基于Hadoop的空间科学大数据的区域检索算法
2018-04-07王广钰李英玉
王广钰,李英玉
(1.中国科学院大学北京100190;2.中国科学院国家空间科学中心北京100190)
我国天基信息基础设施的高速发展使得探测到的空间科学数据呈现出海量化、多源化等特征,现阶段对空间科学大数据的组织方式采用的仍是基于传统数据库的单机集中式处理模式,这种模式的数据查询时间过长。国内外对时空数据[1-2]的组织方法的研究成果可分为3类:1)将时间作为2D位置信息的补充维:THEODORIDIS Y等人提出的3DR-tree[3-5];2)重叠和多版本结构[6]:TAO Y,PAPADIAS D等人提出 MV3R-tree[7];3)面向轨迹[8-10]:Elias Frentzos提出的FNRB-tree[11-12]。上述3种组织方式是基于二维空间数据开发的索引结构,不支持对四维时空数据的检索,并且只适用于单机环境下。用Hadoop处理空间数据的研究也都是基于二维空间数据,例如HQ-Tree[13]和 M-Quadtree[14]和 Spatial Hbase[15]。
因此,文中基于提出了分布式区域检索算法,并基于Hadoop开发了NSSC-Hadoop分布式系统框架,通过多组实验验证了算法的高效性。
1 分布式区域检索算法
区域检索算法是利用建立的时空索引结构对数据进行索引,通过时间区域检索算法和空间网格检索算法快速计算出指定时间范围内的空间区域所包含的网格,完成对时空数据的查询。
1.1 四维空间科学数据的索引方法
采用时间优先的存储策略,按照KTS的存储结构将原始数据文件存储在分布式文件系(Hadoop Data Filesystem,HDFS)中,数据处理步骤如下:
1)原始数据文件根据数据源信息分组存储,并以数据源信息命名。
2)按照数据文件所在的时间域对数据分区存储,并以时间域命名。
3)将每个时间范围下的数据按照数据块大小对文件进行物理分块存储。最后对文件块中的数据建立空间索引结构。
本文在传统空间剖分思想的基础上,结合Hadoop的特点,提出了一种基于立方体的Block-Grid三维网格剖分方法。
基于立方体的Block-Grid三维网格剖分方法的过程包括3个阶段:
1)分区:即将输入文件划分成若干个小分区。小分区需要满足3个条件:①匹配数据块大小;②空间邻近;③负载均衡。分区步骤如下:
①确定分区个数:计算出所有输入文件的分区个数,计算方法如下:

S表示输入文件大小,B是HDFS中数据块大小为128 MB,α是开销比,默认等于0.2。
②确定分区边界:计算每个小分区覆盖的立方体网格区域,均匀计算网格边界,计算方法如下:

剖分结果如图1所示。
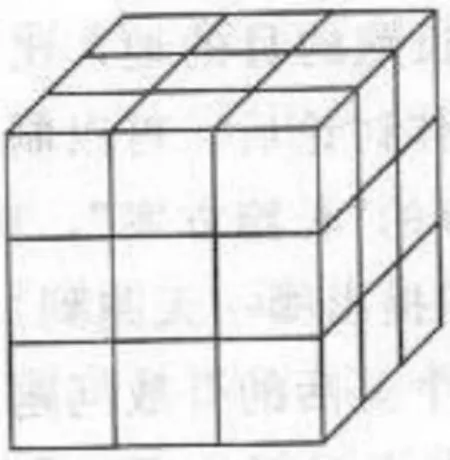
图1 立方体分割
物理分区:根据第二步中确定的分区边界对输入文件物理分区,给每个数据记录r唯一指定一个分区p,格式为<r,p>。
2)建立局部索引:根据数据的物理分区将每个分区中数据覆盖的空间区域写入一个单独的局部索引文件中。局部索引用于检索与查询区域相重叠的分区。
3)建立全局索引:初始化HDFS的连接命令,将所有局部索引文件连接成一个全局索引文件。全局索引用于判断分布式系统中哪些存储数据的节点满足查询条件,用于检索数据分区所在的节点。
1.2 四维空间科学数据的分布式索引架构
1)索引在主从节点的分布策略
在分布式环境下,为了能够实现数据的快速检索,需要将建立的两级索引结构存储在分布式系统的不同节点中。将数据源索引信息、时间索引信息、全局索引文件存储在主节点的内存中,将局部索引文件存储在分布式系统的从节点中。这样的分布策略不仅能够使得MapReduce可以直接访问索引信息,而且能够有效地减少Map任务的数量。
2)数据在分布式环境下的容错机制
当分布式系统出现故障时,为了维护数据的完整性,需要建立分布式系统主从节点的容错机制。将主节点中存储的节点信息以及索引信息定时地备份在另一个独立的分布式节点中,称为主节点备份节点,用于恢复现场。从节点中采用Block备份的机制,每个从节点中包含的所有数据块都在另外的两个分布式从节点中有一个完全相同的备份,这样的容错机制虽然占有了大量的存储空间,但是能够有效地维护数据的完整性。
2 NSSC-Hadoop系统架构设计
NSSC-Hadoop是在Hadoop基础上设计的能够处理带有时空属性的结构化的空间科学数据的系统架构。NSSC-Hadoop由4个层次构成:
1)语言层:在建立数据源索引信息和时间索引信息部分引入了Hive组件,支持HQL语言,它是一种类似于SQL的语言,其他部分使用的是Java语言。
2)存储层:NSSC-Hadoop采用两级索引结构,对Hadoop增加了索引部分。
3)执行层:NSSC-Hadoop允许MapReduce程序直接访问时空索引结构。
4)业务层:将传统的空间区域查询操作以MapReduce的方式执行在分布式系统框架上。
NSSC-Hadoop系统架构如图2所示,下面主要详细介绍存储层和执行层两个层次。
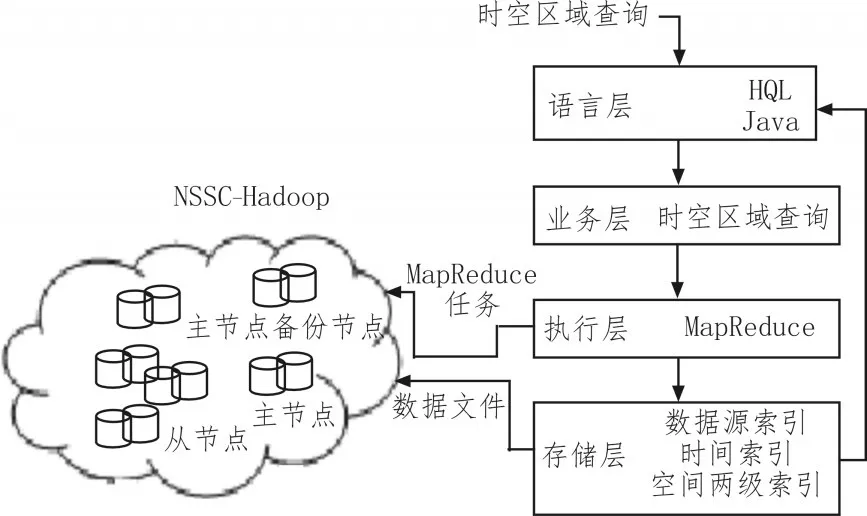
图2 NSSC-Hadoop系统架构图
2.1 存储层
在Hadoop中,输入文件以无索引的堆数据结构存储在HDFS中,而在NSSC-Hadoop中,存储层中不仅包含原始数据文件,同时也包含索引信息文件。原始数据文件以Block的形式存储在从节点中大小为128 MB,并按照上文中介绍的容错机制进行备份处理。局部索引文件与数据块一同存储在从节点的磁盘中,而数据源索引文件、时间索引文件以及全局索引文件存储在主节点的内存中,主节点定期向主节点备份节点发送备份信息。
2.2 执行层
与Hadoop类似,NSSC-Hadoop的执行层中执行的是MapReduce程序。但是,Hadoop中的输入文件是无索引的堆数据结构,而NSSC-Hadoop支持带有索引信息的输入文件。在Hadoop中,首先FileSplitter组件将输入文件逻辑分割成若干个分片Split,然后RecordReader组件从分片Split中根据数据在文件中的偏移量提取记录,传递给map函数处理,如图3所示。这种处理方式使得全部文件都要被遍历一次,增加了数据查询的时间。
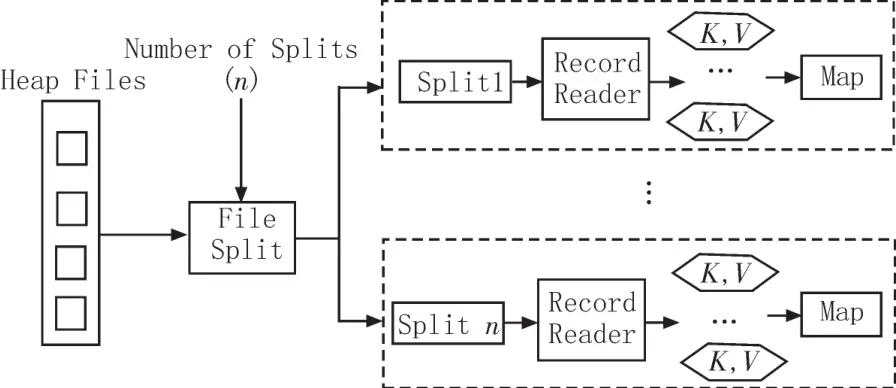
图3 Hadoop的MapReduce执行部分
文中为了有效地提高数据检索的效率,对输入数据增加了索引信息,原本的组件无法满足处理索引文件的需求。NSSC-Hadoop系统对原本的组件进行改进得到了_3D-SpatialFileSplitter,该组件基于主节点内存中存储的全局索引,通过过滤函数得到从节点中满足查询条件的所有文件块的数据节点信息并为每个满足条件的文件创建一个逻辑分片Split。对原本的RecordReader组件进行改进得到了_3DSpatialRecordReader,该组件从分片中提取局部索引信息,将满足查询条件的文件块传递给map函数处理,如图4所示。
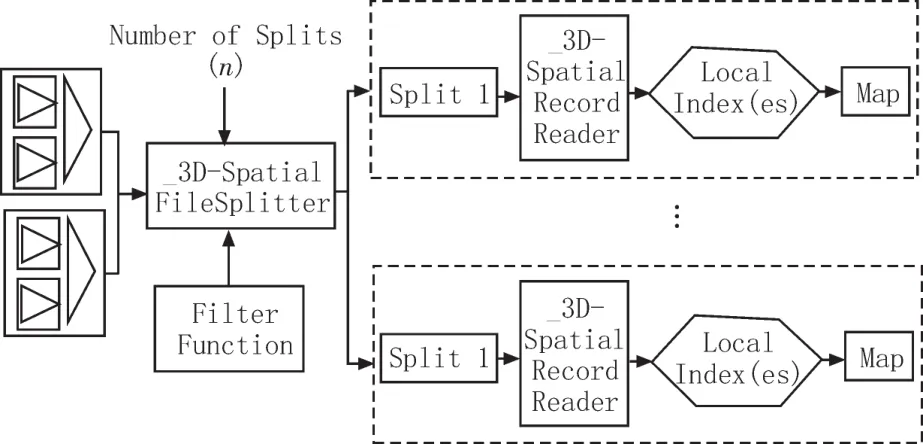
图4 NSSC-Hadoop的MapReduce执行部分
3 试验结果与分析
3.1 试验数据及测试环境
试验数据集用随机生成的多组数据,数据所在空间区域可在有效数字内任意指定,本实验中使用的数据覆盖空间范围为[0,10 000]×[0,10 000]×[0,10 000]。测试环境如表1所示。

表1 测试环境
分布式系统采用主-从集成模式,其中,一台机器作为主节点,另外4台机器作为从节点,分布式系统完成网络和环境配置后,用SSH通信协议实现无密码登录。为了保证集群的时间同步,将主节点作为时钟服务器,其他几台机器均实现与主节点的时间校对。
3.2 实验结果和分析
文中为了验证算法的高效性,进行了多组对比实验,多组数据分别运行在无任何算法的分布式系统以及应用本文提出的分布式区域检索算法支持的分布式系统中。数据量为G数量级,时间单位为毫秒,由于时间数值较大,为了清晰地表示结果,对时间以10为底取对数如图5所示。由实验结果可以看出,应用本文提出的分布式区域检索算法能够有效地较少数据查询的时间,当数据量增大到500G时,数据检索效率提高了将近50倍。并且由图中可以看出,随着数据量的增加,数据检索时间呈现出收敛的趋势,而使用Hadoop直接对数据进行遍历查询时,当数据量增加时数据检索时间也随着成倍增加,整体呈线性趋势。
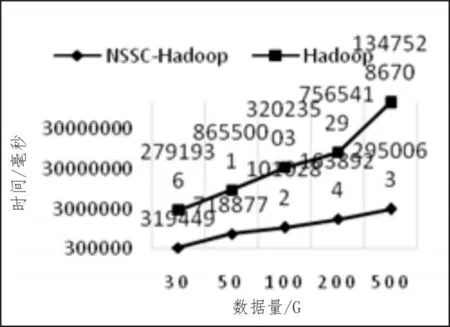
图5 实验结果对比图
表2是对500G数据下检索不同空间区域下包含数据的时间结果的汇总。由表2可以看出,随着检索查询区域的增大,数据检索时间会成倍增加,原因在于当检索空间区域增大时,满足查询条件的数据块数量就会增加。
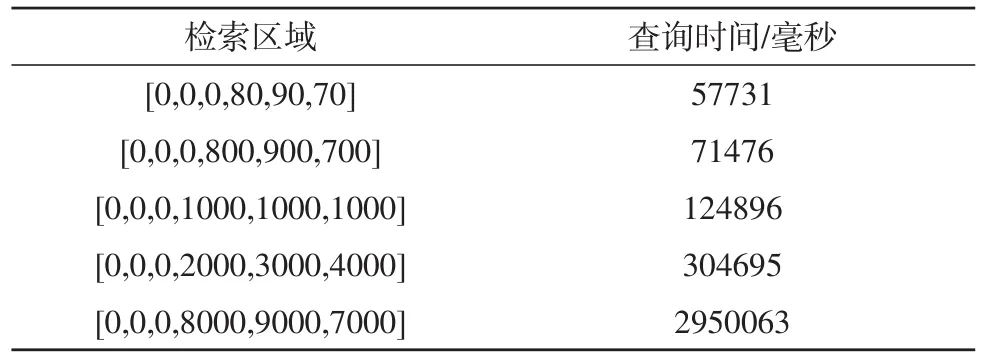
表2 不同空间区域的数据检索时间
当分布式系统节点个数减少时,对同一组输入数据,大小为 500G,当查询区域为[0,0,0,1000,1000,1000]时,检索的时间结果汇总如表3所示,结果表明当分布式系统节点个数减少时数据检索时间会增加,由此可以推断,当分布式系统节点个数继续增加时,由于MapReduce计算节点个数增加,因此数据检索效率增大,检索时间缩短。
虽然图中结果表明数据检索时间相对较大,但是该时间包含了分布式系统的启动时间,这个时间占用了全部时间的较大部分并且无法消除,当分布式系统的节点数增加时,系统启动时间会继续增加。

表3 不同空间区域的数据检索时间
4 结 论
对空间科学大数据的快速查询已成为当前对天基信息分布式组织方法研究的热点,本文基于空间科学大数据的特点提出了分布式区域检索算法,并将理论算法应用到了开发的分布式系统框架NSSCHadoop中,通过对多组实验结果的分析展现了算法的有效性和高效性。该算法主要包括以下几方面的特点:1)基于立方体的Block-Grid三维网格剖分方法建立的局部索引方法与传统的空间网格剖分算法相比,该算法能够很好地运行在Hadoop基础架构上,而传统的空间网格剖分算法运行在Hadoop上会增加Hadoop系统的启动时间以及任务执行时间。2)两级索引结构与其他检索算法相比,增加的节点间的全局索引部分能够有效地缩短数据查询的时间,提高检索效率。3)数据在分布式环境下的容错机制,能够保证数据的完整性,防止任何因系统节点故障导致的数据丢失问题。
参考文献:
[1]张林,汤大权,张翀.时空索引的演变与发展[J].计算机科学,2010,37(4):15-20.
[2]葛斌,唐九阳,张翀.战场环境中基于对等计算的分布式时空索引技术[J].系统工程与电子技术,2011,33(9):2019-2024.
[3]Diaz A J,Gutiérrez Retamal G A,Gagliardi E O.Algoritmo de reunión espacio-temporal usando estructura 3DR- tree podada[J].Spatiotemporal Join,2012,23(2):237-247.
[4]Zhang Z T.Optimization of History Tree in 3DRTree Index Structure[J].Applied Mechanics &Materials,2013,347-350(6):525-529.
[5]Zhang Z T.3DR-Tree Model Improvement Based on Enhance of Index Performance[J].Advanced Materials Research,2013(765-767):1332-1335.
[6]孟学潮,叶少珍.一种基于实时数据和历史查询分布的时空索引新方法[J].计算机应用,2017,37(3):860-865.
[7]张翀,肖卫东,杨晓亮.基于对等计算的分布式时空索引模型建立与整体框架研究[J].计算机应用研究,2012,29(3):961-967.
[8]龚俊,柯胜男,朱庆.一种集成R树、哈希表和B树的高效轨迹数据索引方法[J].测绘学报,2015,44(5):570-577.
[9]汪娜.面向室内空间的时空数据管理关键技术研究[D].合肥:中国科学技术大学,2014.
[10]Tang L,Kan Z,Zhang X,et al.Travel time estimation at intersections based on low-frequency spatial-temporalGPS trajectory big data[J].Cartography&Geographic Information Science,2016,33(13):1523-1545.
[11]Huang Z H,Dai J.FNRB-Tree:Based on SpatialtemporalCo-occurrenceMiningTechnique[J].Journal of Chinese Computer Systems,2012,33(12):2636-2641.
[12]黄照鹤.基于时空同现挖掘技术的FNRB-Tree[J].小型微型计算机系统,2012,33(12):2636-2641.
[13]FENG,TANG,Zhixian,etal.HQ-Tree:A Distributed Spatial Index Based on Hadoop[J].中国通信(英文版),2014,11(7):128-141.
[14]Zhongliang F U,Yulong H U,Weng B.M-Quadtree Index:A Spatial Index Method for Cloud Storage Environment Based on Modified Quadtree Coding Approach[J].Acta Geodaetica EtCartographica Sinica,2016,12(6):256-259.
[15]EldawyA,AlarabiL,MokbelM F.Spatial partitioning techniques in SpatialHadoop[J].Proceedings of the Vldb Endowment,2015,8(12):1602-1605.
