基于数据挖掘的质量监控和评价软件系统研究
2018-04-16曹文梁王超英
曹文梁 王超英 钟 辉
(1.东莞职业技术学院计算机工程系 东莞 523808)(2.广东汇兴精工智造股份有限公司 东莞 523000)
1 引言
传统质量控制的方法是当出现质量问题以后,通过科学合理的方式进行充分解决,但是在信息化的背景下,此种被动式的处理方式,难以满足企业的产品生产需求。数据挖掘是一种数据分析方法,其主要目的寻找大量数据之间的联系和规律,在信息化的背景下,企业产品生产制造过程中产生的数据量呈指数增加,需要通过数据挖掘方法才能在海量数据中找到有效的信息。目前,我国对基于数据挖掘的质量监控和评价软件系统的研究文献较少。因此,本文结合生产实践,通过C4.5决策树算法构建了质量监控和评价软件系统模型,从而提高产品质量检验的效率和准确性。
2 质量监控和评价软件系统现状
我国质量监控和评价软件系统的起步比较晚,和很多发达国家相比仍然存在较大差距,目前仍然采用传统的质量检验评价体系,不但工作效率比较低,而且误差也比较大。如果按照传统质量评价体系,当发现不合格产品后,就可以判定该产品质量不合格,需要检测完全部产品以后,才能进行最后的判定,大大增加了产品质量检验工作量。在检验过程容易受到个体差异等因素的影响,而且检验效果也不够稳定,通过不完全统计,传统质量判定的准确率为85%~90%,而在合格产品中出现不合格率为2%~5%,生产制造业产品基数比较大,所以每天误判定的产品数量非常惊人,在一定程度上限制了企业的发展和质量评定体系的完善[1~4]。
3 质量监控和评价软件系统模型构建
3.1 产品质量细分的意义
产品细分是生产制造企业提供差异化产品和服务的基础,也是现代营销模式发展的必然趋势,大量相关实例表明,通过质量细分经营模式,可以促使企业产品和服务更好地满足消费者的具体需求,进而实现企业资源的最大化利用。在全球经济一体化进程的影响下,各行各业面临的市场竞争越来越激烈,生产制造企业要想在激烈的市场环境中占得一席之地,就必须对客户群进行精细化的分类和管理。
3.2 产品质量细分模型
就流水线产品生产企业而言,产品的质量直接关系到企业经济利益和形象声誉,所以必须建立科学合理的质量评价标准体系,根据产品的具体需求,在性能、强度、耐久性等方面制定标准体系,先把产品分为合格和不合格两大类,然后根据不同的营销方式和产品定价,分为优等产品和合格产品两大类。
3.3 C4.5决策树算法
1)C4.5决策树算法概念
决策树算法[5~9]是目前应用最广泛的推理归纳算法之一,对处理连续型和类别变量型问题有非常独特的优势,可以有效地利用if-then规则和相应的图形来具体表示模型,具有很高的可读性,同时通过决策树算法还能不断地划分信息,最终实现把信息分类到不同分枝和不同组织平台上。其主要目标是针对类别的应变量对质量评价的结果进行解释和预测。决策树算法在数据挖掘中的应用也非常广泛,具有以下优势:第一,图形化分析的结果更加直观易于理解;第二,能够详细处理连续型变量和类别性变量;第三,能够详细科学地处理大量信息,而且决策树的大小和数据库大小无关,大大降低了数据挖掘工作量,当多个变量同时进入模型后,决策树仍然能发挥应有的作用;第四,其模型可以通过图形和规则来表示,进一步加强了有效性。
2)C4.5决策树算法的原理
C4.5 决策树算法[10~14]主要应用了信息理论中的信息增益,从而找到数据库中信息增益最大的属性,并建立相应的节点,根据数据库中信息增益的不同,形成不同的信息分支,然后根据每个分支建立同样的分支,从而形成决策树,在决策树上每个分支都代表了一个分类规则,大量相关实例表明,和其他分类模型相比,决策树算法最大的优势是可以实现模型的图形化,为数据挖掘工作人员提供有效的数据依据。
设定某一事件发生的概率为p,那么此事件发生后所产生的所有信息量就可以用1(p)来表示,如果p=1,那么1(p)=0,表示此事件属于必然事件,即该事件一定会发生,因此该事件不能提供任何有效的信息。如果一个事件发生的概率非常小,而且在具体运行中存在较大的不确定性,那么该事件产生的信息也就越多,综合而言,1(p)属于一个递减函数[15]。
假设数据库中信息量为S,类别变量E包含m个不同类,通过变量E就可以将信息总量分为m分量。对应m种可能发生概率,第i种结果的信息量,该给定样本分类所得的平均信息为熵,熵是测量一个随机变量不确定性的测量标准,可以用来测量训练信息集内纯度的标准。熵的函数表示如下式:
变量分类训练信息集的能力,可以利用数据增加来检测。通过熵函数得到每个影响因素的信息增加,具有高级的数据增加的因素选为判定集合的分类因素。由此得到一个节点,利用这个因素作为标记,对每个变量位进行分支化处理,并以此得到不同的样本数据。
就流水线产品生产企业而言,产品的质量直接关系到企业经济利益和形象声誉,所以必须建立科学合理的质量评价标准体系,根据产品的具体需求,在性能、强度、耐久性等方面制定标准体系,先把产品分为合格和不合格两大类,然后根据不同的营销方式和产品定价,分为优等产品和合格产品两大类。
3.4 建立数据挖掘模型
在建立数据挖掘模型前,必须要对样本的具体情况进行确定之后,才能构建决策树的具体属性,具体如表1所示。
然后对这些数据进行处理:针对性剔除无效的质量评价信息,简化信息处理量。通过A、B、C三种评定标准进行评定,其中A为优质产品、B为合格产品、C为不合格产品。根据具体质量检验情况,把检验产品分为A、B、C三大类。然后利用决策树算法来构建分类模型,由于决策树是树形结构,所以每个分枝都是一个信息属性。利用C4.5决策树算法来处理数据集,由于一类标号中都含有不同的2个属性值,也就可以获得两个类别,假定优等用C1来表示共有9个样本信息数据,用C2来表示共有5个样本,通过数据挖掘技术,就可以获得所需的数据:
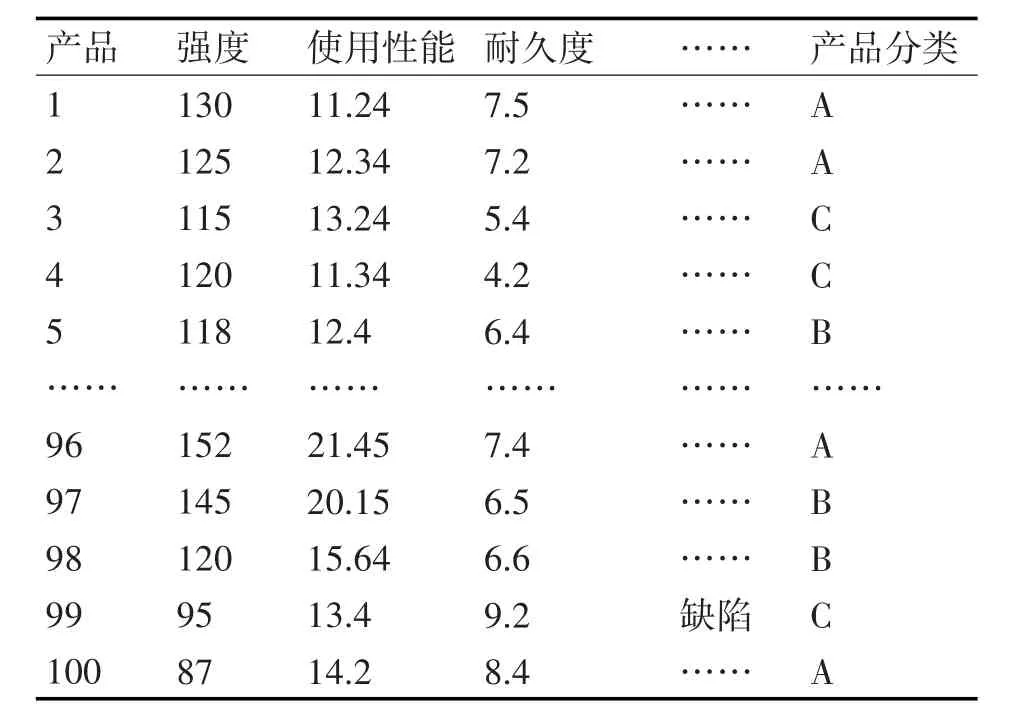
表1 样本数据集
3.5 数据挖掘模型的证实和评估
在得到分类的模型之后,要用测试数据来判断模型的正确情况,用来测试的数据都是从数据库里抽取的,与样本无关联的数据。本文主要利用构建的数据分类模型进行试验,为确保试验的准确性,采用K折交叉检验的方法进行试验,就是先把样本均等分为K份,然后对每一组的正确性进行检验,再对分组检验的正确率和总样本相除,就可以获得C4.5决策树算法的正确率,具体如表2所示。
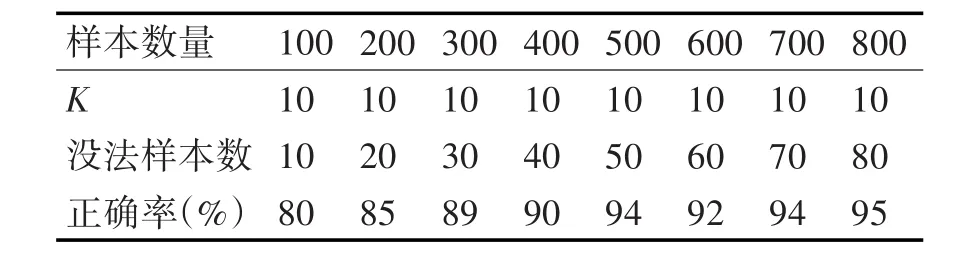
表2 K折交叉检验法险溢数据挖掘检测正确率对比
从表2中可以看出,如果质量检验的数量不断增加,传统手工产品质量检测的正确率明显下降,而通过数据挖掘C4.5决策树算法检验结果的正确性则明显上升,当样品数量为100时,由于质量检验的数量比较少,难以发挥出数据挖掘算法真正的价值和作用,其正确率为80%,但是样品数量在600时,正确率为92%,在800时,正确率为95%,已经明显超过了人工质量检验的的正确率。
4 基于数据挖掘的质量监控和评价软件系统可行性研究
近年来,我国软件系统的发展,基于数据挖掘的质量监控和评价软件系统的种类和品牌越来越多,但是目前我国市场上质量监控和评价软件系统几乎都是通用的软件,没有针对不同生产企业的具体情况而制定具体的指标体系以及判定标准。在这样的基础上研发出一套符合实际的基于数据挖掘的质量监控和评价软件系统就显得尤为重要。但软件系统的开发投资比较大,并存在一定的风险。所以在具体开发过程中,不但要满足客户的需求,而且要从企业的技术力量、经济实力、管理能力等多个方面入手。就质量评价软件系统的可行性而言,可以从三个方面入手,即技术可行性、经济可行性、社会可行性,具体如图1所示。

图1 质量监控和评价软件系统可行性分析
4.1 技术可行性
就基于数据挖掘的质量监控和评价软件系统体系的结构而言,主要有C/S和B/S模式,其中C/S模式,需要客户安装相应的客户端,通过客户端软件上传设计图,而其他客户可以通过像查询和检索对质量监控和评价软件系统上的信息进行检索和获取,其主要缺点是需要在所有工作人员的计算机上安装客户端,工作量比较大,对计算机的配置要求较高,其维护成本也比较大。而B/S模式属于浏览器服务模式,不需要用户安装任何客户端,通过计算机等终端设备和移动设备就可以查询和下载,对计算机配置的要求比较低,而且灵活实用,能有效地满足产品质量评价需求。
4.2 经济可行性
基于数据挖掘的质量监控和评价软件系统不但提高企业产品质量管理的效率,而且也能行之有效地预测未来产品质量的变化情况,为企业制定后期发展战略目标提供真实有效的数据依据,从而实现降低企业生产成本的目的,同时也减少了原管理过程中工时浪费现象,进一步减少了资源浪费问题。
4.3 社会可行性
本文提出的基于数据挖掘的质量监控和评价软件系统能彻底颠覆传统产品质量管理模式,取消了原来被动式的质量管理模式,即简化了产品质量管理的流程,而且促使整个产品质量管理具有更强的预警功能。受到社会各界人士的广泛关注和支持,为软件系统的调研和开发提供了必要的数据支持。
5 结语
综上所述,产品质量对生产制造企业的可持续发展有非常重要的作用,随着人们生活水平的提高,对产品质量提出了更高的要求。所以企业必须不断提升自身竞争力,结合企业产品加工生产各个环节对质量影响因素,研发出基于数据挖掘的质量监控和评价软件系统对企业生产和发展就显得尤为重要。本文通过C4.5决策树算法研究表明,基于数据挖掘的质量监控和评价软件系统能很大程度上提高质量检验的效率和准确性,在技术、经济、社会三个方面具有很强的可行性,值得大力推广。
[1]鲜于丹谦,李宏坤.基于数据挖掘的质量监控和评价软件设计与开发[J].数字技术与应用,2014(10):136.XIAN Yudanqian,LIHongkun.Design and Development of Quality Monitoring and Evaluation Software Based Data Mining[J].Digital Technology and Applications,2014(10):136.
[2]齐良春,侯开虎,张培发,等.基于自动识别与数据采集技术的质量监控系统构架研究[J].机电工程技术,2006,35(11):19-21,109.QILiangchun,HOU Kaihu,ZHANG Peifa,etal.Research on Quality Monitoring System Architecture Based on Automatic Identification and Data Acquisition Technology[J].Mechanical and Electrical Engineering Technology,2006,35(11):19-21,109.
[3]赵方,李兰英.基于业务流程的Web应用监控系统研究[J].计算机工程,2013,39(2):41-45.ZHAO Fang,LI Lanying.Research on Web Application Monitoring System Based Business Process[J].Computer Engineering,2013,39(2):41-45.
[4]王博伦,姜思宁,左健健,等.产品质量数据评价软件系统设计[J].中国科技信息,2017(3):79-81.WANG Bolun,JIANG Sining,ZUO Jianjian,etal.Product quality data evaluation software system design[J].China Science and Technology Information,2017(3):79-81.
[5]周桂如.决策树算法的研究及实例分析[J].南京工程学院学报(自然科学版),2013,11(3):58-61.ZHOU Guiru.Research on the Decision Tree Algorithm[J].Journal of Nanjing Institute of Engineering(Natural Science Edition),2013,11(3):58-61.
[6]张琳,陈燕,李桃迎,等.决策树分类算法研究[J].计算机工程,2011,37(13):66-67,70.ZHANG Lin,CHEN Yan,LITaoying,et al.Research on Decision Tree Classification Algorithms[J].Computer Engineering,2011,37(13):66-67,70.
[7]冯少荣.决策树算法的研究与改进[J].厦门大学学报(自然科学版),2007,46(4):496-500.FENG Shaorong.Research and Improvement of Decision Tree Algorithm[J].Xiamen University(Natural Science Edition),2007,46(4):496-500.
[8]谭俊璐,武建华.基于决策树规则的分类算法研究[J].计算机工程与设计,2010,31(5):1071-1019.TAN Junlu,WU Jianhua.Classification Based on Decision Tree Algorithm rule[J].Computer Engineering and Design,2010,31(5):1071-1019.
[9]季桂树,陈沛玲,宋航.决策树分类算法研究综述[J].科技广角,2007(1):9-12.JI Guishu,CHEN Peiling,SONG Hang.Review of research on decision tree classification algorithm[J].Science and technologywide angle,2007(1):9-12.
[10]杨学兵,张俊.决策树算法及其核心技术[J].计算机技术与发展,2007,17(1):43-45.ZHANG Jun,YANG Xuebing.Decision tree algorithm and its core technology[J].Computer technology and development,2007,17(1):43-45.
[11]W.G.Teng,M.-S.Chen,and P.S.Yu.A Egression-Based Temporal Pattern Mining Scheme for Data Streams[C]//In Proc. of the 29th VLDB Conference,2003.
[12]HuiChen.Mining Frequent Patterns in the Recent Time Window over Data Streams[C]//Proc in:the 10th IEEE International Conference on High Performance Computing and Communications,2009:586-593.
[13]Chi,Y,Wang H,Yu P.MOMENT:maintaining closed frequent itemsets over a data stream sliding window[C]//In:Proceedings of the 2004 IEEE International Conference on DataMining,Brighton,UK,2004:59-66.
[14]Hua-Fu Li,Suh-Yin Lee.Online Mining(Recently)Maximal Frequent Itemsets over Data Streams[C]//In:Proceedings of the 15th RIDE-SDMA Conference,Tokyo,Japan,2005:11-18.
[15]Golab.L.etal.Identifying Frequent Items in Sliding Windows over On-Line Packet Streams[C]//SIGCOMM Internet Measurement Conference.Miami.ACM,2003:173-178.
