基于语言模型的神经网络的文本情感分析
2018-04-24陈军清张毓
陈军清,张毓
(四川大学计算机学院,成都610065)
0 引言
随着网络社交以及网络评论的大量的活动不断地流行,情感分析也迅速地成为一个新的研究课题,其不管在研究方面还是商业应用方面,它都不断地受到越来越多人的重视,并且也产生了不少的价值。情感分析任在自然语言处理中是一个基础而且重要的任务,它是对带有情感色彩的主观性文本进行分析,处理,归纳和推理的过程,发现用户对商品的倾向性表达,对热门事件的关注度等。
目前,基于语言学特征和统计机器学习的方法在情感分析任务中仍然受到很多人的关注,例如,支持向量机、朴素贝叶斯、最大熵等方法,这些传统的机器学习方法,需要先验知识,依赖专业知识,预先的人工设计好的模型特征,构造出结构化的文本信息特征。然而这些方法对文本的表达能力有限,并且需要大量人工标注的情感词典、句法和语法信息,这些需要过多的人工,费时费力,在模型的泛化能力上并不没有表现地很好。
随着大数据时代的到来,文本数据规模也不断地扩大,深度学习方法表现出了它的优势,它是以数据为驱动,可以自动地从数据中获取有用的特征知识,无须人工的参与,避免了大量的先验知识。深度神经网络的出现也在自然语言处理任务中得到了很大的应用,并且取得了很大的提升作用。
对于文本情感分析问题,本文我们提出采用结合语言模型(Language Model,LM)的长短时记忆网络(Long Short-Term Memory Network,LSTM),即 LSTMLM。LSTM通过一种门机制解决了RNN的梯度消失问题,并且能够有效地学习长时间依赖关系。结合语言模型,获取了大量数据的语言特征,加速了训练的收敛速度,以及提高了模型的泛化能力。在中文情感数据集上,用精确率、召回率和F1值3个指标评估了我们的模型,通过实验结果严重表明,相对其他方法,我们的模型LSTM-LM取得了不错的效果。
1 基于神经网络和语言模型的结构
目前,由于深度神经网络在许多领域中取得了不错的成绩,尤其在自然语言处理领域中,达到了先进的效果,例如情感分析,神经机器翻译[3]和短文本分类[4]等。为了实现文本的情感分析任务,本文提出了一种基于语言模型的LSTM,即LSTM-LM(Long Short-Term Memory Network with LanguageModel)。
(1)RNN
标准的回复式神经网络(Recurrent Neural Net⁃work,RNN)结构如图1所示。RNN的隐藏层之间是有连接的,隐藏层的输入不仅有输入层的输入,还包含上一时刻隐藏层的输出,并且模型每个时刻都会结合当前输入和隐藏状态产生一个输出。

图1 RNN神经网络结构图
RNN的公式定义如下,对于一个给定长度为T的输入序列它按照时间顺序,从t=1到t=T顺序迭代公式,按序得到隐藏层神经元状态和输出序列
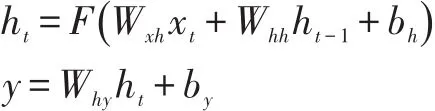
其中模型参数W是权值矩阵(Wxh是输入层x到隐藏层h的连接权值矩阵,Why是隐藏层h到输出层y的连接权值矩阵,Whh是隐藏层h到隐藏层h的连接权值矩阵),b是偏置值向量(bh是隐层偏置值,by是输出层偏置值),F是隐藏层的激活函数[5],通常设置为Sig⁃moid函数。
(2)LSTM[6]
对于文本序列问题而已,简单的RNN模型在处理长序列时可能面临的梯度消失的问题,而对于RNN的变体LSTM,它通过构建特殊的神经处理单元结构,减弱了梯度消失问题的影响,使得网络可以利用长距离的上下文信息,并且可以存储长时间的知识信息,因此在众多的任务中取得了很好的效果。其运算可以表示如下:
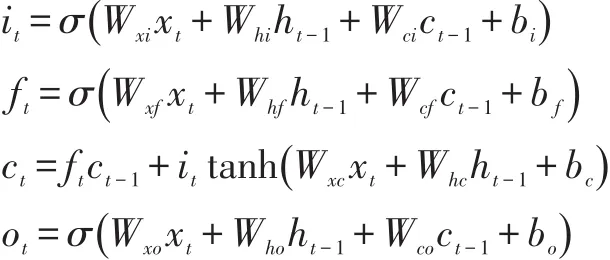
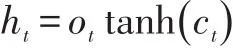
其中σ表示sigmoid激活函数,i、f、o和c分别是表示输入门(InputGate),遗忘门(ForgetGate),输出门(Output Gate)和记忆细胞(Memory Cell)的激活向量[3]。xt表示文本序列分词后的第t个词的词向量输入。
LSTM通过构建特殊的神经元处理结构,通过一种门机制的方式解决梯度消失问题,它能够有效地学习长时间依赖关系,使得网络能更好地发现和利用长距离的上下文信息。
LSTM的结构如图2所示。LSTM通过门机制结构,让输入的信息有选择性的影响每个时刻的神经元状态。而所谓的门结构就是通过不同的激活函数,例如sigmoid函数的输出一个0到1之间的值,来描述当前的输入能有多少信息量可以通过这些门结构,以此来控制和影响其他神经元状态和记忆存储。

图2 长短时记忆单元
(2)语言模型
我们在模型中引入了语言模型,它在自然语言处理处理领域,例如词性标注、机器翻译和信息检索等任务中起到了很大的作业。语言模型主要用来判断一个文本或者一个单词序列的连贯性,即通过大量的语料,通过统计每个词的统计数据,以此来计算该句子的概率,概率越大,表示它作为一个完整有意义的句子的可能性越大,概率越小,表示它作为一个完整有意义的句子的可能性越小。通过在特定的语境下,例如本文实验的语料数据,酒店评论数据集,它可以获得该语境下的语言特点。
语言模型的形象化描述就是给定一个长度为t的字符串,W=(w1,w2,...,wt),看它是自然语言的联合概率P(W)=P(w1,w2,...,wt)有多大,P(W)就是语言模型,即用来计算一个句子W的概率模型。
如何计算P(W)的概率呢?利用Bayes公式,上述联合概率式可以被链式分解为:
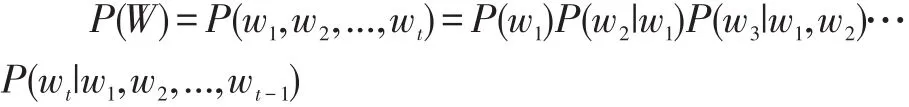
在我们的LSTM-LM网络中,我们采用的是基于循环神经网络的语言模型,词向量作为LSTM的每一个时刻作为输入,并通过一个Softmax分类器来预测下一个词出现的概率,其中用#符号作为结束符。
(3)总体模型结构
LSTM-LM模型的总体结构如图3所示,该模型主要由三部分组成:词向量层、LSTM网络和语言模型。本模型的整体流程为:首先对文本序列通过分词后,用词向量作为模型的输入,通过LSTM模型后,每个时刻都输出一个隐藏表达向量,再通过Pooling机制去融合每个时刻的输出向量,最终输出输入文本的向量化表示,本文采用了平均池化(Mean Pooling)的方式,它可以总体上反映句子的某种特征。对pooling层输入的向量,我们通过Softmax分类器进行二分类处理,进行句子的情感表达判断。同时,在LSTM输出的每个时刻,我们通过了一层前馈神经网络,主要是提升向量的表达能力,并且每个时刻都通过了一个具有语料库词汇大小的Softmax分类器,预测下一个词出现的概率。该语言模型的加入只要是为了提高模型的整体的泛化能力和提高模型的收敛速度。我们还在网络的全链接层中加入了防止过拟合的dropout机制。并且,把语言模型产生的误差和情感分析分类器产生的误差求和,最为该整体模型的代价函数。
2 实验介绍
为了验证本文提出的模型对文本的情感分析的有效性,本文通过互联网获取了有关中文情感挖掘的酒店评论语料数据进行对比实验分析。
(1)数据集介绍
本文我们选用了中科院计算所的谭松波博士提供的较大规模的中文酒店评论语料(ChnSentiCorp),其公布的语料规模约有10000篇,并标注了褒贬类别,被分为了 4个子集,ChSenti Corp-Htl-ba-2000、Ch Senti⁃Corp-Htl-ba-4000、ChSentiCorp-Htl-ba-6000和ChSentiCorp-Htl-ba-10000,本文选用了ChSentiCorp-Htl-ba-6000的数据集做为实验对象,其为平衡语料数据,正负类各3000篇。我们使用了10折交叉验证的方法去划分6000条数据,对我们的LSTM-LM模型进行训练和测试。表1为部分数据的代表样例。
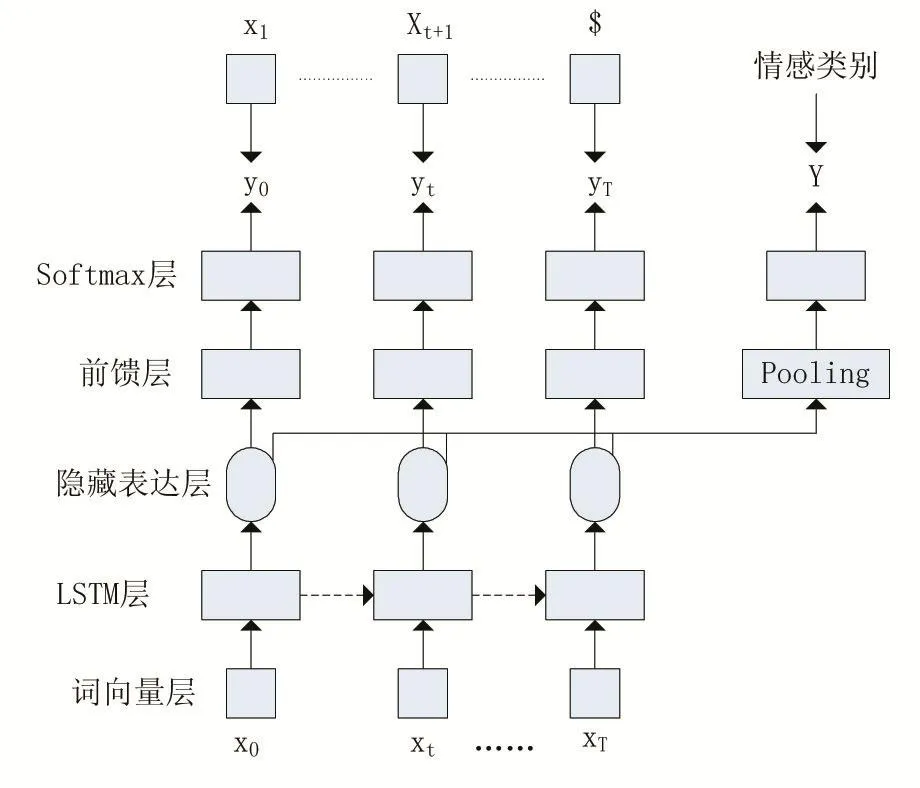
图3 基于语言模型的LSTM

表1 ChSenti Corp-H tl-ba数据集样例
(2)数据预处理
数据预处理是我们模型训练的前提和关键步骤。我们实验所采用的是中文数据,而中文不像英文,在字词层面有明显的分割,例如空格,中文在词层面上没有一个形式上的分界符。所以,我们必须对中文语句先进行分词操作,将文本序列切分成单词序列。本文,我们采用了结巴分词工具来对文本段进行分词处理。在我们的实验中,我们使用非监督的预训练的方式去初始化词向量,最为模型的输入层。我们采用中文维基百科数据作为训练的语料库,并且对其做了特殊的处理:简繁转换、中文分词、去除非UTF-8字符等。使用了Google开源的Word2Vec工具训练了Continuous Bag-of-Words(CBOW)[7]模型,上下文窗口设置为7,词向量的维度设置为400,采样值大小设为1e-5,我们用均匀分布[-0.25,0.25]初始化了未登录词的词向量。在训练过程中,词向量随着模型的其他参数一起调整。
考虑到整个系统软硬件的状况和人员配置问题,备用系统的运行维护采用如下方式:数据服务器、前置服务器、历史服务器长期带电运行,任何时候保证两个系统的图形和数据库的同步。其他设备如调度员工作站定期半个月进行一次通电试运行,对各项功能进行测试,如果发现问题,马上处理。这样的运行维护方式可以减少调度自动化人员的工作量,又能保证备用系统随时可以投人运行。
(3)模型参数设置
对于本文的网络结构,我们采用了Sigmoid作为激活函数,LSTM的隐藏层的神经元个数为100,dropout值为0.5用来防止过拟合,训练集和测试集的batchsize大小为32,输出层采用了Softmax进行二分类处理。我们采用了10则交叉验证方法,随机将数据集分成了10份,我们10折交叉验证,随机将数据集分为10份,每次将一份做为测试集数据,其余作为训练数据。训练过程中,采用了基于随机打乱的mini-batches的随机梯度下降法来进行权值的更新迭代。最后采用了提前终止训练的方法,当验证集上的F1值连续下降5次后,或者迭代次数超过30次后,我们就终止训练。
(4)实验评价指标
对于二分类问题,常用精确率(precision)和召回率(recall)来作为评价指标。通常以关注的类为正类,其他类为负类。根据分类器在测试数据集上的预测结果数分为4种情况:TP:将正类预测为正类数;FN:将正类预测为负类数;FP:将负类预测为正类数;TN:将负类预测为负类数。
则两种评价指标定义如下:

其中精确率用来衡量分类器的精确性,召回率用来衡量分类器是否能找全该类的样本,而为了兼顾两者,引入了它们的调和均值,即F1值,定义如下:

精确率和召回率都高时,F1值也会高。
3 实验结果与分析
本次实验是在深度学习框架Theano上进行训练,在文本情感分析中,我们用Word2Vec的方式对词向量提前做好了预训练处理,在ChnSentiCorp-Htl-ba-600数据集上训练,我们采用了 SVM、CNN、CNN_LM、LSTM、LSTM_LM、BiLSTM、BiLSTM_LM 七种方法进行了对比实验,才用精确率、召回率和F1值作为评价指标。实验结果如表2所示。

表2 七种模型的分类结果性能对比
通过以上对比实验可以发现,基于神经网络的各种方法都优于传统机器学习方法SVM,因为神经网络方法在自动获取文本隐藏的知识特点有更好的能力,并且在泛化能力上也更加出众。并且在神经网络方法对比来看,基于RNN(LSTM,BiLSTM)的方法整体上也好于基于CNN的方法。因为CNN善于获取静态数据特征,例如图片等,它的卷积核的窗口大小在获取文本数据特征时,只能得到有限的上下文的特征。而对于RNN方法,它善于处理连续的动态序列问题,并且可以处理长序列问题,获取更长的上下文数据特征,LSTM对于传统的RNN模型,解决的了梯度消失问题。
语言模型的引入主要为了能在语义特征方面获取语料的语言特征,通过实验发现,它也在不同的程度上给各个模型带来了提升。通过实验对比,它的引入使各种神经网络模型训练可以更快地收敛,并且也提高了模型的性能。
其中本文介绍的LSTM-LM方法,其精确率、召回率和F1值分别为88.64%、88.30%和88.46%,其结果都比其他模型的结果都高,说明了该方法可以取得更好的结果。对于BiLSTM模型,它从文本的两个方向获取数据的信息,也因此获得了更多更全面的知识信息,但是其结果与LSTM模型的结果差不多,也取得较好的效果,但是其参数更多,且训练时间较其他方法缓慢的很多。
4 结语
本文主要提出了一种基于神经网络和语言模型的文本情感分析方法,及LSTM-LM模型,首先对文本进行分词处理,利用词向量对分词后的中文文本进行向量化表示,并且采用了LSTM模型网络获得文本的每个时刻的语义表达,LSTM相比CNN,能够获取更长更多的上下文信息。再对每个时刻通过池化操作,获取文本的向量化表示。将文本向量通过Softmax分类器判别文本的情感。同时,我们还引入了神经网络语言模型,在训练的过程中对每个时刻要求网络预测下一个词的概率,使得模型能搞掌握特定语料中的语言特征,有效的提高了模型的泛化能力和收敛速度。通过实验表明了,本方法的可行性和有效性,能很好的挖掘文本信息的情感倾向性。由于有的文本存在二义性、前褒后贬或者前贬后褒等特点,对情感分析带来了一定的难度,下一步的工作重点就是找到更合适的深度神经网络方法来更好的解决这些问题,使情感分析能力得到提升,也对各种不同任务有所帮助。
参考文献:
[1]S.Hochreiter,J.Schmidhuber.Long Shortterm Memory.Neural Computation,9(8):1735-1780,1997.
[2]R.Collobert,J.Weston,L.Bottou,etal.Natural Language Processing(Almost)from Scratch.Journal of Machine Learning Research,12(Aug):2493-2537,2011.
[3]D.Bahdanau,K.Cho,Bengio Y.Neural Machine Translation by Jointly Learning to Align and Translate.Computer Science,2014.
[4]Yoon Kim.Convolutional Neural Networks for Sentence Classification.In Proceedings of EMNLP,2014:1746-1751.
[5]A.Graves,N.Jaitly,A.R.Mohamed.Hybrid Speech Recognition with Deep Bidirectional LSTM.Automatic Speech Recognition and Understanding,273-278,2013.
[6]Hochreiter S,Schmidhuber J.Long Short-Term Memory.Neural Computation,1997.9(8):1735-1780.
[7]T.Mikolov,I.Sutskever,K.Chen,etal.Distributed Representations of Words and Phrases and Their Compositionality.Advances in Neural Information Processing Systems,.3111-3119,2013.
