一种GPU及深度置信网络的语音识别加速算法研究
2018-03-27景维鹏朱良宽刘美玲
景维鹏,姜 涛,朱良宽,刘美玲
1(东北林业大学 信息与计算机工程学院,哈尔滨 150040) 2(东北林业大学 机电工程学院,哈尔滨 150040)
1 引 言
语音识别作为人机交互的关键技术,已经成为“改变人类未来生活方式的关键技术之一[1].深度置信网络(DBN)作为深度学习中的一种典型模型,拥有强大的判别训练和连续建模能力,可以通过对比散度算法(CD)[2]进行快速训练,因此被广泛应用于语音识别领域[3].软研究人员将DBN引入语音识别中,在大词汇量语音识别系统中获得巨大成功[4].但是,语音数据规模的不断增加、DBN中的随机梯度算法(SGD)收敛速度比较慢和DBN参数过多等问题导致DBN模型训练速度越来越慢.因此如何提高在海量数据下DBN的训练速度成为迫切需要解决的问题.
为了提高DBN模型的训练速度,通常存在优化DBN结构和并行加速两种方法:1)在保证语音识别正确率的前提下,尽可能减少模型训练参数和优化模型训练过程;2)利用CPU集群或者GPU进行DBN模型的加速训练.本文的研究重点是第二种方法,即通过将语音数据进行划分,利用CPU集群或GPU加速DBN的训练.文献[5]通过将语音训练数据分成许多块到不同的机器进行训练,实现并行计算.文献[6]在训练中将语音数据划分成互不相交的子集,在具有上千CPU核的集群上进行训练.但是该方法面临着并行计算单元之间的通信开销问题,使得训练速度变慢.GPU强大的并行计算能力,被广泛应用于DBN模型的训练.文献[7]将GPU运用于大规模的连续词汇的语音识别中取得了较好的加速效果.2008年,Paprotski等人通过CUDA加速DBN模型的训练[8],取得较好的结果.文献[9]通过使用CUDA的库函数CUBLAS加速RBM的训练,取得了较好的成果,但是它的通用性较强,未结合语音数据的特点高效利用GPU的计算资源.文献[10]合理分解了DNB中RBM的计算过程,建立了CUDA模型,但是GPU的共享内存未充分利用.并且DBM模型存在着大量的参数,在单GPU下,模型参数很可能无法一次性存储到GPU内.文献[11]通过将RBM的权重矩阵进行分块处理,极大提高了训练速度.但是它没有考虑RBM参数存储的优化,没有建立合理的内存模型.文献[12]使用4块GPU卡加速DBN的训练速度取得了相对于单GPU 3.3倍的加速.但是,多GPU下通信的开销使得GPU的计算资源不能得到充分的利用.
综上,现有的利用GPU加速DBN模型存在单GPU内存有限、访问不同类型内存地址的延迟不相等、多GPU内参数交换成为制约训练速度提高的瓶颈等问题.因此,为有效利用GPU对DBN模型进行加速,提高语音处理的处理效率,本文提出opCD-k算法:将权重矩阵分片,充分利用GPU的共享内存,建立合理的存储模型;利用GPU的流处理进行并行处理,即数据传输和数据计算并行进行.在多GPU中进行数据并行,利用参数服务器模式,减少参数交换的通信量,并将opCD-k算法应用到多GPU中.
2 深度置信网络的训练
深度置信网络(DBN)是一种概率生成模型[13],由多层受限波尔兹曼机(RBM)和一层反向传播(BP)神经网络构成.如图1所示,是DBN的模型的训练过程,包括无监督逐层预训练RBM(pre-training)和有监督BP算法微调(fine-tuning):
受限玻尔兹曼机(RBM)是一类具有两层结构(可视层和隐含层)、对称连接的基于能量的随机神经网络模型.
由于语音信号的观测数据是连续的,RBM服从高斯-伯努利分布.一组给定状态(v,h)的高斯-伯努利RBM所具备的能量定义如公式(1)所示:
(1)
其中,vi∈Rm表示初始输入的语音特征值(m表示输入语音特征的维度),hj∈Rn表示语音特征提取后的语音特征向量(n表示提取后的语音特征的维度),θ={wij,ai,bj}是RBM的参数,其中wij表示vi和hj之间的连接权重,ai表示vi的偏置,bj表示hj的偏置.

图1 DBN模型训练过程Fig.1 DBN model training process
考虑到RBM特殊的结构,可见单元和隐含层单元的概率分布可用公式(2)和公式(3)表示:
(2)
(3)
其中sigm(x)为sigmoid激活函数.
RBM的学习是为了求出θ的值,通过最大化RBM在训练集上的对数似然函数得到RBM的参数θ,这是较为困难的.因此采用CD算法:以各个训练数据作为初始状态,通过k步Gibbs[14]采样得到近似值.这样,各参数的更新准则变为:
(4)
(5)
(6)
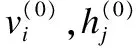
经过pre-training为DBN提供有效的训练初始值后,利用fine-tuning进行有监督训练,通过误差反向传播[15]算法对网络参数进行调整,从而达到全局最优点.
3 GPU实现
本文提出的opCD-k算法从合理建立权重矩阵分片的内存模型和基于流处理的并行两个角度实现单GPU对DBN模型的训练.同时在多GPU训练过程利用数据并行模型方案,采用参数服务器方式,并将opCD-k算法应用到多GPU中.
3.1 基于权重矩阵分片的内存模型
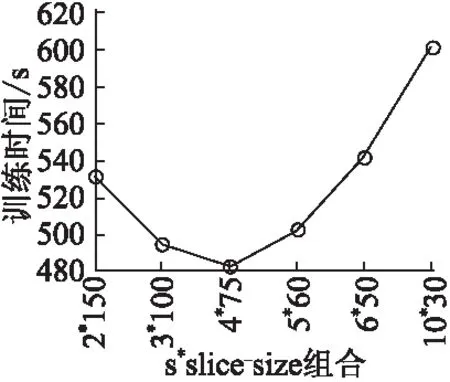
通过每次训练mini-batch[10]语音数据可以有效提高RBM的训练速度,但是mini-batch规模的过大也会造成RBM训练速度的降低.因此在训练中mini-bitch的数目(l)远小于m和n.vi∈Rm×l、ai,hj∈Rn×l、bj由于规模较小可以直接存储到GPU内存中,而RBM中的权重矩阵由于层间的相互连接很可能无法一次性存储到GPU中.因此我们将权重矩阵划分成几个子矩阵Wi(Wi∈Rm′×n,m′< 图计算过程Fig.2 Calculation process of 权重矩阵分片的内存模型提高了DBN模型的训练速度,但是参数的传输成为了制约DBN训练速度提高的瓶颈.例如更新每个Wi,Wi需要两次从CPU传输到GPU和一次从GPU传输到CPU.但在Wi传输过程中,GPU是处于空闲状态的. 图3 GPU流并行图Fig.3 GPU stream parallel diagram 结合CUDA的streams和CD算法的实现,在同一个stream中,1)和2)可以并行执行;在不同的stream中,2)和3)可以并行执行;1)和6)可以在不同的stream中并行执行.如图3所示:其中,HtD是从主机端(CPU)传输到设备端,DtH是设备端(GPU)传输到主机端(CPU). 上述的opCD-k算法可以提高DBN模型的训练速度,但是单GPU的计算能力是有限的.为了进一步提高DBN模型的训练速度,我们使用多GPU进行加速.考虑到DBN模型的全连接特性,我们选择数据并行的方法. 进行多GPU训练时,选择参数服务器模式:即一个GPU作为参数服务器,其他GPU作为工作节点.其工作流程是:工作节点将一次迭代计算得到的结果上传到参数服务器,然后参数服务器进行参数的更新操作;参数服务器将更新后的参数传输到工作节点,工作节点进行下一次的参数交换.并且在参数服务器进行参数交换的时候使用的是异步随机梯度下降方法.在这种情况下,参数服务器的带宽成为瓶颈.因此我们减少参数服务器和工作节点的通信量. 神经网络一般采用mini-batch来训练,每次迭代遍历mini-batch个数据,然后每次只加载mini-batch进入内存进行计算得到残差,为减少通信量,在工作节点上训练fetch个mini-batch数据,然后将获得的残差累加起来,最后和参数服务器进行参数交换,用来更新参数.在划分fetch次数时,采用热启动方式:在训练初期,应该使用较小的fetch,等模型收敛到一定程度之后再逐渐增加fetch的大小.同时我们将上述的opCD-k算法应用到多GPU中. 为验证CUDA对DBN训练加速的效果,本文采用TIMIT语音集.在训练过程中,采用early-stop方法.实验的输入数据是由Kaldi语音识别工具经过处理后的40维fMLLR特征拼接而成的440维语音特征参数,输出为183个音素状态分类.实验中的DBN模型共由6层RBM和一层BP网络组成.在预训练中,Gauss-Bernoulli RBM学习率为0.002,迭代次数为250,Bernoulli-Bernoulli RBM学习率为0.002,冲量因子为0.9,权重衰减为0.002.mini-batch数目为128. 在实验中,CPU型号是Intel(R) Xeon(R) CPU E5-2620 v2 @ 2.10GHz,GPU型号为Teskla K20m,由于K20m可以存储全部的训练参数,因此我们每次只向GPU传输权重矩阵的一部分来模拟实验效果.操作系统为Red Hat Enterprise Linux Server release 6.4,CUDA Toolkit 版本为7.0. 在本实验中,我们利用不同内存大小的GPU来验证基于权重分片内存模型的RBM的训练速度.由于实验中的RBM模型的参数可以存储到单个GPU内,因此为验证权重分片的内存模型的性能,我们每次从CPU传输到GPU内的权重矩阵只占整个权重矩阵的一部分,例如将权重矩阵的1/4传输到GPU内进行计算(在GPU核函数运行的过程中,始终只有1/4大小的权重矩阵位于GPU内存内).根据文献[11]我们拷贝权重矩阵的范围从1/64到1/4,并且设定streams的数量s=4,测试GPU完整训练一个RBM所需要的时间.表1为运行一个RBM迭代在GPU in Kaldi和不同GPU内存下的运行时间. 表1 RBM在不同GPU内存下运行时间Table 1 RBM running time in different GPU memory 其中GPU(1/64)表示将权重的矩阵的1/64从CPU传输到GPU内.从表1我们可以看出,通过合理划分GPU的内存模型,使用GPU1/8的内存就快于GPU in Kaldi 的训练速度 .并且随着权重矩阵分片的逐渐越大,权重矩阵的交换次数越来越少,GPU和CPU运行时间的加速比越来越大,到权重矩阵的1/4时,达到了最高的1.46倍的加速比.由此可以证明,在权重参数较大单GPU不能一次性存储整个权重矩阵时,基于权重矩阵分片的内存模型在单GPU实现中也可以取得较好的加速效果. opCD-k算法的实现依赖于对权重矩阵进行分片,这种分片导致权重矩阵的二次传输,并且流同步和调度将会引入更多的开销,从而影响RBM的训练速度,因此在本部分中,我们对这些参数进行合理的设置.以下实验中,假定GPU的内存只能存储权重矩阵的1/4. 4.3.1 slice_size大小的选择 opCD-k算法中的参数和GPU的内存关系可以被描述为: S×n×sizeof(float)≤M(G) (7) 其中s代表slice_size,slice_size是s的行数,代表GPU内存.对于给定的GPU,它的内存是一定的,因此s和slice_size的选择是提高RBM训练速度的重要因素.图4为在不同参数组合下训练一个RBM所需要的时间. 图4 不同参数组合下RBM训练时间Fig.4 RBM training time for different combinations of parameters 从图4可知:slice_size太大或者slice_size太小都不会取得较好的加速效果.当s最小时,训练时间是较长的,这是因为streams数量太少,导致GPU在数据传输过程中处于空闲状态.当参数组合为4×75时,训练时间最少.并且随着s的增加,训练时间逐渐增多,原因是s数目的增多使得需要更多的时间进行流同步和调度. 4.3.2 streams数目的选择 在本实验中,我们验证slice_size数目为50 (根据4.3.1得到最好结果为75,但是它的数目超过了1/4内存,因此选择50)的前提下streams数量的多少,对于RBM训练速度的影响.我们通过增加streams的数量,观察训练一个RBM迭代所需要的时间.训练结果如图5所示. 由图5可知,在s=1时,训练需要的时间是最多的,随着streams的增多,需要的时间越来越少.并且,在s=1和s=2之间的变化最大,这是因为只有一个stream的情况下,GPU需要等待所有的计算资源到达后才可以进行计算,因此使得这种变化最大.在s=8时,消耗时间最少,即可以将GPU的空闲时间完全利用.如果开启过多streams不会导致性能的提升,相反会造成性能下降,因为streams之间的调度和同步需要时间.同时我们发现,在s=5时,基本就可以充分利用GPU的计算资源.因此在下述实验中,s的数量设为5. 图5 不同streams下RBM的训练时间Fig.5 RBM training time for different streams 本部分中,我们将通过三个方面验证opCD-k算法对DBN训练性能的影响:1)一个RBM迭代训练需要的时间2)DBN训练需要的时间3)DBN训练的正确率. 4.4.1 RBM训练时间 本实验中,我们用3种方法在可视层节点为440的条件下,测试隐含层数目不同时,完成一个RBM迭代训练所使用的时间:1)opCD-k 算法;2)文献[12]中的单GPU;3)Kaldi中单GPU.实验结果如图6所示. 图6 不同模型下RBM训练时间Fig.6 RBM training time for different models 根据图6可知,对于不同规模的RBM网络,3种方法训练RBM的时间随着隐含层数目的增加而增多.最开始,opCD-k需要的时间最多,原因是它需要权重矩阵的交换和流同步,而其它两种方法的权重矩阵可以一次性存储在GPU内.随着隐含层的数目增加,opCD-k需要的时间少于[12]和kaldi中单GPU所需要的时间,因为它建立了合理的内存模型和流处理的并行模型.并且在隐含层数目为213时,取得了相对于kaldi最高1.7倍的加速. 4.4.2 DBN训练时间 我们用4种方式训练一个DBN模型:1)kaldi下单CPU 2)单GPU+CUDAC 3)Kaldi下单GPU 4)opCD-k算法,实验结果如表2所示. 表2 单GPU下DBN模型训练时间Table 2 DBN model training time for single GPU 由表2可知,opCD-k算法明显缩短了DBN模型的训练时间,相对于Kaldi语音识别工具,取得了1.5倍的模型加速,相对于CPU最高的加速比为223.实验结果证明opCD-k算法在DBN训练中可以取得较好的加速效果. 4.4.3 DBN训练正确率 在加快DBN模型训练速度的同时,必须保证模型的正确率.表3是利用3种方式运行DBN模型音素的错误识别率比较:1)Kaldi下CPU 2)Kaldi下GPU 3)opCD-k 算法: 表3 单GPU下DBN模型训练错误率Table 3 DBN model training error rate for single GPU 由表3可知,利用opCD-k算法训练DBN相对于Kaldi的GPU模式,错误率的相对损失控制在1%内.出现性能损失的原因是使用了CUDA的expf(x)函数,并且权重矩阵参数使用了单精度浮点数.实验结果证明了优化后的单GPU可以在提高训练速度的同时,可以保证DBN模型训练的正确率. 如表4所示,是我们利用4种方法训练DBN模型需要的时间:1)Kaldi下单GPU 2)Kaldi 下多GPU 3)文献[12] 中多GPU实现4)优化的多GPU: 表4 多GPU下DBN模型训练时间Table 4 DBN model training time for multi-GPUs 从表4可以发现,优化后的多GPU训练方法只用了0.54小时,明显缩短DBN模型的训练时间.相对于Kaldi中的多GPU和文献[12]中的多GPU实现分别取得了1.35和1.2倍的加速.并且相对与Kaldi中的单GPU实现取得了4.6倍的加速.实验结果证明了优化后的多GPU实现在DBN训练中可以取得较好的效果. 表5 多GPU下DBN模型训练错误率Table 5 DBN model training error rate for multi-GPUs 如表5所示,是利用这四种方式训练DBN模型的错误率.从表5中我们可以发现,优化后的多GPU实现,相对于Kadli的多GPU实现有1.6%的性能损失.相对于取得的加速效果,这种模型损失是可以接受的. 为了提高基于DBN的语音识别的训练效率,本文提出了opCD-k算法:将权重矩阵分片,建立合理的存储模型;采用GPU的流处理技术.并且在多GPU中采用参数服务器,减少参数的通信量.实验结果证明,优化后GPU并行算法,在保证DBN模型正确率的前提下,可以加速模型的训练速度.下一步,我们将在DBN模型的训练中加入噪声,提高模型的鲁棒性. [1] Liu Chun.Research progress of speech recognition technology[J].Gansu Science and Technology,2008,24(9):41-43. [2] Hinton G E.Training products of experts by minimizing contrastive divergence[J].Neural Computation,2002,14(8):1771-1800. [3] Mohamed A R,Dahl G E,Hinton G.Acoustic modeling using deep belief networks[J].IEEE Transactions on Audio Speech & Language Processing,2012,20(1):14-22. [4] Kim J,Lane I.Accelerating large vocabulary continuous speech recognition on heterogeneous CPU-GPU platforms[C].IEEE International Conference on Acoustics,Speech and Signal Processing(ICASSP2014),2014:3291-3295. [5] Seide F,Li G,Yu D.Conversational dpeech transcription using context-dependent deep neural networks[C].International Conference on Machine Learning(ICML2012),2012:1-2. [6] Park J,Diehl F,Gales M J F.Efficient generation and use of MLP features for Arabic speech recognition[C].Conference of the International Speech Communication Association(INTERSPEECH2010),2010:236-239. [7] Sainath T N,Kingsbury B,Ramabhadran B,et al.Making deep belief networks effective for large vocabulary continuous speech recognition[C].IEEE Workshop on Automatic Speech Recognition and Understanding(ASRU 2011),2011:30-35. [8] Daniel L Ly,Paprotski V.Neural networks on GPUs:restricted boltzmann machines[C].IEEE Conference on Machine Learning and Applications(ICMLA2010),2010:307-312. [9] Ly D,Paprotski V,Yen D.Neural networks on GPUs:restricted boltzmann machines [R].Department of Electrical and Computer Engineering,University of Toronto,Canada,2008. [10] Lopes N,Ribeiro B.Towards adaptive learning with improved convergence of deep belief networks on graphics processing units[J].Pattern Recognition,2014,47(1):114-127. [11] Zhu Y,Zhang Y,Pan Y.Large-scale restricted boltzmann machines on single GPU[C].IEEE International Conference on Big Data(IEEE BigData 2013),2013:169-174. [12] Xue Shao-fei,Song Yan,Dai Li-rong.Fast training algorithm for deep neural network using multiple GPUs[J].Journal of Tsinghua University (Science and Technology),2013,53(6):745-748. [13] Roux N L,Bengio Y.Representational power of restricted boltzmann machines and deep belief networks[J].Neural Computation,2008,20(6):1631-1649. [14] Gentle J E.Monte carlo strategies in scientific computing[J].Siam Review,2002,44(3):490-492. [15] Li Xuan,Li Chun-sheng.Alternating update layers for DBN-DNN fast training method[J].Application Research of Computers,2016,33(3):843-847. 附中文参考文献: [1] 柳 春.语音识别技术研究进展[J].甘肃科技,2008,24(9):41-43. [12] 薛少飞,宋 彦,戴礼荣.基于多GPU的深层神经网络快速训练方法[J].清华大学学报(自然科学版),2013,53(6):745-748. [15] 李 轩,李春升.一种交替变换更新层数的DBN-DNN快速训练方法[J].计算机应用研究,2016,33(3):843-847.
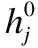
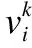
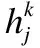
3.2 流处理的并行模型

3.3 多GPU实现
4 实验结果与分析
4.1 实验环境
4.2 权重矩阵分片模型下RBM的训练速度

4.3 opCD-k算法参数的调整

4.4 改进的单GPU下DBN性能实验



4.5 改进的多GPU下DBN性能实验


5 结束语
