图松弛优化聚类的快速近似提升方法*
2018-04-08王士同
谢 磊,王士同
江南大学 数字媒体学院,江苏 无锡 214122
1 引言
聚类是数据挖掘、统计机器学习和科学发现的首要问题。在过去几十年中,已经开发了各种各样的方法来解决聚类问题[1-4]。例如在完成一些图像分割任务时,其中的数据聚类问题便是通过高阶相关聚类[5]来解决。作为解决NP-hard组合优化问题的替代方案,半定规划松弛被提出。基于半定规划松弛的方法相比于光谱/特征向量方法具有一定优势[6-7],因为该方法的附加约束迫使优化过程找到效果更好的解决方案。然而,这一约束也带来了很大的负面效果:迭代终止标准对聚类结果有显著影响。与之相比,基于图松弛优化聚类(graph-based relaxed clustering,GRC)[8]算法表现出很好效果。通过归一化剪切改进[6]中引入的归一化目标,简化了计算,使得聚类任务可以作为二次规划解决。聚类效果在处理复杂的集群时有所改善,且实现也非常简单。
虽然GRC算法有许多优点,但其并不能和经典算法相媲美,例如层次聚类以及k-means算法,它们都在大规模数据挖掘中得到很好的应用。原因很简单,此算法由于计算矩阵的逆会消耗多项式计算时间,在计算高维大数据时会显得非常吃力甚至不可行。
本文主要专注于设计对GRC算法的快速近似改进算法,即主要对GRC算法做速度提升。正如在涉及计算瓶颈的数据挖掘中的许多情况一样,本文的目标是找到一种有效的预处理器,减少输入到该瓶颈的数据结构的大小(参见文献[9-10])。此预处理步骤可以考虑许多方式,例如,可以对数据进行多种形式的二次采样,随机选择数据点或根据某种形式进行分层选取。另一个选择是用少量点(即“代表点”)替换原始数据集,目的是捕获数据相关结构。本文主要提供了两个这样的预处理方式。第一个是将k-means应用于对初始数据的缩减步骤,第二个是使用文献[11]中的随机投影树(random projection tree,RPTree)。实验显示,通过这两种预处理,弥补了GRC算法的不足,尤其在速度方面有显著改进。同样,在处理一些较大规模数据时性能得到了提高。
2 相关准备
2.1 GRC算法
给定n个数据点X1,X2,…,Xn,每个Xi∈Rd。令邻接图G=(V,E)定义为无向图,其中第i个顶点对应于数据点Xi。对于每个边缘(i,j)∈E,本文用权重aij来表示数据点Xi和Xj的亲和度(或相似度)。并将矩阵作为邻接矩阵。
GRC算法的目的同样是将数据分为多个类,使得每一数据样本属于且仅属于某一类。各种聚类算法用不同的方式将这种分割问题形式化。作为解决NP-hard组合优化问题的一个替代方案,文献[12]提出了半定规划松弛方法。同样的,Lee等人在文献[8]中提出了基于图松弛优化算法,需要注意的是,其中归一化剪切(normalized cut,NC)[13]被宽限到广义特征值系统:

其中e′=(1,1,…,1),L=D-A作为拉普拉斯矩阵。e的维度为数据点的数目,D、A分别为图的度矩阵和邻接矩阵。
式(1)中的两个约束将最优解限制在二进制分区上。为了克服这个短缺,Lee等人进一步松弛式(1)得:

其中Q=e′,ζ为常数,这就是所谓的GRC算法。式(2)是它的二次规划(quadratic programming,QP)形式。作者通过使用拉格朗日乘数法又进一步将其简化为如下形式:

本文聚类问题的优化以封闭形式求解,无需任何迭代即可找到L的特征属性。但如果L是半正定,会出现一些问题,所以通过在L中的对角线项添加正值α来近似替代L,以此来保证L是正定的。当然,在式(3)之前还可以根据对数据的了解做更多约束条件,增强对聚类的区分。通过y,可以很容易地知道有多少个聚类存在,直观地区分它们。为了最后方便对比,可以对y进行k-means运算得到比较统一的聚类标签。可见,GRC算法是自适应的(即它不需要预先设定聚类的数量)和直接的(即所有聚类的区分可以仅通过一次单一的计算完成)。但是此方法在计算矩阵的逆时,消耗多项式时间,不难想象,随着数据量的增多,矩阵维度的增大,时间消耗将逐渐变得不可接受。因此,在下节将给出快速近似提升方面的内容。
关于GRC算法具体过程详解如下所示。需要注意的是,在σ的选值方面,不同数据集则选值不同,一般可对各维度计算标准差后求均值得出。本文方法则是在循环计算每一维度时,根据所得数据实时运算求出标准差。
算法1基于图松弛优化(GRC)算法
输入:n个数据点
输出:输入数据的簇标记。
1.计算出邻接矩阵A:

2.2 快速近似方法介绍
文献[17]巧妙地选择以与其规范成比例的值对Gram矩阵的列进行采样的方案,从而代替均匀采样这一步骤。因为这对Gram矩阵在近似误差的约束上做出让步,所以该方法可能需要选择较多的列以实现较小的近似误差。其误差界限可由如下公式表示:
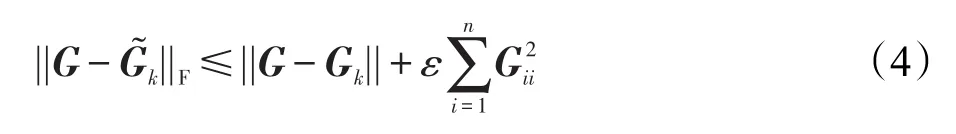
其中,Gk是G秩为k的最佳近似,这形成了用于近似Gram矩阵的约束。由于来自G的数量为n的采样列,数量级为且该算法具有级的计算复杂度。从式(4)的右侧可看出,为了获得较小的近似误差则需要非常小的ε,这也使得将要选择的行数变大。例如,当使用高斯内核时会按照O(n)的量级增长,因此预期采样列数为O(n)。本文的快速近似方法则做了相对改进,避免像Nyström方法的较高内存需求,且在处理平衡性较低的数据集时,因较小聚类被遗漏所导致的数值稳定性问题也得到较好解决。
3 GRC算法的快速近似改进
本章将介绍对GRC算法的快速近似提升的算法框架。对于这一算法的改进,重点放在其建立邻接矩阵和矩阵求逆的时间优化上。对于此问题的解决,最为直接有效的方式便是通过缩小数据量来实现。文中算法主要是由预处理步骤和GRC算法步骤组成。根据GRC算法输出的错误聚类率与输入失真之间的量化关系,便可在执行GRC算法之前,选取合适的预处理方式,使得调用原始数据的失真最小化。本文给出两种处理方法:第一种是基于k-means的数据预处理方式,第二种则基于RPTree。此外,这两种方式主要具有有利的计算性质和实现简单等优点。算法过程可简单概括为图1所示。
3.1 k-means对GRC算法的快速提升
矢量量化是为了在最小化失真度量的情况下,选出表示数据集的最佳代表点集合[22]。当失真测量使用均方误差时,矢量量化中最常用的算法是kmeans,因其具有理论支持以及简单等多方面的优点。k-means算法采用迭代过程,在每次迭代时,算法将每个数据点分配给最近的质心,并重新计算聚类质心。当均方误差的总和稳定时,则程序停止,以此可得到很好的聚类中心作为数据代表点。使用kmeans作为聚类的预处理器,选出数据代表点来进行之后的GRC运算。以此,提出了一种“基于k-means的快速近似GRC算法”(KAGRC)算法。算法过程如下所示。
算法2KAGRC:(x1,x2,…,xn,k)
输入:n个数据点k个代表点。
2017年,我国甘薯总产量7 057.1万t,按照55%的加工比例和20%的产品原料比,当年我国甘薯加工品产量约为780万t.戴起伟等[5]估算结果显示,当前我国国内甘薯加工产品消费量约在500万t以上,因此,粗略估算,我国甘薯加工品的年出口水平应在200~280万t之间.
输出:输入数据的聚类标签label。
1.将x1,x2,…,xn数据类别定义为k,进行k-means计算。
(1)计算得出的聚类中心为y1,y2,…,yk,将其作为k个代表点。
(2)构建一个对应表,将每个xi与最近的聚类质心yi相关联。
2.对聚类质心y1,y2,…,yk进行GRC算法运算,从而得到每一yi对应的聚类簇标记y,于是可直观得到聚类情况,了解聚类数目以及大体数量。
3.通过建立的对应表以及yi对应的聚类簇标记得到每一xi所对应的聚类簇标记label。
在KAGRC算法中,第一步k-means的计算复杂度是O(knt),其中t表示迭代次数。第二步的复杂度不小于O(k3),第三步复杂度为O(n),则可知KAGRC的复杂度为O(k3)+O(knt)。
3.2 RPTree对GRC算法的快速提升
在这一方法中,则是用RPTree对k-means进行替代,即通过随机投影这一方式来减少失真[11]。RPTree给出了数据空间的分区,分区的每个单元格中的中心点作为该单元格中大量数据点的代表点。RPTree是基于k维树(k-dimensional tree,k-d树)的,这种空间数据结构[23]是通过每次沿着一个坐标递归地分割数据空间所得到,并非沿着坐标方向分割,其根据选择的方向进行随机投影分割。当前单元格中的所有点都沿随机方向投影,然后被分割开来。虽然古典kd树由于对轴平行分裂的限制而缩小了数据空间的维度,但RPTree在处理数据的固有维度方面更加适合,故使用RPTree作为局部失真最小化变换不失为一种不错的选择。由此可见,本文的第二种算法将KAGRC算法的步骤1替换为如下的部分内容:
在x1,x2,…,xn上构建一个h级随机投影树;将各单元格中数据点的质心y1,y2,…,yk作为k个代表点。
得到本文的第二种改进算法“基于RPTree的快速近似GRC算法”(RAGRC)。
该算法的时间消耗主要是RPTree在进行数据预处理时的建树部分以及GRC部分,算法的复杂度为O(k3)+O(hn),其中O(hn)是建立h级随机投影树所需的复杂度。
至此,以上内容即为本文算法的主要内容,首先通过k-means或者RPTree对原始数据进行预处理,再通过GRC算法对预处理所得的代表点进行聚类,之后再映射到各点,从而得到数据标签的快速近似提升方法。
4 实验分析
实验中,主要使用两个量来评估聚类性能:运行时间,以及通过每个数据集的真实簇标记和算法所得簇标记计算出的聚类精度。运行时间即对某一数据集运行一次聚类算法所用时间(在此使用计算机时间)。则在同样数据集及环境的情况下,耗时越短且聚类精度越高表明算法性能越好。聚类精度的计算方法很多,本文采用较为通俗的做法,这里需要搜索类的排列,则可令表示类情况,和分别表示数据点的真实簇标记和采用聚类算法后所得簇标记。可用公式将聚类精度β定义为:
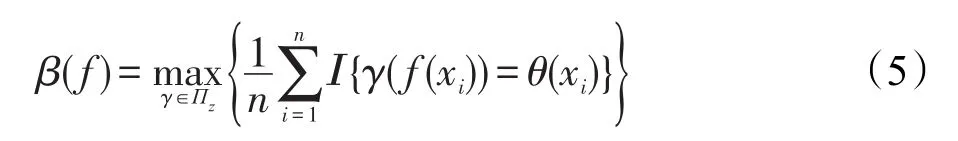
其中,Ι表示指标函数;Πz是z上的所有置换集合。考虑到当聚类数量较多时,式(5)在计算方面受到限制,在这种情况下,从集合Πz中采样,逐一计算后取出最佳结果使之作为β的最终估计值。在实验中,如果k<8,穷举Πz,否则就从中取10 000个样例。
4.1 实验平台及数据集
本文实验中,所有实验均使用单一机器作为实验平台,同时保证CPU在进行运算时,严格控制其他程序对其资源的消耗。实验平台的详细信息如表1所示。本文共9个实验数据集,分别为5个人造平面数据集DS1、DS2、DS3、DS4、DS5以及4个选自UCI(http://archive.ics.uci.edu/ml/datasets.html)的复杂数据集 mGamma、musk、sensorreadings和 PokerHand。数据集的具体信息如表2所示。需要说明的是,PokerHand数据集由10个类别组成,共有100万个实例。然而,原始数据集是非常不平衡,其中有6类的总量少于总样本的1%。本文将较小类别合并在一起,同时保持其中较大类别不变。操作之后,数据集共分为3类,分别对应于样本总数的50.12%,42.25%和7.63%。

Table 1 Experimental platform表1 实验平台

Table 2 Experimental datasets表2 数据集
4.2 速度提升实验
本节将使用人造数据集DS1、DS2、DS3、DS4,DS5来进行实验。需要注意的是,本节用到的5个数据集为了在时间上形成对比,都采取了较多数据点。此外,为了证明算法的普遍适用性,这些数据集也具有不同聚类形式,从简单到复杂,覆盖面较为广泛,选取具有代表性。
首先,图2~图6给出了原图及运行GRC算法后和KAGRC算法后的图解。
从图中可以看出,相对于GRC算法,KAGRC算法对于各种图形数据集聚类的效果都非常好。在运行KAGRC算法时,其所对应的缩减率γ为1/8,即各数据集的代表点k为3 750、812、1 250、750和525,其运行时间分别为12 s、0.8 s、1.3 s、0.7 s和0.5 s。相对于直接使用GRC的259 s、8 s、28 s、6.4 s和3 s,速度都有显著提升。本文实验具体的情况如表3至表7所示。
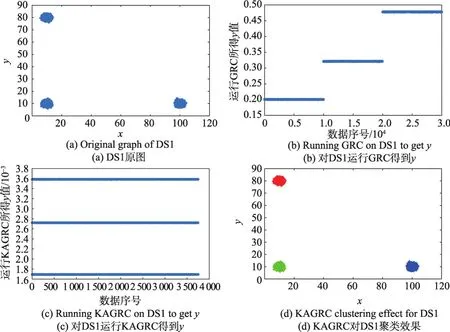
Fig.2 Original graph and experimental graph of DS1图2 DS1原图及实验图

Fig.3 Original graph and experimental graph of DS2图3 DS2原图及实验图

Fig.4 Original graph and experimental graph of DS3图4 DS3原图及实验图

Fig.5 Original graph and experimental graph of DS4图5 DS4原图及实验图
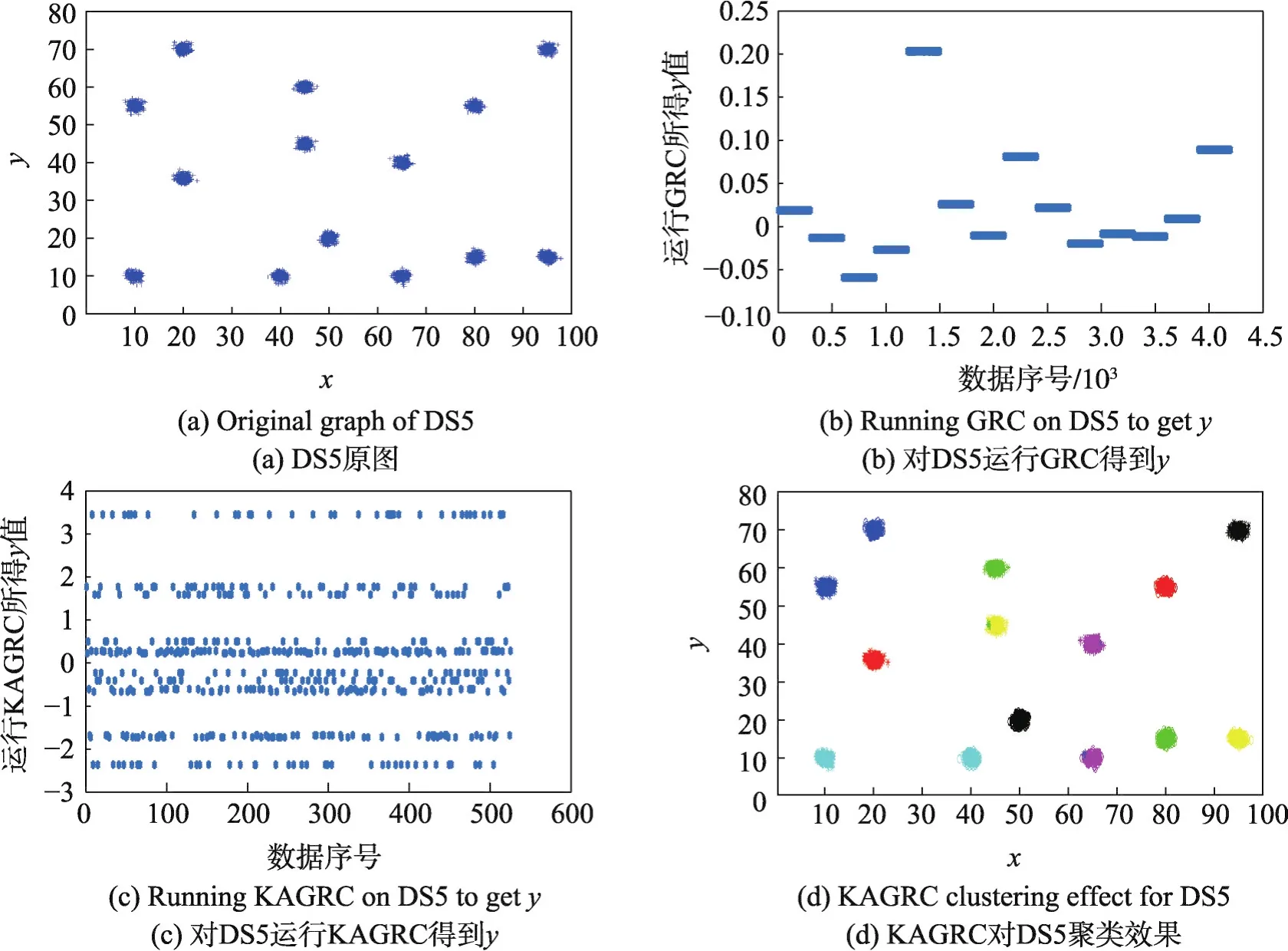
Fig.6 Original graph and experimental graph of DS5图6 DS5原图及实验图

Table 3 Experimental results on dataset DS1表3 数据集DS1的实验结果

Table 4 Experimental results on dataset DS2表4 数据集DS2的实验结果

Table 5 Experimental results on dataset DS3表5 数据集DS3的实验结果
表中,γ为缩减率,k为代表点数。对DS1、DS3等数据样本量大于10 000的数据集分别进行KAGRC和RAGRC算法实验。需要注意的是,在随机投影树建树选取代表点时,不能做到和KAGRC算法中所选代表点数目完全相同。因此,RAGRC算法在代表点选取时选择与KAGRC算法代表点相近数量。在实验中,由于选点时存在随机的情况,则会造成每次实验结果出现小范围内波动。为此,实验数据则选取均值作为数据结果,以上每组实验所记录数据都是在运行数十次之后计算均值得到。从实验数据可以明显看出,同预想一样,本文提出的KAGRC算法及RAGRC算法同GRC算法相比较,在准确率几乎不变的情况下,速度明显提高。当然,随着缩减率γ逐渐地减小,其代表点随之增多,算法在时间消耗上也会相应增加。从以上实验来看,本文算法在保证精度情况下,速度有了非常大的提升,完全达到期望值。
下面的内容主要针对来自UCI的3个真实数据集mGamma、sensorreadings及musk进行实验。对于sensorreadings数据集,本文选取其中24维度的数据样本进行实验,并对其字符进行数字化地处理。实验中也都对GRC以及k-means算法进行详细的比较。详细的实验结果在表8~表10中分别给出。

Table 6 Experimental results on dataset DS4表6 数据集DS4的实验结果

Table 7 Experimental results on dataset DS5表7 数据集DS5的实验结果

Table 8 Experimental results on dataset mGamma表8 数据集mGamma的实验结果
从表中数据可看出,本文算法对于真实数据集,相对于GRC算法在速度上显著改善。对于不同的缩减率,耗时方面会随着代表点增加而增加,但速度也都远快于GRC。相对于k-means算法,KAGRC在精度方面同样表现得非常优秀。
musk数据集的维度为166维,相比于文中的其他数据集,在维度上有所提升。接下来的实验中,为了进一步展现本文算法的优秀性能,在musk数据集分别对KAGRC、RAGRC以及GRC、k-means等算法的运行结果进行比较。详细的实验情况如表10所示。

Table 9 Experimental results on dataset sensorreadings表9 数据集sensorreadings的实验结果

Table 10 Experimental results on dataset musk表10 数据集musk的实验结果
从表10的实验结果不难看出,KAGRC和RAGRC算法在精度方面已经远远甩开k-means算法。也可注意到,两种算法在缩减率γ减小,即代表点k的数量增大时,其准确率也同样是稳步提升。可以明显看到,在KAGRC算法中,当缩减率γ为2时,其对应的精度已经同GRC精度完全相同。同样,在RAGRC算法中,当代表点k为2 048时,其精度也和GRC精度非常相近。反观时间消耗,KAGRC以及RAGRC算法无论缩减率及代表点如何取值,都远小于GRC算法。同样,随着缩减率γ减小,或者代表点k的数量增大时,算法的消耗时间也在合理地随之增加。同之前实验相同,本节实验所得数据结果也是多组实验后取均值得到。
4.3 百万级数据可行性实验
本节将对百万量级的PokerHand数据集进行实验分析,以说明本文算法对百万量级数据操作的可行性。由于数据集样本量过大,受实验环境的限制,无法在同等条件下进行GRC运算作为实验的对比选项,但是可以用其他方式来提供一个粗略的上限。在此,可将聚类问题作为一个分类问题去看待,并且选取最先进的分类算法,即随机森林(random forest,RF)算法[24],以此算法所得结果来作为对比的取值。对于RF算法,选取其训练数据集的大小为25 010,测试数据集大小为1 000 000。同样,在实验中也用k-means算法同本文算法进行对比,其中需适量增加k-means的迭代次数,以便运行时间与文中算法的运行时间相同,从而保证遵循实验对比的单一变量原则。表11是详细的实验结果。
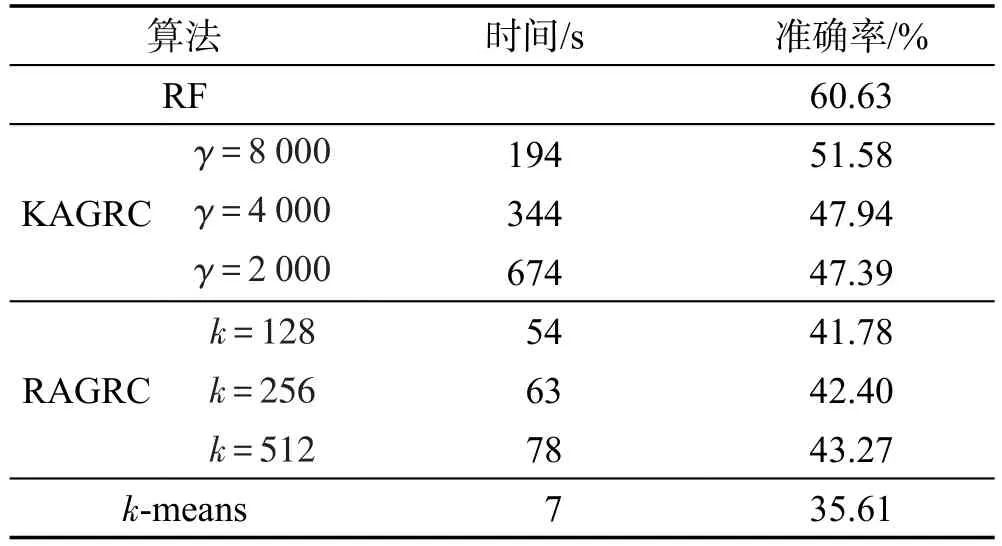
Table 11 Experimental results on dataset PokerHand表11 数据集PokerHand的实验结果
实验表明,k-means算法在增加迭代次数后并没有显著提高准确率。同时,结果显示,算法KAGRC和RAGRC中的数据减少并没有严重降低聚类的精度,且在几分钟内完成算法计算。另一方面,相对而言,KAGRC算法一定程度上稍优于RAGRC算法。
5 结束语
本文提出了两种对基于图松弛优化聚类的快速近似优化方法。文中算法利用k-means和RPTree首先对数据点进行预分组,并产生一组用于GRC算法的代表点。在实验阶段,对多种样本量、维度以及类别数数据集的实验表明,本文算法可以在聚类精度上下小范围浮动的情况下使GRC算法在速度上得到大幅提升。值得注意的是,本文近似算法能够使单个机器为大型数据集运行GRC算法。
[1]Dong Qi,Wang Shitong.Improved latent sub-space clustering algorithm and its incremental version[J].Journal of Frontiers of Computer Science and Technology,2017,11(5):802-813.
[2]Gold S,RangarajanA,Mjolsness E.Learning with preknowledge:clustering with point and graph matching distance measures[J].Neural Computation,1996,8(4):787-804.
[3]Li Tao,Wang Shitong.Incremental fuzzy(c+p)-means clustering for large data[J].CAAI Transactions on Intelligent Systems,2016,11(2):188-199.
[4]Cheng Yang,Wang Shitong.A multiple alternative clusterings mining algorithm using locality preserving projections[J].CAAI Transactions on Intelligent Systems,2016,11(5):600-607.
[5]Kim S,Nowozin S,Kohli P,et al.Higher-order correlation clustering for image segmentation[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2011,36(36):1761-1774.
[6]Sáez A,Serrano C,Acha B.Normalized cut optimization based on color perception findings:a comparative study[J].Machine Vision&Applications,2014,25(7):1813-1823.
[7]Sookhanaphibarn K,Thawonmas R.Exhibition-area segmentation using eigenvectors[J].International Journal of Digital Content Technology&ItsApplications,2013,7(2):533-540.
[8]Lee C H,Ane O R,Park H H,et al.Clustering high dimensional data:a graph-based relaxed optimization approach[J].Information Sciences,2008,178(23):4501-4511.
[9]Madigan D,Raghavan N,Dumouchel W,et al.Likelihoodbased data squashing:a modeling approach to instance construction[J].Data Mining and Knowledge Discovery,2002,6(2):173-190.
[10]Mitra P,Murthy C A,Pal S K.Density-based multiscale data condensation[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2002,24(6):734-747.
[11]Dasgupta S,Freund Y.Random projection trees and low dimensional manifolds[C]//Proceedings of the 40th Annual ACM Symposium on Theory of Computing,Victoria,May 17-20,2008.New York:ACM,2008:537-546.
[12]Keuchel J.Image partitioning based on semidefinite programming[D].Mannheim:University of Mannheim,2004.
[13]Shi J,Malik J.Normalized cuts and image segmentation[J].IEEE Transactions on Pattern Analysis and Machine Intelli-gence,2000,22(8):888-905.
[14]Deveci M,Kaya K,Uçar B,et al.Hypergraph partitioning for multiple communication cost metrics:model and methods[J].Journal of Parallel&Distributed Computing,2015,77:69-83.
[15]Karypis G,Kumar V.A fast and high quality multilevel scheme for partitioning irregular graphs[J].SIAM Journal on Scientific Computing,2006,20(1):359-392.
[16]Bādoiu M,Har-Peled S,Indyk P.Approximate clustering via core-sets[C]//Proceedings of the 34th Annual ACM Symposium on Theory of Computing,Montréal,May 19-21,2002.New York:ACM,2002:250-257.
[17]Drineas P,Mahoney M W.On the Nyström method for approximating a gram matrix for improved kernel-based learning[J].Journal of Machine Learning Research,2005,6:2153-2175.
[18]Williams C K I,Seeger M.Using the Nyström method to speed up kernel machines[C]//Proceedings of the Neural Information Processing Systems,Denver.Cambridge:MIT Press,2001:682-688.
[19]Fine S,Scheinberg K.Efficient SVM training using low-rank kernel representations[J].Journal of Machine Learning Research,2002,2(2):243-264.
[20]Hao P,Wang L,Niu Z.Comparison of hybrid classifiers for crop classification using normalized difference vegetation index time series:a case study for major crops in North Xinjiang,China[J].PLOS One,2015,10(9):e0137748.
[21]Fowlkes C C,Belongie S J,Chung F R K,et al.Spectral grouping using the Nyström method[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2004,26(2):214-225.
[22]Gray R M,Neuhoff D L.Quantization[J].IEEE Transactions on Information Theory,1998,44(6):2325-2383.
[23]Buaba R,HomaifarA,Kihn E.Optimal load factor for approximate nearest neighbor search under exact Euclidean locality sensitive hashing[J].International Journal of Computer Applications,2013,69(21):22-31.
[24]Breiman L.Random forest[J].Machine Learning,2001,45(1):5-32.
附中文参考文献:
[1]董琪,王士同.隐子空间聚类算法的改进及其增量式算法[J].计算机科学与探索,2017,11(5):802-813.
[3]李滔,王士同.适合大规模数据集的增量式模糊聚类算法[J].智能系统学报,2016,11(2):188-199.
[4]程旸,王士同.基于局部保留投影的多可选聚类发掘算法[J].智能系统学报,2016,11(5):600-607.
