限价指令驱动市场中信息聚类分析模型研究
2018-03-13潘春玲
潘春玲
摘 要: 针对传统限价指令驱动市场信息聚类分析不准确,且存在耗时长的问题,提出基于信息相似度计算的限价指令驱动市场中信息聚类分析模型。首先给出信息聚类模型的模块结构图,并导入限价指令驱动条例,以条例为制约,根据信息熵获取指标权重,计算信息相似度,将每一个带有趋向性的信息进行簇源追踪,对于远离簇中心的信息进行剥离,将剩下的信息重新赋予数据族编,实现信息聚类分析模型建立。实验数据表明,构建的信息聚类分析模型能够依据信息相似度进行同源信息的聚类,聚类分析准确度较高,且耗时较短。
关键词: 限价指令; 市场信息; 聚类分析; 相似度; 信息分类; 数据族编
中图分类号: TN911?34; TN393 文献标识码: A 文章编号: 1004?373X(2018)06?0169?03
Abstract: Since the information clustering analysis of the traditional limit order driven market is inaccurate, and has long time consumption, an information clustering analysis model of limit order driven market is put forward, which is based on information similarity calculation. The module structure diagram of the information clustering model is given, and the limit order driven regulation is imported. Taking the regulation as the restriction, the index weight is acquired according to information entropy, and the information similarity is calculated. The cluster source tracking is performed for each information with tendency. The information away from the cluster center is eliminated, and the rest of information is endowed with data family compilation renewedly to realize the establishment of information clustering analysis model. The experimental data shows that the constructed information clustering analysis model can cluster the homologous information according to information similarity, and has high clustering analysis accuracy and short time consumption.
Keywords: limit order; market information; clustering analysis; similarity; information classification; data family compilation
0 引 言
在限價指令驱动的市场中,市场中信息数据之间是一个复杂的交互作用过程。限价指令驱动下,市场信息具有一定的流动供给功能。信息流动性促进市场交易策略信息互相参杂,致使市场中信息杂乱无序[1?2]。每一类型的市场信息具有特有的属性,不同属性下的信息代表的意义也是不同的,但在限价指令驱动下的市场中找到同一类的信息变得十分困难。传统的市场信息聚类方法能够对市场中的信息进行简单分类,但是无法区分同源信息数据的归类源,数据间的相似度无法比较,造成同一簇的信息可能是非同族数据。针对上述问题,本文设计了限价指令驱动市场中的信息聚类分析模型,并进行试验分析。
1 限价指令驱动市场中信息聚类分析模型设计
本文设计的信息聚类分析模型,以限价指令为信息数据的主导,将每一项指标都视为同等二级指标,使用权重指标为特级指标,解决市场信息的相似度的问题[3],利用冗余性对数据信息进行同族处理,实现信息簇族化,实现信息聚类分析模型的建立以及信息聚类分析。本文设计信息聚类模型模块结构如图1所示。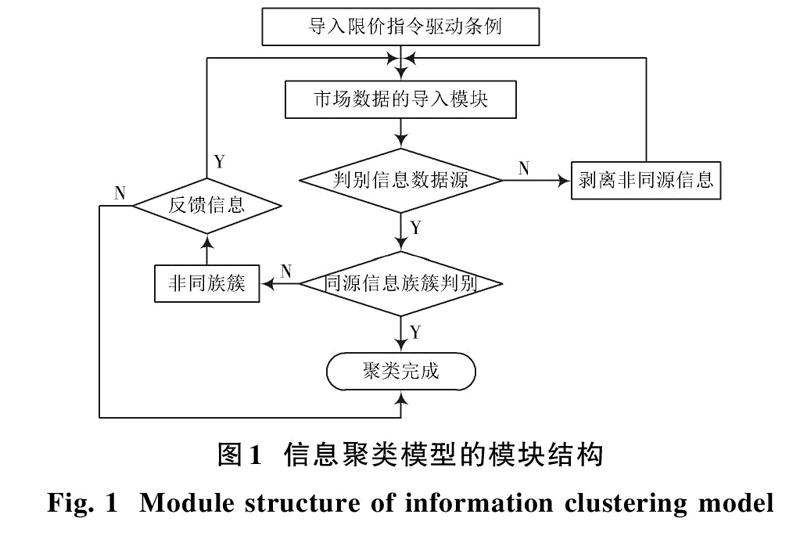
1.1 限价指令驱动条例
限价指令在市场中,能够对信息数据进行一定的制约,由于限价指令能够将信息数据进行累积,累积的数据信息会按照限价指令的先后进行时间上的排序,这种按照时间的排序就称为信息的优先权重[3?4]。限价指令能够直接影响市场上的交易量,从而控制信息的走向。不同的限价指令推行下,累积的信息数据会产生交互作用,将非同族的信息进行交互混杂,致使最终的信息走向偏向于杂乱无序的状态。本文使用限价指令驱动能够激活数据信息,使其具有一定的信息流动性,在流动性的驱使下能够产生一定的信息簇族效应,方便数据的聚类处理。
假设限价指令驱动能力为[T],利用市场的信息发展趋势进行条件限制函数的建立,用公式表示为:
[S=PrT>tX∈P?S?I]
式中:[S]为限价指令驱动限制能力,利用限价指令驱动的条件限定[T>t],致使信息具有单一的趋向性。即使限价指令驱动在[t]之下,仍然有信息补缩的趋势,因此信息仍然具有趋向性[5]。使用[X],[P],[S],[I]四项条件限制使用过程的信息外延展。[X]为信息的动向力,能够提升市场信息的格局化;[P]表示信息的过程交互概率,是衡量信息的杂乱度的条件;[I]为数据信息的向心趋势。经过上述的限价指令驱动条例的引入完成对数据信息的限定。endprint
1.2 指标权重的确定
由于限价指令的使用,本文需要对指标权重进行重新确定,在信息聚类分析中各个指标的权重程度是不同的,通常需要对同源信息进行簇族权重重新确认[6?7]。根据信息熵的概念,市场信息在熵度量的获取中,能够提供适度的专项同源族簇。将市场数据的整体想象成为一个具有理想尺度的综合体,归一化的数据信息权重便可以进行确认,信息聚类分析过程的指标权重可以定义为,由信息熵以及过程权重所组成,过程权重只能说明整体权重的量,无法实现单一分类。因此,重新定义信息的过程交互概率是一个定值,将每一个信息源中的使用概率、信息驱动程度以及权重决定因子进行指标化处理,便可以得到总体信息权重分量,使用转化信息矩阵将定义的指标化分量与其结合,信息权重矩阵会变得有序化,对每一个同源信息进行多次提取,把整体信息权重分配给每一个信息源中,便可以得到具有指标化的权重。
通过上述过程的分配,能够确认每项同源信息的权重,其中分配到的权重可能与信息的发展趋势有偏差,但是信息的趋势是矢量,权重也是矢量,在不同的分布状态下也可进行叠加或类减。至此,完成指标权重的重新确定过程。
1.3 信息聚类分析模型建立
本文设计的市场信息聚类分析模型,能够进行信息的划分或分组处理。设计的信息聚类分析模型,能够将市场信息中的限价指令驱动以矢量的形式进行子集化,每一个子集代表限价指令驱动样本或者是限价指令驱动趋势[8]。通过上述确认的指标权重,能够对子集中的元素进行同源化处理,方便进行信息聚类分析。本文利用[K]进行信息相似度计算,将每一个带有趋向性的信息进行簇源追踪,对于远离簇中心的信息进行剥离,将剩下的信息重新赋予数据族编,便完成信息聚类分析模型建立[9]。假设每个信息簇的数据源值是相同的,聚类过程是不断重复的,信息聚类过程函数分别使用市场信息原始信息分类源以及限价指令驱动下的信息聚类能力进行信息聚类处理。经过信息的甄别,完成聚类分析过程,至此信息聚类分析模型构建完成,见图2。
2 实验分析
2.1 实验参数设定
本文为了检验限价指令驱动市场中信息聚类分析模型的有效性,对原始市场信息和限价指令驱动后的市场信息,分别设计了两组实验。在第一组实验中,使用限价指令驱动市场中信息聚类分析模型与传统信息聚类分析方法,在原始市场信息状态下进行实验。在第二组实验中,使用限价指令驱动市场中信息聚类分析模型与传统信息聚类分析方法,但市场信息受到限价指令驱动。模拟实验每组执行10天,每天对10期市场信息运行结果数据的聚类分析。分析过程观察每组实验中不同市场信息的实验结果,以此判断该方法的适用度。为了试验的严谨性,对试验参数进行设置,设置结果如表1所示。
2.2 试验结果分析
表2是在不同市场状态下的同源性测试结果。温和市场对应的信息趋向性;急躁市场对应的信息同源率;耐心市场对应的信息归属速率。三种市场中最具有代表性的数据能够反映出信息的同源规律。温和市场选用信息趋向性能够反映信息同源的规律变化,温和市场的信息波动不剧烈没有信息断代,使用信息趋向性足以说明。急躁市场状态下带有强烈的信息波动性,选用其他数据不能进行代表性说明,因此选用信息同源率。耐心市场存在信息断代,其他数据不具有说明性。
%
通過表2的数据对比结果可以看出本设计的聚类模型比传统方法更佳具有信息趋向性,信息同源性结果说明,本文设计的聚类模型比传统方法更具有说明性。
3 结 语
本文设计的限价指令驱动市场中信息聚类分析模型,导入了限价指令驱动条例,以条例信息为制约,优化指标权重确认过程。希望通过本文研究能够促进市场信息聚类能力。
参考文献
[1] 王硕,李鹏程,杨宝臣.基于指令驱动市场EKOP模型的异质期望研究[J].管理科学,2016,29(3):123?135.
WANG Shuo, LI Pengcheng, YANG Baochen. Heterogeneous expectations study based on EKOP model under order driven market [J]. Journal of management science, 2016, 29(3): 123?135.
[2] 邴涛,刘善存,张强,等.指令驱动市场中非知情交易者的最优交易策略[J].管理科学学报,2017,20(3):24?45.
BING Tao, LIU Shancun, ZHANG Qiang, et al. The optimal trading strategy of uninformed traders in an order driven market [J]. Journal of management sciences in China, 2017, 20(3): 24?45.
[3] 刘翠霞,史代敏.基于关系聚类的动态面板数据模型及其应用研究[J].统计与信息论坛,2015,30(3):10?16.
LIU Cuixia, SHI Daimin. Dynamic panel data model and its application based on structural relationships of clustering analysis [J]. Statistics & information forum, 2015, 30(3): 10?16.endprint
[4] 谢洪安,李栋,苏旸,等.基于聚类分析的可信网络管理模型[J].计算机应用,2016,36(9):2447?2451.
XIE Hongan, LI Dong, SU Yang, et al. Trusted network management model based on clustering analysis [J]. Journal of computer applications, 2016, 36(9): 2447?2451.
[5] 李镇镇,李晓东,李飞,等.基于动态聚类分析和盲数理论的综合营养状态指数评价模型[J].环境工程学报,2015,9(4):2021?2026.
LI Zhenzhen, LI Xiaodong, LI Fei, et al. Improved assessment model for comprehensive trophic state index based on dynamic cluster analysis and blind theory [J]. Chinese journal of environmental engineering, 2015, 9(4): 2021?2026.
[6] 李娜,王磊,张文月,等.基于高维数据优化聚类的长周期峰谷时段划分模型研究[J].现代电力,2016,33(4):67?71.
LI Na, WANG Lei, ZHANG Wenyue, et al. Research on the partition model of long period peak and valley time based on high dimensional data clustering [J]. Modern electric power, 2016, 33(4): 67?71.
[7] 孙善武,王楠,欧阳丹彤.基于聚类分析的业务流程模型抽象[J].计算机科学,2016,43(5):193?197.
SUN Shanwu, WANG Nan, OUYANG Dantong. Business process model abstraction based on cluster analysis [J]. Computer science, 2016, 43(5): 193?197.
[8] 迟志浩,于艳雪,周萍,等.基于有害生物集群的聚类分析在入侵生物定殖研究中的应用[J].中国植保导刊,2017,37(1):17?22.
CHI Zhihao, YU Yanxue, ZHOU Ping, et al. Application of clustering analysis based on invasive pest assemblage in invasive pest establishment [J]. China plant protection, 2017, 37(1): 17?22.
[9] 杨超宇,杨顶田.基于聚类分析算法的浮游植物吸收系数非线性模型[J].中国激光,2015,42(z1):244?249.
YANG Chaoyu, YANG Dingtian. A non?linear model of phytoplankton absorption based on cluster analysis [J]. Chinese journal of lasers, 2015, 42(S1): 244?249.
[10] 陈玉川.物联网走进中国家庭的技术条件分析[J].物联网技术,2015,5(11):66?69.
CHEN Yuchuan. Technical condition analysis for Internet of Things going into Chinese families [J]. Internet of Things technologies, 2015, 5(11): 66?69.endprint
