高校图书馆员数据素养能力评价指标体系构建研究
2018-03-25朱朝凤
朱朝凤
(辽宁工业大学图书馆,辽宁 锦州 121001)
1 引言
数据素养(data literacy)一词最初是在美国教育界流行起来的,关于它的定义和内涵国内外很多研究者都进行过阐述。纵观众多研究者的表述,他们大多支持数据素养是人们有效且正当地发现、评估和使用信息及数据的一种意识和能力。只是国外研究者侧重于利用数据来演绎结果、推导结论从而进行决策,而国内的研究者则侧重于数据获取处理以及数据意识评估。笔者所指的数据素养是指人们运用数据思维收集、分析、使用、传播数据信息的能力以及在此过程中体现出来的数据伦理和数据规范[1]。
国内关于图书馆员数据素养的研究中,多将馆员数据素养能力现状以及提升策略作为研究重点,而有关馆员数据素养能力评价指标的研究较少,这就给客观评价馆员数据素养能力带来了困扰。鉴于此,笔者通过文献调研法和专家访谈法就该命题展开研究,旨在构建科学客观有效的高校图书馆员数据素质能力评价指标体系。在对现有研究成果进行考证的基础上,观照当前高校图书馆信息素养能力建设的实践,采用层次分析法和熵权法确定复合权重,对现有成果所涉及的评价指标体系进行深入研究,对相关指标加以筛选和整合,以期构建出一套能科学全面客观公正评价高校图书馆员数据素养能力的指标体系,以有效指导高校图书馆数据素养教育,提高馆员数据素养能力。
2 高校图书馆员数据素养能力原始评价指标及其筛选
2.1 选取原始评价指标
评价指标能够量化细化评价主体中定性的部分,把抽象的评价目标变得具体可操作。笔者所提及的高校图书馆员数据素养能力原始评价指标来源于已有研究成果和相关领域专家学者的意见。在阅读了与之相关的文献后,分析归纳了现有成果构建的评价指标,选取那些出现频率高、具有代表性的指标,纳入馆员数据素养能力原始评价指标体系。其次,选取20位图书馆界的研究馆员作为调查对象,听取他们的建议,对初建的图书馆员数据素养评价指标体系进行补充和完善。最终,构建了一个包括6个一级指标、31个二级指标的高校图书馆员数据素养能力评价的原始指标体系。具体包括:
(1)数据意识:认识到数据的重要性;能够有使用数据解决问题的意识;能认识数据是科研过程中重要因素;能够认识到科学数据具有生命周期;能够以严谨认真的态度对待使用科研中产生的数据;具有细化、具化表达数据需求;能够保证数据的公正性与开放性[2]。
(2)数据获取能力:能够熟悉各类数据源;具有熟练检索与收集各种数据的能力;能够对获取的各种显性隐性数据准确解读;了解数据类型格式等基础概念。
(3)数据处理能力:能够熟练使用数据分析工具,呈现数据分析结果;能够有效选择数据分析方法;理解数据代表的含义;对数据的分析结果认定、质疑及改进解释能力;对数据结果能够进行多角度呈现和建模;能够准确解释统计分析结果。
(4)数据转换能力:能够正确描述数据,准确表述结果;了解并熟练运用本学科领域数据标准;能够采用统计图来表征揭示数据中隐含的趋势变化;能够利用数据的统计分析结果支撑结论;能够依据数据分析提供决策支持;能够利用数据及数据分析结果撰写论文等;能够熟练使用转换平台及工具[3]。
(5)数据评价能力:能够审核数据的准确性,剔除错误或无效数据;能够批判性地评价质疑数据;确保数据的可信敏感;能够认识到数据所反映事实有的局限性[4]。
(6)数据伦理:对数据真实性负责;规范数据著录格式;遵守学术道德及法律准则。
2.2 研究方法
笔者采取的研究方法分别是层次分析法和熵权法。利用这两种分析方法分别确定指标权重,然后依据这两种权重计算复合权重作为各指标的最终权重。
层次分析法是通过逐层比较多种关联因素来为分析、决策、预测或控制事物的发展提供定量依据。它是定性和定量的结合,是系统化层次化的分析方法。[5]首先按照各指标的重要程度构建判断矩阵,然后将判断矩阵按列进行归一化,最后确定各指标权重值。具体公式如下:

计算完权重后还要通过计算一致性检验指标C r来评价指标权重分配是否合理。其中,Cr=CI/RI,其中CI=(λmax-n)/(n-1),如果CR值<0.1,则权重构成合理,否则就要请专家修正判断矩阵。RI的数值见表1所示。

表1 RI-n对应表[6]
熵权法是一种客观赋权方法,它主要是根据事物变异性的大小来确定客观权重。指标的信息熵越小,指标的变异程度越大,它所提供的信息就越多,在综合评价中所能起到的作用越大,其权重值也越大。[7]首先要对各个指标的数据进行归一化处理,然后计算各指标的信息熵,依据信息熵确定各指标效用值,最后计算各指标的权重值:假设有m个指标X1、X2……、Xm,其归一化后的数据为 Y1、Y2……、Ym,首先利用公式(5)进行数据归一化处理,然后在归一化数据的基础上计算信息熵Ei,计算公式为(6),利用公式(7)计算各指标的效用值Di,最后利用公式(8)计算指标权重值Wi。
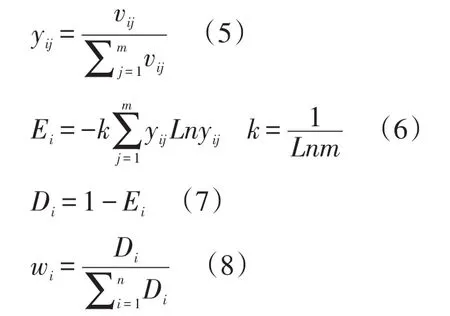
单一利用层次分析法进行数据分析,尽管实现了数据评价由定性向定量的转化,从模糊向精确的转化,但在指标权重的确定方面仍存在一定的人为主观性,而熵权法能够修正层次分析法中指标的主观权重,利用两种分析方法的组合权重作为高校图书馆员数据素养评价指标的构建依据,能有效地解决评价中存在的仅靠主观臆断选取专家的缺陷,减少了权重确定的主观性,为高校图书馆员数据素养能力指标的构建提供了一种新的方法。计算公式为:

2.3 数据素养评价指标的筛选
首先,选取原始变量,即在查阅了相关文献及咨询专家的基础上,构建了高校图书馆员数据素养能力评价指标体系;其次,分别应用层次分析法和熵权法对初建的指标进行分析评价,进而对他们进行整合优化,力争使每个指标对测评结果具有显著性影响;在此基础上重建高校图书馆员数据素养评价指标体系。
3 基于AHP及熵权法的高校图书馆员数据素养能力评价指标体系构建
3.1 建立评价因素集
根据前文构建的数据素养原始评价指标体系,准则层的因素集为 A={A1,A2,A3,A4,A5,A6}={数据意识,数据获取能力,数据处理能力,数据转换能力,数据评价能力,数据伦理},其下属的各个指标层的因素集分别为:A1={A11,A12,…,A17},A2={A21,A22,…,A24},A3={A31,A32,…,A36},A4={A41,A42,…,A47},A5={A51,A52,…,A54},A6={A61,A62,A63}。
3.2 层次分析法权重的计算
笔者按照高校图书馆员数据素养能力原始评价指标体系,针对各项指标重要程度设计调查问卷,邀请高校图书馆中从事该领域研究的15名专家学者对前期构建的指标因素进行两两比较,在对各位专家的结论进行归纳汇总的基础上,对各因素按重要程度进行权重赋值(“同样重要”—1、“稍重要”—3、“相当重要”—5、“明显重要”—7、“绝对重要”—9,介于中间的数值用2、4、6、8表示),构建判断矩阵,并以此为基础计算得出各指标权重。

表2 准则层判断矩阵

表3 数据意识判断矩阵

表4 数据获取能力判断矩阵

表5 数据处理分析能力判断矩阵

表6 数据转换能力判断矩阵

表7 数据评价能力判断矩阵

表8 数据伦理判断矩阵
通过计算得到一致性检验指标的值,见表最后一行数据,CR<0.1,权重构成合理。
3.3 熵权法权重的计算
依据熵权法的计算步骤,按照公式(5、6、7、8),计算出高校图书馆员数据素养能力评价指标的权重值Wi(2),具体数值如下:
(WA1(2),WA2(2),…,WA6(2))=(0.2181,0.1058,0.2002,0.2398,0.1086,0.0824)
(WA11(2),WA12(2),…,WA17(2))=(0.131,0.143,0.131,0.16,0.253,0.104,0.131)
(WA21(2),WA22(2),…,WA24(2))=(0.235,0.306,0.255,0.204)
(WA31(2),WA32(2),…,WA36(2))=(0.1588,0.1963,0.1809,0.1963,0.1588,0.109)
(WA41(2),WA42(2),…,WA47(2))=(0.125,0.166,0.125,0.125,0.08,0.199,0.18)
(WA51(2),WA52(2),…,WA54(2))=(0.47,0.2738,0.273,0.207)
(WA61(2),WA62(2),WA63(2))=(0.325,0.246,0.43)
3.4 组合权重的计算
利用公式(9),将层次分析法得到的原始权重Wi(1)和熵权法得到的客观权重 Wi(2)进行组合,得到高校图书馆员数据素养能力各评价指标的组合权重Wi见表 9。

表9 高校图书馆员数据素养能力评价指标权重系数
5 结论
层次分析法是一种主观赋值方法,它依据的是相关专家固有的经验判断,而熵权法是在挖掘原始数据蕴含信息基础上的一种客观赋权方法。利用这两种方法的结合确定组合权重,能够减弱主观臆断选取专家的缺陷,减少权重确定中的人为主观性。笔者在深入研究高校图书馆员数据素养能力相关文献的基础上,结合该领域专家的问卷调查,构建了6个一级指标、31个二级指标作为原始评价指标。采用层次分析法计算出指标权重Wi(1),再利用熵权法计算出权重Wi(2),再依据公式计算出组合权重作为高校图书馆员数据素养能力评价指标的最终权重,并据此对原始评价指标进行了基准性和鉴别性的划分(见表9),避免了指标间的重复,优化重构了高校图书馆员数据素养能力评价指标体系,以期为高校图书馆员数据素养能力评价提供新的思路和方法。
