基于混合策略的藏文人称代词指代消解研究
2018-04-08夏吾吉华却才让
夏吾吉,华却才让
XIAWuji1,2,HUAQUE Cairang1
1.青海师范大学 藏文信息处理教育部重点实验室,西宁 810008
2.青海师范大学 民族师范学院,西宁 810008
1.Tibetan Information Processing Key Laboratory of Ministry of Education,Qinghai Normal University,Xining 810008,China
2.Normal College for Nationalities,Qinghai Normal University,Xining 810008,China
1 引言
指代是自然语言中一种复杂的语言现象,是文本处理和信息抽取不可或缺的重要组成部分[1],指代消解在文本处理和信息抽取中起着重要的作用,并已成为文本摘要、机器翻译、多语言信息处理、语义分析、问答系统等应用的关键问题[2]。近五十年来,国外对主流语言指代消解问题的研究比较深入,提出了各种消解方法[3],并且许多重要的会议都设立了指代消解的专题会议(比如:1997年的EACL、MUC和1999年的ACL等)[4]。随着网络和计算机技术的快速发展,近期国内研究者对中文指代消解问题的研究也取得了很大的进步,也有不少相关的研究论文和成果[5-10]。
以计算机科学技术为核心的信息化时代,在信息界的相关研究者对藏语言文字进行了分词、词性标注、命名实体识别[11]、词法分析、分句、句法分析等研究工作,对今后的藏文信息处理发展奠定了坚实的基础,而对藏文进行指代消解也是藏文通过分词标注和命名实体识别后需要解决的一项重要工作。目前还未见到对藏文进行指代消解的相关文献和报道。因此,本文将英文和中文的指代消解研究作为参考,采用规则、最大熵模型和规则与最大熵模型相结合等三种方法对藏文人称代词进行指代消解研究。
2 藏文人称代词的分类及识别
藏文中的人称代词同汉文一样有三种:第一人称代词、第二人称代词和第三人称代词,每个人称代词都有单复数之分,并且其表达方式丰富多样;根据藏文自身的特点和表达方式的多样性,在汉文中表示第一人称代词的单数“我”和复数“我们”,表示第二人称代词的单数“你(您)”和复数“你们(您们)”以及表示第三人称代词的单数“他、她”和复数“他们、她们”在藏文中分别可以表示成:“ བདག བདག ཁཁོ་བཁོ། རང་། བདག་ཉི གླིད། ང་ཚཚོ། ངཁྱེད་ཅག འཁོ་སྐོ ཁོལ། འུ ་ཅག འུ ་བུ ་ཅ ག ངཁྱེད་ ཚཚོ། བ ད ག ་ ཅ ག ”、“ ཁྱོ ཁོད ། ཁྱོ ཁྱེད། ཁྱོ ཁོད ་ ཉི གླིད ། ཁྱོ ཁྱེད་ ཉི གླིད ། ཁྱོ ཁོད ་ ར ང ་ ། ཁྱོ ཁོད ་ ཚཚོ། ཁྱོ ཁོད ་རང ་ཚཚོ།ཁྱོ ཁྱེད ་ ཚཚོ། ཁྱོ ཁྱེད ་ ར ང ་ ཚཚོ། ཁྱོ ཁྱེད ་ ཅ ག”以及“ཁཁོ། ཁཁོ་ མཁོ། ཁཁོ་རང ་། མཁོ་རང ་། མཁོ། ཁཁོ་ ཚཚོ། ཁཁོ་ར ང ་ཚཚོ།ཁཁོང་ཚཚོ། ཁཁོ་མཁོ་ཚཚོ། མཁོ་རང་ཚཚོ། ”等。
3 规则预处理
分词标注和命名实体识别是对代词进行指代消解的关键问题,本文针对表示同一人名实体的名词和代词进行分析,采取了三种特征属性和规则进行消解。
3.1 单复数属性
在藏文中,人称代词的单复数有很多种不同的表达形式:第一人称的单、复数形式“ང་(我)”和“ང་ཚཚོ(我们)”可以表示成“བདག ཁཁོ་བཁོ། རང་། བདག་ཉི གླིད། ང་ཚཚོ། ངཁྱེད་ཅག འཁོ་སྐོ ཁོལ། འུ ་ཅག འུ ་བུ ་ཅགངཁྱེད་ཚཚོ། བདག་ཅག”等,第二人称的单、复数形式“ཁྱོ ཁོད་དང་ཁྱོ ཁྱེད།(你和您)”和“ཁྱོ ཁོད་ཚཚོ་དང་ཁྱོ ཁྱེད་ཚཚོ། (你们和您们)”可以表示成“ཁྱོ ཁོད་ཉི གླིད།ཁྱོ ཁྱེད ་ ཉི གླིད ། ཁྱོ ཁོད ་ རང་། ཁྱོ ཁོད་ཚཚོ། ཁྱོ ཁོད་རང ་ཚཚོ། ཁྱོ ཁྱེད ་ཚཚོ། ཁྱོ ཁྱེད ་རང་ཚཚོ། ཁྱོ ཁྱེད་ཅག”等,第三人称的单、复数形式“ཁཁོ་དང་ཁཁོ་མཁོ། (他和她)”和“ཁཁོ་ཚཚོ་དང་ཁཁོ་མཁོ་ཚཚོ། (他们和她们)”可以表示成“ཁཁོ་རང་། མཁོ་རང་། མཁོ། ཁཁོ་ཚཚོ། ཁཁོ་རང་ཚཚོ། ཁཁོ་མཁོ་ཚཚོ། མཁོ་རང་ཚཚོ། ཁཁོང་ཚཚོ། ”等;在藏语语法中,名词和代词所对应的单复数有非常严格的要求,具体如下。
3.1.1名词短语作主语的情况
若主语是由几个单一名词通过连接词“དང(་和)”连接而成的名词短语时,对应的代词为复数。比如:“བསཁོད་ན མས་ ད ང་ བཀྲ ་ ཤི གླིས་ ག ཉི གླིས་ སློ ཁོབ་ གྲོ ཁོགས་ཡགླིན ་ ལ། ཁཁོ་ ཚཚོ་ ཡགླི་ འ བྲེ ཁྱེལ་ བ ་ ཧ ་ ཅང ་ བ ཟ ང་། ”,其 中“ ཁཁོ་ཚཚོ”是复数,指代的是“བསཁོད་ནམས་དང་བཀྲ ་ཤི གླིས”。
3.1.2名词作主语的情况
(1)若主语为单独的人名时,对应的代词为单数。比 如 :“བཟ ང་མཁོ་ནགླི་ ངཁྱེད་འཛཛིན ་ གྲྭ འགླི་སློ ཁོབ ་ མ ་ ཡགླིན ་ ལ། ཁཁོ་ མཁོ་སློ ཁོབ་ སྦྱོ ཁོང་ལ ་ ཤི གླིན་ཏུ ་བཟ ང་། ”,其 中“ཁཁོ་མཁོ”是单数,指代的是“བཟང་མཁོ”。
(2)若主语为表示人的群体的单一名词+“རྣམས། ཚཚོ།དག”等数词时,对应的代词为复数。比如:“ཚན་རགླིག་པ་རྣ མས་ནགླི་འཛམ་གླི གླིང་འཕཁྱེལ་རྒྱ ས་ཐད་ ལ་བྱ ས་རྗེ ཁྱེས་བླ ་མཁྱེད ་འཇོ ཁོག་མཁན་ཡགླིན་པས། ཁཁོ་ཚཚོ་ནགླི་མགླིའགླི་རགླིགས་ཀྱ གླི་མགླིག་ད པཁྱེར་གྱུ ར་ཡཁོད་པ་རཁྱེད། ”,其中“ཁཁོ་ཚཚོ”是复数,指代的是“ཚན་རགླིག་པ་རྣ མས”。
根据上述可以看出,在藏语中人称代词的单复数有着很严格的界限,即表示单、复数的名词一定与表示单、复数的代词一一对应,因此命名实体和人称代词的单复数一致性作为代词消解的条件,并对单复数属性制定以下规则。
规则1若人称代词是单数,则找到表示单独人名的名词;若人称代词是复数,则找到连接词“དང་(和)”连接而成的名词短语或表示人的群体的单一名词+“རྣ མས། ཚཚོ།དག”等数词的命名实体;否则不予消解。
3.2 性别属性
无论是藏语、汉语还是英语在表达上对人名都有性别之分,藏语中用“ཁཁོ(他)”表示男性,用“ཁཁོ་མཁོ或མཁོ(她)”表示女性;在汉语和英语中的用法也相类似,用“他(he)”表示男性,用“她(she)”表示女性,用“它(it)”表示不知性别的人或物。在藏语中人名的结构成分复杂多样,最短两个音节和最长八九个音节及其以上,比如:“རྡོ ཁོ་རྗེ ཁྱེ”、“པཎ་ཆེ ཁྱེན་ཨཁྱེར་ཏི གླི་ནགླི་ཆེ ཁོས་ཀྱ གླི་རྒྱ ལ་མཚན”。通过对安多藏区典型的常用人名进行搜集,除了宗教人士以外的人名大部分都是由二到四个音节组成,并且性别有明显的界限区分,在两个音节组成的藏语人名是从自身可以区分性别的,一般像“རྒྱ ་མཚཚོ། བཀྲ ་ཤི གླིས། ཕུ ན་ཚཚོགས། ”等都是典型的男性名字,而“སྒྲོ ཁོལ་མ། ཆེ ཁོས་སྒྲོ ཁོན། ལྷ ་མཁོ། ”等都是典型的女性名字;三个音节组成的藏语人名由最后一个音节来区分性别,最后的音节为“འབུམ།སྐྱ བས། ”等的是属于男性名字,最后的音节为“མཚཚོ། སྐྱགླིད། ”等的是属于女性名字,而最后的音节为“རྒྱལ། བྱམས། མཁར། ”等是属于不知性别的人的名字;四个音节组成的藏语人名由后两个音节来区分性别,后两个音节为“དཁོན་འགྲུ བ། ཚཚེ་བརྟ ན།འཁོད་ཟཁྱེར། ”等的是属于男性名字,后两个音节为“བདཁྱེ་སྐྱ གླིད། བཟང་མཁོ། མཚཚོ་མཁོ། ”等的是属于女性名字,而后两个音节为“ཚཚེ་རགླིང་། ”等的是属于不知性别的人的名字。不知性别的主要由其前面的音节来区分性别,如果其前面的音节是两个音节组成的典型的男性名字,则属于男性,否则就属于女性(本文针对除了宗教人士以外的安多藏区常用人名以及所对应的代词进行指代消解)。
根据上述可以看出,由“ཁཁོ(他)”和“ཁཁོ་ཚཚོ(他们)”来指代人名为男性的命名实体,而“ཁཁོ་མཁོ(她)”和“ཁཁོ་མཁོ་ཚཚོ(她们)”来指代人名为女性的命名实体。
规则2若人称代词为“ཁཁོ(他)”和“ཁཁོ་ཚཚོ(他们)”,则找到表示男性的人名进行消解;若人称代词为“ཁཁོ་མཁོ(她)”和“ཁཁོ་མཁོ་ཚཚོ(她们)”,则找到表示女性的人名进行消解;否则不予消解。
3.3 距离属性
在语言学中用代词来指代前文内容的现象是很常见的,但代词在指代命名实体时对不同句子指代的距离值不同[12],通过对大量的藏文语料和各种类型的句子分析发现,代词所指代的内容一般都是离代词很近的内容,而且距离值越小的句子内容越容易看懂,被代词指代的概率也就越大。根据上述可以对距离属性制定以下规则。
规则3本文将指代的距离限制在小于等于4的范围内,并且距离值越小时命名实体被指代时的权重就越大[13]。
具体的消解流程如图1所示。
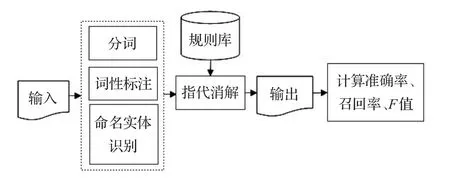
图1 基于规则的指代消解流程图
图1中,运用青海师范大学分词标注工具,对包含2 306个待消解对的藏文句子集进行了分词、词性标注,并采用文献[11]的命名实体识别方法对藏文句子中的命名实体进行自动识别后,对分词标注和命名实体识别错误部分进行了手动修改,最后通过上述三种规则对句子中的人称代词进行了指代消解。
4 基于最大熵模型的指代消解
最大熵模型的基本思想是只掌握关于未知分布部分信息的前提下,选取符合这些信息且熵值最大的概率分布[14]。在最大熵模型训练中,信息一般是以特征的形式进行表达,假设存在n个特征 fi()i=1,2,…,n ,那么定义{0,1}域上一个二值函数来表示一个特征:
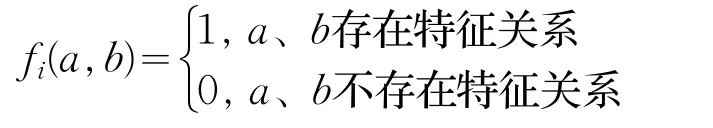
对于每一个特征F(a,b),模型P的熵函数为:
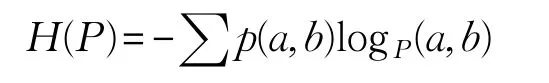
其条件概率的最大熵模型为:
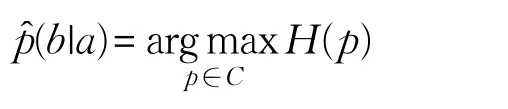
其中C表示满足限制条件下的模型集合。
对于藏文人称代词的指代消解,最大熵模型训练是可以通过 p(b|a)的计算来判断待消解对(a1,a2)是否指向同一实体,其中,a为特征向量,是通过对待消解对(a1,a2)的特征属性进行比较而得到的,a1表示候选先行词,即名词、命名实体和名词短语;a2表示代词,是一个二值属性,若待消解对(a1,a2)指向同一实体,则F值等于1,否则等于0。p(b|a)表示特征向量a条件下计算指向同一实体的条件概率[15]。
通过大规模的相关藏文文本语料以及对藏文的语法和句法进行分析发现,在藏文中指代同一实体的候选先行词(名词、命名实体和名词短语)和代词具有三种相同的特征属性。
4.1 单复数一致性
该属性是个二值函数,对两个待消解项的单复数属性值进行比较,若两个属性值一致,则其特征值为1;否则为0。

以上函数中,a表示测试语料中的候选先行词,b表示测试语料中的代词。例如:(1)“བཟང་མཁོ་/nrནགླི་/uuངཁྱེད་/rrའཛཛིན ་གྲྭ /ntའགླི་/gzསློ ཁོབ་མ་/nnཡགླིན ་/upལ/gl། ཁཁོ་མཁོ་/rrསློ ཁོབ་སྦྱོ ཁོང་/nvལ ་/glཤི གླིན་ཏུ ་/dcབཟང་/ad། ”;(2)“བསཁོད་ནམས་/nrདང་/cdབཀྲ ་ཤི གླིས་/nrགཉི གླིས་/mjསློ ཁོབ་གྲོ ཁོགས་/nnཡགླིན་/upལ/gl། ཁཁོ་ཚཚོ་/rrཡགླི་/gzའབྲེ ཁྱེལ་བ་/nnཧ་ཅང་/dcབཟང་/ad། ”。经过规则预处理以上两个句子(1)、(2)中可以提取候选先行词和待消解的词对有:(བཟང་མཁོ། ,ཁཁོ་མཁོ། )和(བསཁོད་ནམས་དང་བཀྲ ་ཤི གླིས། ,ཁཁོ་ཚཚོ། ),其中(བཟང་མཁོ། ,ཁཁོ་མཁོ། )的属性值相同(都属于单数),所以其函数值为 F1(བཟང་མཁོ། ,ཁཁོ་མཁོ། )=1,(བསཁོད་ནམས་དང་བཀྲ ་ཤི གླིས། ,ཁཁོ་ཚཚོ། )的属性值相同(都属于复数),因此其函数值为 F1(བསཁོད་ནམས་དང་བཀྲ ་ཤི གླིས། ,ཁཁོ་ཚཚོ། )=1。
4.2 性别一致性
该属性是个二值函数,对两个待消解项的性别属性值进行比较,若两个待消解项的性别一致,则其特征值为1;否则为0。

比如,4.1节中的句子(1)经过规则预处理后发现其中的待消解对(བཟང་མཁོ། ,ཁཁོ་མཁོ། )的性别一致(都属于女性),因此其函数值为 F2(བཟང་མཁོ། ,ཁཁོ་མཁོ། )=1。
4.3 距离属性
该属性是个多值函数,对两个待消解项的文本距离进行考查,其取值为它们所属句子的编号之差的绝对值。根据上一章的规则集(3.3节中的规则3),本文将指代的距离限制在小于等于4的范围内。因此,若两个待消解项处在同一句中,则其特征值为4;若它们之间相差一句,则其特征值为3;若它们之间相差两句,则其特征值为2;若它们之间相差三句,则其特征值为1;否则为0。

例如:“བསཁོད་ནམས་/nrལ་/glན་བསྲ ན་/nnམཁྱེད་པ/upས་/gxང/rrས་/gxརྒྱུ ན་པ/nnར་/glཁཁོ་/rrལ་/glཐུ བ་ཚཚོད་/nnབྱ ས/ux། lzབཙན་ཚུ གས/nnཀྱ གླིས/gxཁཁོ/rrར་/glང/rrལ/glཕུ ་ བཁོ/nn ཞེ ཁྱེས/rzའ བཁོད/vtདུ ་/glབ ཅུ ག/vtཉི གླིན ་/ttཞེ གླིག ་/mjལ ་/glཁཁོ/rrའགླི་/gzཨ ་ མ/nnས་/gxང་/rrལ་/glཁ་/nnཅགླི་ཡང་/ryམགླི་/dfགྲོ ག་པ/viར་/glཁུ ་ཚུ ར་/nnགྱི གླིས་/gxབརྡུ ངས/vt། lz ཁཁོ/rrའགླི་/gzཨ་ཕ/nnས་/gxཀྱ ང་/cjང་/rrལ་/glསྡི གླིག་དམཁོད་/nvབྱ ས/vt། lz”经过规则与处理,在本例中提取的候选先行词和待消解的词对及其函数值分别为:F4-1(བསཁོད་ནམས།,第一句中的ཁཁོ)=4,F4-2(བསཁོད་ནམས།,第二句中的ཁཁོ)=3,F4-3(བསཁོད་ནམས།,第三句中的ཁཁོ)=2,F4-4(བསཁོད་ནམས།,第四句中的ཁཁོ)=1。
根据以上特征,具体的消解流程如图2所示。
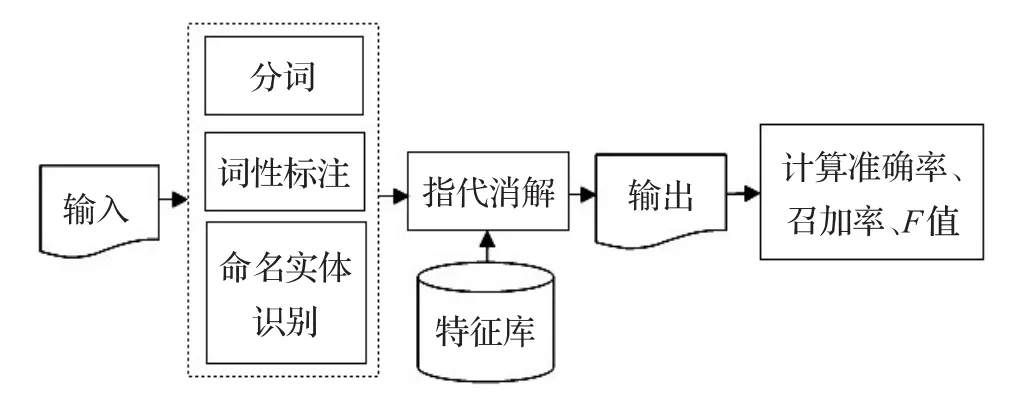
图2 基于统计的指代消解流程
5 基于混合策略的指代消解流程
本文所使用的混合策略方法是规则和最大熵模型相结合的方法,首先对语料进行分词、词性标注、命名实体识别后对代词进行过滤,找出能够用规则的方法进行消解的代词并进行消解;如果在消解后的语料中出现没有进行指代消解的名词和代词,将把它们提取出来组成待消解对候选集,再利用统计的方法进行消解。具体流程如图3所示。
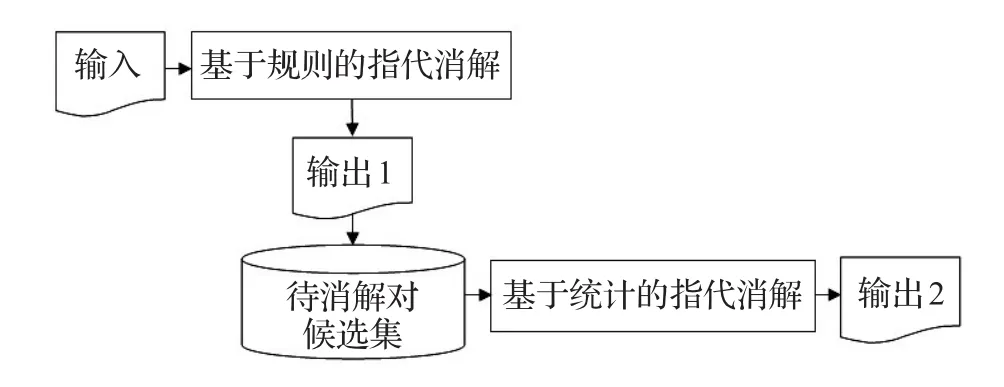
图3 混合策略的指代消解流程图
从图3中可以看到,基于混合策略的方法主要有规则预处理、代词过滤、基于规则的消解和基于统计的消解等四部分。
6 实验
本文的训练语料和测试语料取材于藏文小说、新闻、童话等。对这些取材进行切分标注和命名实体后,经手动修改其中出现错误的切分标注,精选了包含2 306个待消解对的藏文句子进行测试,并采用了自然语言处理中常用的三个评测指标:准确率(P)、召回率(R)和F值进行实验分析。各个指标的定义如下:


其中,w是召回率和准确率的相对权重,本文中w取为0.5。实验结果如表1、表2所示。
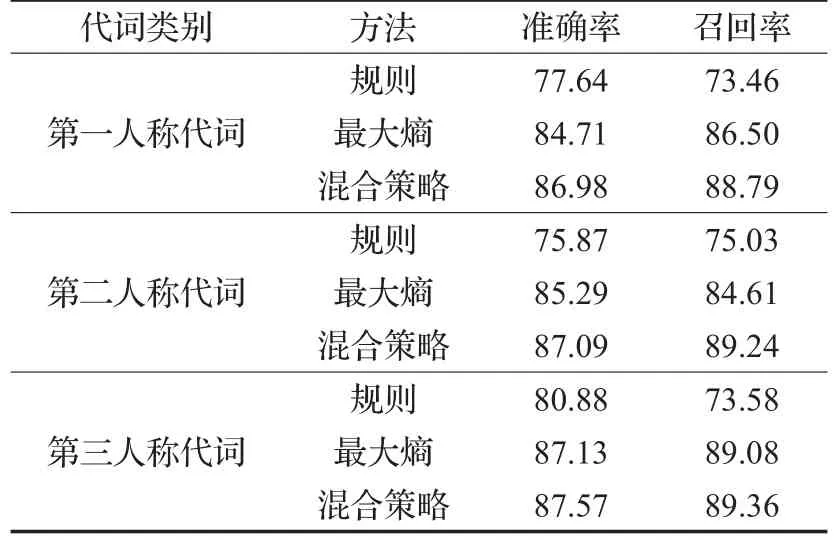
表1 三个人称代词实验结果对比%

表2 三种方法的实验结果对比 %
实验结果表明,基于规则、统计和规则与统计相结合的方法对藏文人称代词指代消解研究的效果较好,但仍然未能达到很理想的效果,主要原因有两方面。一方面,如果在一个句子当中出现两种不同的人称代词,而只有一个人名,比如 4.3 节中的藏文句子“བསཁོད་ནམས་/nrལ་/glན་བསྲ ན་/nnམཁྱེད་པ/upས་/gxང/rrས་/gxརྒྱུ ན་པ/nnར་/glཁཁོ་/rrལ་/glཐུ བ་ཚཚོད་/nnབྱ ས/ux ། lzབ ཙ ན ་ ཚུ ག ས/nn ཀྱ གླིས/gx ཁཁོ/rrར ་/glང/rrལ/glཕུ ་ བཁོ/nn ཞེ ཁྱེས/rzའ བཁོད/vtདུ ་/glབཅུ ག/vt ཉི གླིན་/ttཞེ གླིག་/mjལ་/glཁཁོ/rrའགླི་/gzཨ་མ/nnས་/gxང་/rrལ་/glཁ་/nnཅགླི་ཡང་/ryམགླི་/dfགྲོ ག་པ/viར་/glཁུ ་ཚུ ར་/nnགྱི གླིས་/gxབ རྡུ ང ས/vt། lz ཁཁོ/rrའགླི་/gzཨ་ཕ/nnས ་/gxཀྱ ང་/cjང་/rrལ་/glསྡི གླིག་དམཁོད་/nvབྱ ས/vt། lz”中人名只有“བསཁོད་ནམས་/nr”一个,而人称代词有第一人称代词“ང/rr”和第三人称代词“ཁཁོ/rr”两种,因此在消解过程中人称代词未能正确找出所对应的人名,导致消解错误。另一方面,藏文复数形式的人称代词不仅形式复杂多样,而且指代情况千差万别,导致在指代过程复杂多变,影响了实验结果。
7 结语
本文根据藏族人名和藏文人称代词的构词规律和形态特征,制定了三类消解规则,并设计了相应的统计特征,最后采用基于规则、最大熵和规则与最大熵模型相结合的方法研究了藏文人称代词指代消解。经实验,对于藏文人称代词指代消解研究问题,采用基于混合策略(规则和最大熵模型相结合)的方法为较好的一种消解方法,基于最大熵模型的方法为其次,基于规则的方法相对差一些。后续工作中,将借助于藏语句法和藏语语义的研究,分析影响实验结果的复数形式人称代词,以改善指代消解任务。
参考文献:
[1]Morton T S.Coreference for NLP applications[C]//Proc of ACL,2000:173-180.
[2] 孔芳,周国栋.指代消解综述[J].计算机工程,2010,36(8):33-36.
[3]王厚峰.指代消解的基本方法和实现技术[J].中文信息学报,2002,16(6):9-17.
[4]王海东,胡乃全.指代消解中语义角色特征的研究[J].中文信息学报,2009,23(1):23-29.
[5]孔祥勇,张冬茉.一种信息抽取系统中汉语指代消解算法[J].计算机工程,2003,29(16):76-78.
[6]周俊生,黄书剑.一种基于图划分的无监督汉语指代消解算法[J].中文信息学报,2007,21(2):76-82.
[7]金可佳.统计与规则相结合的指代消解[D].武汉:武汉科技大学,2009.
[8]孔芳,朱巧明,周国栋.中英文指代消解中待消解项识别的研究[J].计算机研究与发展,2012(5):1072-1085.
[9]奚雪峰,周国栋.基于Deep Learning的代词指代消解[J].北京大学学报:自然科学版,2014,50(1):100-109.
[10]周炫余,刘娟,罗飞,等.中文指代消解模型的对比研究[J].计算机科学,2016,43(2):31-34.
[11]华却才让,姜文斌,赵海兴,等.基于感知机模型藏文命名实体识别[J].计算机工程与应用,2014,50(15):172-176.
[12]张文艳,李存华.结合规则与语义的中文人称代词指代消解[J].数据采集与处理,2017,32(1):149-156.
[13]李国臣,罗云飞.采用优先选择策略的中文人称代词的指代消解[J].中文信息学报,2005,19(4):24-30.
[14]宗成庆.统计自然语言处理[M].2版.北京:清华大学出版社,2013:122-124.
[15]钟丹,朱倩,李梅,等.人称名词短语单复数信息和最大熵模型的指代消解[J].江南大学学报:自然科学版,2009,8(6):666-669.
