选过程中运用TF-IDF算法从语料库中过滤出与关键词相关的文档,有效地去除了大部分噪声文档。然后使用TextRank关键词提取算法,提取关键词,即为推荐关键词。与同类关联关键词推荐算法相比,本算法在准确率有大约提高7%,召回率也有所提升。另外本算法在运行时间上也有比较好的表现。因为本算法在第一阶段使用TF-IDF算法预先筛选获取到关联文档,所以算法对语料库要求不严格,不需要人工分类和标记等工作,新加入的语料库可以立即参与推荐,在适用和实时性方面都有较好的表现。但由于本算法在处理分词上采用第三方分词库,分词效果对推荐词有影响,在分词上,对不同领域需要做额外分词的处理,才能取得更好的推荐效果。
参考文献:
[1]Blank I,Rokach L,ShaniG.Leveraging Meta data to Recommend Keywords for Academic Papers[J].Journal of the Association for Information Science&Technology,2016,67(12):n/a-n/a.
[2]ZhangW,Xue GR,XueGR,etal.Advertising Keywords Recommendation for Short-Text Web Pages Using Wikipedia[J].Acm Transactions on Intelligent Systems&Technology,2012,3(2):36.
[3]李欢.个性化搜索引擎中关键词推荐专利技术综述[J].科技创新与应用,2017(5):95-96.
[4]崔婉秋,李昕,孟祥福,等.耦合关系分析下的Top-k关键字推荐方法[J].小型微型计算机系统,2016,37(8):1686-1691.
[5]温有奎.信息检索系统的关联关键词推荐研究[J].数字图书馆论坛,2016(4):11-14.
[6]张瑾.基于改进TF-IDF算法的情报关键词提取方法[J].情报杂志,2014(4):153-155.
[7]张莉婧,李业丽,曾庆涛,等.基于改进Text Rank的关键词抽取算法[J].北京印刷学院学报,2016,24(4):51-55.
[8]Nanos A G,James A E,Iqbal R,et al.Content Summarization of Conversation in the Context of Virtual Meetings:An Enhanced Text-Rank Approach[C].IEEE,International Conference on Computer Supported Cooperative Work in Design.IEEE,2017.
[9]Yu S,Su J,LiP,etal.Towards High Performance Text Mining::A Text Rank-based Method for Automatic Text Summarization[J].International Journal of Grid&High Performance Computing,2016,8(2):58-75.
[10]孙明.基于语义的信息检索与关联推荐关键技术研究[D].电子科技大学,2015.
[11]谢玮,沈一,马永征.基于图计算的论文审稿自动推荐系统[J].计算机应用研究,2016,33(3):798-801.
[12]王煦祥.面向问答的问句关键词提取技术研究[D].哈尔滨工业大学,2016.
[13]张丽颖.基于聚类的网络舆情热点关键词推荐研究[D].华北电力大学(北京),2016.
[14]朱郁筱,吕琳媛.推荐系统评价指标综述[J].电子科技大学学报,2012,41(2):163-175.
