工业大数据助力两化融合:挑战、机遇与未来
2018-04-10高韵,李成
高 韵,李 成
(1.工业和信息化部国际经济技术合作中心, 北京 100846;2.中国电信集团有限公司政企客户事业部, 北京 100032)
1 工业大数据简介
1997年,在“Application-controlled demand paging for out-of-core visualization”这篇文章中,作者提到,海量的数据已经无法被存储于内存、本地磁盘甚至远程磁盘中,于是他将这一现象,称为“大数据”问题。从此以后,学术界和产业界均对这一新概念产生了极大的兴趣,并不断丰富和完善大数据的内涵、技术体系和应用场景。
为了更清晰地描述大数据,维克托·迈尔·舍恩伯格在《大数据时代》一书中提出大数据具有4V特性,即 Volume(数据量大)、Velocity(流动速度快)、Veracity(准确性)和 Variety(来源多样)。目前,4V特性已被学术界广泛使用,成为描述大数据特点的共识。
相比于传统的大数据,对于工业大数据,还应该有两个“V”[1]。
Visibility:可见性,即通过大数据分析使以往不可见的重要因素和信息变得可见。
Value:价值,即通过大数据分析得到的信息应该被转换成价值。
正是因为工业大数据具有更强的专业性、关联性、流程性、时序性和解析性等特点,工业大数据的挑战和目的一般通过“3B”和“3C”来理解。
Bad Quality:数据质量差。受制于生产一线数据获取手段,以及现有传感器、传输信道的稳定性,加之不可避免的人为干扰,极大地降低了所采集数据的准确性和真实性。
Broken:碎片化。面向应用要求具有尽可能多维度的样本数据,全方位反映生产过程中各类变化的因素,保证从数据集中能够提取出真实反映对象状态的全面性信息。
Below Surface:隐匿性。除了对数据所反映出来的表面统计特征进行分析以外,更应该关注数据背后的物理意义以及特征之间关联性。
Comparison(比较性):通过纵向或横向比较,发现数据波动的规律和异常,为海量信息的分类与管理奠定基础。
Correlation(相关性):借助大数据相关技术,才能发掘出不同维度数据的相关性,从不同维度分析同一生产过程,优化生产效率。
Consequence(因果性):工业生产的流程众多,影响因素错综复杂,但无论如何目标都是利用最少的材料,生产出质量最优的产品。因此,在制定特定决策时,需要通过数据预测分析出其所带来的影响,判断决策是否对于实现最终目标有益。
通过以上分析可以看出,工业大数据贯穿了工业生产的全过程,全面细致地反映出制造业生产的全流程,从不同角度记录制造业生产的影响因素。通过对数据的汇总分析,以信息化带动工业化,帮助制造业企业科学决策、优化生产、精细管理,走上新型工业化的道路。这其实正是两化融合的内在要求。
2 工业大数据技术
对于制造业而言,随着信息化建设进步和工业物联网的普及,数据量呈现出爆炸性增长趋势。大数据技术,正是为了解决海量数据的存储、处理、分析以及利用数据决策这些问题(如图1所示)。
图1 大数据分析流程及相关技术
2.1 数据存储技术
随着数据规模的显著上涨和对数据写入速率要求的提升,以及例如日志、文本和图片等非结构化数据的增多,Oracle、DB2、PostgreSQL、Microsoft SQL Server为代表的传统关系型数据库(RDBMS)已经不能适应工业大数据的发展要求。因此,为适应大数据的发展,越来越多的企业开始使用MongoDB、Redis、CouchDB等非关系型数据库(NoSQL)。这些非关系型数据库,简化了数据之间的关系,因此非常容易扩展,可以适应数据量迅速上涨的要求,并且特别适合部署在分布式存储系统中,符合大数据发展的要求。
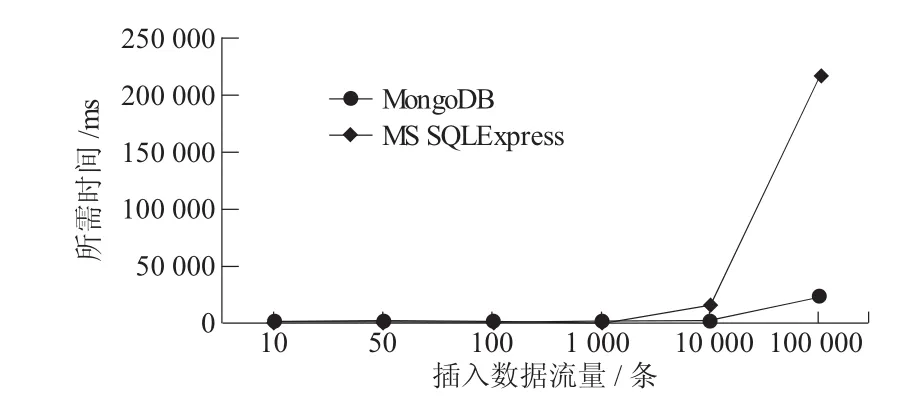
图2 关系型数据库与非关系型数据库速度对比
从图2可以看出,数据量较小时,关系型数据库与非关系型数据库二者速率相当。但随着写入数据量的增大,非关系型数据库(MongoDB)表现明显优于关系型数据库(MS SQLExpress),因此非常适合大量数据的写入[3]。
2.2 数据处理技术
数据处理包含数据的清洗、筛选以及加工。然而,受制于存储容量、数据读取速度、硬件稳定性等原因,传统的计算机系统已经无法满足海量数据的处理要求。为解决这一问题,新的分布式系统架构应运而生,其中最有代表性的就是由Apache基金会开发的Hadoop系统。
Hadoop的框架两大核心设计:分布式文件系统HDFS和并行计算模型MapReduce。其中HDFS负责为海量数据提供存储能力,分布式的设计,也让其具有理论上无限扩展容量的能力;而基于并行计算的MapReduce为海量数据提供了高效快速的计算框架,可以充分利用集群内所有机器的计算、数据读取、网络带宽等资源。解决了数据的存储和计算问题,技术人员就可以通过Hadoop来实现对海量数据的全面提取加工。
然而,发展10余年的Hadoop解决了处理大数据的问题,但因其设计之初没有考虑到效率,导致在面对迭代计算问题时效率很低,在此背景下,强调效率与速度的Spark应运而生。Spark允许传统Hadoop集群中的应用程序在内存中以100倍的速度运行,即使在磁盘上运行也能快10倍。与此同时,Spark使用了 RDD(Resilient Distributed Datasets)数据抽象,这允许它可以在内存中存储数据,只在需要时才持久化到磁盘。这种做法大大减少了数据处理过程中磁盘的读写,大幅度降低了运行时间。当前越来越多的企业正在通过升级改造,加入到Spark的生态系统中。
2.3 数据分析技术
大数据分析指的是运用不同方法以发现数据的隐藏模式,未知相关性和其他有用信息的过程[4]。主要目的是帮助决策者更进一步了解数据,发现数据的规律,以便科学决策,提升生产效率。目前在Hadoop生态系统中,活跃着许多数据建模分析工具,帮助开发人员从不同角度对现有数据进行建模分析。比如,Apache旗下开源项目Mahout。借助Mahout提供的机器学习算法包,开发人员可以方便快捷地运用聚类、分类、推荐过滤和频繁子项挖掘等不同算法对数据进行建模分析。此外,为了更进一步降低数据分析门槛,微软推出的商业分析工具Power BI可以帮助普通用户一键生成美观的报表,直观地发现数据的规律和特点。
当前,随着图像识别、语音识别和神经网络等人工智能技术的发展,为大数据的使用提供了更广阔的思路。比如,利用图像识别技术,生产企业可以进行实时的缺陷检测,发现流水线上产品的瑕疵,效率和准确率都比之前的人工检测大大提高。
3 工业大数据面临挑战与机遇
虽然大数据发展形势向好,但目前大数据依然面临四大挑战:数据收集、数据传输、数据隐私保护和数据模型决策。
3.1 大数据采集
数据采集是工业大数据应用的第一步,直接决定了数据的质量和维度,是数据分析决策的基础。尽管现在多种多样的传感器被大量应用在工业生产环境中,但是,数据的采集仍存在一些问题。首先,受制于制造信息化水平以及从业者素质,许多企业不得不采取手动抄录的方法记录数据。因此,数据经常不完整、不准确、不及时,这导致基于数据的决策不能真实及时准确解决生产实际问题。此外,即使数据由传感器自动采集传输,由于各个制式的传感器数据的异构性,缺乏统一的采集标准,大量的非结构化数据对下一步的数据处理造成了极大困难。最后,采集有效数据也是另一大难题。由于缺乏有效的规划,没有考虑过数据分析的目标,往往是先有数据后有模式,很容易造成众多传感器采集回传的数据没有用武之地,而一些对决策关键的数据反而没有采集的情况。
针对以上的问题,各方一直在着手解决,并且已经形成了一些可行的办法。随着工厂信息化智能化的改造,以及一线人员素质的提升,很多工厂已经逐渐实现了机器换人,淘汰了落后的手工统计数据的做法,转型升级成“数字无人工厂”。此外,更多的射频识别(RFID)、红外感应器、全球定位系统和激光扫描器等信息传感设备在制造车间使用,大大提升了工厂的信息采集能力。各个传感设备厂商也开始着手制定行业统一的数据格式和传输标准,保证设备的兼容性和数据的格式统一性,并合力打造数据集成监测云平台,让各类数据在云平台上聚集,发挥互补优势,全面反映生产状况。最后,在建设信息系统之初就要确立数据分析的目标,从应用价值的功能与目标出发,反推需要分析与利用的数据要求,进而设计满足要求的物联网数据环境和数据标准,针对性地选取数据,做到先有需求再采集数据。
3.2 大数据传输
传感器收集到数据以后,需要将数据传输到数据中心存储。其中,传输主要分为两部分:有线传输和无线传输。特别是无线传输,由于数据的传输量大、采集频率高,传输信道极易受到其他电子设备的干扰,造成数据的丢失和损坏。此外,工业互联网传感器众多,为确保数据采集效果,每个传感器均被接入到无线网络中,占用大量的网络资源,给现有的网络造成了极大的压力,甚至有可能超出了基站容量。此外,受限于现在的网络带宽,海量的数据传输速度可能变得十分缓慢。
为解决以上问题,基于蜂窝的窄带物联网协议(Narrow Band Internet of Things简称NB-IoT)应运而生。具体来说,NB-IoT具备四大特点:一是广覆盖,在同样的频段下,NB-IoT比现有的网络增益20 dB,相当于提升了100倍覆盖区域的能力,极大提升了传输信道的抗干扰能力;二是具备支撑海量连接的能力,NB-IoT一个扇区能够支持10万个连接,支持低延时敏感度、超低的设备成本、低设备功耗和优化的网络架构,非常适合数量众多的传感器连接;三是更低功耗,NB-IoT终端模块的待机时间可长达十年;四是更低的模块成本,企业预期的单个接连模块不超过五美元[5]。
对于数据传输慢这一问题,产业界也进行了许多尝试,比如向运营商购买专用网络、部署速度更快的互联网交换设备、使用更先进的通信标准等。但总体来说,对于提升传输速率的作用有限。2016年11月,亚马逊新推出一项名为AWS Snowmobile的服务,为用户提供一种新意十足的数据传输方式:通过载有一个45 ft标准集装箱能够容纳100 PB数据的卡车,将大型企业客户数据由企业数据中心“开到”亚马逊公共云计算数据中心。根据亚马逊的数据:如果使用一条10 Gbps的高速网络传输1 EB(1 EB=1 024 PB)的数据,需要26年;但如果使用Snowmobile,这个时间很可能会缩短到6个月。亚马逊的这项服务,为大数据传输提供了新的思路。
3.3 数据模型决策
对于数据的利用,最终要落实到大数据模型的建立以及基于模型的科学决策上。但是,目前大数据模型的建立仍存在一定的困难,主要由于工业大数据来源于工业生产,涉及众多的生产过程。对于大数据分析师而言,虽然在数据分析建模领域有丰富的经验,但无法深刻理解工业生产过程,因此无法实现对大数据的精准分析。另一方面,工业生产专家虽然熟悉生产过程,但缺乏相关的统计学知识和数据分析技能,面对大数据时经常显得束手无策。因此,要解决这一问题,需要企业培养一批既懂生产过程,又具备统计及数据分析能力的人才,与大数据分析师一起联合攻关,共同构建大数据模型。
4 结语
以工业大数据为代表信息技术不断被政府和企业所重视,从德国的“工业4.0”到美国的“工业互联网”战略规划,再到中国的“中国制造2025”和“互联网+”,这其中无不体现政府对以云计算、物联网和大数据技术与传统工业深度融合,协同发展的期待。
面对发达国家的“再工业化”与新兴市场低生产成本的双重挤压,在新一轮的工业革命和产业变革中,中国的制造业正面临前所未有的严峻挑战和难得的历史机遇。为了实现制造业强国的战略目标,2015年5月8日,国务院正式印发《中国制造2025》。这一十年期的行动纲领对于两化融合做出了进一步阐释,明确提出“新一代信息技术与制造业深度融合,正在引发影响深远的产业变革,形成新的生产方式、产业形态、商业模式和经济增长点。”与此同时,对于工业大数据,也明确指出“工业大数据是我国制造业转型升级的重要战略资源”。
相信在未来的十年里,中国的制造业将以两化融合为主线,以智能制造为主攻方向,借助工业大数据、云计算、5G等信息技术,实现工业化信息化相互渗透、相互融合。到2025年,制造业整体素质大幅提升,创新能力显著增强,全员劳动生产率明显提高,两化融合迈上新台阶。
[1]李杰(Jay,Lee).工业大数据:工业4.0时代的工业转型与价值创造[M].北京:机械工业出版社,2015.
[2]工业互联网产业联盟.中国工业大数据技术与应用白皮书[Z],2017.
[3]Y.Li,S.Manoharan.A performance comparison of sql and nosql databases[G]//Communications Computers and Signal Processing(PACRIM)2013 IEEE Pacific Rim Conference on,2013:15-19.
[4]SearchBusinessAnalytics.What is big data analytics-Definition from WhatIs.com.[EB/OL].[2017-10-09.]http://searchbusinessanalytics.techtarget.com/definition/big-data-analytics.
[5]未来移动通信论坛.蜂窝上的万物互联:NB-IoT[EB/OL].[2016-02-03].http://www.future-forum.org/2009cn/onews.asp id=5627.
