基于混合聚类算法的图书馆管理系统研究
2018-04-16周运丽
周运丽
(商丘医学高等专科学校 商丘 476000)
1 引言
图书馆中的文献是人们获得知识的重要途径。但是随着信息技术的兴起和网络的普及推广,使得图书馆不仅拥有传统的纸本书籍,越来越多的电子书籍资源在图书馆中也能够给公众提供信息资源[1~2]。图书馆系统也记录了读者信息资源并且更迭出新的数据为读者提供便利。但是数据随着时间会越来越多,书籍资料会渐渐庞大,读者与书馆的联系变得更加复杂,所以需要更好的系统来处理信息数据为图书馆建设提供数据支持[3]。数据挖掘技术的产生解决了庞大数据的问题,不仅可以快速搜索出读者想要的书籍,甚至可以分析读者的使用习惯来推荐文献,并且通过分析文献来提出合理的采购建议等。所以数据挖掘技术结合图书馆管理系统运用关联技术来搜索文献,了解读者与图书馆的内在联系,提出个性化推荐。
图书的分类是系统的重点,例如传统的PAM算法技术可以有效地解决不同书籍的分类[4],Clarans算法也是数据处理的一种手段[5~6],不过两者都有数据量的局限性。
本文运用混合聚类分析技术来进行文献分类[7],通过文献借还过程中隐藏的数据规律,为图书馆文献收集和建设提供根据。数据挖掘技术可以找出读者的潜在需求[8],提供个性化帮助,也为读者选择购买电子书籍提供帮助,使读者快速,准确地利用图书馆的资源。通过算法实现,搭建读者与图书馆之间的系统服务,并与其他算法进行比较,得出混合聚类算法的优越性,证明该算法的合理性和有效性。
2 系统建模
移动互联网业务优化指的是针对运行的网络进行数据采集、数据分析,进行高效的数据处理,数据分析就是互联网优化的重点,信息化的时代数据量非常巨大,而有效的、有益的数据却被海量的数据所隐藏,我们要解决的就是找到我们所要的数据,并且找出数据之间的关系,为决策者做出决定,从而得到想要的效果。
2.1 借还模型的建立
图书管理系统是根据图书馆的具体业务的需要从而搭建的计算机系统,该系统主要提供了两个方面的模型为图书馆的实际业务提供服务,一个是图书借还管理模型,另一个是读者库管理模型[9]“图书借还管理”主要负责的是书馆的一般业务,一般业务主要包括查询书籍、书籍的借出、返还、预定书籍等。模型如图1所示,每个读者用户我们令为xi,书籍设为cj,模型建立xi,cj之间的关系。
2.2 读者库模型的建立
读者库管理模型主要负责读者对信息进行保护、修改以及挂失等等,另外还包含读者在书馆进行办证、补办证件等[10]。模型如图2所示,读者可以通过两种方式,一个是向管理人员进行及时的证件处理,书证的办理,书证的挂失,另一个是读者可以通过图书馆在线主页面进行业务处理,省去时间,最后的补卡要管理人员进行处理。
3 混合聚类算法设计
图书馆管理系统包括为2个模块[11],包括为读者用户、管理人员的后台系统都采用混合聚类算法分析,2个模块又划分成几个子块来实现其各自的功能,算法实现的功能设计如下。
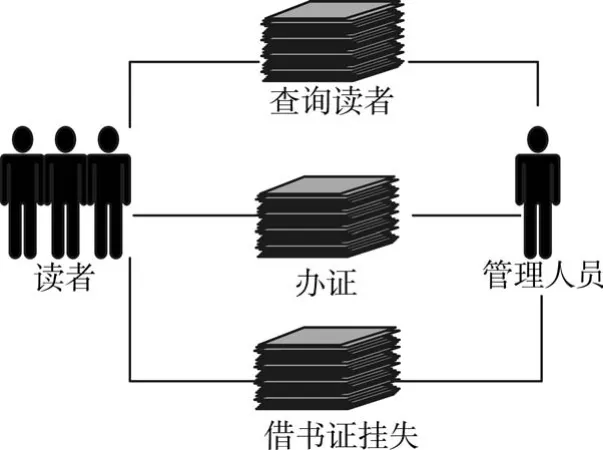
图2 读者库管理
读者管理分为用户信息注册、用户登录以及用户个人信息的浏览与修改。用户在系统主页面注册流程包括填写姓名、身份证号、工作单位以及绑定金额等有用信息来实现注册。当读者登录系统之后,可以进行个人信息的完善、查看和修改等;管理人员的后台管理图书馆书籍的海量信息,实现书籍信息的添加、删除、编辑和显示等功能,另外管理技术人员必须定期地进行系统修复、及时地安装补丁进行系统升级。
采用的混合聚类的算法对图书馆书籍进行分析[12],首先要确定混合聚类的目标:给定一个包含n个 a维书籍或对应用户数据集 X={x1,x2,…,xi,…,xn},其中 xi∈Ra,确定要生成的书籍数据子集的数目m,混合聚类算法将各读者书籍和未借出书籍进行分类,进行m个划分C={cm,i=1,2,…,m}),信息的种类都表示一个书籍与用户类cm,对于各类cm都有一个类别中心值ui,ui是这个类最具代表的数值信息,也就是中心值成绩。采用欧式距离作为依据来判断相似度的原则,计算各书籍类中各点到ui的距离平方之和,作为该点与中心数值的相似度,则欧式距离平方之和是

混合聚类的目标函数就是各类的距离平方和。若J(c)最小时,那么
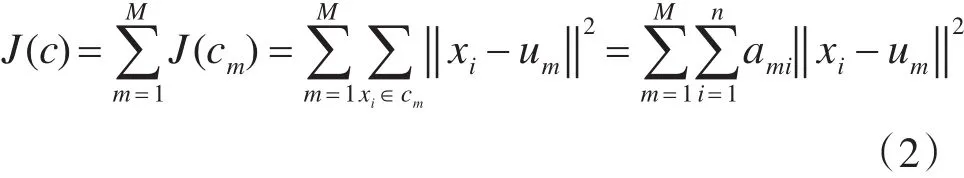
其中ami=1(xi∈ci)或ami=0(xi∉ci)。可以看出,混合聚类的中心ui应取为各类别cm类各书籍类数据点的平均值。
混合聚类算法是从初始的M类别开始进行划分。聚类过程如图3所示,混合聚类算法中总的距离平方和是根据个数M的类别增长而距离和却趋于减小。特殊情况,当M=0时,J(c)=0。所以,可以得出只有当总的距离平方和在确定的类别个数M下J(c)才能取得最小值。

图3 混合聚类树状过程图
混合聚类算法将书籍数据集划分成M个分类,算法的流程如下:
第1步:从书籍数据集中任意选择M个初始聚类中心;
第2步:对书籍数据集中的每个数据对象,算出对象与其他所有聚类中心的距离,并依据最近邻准则将其划分给距离最近的类别中;
第3步:上一步计算之后,依据计算结果重新计算各个新聚类的聚类中心,计算全部书籍数据的距离平方之和;
第4步:再判断所得的聚类中心J(c)值是否有变,若发生改变,重复第2、3两步操作若聚类中心不再变化那么算法结束;若没有变化,算法直接结束。
令 Ai,j为书籍信息Mi与Mj之间的相似度,则有

4 算法实现
算法实验对象是商丘某学校的校图书馆,测试环境包括服务器端与客户端。测试用服务器端部位是系统为Windows Server 2003联想。所使用的台式机是Intel Core i7的CPU频率为3.2 Hz,内存是132GB DDR3a。通过运行仿真脚本,最后分析实验结果。
4.1 实例显示
混合聚类算法得出的系统如图4所示,图书登记表单、图书登记、库存图书、注册表单等四个模块是算法实现的结果类别,图书登记是面向混合聚类算法方法的核心技术,通过算法实现具体到每个类中,因此可以完成设计走向细化的过程。该系统可以有效地完成图书馆庞大数据的实现和管理,有利于用户与图书馆进行有效的联系。

图4 图书库管理
采用聚类分析方法去挖掘、评价书籍的内容,为书籍评分,这样好的数据就可以呈现在系统界面,提供读者建议,每一个好书都成为一个集合群,处于该集合中心的值、具有代表的书籍就是中心值,那么中心值成绩就是此类书籍的评分指标。图5所示就是该算法通过Java实现的系统界面。

图5 系统界面实现
4.2 算法比较
系统中有对书籍的评价功能,如表1所示,包括封面设计,书籍材料,内容价值以及购买意向,最后得出的总评分能够为其他读者用户提供阅读和购买的依据,也为图书馆的建设提供帮助,是个性化服务的体现。

表1 系统中对书籍的评价功能
除了本文的混合聚类算法,还有很多传统的算法进行图书馆的信息数据处理,可以有效地进行系统管理,混合聚类算法的优势在于处理速度快,处理的数据量更大,在系统维护和升级上更有优势。图6表示该算法与其他算法的处理速度比较。
5 结语
本文研究的是构建图书馆中积累的大量书籍数据和用户信息之间建立联系,用来帮助图书馆进行系统管理,图书馆作为一个庞大的数据库,数据挖掘的技术的引入为图书馆的管理增加便利,在数据挖掘后,基于混合聚类算法可以对书籍信息进行合理安排,提升系统的便利性,通过算法实现和算法比较可以看出本文系统结合算法可以形成良好的系统管理秩序,实现功能可视化,为图书案的用户以及管理技术人员提供服务,所以该算法具有合理性。

图6 不同算法比较
[1]江丽,伍萍,JIANGLi,等.在ILASⅡ2.0图书馆管理系统下构建RFID系统——以武汉图书馆为例[J].图书馆界,2008(4):39-42.JIANG Li,Constructing RFID System Based on ILAS Ⅱ2.0 Library Management System-Taking Wuhan Library asan Example[J].Library Circles,2008(4):39-42.
[2]李仁玲.C/S与B/S结合的图书馆管理系统设计[J].情报杂志,2006,25(1):102-104.LIRenling.Design of Library Management System Combining C/Sand B/S[J].Journalof Information,2006,25(1):102-104.
[3]曾频,高飞,宁璐.基于RFID技术的图书馆管理系统的分析与评价[J].图书情报工作,2013,57(9):75-79.ZENG Ping,GAO Fei,NING Lu.Analysis and Evaluation of Library Management System Based on[J].Library and InformationWork,2013,57(9):75-79.
[4]李秀霞.VTLSRFID图书馆管理系统的结构与实现[J].图书馆学研究,2009(3):27-29.LI Xiuxia.Structure and Realization of VTLS RFID Library Management System[J].Journal of Library Science,2009(3):27-29.
[5]朱福珍,薛景.蚁群聚类算法在高职院校教学评价系统中的应用研究[J].江苏第二师范学院学报(自然科学),2014,30(3):93-96.ZHU Fuzhen,XUE Jing.Application of Ant Colony Clustering Algorithm in Teaching Evaluation System of Higher Vocational Colleges[J].Journal of Jiangsu No.2 Normal University(Social Science),2014,30(3):93-96.
[6]刘建伟,李卫民.基于摘要技术的混合模型流数据聚类算法[J].计算机科学,2009,36(11):148-151.LIU Jianwei,LIWeiming.Synopsis Data Structure Based Mixture Probabilistic Density Data Stream Clustering Approach[J].Computer science,2009,36(11):148-151.
[7]邵磊,陈志德.基于聚类算法的数据库访问日记入侵检测[J].电脑与电信,2013(4):48-50.SHAO Lei,CHEN Zhide.Database Access Diary Intrusion Detection Based on Clustering Algorithm[J].Computer and Telecommunications,2013(4):48-50.
[8]马铁军.基于先进聚类分析算法的管理系统研究与实现[J].河北省科学院学报,2015(1):5-8.MA Tiejun.Research and Implementation of Management System Based on Advanced Clustering Algorithm[J].JournalofHebeiAcademy of Sciences,2015(1):5-8.
[9]夏宇,刘天华.基于聚类分析的教职工档案管理[J].沈阳师范大学学报(自然科学版),2016,34(2):196-200.XIA Yu,LIU Tianhua.File Management of Teaching Staff Based on Cluster Analysis[J].Journal of Shenyang Normal University(Natural Science Edition),2016,34(2):196-200.
[10]王少鹏,彭岩,王洁.基于LDA的文本聚类在网络舆情分析中的应用研究[J].山东大学学报(理学版),2014,49(9):129-134.WANG Shaopeng,PENG Yan,WANG Jie.Application of Text Clustering Based on LDA in Network Public Opinion Analysis[J].Journal of Shandong University(NaturalScience),2014,49(9):129-134.
[11]潘伟.基于UML实现图书管理系统的建模设计[J].图书情报知识,2005(1):51-52.PANWei.Modeling and Design of Library Management System Based on UML[J].Journal of Library and Information Science,2005(1):51-52.
[12]周莹,张宇华.UML及其在图书管理系统中的应用[J].电脑与信息技术,2004,25(4):52-54.ZHOU Ying,ZHANG Yuhua.Application of UML and Its Application in Library Management System[J].Computer&Information Technology,2004,25(4):52-54.
