基于改进用户相似性度量和评分预测的协同过滤推荐算法
2018-03-27李昆仑万品哲张德智
李昆仑,万品哲,张德智
(河北大学 电子信息工程学院,河北 保定 071000)
1 引 言
随着互联网经济的产生和发展,网络上的信息量呈爆发式增长.为了让信息消费者方便的从海量信息中找到自己真正有用的信息,同时使信息生产者及时的将自己的信息展现给目标用户,大量的学者进行了相关的学习和研究,因此,就有了个性化推荐系统[1]的产生和发展.
推荐算法包含基于内容的推荐[2]、基于关联规则的推荐[3,4]、基于协同过滤的推荐[5,6]、基于知识的推荐[7]等等.其中基于协同过滤的推荐是最主流的推荐算法之一,它同时也面临着各种问题和挑战,例如数据稀疏性问题、新加入用户冷启动问题[8]、可扩展性问题等等.
基于用户的协同过滤推荐算法基于一种假设,如果两个用户的兴趣爱好比较相似,那么其中一个用户可能会对另一个用户感兴趣的东西也感兴趣.协同过滤推荐算法在用户建模时候严重依赖于用户的历史评分数据,而评分数据往往具有很高的稀疏性,这就给我们建立准确的用户模型带来了很大的挑战.目前针对数据集稀疏性问题的优化方案可以分为三大类,第一类是将其它因素引入到相似度的计算中,从而减少单纯利用稀疏的评分数据对相似度计算的影响;第二类是将含有缺失值的评分矩阵按照某种方式进行填充,从而减少数据集的稀疏度;第三种就是引入聚类算法[9-11],此类方法一般是通过计算目标用户与质心的距离,最后确定目标用户所在的簇,初步的得到目标用户的近邻用户集.
针对评分数据稀疏性问题,传统的解决方案是将项目评分进行均值填充或者缺失值补零,这必然给预测结果带来很大的误差.针对这种问题,文献[12]提出了将用户评论信息转化为特征矩阵,最后结合特征矩阵和评分矩阵计算出来的相似度得出目标用户的综合相似度.文献[13]中提到综合考虑用户评分相似性和用户评论特点的相似性,然后通过权值来控制两者的重要程度.它们都有一个共同点,都是靠引入另一种因素来减少相似度对稀疏数据的依赖程度从而达到提高相似度计算准确性的目的.这种算法的优点是能够很好的降低因数据稀疏性导致的计算近邻用户不准确的问题,缺点是增加了算法的复杂度,因此,文献[14]提出了用均值对缺失值进行填充的方法,这虽然能在一定程度上缓解数据稀疏带来的问题,但是对于过于稀疏的数据集效果却并不理想.
另一方面,可扩展性也是衡量推荐系统性能一个非常重要的指标.目前,互联网上每天都有成千上万的用户和商品出现,而推荐系统依然能够实时快速的为每个用户提供个性化服务,这是因为算法具有很好的可扩展性[15].协同过滤推荐算法中,在寻找近邻用户时往往会遇到高维向量的计算问题,这将占用系统大量的时间,因此,如果能够实现对高维的评分矩阵进行降维,将大大的增加算法的可扩展性.针对高维数据的处理问题,文献[16]提出了将PCA主成分分析引入推荐系统,实现数据维数缩减,减少了系统的时间损耗.
针对数据稀疏性问题和可扩展性问题,本文提出了一种新的填充和降维方式,同时将用户评分的均值差引入对相似度的计算并且将用户评分的均值引入对目标项目的评分预测,从而大大减少了因用户评分尺度不同导致的推荐结果不准确的问题.从4.3节中的实验结果显示改进后的方法相比于传统的方法推荐准确度有了较大的提高.
2 传统的基于用户的协同过滤推荐算法
传统的基于用户的协同过滤推荐算法的关键是准确的得出目标用户的近邻用户集.寻找的近邻用户集是否准确会影响到推荐系统的推荐精度,推荐系统的推荐精度直接决定了用户对推荐系统的认可程度和依附程度.传统的基于用户的协同过滤推荐算法可以分成以下三步:
Step1.获取到用户对项目的评分数据,并把它转化为m行n列的用户-项目评分矩阵,记为:Rm,n;
Step2.根据第一步确定的评分矩阵,计算每个用户与其他所有用户之间的相似度,得到用户相似度矩阵,最后按照相似度从高到低确定目标用户的近邻用户集Nu;
Step3.使用近邻用户集中的用户评分对目标项目i进行评分预测.
u,i分别表示目标用户和待预测项目,则预测评分pu,i用公式表示如下:
(1)
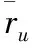
对传统的协同过滤推荐算法而言,相似度计算结果直接影响着近邻用户集寻找的结果,因此,对相似度计算方法的改进也是推荐系统研究热点之一.下面本文将对常见的相似性度量方法进行一些简单介绍.
2.1 常用相似性度量方法
2.1.1 余弦相似度
通过两个向量的夹角余弦值[17]sim(u,v)的大小来衡量用户u、v之间的相似程度,sim(u,v)满足:-1≤sim(u,v)≤1,且sim(u,v)越大则表明两个用户越相似,sim(u,v)用公式表示如下:
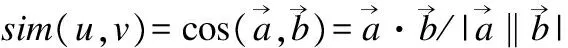
(2)
2.1.2 修正余弦相似度


(3)
2.1.3 基于Pearson相关系数的相似度
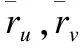
(4)
2.1.4 基于欧几里德距离的相似度
欧几里德距离[19]也称欧式距离,当采用欧式距离度量相似度时候,其表达式如公式(5)所示,其中,d(x,y)表示两者之间的欧式距离,simo(x,y)表示两者之间相似度.
(5)
3 改进的协同过滤推荐算法
本文的主要思路是将原始的用户-项目评分矩阵A经过缺失值填充和降维得到新的矩阵B,再用改进的相似度计算方法计算目标用户和其他用户之间的相似度,把相似度按照降序排列,取前N个近邻用户形成近邻用户集Nu,然后根据近邻用户集Nu中的每个近邻用户分别对目标用户的目标项目进行评分预测,最后按照公式(9)得出最终的预测评分.
3.1 基于平均欧式距离与均值的填充和降维
3.1.1 基于平均欧式距离和用户均值的填充

(6)
移项得:
(7)
a3=b3+2
当b3=2时,则a3=4,也就是说,当两个向量评分尺度有差距时,我们可以用一个向量中的已知项对目标向量中对应的缺失值进行填充,特别是当这两个向量的平均欧式距离很小的时候,填充效果非常好.
3.1.2 基于平均欧式距离和用户均值的降维
前面已经介绍了填充的思想,本文接下来简单介绍是如何实现降维的.首先,看下面的表1.

表1 淘宝店的反馈基本信息Table 1 Taobao shop feedback basic information
经过对该反馈信息进行分析,可以发现当浏览量增加或者减少的时候,访客数也按照一定的规律增加或者减少,同样的,下单数、成交量、交易额似乎也满足这个规律.也就是说,当把访客数、成交量、交易额当作冗余的特征去掉,对了解每天的交易情况没什么影响.
同样的道理,如要根据电影评分数据来探究用户之间的关系,此时,如果把每一部电影当作一个特征,那么这些特征很可能也具有上面类似的关系,当删除掉某些“特征”时,对研究用户之间的相似关系并没有什么影响.
本文对数据集的降维就是基于这种理解,在这里用项目之间的平均欧式距离来度量各个项目之间的相似关系.具体的实现过程如下:
Step1.确定需要进行填充的目标向量,然后选出能够对目标向量缺失值进行填充的所有向量并组成一个集合A;
Step2.分别找出目标向量和集合A中所有向量的共同评分项目,然后计算出目标向量和集合A中所有向量的平均欧式距离d;
Step3.用集合A中平均欧式距离最小的向量按照公式(7)进行缺失值填充;
Step4.填充完毕后,直接删出集合A中与目标向量平均欧式距离最小的向量,最终实现降维;
Step5.重复步骤1、2、3、4,直到数据集的维数达到预设值结束.
3.2 基于余弦距离和均值差的相似度
余弦相似度是最经典的相似度计算方法之一,由于它完全忽略了用户之间评分尺度不同这个重要的因素,所以后来出现了修正余弦相似度和皮尔森相关系数法这些改进型的相似度计算方法,这在一定程度上能够很好的弥补因用户评分尺度不同对相似度计算结果的影响.
余弦距离注重两个向量方向上的差异,同时为了弥补因用户评分尺度不同对相似度计算结果的影响,本文提出了一种方法,结合两个用户评分尺度的相似度和余弦相似度得到一个综合相似度,然后通过权值k来控制二者的重要程度.最后得到的相似度计算公式如下:
(8)
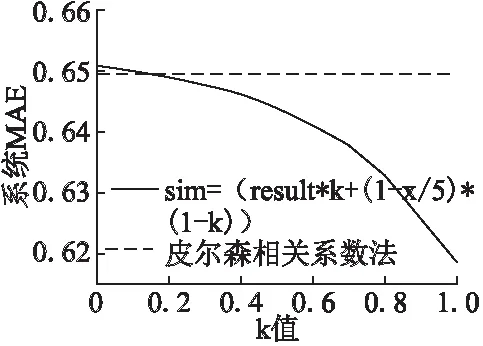
其中sim(u,v)表示u、v两个用户之间的相似度,k是两者之间的权值,满足0 在协同过滤推荐算法中,关键是能准确的得到目标用户的近邻用户集.本文给公式(8)中的k赋一个合适权值(k的取值与用户评分尺度的集中度有关,评分尺度越集中,k值越大),然后根据该公式计算用户之间的相似度,最后得到目标用户近邻用户集为Nu. 接下来就是根据Nu对目标项目进行评分预测,可以分成以下4个步骤: Step1.从Nu中选出一个近邻用户un,他与目标用户u之间的相似度为simu,un; Step2.把目标项目的评分设成xn,类比于3.1.1中需要填充的缺失值,然后把该近邻用户的评分转化为可以对xn进行填充的向量,最后按照公式(7)对xn的值进行填充.此时的填充值xn作为近邻用户un对目标项目的预测值; Step3.重复步骤1、步骤2,直到遍历完Nu里面的所有用户,最终得到的预测值形成一个集合v,则v=[x1,x2,x3…xn]; Step4.根据下面的公式(9)得到最终的预测评分,valuei表示对项目i的最终预测评分. (9) 本章首先介绍了实验环境和选取的数据集以及实验的评价指标,最后根据该数据集将改进的方法和传统的方法进行对比分析. 实验使用的PC配置是Intel 酷睿i5 3230M的CUP,8GB内存,Windows 8企业版64位操作系统.编程语言使用python语言,版本为python2.7,编辑器用的是pyCharm社区版. 本实验选用的是由Minnesota大学GroupLens小组给出的100k的movieLens数据集.该数据集包含943个用户,1682部电影,评分范围0.5-5分,且每个用户电影评分次数不少于20次.实验随机选取数据中的80%作为训练集,20%作为测试集,并且进行了交叉验证. 目前推荐算法性能的评价指标[20]包括平均绝对误差(Mean Absolute Error,MAE)以及查全率、查准率等.本文算法性能的评价指标选用的是MAE,MAE反映了预测值和真实值之间的差距,其值越小越好.假设推荐系统对项目的预测评分为集合{r1,r2,r3…rn},项目的实际评分为集合{p1,p2,p3…pn},则用户MAE计算公式如下: (10) 系统的MAE可以用式子(11)表示: (11) 本文实验选用的数据集为100k的movieLens数据集,其稀疏度为93.69%.实验分两轮进行,第一轮训练集数据稀疏度低于93.69%,第二轮训练集数据稀疏度高于93.69%. 4.3.1 第一轮实验结果 图1反映的是把训练集数据进行填充和降维处理前后,用皮尔森相关系数法计算相似度时,系统的MAE随近邻用户N取值的变化曲线. 从图1中我们可以看到,训练集数据经过填充和降维以后,虽然近邻用户数量小于200、大于700时,系统MAE明显比填充、降维前略大,但是近邻用户数量在200到600之间时,改进后系统的MAE更低,也就是说当我们选择合适的近邻用户数量时,改进后的结果更可靠.另一方面本文实验将训练集数据经过几轮填充和降维处理,把训练集中的1345部电影用71个新的‘特征’代替,大大的减少用户建模过程的时间损耗,增加了系统的可扩展性. 图2中的两条曲线都是将训练集数据经过填充和降维处理后,用皮尔森相关系数法计算相似度时得到的系统MAE随近邻用户数量变化的曲线,实线表示在填充和降维的基础上,还通过公式(7)对预测的评分进行调整,虚线表示没有经过调整. 从图2中可以容易的看出,通过近邻用户对目标项目进行评分预测时,由公式(7)调整后,大大的减少了系统的MAE,增加了推荐准确度. 从图2的实线我们可以得出,当近邻数量为250的时候,系统的MAE最低,接下来,本文实验用皮尔森相关系数法计算相似度的最好结果与公式(8)计算相似度的结果进行对比,结果如图3所示. 图1 系统EAM随近邻数量变化曲线Fig.1 System MAE with the number of neighbors near the curve 图2 系统EAM随近邻数量变化曲线Fig.2 System MAE with the number of neighbors near the curve 图3 系统MAE随常数k变化曲线Fig.3 System MAE constant k curve of change 改进后的相似度计算方法相比于皮尔森相关系数法求解相似度又有了很大的提高,当k接近于1的时候,改进后的方法越接近于余弦相似度,皮尔森相似度是余弦相似度的改进型,能够对因评分尺度不同导致的相似度计算不准确的问题进行改善,从图中可以看出,当k趋近于1的时候,皮尔森相关系数法的优势不太明显,这是为什么呢? 首先,对于皮尔森相关系数法或者是修正余弦相似度,它们认为两个向量夹角越小,模长越接近那么这两个向量越相似,但是对于改进型的相似度计算方法,当k趋近1的时候,它判断两个向量相似的标准就发生了变化,也就是说,它几乎不考虑向量的模长,但并不是说改进后的方法完全不考虑用户评分尺度的问题,在3.3中,本文对目标项目进行评分预测时,利用公式(7)对预测结果进行了调整,这里就是针对评分尺度存在差距的用户进行的优化.从公式(9)可以分析得出,计算相似度的值在本文实验中仅仅决定了对应近邻用户对目标项目预测分值时的权重,最终预测结果是各个权值结果相加. 4.3.2 第二轮预测结果 同样的,第二次实验也得出了三张图,分别为图4、图5、图6.图5依然是当经过填充和降维处理后,用皮尔森相关系数法求解相似度时,系统MAE随近邻用户的变化曲线,这里的最佳近邻用户数量为300,目的是选出皮尔森相关系数法最优的近邻数量和改进的相似度计算方法做比较,最终得到图6. 图4 系统EAM随近邻数量变化曲线Fig.4 System EAM with the number of neighbors near the curve 图5 两种方法对应的MAE值对比Fig.5 Comparison of the two MAE values corresponding to the two algorithms 图6 系统MAE随常数k变化曲线Fig.6 System MAE constant k curve of change 从上面的六张图中可以看出,第二轮系统的MAE整体都高于第一轮,主要是因为第二轮训练集数据的稀疏度高于第一轮,因此,通过训练集建立的用户模型相对会产生较大的误差.所以,我们可以得出一个结论,在其他条件不变的情况下,训练集数据越稠密,建立的模型越可靠. 本文针对传统的相似性度量在数据稀疏情况下的不足提出了一种改进的协同过滤推荐算法,该方法通过对相似度计算进行一定的改进,并且结合评分矩阵的填充和降维,提高了推荐的准确性,同时减少了在寻找目标用户的近邻用户集时的时间损耗,提高了系统的可扩展性. [1] Zhao Nan.Practice and algorithm improvement of recommendation system based on mahout[D].Xian:Xidian University,2015. [2] Hoy E,Rajarajan M.Recommendations in a heterogeneous service environment[J].Multimedia Tools and Applications,2013,62 (3):785-820. [3] Suguna R,Sharmila D.Association rule mining for web recommendation[J].International Journal on Computer Science and Engineering,2012,4(10):1686-1690. [4] Ujwala H.Wanaskar,Sheetal R.Vij,Debajyoti Mukhopadhyay.A Hybrid Web?recommendation system based on the improved association rule mining algorithm[J].Journal of Software Engineering and Applications,2013,6 (8):396-404. [5] Soo-Cheol Kim,Kyoung-Jun Sung,Chan-Soo Park,et al.Improvement of collaborative filtering usingrating normalization[J].Multimedia Tools and Applications,2016,75 (9):4957-4968. [6] Cui Bao-jiang,Jin Hai-feng,Liu Zhe-li,et al.Improved collaborative filtering with intensity based contraction[J].Journal of Ambient Intelligence and Humanized Computing,2015,6(5):661-674. [7] Hoill Jung,Kyungyong Chung.Knowledge-based diedietary nutrition recommendation for obese management[J].Information Technology and Management,2016,17(1):29-42. [8] Ahmad Nurzid Rosli,Tithrottanak You,Inay Ha,et al.Alleviating the cold-start problem by incorporating movies facebook pages[J].Cluster Computing,2015,18(1):187-197. [9] Ghazanfar M A,Prtigel-bennett.Leveraging clustering approaches to solve the gray-sheep users problem in recommender systems[J].Expert Systemswith Applications,2014,41(7):3261-3275. [10] Liu Wen.Research on ecommerce recommendation algorithm based on singular value decomposition and k-means clustering[D].Wuhan:Central China Normal University,2015. [11] Gong Song-jie.A collaborative filtering recomme-ndation algorithm based on user clustering and item clustering[J].Journal of Software,2010,5(7):745-752. [12] Ye Hai-zhi,Liu Jun-fei.Collaborative filtering recommendation algorithm based on user reviews[J].Journal of Henan Normal University,2017,45(1):79-84. [13] Liu Hong-yan,He Jun,Wang Ting-ting,et al.Combining user preferences and user opinions for accurate recommendation[J].Electronic Commerce Research and Applications,2013,12(1):14-23. [14] Jang Zong-li,Wang Wei,Lu Chen.Improvement of collaborative filtering recommendation algorithm based on mean estimation[J].Computer Technology and Development,2017,27(5):1-5. [15] Balázs Hidasi,Domonkos Tikk.Speeding up ALS learning via approximate methods for context-aware recommendations[J].Knowledge and Information Systems,2016,47(1):131-155. [16] Wang Zan,Yu Xue,Feng Nan,et al.An improved collaborative movie recommendation system using computational intelligence[J].Journal of Visual Languages & Computing,2014,25(6):667-675. [17] Xia Pei-pei,Zhang Li,Li Fan-zhang.Learning similarity with cosine similarity ensemble[J].Information Sciences,2015,307:39-52. [18] Chen Gong-ping,Wang Hong.A personalized recommendation algorithm for improving pearson correlation coefficient[J].Journal of Shandong Agricultural University,2016,47(6):940-944. [19] Haw-ren Fang,Dianne P.O′Leary.Euclidean distance matrix completion problems[J].Optimization Methods and Software,2012,27(4-5):695-717. [20] Zhang Feng,Ti Gong,Victor E.Lee,et al.Fast algorithms to evaluate collaborative filtering recommender systems[J].Knowledge-Based Systems,2016,96:96-103. 附中文参考文献: [1] 赵 楠.基于Mahout的推荐系统实践及算法改进[D].西安:西安电子科技大学,2015. [10] 刘 雯.基于奇异值分解和k-means聚类的电子商务推荐算法研究[D].武汉:华中师范大学,2015. [12] 叶海智,刘骏飞.基于用户评论的协同过滤推荐算法[J].河南师范大学学报,2017,45(1):79-84. [14] 蒋宗礼,王 威,陆 晨.基于均值预估的协同过滤推荐算法改进[J].计算机技术与发展,2017,27(5):1-5. [18] 陈功平,王 红.改进Pearson相关系数的个性化推荐算法[J].山东农业大学学报,2016,47(6):940-944.3.3 基于用户评分均值的评分预测
4 实验结果与分析
4.1 实验环境和数据集介绍
4.2 实验评价指标
4.3 实验结果与分析





5 结 论
