基于Pyspark平台的协同过滤推荐算法应用与实现
2018-04-21许文英
许文英,向 强
(西南民族大学电气信息工程学院,四川 成都 610041)
随着互联网技术的发展,人们的生活越来越丰富.尤其近几年来,电子商务的快速发展,各大网站销售的商品几乎涵盖人们的所有需求.并且伴随着电商平台的物品丰富多样,数量数不胜数,甚至一类相似物品数量达到几十个,使得人们选购商品的时候,信息过载导致选购商品倍感费力.在海量的信息情况下,商家对顾客消费的大量数据的处理技术提出严峻的挑战,消费者对纷繁复杂的商品,很难准确定位自己所需求的物品.因此,推荐系统[1]应运而生.
由最早的亚马逊推荐系统[2],到目前各知名的淘宝网、豆瓣网、京东等电商门户的各自的推荐系统,都得到广泛的应用,并取得显著的成功.传统的推荐系统包括基于协同过滤算法的推荐系统[3]、基于用户相似的矩阵分解模型算法的推荐系统[4]、社会化的推荐系统[5]等.在电商时代,更好的掌握和运用用户与物品的数据,才能为电商的运营带来更好的指导方向.随着大数据分布式技术的发展,对于推荐系统框架:车晋强等人对分布式Spark的协同过滤推荐算法研究[6],岑凯伦等人基于Spark平台,对电商实时推荐系统的研究[7],刘寿强等人对Hadoop平台推荐算法的研究[8],彭建喜对MapReduce平台推荐系统的研究[9];近年来,对推荐算法的有很大的改进,随着大数据环境的发展,大数据运用推荐系统也随着变化[10],大数据推荐算法有:关联规则算法[10],社交网络算法[11],组合推荐算法[12].本文针对传统的协同过滤算法,在大量数据运算的情况下,存在单节点计算难度大以及特征矩阵稀疏等问题,适应大数据环境的要求、采用大数据分布式框架Pyspark,对并发性很好的ALS协同过滤算法原理进行研究并实践应用.
1 pyspark实现原理与架构
1.1 pyspark原理
根据官方提供,Apache Spark是一个开源的大数据处理框架,它具有高速处理、易用性、构建复杂大数据分析的特点.相比其它大数据处理技术(如Hadoop,Storm)和MapReduce技术,Spark提供了一个全面、统一的大数据处理框架.
Spark技术族包括资源调度、文件存储、编程模型、分析工具,其中资源调度包括YARN、Mesos,文件存储包括HDFS、Tachyon,编程模型包括Hadoop、MapReduce、Spark/Spark Straming,分析工具包括 Hive、Spark SQL、SparkR、Pyspark、GraphX、MLlib.Spark 吸收和借鉴大数据分布式计算模式的优势,它巧妙的融合弹性分布式数据集(Resilient Distributed Datasets,RDD)和算子(Operation),以此减少对内存的访问和消耗,实现简洁高效的分布式计算的运行框架.其中Spark的算子包括创建算子(Creation)、变换算子(Transformation)、缓存算子(Cache)、行动算子(Action),用于对RDD中的数据进行转换和操作.
Spark是用面向函数式变成语言(Scala)编写的,并提供了几个交互式的API.Pyspark即是Spark开发者为python语言开发者提供的pythonAPI,与Spark相似,PySpark的中心数据抽象是一个“弹性分布式数据集”(RDD),它只是一个Python对象的集合,图1给出了Pyspark与Spark的关系示意图.选择Pyspark的原因是对于熟练Python的程序员,Python自身的轻量级、简单的优势,结合Spark的特点,得到很多程序员的青睐.
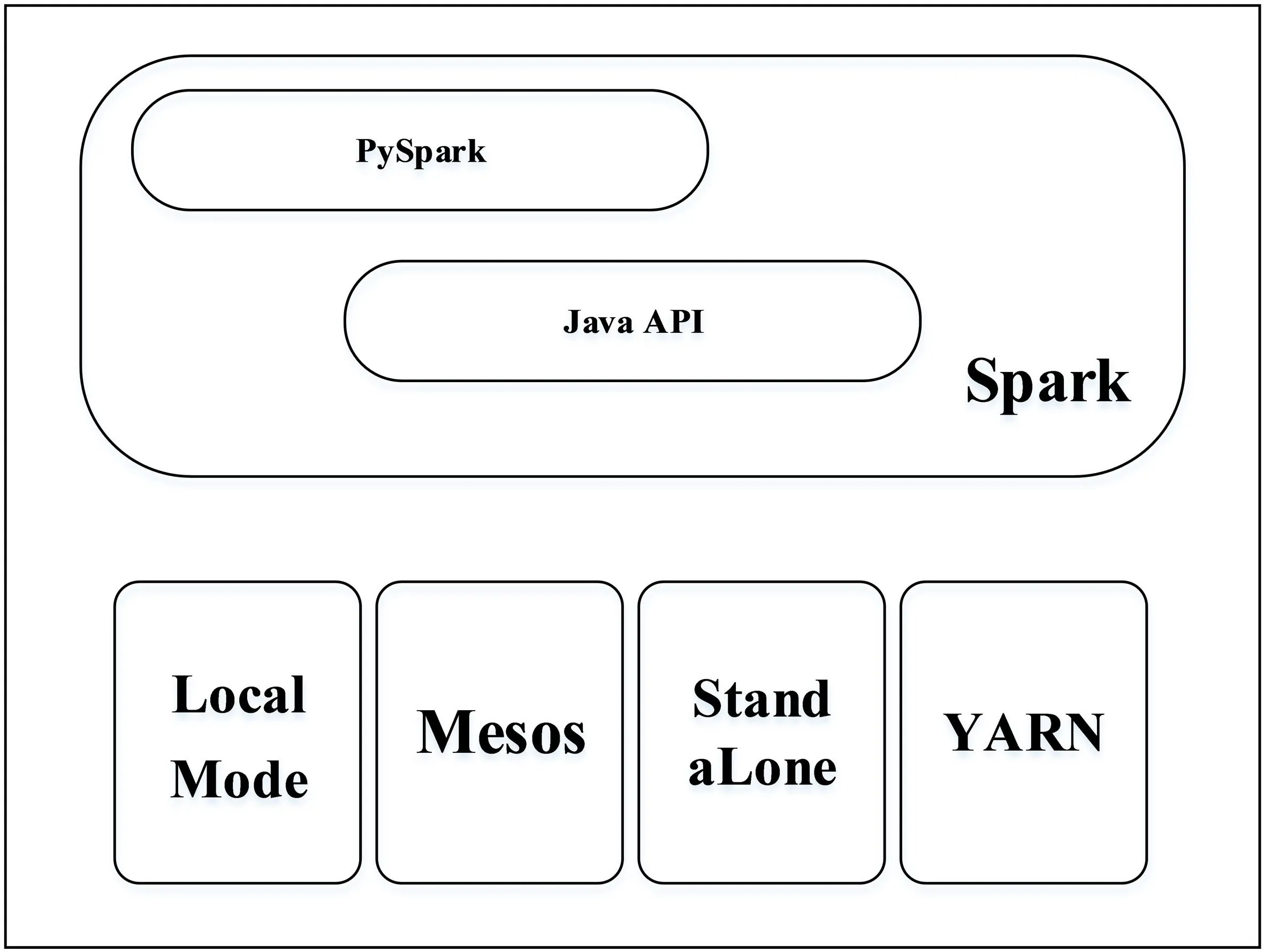
图1 Pyspark与Spark的关系示意图Fig.1 diagram of the relationship between Pyspark and Spark
1.2 pyspark基本架构
Pyspark相对于Spark是在外围包装一层Python API,通过集成的Py4J对Python和Java进行交互,进而实现Python编写Spark应用程序,其运行基本架构如图2所示:
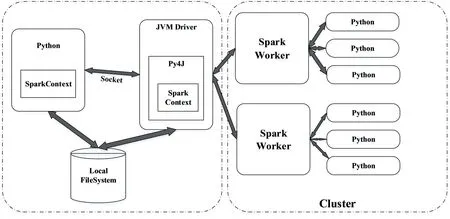
图2 pyspark架构Fig.2 pyspark architecture
a)在Python引擎中,SparkContext通过Py4J连接Java的解释器JVM,并且创建一个JavaSparkContext.
b)Py4J通过引擎,把本地的Python与JavaSpark-Context的对象进行互相通信.
c)Pyspark的RDD在Python下的转化被映射成Java环境下的PythonRDD.
d)在远程的worker机器上PythonRDD对象启动子进程,并且使用Pipes与启动的这些子进程进行通信,通过这样的关系为用户传递代码和数据.
2 协同过滤推荐算法
协同过滤模算法摸型:假设有一个用户数据集:U = {u1,u2,u3,…,uk} , 收 集 用 户 买 过 商 品:,用评分矩阵Mn×k表示用户对商品的评价[13]、打分、点赞等方式,Mu,i表示第u个用户对第i个商品的综合评分,评分相近的表示用户喜欢的商品相似.

2.1 基于隐含的ALS协同过滤算法

基于改进的协同过滤算法摸型:ALS(alternatingleast-squares)继承协同过滤算法模型的思想,用户与用户对商品的打分构成隐含的评分矩阵,其中隐含因子就是用户对一些物品的偏好.
基于隐含的ALS协同过滤算法原理:由于一个用户不能给所有物品打分,因此决定了评分矩阵高度稀疏,因此假设一定存在两个低秩矩阵U、I尽可能逼近M,即
为了使低秩矩阵乘法最大限度逼近真实值,需要计算平方误差函数,且使得误差达到最小:
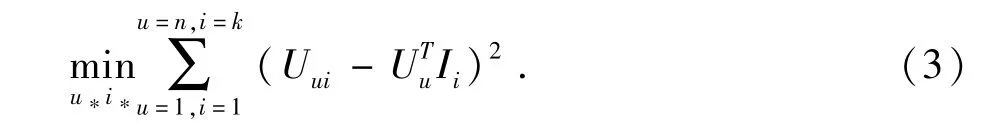
根据洁洪诺夫正则化(Tikhonovregularization)准则[14],则(3)式变为
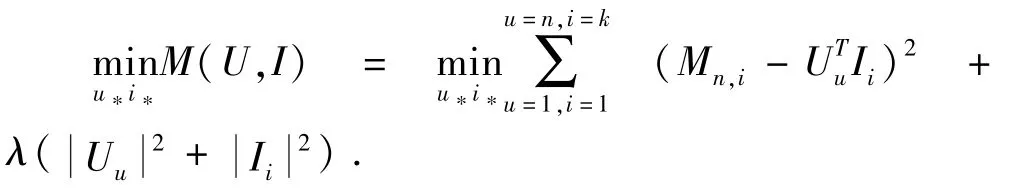
根据偏微分原理,求解U,固定I,对U求偏导:
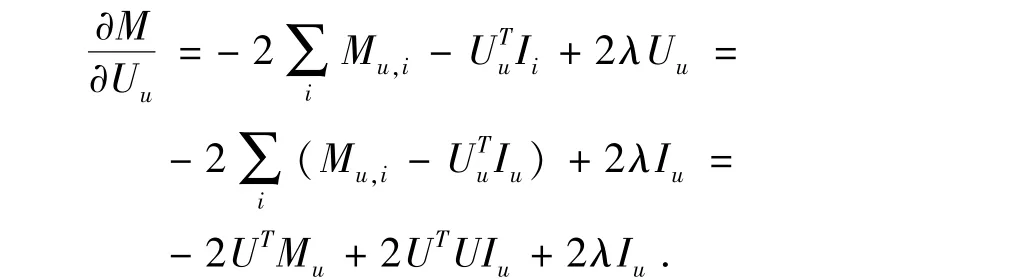
令偏导数为零,得:
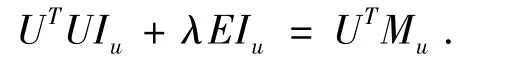
化简得:
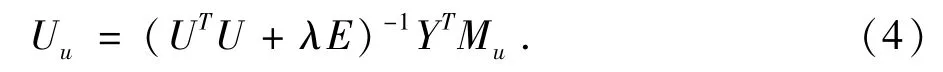
根据偏导数对称原则,同理可得:
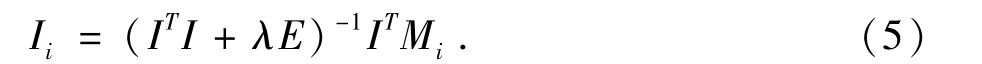
根据(4)、(5)式,随机给定 U,I的初始值,可以迭代求出U,I矩阵,当平方误差(6)的值变化很小时,算法达到收敛,进而求得评分矩阵M.
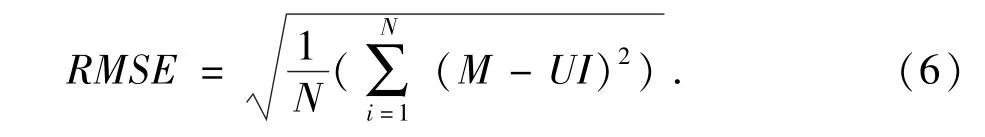
2.2 正则化参数λ
Tikhonovregularization求解的质量依赖于正则化参数λ,为了合理迭代求取(4)、(5)式,根据最小化广义交叉验证算法求取[15]λ:
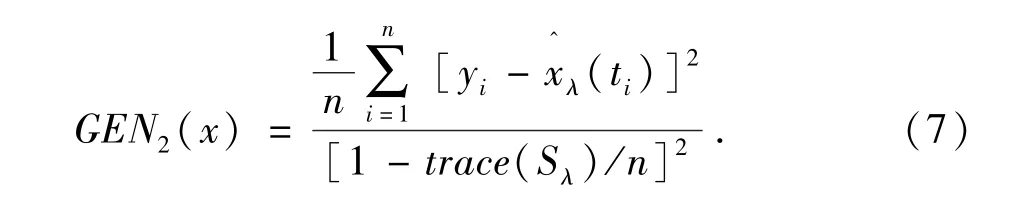
其中 Sλ= Φ(Φ'Φ + λR)-1Φ',Φ表示全体基函数.
3 实验及结果分析
3.1 实验过程
数据准备:选取开源的电影评价数据集(MovieLens);
平台部署:官方网址下载对应操作系统版本的Spark,本次采用 Spark 2.0、JDK 1.8.0、 Python 2.7.13,安装完成并配置环境变量,启动Pyspark,如图3.
图3 Pyspark启动(MovieLens数据集)Fig.3 Pyspark startup(MovieLens data set)
3.2 实验程序流程图
推荐程序流程图如图4:
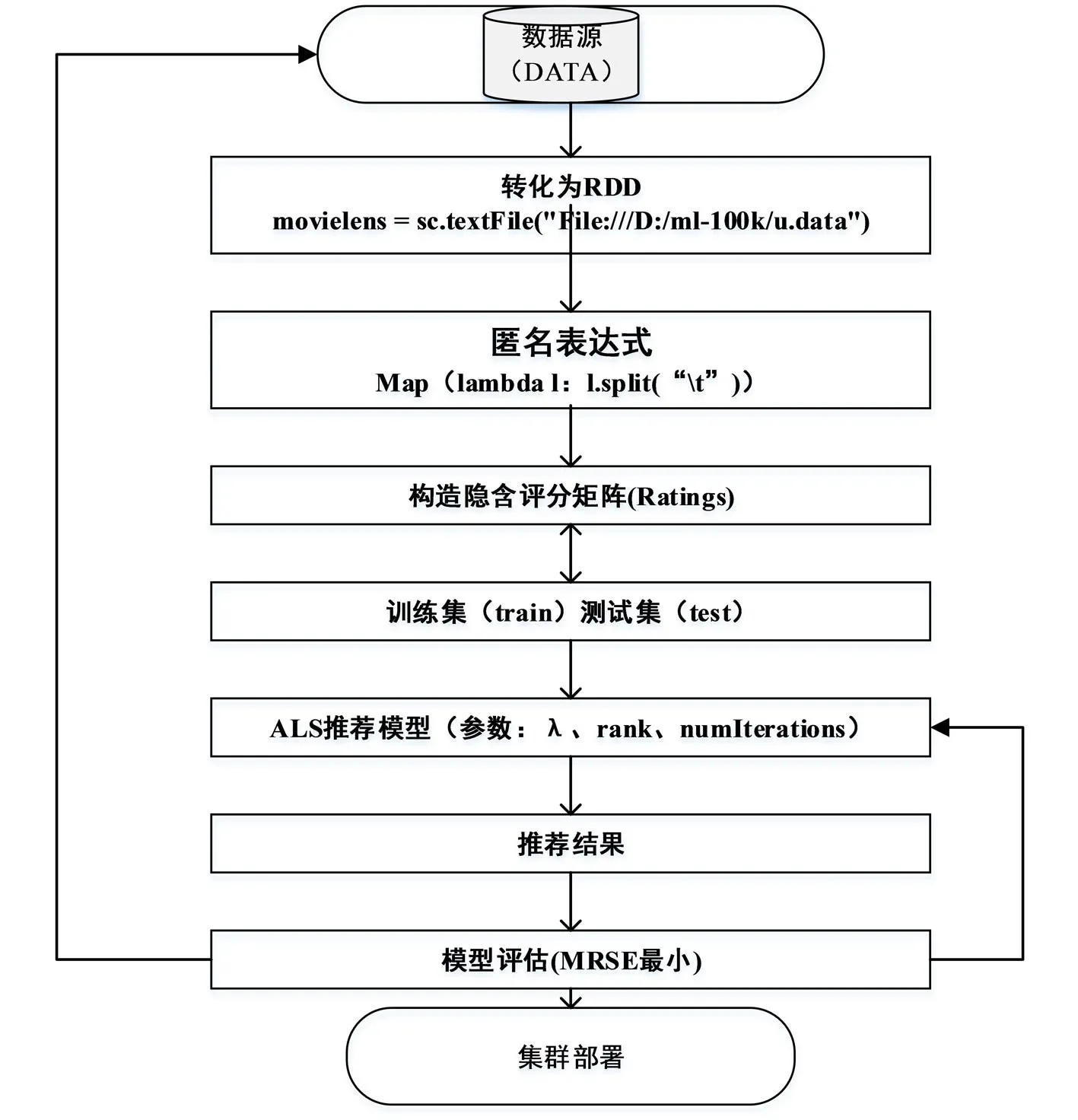
图4 推荐系统流程图Fig.4 recommendation system flow chart
3.3 变换配置参数,RMSE对比图
使用Anaconda仿真,调节程序中三个参数λ,RANK,numIteration.首先取λ =0.01、λ =0.02、λ=0.03,改变隐形因子的数量,画出RMSE变化,如图5所示;其次取 rank=8、rank=10、rank=12,改变参数Lambda,画出RMSE,如图6所示.
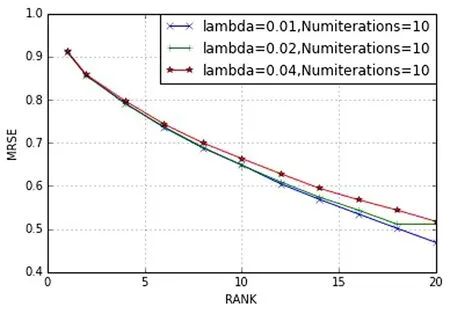
图5 RMSE1Fig.5 RMSE1
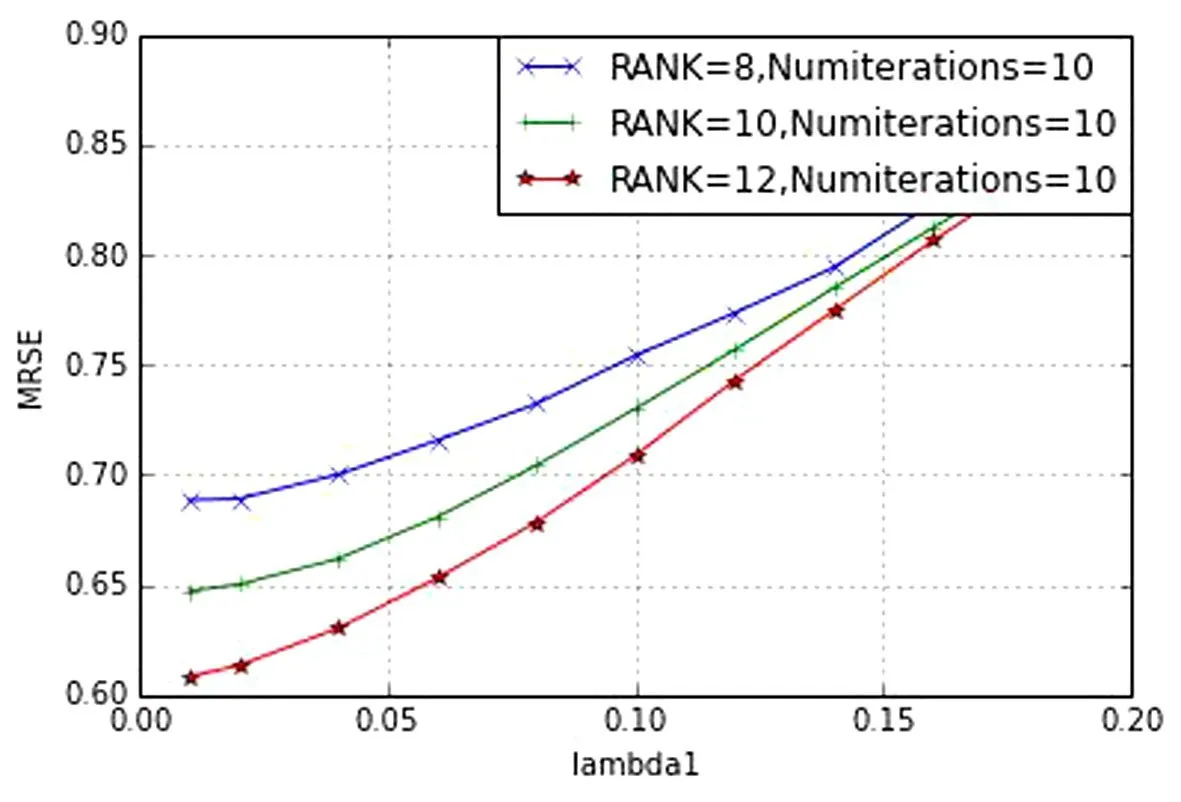
图6 RMSE2Fig.6 RMSE2
通过实验结果,当隐形因子数取10,正则参数为0.01时,RMSE最大,得到本次数据集在本次实验环境下的最佳推荐结果,其中RMSE如图7所示;并且保存模型,根据ALS模型,分别计算出第196个用户对第241,第240,第139部电影的评分,以及第197、第198、第199、第200个用户对第139部电影的评分结果,如图8所示,然后根据模型(ALS)计算结果,将评分最高的推荐给相应用户.

图7 RMSE最佳值Fig.7 RMSE best value
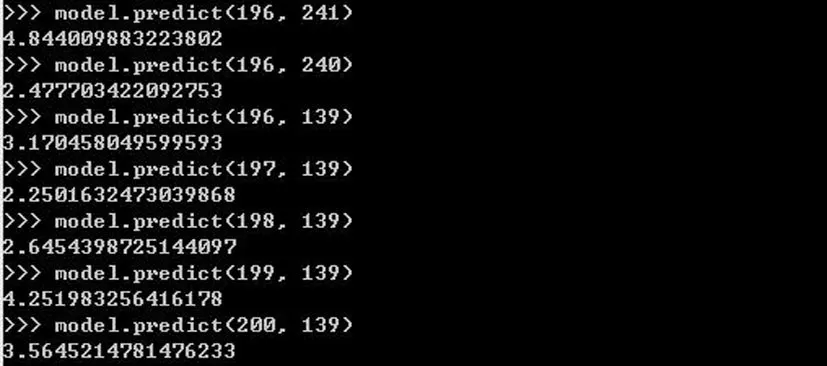
图8 第i用户个对第j个电影的评分Fig.8 Thei-th user scores the j-th movie
4 结论
与传统的协同过滤推荐相比,首先,Pyspark针对大数据环境平台,在计算量很大的情况下,运行速度快,并发性好,稳定,可以用于生产环境.其次,ALS协同过滤算法,并发性好,在Pyspark平台下,随着隐形因子数的增多,平方误差越小;随着正则数的增大,平方误差变大,这个实验结论可用于生产环境中对模型参数调优有决策的方向,能使推荐精度更高.最后,随着物品的日益增多,数据量增大,上网购物体验会有很大变化,推荐系统的性能还有很多改进的地方,比如怎么实现实时推荐有效的问题、算法平台迁移稳定性等,需要进一步的研究.
[1]张素智,赵亚楠,吴健.推荐系统研究[J].湖北民族学院学报(自然科学版),2016,35(2):1-6.
[2]洪亮,任秋圜,梁树贤.国内电子商务网站推荐系统信息服务质量比较研究—以淘宝、京东、亚马逊为例梁树贤[J].2016,60(23):97-110.
[3]余娜娜,王中杰.基于Spark的协同过滤算法的研究[J].系统仿真技术,2016,12(1):41-45.
[4]盛伟,余英,王保云.基于相似用户索引和ALS矩阵分解的推荐算法研究[J].陕西理工学院学报(自然科学版),2016,32(6):47-52.
[5]孟祥武,刘树栋,张玉洁,等.社会化推荐系统的研究[J].软件学报,2015,26(6):1356-1372.
[6]车晋强,谢红薇.基于Spark的分层协同过滤推荐算法[J].电子技术应用,2015,41(9):135-138.
[7]岑凯伦,于红岩,杨腾霄.大数据下基于Spark的电商实时推荐系统的设计与实现[J].现代计算机,2016(11):61-69.
[8]刘寿强,祁明.基于Hadoop云平台的社交大数据协同过滤个性化推荐的研究与实现[J].现代计算机,2016(32):76-79.
[9]彭建喜.基于MapReduce的潜在因素算法在推荐系统中的研究与应用[J].科技通报,2013(29):124-126.
[10]陈平华,陈传瑜,洪英汉.一种结合关联规则的协同过滤推荐算法[J].小型微型计算机系统,2016(2):287-292.
[11]李霞,李守伟.一种基于社交网络舆论影响的推荐算法[J].计算机应用与软件,2017,34(1):276-280.
[12]王子政,姚卫东.一种改进的组合推荐算法研究[J].军民两用技术与产品,2015(1):46-51.
[13]李伟霖,王成良,文俊浩.基于评论与评分的协同过滤算法[J].计算机应用研究,2017(3):362-412.
[14]傅初黎,李洪芳,熊向团.不适定问题的迭代iT k h o n o v正则化方法[J].计算数学,2006,28(3):238-246.
[15]王丽,王文剑,姜高霞.数据拟合中光滑参数的优化[J].计算机科学,2015,42(9):226-234.
