机构规范文档构建中机构筛选方法研究
2018-03-22,,
, ,
机构在现代汉语字典中被定义为“泛指机关、团体或其他工作单位”,全国组织机构代码管理中心把组织机构定义为“依法成立的机关、事业、企业、社团及其他依法成立的单位”。本文涉及的“机构”指文献中的机构,包括实体机构和虚拟机构。虚拟机构主要是指分散于不同时间、空间和组织边界的一起工作完成共同任务的团体的结合[1],如网络社区、专家委员会等,因此机构数据的数量之大、类型之复杂可见一斑。
机构数据具有以下两大突出特点:一是机构数据来源广泛,类型丰富;二是机构数据量大、更新速度快,这也是机构规范文档构建难度大的主要原因。机构的来源具有多种途径,包括文献、网络等。文献中作者标注的作者单位准确率高,文献数据相对容易获取,但是信息不够丰富,仅包含机构名称、地址、邮编等。网络的迅速发展和高共享性,意味着其中包含的机构信息比较丰富,来源广泛,但是信息质量良莠不齐。机构合并、拆分、撤建等,新机构的不断产生,传统机构的淘汰,从数量的角度讲机构具有基数大且增长速度快的特点。以上因素增加了机构规范文档构建的难度。
机构数据的特征造成了机构名称的多样性、机构间关系的复杂性和模糊性,由此导致了用户在开展信息检索、学术统计等科研活动的不准确性。因此,有必要通过构建机构规范文档对机构数据进行规范。全国科学技术名词评定委员会出版的《图书馆·情报与文献学名词》第一版中,把规范文档定义为“由规范记录组成的计算机文档。其作用是实行规范控制,即保证机读目录中文档标目的一致性,以便有效地实现对机读目录的统一管理,包括主题规范档、名称规范档和丛编规范档”[2]。机构规范文档主要是通过实行规范控制保证机构的唯一性和稳定性,把机构的不同名称添加到规范文档中,对其实体进行有效识别,并对机构间的关联关系进行有效揭示。由于机构数量级大,无法在短时间内完成所有机构的规范,因此需要从大量的机构数据中进行筛选。在机构规范文档构建策略的基础上对机构的筛选方法进行研究,以用于机构规范文档的初步构建。
1 机构规范文档构建的研究现状
关于机构规范文档的构建,国内外均开展了相关实践工作。由联机计算机图书馆中心(Online Computer Library Center,OCLC)主导,主要针对名称规范问题开展了虚拟国际规范文档项目,链接国家图书馆及权威数据库的规范名称,形成包括个人、机构、会议和地名的全球共享、可复用的规范文档,其中仅关于团体的规范记录已达到500万条以上[3]。由欧洲IST计划资助的规范文档链接与探索项目,致力于开发一种分布式搜索系统的模型架构,收集已经存在的名称权限文件,然后将这些数据汇聚在一起,旨在建立基于用户需求的通用名称授权文件[4]。
中国国家图书馆、中国高等教育文献保障系统管理中心、台湾汉学研究中心、香港特别行政区大学图书馆长联席会共同参与构建了中文名称联合数据库检索系统,主要包括名称规范库的构建、对规范规则和规范系统的研究等,涉及个人名称、团体名称、会议名称、题名等相关记录的规范[5]。国家工程技术图书馆针对论文中的机构要素,建立的机构规范文档主要包括5类数据:机构规范名称和非规范名称的对照,机构基本属性(所在地域、机构类型、所属学科等),机构上下级隶属关系,机构中英文名称对照,机构名称变迁[6]。
国内外开展了一系列关于机构名称规范的实践活动,并形成了一定数量的规范记录。由于机构数据的海量特征,如何选取具有代表性的机构开展机构规范是机构规范文档构建的重要环节。
Ringgold标识数据库对机构数据进行了规范,通过唯一ID来实现机构的唯一识别[7]。其中的机构类型包括学术机构、公司企业、政府部门、医疗机构、卫生组织、公益机构、公共机构等7个大类,涵盖的范围广泛且不断进行更新和补充。微软学术[8]从出版物及其元数据中获取作者机构的相关信息,并对其进行规范,按照学科对机构进行筛选。以各学科领域的被引频次、h指数为标准,截至2018年5月,已完成规范的机构总数为18 717,但相对于庞大的机构数量,这只是其中的极小部分。万方数据构建机构数据库,按照机构类型、领域以及当前机构类型的重要指标等进行机构的规范,机构数据已达到近20万条[9]。机构规范文档的建设是一个循序渐进的过程,如何从大量的机构数据中选出具有代表性、覆盖性强的数据是构建机构规范文档的首要问题。
ESI(InCites Essential Science Indicators)是以Web of ScienceTM核心合集数据库为基础的计量分析数据库,它提供了全球超过5 000多个规范化的机构名称,有利于开展以机构为检索点的信息检索和相关的计量分析工作。ESI主要是通过论文数、论文被引频次、论文篇均被引频次、高被引论文、热点论文和前沿论文、学科领域等指标对机构进行衡量和筛选。以上指标具有很高的准确性,能充分地从文献的角度实现对机构的评价[10]。
中国医学科学院医学信息研究所在构建基于中国生物医学文献数据库(CBM)的机构规范文档时,采用的原则为边建设边服务,进行阶梯式可循环式建设。首先对核心类型的机构进行形式规范的基础上进行一般描述规范,并引入非核心类型的机构规范;然后进行CBM中作者机构内部关系的规范,优先构建核心机构;最后构建CBM作者机构名称与外部机构规范文档映射关系[11]。在整个构建过程中是按照文献年代、文献频次、语种、机构类别、机构等级、期刊等级、所在地区等因素对初步的机构数据进行筛选。采用的方法是初级阶段进行部分数据的部分规范,然后加入新的非规范数据,进行更深层次的规范。中国科学院在构建机构名称规范库时的建设思路是以中科院为突破口,由中科院逐步覆盖到高等院校、省级研究所、政府、企业研究院等其他的科研机构[12]。
上述为机构规范文档初步建设提供数据源的筛选方法不够全面,是由点到面的构建策略。本文提出由线到面的构建策略,涉及到多种不同领域、不同类型的机构,使初步筛选出的机构更具全面性和代表性。另外,大多构建过程主要从自身的数据和学科需求出发。如中国医学科学院医学信息研究所主要涉及的机构是与医学相关的,由此导致筛选机构的覆盖面不够广,故本文在对筛选方法进行研究时,不涉及学科、地域、研究内容的限制,筛选结果更具全面性。
2 机构筛选方法的研究思路
研究机构规范文档的构建策略,为机构规范文档的构建提供基础数据,即研究如何从大量机构中获取具有代表性的机构数据的方法。利用归一化方法把大量的机构数据通过模糊算法限制在一定的范围,主要以机构发文的稳定性、活跃度和机构的学科影响力为指标,获得具有全面性和代表性的机构。
2.1 机构规范文档的构建策略
构建机构规范文档是一个长久而艰巨的任务,需要循序渐进地开展,首先对活跃度高、具有代表性的机构进行规范,然后不断更新和补充,涉及数据采集、数据筛选、名称规范、关系构建以及数据的存储等主要环节(图1)。

图1 机构规范文档构建流程
机构规范文档的构建是一个循序渐进、循环往复的过程。通过图1所示流程把无序的机构数据转化为有序的机构数据,形成机构规范文档,并且要把新的来源数据与已有的机构规范文档进行匹配,对其进行更新和补充。鉴于文献数据库中的机构数据具有准确性高、易获取等特点,从文献数据库中获取机构相关数据,对海量的机构数据进行筛选,并对筛选结果进行名称规范和关系构建,最后进行数据存储并应用于新一轮的规范文档的构建,以实现对机构规范文档的补充和更新。
基于机构海量的数据特征,机构筛选作为其中一个关键环节,有必要对其筛选方法进行研究,且有利于机构规范文档构建工作的循序开展。
2.2 机构筛选的模型与方法
数据归一化,即把需要处理的数据经过处理后限制在需要的范围内,其具体作用是归纳统一样本的统计分布性[13]。模糊算法是指用隶属关系将数据元素构建成模糊集合,确定隶属函数。机构数据筛选的过程即为数据归一化的过程,根据其分布性特征对其进行筛选,构建模糊集合并确定其隶属函数,主要包括机构提取、机构分析、文献计量、机构筛选4部分(图2)。

图2 机构筛选方法
2.2.1 机构提取
基于机构来源的特征,选取文献数据库中的机构数据作为原始数据,它具有准确性高、易获取、机构类型丰富等优点。获取中文发文的中国机构和外文发文的中国机构数据,主要包括机构名称、中文文献ID、中文文献的中图分类号、外文文献ID。
对获取的数据进行清洗、规范、归并和分类。根据文本相似度计算去除机构名称的重复值和明显错误的数值,并对机构名称对应的计量指标进行归并。对英文机构名称进行规范,转换为规范的中文机构名称,根据文本相似度与已有的中文机构名称进行匹配,并对其对应的计量指标进行归并。
由于不同机构类型在发文数量等方面的差异性,需要对机构数据进行分类,通过对大量数据的分析构建机构类型的特征词表(表1),对机构类型进行分类,使筛选结果更具全面性和均衡性。
本文主要是在对机构类型分类的国家标准的基础上进行延展得到新的机构类型分类。《组织机构类型(GB/T 20091-2006)》主要将机构类型分为企业、机关、事业单位、社会团体、其他机构和组织(主要包括基金会、宗教活动场所、农村村民委员会等)[14]。以国家标准为基础,结合科研机构、高校、医疗机构等具有较突出的发文水平,对机构类型重新分类,包括学前与初中等教育机构、高等教育机构、医疗机构、事业单位、科研机构、行政机构、公司企业、社会团体、其他组织和机构9类机构类型。根据不同机构类型中机构名称的特性,建立机构名称的特征词表;基于特征词表对机构进行类型分类,并在分类过程中不断对特征词库进行补充,保证分类结果的准确性和全面性。

表1 机构类型特征词
2.2.2 机构分析
从机构发文的活跃度、机构学科影响力、机构发文稳定性3方面对机构进行分析和筛选。以机构的发文量表征机构的活跃度,以机构的连续发文表征机构的稳定性,以机构学科的发文和被引频次表征机构的学科影响力,并以此构建机构筛选指标体系,如图3所示。

图3机构筛选指标体系
2.2.3 文献计量
根据机构筛选的指标体系和文献数据库中的“机构—文献—学科”的对应关系,运用文献计量方法对文献的被引频次、文献对应的学科的发文和被引情况、机构的发文情况进行统计分析,得到近10年内的每年发文量、SCI发文量、机构对应学科的发文量和被引频次。根据以上指标设计筛选方法,构建机构的模糊集合,确定隶属函数。
2.2.4 机构筛选
本文主要采用机构的中文发文量、机构的SCI发文量、机构的年均发文量、机构学科发文量和被引频次等指标。机构的SCI发文主要是均衡某些机构倾向国外发文,这在很大程度上也能反映出其活跃度,从而增强了筛选结果的全面性。用机构的学科发文作为衡量机构学科活跃度的指标之一,可以筛选出某一学科较为突出而综合能力相对较弱的机构,使筛选结果更具全面性。
基于模糊算法将大量的机构数据,转化为筛选后的机构集合并确定隶属函数。其中模糊集合的筛选是以得到的机构数据的集合能够覆盖SCI的发文机构和学科表现突出的机构为依据,隶属函数以获得的数据集合对应中文年均发文为依据(图4)。

图4 机构筛选方法流程
其中,若M为SCI发文机构组成的集合,那么A为集合M中的中文年均发文的最小值;若N为学科水平较为突出的机构组成的集合,那么B为集合N中对应的中文年均发文的最小值。机构信息筛选列表主要包括机构名称、机构每年的发文量、机构年均发文、机构SCI发文、是否属于学科水平较高的机构等信息。年发文量不连续为零的机构,作为衡量其稳定性的指标,对机构进行初步筛选,选择年均发文≥1的机构,作为衡量其活跃度的指标。按照机构的年均发文值对机构信息列表进行排序。如果此时
SCI发文机构中的对应的中文年均发文的最小值A小于等于学科水平较高的机构中对应的中文年均发文的最小值B,即A≤B,就以A为机构筛选的阈值;如果A>B,则以B作为机构筛选的阈值。按照不同的机构类型重复以上步骤,分别获取机构的筛选阈值。该筛选方法能在很大程度上涵盖外文发文的机构和学科表现较为突出的机构,对于获取活跃度较高的机构具有很好的代表性。
3 机构筛选的实证研究
以中国科学技术信息研究所建设的中国知识链接数据库的机构数据为例,按照以上筛选方法进行实证研究,确定各机构类型的筛选阈值(图5)。

图5 机构筛选步骤
3.1 数据采集
本文数据主要来源于中国知识链接数据库和Web of Science,获取2007-2016年的中文文献中的机构、文献、学科以及中文机构的SCI发文等数据。
3.2 数据处理
对数据进行初步处理,包括去除明显错误的数据、去重、中英文对照以及对应数据的归并,经过处理后获得1 159 247条机构数据。按照机构类型的特征词表对其进行分类,在分类的过程中不断提取新的特征词,也可组合特征词,实现对机构数据机构类型的划分。对划分数据类型后的机构进行统计,各机构类型的数目占比与其对应的发文量的所占比例具有很大的差异性,详见表2。
从表2发现,在机构数目占比排名靠前的初中等教育机构和事业单位,在类型机构的发文总量的占比中并不占优势,反而机构数量较少的高等教育机构、医疗机构的发文总量占比较多,不同的机构类型之间的差异也比较明显。由此可认为机构类型的划分是合理且必要的,有利于机构筛选的均衡性。
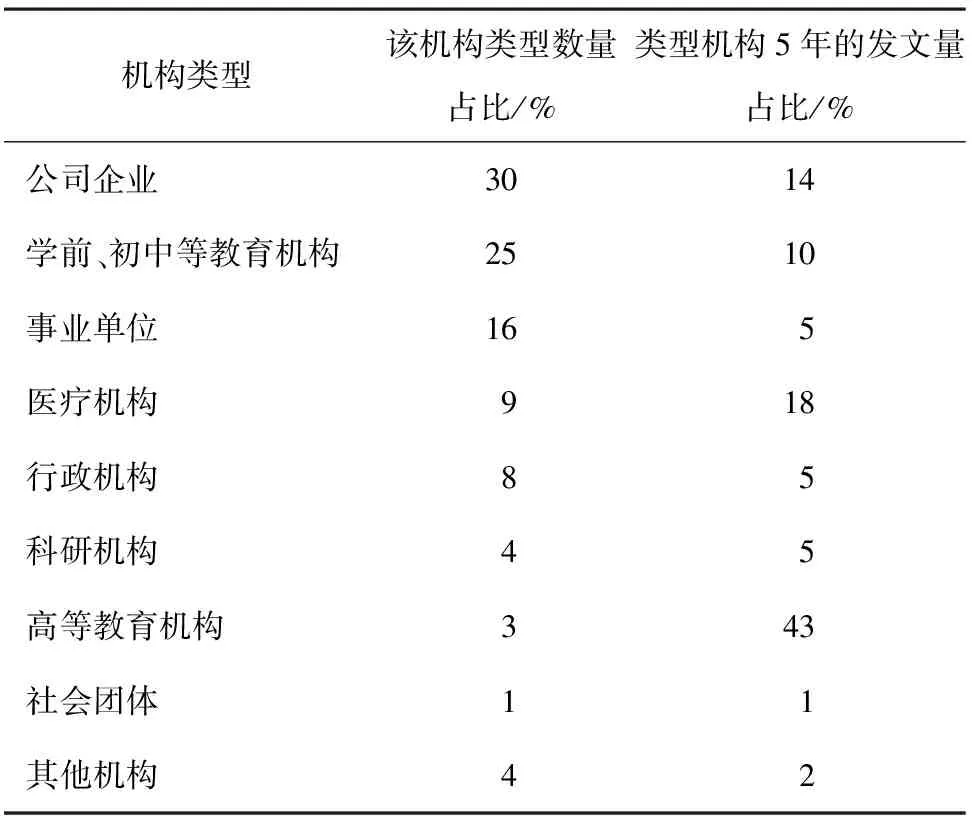
表2 各机构类型数量、发文占比
3.3 数据筛选
按照机构筛选的指标体系,运用文献计量获得指标数据:机构年发文量、机构年均发文量、机构的学科发文量和被引频次、机构SCI发文量。以机构学科的发文量和被引频次作为衡量机构学科影响力的指标,选取排名前100的机构作为学科水平较为突出的机构。构建机构信息列表,包括机构名称、机构年发文量、机构年均发文量、机构SCI发文量、是否属于学科水平较突出的机构。
按照图4中的机构筛选方法,构建机构的筛序集合,并确定其筛选阈值(表3)。根据阈值对机构数据进行筛选,最后获得不同机构类型中的代表性数据共20 433条。
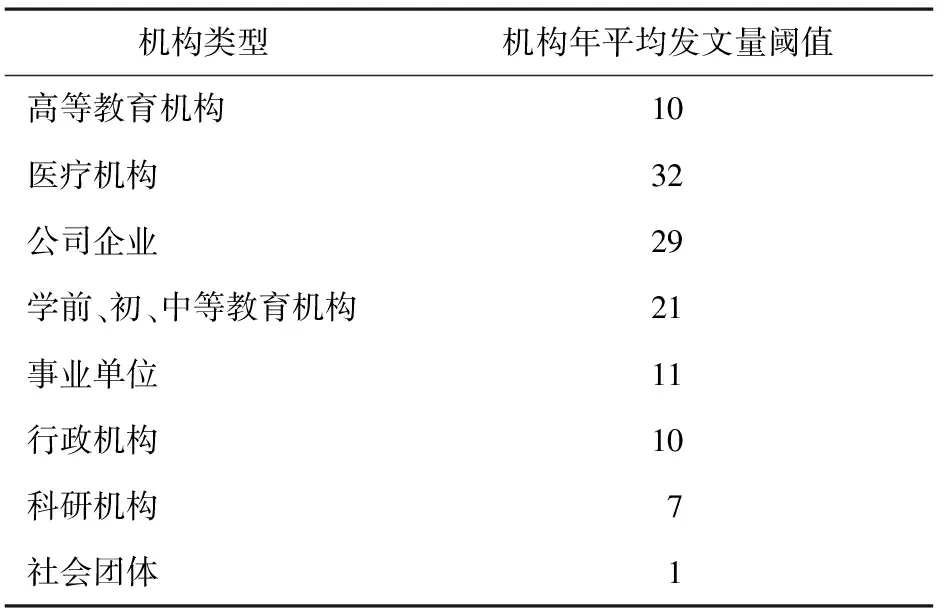
表3 机构筛选阈值及结果
3.4 结果分析
对筛选后的数据进行统计分析,各机构类型数量在机构总数的比例相对均衡,占比在10%左右。对比筛选前后的各机构类型中机构数量占比发现,高校、科研机构、医疗机构的占比明显增加,其发文数量是比较突出的,证明筛选的结果把各机构类型的发文水平涵盖其中,而且筛选后的各机构类型相对均衡,使获得的数据具有全面性和代表性。筛选后的机构数目是筛选前机构数目的7%左右,筛选后机构的总发文量占筛选前的73%左右。从统计角度看,筛选后的机构能够代表筛选前的机构,属于需要首先重点规范的机构。
4 结语
基于机构规范文档的构建策略,对机构规范文档构建中的机构筛选方法进行研究。从机构的稳定性、活跃度、学科影响力出发,构建机构筛选的指标体系、隶属函数,使筛选结果具有代表性和全面性,便于快速有效地对大量数据进行筛选,进而有效开展机构规范工作。另外,可以根据此筛选方法构建自动化的数据筛选流程,有利于机构规范文档管理系统的构建,实现其自动化管理。
