使用深度长短时记忆模型对于评价词和评价对象的联合抽取
2018-04-16沈亚田黄萱菁曹均阔
沈亚田,黄萱菁,曹均阔
(1.复旦大学 计算机科学技术学院,上海 201203; 2.海南师范大学 信息科学技术学院,海南 海口 570100)
0 引言
细粒度的意见分析目标是发现句子中的主观表达(例如“可爱”)、主观的强度(例如“十分的”)、包含的情感(例如“正的”)以及识别意见的目标对象(也就是关于什么的意见)[1]。例如,“The phone has a colorful and even amazing screen”的句子中,“screen”是评价对象,“colorful” 和 “amazing”是评价词。在这个工作中,我们重点关注了评价词和评价对象的联合抽取。这里的联合抽取是相对于过去传统的串行化抽取方式而言,串行化方式先识别评论词,然后再根据评价词与评价对象的关系线索识别评价对象。
细粒度的评论分析对于许多自然语言处理任务是很重要的,包括面向意见的问答系统、意见总结和信息检索。因此,这个任务已经被自然语言处理社区研究了多年。
为了抽取评论对象,许多研究者把评价词作为强烈的暗示[2-3],以上工作基于这样的观察:评价词一般在评价对象的的周围,它们之间有很强的相关性。因此,大多数以前的方法迭代地抽取评价对象,其主要依赖评价词和评价对象的关联性,评价词和评价对象抽取是个相互增强的过程[3-4]。然而,评价词和评论对象之间的关联性并不能准确有效地获得,尤其是长距离的语义关联关系的情况。因此,如何发现评价词和评论对象之间的关联是解决这个问题的关键。
在解决评价词和评价对象之间关联的问题上,许多研究者研究了句法信息,例如凭借依存句法树[3]。这种方法的效果严重依赖句法分析的结果,而各种评论数据经常都是不规范的文本(包括一些文法错误、不合适的标点等),句法分析过程中会产生许多错误,这将导致后续的抽取任务发生连带错误。为了克服以上方法的缺点,评价词和评价对象抽取已经被作为序列标注的问题[5],把评价词和评价对象的抽取过程看成是普通的自然语言处理的序列标注问题,从而实现联合抽取。该工作把句子作为被标注序列,通过使用传统的BIO标注模式:B-OP 表示意见表达的开始,B-TA 表示意见目标的开始,I-OP 和 I-TA 表示意见和意见对象的内部,O 表示和意见相关的外部词。表1中的句子实例显示了用BIO方法的标注结果,例如
B-OP是 “beautiful” ,B-TA是 “quality”。

表1 一个标注的例子
条件随机场的许多变种已经被成功地应用到评价词和评价对象的联合抽取任务中[5]。然而,条件随机场和半条件随机场的方法需要人为手动设计大量的特征,通常需要句法成分树和依存树,手动建立的意见词表,命名实体的标注和其他的一些预处理的成分。同时,抽取特征的过程非常耗时,而且,手动设计特征严重依赖于大量的人类先验知识以及专家和语言学家的经验等,这是不现实的。
近年来,以特征学习为目标的深度学习已经成为研究的热点[6],该方法被应用到各种自然语言处理的任务中,例如分词等序列任务[7]。把循环神经网络用在细粒度的意见挖掘方面,他们尝试了RNN的Elman-RNN、Jordan-RNN、LSTM三种模型,把意见挖掘作为序列标注的任务[8]。
但是,该模型没有考虑标注之间的依赖关系,标注之间的关系对于序列标注的任务很重要,这在分词[7]、语音识别方面得到了充分的证明。其次,一些方法[8]没有在数据的标签级别上做到联合抽取,仅仅分别抽取评价词和评价对象,没有进行评价词和评价对象的联合抽取,忽略了这样的事实:很多评价词和评价对象有很强的依赖和互增强的关系[3-4]。为了解决以上的问题,我们使用长短时记忆神经网络模型进行评价词和评价对象的联合抽取,我们考虑了几种长短时记忆神经网络模型的变种,把评价词和评价对象的抽取看成是序列标注的任务,同时,长短时记忆神经网络模型避免了梯度消失和爆炸的问题[9]。
本文工作的主要贡献总结如下:
(1) 本文在句子级的评价词和评价对象联合抽取任务上研究了长短时记忆循环神经网络的应用。长短时记忆神经网络模型能够获得文本更多的长距离上下文信息,避免了普通的循环神经网络的梯度消失和梯度爆炸的问题。
(2) 本工作对比了长短时记忆循环神经网络模型的几种变种的性能,实验结果表明LSTM-1模型是更加有效的。
(3) 与传统的方法相比,我们的实验结果显示:长短时记忆循环神经网络优于以前的传统方法,在评价词和评价对象的联合抽取任务上达到了最好的性能。
1 相关工作
早期的评价词和评价对象的联合抽取任务主要关注识别主观的表达短语[1-2]。有些系统解决这个问题的方法为序列标注问题,这种方法在很大程度上超过以前的工作[10]。条件随机场被应用于识别评论者[5],还有些研究者联合识别评论表达的级性和强度[11],重排序的方法也被用来提高序列标注任务的性能[12-13]。
近年来的工作松弛了条件随机场的马尔科夫假设,用来获得短语级的上下文关联,很明显地高于词语级的标注方法[14]。
特别地, 一些研究者提出了联合抽取评论表达式、评论者、评论对象以及它们之间的关系[15]。
还有研究者将深度循环神经网络被应用到评论表达式的抽取任务中,被用于词级的序列标注任务[16]。
在自然语言处理任务中,循环神经网络模型把句子作为词语序列,已经成功地应用到语言模型[17]、分词任务[7]等任务中。传统的循环神经网络仅仅包括一些过去的信息(例如上一个词语),双向的变种循环神经网络已经被提出,结合了过去和未来的两个方向的信息(下一个字符)[18]。
系统[19]抽取过程由两部分构成,首先分类评价对象,然后用条件随机场模型抽取评价对象。
系统[8]与我们的工作很相似,它把循环神经网络用在细粒度的意见挖掘方面,尝试了RNN的Elman-RNN、Jordan-RNN、LSTM三种模型,把意见挖掘做为序列标注的任务。
但是,我们的工作主要在两个方面不同于他们的。首先,考虑了标注之间的关系,标注之间的关系对于序列标注的任务很重要,这在分词[7]、语音识别[20]方面得到了充分的证明。其次,我们的工作是把评价词和评价对象进行联合抽取。事实上,很多评价词和评价对象有很强的依赖和互增强的关系[3-4],利用这种现象采用串行化的方法对评价词和评价对象进行抽取,但是他们没有考虑联合抽取的方式。
在本研究工作中,我们集中在长短时记忆神经网络模型的评价词与评价对象联合抽取任务的应用上。
2 神经网络用于序列标注任务框架
评价词与评价对象联合抽取被看作是序列标注的问题。近年来,神经网络已经被用于传统的自然语言处理中的序列标注任务,其流程框架如图 1 所示。在这个框架中,神经网络模型用三个特殊的层描述:(1)词语嵌入层,也就是词向量层;(2)一系列传统的神经网络层;(3)标注推理层。

h(t)=g(W1x(t)+b1)
(1)
在式(1)中,W1∈RH2×H1,b1∈RH2,h(t)∈RH2,H2是超参数,它表示第二层隐单元数。假定标注集的大小是|T|,相似的线性转换被执行如下:
y(t)=W2h(t)+b2
(2)
在式(2)中,W2∈R|Τ|×H2,b2∈R|Τ|,y(t)∈R|Τ|是每一个可能标注的打分。在评价词与评价对象的联合抽取任务中,如图1中提到那样,使用BIO标注模式的标记集。
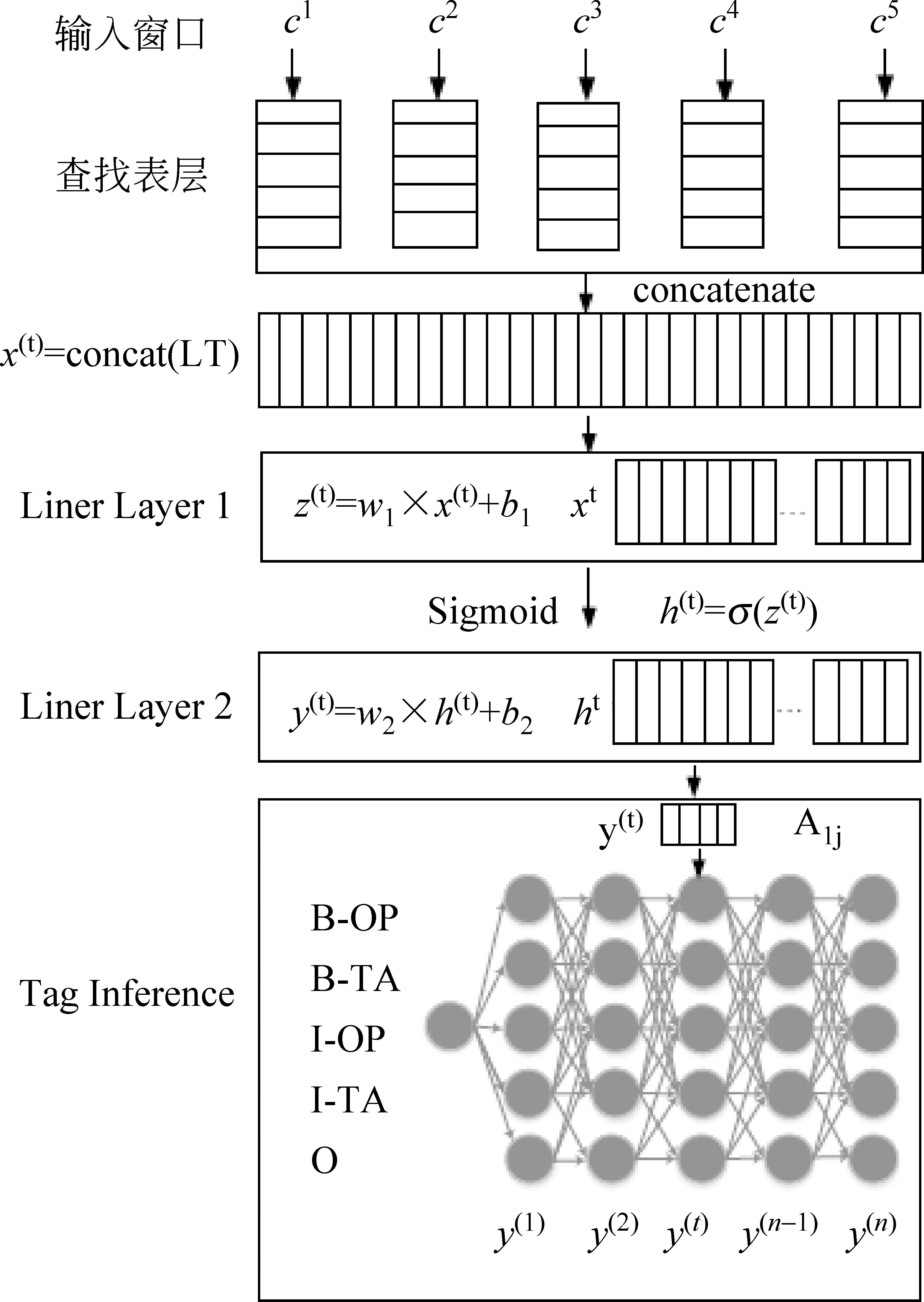
图1 神经网络作为序列标注任务框架
为了建模标注的依赖关系,A(ij)引进了一个转移打分记录,表示从标注i到标注j的跳转概率。尽管这个模型对于序列标注的任务表现很好,但是它仅仅利用了有限的上下文窗口信息,因此,某些长距离信息没有被充分利用。
3 长短时记忆神经网络用于评价词与评价 对象联合抽取
在这一部分,我们将介绍长短时记忆模型的神经网络对于评价词与评价对象的联合抽取任务。
3.1 词向量层
使用神经网络处理符号数据的第一步首先是数据表示成分布式向量,也叫作词语嵌入或者词向量。形式上,在序列标注的任务上,我们有一个大小是|C|的词典C。每一个词c∈C表示成一个实数值向量(c)∈Rd,d是向量维度。然后词向量被堆叠成词向量矩阵M∈Rd×|c|。对于每一个词语c∈C,对应的词向量(c)∈Rd通过查找表层检索,查找表层被作为一个简单的投影层,每一个词语根据其索引得到维度是d的词向量。
3.2 长短时记忆模型(LSTM)
长短时记忆模型(LSTM)是循环神经网络的扩展(RNN),循环神经网络的隐状态在每一个时间步都依赖于以前的时间步,其简单的结构如图2(a)所示。形式上给予一个序列x(1:n)=(x(1),x(2),…,x(t),…x(n)),循环更新其隐状态h(t),按照下面的公式计算:
h(t)=g(Uh(t-1)+Wx(t)+b)
(3)
式(3)中,g是非线性函数。虽然循环神经网络已经取得了很大成功,但是,在训练过程中,获得文本序列上下文背景的长时序依赖却是十分困难的,这在很大程度上是由于普通的循环神经网络所遭遇的梯度消失和梯度爆炸问题[9],因此,文献[18]的模型使用LSTM 单元代替普通的非线性单元解决这种问题。

图2 循环神经网络和长短时记忆单元
LSTM通过使用记忆单元解决上述的问题,LSTM的记忆单元允许网络或者忘记以前的信息,或者当新的信息给予的时候更新记忆单元存储的内容。因此,应用LSTM单元到序列标注的任务中是很自然的选择,因为LSTM神经网络考虑了输入和对应输出之间的时间滞后性,使得网络能够从数据中学习出长距离的时序依赖性。
LSTM模型的核心是记忆单元c,该单元编码了到现在这个时间步为止所有的可观察到的输入信息。记忆单元的行为被三个门,即输入门i,输出门o、忘记门f控制,LSTM 的结构如图2(b)所示。门的操作定义为向量对应乘,当门是非零向量的时候,门能够放大输入值;当门是零值的时候,忽略输入值。相应地门的定义,记忆单元的更新和输出如下:
在式(4)~(9)里,σ是sigmoid 函数、tanh是hyperbolic tangent函数。it、ft、ot、ct分别是时间步t时刻相应的输入门、忘记门、输出门、 记忆单元,所有的这些门向量的尺寸大小等同于隐藏向量h(t)∈RH2,⊗表示向量对应乘,具有不同下标的W都是权方阵。注意,Wi、Wf、Wo、Wg都是对角矩阵。
3.3 长短时记忆的循环神经网络对于评价词与评 价对象的联合抽取
为了完全利用LSTM结构,我们使用了四个不同的神经网络结构来选择有效的特征,其结构被用在分词、词性标注等任务上[7]。图3表示了被提出的四种LSTM结构的变体,它们被用于评价词与评价对象的联合抽取任务。
(1) LSTM-1
LSTM-1简单地使用LSTM单元替换掉式(1)中隐藏神经元,如图3(a)所示。
LSTM单元的输入来自于词语的上下文窗口。对于每一个词语ct(1≤t≤n):
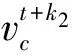
(10)
LSTM单元的输入xt来自于x(t-k1):(t+k2)词向量的拼接,k1、k2分别表示词语ct的左右上下文的词语数量。LSTM单元的输出被线性转换后作为最后的标注推理。
(2) LSTM-2
LSTM-2能够一层一层堆叠LSTM单元,形成多层结构,这里我们仅仅选择两层结构,也即其中一层的输出作为下一层的输入,结构如图3(b)所示。具体来说,上层LSTM层输入来自于h(t)底端LSTM层的没有经过任何变换的输出,第一层的输入等同于LSTM-1,第二层的输出等同于LSTM-1模型输出。
(3) LSTM-3
LSTM-3是LSTM-1的扩展,其采用LSTM的局部上下文作为最后一层的输入,结构如图3(c)所示。
对于每一个时间步,我们拼接LSTM层的窗口,输出成一个向量
⊕…⊕ht+m2
(11)
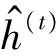
(4) LSTM-4
LSTM-4是LSTM-2和LSTM-3的混合,它有两个LSTM层构成,低端LSTM层的输出形成上端LSTM层的输入,最后层采用上端LSTM层的局部上下文作为输入,如图3(d)所示。
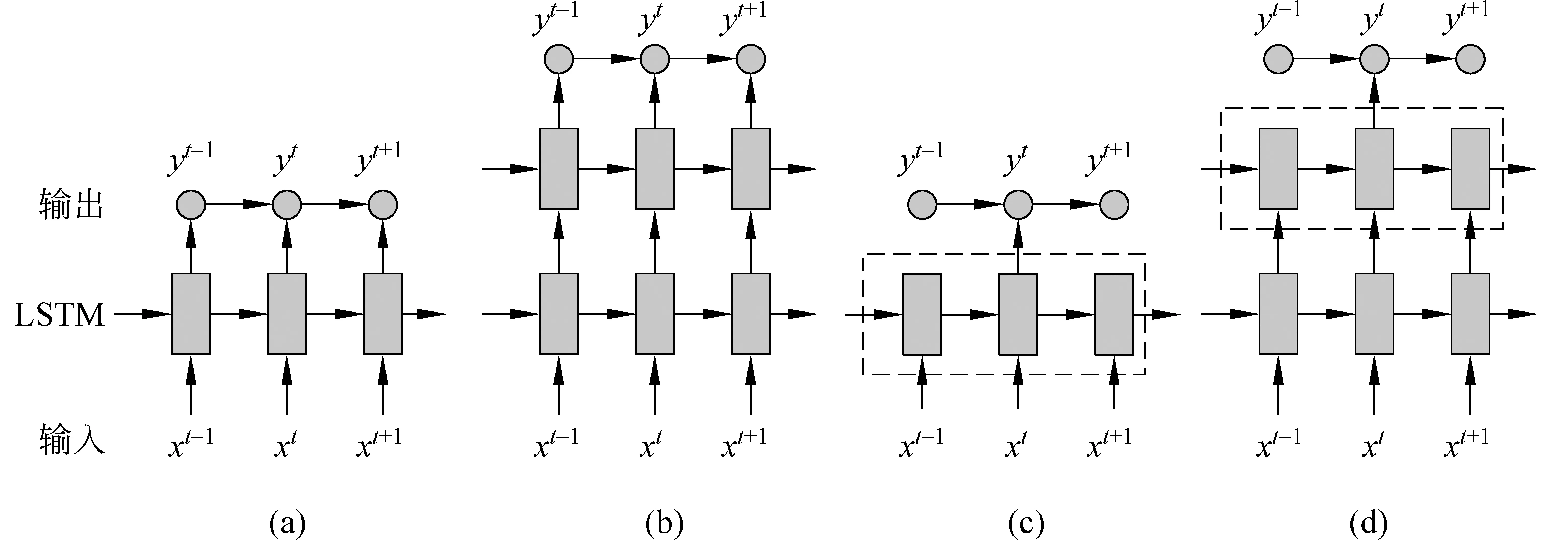
图3 长短时记忆的循环神经网络的变种
3.4 句子级标签推理
给予感兴趣任务的标注集,神经网络模型输出一个|T|大小的向量在每一个词的位置i,向量里面的每一个分量被解释为标注集中每一个标注的打分,ci是句子中的每一个词。
由于在序列标注的任务中词的标注之间有强烈的依赖关系,我们引进一个转移分数A(ij)表示从i∈|T|到j∈|T|的转移分数,初始考虑句子的结构,一个初始的分数A(0i)从第i标注开始,我们的目的是抛弃其他无效路径,寻找一条最优的路径。
假定给予一个句子c[1:n],网络的输出是一个打分矩阵fθ(c[1:n])。fθ(ti|i)表示在网络模型参数θ下,句子c[1:n]中的第i个词获得t标注时所给予的预测打分,这个值是通过神经网络模型由式(2)计算获得。因此,一个具有标注路径t[1:n]的句子c[1:n]获得的标签打分等于标签转移分数和神经网络输出标注分数的和,如式(12)所示。
(12)
为了预测句子c[1:n]的标签,我们通过最大化句子打分发现最好的标注路径,如式(13)所示。
(13)
随着句子的长度的增加,式(12)中的路径数量会指数增加,维特比算法[21]被用来标注推理,能够在线性时间内计算它。
4 训练模型
标注路径的对数条件概率由式(13)得出。
(14)
模型训练在整个数据集M上使用最大似然估计的方法,使用随机梯度下降方法更新参数,如果我们表示θ为所有的训练参数,可得:
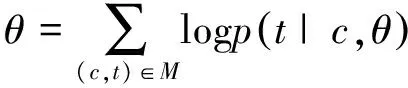
(15)
式中,c是对应的句子,t表示对应的标注,θ是相关的参数,在我们的模型中参数集θ={M,A,Wi,Wf,Wo,Wg,Ui,Uf,Uo,Ug,bi,bf,bo,bg}p(t|c)是神经网络输出标签条件概率。
LSTM网络使用BPTT 的方法[21]进行梯度计算,假定θj是所有的参数集更新了j步后的参数,η0是学习率,N是最小批大小,θ(j)是代价函数的梯度,参数更新如式(16)所示。
(16)
5 实验
5.1 数据集和评估方法
实验中,我们选择COAE2008 dataset2数据集来评估我们的方法,它包括四个不同的产品评论数据,详细的信息可以参见表2。在实验过程中,每一个评论根据标点被分割,由于标注数据中的句子较长,我们仅仅截取含有评价词或者评价对象的句子进行实验,然后用StanfordNLP工具进行分词。系统[23]被用来识别名词短语。我们使用准确率、召回率和 F值进行性能评估。
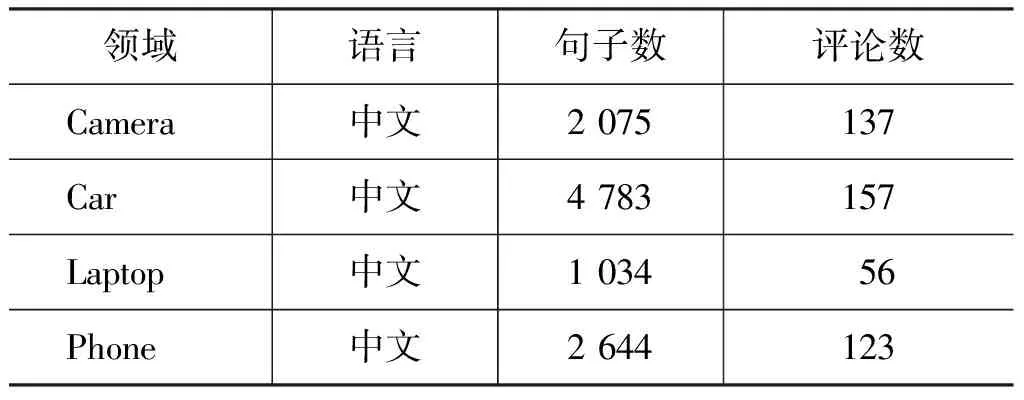
表2 COAE2008 dataset2数据集
5.2 超参数
对于网络的学习,超参数的设置是很重要的,根据实验的结果,我们选择的超参数的情况被列举在表3中。实验中,我们发现隐藏单元数对网络模型性能有一定的影响,为了调和性能和速度之间的矛盾,我们选择200作为一个最好的折衷。LSTM模型中的权矩阵全部被随机初始化在[-0.05,0.05]的范围内。我们使用Google的Word2Vec工具在4GB的Sogou数据集上预训练一个300维词向量,获得的词向量被用来初始化神经网络模型的查找表层,以代替随机初始化出现的误差。整个神经网络模型训练花费了31个小时。LSTM模型变种、学习率及窗口上下文的设置我们将在下节详细讨论。

表3 模型超参数的设置
5.3 超参数的影响
我们也评估了四种LSTM模型的变种,按照表3中超参数的设置,窗口上下文被设置成不同的大小,在数据集COAE2008进行评估,LSTM隐藏层的尺寸被设置成200。在COAE2008的数据集上,39轮的训练周期内,LSTM-1模型收敛是最快的,达到了最好的标注结果。LSTM-2得到较差的结果,这显示了网络模型的深度未必有利于结果的提高。LSTM-3和LSTM-4模型在训练过程中很难收敛,很大部分的原因是由于模型过于复杂,不利于参数的学习。COAE2008数据集的结果被显示在表4中,从中可看出LSTM-1 模型达到了最好的性能。因此,后面的实验分析都基于LSTM-1模型,按照表3中的超参数进行实验设置。
表4表明,LSTM-1模型性能在不同的上下文长度中表现最好。但是,LSTM-1模型用最小的上下文长度节约了计算资源,使得模型更加有效。同时,LSTM-1模型用(0,2)窗口上下文长度比用(1,2)、(2,2)窗口上下文长度能够获得更好的性能。这充分说明了LSTM模型能够更好地建模以前信息,并且对于窗口上下文大小的变化具有很强的鲁棒性。
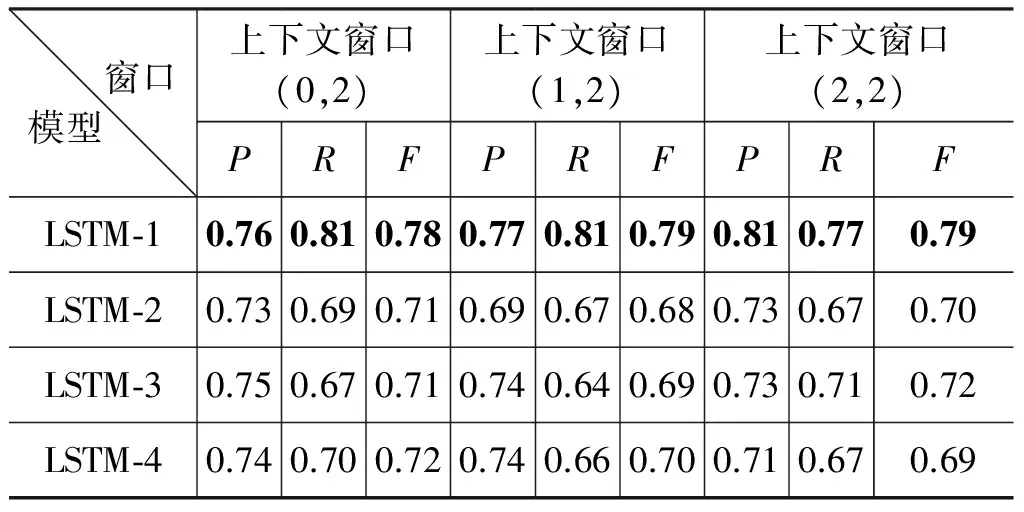
表4 各种模型不同上下文窗口实验结果对比
学习率是一个重要的超参数,为了使网络达到较好的性能,如何正确地设置学习率显得尤为重要。图4显示学习率设置如何影响测试集上的F值性能。
在COAE2008数据集上,当学习率设置成 0.5的时候,学习性能变化非常明显,出现了尖峰,F值达到了80%,因此我们能得出学习率是非常敏感的参数。
图5显示了隐藏层大小对F值的影响。在COAE2008数据集上,LSTM-1取得隐藏层的大小尺寸是200,F值达到了80%,这是我们得到的最好结果。毫无疑问,LSTM-1结构隐藏层尺寸 大 小 是重要的超参数,在很大程度上影响LSTM的网络性能。
如同期望一样,更大的网络表现也更好,随着网络尺寸的增加,需要的训练时间也在增加。但是,当隐藏层尺寸变得更大的时候,性能将逐渐下降,网络趋向过拟合。
5.4 各种方法的对比
我们在COAE2008 dataset2数据集上对比了几种常用的评价词与评价对象的抽取,仅仅使用最简单LSTM-1的模型,按照表3中超参数设置方法与当前的常用方法进行对比,实验结果显示在表5和表6中,通过表中结果的分析,我们能够得到如下的观察和结论。
(1) 对比神经网络方法LSTM-1和传统的方法[3-4,15],实验结果显示:在数据集上,LSTM-1方法取得优于传统方法的实验效果,它有效证明了LSTM-1的方法能捕获文本的语义组合,保存更长的上下文特征信息,并且遭受更少数据稀疏问题的困扰。
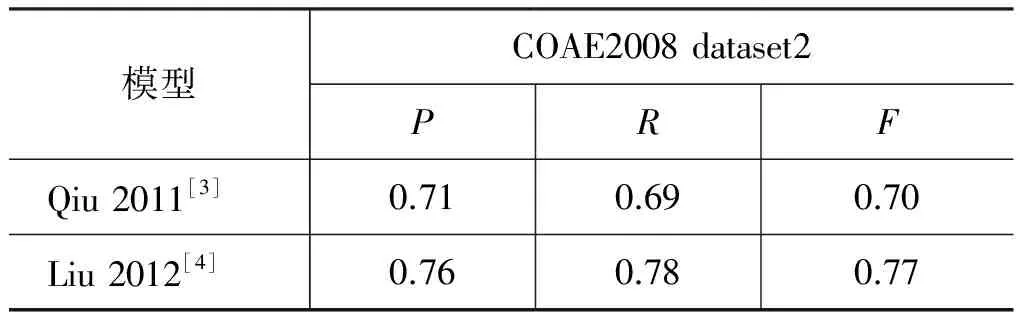
表5 COAE2008 dataset2上方法对比
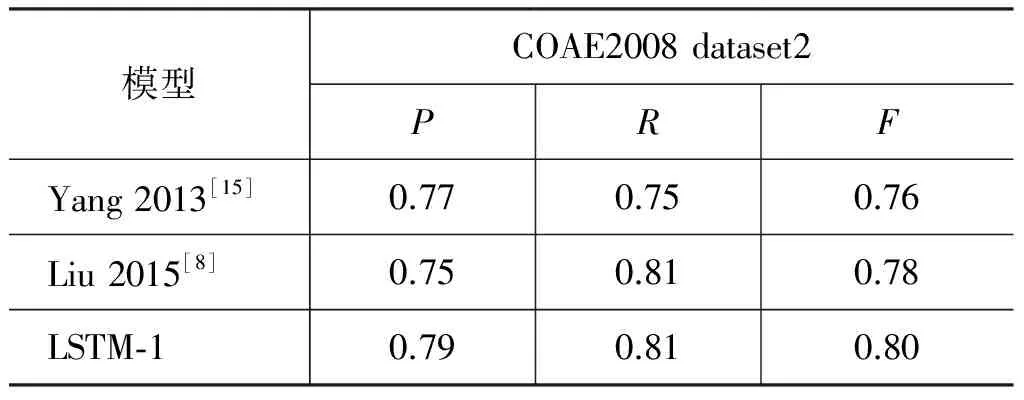
续表
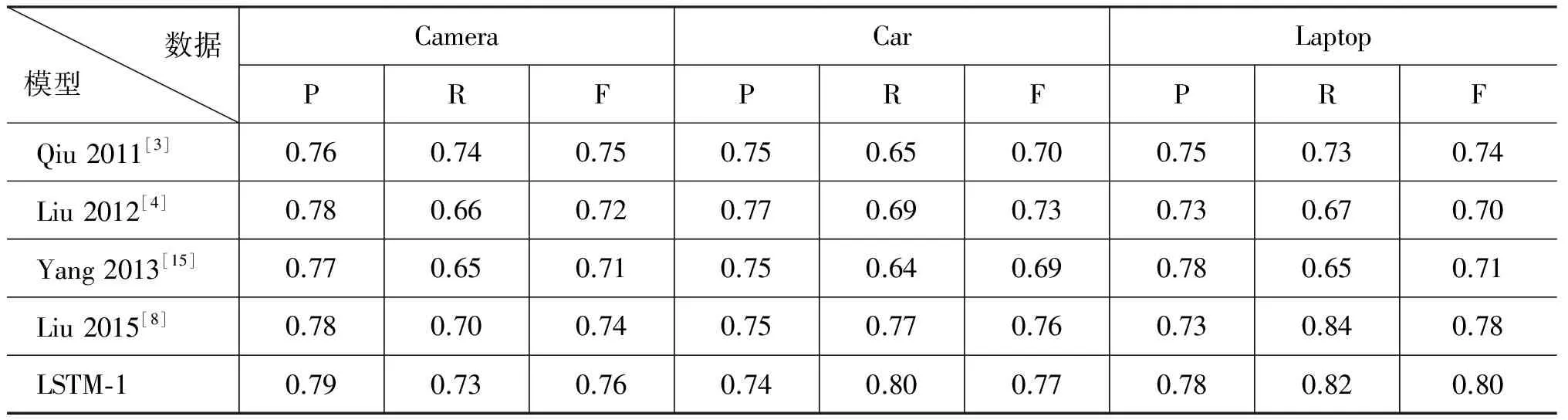
表6 COAE2008 dataset2不同领域数据对比
(2) 在COAE2008 dataset2数据集上,通过与以前传统方法[3-4,15]的对比,我们能看到LSTM-1获得了较好的结果,这也表明LSTM-1更准确地捕获了评价词与评价对象之间的语义关系,也更符合直觉上评价词与评价对象之间的强烈依赖和修辞关系。例如,在汽车数据中,“强劲”的“动力”、“很大”的“机器噪声”等。
我们相信LSTM-1能够通过LSTM单元选择更加具有区分性的特征和捕获长距离的上下文信息。
文献[3]依赖句法树的性能是不现实的,某些评论数据有大量的噪声,句法分析的准确性是很难保证的。
文献[4]使用机器翻译的方法发现评价词和评价对象之间的关联,然后基于图的模型抽取评价词,这样避免了串行方法中错误的有效传播。但是,这种方法很难发现使用复合句方式修辞的评价对象。然而,很多评论数据中含有整个句子修饰评价对象的现象,一些从句中包含大量的评价词,直接或者间接修饰评价对象,例如,“入住的套房相当舒适,很多住过的客人都十分喜欢它的干净,整洁”,在这个句子中,由于“干净,整洁”语义距离“套房”较远,普通的方法很难发现它们之间的修辞关系。
LSTM-1通过LSTM单元能够获得上下文信息,把评价词和评价对象的联合抽取作为序列标注任务。文献[3-4]的工作对待评价词和评价对象关系的抽取使用管道串行的方式,评价对象和评价词抽取任务没有被联合建模,前者的抽取错误会影响后者的抽取,同时错误传播没有被考虑。
文献[15]联合识别和评价词相关的实体,包括评论表达式,评价目标和评价持有人以及它们之间相关的关系,如IS-ABOUT 和 IS-FROM等,然而,模型[15]不能表达评价词和评价对象的长距离依赖关系。
文献[8]使用了Elman-RNN、Jordan-RNN、LSTM三种模型,把意见挖掘作为序列标注的任务。但是,它们忽略了标注之间的关系,并且没有考虑评价词和评价对象之间有很强的依赖的事实,在一定程度上损失了抽取的准确率。
(3) 我们在COAE2008数据集上也对比了被设计较好的特征,实验结果显示我们的方法超过了文献[15]的特征集,获得了一个较好的结果,相信我们的方法能够获得评论句子长距离的依赖模式,并且不需要人工设计特征,这对于低资源的语言是很有利的。
6 结论
在本文工作中,我们在句子级评价词和评价对象联合抽取任务上研究了长短时记忆神经网络模型几种变种的应用。把句子级评价词和评价对象联合抽取看成是一种序列标注任务,而长短时记忆神经网络模型是一种循环神经网络模型,该模型使用长短时记忆模型单元作为循环神经网络的记忆单元,能够获得更多的长距离上下文信息,同时避免了普通的循环神经网络的梯度消失和梯度爆炸问题。我们对比了以前的方法,在现有的COAE2008 dataset2数据集上,我们提出的长短时记忆循环神经网络在评价词和评价对象的联合抽取任务上达到了最好的实验结果。
评价词和评价对象的抽取是自然语言处理中很重要的工作,未来我们将结合评价词和评价对象的抽取任务本身的特点,进一步探索更多的深度学习模型在这方面的应用,例如研究门限循环单元(GRU)代替长短时记忆单元(LSTM)。另外,能否利用深度学习方法有效学习评价词和评价对象之间的关系也是我们未来的研究方向。
[1]Janyce Wiebe,Theresa Wilson,Claire Cardie.Annotating expressions of opinions and emotions in language[J].Language resources and evaluation,2005,[1]39(2-3):165-210.
[2]Minqing Hu,Bing Liu.Mining and summarizing customer reviews[C]//Proceedings of the tenth SIGKDD,ACM,2004:168-177.
[3]Guang Qiu,Bing Liu,Jiajun Bu,et al.Opinion word expansion and target extraction through double propagation[J].Computational Linguistics,2011.37(1):9-27.
[4]Kang Liu,Liheng Xu,and Jun Zhao.Opinion target extraction using word-based translation model[C]//Proceedings of EMNLP.Association for Computational Linguistics.2012:1346-1356.
[5]Yejin Choi,Claire Cardie,Ellen Riloff,et al.Identifying sources of opinions with conditional random fields and extraction patterns[C]//Proceedings of EMNLP,2005:355-362.Association for Computational Linguistics.
[6]Ronan Collobert,Jason Weston.A unified architecture for natural language processing:Deep neural networks with multitask learning[C]//Proceedings of ICML,2008:160-167.ACM.
[7]Xinchi Chen,Xipeng Qiu,Chenxi Zhu,et al.Long short-term memory neural networks for Chinese word segmentation[C]//Proceedings of EMNLP.Association for Computational Linguistics,2015.
[8]Pengfei Liu,Shafiq Joty,Helen Meng.Finegrained opinion mining with recurrent neural networks and word embeddings[C]//Proceedings of EMNLP.Association for Computational Linguistics,2015.
[9]Sepp Hochreiter.The vanishing gradient problem during learning recurrent neural nets and problem solutions[J].International Journal of Uncertainty,Fuzziness and Knowledge-Based Systems,1998.6(02):107-116.
[10]Eric Breck,Yejin Choi,Claire Cardie.Identifying expressions of opinion in context[C]//IJCAI,volum 7,2007:2683-2688.
[11]Yejin Choi,Claire Cardie.Hierarchical sequential learning for extracting opinions and their attributes[C]//Proceedings of the ACL 2010 Conference Short Papers,2010:269-274.Association for Computational Linguistics.
[12]Richard Johansson,Alessandro Moschitti.Syntactic and semantic structure for opinion expression detection[C]//Proceedings of the Fourteenth Conference on Computational Natural Language Learning,2010:67-76.Association for Computational Linguistics.
[13]Richard Johansson,Alessandro Moschitti.Extracting opinion expressions and their polarities:exploration of pipelines and joint models[C]//Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics:Human Language Technologies:short papers-Volume 2,2011:101-106.Association for Computational Linguistics
[14]Bishan Yang,Claire Cardie.Extracting opinion expressions with semi-markov conditional random fields[C]//Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning,2012:1335-1345.Association for Computational Linguistics.
[15]Bishan Yang,Claire Cardie.Joint infence for fine-grained opinion extraction[C]//ACL(1),2013:1640-1649.
[16]Ozan Irsoy,Claire Cardie.Opinion mining with deep recurrent neural networks[C]//Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing(EMNLP),2014:720-728.
[17]Tomas Mikolov,Stefan Kombrink,Lukas Burget,et al.Extensions of recurrent neural network language model[C]//Acoustics,Speech and Signal Processing(ICASSP),2011 IEEE International Conference on,2011:5528-5531.IEEE.
[18]Mike Schuster,Kuldip K Paliwal.Bidirectional recurrent neural networks.Signal Processing,IEEE Transactions on,1997,45(11):2673-2681.
[19]Zhiqiang Toh,Jian Su.Nlangp at semeval-2016 task 5:Improving aspect based sentiment analysis using neural network features[C]//Proceedings of SemEval,2016:282-288.
[20]Grégoire Mesnil,Xiaodong He,Li Deng,et al.Investigation of recurent-neural network architectures and learning methods for spoken language understanding[J].INTERSPEECH,2013:3771-3775.
[21]G David Forney Jr.The viterbi algorithm[C]//Proceedings of the IEEE,1973.61(3):268-278.
[22]Alex Graves,Schmidhuber.Framewise phoneme classification with bidirectional LSTM and other neural network architectures[J].Neural Networks,2005,18(5):602-610.
[23]Jingbo Zhu,Huizhen Wang,Benjamin K Tsou,et al.Multi-aspect opinion polling from textual reviews//Proceedings of the 18th ACM Conference on Information and Knowledge Management,2009:1799-1802.ACM.

沈亚田(1982—),博士,主要研究领域为自然语言处理。E-mail:sy602@126.com

黄萱菁(1972—),博士,教授,主要研究领域为自然语言处理。E-mail:xjhuang@fudan.edu.cn

曹均阔(1975—),通信作者,博士,副教授,主要研究领域为自然语言处理。E-mail:jkcao@qq.com
