二值选择模型内生性检验方法、步骤及Stata应用
2018-04-11袁微
袁 微
(上海财经大学 商学院,上海 200433)
0 引言
利用二值选择模型进行实证研究,有时会遇到解释变量为内生变量的情形。例如,考察幸福感影响慈善捐赠行为(捐赠/不捐赠)时,幸福感或许为内生变量。其原因是幸福感和慈善捐赠行为存在反向因果关系。具体来讲,一方面,个体幸福感显著正向影响个体慈善捐赠行为[1];另一方面,个体慈善捐赠行为的发生又显著提升个体幸福感[2]。幸福感是内生变量,在实证检验中使用通常的二值选择模型将有可能得不到一致估计[3]。对此,要缓解或解决此问题就有必要进行内生性检验。
纵观国内外有关内生性检验的文献,虽然有提及OLS模型内生性检验方法、步骤及Stata应用[4-6],但是却鲜少提及二值选择模型内生性检验的具体方法、步骤及Stata应用。即使陈强(2014)[6]曾在著作中将二值选择模型中的Probit模型内生性检验作为“选读”章节,但是其却并未对此问题进行深入探讨。正如以上原因,使得众多学者,尤其是初学者在进行二值选择模型内生性检验时心存众多疑问。例如,(1)相对于OLS模型内生性检验,二值选择模型内生性检验的具体方法、步骤和Stata应用是什么?(2)对于二值选择模型中含有的内生变量数量的变化,则又该如何处理?(3)对于二值选择模型中存在内生变量与其他解释变量交互的情况,则又该如何处理?以上这些问题均是学者们在进行二值选择模型内生性检验时可能会遇到的问题。因此,本文将以二值选择模型中的Probit模型为例,根据陈强(2014)[6]提出的Probit模型内生性检验原理,围绕以上问题展开研究,以期能解开学者和初学者们在进行二值选择模型内生性检验时所遇到的困惑。
1 Probit模型内生性检验的方法及原理
“工具变量 Probit”(Instrumental Variable Probit,简称IV Probit)和“两步法”(Two-step Method)是学术界公认的两种检验Probit模型内生性的有效方法[7-9]。目前,有众多学者已对以上两种方法的原理进行了详细介绍。本文主要基于已有文献提出的原理,针对学者们在研究中对Probit模型内生性检验的若干疑问进行阐释。本文将陈强(2014)[6]对Probit模型内生性检验的方法及相关原理的介绍如下:

其中,y1i为可观测的虚拟变量,y*1i为不可观测的潜变量,y2i是模型中唯一的内生变量。方程(1)称为“结构方程”(该方程右边含内生变量),而方程(2)称为“第一阶段方程”或“简化式方程”(该方程右边不含内生变量)。
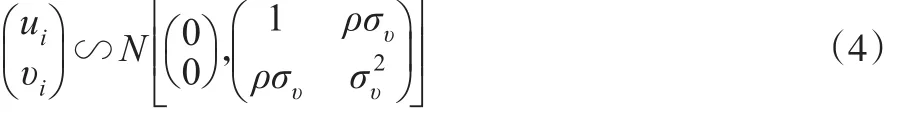
其中,ui的方差被标准化为1,而ρ为的相关系数。显然,由于υi服从正态分布,故y2i也服从正态分布,因此y2i必须为连续变量。进一步,假设独立于xi与zi,故在方程(1)中,xi为外生解释变量。而且,zi可作为方程(1)中内生变量y2i的工具变量,因为zi与内生变量y2i相关,且zi与ui无关。在此模型中,y2i的内生性完全来自于ui与υi的相关性;如果二者的相关系数ρ=0,则y2i为外生变量。因此,对于y2i内生性的检验可以通过检验“H0:ρ=0”来进行。
由方程(1)至方程(4)所构成的模型,在给定xi与zi的情况下,的条件概率分布已经完全确定。将联合概率密分解为zi),可写出样本数据( )y1i,y2i的似然函数,然后进行最有效率的MLE估计。此方法称为“工具变量Probit”。
尽管MLE最有效率,但在数值计算时,可能不易收敛,特别在多个内生解释变量的情形下。可以使用两步法。基本思想如下:
在方程(1)中,既然y2i的内生性是由于遗漏了变量υi所造成,那么如果能把υi作为控制变量放入方程(1)即可得到一致估计。虽然方程(2)的扰动项υi不可观测,但可用OLS残差作为υi的一致估计。
由于( )ui,υi服从二维正态分布,故根据多元统计知识,ui对于υi的总体回归方程可以写为:


其中,Vаr()ui=1。将方程(5)代入方程(1)可得:

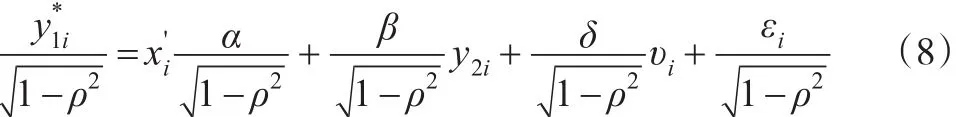
由于方程(8)中的υi不可观测,故两步法由以下两步构成:
第一步:对简化式方程(2)进行OLS回归,得到残差。
第二步:以残差替代方程(8)中的υi,进行Probit估计,得到对变换后系数的估计。
在使用两步法的情况下,对y2i内生性的检验可通过检验原假设“H0:δ=0 ”来进行,如果δ=0 ,则ui与υi不相关。
综合以上所述可知,Probit模型内生性检验的方法主要有MLE和两步法两种,但是鉴于两步法比MLE计算方便且适合在多个内生解释变量的情形下使用,所以本文将基于两步法来阐述Probit模型内生性检验的具体步骤及Stata应用。
2 不同情况下Probit模型内生性检验的步骤及Stata应用
2.1 只含有单个内生解释变量
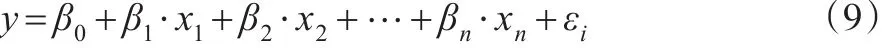
其中,y为被解释变量,x1为内生解释变量;x2…xn为控制变量;β0、β1、β2…βn为待估计的系数;εi为随机扰动项。本文假设z1和z2为内生解释变量x1的工具变量,则可根据以下步骤进行Probit模型内生性检验。
2.1.1 初始工具变量检验
对于所选择的工具变量,首先需要进行初步检测,即检测工具变量z1和z2的有效性以及判断x1是否为内生解释变量。初始工具变量的检验的原假设为“H0:内生变量为外生”;备选假设为“H1:内生变量为内生”。初始工具变量的检验应该拒绝原假设,不拒绝备选假设。
初始工具变量检验的Stata命令:
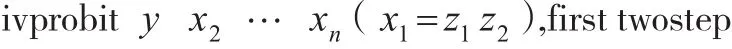
2.1.2 过度识别检验
若模型中含有的内生解释变量个数等于或少于工具变量个数,则无需进行过度识别检验;反之,则需要进行过度识别检验[3]。所谓的过度识别检验自身为一种卡方检验,它是对所选取的工具变量进一步的检测,以确认所选择的工具变量均为外生,即与扰动项不相关。它的原假设为“H0:所有工具变量均为外生”;备选假设为“H1:至少存在一个工具变量为内生”。过度识别检验应该不拒绝原假设,拒绝备选假设。鉴于模型(9)中所含有的内生解释变量(x1)个数少于所选取的工具变量(z1和z2)个数,所以需要进行过度识别检验。
过度识别检验的Stata命令:overid
2.1.3 弱工具变量检验
弱工具判断也叫考察工具的相关性。检验内生变量和工具变量的相关性,也就是检验模型的回归系数的极限分布是否是正态分布,是否会扭曲相应统计量的一致性[10]。弱工具变量检验的原假设为“H0:内生变量与工具变量不相关”;备选假设为“H1:内生变量与工具变量相关”。弱工具识别检验应该拒绝原假设,不拒绝备选假设。
弱工具识别检验的Stata命令:

值得注意的是,ivprobit与OLS模型在内生性检验步骤上的区别是:OLS模型经过以上三种检验之后,还需要进行最后一步检验——Durbin-Wu Hausman检验,即外生性检验,用以检测IV模型是否优于OLS模型。但是ivprobit模型则不需要再进行Durbin-Wu Hausman检验,其原因是ivprobit已经在上述三种检验中提供了内生性检验(H0:内生变量为外生,及rho=0)[6]。
综合以上可知,完整的Probit模型内生性检验主要包括三个步骤:初始工具变量检验、过度识别检验和弱工具识别检验。若模型中含有的内生解释变量个数多于所选取工具变量个数,则需要进行过度识别检验;反之,则不需要进行过度识别检验。
鉴于处于不同情况下的Probit模型内生性检验的方法、原理及步骤并无显著差异,因此本文将直接书写相应的Stata命令。
2.2 含有多个内生解释变量
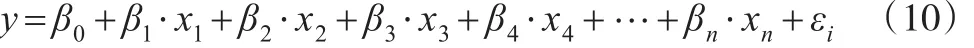
其中,y为被解释变量,x1、x2、x3为内生解释变量;x4,…,xn为控制变量;β0、β1、β2、β3、β4…βn为待估计的系数;εi为随机扰动项。本文假设z1、z2和z3分别为内生解释变量x1、x2和x3的工具变量,则可根据以下步骤进行Probit模型内生性检验。
2.2.1 初始工具变量检验
初始工具变量检验的Stata命令:
ivprobity x4…xn(x1x2x3=z1z2z3),first twostep
2.2.2 过度识别检验
由于模型(10)中含有的内生解释变量(x1、x2和x3)个数等于所选取的工具变量(z1、z2和z3)个数,则无需进行过度识别检验。
2.2.3 弱工具变量检验
弱工具识别检验的Stata命令:
weakiv ivprobityx4…xn(x1x2x3=z1z2z3),twostep
2.3 含有单个内生解释变量,且该变量与其他解释变量存在交互项

其中,y为被解释变量,x1为内生解释变量;x2为外生解释变量;x1x2为内生解释变量x1和外生解释变量x2的交互项;x3,…,xn为控制变量;β0、β1、β2、β3、β4…βn为待估计的系数;εi为随机扰动项。本文假设z1和z2为内生解释变量x1的工具变量,则可根据以下步骤进行Probit模型内生性检验。
2.3.1 初始工具变量检验
模型(11)中x1x2是内生解释变量x1和外生解释变量x2的交互项,因为x1是内生解释变量,所以交互项x1x2也是内生解释变量。在进行初始工具变量检验之前,针对交互项x1x2,需要先分别生成工具变量z1和z2与外生解释变量x2的交互项z1x2和z2x2。其相应的Stata命令为:genz1x2=z1*x2;genz2x2=z2*x2。完成以上操作,便可进行初始工具变量检验。
初始工具变量检验Stata命令:
ivprobityx2x3…xn(x1x1x2=z1z2z1x2z2x2),first twostep
2.3.2 过度识别检验
由于模型(11)中含有的内生解释变量(x1和x1x2)个数少于所选取的工具变量(z1、z2、z1x2和z2x2)个数,所以需要进行过度识别检验。
过度识别检验的Stata命令:overid
2.3.3 弱工具变量检验
弱工具识别检验的Stata命令:
weakiv ivprobityx2x3…xn(x1x1x2=z1z2z1x2z2x2),twostep
2.4 含有多个内生解释变量,且这些变量与其他解释变量存在交互项
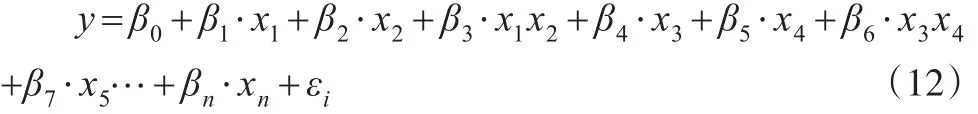
其中,y为被解释变量,x1、x3为内生解释变量;x2、x4为外生解释变量;x1x2为内生解释变量x1和外生解释变量x2的交互项;x3x4为内生解释变量x3和外生解释变量x4的交互项;x5,…,xn为控制变量;β0、β1、β2、β3、β4…βn为待估计的系数;εi为随机扰动项。本文假设z1和z2分别为内生解释变量x1、x3的工具变量,则可根据以下步骤进行Probit模型内生性检验。
2.4.1 初始工具变量检验
根据前文的介绍,在进行初始工具变量检验之前,针对交互项x1x2和x3x4,需要先生成工具变量z1与外生解释变量x2的交互项z1x2,以及工具变量z2与外生解释变量x4的交互项z2x4。其相应的Stata命令为:genz1x2=z1*x2;genz2x4=z2*x4。完成以上操作,便可进行初始工具变量检验。
初始工具变量检验的Stata命令:
ivprobityx2x4…xn(x1x3x1x2x3x4=z1z2z1x2z2x4),first twostep
2.4.2 过度识别检验
由于模型(12)中含有的内生解释变量(x1、x3、x1x2和x3x4)个数等于所选取的工具变量(z1、z2、z1x2和z2x4)个数,所以不需要进行过度识别检验。
2.4.3 弱工具变量检验
弱工具识别检验的Stata命令:
weakiv ivprobityx2x4…xn(x1x3x1x2x3x4=z1z2z1x2z2x4),first twostep
3 实例分析
3.1 模型和数据
3.1.1 模型设定
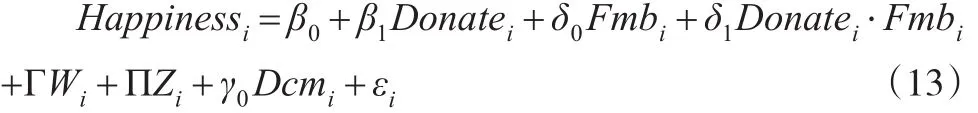
模型(13)为Probit模型,其中Happinessi是被解释变量,用来衡量家庭i是否幸福的指标;解释变量中,变量Donatei是衡量家庭i慈善捐赠额的指标;Fmbi为哑变量,表示家庭i的成员数水平;变量Wi是影响家庭幸福感的家庭特征变量矩阵,如Inc、Hel、Emp;变量Zi是影响家庭幸福感的宏观经济安全环境变量矩阵,如Pse、Fey;Dcmi表示城市虚拟变量;β0、β1、δ0、δ1、Γ 、Π 和γ1分别为待估计的系数或系数向量;εi为随机扰动项(变量定义见表1)。

表1 变量定义
3.1.2 数据描述
本文采用的数据均来自于2011年的《中国家庭金融调查》(China Household Finance Survey,CHFS)。CHFS(2011)是西南财经大学中国家庭金融调查与研究中心进行的一项全国性的调查,以随机抽样的方法访问被调查者,被调查者的足迹遍布全国25个省、80个县、320个社区,完成样本8438份。
在剔除了数据缺失的样本之后,本文最终整理得到了3013份微观样本。这3013份样本分别分布在中国东部城市(9个)、中部地区(8个)、西部地区(8个)。从表2的样本城市地理分布来看,其分布较为平均,说明本文所研究的样本具有一般的代表性。

表2 样本城市分布表
3.2 回归分析与内生性检验
3.2.1 回归分析
在进行一般的Probit模型回归之前,首先需要生成解释变量Donate与解释变量Fmb的交互项Donate_Fmb,其相应的Stata命令为:
gen Donate_Fmb=Donate*Fmb
完成以上操作,则可进行一般的Probit模型回归,其相应的Stata命令为:
probit Happiness Donate Fmb Donate_Fmb Hel Emp Inc Pse Fey Dcm
一般的Probit模型回归结果见表3。

表3 一般的Probit模型回归结果
表3显示,Donate的系数为0.128,且在1%水平上显著,即家庭慈善捐赠额越高,则家庭越幸福。Donate_Fmb的系数为0.093,且在5%水平上显著,即在其他条件保持不变的情况下,家庭成员数水平高的家庭与家庭成员数水平低的家庭所捐赠的金额一致时,则家庭成员数水平高的家庭可能比家庭成员数水平低的家庭更幸福。但本文认为Donate不是内生解释变量,因为家庭慈善捐赠与家庭是否幸福之间可能存在反向的因果关系,即家庭是否幸福也影响了家庭慈善捐赠。具体来说,感到幸福的家庭在亲社会行为方面表现得更为积极(如频繁捐赠,捐款金额较多),而帮助他人本身又能提高家庭的幸福感。由于家庭慈善捐赠和家庭是否幸福这两者之间可能存在反向的因果关系,所以这将会使得家庭慈善捐赠是家庭是否幸福决定方程中的内生解释变量。此时,一般的Probit模型计算得到的回归系数就不具有一致性。为此,基于此情况就需要对Probit模型进行内生性检验。
3.2.2 内生性检验
(1)初始工具变量检验
本文将Hgen(户主的性别,1代表男性,0代表女性)、Hpmr(户主的政治身份,1代表党员,0代表非党员)、Hedu(户主的教育水平,1代表高教育水平,0代表低教育水平)作为内生解释变量Donate的工具变量。一方面,户主性别、政治身份与教育水平与家庭慈善捐赠额Donate相关,满足工具变量的相关性;另一方面,假设户主的性别、政治身份与教育水平不直接影响家庭的幸福,故满足工具变量的外生性。在使用这些工具变量进行IV Probit估计之前,依然需要先分别生成户主性别Hgen、政治身份Hpmr、教育水平Hedu与外生解释变量Fmb的交互项Hgen_Fmb、Hpmr_Fmb和Hedu_Fmb,其相应的Stata命令为:
gen Hgen_Fmb=Hgen*Fmb
gen Hpmr_Fmb=Hpmr*Fmb
gen Hedu_Fmb=Hedu*Fmb
完成以上步骤,方可进行IV Probit估计,其相应的Stata命令为:
ivprobit Happiness Fmb Hel Emp Inc Pse Fey Dcm(DonateDonate_Fmb= HgenHpmrHeduHgen_FmbHpmr_Fmb Hedu_Fmb),first twostep
IV Probit估计的结果见表4至表6。

表4 IV Probit估计第一阶段回归结果I
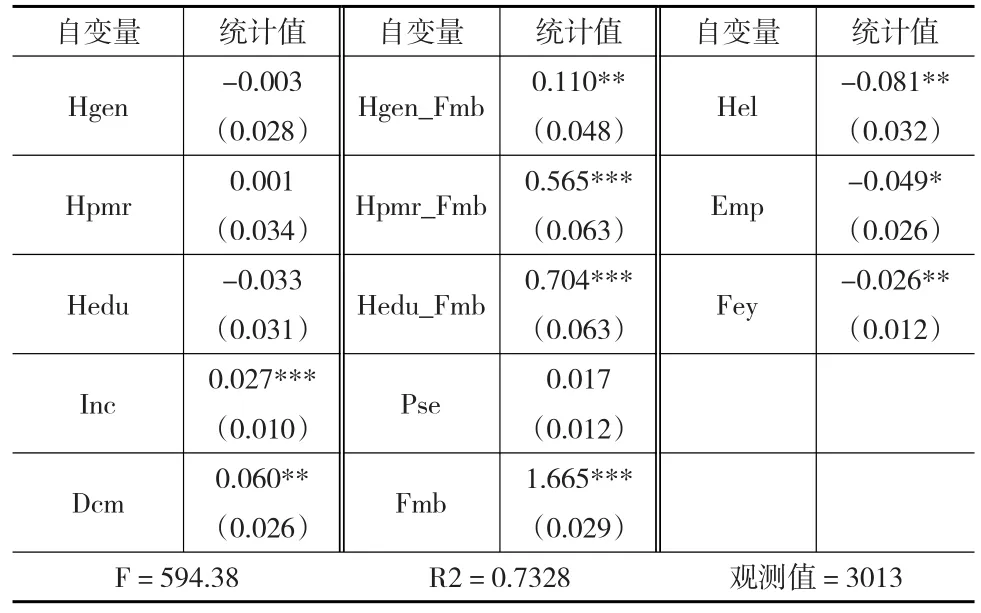
表5 IV Probit估计第一阶段回归结果II

表6 IV Probit估计第二阶段回归结果
表6提供了对外生性原假设“H0:ρ=0”的沃尔德检验结果,其p值为0.0006,故可在1%的水平上认为Donate和Donate_Fem为内生解释变量。根据表3的估计结果可知,Donate变量的系数为0.128,在1%的水平上显著;Fem变量的系数为-0.282,在1%的水平上显著;Donate_Fem变量的系数为0.938,在10%的水平上显著;Hel变量的系数为0.53,在10%的水平上不显著。但是表6的IV Probit估计结果显示,Donate变量的系数为0.215,在5%的水平上显著;Fem变量的系数为-0.104,在1%的水平上显著;Donate_Fem变量的系数为0.505,在1%的水平上显著;Hel变量的系数为0.138,在10%的水平上显著。以上结果表明,如果使用一般的Probit模型进行估计,由于忽略了Donate的内生性,将低估家庭慈善捐赠额对家庭幸福的正作用;将高估家庭成员数水平对家庭幸福的负作用;将高估家庭慈善捐赠与家庭成员数水平的交互项对家庭幸福的正作用;将忽略家庭成员健康状况对家庭幸福的正作用。另外,从表4的回归结果来看,工具变量Hgen、Hpmr、Hedu对于内生变量Donate具有较强的解释力;从表5的回归结果来看,工具变量Donate_Hgen、Donate_Hpmr、Donate_Hedu对于内生变量Donate_Fmb具有较强的解释力。
(2)过度识别检验
由于模型(13)中含有的内生解释变量(Donate、Donate_Fem)个数少于所选取的工具变量(Hgen、Hpmr、Hedu、Hgen_Fmb、Hpmr_Fmb、Hedu_Fmb)个数,所以需要进行过度识别检验以进一步检测选取的工具变量。
过度识别检验的Stata命令为:overid
过度识别检验结果中的p值为0.3870,其小于0.05,则不拒绝原假设“H0:所有工具变量均为外生”,这说明本文所选取的工具变量都是外生变量。
(3)弱工具识别检验
弱工具识别检验的Stata命令为:
Weakiv ivprobit Happiness Fmb Hel Emp Inc Pse Fey Dcm(Donate Donate_Fmb=Hgen Hpmr Hedu Hgen_Fmb Hpmr_Fmb Hedu_Fmb),twostep
弱工具识别检验的结果见表7。

表7 弱工具识别检验结果
表7结果显示,CLR、K-J、AR、Wald的p值均在1%水平上显著,则应该拒绝原假设“H0:内生变量与工具变量不相关”,不拒绝备选假设“H1:内生变量与工具变量相关”。这也说明,本文所选择的工具变量不是弱工具变量。
4 总结
本文基于学者们在二值选择模型内生性检验方面积累的研究成果,以Probit模型为例,对二值选择模型内生性检验的具体方法、步骤和Stata应用进行了拓展。例如,本文提出完整的Probit模型内生性检验由三大步骤组成:初始工具变量检验、过度识别检验和弱工具识别检验,而后两个步骤前辈们并未指出。另外,本文给出了处于不同情况下的Probit模型内生性检验方法及Stata应用。
参考文献:
[1]南方,罗微.社会资本视角下城市居民捐款行为的影响因素分析[J].北京师范大学学报:社会科学版,2013,(3).
[2]唐闻捷.民营企业家慈善捐赠行为与主观幸福感——基于温州地区中小型民营企业家的调查[J].浙江社会科学,2013,(8).
[3][美]伍德里奇.计量经济学导论(第四版)[M].北京:中国人民大学出版社,2010.
[4]倪伟才.两种内生性检验方法的等价性[J].科技视界,2012,(29).
[5]王美今,林建浩,胡毅.IV估计框架下模型设定检验问题的讨论[J].统计研究,2012,(2).
[6]陈强.高级计量经济学及Stata应用(第二版)[M].北京:高等教育出版社,2014.
[7]Newey W K.Efficient Estimation of Limited Dependent Variable Models with Endogenous Explanatory Variables[J].Journal of Econometrics,1987,36(3).
[8]Rivers D,Vuong Q H.Limited information Estimators and Exogeneity tests for Simultaneous Probit Models[J].Journal of econometrics,1988,39(3).
[9]周广肃,梁荣,田金秀等.Stata统计分析与应用[M].上海:机械工业出版社,2011.
[10]Pflueger C E,Wang S,Newton H J,et al.A Robust Test for Weak Instruments in Stata[J].Social Science Electronic Publishing,2015,31(3).
