DOLDA模型设计与主题演化分析
2018-03-16郑山红李万龙
蒋 权,郑山红,刘 凯,李万龙
(长春工业大学 计算机科学与工程学院,吉林 长春 130012)
0 引 言
近年来,各类信息源的存储量都呈现海量特征,以文本数据的增长最为显著,从海量文本数据中及时提取热点主题并对主题演化分析逐渐得到相关研究者的关注,由于LDA(latent dirichlet allocation)在演化领域具有独特的优势,所以,许多基于LDA模型的扩展模型相继被提出[1-4]。
C.Wang等[5]针对不同时间序列的主题分布,提出反映主题在时间上内容和强度变化的TOT(topic over time)模型,其中假设模型是基于正态分布的,但正态分布与多项式分布非共轭分布,模型参数推理和估计上是比较困难的;R.Nallapati等[6]提出多时间粒度主题演化的MTTM(multinomial topic tomography),虽然该模型采用泊松分布作为共轭先验来建模,但不具备在线处理文本的能力;Hoffman等[7]提出的OLDA,按照数据流来划分大数据文档比批处理LDA算法快2-5倍,但OLDA主题建模需要包括细分的批处理文档大小在内的3个参数,这样会使主题模型的精度降低,并且OLDA容易产生新旧主题混合而导致不能及时的发现新的主题;崔凯等[8]基于OLDA思想提出一种在线主题演化挖掘模型;Newman等[9]得出并行的OLDA算法比批处理LDA算法的效率快700多倍的结论;Ahmed等[10]在Yahoo基于共享内存系统提出一种在多处理器提高运算速率的缓存技术。然而,这些研究都没有很好解决OLDA模型自身的缺陷。针对OLDA模型在大量主题文档集中计算时间长和新主题不能及时发现的问题,以及在并行算法中各处理器之间的通信成本很高的缺陷,提出一种分布式的DOLDA模型。
1 LDA模型与OLDA模型
1.1 LDA模型
LDA实质是添加Dirichlet先验的pLSA模型的贝叶斯生成模型,是将文档中每篇文档的主题以概率的形式表示出的一种贝叶斯无监督的概率模型,是一种典型的词袋模型,同时是一种对文本数据集潜藏的主题信息进行建模的方法[2]。如图1所示,M表示文档数目,K表示主题数目,Nm表示第m个文档的单词数目,文档的生成过程如下。
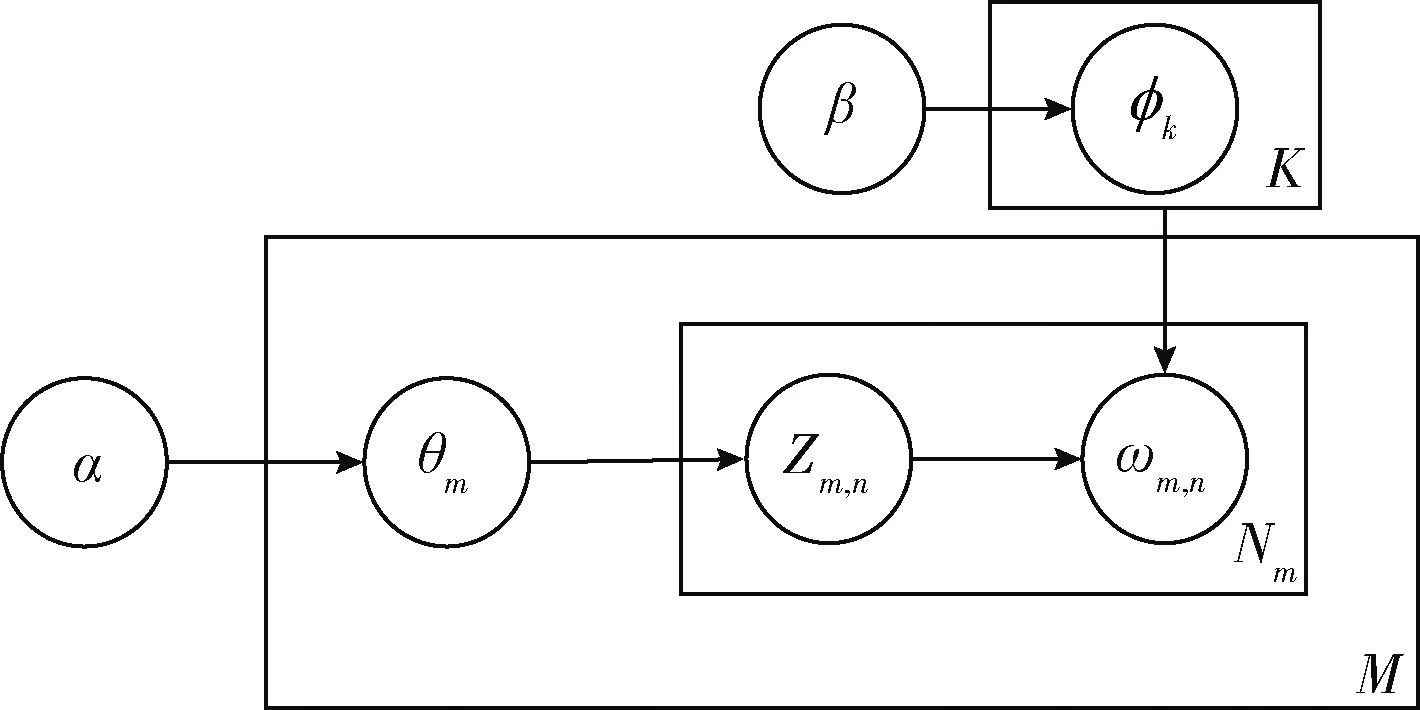
图1 LDA的图模型表示
首先,LDA通过先验知识选择一篇文档di,并从α分布中取样生成文档di的主题分布θi;然后从主题的多项式分布θi中取样生成文档di的第j个词的主题Zi,j;接着从β分布中取样生成主题Zi,j对应的词语分布Φzi,j;从词语多项式Φzi,j中采样最终生成词语ωi,j。因此,LDA中单词和对应主题的联合概率分布如式(1)所示
p(w,z|α,β)=p(w|z,β)p(z|α)=
(1)
1.2 OLDA模型
在文本处理中,通常主题具有持续性和稳定性。固定划分的时间片大小出现的主题很大程度上以固有特征出现在现有的时间片中,往往这种主题的特征是由主题-词项概率分布来体现。所以,在每段文本流中每个时间片的主题的后验分布能够作为当前时间片主题分布先验分布,这对于分析时间片之间的主题演化是极其重要的。
(2)
计算模型参数时,利用多项-狄利克雷(multinomial-Dirichlet)这组共轭先验-似然分布不需要归一化常数,只要找到与感兴趣密度相成比例的分布形式,就能简单地解决模型参数计算难题。OLDA按照文本数据流生成的先后顺序给各个时间片中的文档建模,通过不同的时间段挖掘主题可以实时在线或近似在线的分析主题演化。
2 分布式的DOLDA模型
DOLDA模型是基于Spark分布式计算平台[11,12],模型建立主要分为3部分:分布式主题-词项矩阵设计、新的动态负载均衡策略、潜藏主题-词项分布倾斜权重提出。最后,给出DOLDA模型的整个算法实现过程。
2.1 分布式主题-词项矩阵
Spark是基于内存的迭代计算框架,数据之间相互操作都是基于容错的、并行的RDD(resilient distributed datasets)。首先,zipWithIndex函数给需处理RDD每个文档分配独立的id,map函数通过该id仅处理一个文档作为输入;接着,flatMap函数产生新的三元组RDD(docId,wordId,frequency)。然后,wordId为关键字用join函数合并每个主题-词项矩阵生成四元组矩阵RDD(docId,wordId,frequency,row);最后,groupByKey函数通过指定的docId用map函数处理三元组RDD(row,wordId,frequency)。
经过一系列的RDD操作,好处有两个:一是,用一个RDD算子函数一致处理得到RDD文本集,这样可以更加快速和准确地切分大数据集;二是,能获得适应DOLDA模型E-step这一步操作的输入数据。
2.2 动态负载均衡策略
以往算法都采用静态负载均衡策略来分配全部数据集进程资源,没有考虑到处理文档长度不一的问题。再者,操作系统对线程的调度是不公平的,即使有相同线程开启时间和等样工作量,全部线程还是不会在同一时间结束工作,这样会导致资源大量浪费。Nallapati等[13]在这方面做了很多工作,但他们的研究报告结果显示,计算机上运行4条线程情况下获得大约2.0的加速比,算法在并行效果上并不是很理想。
为了从高性能计算角度上提高系统使用资源率,DOLDA模型采用了一种新的动态数据分配负载均衡策略。其核心设计思想:第一,不以文档长度的计算量来调度资源,是否还有未处理的文档,动态线程基本能保证所有线程能最后同时完成,减少了因线程执行的时间不一致而导致线程的计算资源浪费的情况;第二,动态分配文档数量仅为时间片中最长文档d动态分配K×|d|的计算资源空间,相比静态分配数据集方法所需要的K×V节约很大的资源空间,因为整个数据集词的数量V远远大于一个文档词量|d|。在分布式计算中,节点是先访问Cache数据再访问内存,动态分配过程中对数据集的计算是连续的,这样做的好处能大幅度提高Cache利用率。
2.3 潜藏主题-词分布倾斜权重
根据Zipf定律[14],在自然语言里只有小部分的高频词汇,大部分的词出现频率较低,并且OLDA模型表达的主题权重ω是无法根据主题在不同的时间片中相应调整的。为此我们重新设定权重,为了避免因为ω设置过小导致前后主题不能对齐;ω过大导致Zipf定律固定词频强制对齐并非同一主题事件,特别在当前t时间片有产生新的主题,但新旧主题混合一起与t-1中的相关主题产生对齐,会给及时发现新的主题带来麻烦,考虑到主题之间的差异性,潜藏主题-词项分布倾斜权重ϖ。ϖ来衡量主题的重要性,包括基准主题权重和主题遗传强度权重两部分。按Zipf定律在词汇上的分布p(ω|Z)应该往词汇集合中的一个子集偏斜,设一个Zipf主题权重Zs,p(ωi|Zs)=1/V,i∈{1,2,…V},则潜藏主题Zk的主题-词分布倾斜权重设定为基准主题Sbase(Zk),其定义为Zs的词分布与Zk词分布的相似度,散度定义请参见文献KL(kullback-leibler divergence)[15]所示。
基准主题Sbase(Zk)反应了潜藏主题的主题分布权重,Sbase(Zk)越小,Zk在主题分布的概率分布越平均,则基准主题的倾斜性越低,主题重要性越低。
考虑到当前时间片中主题强度越高的主题会在下个时间片出现并遗传出更多的相关主题,则定义潜藏主题Zk的词分布主题遗传强度倾斜权重Sinher(Zk)。潜藏主题-词分布的倾斜权重ϖ是由基准主题权重Sbase(Zk)和主题遗传强度Sinher(Zk)的加权和,其计算由(3)式所示
ϖ=λ1Sbase(zk)+λ2Sinher(zk)
(3)
其中,λ1、λ2分别是权重系数。如图2所示,DOLDA模型在主题内容的演化。通过ϖ控制主题遗传度,ϖ低的主题很有可能在下一个时间片消亡或者突变为其它的主题,相反ϖ很高的主题可依然保持它的主题连续性,很明显ϖ的高低在主题演化分析上具有很大参考价值。
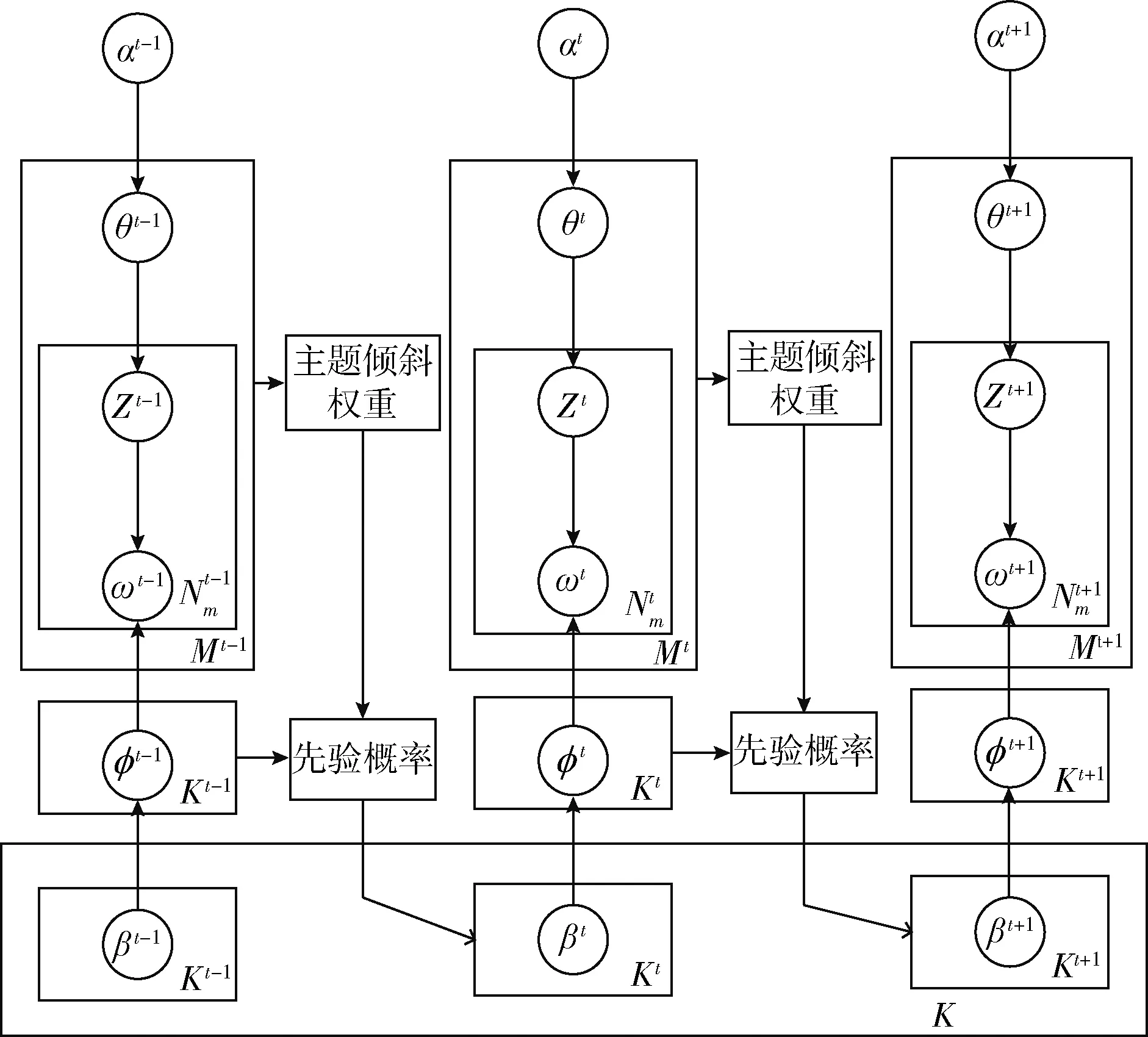
图2 DOLDA模型在主题内容演化

(4)
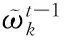
(5)
Spark分布式集群调用动态负载均衡算法分配线程资源给整个数据集文档DM,V,从切分文档Dth选择文档di,分布式的主题-词项矩阵通过一系列的RDD算子方法切分数据集并且在相应的时间片内得到新的RDD。首先从参数α的Dirichlet分布中取样生成文档di的主题分布θi,如果时间段t=1,通过Zipf定律计算基准主题权重,从Dirichlet分布β中取样生成主题Zi,j对应的词语分布Φzi,j。如果是t+1时间段,需要计算ϖ。然后,分布式集群是从K×|d|选择一个文档集合并合理分配线程资源,分布式主题-词矩阵Sd存储RDD算子处理后的新的RDD;最后,distributed E-Step函数处理上一步新的RDD,循环计算ϖ,词语多项式Φzi,j中采样最终生成词语。并且distributed M-Step函数通过全局的主题-词项矩阵更新主题-词项矩阵。
综上所述,DOLDA算法的具体过程如图3所示。
3 主题演化分析
内容演化和强度演化是主题演化分析的主要组成部分。本文采用何建云等[15]在相关研究来计算主题演化强度。在计算主题之间相似度方法时考虑到KL距离度量的是两个主题在词语集上分布的差异性,而对实时性和近实时性的要求,采用一种新的计算主题相似度方法。
(1)主题强度度量:主题的重要性主要是通过主题在文本中所占的比重的高低来度量。分析文档的主题分布高低来赋予每篇文档相应的权值。采用熵来度量文档-主题分布的密集程度,并用熵估算文档权重,计算分别由式(6)

图3 DOLDA算法的具体过程
和式(7)所示
(6)
(7)
θm,k为估计文档m在第k个主题的值。当权重逼近最大值1时,文档只属于一个主题;当权重逼近0时,文档在K个主题上均匀分布。一个新的主题强度计算由式(8)所示
(8)
(2)主题相似性度量:本文使用Cosine距离来计算主题间相似性。首先将离散的概率分布函数Φz表示成向量,利用Cosine距离计算Φ1和Φ2的相似性,由(9)式所示
(9)
两个主题Φi和Φj词的概率值越相近,两个主题相似性越大,并值得注意的是,公式中所有符号没有像KL距离或者Jensen-Shannon距离一样有时间上标,因为主题相似性的度量是针对任意不同或者相同的时间片的主题的。
4 实 验
4.1 实验准备
数据集:本文实验采用的英文数据集NIPS,该数据集包括1988-2001年共14年会议1740篇研究论文,13 649个出现一次的词汇和总共2 301 375个单词。数据集解压后都是文本格式,以年为单位总共划分14个时间戳,每个文档有一个时间戳,每个文本集包括90-250篇文档之间。
数据预处理:数据集包含了14年的会议相关数据,在使用DOLDA模型分析之前必须进行数据预处理工作:取出停用词(stopwords)和在数据集中出现次数少于5次的词。
实验环境:实验由3台虚拟机来搭建集群实验环境,每台虚拟机的硬件配置为8 cores、8 G内存、50 G磁盘,操作系统版本为centos6.2。Spark版本为1.5.2,hadoop版本为2.6.2。实验的集群架构图如图4所示。
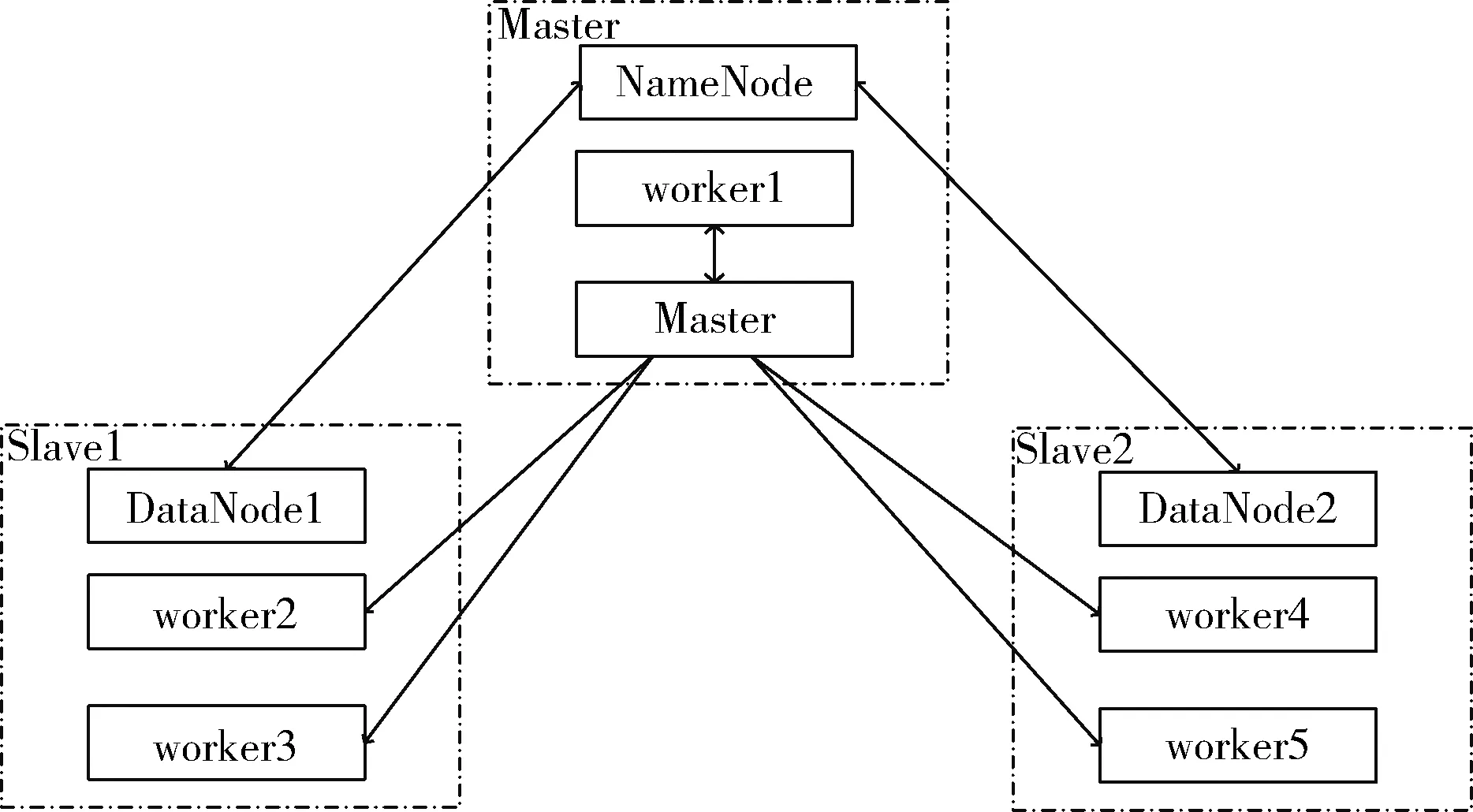
图4 集群架构
4.2 实验结果
4.2.1 整体效果
在Spark集群上运行DOLDA模型,使用主题T=20,100轮迭代。超参数设置为α=0.1,β=0.1,模型的主题挖掘整体效果如图5所示,总共挖掘出20个主题,每个主题标识10个最重要的10个词语。人工筛选4个主题,各个主题对应的关键词,Topic1是与GraphX相关的,Topic8是与主题模型相关,Topic10是与算法相关的,Topic15是机器学习相关的主题。从模型中挖掘出来的主题所对应的关键词的准确性较高,并且主题之间内容独立性较强。
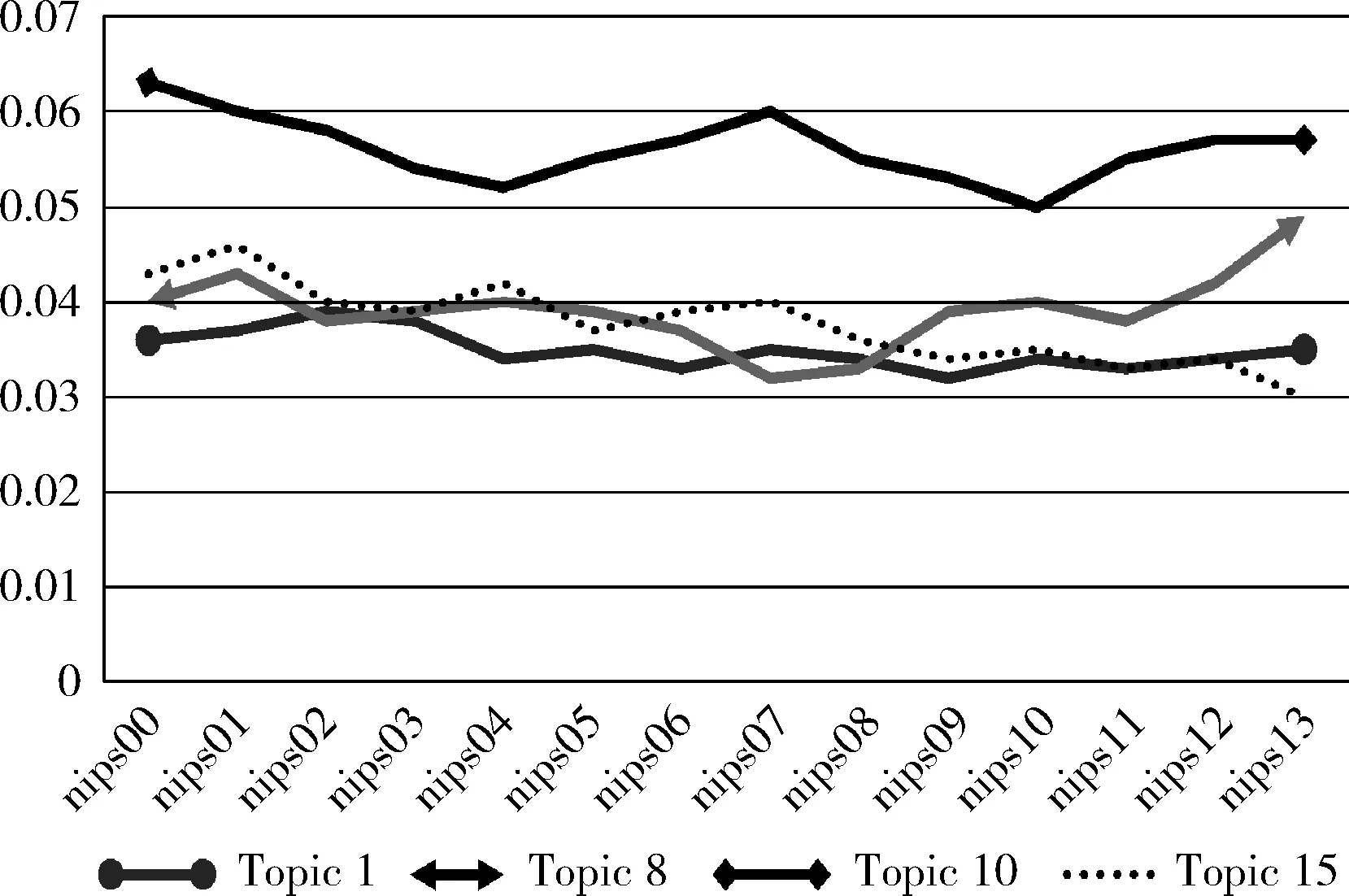
图5 主题强度变化
如图6所示,可以很直观看清楚主题强度的变化趋势,主题1的波动是最平缓的,主题1在nips会议中的地位每年都比较重要,猜测主题1在下一年的会议中仍会被重视。主题10的强度就有别其它主题,由主题关键词概率所占的比重可以分析出主题10里词汇有比较高的普遍性,即背景噪声词汇。主题8讨论的内容呈上升趋势,说明主题8的讨论越来越成为热点话题,相对主题15的讨论有所下降。
图6 部分主题概率
主题内容的演化也是本文研究重点。我们专门对主题12(reinforcement learning)随着时间的变化程度分析,采用Cosine距离来计算相邻时间块内的主题间相似性。如图7所示,展现主题12随着时间变化预测走势图,nips00、nips10、nips11和nips12的主题距离明显高于阈值(虚线表示),反映了会议中主题12谈论的主题是重要的。看到nips00->nips01之间距离突然增大,表明主题12在期间内发生了重大的变化。通过如表1所示的相应的关键词的概率分布情况,对于“强化学习”的关键词的概率明显下降,且一直低于阈值水平到nips09,其后有关“强化学习”主题的相关关键词逐渐呈现上升趋势,并且在nips13中的内
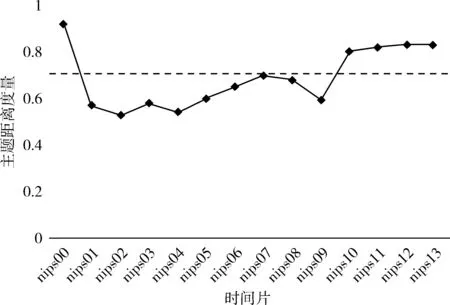
图7 主题12变化预测
容都是与“强化学习”相关的,这样说明主题12逐渐演化成为“强化学习”。
表1 Topic12的内容演化

4.2.2 对比实验
DOLDA是在OLDA模型基础上提出来的,OLDA模型的主题边界比较模糊,容易造成新旧主题混合导致不能及时发现新主题的问题。如表2所示,DOLDA与OLDA对几个主题检测的对比效果。
表2 DOLDA与OLDA的主题检测结果
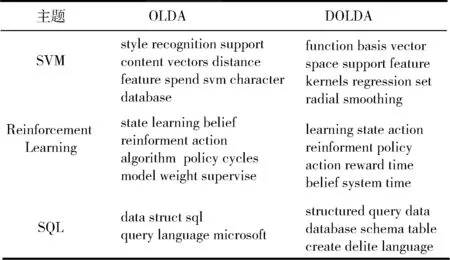
从上表中可以分析出:在3个主题检测中,OLDA模型在检测SQL主题时检测结果不完整,难以判别该主题是SQL,在检测主题reinforcement learning时,出现主题不同程度的混合现象。比如在OLDA检测中supervised learning和model learning 的共现与reinforcement learning主题混合在一起导致新旧主题混合。DOLDA模型中,潜藏主题-词分布倾斜权重ϖ,ϖ比较低的主题会被提前预处理,给产生的新主题的权重相对高一点,这样新主题和原有冷门主题就不会出现混淆的现象。
实验进一步比较了OLDA模型和DOLDA模型的困惑度(Perplexity)这一度量概率模型性能指标[16],Perplexity表示主题模型对于观测数据的预测能力,取值越小就表示模型的性能越好,模型的推广度越高。Perplexity定义如下
(10)
其中,wd为文档d中的可观测单词序列;Dtest为实验所整理的测试集;Nd为文档d的单词个数。为了计算p(wd),选择20%的文档作为测试集,剩下80%文档作为训练集,需要计算预测文档的似然度。如图8所示,在NIPS数据集上训练OLDA模型和DOLDA模型,在每一个时间片,比较模型困惑度。
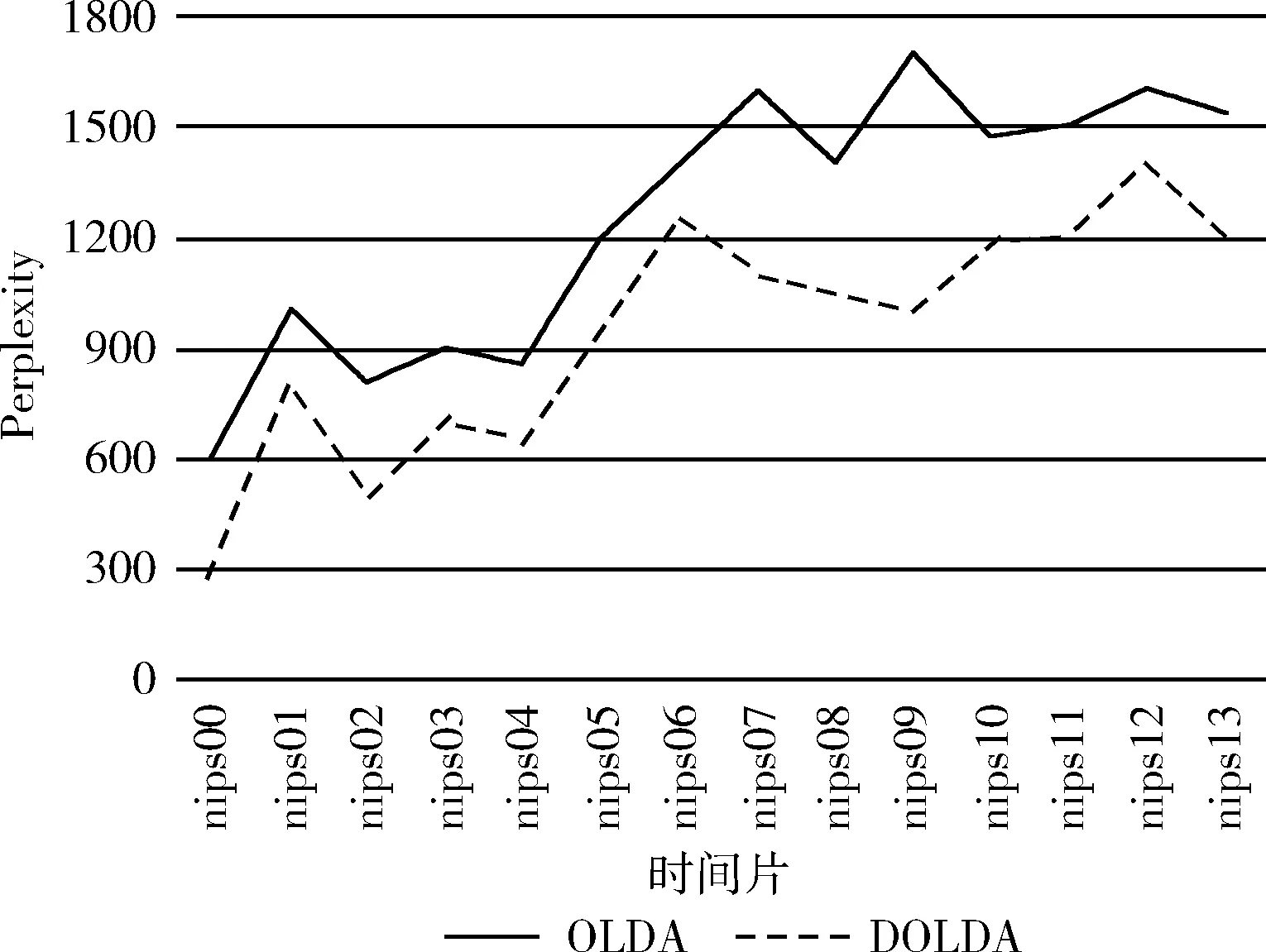
图8 OLDA与DOLDA模型的困惑度对比
与OLDA模型的对比实验发现,在相同的实验环境下,DOLDA模型在每一时间片的困惑度均要小于OLDA,这样验证了在OLDA模型基础上提出的优化方案确实能提高模型的性能和推广性。
最后,DOLDA模型运行在Spark分布式计算平台上,提出了一种新的动态负载均衡的调度策略,如图9所示,在NIPS数据集上对OLDA模型和DOLDA模型的加速比进行对比。在NIPS数据集上使用6个线程,DOLDA相比OLDA的加速比提高了近16%,这表示新的调度算法更加有效地调度线程,使用动态的调度策略使线程的分配和利用更加高效和合理,随着线程数量的增多、文档集的分块粒度越小,DOLDA模型在加速比上相对有优势。
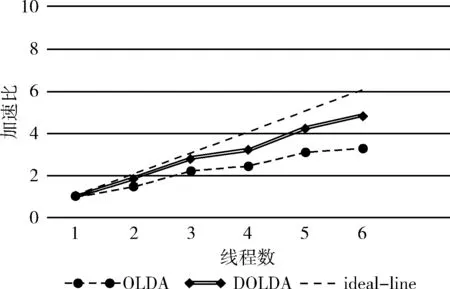
图9 OLDA与DOLDA在NIPS数据集上的加速比
5 结束语
综上所述,本文基于OLDA模型提出了DOLDA模型,其不仅很好的利用Spark中RDD分布式数据结构的特性,设计一个新的动态负载均衡的策略,提出潜藏主题-词分布倾斜权重定义很好避免了OLDA模型新旧主题混合的问题,获得较低的困惑度、较高的加速比以及有效的在线分析主题的演化情况。
未来的研究工作主要将从以下两方面入手:第一,继续优化DOLDA模型;第二,在主题演化过程中,探索更早时间片的主题之间的影响程度。
[1]Blei DM,Ng AY,Jordan M.Latent dirichlet allocation[J].The Journal of Machine Learning Research,2003,3(3):993-1022.
[2]Chen TH,Thomas SW,Hassan AE.A survey on the use of topic models when mining software repositories[J].Empirical Software Engineering,2016,21(5):1-77.
[3]Ma HF,Sun YX.Microblog hot topic detection based on Topic model using term correlation matrix[C]//Proceedings of the 17th International Conferenceon Machine Learning and Cybernetics,2014:25-29.
[4]Hirzel M,Andrade H,Gedik B,et al.IBM streams proce-ssing language:Analyzing big data in motion[J].IBM Journal of Research and Development,2013,57(5):1-7.
[5]Wang C,Blei D,Heckerman D.Continuous topic models[C]//The 23rd Conference on Uncertainty in Artificial Intelligence,2012:579-586.
[6]Nallapati R,Ditmore S,Latterty JD,et al.Multiscale topic tomography[C]//Proceedings of the 13th ACM SIGKDD International Conference on Knowledge Discovery in Data Mining,2014,25(1):17-32.
[7]Hoffman M,Blei D,Bach F.Online learning for latent dirichlet allocation[C]//The 24th Annual Conference on Neural Information Processing Systems,2010:856-864.
[8]Cui Kai,ZHOU Bin,JIA Yan,et al.LDA-based model for online topic evolution mining[J].Computer Science,2010,37(11):156-159.
[9]Newman D,Asuncion A,Smyth P,et al.Distributed algorithms for topic models[J].Journal of Machine Learning Research,2009,10(12):1801-1828.
[10]Ahmed AM,Gonzalez J,Narayanamurthy S,et al.Scalable inference in latent variable models[C]//ACM International Conference on Web Search & Data Mining,2012:123-132.
[11]Zaharia M,Chowdhury M,Franklin MJ,et al.Spark:Cluster computing with working sets[C]//In Proceedings of the 2nd USENIX Conference on Hot Topics in Cloud Computing,2010.
[12]Zhao B,Zhou H,Li G,et al.ZenLDA:An efficient and scalable topic model training system on distributed data-parallel platform[J].Computer Science,2015,5(5):46-50.
[13]Nallapati R,Cohen W,Lafferty J,et al.Parallelized variational EM for latent dirichlet allocation:An experimental eva-luation of speed and scalability[C]//IEEE International Conference on Data Mining Workshops,2007:349-354.
[14]Kalyanam J,Mantrach A,Saez-Trumper D,et al.Leveraging social context for modeling topic evolution[J].Know-ledge Discovery & Data Mining,2015,18(6):517-526.
[15]HE Jianyun,CHEN Xingshu,DU Min,et al.Topic evolution analysis based on an improved online LDA model[J].Journal of Central South University(Science and Technology),2015,7(2):547-553(in Chinese).[何建云,陈兴蜀,杜敏,等,基于改进的在线LDA模型的主题演化分析[J].中南大学学报(自然科学版),2015,7(2):547-553.]
[16]Griffiths TL,Steyvers M.Finding scientific topics[J].Proc of the National Academy of Sciences of United States of America,2004,101(S11):5228-5235.
