基于复合字典的地名地址匹配技术
2018-03-15程琦梁武卫汪培
程琦,梁武卫,汪培
(武汉市测绘研究院,湖北 武汉 430022)
1 引 言
地名地址匹配定位是将文字性的描述地址与其空间的地理位置坐标建立起对应关系的过程。地名地址匹配定位按照特定的步骤为地址查找匹配对象,首先要将地址标准化,然后搜索地址匹配参考数据进行分词,最后根据与地址的接近程度为每个候选位置指定分值,用分值最高的来匹配地址,达到空间定位的目的。
通常来说,地名地址匹配工作分为标准地址数据库建设和中文分词算法实现两个步骤。一是建立标准地址数据库建设是研究城市地名地址要素分类及描述规则,在此基础上构建地址标准化模型,依据地址标准化模型来建立标准地址数据库,同时在数据库中记录各类地名地址要素的标准名称和空间坐标的编码。二是实现一种适合本地化的地名地址中文分词算法,将拆分结果与标准地址数据库地址要素进行匹配,通过将标准化的地址赋予空间坐标信息,完成地址字符串的空间定位,从而实现地名地址匹配。
2 复合字典的设计
地名地址信息中的地名数据具有数据量大、覆盖范围广、信息复杂度高的特点。在地名地址匹配过程中,地名库的字典设计既要考虑区域范围内地名数据的特征,还要考虑用户对地名数据的模糊查询、日常用词、短语、专用词汇、地名词条等均应包含其中。
中文分词的精确性很大程度上取决于分词字典的规范程度。目前,用于分词的传统字典存在以下不足:一是对于同音字、错别字、简称、旧称等情况没有进行更好地纠正;二是仅包含日常用词、短语、专用词汇、地名地址信息,未对其精确程度进行分级;三是对于特殊字符没有考虑更多,导致错分、漏分等多种情况。因此,针对以上三点问题设计了一套复合字典,包括用于纠错的标准化字典,用于定位精确度分级的地名字典、用于提取地址准确度标识信息的特殊标识字典等,我们将这一系列不同作用的字典组合而成的字典组称之为“复合字典”。
复合字典的主要作用有以下四点:使用“通用字典”,拆分出常用词语;使用“标准化字典”,标准化位置描述;使用带权重级别的“地名字典”,量化拆分结果;使用“标识字典”,精确标识出门(楼)牌号。
2.1 通用字典
通用字典的目的在于拆分出常用词语,该字典在拆分与地域性无关的单位名称时十分有效,如:招商银行武汉市分行,拆分为“招商银行/武汉市/分行”,其来源为新华字典。
2.2 标准化字典
标准化字典的来源有两部分:一部分来源于标准地名地址编码库中对行政区划、街路巷、小区、标志性建筑物的标准称谓,其数据出处一般来源于当地公安机关户政处或民政部门的地名办;另一部分来源于社会上对地名的各种叫法和称呼,如一个地名不同的叫法、简称、别名等。标准化字典则是建立两者之间的关系,将非标准的地名与标准名称进行对照,其作用是在中文分词步骤前将待分析的词进行标准化处理,从而提高地名地址匹配的准确率。
标准化字典的建立主要是在地名地址批量匹配后,对未匹配的大量地址结果逐级进行筛选分析出来的。标准化字典中的对应关系可以是一对一或多对一,例如:我们在实际工作中遇到过土地发证部门的土地坐落中有“转车楼小区”,工商组织机构代码中有“转车楼社区”,其对应的标准名称应均为“转车楼一村”。表1显示了标准化字典的结构:
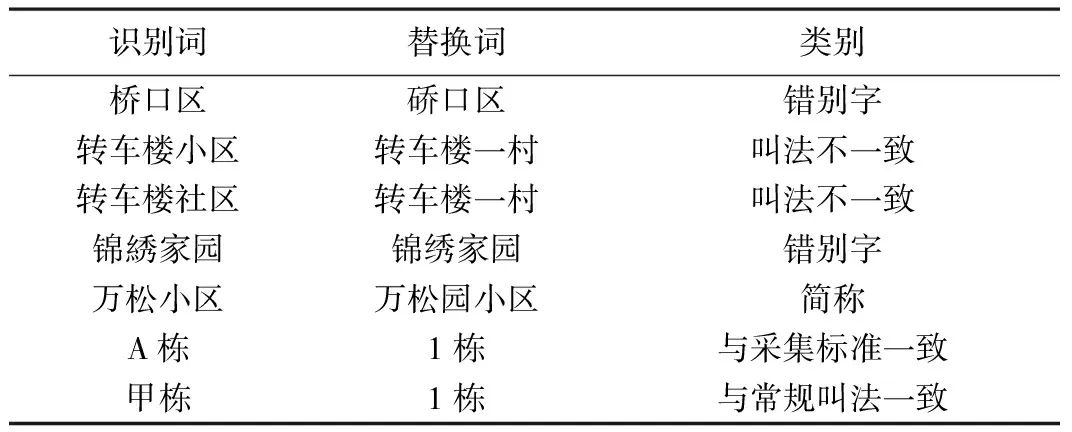
标准化字典 表1
注:经过30 w条地名地址匹配的实验结果,使用标准化字典能使匹配准确率提高20%左右。
2.3 地名字典
地名字典包含各级行政区划、道路、小区、标志性建筑物名称、各场所、单位名称等,除了单一的拆分作用外,还根据其精确程度进行逐级排序,取累计权重最大的为精确结果。表2显示了地名字典的结构:

带分级权重的地名字典 表2
2.4 特殊标识字典
特殊标识字典主要作用是识别出地址描述中与门(楼)牌号相关的数字和字母。来源于待处理地址的具体描述,包含:号栋门幢座#舍#等。
实际应用的字典根据不同目标源还有很多种,以上只是列出了几个主要的字典。
3 分词算法
3.1 基本算法
选择了基于字符串匹配的分词算法作为基本算法。此算法也称为机械分词算法,它是按照一定的策略将待分析的汉字串与一个“充分大的”机器词典中的词条进行配,若在词典中找到某个字符串,则匹配成功(识别出一个词)。按照扫描方向的不同,串匹配分词方法可以分为正向匹配和逆向匹配;按照不同长度优先匹配的情况,可以分为最大(最长)匹配和最小(最短)匹配。实际过程中设计了一种正向最大匹配方法和逆向最大匹配方法结合的双向匹配法,以提高分词的准确性。
3.2 基于复合字典的地名地址匹配算法
首先,选择了易于实现的、准确率高的基于字符串匹配的分词算法。其逆向匹配的切分精度略高于正向匹配,遇到的歧义现象也较少。统计结果表明,单纯使用正向最大匹配的错误率为1/169,单纯使用逆向最大匹配的错误率为1/245。但这种精度还远远不能满足实际的需要。因此,我们将此分词作为一种初分手段,利用复合字典和算法特性相匹配,进一步提高切分的准确率。
其次,除了通常的批量匹配、正向反相匹配、单条匹配之外,为了适应地址的复杂性,还增加了丰富的地址标准化处理功能,如繁体简体转换、半角全角转换、汉字和数字转化等,对匹配条件也可设置选择,特别是别名处理功能,抗干扰处理功能,多次匹配功能,以这些丰富的手段和方法来提高地址匹配得准确率。流程如图1所示:
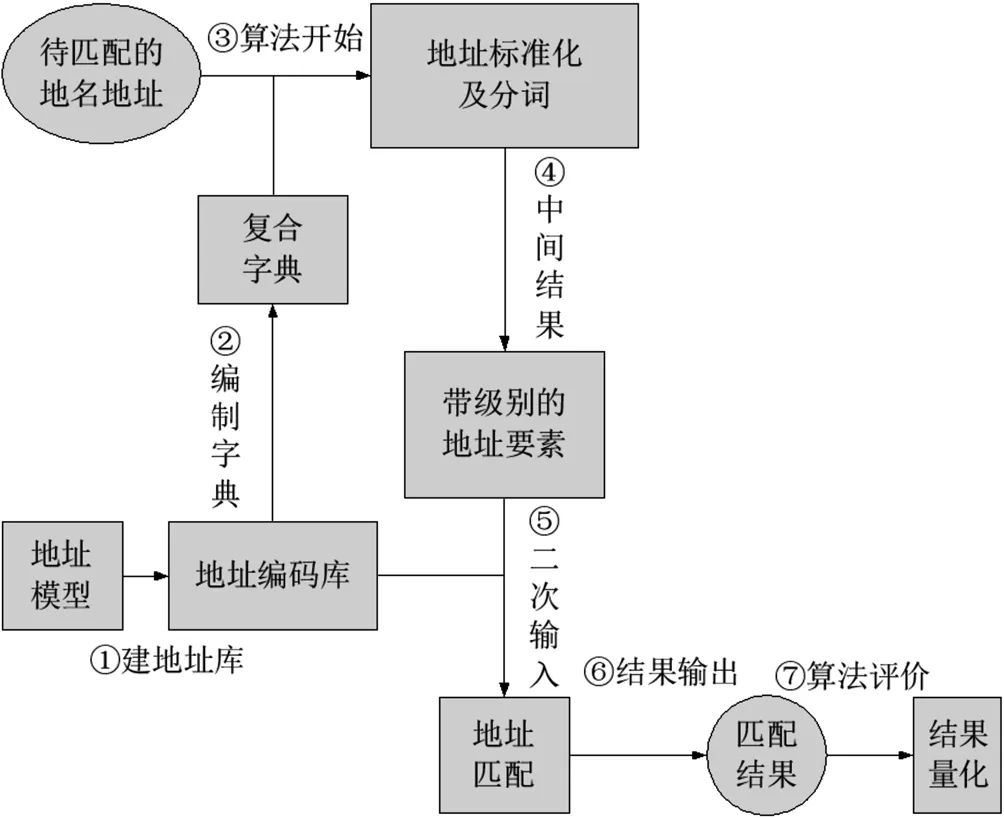
图1 地名地址逐级定位匹配流程
(1)解决地址描述不规范问题。如“1栋”变为“一栋”、统一增加或去掉“江汉区”等,使之与标准地址库中的描述一致。解决思路就是设计一个类似WORD里的Replace功能,用规范的描述来代替不规范的描述,并且具有智能扩展功能的选项,将类似的“二栋”、“乙栋”变成所希望的描述“2栋”;建立常见替换词典库,把常见的、需要替换的词汇和对应词汇建立一个通用词典,让程序对常见不规范的描述批量判别和替换(如别名、简称等),达到常见问题自动处理,个别问题单独处理的目的,逐个规范。
(2)解决地址拆分问题。将地址按标准地址库的描述,拆分成区、街、路、巷、小区、栋、号格式。解决办法就是:建立可维护(添加、编辑、查找、删除等)常用拆分词汇字典,按照其精确度建立包括区、街道、道路、小区、独栋房屋、标志性楼宇等词典库,设计不同类型经典匹配算法和拆分处理步骤,并对其反复锻炼优化,按照分类处理的原则,逐类拆分。
(3)解决地址匹配问题。将目标地址与标准地址进行关联。解决办法就是,建立标准地址库维护更新模块,确保标准地址库的规范描述;根据目标数据的不同特点,按照拆分后的标准地址库字段结构,由大地址向小地址(按权重进行递减),逐级匹配。

图2 地名地址逐级定位匹配层次
4 应用案例
目前,武汉市标准地址编码数据库覆盖了武汉市中心城区、两个开发区及新城区城关镇,共计63万余条,能满足绝大多数行业对武汉地区地址匹配技术的需要。例如,在武汉警用信息数据库建设过程中,对4大类、33小类警用公共地理信息以及16类业务信息,采用批量匹配的方法进行定位,大大提高了数据采集的效率,缩短了外业数据采集的时间。在武汉市土地证落地项目中针对武汉市10万余发证土地进行了定位,依据其采集要求,以完成80%左右土地证精确定位。在武汉市“两实”人口调查应用中,利用算法成功将武汉市800多万户籍人口信息进行了定位,由于其效率高、并具有多线程功能,一个月的时间内完成了所有人口的定位工作。在2015年开展的武汉市第一次地理国情普查中利用算法将武汉市5万余工商登记企业进行了上图定位,准确率达76%。
经过反复调试和优化,并结合抗干扰、别名、多次匹配等技术,效率和精度得到大幅提升,匹配速度达到200条/分钟,准确度能达90%以上。目前,通过该算法已完成了100多种业务数据的定位工作,业务数据涉及公安、安全、土地、环保等多个部门,极大地提高了管理对象定位上图的效率;同时通过相关匹配上图工作,又大大拓展了地理信息外延,这些数据涉及了房产、机关团体、文教卫生、食宿娱乐、金融保险、工商质监、环保水务和应急危险源等。

图3 匹配软件

图4 匹配上图效果
5 结 语
今后,匹配算法的发展方向一是在线封装,通过将算法编写成JSON、API之类的接口,借助网络进行在线实时解析,提供在线式服务。二是通过网络爬虫技术进行网络热词的自动搜索,通过大数据手段使得更新复合字典,不断提高匹配效率。三是通过不同行业的信息对比,积累不同行业的分词信息,不断丰富分词字典内容,以提高地名地址匹配的成功率。
[1] 袁园. 标准地址库系统的设计与实现[J]. 地理空间信息,2009(6).
[2] 宋子辉. 自然语言理解的中文地址匹配算法[J]. 遥感学报,2013(4).
[3] 黄华国. 标准地址模型在PGIS中的研究与应用[J]. 中小企业管理与科技(中旬刊).2014(4).
[4] 钱敏,顾国强,鲁明. 用于地址(地理位置) 匹配的关键路径法[J]. 计算机应用与软件,2012(29).
[5] 马照亭,李志刚,张伟等. 一种基于地址分词的自动地理编码算法[J]. 测绘通报,2011(2).
[6] 范立新,谢晓能,吴飞. 基于过滤的中文多模式近似字符串匹配算法[J]. 计算机工程,2006(20).
[7] 丁小陆,黄炳耀,鲍晓娣. 基于GIS的地名地址管理系统构建[J] . 地理空间信息,2015(4).
[8] 王野,张志文. 沈阳市地名地址数据采集与建库[J]. 城市勘测,2013(6).
