笔画背景抑制的自然场景文本检测
2018-04-09熊承义田清越高志荣龚忠毅
熊承义,田清越,高志荣,龚忠毅
(1 中南民族大学 电子信息工程学院,智能无线通信湖北省重点实验室,武汉430074;2 中南民族大学 计算机科学学院,武汉 430074)
自然场景文本检测与识别是图像处理、机器视觉领域的研究热点,其在增强现实[1]、盲人辅助系统[2]以及无人驾驶等方面有着重要的应用.虽然经过多年发展,背景较单一的文本检测与识别已经取得了不错的效果,但是基于复杂场景的文本检测在当前仍然存在着许多困难.主要原因在于:一是不同的自然场景嵌杂许多不同的干扰,如纵横交错的铁丝网、密集的树叶、相互重叠的栅栏等;二是自然图像中的文本可能还存在光照变化、模糊和颜色不同及方向变化等情况.
目前的文本检测方法大致可以划分为3类,即基于边缘的方法[3,4],基于纹理的方法[5,6]及基于连通域的方法[7-11].基于边缘的方法通常利用文字区域结构以及灰度的变化,先采用边缘检测算子来检测图像的边缘,然后结合数学形态学方法与启发式规则去除非文本区域,从而实现文本检测;基于纹理的方法是将文字视为特殊类型的纹理,并利用其幅频响应、离散余弦变换系数、小波变换等纹理属性判断文本与非文本; 基于连通域的方法通常利用文本区域的特点,采用聚类分析等方法对图像进行连通域提取,并通过逐步的分类规则将连通区域中的非文本排除并获取最终的文本.
Guo等人[7]较早提出采用笔画作为滤波器来定位场景中的文字,由于大量的参数根据经验而设置,缺乏普适性,无法满足应用的需要.受到笔划滤波器的启发,Epstein等人[8]提出了一种有效描述文字的笔划宽度特征,称之为笔画宽度变化.该方法充分利用了局部区域文字的笔画宽度基本一致的原理,结合图像数据的局部特征,使得检测结果具有较大的改善,并且在ICDAR 2011文本定位竞赛中取得了优异的成绩.不过,原始的基于SWT的检测方法存在两个主要的问题:一是采用的Canny检测算子,对噪声会比较敏感,易产生梯度方向不规则的边缘像素,降低了笔画宽度提取的准确度;二是在复杂背景中(树枝、网格、人群等),较多的边缘信息易产生大量的虚警文字区域,在增加计算量的同时易造成文本区域的漏检;到目前,许多研究者针对原始SWT文本检测存在的不足开展了大量的改进性的工作.Yi等人[9]提出通过将SWT与颜色聚类的方法相结合来对文本区域进行提取,并利用高斯滤波以降低噪声的干扰,增加了SWT检测的召回率.但该方法存在大量经验参数的设置,具有一定的局限性.Yao等人[10]通过设计多层的文本与非文本分类器,并在笔画宽度的特征之中加入具有鲁棒的旋转不变特征,以弥补单一笔画宽度特征的不足,有效提高了SWT检测的准确率.Liu等人[11]提出利用最大稳定极值区域(MSER)与SWT相结合的方法,通过将笔画宽度的作用对象从原始图像转换到MSER标记的候选区域,在减少非文本因素的基础上结合SWT的方法,有效提升了SWT的检测效率.但当图像较模糊或低对比度时,基于MSER的方法无法准确的标记出候选区域,影响了后续的SWT检测.
本文提出了一种结合纹理背景抑制的笔画宽度变化的文本检测方法.主要工作体现在以下几点:通过在DCT域中采用Butterworth高通滤波与纹理特征结合进行背景抑制,能够在有效抑制背景的同时突出图像的文本区域,使得保留的区域具有良好的区分性;采用加权引导滤波的图像去噪技术,减少噪声对边缘检测的干扰;针对文本与非文本在笔画宽度以及边缘梯度上的差异,结合利用SVM分类的方法改善对非文本的滤除.基于ICDAR数据库的实验结果验证了本文方法的有效性.
1 相关工作
笔画宽度变换(SWT)是由Epshtein等人[8]根据同一区域的文本元素具有相同的笔画宽度而提出的一种文本检测方法.基于文献[8]SWT的方法简单描述如下,有关细节可参考原文献.先通过边缘检测算子提取图像的边缘,令其中一边缘像素点P的梯度方向为dp,从P出发沿射线r=p+n×dp(n>0)的方向寻找,直到找到另一个边缘像素点q,令其梯度方向为dp;若dp与dq方向相反且满足dq-dp±π/6,那么p与q则是笔画边缘上的匹配像素点,两点之间的距离通过欧氏距离来度量,将其表示为|p-q|.得到像素点之间的距离后,通过遍历整个区域,选取合适的距离作为笔画宽度,然后根据笔画宽度特性作为筛选条件,从而达到文本检测的目的.一般文本内部的笔画宽度以及结构比较相似,可以用笔画宽度进行表征.但是对于背景复杂度较高的图像,背景之间的笔画宽度与文本区域的笔画宽度也存在相似,通过SWT提取图像显得较为复杂,不能得到满意的检测效果.图1给出了不同背景复杂度的SWT提取结果比较,从图中可以看出,当图像背景较单一时,SWT可有效检测文本区域,但是当图像背景较复杂时,SWT检测中则出现了较多的干扰,从而一定程度上影响了后续的处理.

图1 不同背景复杂度的SWT提取结果比较Fig.1 The comparison of differentcomplexbackgroundSWT
2 提出的文本检测方法
本文提出了一种新的结合纹理背景抑制的笔画宽度变换自然场景文本检测方法,包括三个主要模块:1)结合DCT高通滤波与纹理特征的背景抑制;2)基于图像去噪的特征提取;3)基于SVM的非文本滤除.具体步骤如下.
(1)先通过对图像做离散余弦变换,划分出图像的高频与低频信息;然后利用Butterworth高通滤波器来滤除处于低频的背景,最后结合灰度共生矩阵来对图像纹理进行表征,利用有效的判别函数来保留潜在文本块;
(2)先对保留的区域采用加权引导滤波处理,然后在有效提取笔画宽度的基础上,分别对笔画宽度特征以及边缘梯度特征进行表征;
(3)利用连通域的形状以及纵横比启发式规则对文本候选区域进行初步过滤,结合SVM的分类方法来排除非文本,最后将保留的文本区域聚合成文本行输出.
2.1 结合DCT高通滤波与纹理特征的背景抑制
由于复杂背景中较多的边缘信息易对笔画宽度的提取造成干扰,因此通过将SWT的作用对象从原始图像转换到含有较少背景干扰的图像,可有效提升SWT检测的准确性.虽然文献[11]利用MSER的方法可实现将原始图像转换到含有较少背景的区域,其对于后续的SWT检测具有良好的增强效果.但是MSER标记的效果易受到图像模糊及低对比度的干扰,本文探讨一种结合DCT高通滤波与纹理特征的背景抑制方法,其好处在于能够在有效抑制背景的同时突出图像的文本区域,使得保留的区域具有良好的区分性.
(1)基于DCT的高通滤波.离散余弦变换(DCT)是由Ahmed等人[12]提出的一种变换压缩的方法.考虑到连续的背景在频域中呈现出低频的特性,本文先通过对图像进行离散余弦变换,以区分出低频的背景,然后采用高通滤波的方法来筛除这些背景.
首先给定输入图像为f(x,y),通过将图像转化为多个8×8的宏块,对每个宏块分别做DCT变换,进而得到变换后的图像G(u,v);经DCT变换后,低频信息集中在矩阵的左上角,高频信息则集中右下角,考虑到连续的背景在频域中呈现出低频的特性,通过高通滤波的方法可以滤除低频部分.由于图像的背景往往较为复杂,以往常用的理想高通滤波器存在的“振铃”现象会导致文本信息的漏检.与理想高通滤波器相比,Butterworth高通滤波器[13]振铃微小,并且具有灵活多变的滤波特性.这里采用Butterworth高通滤波器来实现图像的高通滤波,其传递函数如公式(1)所示:
(1)
其中ωε为截止频率,ωp为通频带边缘频率;最后通过反DCT变换得到滤波后的图像g(x,y),有g(x,y)=DCT-1[P(u,v)].图2给出了基于DCT的高通滤波流程图.

图2 基于DCT的高通滤波流程图Fig.2 Theflow chart with DCT high pass filter
(2)基于纹理特征的文本保留.灰度共生矩阵(GLCM)是由Haralick[14]提出的一种分析图像纹理的方法,由于它能够有效反映图像灰度在相邻方向的综合信息以及相同灰度级像素之间的位置分布特征,因而被广泛的应用于纹理特征的计算中.文献[14]提出利用GLCM提取了角二阶矩、对比度、逆差距等14种特征值来表述纹理,但全部考虑这些影响参数,存在较高的计算复杂度.文献[5]通过理论证明和实验分析得出上述特征值之间存在冗余,其中对比度和逆差矩这两个特征之间不相关,并且具有良好地分辨文本与非文本的能力.因此,本文通过利用对比度和逆差矩这两种特征值来描述文本的纹理特征,其好处在于在较低计算复杂度的条件下可有效保留潜在的文本区域.计算方法如公式(2)、(3)所示:
(2)
(3)
其中p(i,j;d,θ)表示在θ方向上,相隔距离d的一对像素分别具有灰度值i和j出现的概率,L表示图像的灰度集,R为归一化常数.对比度C反映了图像的清晰度和纹理沟纹深浅的程度.纹理沟纹越深,其对比度越大,视觉效果越清晰.逆差距H反映图像纹理的同质性,度量图像纹理局部变化的多少.逆差距越大则说明图像纹理的不同区域间缺少变化,局部非常均匀.根据其特性设定的阈值T1,T2作为判别条件(具体细节参见3.1实验参数设置),在特征向量Xi=[rmin,rmax,cmin,cmax,fj]上将每个块分成两类w1和w2,其中w1指的是含有文本的块,w2指的是不含文本的图像块,rmin,rmax,cmin,cmax行和列的最(小)大坐标.通过判别函数将文本块与非文本块分类出来后,将每个文本块Ci中的行和列中最大和最小的坐标保留到新的向量B中,最后将潜在的文本块Ci在行和列中连接起来形成,含有文本的区域ri.表1给出了具体结合纹理特征的背景抑制方法.

表1 结合纹理特征的背景抑制方法Tab.1 The method of joint texture background suppression
2.2 基于图像去噪的特征提取
尽管采用背景抑制的方法可降低复杂背景对SWT提取的干扰,但是由于SWT在提取边缘时采用的是Canny检测算子,其使用的一阶偏导有限差分对噪声会比较敏感.为了降低噪声的干扰,我们采用加权引导滤波[15]的方法对图像进行平滑处理,以有效抑制噪声的干扰.与传统方法相比,该方法在实时性和去除伪影等方面表现出了明显优势,通过结合局部窗口的方差信息,自适应地调整规整化因子,从而可以更好地降低噪声的干扰.
首先在以k为中心的窗口ωk中,通过求解加权引导滤波模型来得到滤波输出图像q,这里滤波模型表示为:
qi=akIi+bk,∀i∈ωk,
(4)
其中i为像素标签,I为引导图像,ak、bk为ωk中的常系数.由公式(4)可以看出,滤波模型的关键在于常系数的求解,而通常求解的方式是将其转化为最小化窗口的损失函数E,通过得到损失函数来实现常系数的计算,如式(5):
(5)
式中ε为正则化因子,用来防止系数ak过大,Γ为加权因子,规整化因子通过Γ的定义来实现.通过采用线性回归方法求解(5)得到ak,bk代入式(4)进而得到滤波后的输出图像q.
有了加权引导滤波的去噪处理,降低了噪声的干扰.增强了Canny算子边缘提取的有效性,在此基础上利用图像中的边缘像素,采用SWT在区域内做距离变换,计算并统计区域内像素点的欧式距离,通过遍历整个标记的区域,并由此得到原图像各像素的笔画宽度值映射.鉴于文献[8]中的笔画宽度具有良好的区分文本与非文本的特性,在这里首先根据笔画宽度变化系数来描述文本笔画宽度特征.
在笔画宽度图像中对每个连通区域求笔画宽度的平均值,根据变化系数SW来度量笔画宽度变化的大小,如公式(6)所示:

(6)
其中meanSW是指笔画宽度的平均值,N是指区域内的像素个数,xi是指区域内某一点像素的笔画宽度.SW越大,表明该区域中含有非文本的概率越大.一般来说,文本区域内的笔画宽度变化都会保持相对稳定即SW较小.
尽管笔画宽度可以较好的区分文本与非文本,但仅由单一的笔画宽度,无法充分地表征文本的局部特征[10].文献[16]研究发现场景文本区域的边缘存在大量的混合像素,这些混合像素的梯度幅值往往大于其它区域的像素,并通过实验证明了边缘方向的梯度具有良好的区分文本的特性.这里将边缘梯度特征引入,以弥补单一笔画宽度的不足.在Canny边缘提取的基础上,利用字符边缘的对称性,将边缘梯度特征定义为:
(7)
其中wi(r)表示区域r中第i类边缘像素点的个数.
2.3 基于SVM的非文本滤除
经过上述方法的处理,文本候选区域中仍然存在着一些非文本区域,需要进一步的将这些非文本进行排除,才能获得最终的文本定位.尽管文献[8]通过利用6种不同类型的先验信息滤除非文本取得了一定的效果,但该方法中含有大量的人工定义的规则以及经验参数,会产生一些漏检,影响最终的定位.为了减少人工参数的设置,本文通过在利用笔画宽度以及边缘梯度两种有效的特征的基础上,结合采用支持向量机(SVM)[17]的方法来改善对非文本的滤除.
在SVM分类前,先利用一些启发式规则对文本候选区域进行过滤,以去除明显不含有文本的区域,有了背景的有效抑制,这里仅采用连通域的形状以及纵横比来进行排除,最后利用SVM训练的模型得到最终的文本区域,采用形态学膨胀的方法聚合成文本行输出.
图3 给出了原始图像到最终文本定位过程中每个环节的效果图,从图中可以清晰地看出,在SVM分类器的作用下,通过有效地笔画宽度特征以及边缘梯度特征可以达到有效滤除非文本的效果,大大减少了经验参数的设置.

图3 文本定位效果图Fig.3 The results of text detection
3 实验结果与分析
为验证本文方法的有效性,以 Windows 7 操作系统、Matlab R2015b 为模拟实验平台,在ICDAR2003 数据库上实验,并将本文方法和其它相关算法[4,6,8,10,11]进行对比.
3.1 参数设置
实验中用到libsvm以及vl-feat两种开源数据包;将对比度和反差的判定条件阈值分别设定为T1=0.4,T2=50;将综合指数计算中的权系数a设置为0.5;从ICDAR2003训练集中选取了900个正样本和1400个负样本训练分类器.将所有正样本的标签记为1,负样本的标签为-1,提取样本的EHOG和SW特征并归一化.
3.2 基于ICDAR2003的实验
ICDAR2003数据库共由509幅场景图像组成,包含有258幅训练集图像和251幅测试集图像.这些场景图像涵盖了街道门牌、衣服商标、路牌等不同场景,以及不同大小、颜色和光照的水平排列的英文文本.采用信息检索系统中的准确率P和召回率R作为评价标准.对于文本检测,L为图像中原有的目标总数,E为正确估计目标的总数,m(j,E)是矩形j最佳的匹配,准确率P、召回率R以及综合测量值f分别表示为:
P=∑j∈Em(j,L)/|E|,
(8)
R=∑j∈Tm(j,E)/|L|,
(9)
(10)
其中准确率P表示正确检测的文本框个数与检测的总文本框个数的比值;召回率R表示正确检测的文本框个数与真实文本框总数的比值;系数f综合衡量了算法的回召率和准确率.
本次实验分别将纹理背景抑制方法以及整体的方法在ICDAR2003测试集上进行试验,选取其中具有代表性的指示牌、路标、房屋以及门牌等自然场景图像,实验结果如图4(b)、4(c)所示.从图4(b)中可以看出结合DCT高通滤波与纹理特征的方法能够有效地降低背景的干扰,突出潜在的文本块;从图4(c)中可以看出,当文本所处位置较附近复杂的场景存在一定对比时,本文方法取得了较好的检测效果.但是当背景和文本之间颜色极为为相近时或者文本尺度不一时,检测效果不太理想,如图4(c)最后一行所示.

图4 基于ICDAR文本检测效果示例Fig.4 The results of text detection based on ICDAR
将本文方法与其他相关算法[4,6,8,10,11]进行比较,实验结果如表2所示.从表2结果可以看出,与文献[8]相比,本文提出的方法在各项指数上均获得了较好提升,这是由于提出的背景抑制的方法有效抑制了背景的干扰,缩小了SWT的检测范围,增加了正确检测的总数量,从而使得召回率和综合指数有较大的提升.由于文献[8]是直接对原始的图像进行的SWT变换,其单幅图像处理的时间平均为0.72 s,而本文在处理过程中结合了背景抑制方法,其计算复杂度略有提升,处理时间为1.015s,综合来看,本文方法总体获得了最优效果.
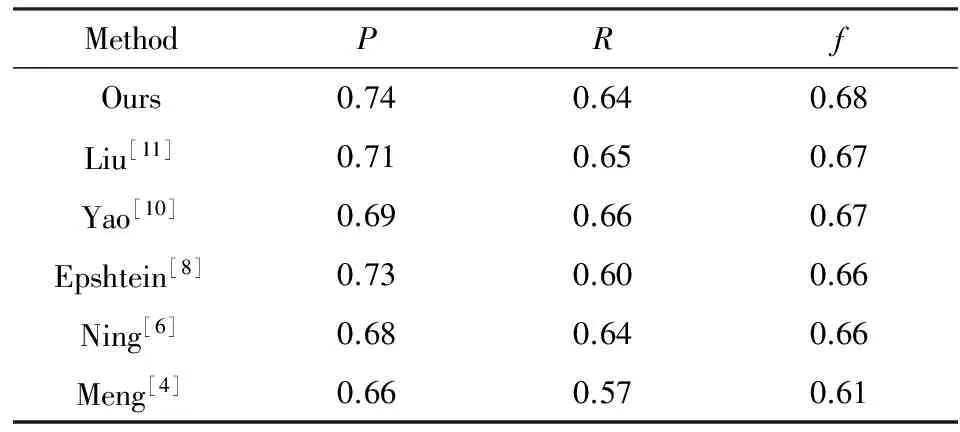
表2 几种检测算法的性能比较Tab.2 Performance comparison of different method
4 结语
针对复杂背景中存在的边缘信息与噪声干扰引起笔画宽度检测不准确的问题,提出了一种结合纹理背景抑制的笔画宽度变换文本检测方法.采用Butterworth高通并结合文本纹理特征,实现了在抑制背景的同时有效保留文本区域的信息.通过结合利用加权引导滤波的图像增强技术降低噪声对边缘检测的影响,文本图像的笔画宽度与边缘梯度信息得到更准确提取,从而有效提升了基于笔画宽度变换文本检测的性能.基于ICDAR数据库的实验结果验证了本文方法的有效性.但是当背景和文本之间颜色极为为相近时或者文本尺度不一时,检测效果不太理想,可作为进一步研究方向.
[1]Fragoso V, Gauglitz S, Zamora S, et al. TranslatAR: A mobile augmented reality translator[C]//IEEE.Applications of Computer Vision. New Jersey:IEEE Xplore, 2011:497-502.
[2]Merino-Gracia C, Lenc K, Mirmehdi M. A head-mounted device for recognizing text in natural scenes[C]//CDAR.International Conference on Camera-Based Document Analysis and Recognition. Berlin:Springer-Verlag, 2011:29-41.
[3]Shivakumara P, Phan T Q, Tan C L. Video text detection based on filters and edge features[C]// IEEE. International Conference on Multimedia and Expo. New Jersey:IEEE Press, 2009:514-517.
[4]Meng Q, Song Y. Text Detection in Natural Scenes with Salient Region[C]//IEEE.Iapr International Workshop on Document Analysis Systems. New Jersey:IEEE, 2012:384-388.
[5]Angadi S A, Kodabagi M M. Text region extraction from low resolution natural scene images using texture features[C]//IEEE.Advance Computing Conference.New Jersey:IEEE, 2010:121-128.
[6]宁仲, 唐雁, 张宏,等. 一种基于频域纹理特征的图像文字定位算法[J]. 四川大学学报(自然科学版), 2014,(02):306-312.
[7]Liu Q, Jung C, Kim S, et al. Stroke filter for text localization in video images[C]// IEEE. International Conference on Image Processing.New Jersey:IEEE, 2006:1473-1476.
[8]Epshtein B, Ofek E, Wexler Y. Detecting text in natural scenes with stroke width transform[C]//IEEE. Computer Vision and Pattern Recognition.New Jersey:IEEE, 2010:2963-2970.
[9]Yi C, Tian Y. Localizing text in scene images by boundary clustering, stroke segmentation, and string fragment classification[J]. IEEE Transactions on Image Processing, 2012, 21(9):4256-4268.
[10]Yao C. Detecting texts of arbitrary orientations in natural images[C]//IEEE.Computer Vision and Pattern Recognition. New Jersey:IEEE, 2012:1083-1090.
[11]刘亚亚, 于凤芹, 陈莹. 基于笔画宽度变换的场景文本定位[J]. 小型微型计算机系统, 2016, 37(2):350-353.
[12]Ahmed N, Natarajan T, Rao K R. Discrete Cosine Transfom[J]. IEEE Transactions on Computers, 1974, 23(1):90-93.
[13]侯洁, 辛云宏. 基于高通滤波和图像增强的红外小目标检测方法[J]. 红外技术, 2013, 35(5):279-284.
[14]Haralick R M. Texture features for image classification[J]. Systems Man & Cybernetics IEEE Transactions on, 1973, 3(6):610-621.
[15]Li Z, Zheng J, Zhu Z, et al. Weighted guided image filtering[J]. IEEE Transactions on Image Processing A Publication of the IEEE Signal Processing Society, 2015, 24(1):120-9.
[16]Li Y, Jia W, Shen C, et al. Characterness: An Indicator of Text in the Wild[J]. IEEE Transactions on Image Processing, 2014, 23(4):1666-1677.
[17]Kim K I, Jung K, Jin H K. Texture-based approach for text detection in images using support vector machines and continuously adaptive mean shift algorithm[J]. Pattern Analysis & Machine Intelligence IEEE Transactions on, 2003, 25(12):1631-1639.
