基于云计算的Web数据挖掘Hadoop仿真平台研究
2018-03-29王勃,徐静
王 勃,徐 静
(陕西国防工业职业技术学院陕西西安710302)
云计算自出现伊始,就被广泛的应用到分布式计算机网络处理上,面对大量的网络服务器终端,如何能够有效地将它们组合在一起,建立稳定、快捷的服务网络已经成为云计算网络急需解决的关键问题。面对服务器日益增大的网络服务数据流,web数据挖掘不断收取网络中的数据源,通过Hadoop仿真平台进行相应的计算、分析,该平台能够较成功的解决了云计算的分布式的复杂问题[1]。
1 云计算与WEB数据挖掘技术
1.1 云计算
云计算通过互联网服务的方式,收集、处理大量相关数据软件的能力,并将传统基于客户端的复杂运算移植到云计算上,降低客户端用户的硬件要求,提升客户端的各项速度。它具有分布处理(Distributed Computing)、网格计算(Grid Computing)和并行处理(Parallel Computing)等特点,是虚拟化服务的结果。云计算能够使客户通过较低投资,获取许多无限的网络资源,同时云计算还对所有的数据安全性提供了较大的保证,实现了数据共享[2]。
1.2 WEB数据挖掘
WEB数据挖掘是以互联网为载体,相关仿真平台为依托,从大量的网络WEB日志中发现未知的,有规律的网络数据源,得到各类用户在云计算环境下使用WEB的结构,WEB的内容、调用WEB数据库、使用记录等相关信息并对其进行挖掘。目前,WEB数据挖掘算法主要采用分类分析、频繁序列模式分、关联规则分析、聚类分析等多种挖掘形式,这些WEB挖掘算法在处理分布式网络数据源时具有动态性强等特点,使其更新速度、访问频率加快[3]。
2 Hadoop仿真平台
Hadoop仿真平台是一个基于分布式的网络框架仿真平台,该平台能够将大量的网络数据任务进行分解,并将处理后的结果汇总输出,同时还拥有简化的,不需要改变原有网络框架的可扩展性,具有经济、运行速度快等特点。其结构示意图如图1所示。
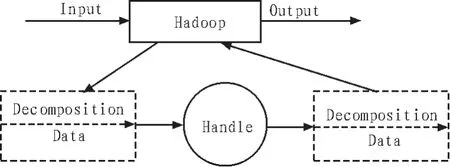
图1 Hadoop结构示意图
Hadoop仿真平台是一个具有高度纠错性的系统,该平台把输入数据按照相同的属性分解为大量的数据模块,通过Handle将数据模块以并行方式处理,然后结果返还到主机,并且输出。其可用公式(1)表示。

在公式(1)中,Q为平台的输出数据值,m为数据模块数量,n为单位时间,为单位时间处理数据的数量[5-7]。
3 基于云计算的web数据挖掘Hadoop仿真平台
3.1 基于云计算的web数据挖掘Hadoop仿真平台概述
云计算的Hadoop仿真平台是由大量的服务器群组合而成的,这些服务器具有地域分布较广,因此相对于一般平台复杂程度更高,在云计算环境中,有效地利用了云计算的可扩展性、稳定性等特点组成该平台,使平台能够存储大量的客户信息,而且不会因为客户信息流量的大量增加造成网络的堵塞。该平台根据实际需要通过主网分支为多个支网,支网又可分为多个子网,最后形成一个类似于树形的网络结构。其网络结构如图2所示。

图2 网络结构图
由图2可知该网络结构客户端用户通过SOAP OVER HTTPS协议实现与云计算服务器端的数据信息传递、计算与交换等功能,为了保证数据信息在交换过程中的安全性,使用HTTPS5协议作为网络通讯协议,最终形成了一个网络集合,使客户端用户、服务器端管理同时降低了运行过程中对硬件的要求。节约大量的资源,最终使该网络仿真平台具有容纳网络流量、网络交换容量和获取网络地图信息等特征,可以形成一个网络结构饱满、网络维护简便、运行成本低廉的网络构架[8-10]。
3.2 平台的MapReduce编程模型
仿真平台在建立软件框架时,需要使用MapReduce技术建立其编程模型,MapReduce表示Map(映射)和Reduce(归约),该技术应用于大量的数据并行计算,其最大的特点就是建立了输入模式(Input)后,输入任务分为两个步骤,分别是Map和Reduce作业区,在每个步骤中,都使用关键字Key,经过高速运算,得到输出模式(Output)[11]。其核心结构是:

由于运算过程中产生的是临时文件,因此其数据交换时间更加快捷,运行速度得到大幅提升。MapReduce工作流程图如图3所示。
其工作流程步骤如下:
步骤一:使用库文件MapReduce把程序分解为若干个小任务,如图中任务a,任务b,任务c,平台要求分解的任务大小是16 M至64 M。
步骤二:通过调度功能将闲置的任务及时分配到Map或者Reduce作业区,并且由调度功能按照平台任务大小要求分配任务个数。
步骤三:在Map作业区的多个被分解的任务启动,并且开始输入数据,开始读取相关大小的数据信息,通过关键字Key传递相关函数,并将计算过程中产生的临时文件有效存储。
步骤四:临时文件的关键字Key将会及时存入本地空间中,并且会在Reduce作业区找到相对应的位置,通过介质文件将相关信息数据传递给Reduce作业区。Reduce产生的数据将会以输出文件的方式输出[12-13]。
7.1.1 苗期猝倒病:苗床严格消毒,方法同上。底水浇足后,基本不大浇灌,出苗后喷施75%百菌清600倍液,或64%杀毒矾500倍液,每7~10天喷一次。
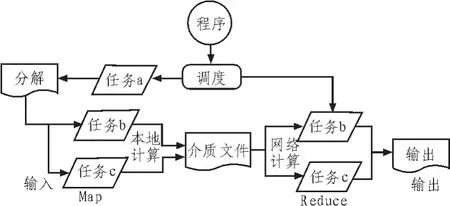
图3 MapReduce工作流程图
3.3 平台的实现及算法过程
平台的建立过程可用公式(2)表示。
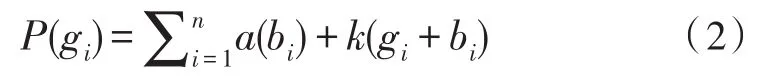
其中,P表示平台网络分支及连接结构,gi表示分支的各条路线的带宽,i表示分支的各条路线的常量,a表示建立该平台的基本支出,bi表示网络带宽容量。k是简捷的无向图标,同时表明k是没有重合的边框[14]。
在建立平台的过程中,需要对平台的容错度做以评估,它是平台的稳定运行的重要指标之一,它的作用是在该仿真平台相关信息点出现无效的情况下,进行容错的能力,其可用公式(3)表示。
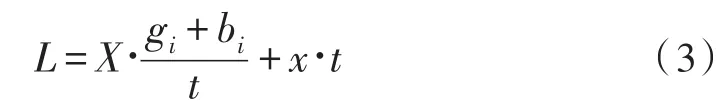
其中,L平台容错度,X为容错常量,其取值范围是X{1,2,3,4,5,6},如无特殊情况,X取值为3,t为时间变量值。
在该平台建立的过程中,还使用了CRF(条件随机场)算法,该算法可用公式(4)表示。

其中,Q(f)为该算法的表示方法,P(i)为所有子模块的集合,其每个子模块的非负的势能函数为f[15-16]。
通过以上公式可知,其算法基本思想就是,在云计算的Hadoop仿真平台中,为避免云计算网络中相关数据任务长时间等待,不同任务又能够根据实际情况变化调度优先级,可以使用加权轮转调度算法。其相关步骤如下:
步骤二:类tasktracker在有空闲存量的情况下,向子任务J发送任务执行命令。子任务J接到相关命令后,将发送距离最近的任务分配执行,同时执行指针会指向下一个子任务,继续等待下一个类tasktracker发送的执行命令。
步骤三:当类tasktracker执行命令到最后一个子任务时,子任务J会自动排序新的任务集合,并将执行指针指向第一个子任务。
类tasktracker的数据结构如下:

在该算法过程中,各个子模块经过迭加运算后,得到各条路线的最短路径,降低了平台的复杂度,得到运行时间最短的平台布局图,提高了平台的运行效率[17-18]。
4 仿真结果
基于云计算的Web数据挖掘Hadoop仿真平台的运行,有效的验证了算法,同时得出了仿真结果。在仿真实验中,确定了平台路线的数目,连接各条路线的信息点,最终完成了网络的布局。其仿真运行结果如图4所示。
由图4可知,在该仿真实验中,设置了5,10,15,20,25,30等 6个信息点,设置 20,40,60,80,100,120等6个时间节点,随着信息点的增加,各个子模块的路线不断增加,同时也得到了较多的时间,实现了该平台的云计算实现是由主干交换部分和众多树状子模块网络形成的构想。
5 结 论
本文通过基于云计算的web数据挖掘Hadoop仿真平台研究,分析了在云计算的普及和快速发展的情况下,Hadoop的结构与流程,提出了基于云计算的Web数据挖掘Hadoop仿真平台的设计与实现方法,完成了易于搭建的仿真平台,建立了完整的网络算法,通过仿真实验数据得出仿真平台的实用性,也为最终达到云计算环境下的高速分布式计算的目标提供了数据依据。

图4 仿真结果运行图
[1]Liang Q,Wang Y Z,Zhang Y H.Resource Virtualization Model Using Hybrid-graph Reprsenetation and Conver-ging Algorithm for Cloud Computing[J].International Journal of Automation &Computing,2013,10(6):597-606.
[2]Oruganti S,Ding Q,Tabrizi N.Exploring HADOOP as a Platform for Distributed Association Rule Mining[C]//FUTURE COMPUTING 2013,The Fifth International Conference on Future Computational Technologies and Applications,2013:62-67.
[3]Jinbo Shang,Yu ZhengTong,EricChang,Yong Yu.Inferring gas and consumption pollution emission of vehicles throughout a city[C]//In Proceedings of the 20th ACM SIGKDD international conference on Knowledge discovery and data mining.ACM,2014:1027-1036
[4]Zhou X,Huang Y An improved parallel association rules algorithm based on MapReduce framework for big data[C]//Fuzzy Systems and Knowledge Discovery(FSKD) ,2014 11th International Conference on.IEEE,2014:284-288.
[5]Wen Yang,Yinan Dou.High Performance Distributed Indexing and Retrieval for Large Volume Traffic Log Datasets on the Cloud[C]//International Conference on Intelligent Human- Machine Systems and Cyemetics(IHMSC),2013:185-189.
[6]Vijay Rana,Gurdev Singh.Analysis of Web Mining Technology and Their Impact on Semantic Web[C]//International Gonferencr on Innovative Applications of Computational Intelligence on Power,Energy and Crontrols with their Impact on Humanity,20I4:5-11.
[7]郭建伟,李瑛,杜丽萍,等.基于hadoop平台的分布式数据挖掘系统研究[J].中国科技信息,2013,13:81-83.
[8]杨勇,王伟.一种基于MapReduce的并行FP-growth算法[J].重庆邮电大学学报:自然科学版,2013,25(5):651-670.
[9]戴小平,张宜力.Hadoop平台下计算能力调度算法的改进与实现[J].计算机工程与应用,2015(19):61-65.
[10]郝伟妓,周世健,彭大为.基于HADOOP平台的云GIS构架研究[[J].江西科学,2013(1):109-112.
[11]刘义,景宁,陈荦,等.Map Reduce框架下基于R-树的k-近邻连接算法[J].软件学报,2013,24(8):1836-1851.
[12]叶可江,吴朝晖,姜晓红,等.虚拟化云计算平台的能耗管理[[J].计算机学报,2013,35(6):209-223.
[13]李建江,崔健,王耽,等.MapReduce并行编程模型研究综述[[J].电子学报,2012,39(11):2635-2642.
[14]李燕,陈莹,董秀兰,等.基于神经网络的遥感图像识别算法[[J].测绘与空间地理信息,2012,35(2):156-158.
[15]鲁伟明,杜晨阳,魏宝刚,等.基于MapReduce的分布式近邻传播聚类算法[[J].计算机研究与发展,2012,49(8):1762-1772.
[16]崔杰,李陶深,兰红星.基于Hadoop的海量数据存储平台设计与开发[[J].计算机研究与发展,2012 49(S1):12-18.
[17]虞倩,戴月明.基于MapReduce的并行模糊C均值算法[J].计算机工程与应用,2013,49(14):133-137.
[18]余思,桂小林,黄汝维,等.一种提高云存储中小文件存储效率的方案[J].西安交通大学学报,2011,45(6):59-63.
