基于静态分析的缺陷模式匹配研究
2018-04-19王建斌胡昌振钟松延
王建斌 刘 臻 胡昌振 单 纯 钟松延
1(中国航天科工集团有限公司网络信息总体部 北京 100048)
2(北京理工大学软件学院软件安全工程技术北京市重点实验室 北京 100081)
(jb.wang2000@163.com)
如何保障软件的可靠性和运行的稳定性,是软件开发一直以来难以避免的问题.影响软件可靠性和稳定性的因素有许多,但主要的影响因素是软件中存在的缺陷数量.通过检测查找并及时修改软件中存在的缺陷,可以在一定程度上对软件的可靠性和稳定性进行控制.
现有的软件缺陷检测工具多采取静态分析技术,并通过软件缺陷模式匹配的方法进行缺陷检测.本文在研究软件缺陷以及软件缺陷静态检测技术的基础上,提出了2种新的缺陷匹配方法;并通过实验验证了这2种方法在实际应用过程中的可行性.
1 相关工作概述
1.1 静态分析技术
现有的主流软件缺陷检测方式一般分为2种:动态检测和静态检测.动态检测方法通常通过软件运行过程中软件功能是否可以正常实现,来判断软件是否存在缺陷或者漏洞.但测试用例往往很难将所有的逻辑流程穷尽,也就极有可能漏掉一些隐藏更深的缺陷.同时,动态检测难以直观地确定缺陷及其定位,这也为检查和修改带来了很大的困难.静态检测是指在不实际执行程序的情况下,通过分析软件源代码或某种形式的目标代码,从而发现可能存在的缺陷以及漏洞的分析方法[1].由于静态检测不需要软件运行,因而静态检测更适合对软件代码中的编写错误或深层逻辑代码进行检测.
静态分析是通过对代码进行自动化扫描来发现可能的漏洞或缺陷.相对于动态分析而言,其优点在于[2-3]:由于有些静态分析是直接对代码进行分析的,因此静态分析工具可以对某一部分模块进行分析,也就无须等到整个项目完成才可以进行检测,因而可以更早更有针对性地进行检测;软件执行路径的组合是非常复杂的,静态检测可以无视这种执行路径的复杂性,对难以执行的路径实施有效的检测;静态分析的自动化程度高,执行速度快,相对效率更高,定位更准确.
1.2 正则表达式及其意义
在计算机科学或形式语言理论中,正则表达式指的是一种用于定义搜索模式的序列.这种序列主要用于针对字符串进行模式匹配或者字符串的匹配[4].在正则表达式中,每一个字符都可以被理解为一个具有特殊含义的“元字符”或者是一个仅仅代表其字面意义的标准字符.通过正则表达式中不同的字符组合,可以确定一种用于处理大量文字材料的模式.使用这种模式序列,可以直接自动化地处理和分析普通文本文件或输入的字符串中的特定文本形式.正则表达式处理器在处理正则表达式中,将正则表达式转换为一个非确定的有限自动机,计算机会将这个有限自动机作为匹配规则,来识别符合该有限自动机表示的正则表达式代表的模式[5].
正则表达式在如今的软件开发中具有极大的意义,它可以为不同标准的系统提供一种特定的正规表达方式.使得不同的系统在文字处理方面可以有相同的标准为依据[6].
1.3 软件缺陷
软件缺陷其实是软件开发过程中导致错误运行结果或性能上不足的问题代码,且在软件开发过程中难以完全避免.通常情况下,软件缺陷表现为人工编写代码的过程中产生的编译错误或者逻辑错误.这些错误通常比较隐蔽,在动态检测过程中并不容易检测出来,甚至可以一直潜伏,在某个特定的逻辑流程产生时才会出现.这就为软件的安全运行留下的隐患,比较严重的缺陷甚至会对用户造成极大的损失,包括经济资产的损失和非经济资产的损失[7-8].
1.4 软件缺陷模式
软件缺陷模式指由具有丰富的领域程序设计经验的程序编码人员、或具有丰富测试及缺陷修复经验的测试人员总结出来的,可能经常出现在程序中的特定规律,这些特定规律的出现往往意味着某种设计与实现错误或是某种缺陷.一般说来,不同的编程语言会对应不同的缺陷模式集.
缺陷模式的确定主要通过3个途径[9]:软件开发和测试过程中积累的缺陷资源;各类文献归纳的项目中实际积累的缺陷数据;各领域内的专家总结的缺陷数据.
2 缺陷模式匹配方法
2.1 软件缺陷检测模型
利用静态分析的方法构建软件缺陷检测模型对软件代码中的缺陷进行检测,一般需要3个步骤:首先获取软件各个文件中的代码文本;其次对代码文本进行语法分析,构建语法树,根据预先规定的语法规则,对每一段有具体意义的代码进行切分;最后将得到的有具体意义的代码片段与缺陷模式库中已有的缺陷模式进行匹配,逐一排查[10-11].
其中软件缺陷检测模型的主要技术点在于语法分析和缺陷模式匹配2个方面.一般而言,构建语法树的规则和方法大同小异,且并非是影响一个软件缺陷检测系统性能的核心.而缺陷模式和缺陷模式的匹配才是决定软件缺陷测试系统性能的关键.
2.2 缺陷模式匹配存在的问题
现有的静态分析工具所使用的缺陷模式以及匹配方法还存在不足.在研究中发现,现有的静态分析工具还不能很好地对自增自减语句可能存在的溢出缺陷作出良好的反应,或者时常会出现将正确的自增自减运算作为溢出缺陷进行报错处理的现象.经过研究发现,造成这一问题的原因是在语法分析过程中,不能对自增自减语句构建有效合理的语法树,因而导致语义理解产生偏差.同时,在C语言语句中,难以对判断语句和输入输出语句中数据类型前后不符的缺陷进行检测.例如scanf(“%d”,&a)语句中,要求a的数据类型与前面的%d(整型数据)一致.如果a的数据类型不是整型,此处应当是一个比较严重的数据类型错误,但传统的检测工具一般不会对这一错误进行检查[12].
因此基于以上2个待解决的问题,本文提出了代码替换方法以及一种新的正则表达式语句来实现对这2种缺陷的有效检测.
2.3 代码替换方法
代码替换方法的核心思想是,将在语法分析阶段难以解读的代码替换成效果相同且可以被解析的代码.
在语法分析阶段,通常会引入抽象语法树对代码进行解析,因而形似i++的自增自减运算,由于仅包含一个实体对象以及2个相邻的运算符,所以很难被构造成1棵符合规则的抽象语法树,也就无法对其进行有效的检测[13].
因此,通过代码替换方法,将形似i++的自增自减运算替换成具有相同效果的运算公式,便可以构造1棵对应具有相同效果的抽象语法树,也就可以相应地对其进行溢出缺陷的检测.
C语言中自增自减运算通常包括:

替换代码为:

2.4 正则表达式匹配语句
该正则表达式匹配语句主要是为了实现对判断语句和输入输出语句中数据类型前后不符的缺陷的检测.这类缺陷在程序编译过程中是不会报错的,但是会对程序的运行造成极大的影响.
增加类似如下缺陷模式正则表达式语句:

其中,“%var%”,“%num%”,“%any%”以及“%str%”都是变量.由于数据类型组合多且复杂,因此这里并没有列举所有的语句.
3 实验结果与分析
3.1 实验描述
该实验以C语言为语言基础,并采用故障注入方法,以开源软件为载体,植入CWE数据库中涉及的,隐含不同类型缺陷的20个代码段,进行对比检测.以Cppcheck为对照比较14],进行对照实验.本实验采用查出缺陷的准确率、误报率以及漏报率作为比较的标准,对于相同的C语言程序源代码,准确率越高检测的误报率和漏报率越低,则认为检查的效果越好.
准确率的计算公式如下:

其中,Ra是准确率,Na是检测出的缺陷数,Nd是程序中的缺陷总数.
漏报率Rm和误报率Rf计算公式如下:


式(2)中的Nm是漏报的缺陷数量,式(4)中的Nf是误报为缺陷的数量.式(3)意为漏报率还可以表示为1减去准确率.
3.2 实验结果
本实验设置了4种类型共20个的缺陷,包括空指针异常、内存泄露、类型溢出和数组越界各5个.先记录Cppcheck对这20个缺陷的检测结果,如表1所示;再在Cppcheck所使用的缺陷库的基础上,加入本文涉及的2种新方法,组成待验证程序,并对其进行检测,结果如表2所示.

表1 Cppcheck运行结果
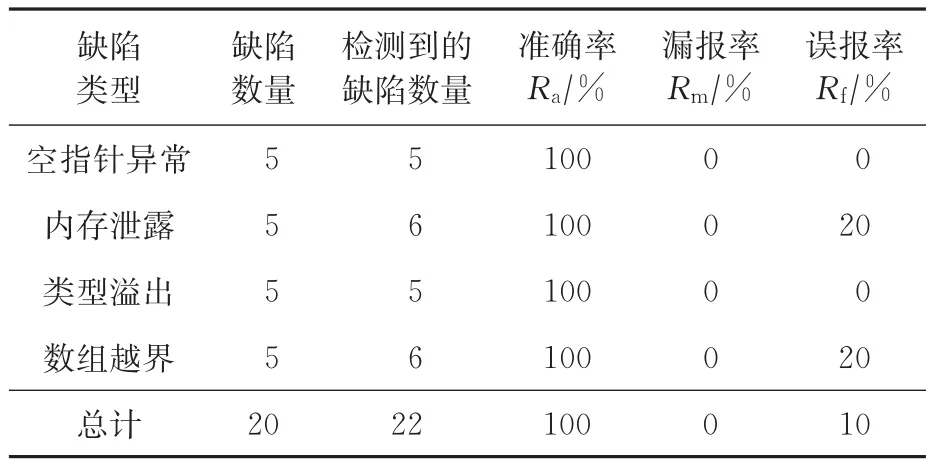
表2 待验证程序运行结果
从对比结果可以看出,加入了本文提出的代码替换以及正则表达式的检测工具,对类型溢出缺陷和数组越界缺陷的检测有更加出色的表现,漏报率降低为0%,准确度得到明显提高.但是仍然存在一定的误报现象,数组越界出现了20%的误报率,在今后工作中仍需要对此进行优化和改进.
4 结 语
本文在现有的静态检测技术的基础上,针对缺陷模式匹配方法和现有静态检测工具使用的缺陷模式库所表现出的不足,提出了2种优化改进的缺陷模式匹配方法.极大地提高了缺陷检测的准确率,降低了漏报率.虽然本文是在C语言的环境基础上进行讨论与实验的,但根据本文谈到的设计思想,可以扩展到其他编程语言的缺陷检测中去.
[1]Wichmann B A,Canning A A,Marsh D W R,et al.Industrial perspective on static analysis[J].Software Engineering Journal,1995,10(2):69-75
[2]Silva V D,Kroening D,Weissenbacher G.A survey of automated techniques for formal software verification[J].IEEE Trans on Computer-Aided Design of Integrated Circuits and Systems,2008,27(7):1165-1178
[3]周丹丹,李先国.基于静态检测工具的软件缺陷检测模型研究[J].计算机与现代化,2012,11:55-58
[4]彭坤杨.基于TCAM的高速可扩展的正则表达式匹配技术[D].合肥:中国科学技术大学,2013
[5]熊忠阳,蔺显强,张玉芳,等.结合网页结构与文本特征的正文提取方法[J].计算机工程,2013,39(12):200-203,210
[6]杨朝红,宫云战,肖庆,等.基于软件缺陷模型的测试系统[J].北京邮电大学学报,2008,31(5):1-4
[7]王斌,吴太文,胡培培.软件缺陷分类与分析研究[J].计算机科学,2013,40(9):16-24
[8]尹相乐,马力,关听.软件缺陷分类的研究[J].计算机工程与设计,2008,19(29):4910-4913
[9]曾福萍,靳慧亮,陆民燕.软件缺陷模式的研究[J].计算机科学,2011,38(2):127-130
[10]叶亮.基于安全规则的源代码分析方法研究[D].武汉:华中科技大学,2013
[11]王雅文.基于缺陷模式的软件测试技术研究[D].北京:北京邮电大学,2009
[12]侯苏宁.基于抽象解释的数值程序分析技术研究[D].长沙:国防科技大学,2009
[13]崔舒宁,吴宁,叶丹.建立抽象语法树模型评测C++代码[J].计算机应用,2015,35(S1):183-185
[14]张仕金,尚赵伟.基于区间集的Cppcheck数组边界缺陷检测[J].计算机应用,2013,33(11):3257-3261
