TPTVer: A Trusted Third Party Based Trusted Verifier for Multi-Layered Outsourced Big Data System in Cloud Environment
2018-03-13JingZhanXudongFanLeiCaiYaqiGaoJunxiZhuangCollegeofComputerScienceFacultyofInformationTechnologyBeijingUniversityofTechnologyBeijingChinaBeijingKeyLaboratoryofTrustedComputingBeijingChinaNationalEngineeringLaboratoryforC
Jing Zhan, Xudong Fan Lei Cai Yaqi Gao Junxi Zhuang College of Computer Science, Faculty of Information Technology, Beijing University of Technology, Beijing, China Beijing Key Laboratory of Trusted Computing, Beijing, China National Engineering Laboratory for Critical Technologies of Information Security Classified Protection, Beijing, China
I. INTRODUCTION
Cloud computing can provide scalable computing environment for the customers, which can be very useful for big data computation.However, there are also serious security doubts [6][10]. Suppose a big data owner does not want to manage the IT infrastructure and the details of data processing technique. He or she may outsource data processing work to a service provider for data computation (DCSP).Then the DCSP may rent cloud service (e.g.,Hadoop [2] service in VMs on the cloud) from a cloud service provider (CSP). In order to do the work for the data owner, the DCSP and the CSP have to work together with this two-layered outsourced service system, which we mention later in this paper as multi-layered outsourced big data system. This means the data owner actually delegates the power to access the data to different service providers, probably in different service forms too.Naturally, there may be interest conflicts between all the participants (e.g., the data owner,DCSP, and CSP) in data computation process,which can bring to security risks for the big data. In addition, if one of the multi-layered services is attacked, all participants may be affected.
On the one hand, due to security sensitivity of big data, the data owner often finds it hard to trust outsourced services. This is because the data owner lacks the techniques to verify outsourced services, and it is even harder to verify which part of which outsourced service causes the problem. On the other hand, the CSP and DCSP may have problems to trust each other’s codes.
We mainly review two fields of studies related to the trust issues mentioned above:
1) Cloud service and platform verification:trusted computing[4][20][26] proposes concept of the chain of trust with a hardware chip called trusted platform module (TPM) as the root of trust of the platform, which provides trusted measurement, storage and report functions for the hardware and software running on the platform. IBM proposes the first Linux integrity measurement architecture IMA [5],together with trusted boot loader [16][17], the chain of trust can be extended from the hardware to the applications. TCCP [13] proposes two protocols for the CSP to verify remote resources and VMs in cloud with a Trusted Coordinator. Ta-TCS [12] uses VM introspection to attest the integrity of tenants’ services for them. All of them focus on VM security (IaaS security).
2) Big data service and application security:secure and fine-grained access control for big data is a big problem for the big data system[14]. Hadoop uses simple access control lists[3] [11] to make sure that one client’s specific MapReduce application [1] data cache can only be accessed by the same client and application. Nevertheless, the MapReduce applications from different client can easily collude to leak data owner’s sensitive data by reading/writing to common directory [23]. TMR [9]proposed MapReduce architecture based on IMA by using the TaskTracker to report its state periodically for worker nodes verifications. SecureMR [15] aims at protecting the integrity of MapReduce data processing services, and proposes to reduce the replications rate based on probability models. Secure protocols are used for encrypting the task information, and signing the outputs. VC3 [18]allows users to run MapReduce computations protected by SGX hardware [24] on cloud platforms without trusting Hadoop, operating system and hypervisor, which can prevent attacks due to unsafe memory reads and writes.However, none of above researches can prevent malicious MapReduce application itself by leaking data to the CSP or other cloud users intentionally. Airavat [7] combines MAC and privacy policies to prevent data leakage with network and storage device. Nevertheless,users can only use Airavat provided reducer.GuardMR [8] provides fine-grained MapReduce policy enforcement mechanism on key-value level of user data, but only considered filtering of the inputs of Map, and relies on the security of Java sandbox.
In this paper, we presents the TPTVer for trusted verification in outsourced big data computation context. We propose a new three-level definition of the verification and threat model based on different roles in multi-layered outsourced big data system.We also propose three kinds of corresponding trusted policies based on the threats. In TPTVer, we presents two policy enforcement methods for trusted data computation environment: the first one extends the chain of trust up to MapReduce application, while the second one monitors and controls MapReduce application’s behaviors with AOP. Finally, to prevent privacy information leakage from verification logs of service providers, we provide a privacy-preserved verification method for measurement log. Our evaluation and analysis show that the TPTVer can provide trusted verification for every participant in multi-layered outsourced big data system with low overhead.
II. THREAT MODEL
In this paper, we mainly discuss data leakage threats and consider the verifiability of all the entities participating in data computation process for the data owner, during which the data is normally processed in plain text. Once the CSP (e.g., host root, VM root, Hadoop admin)and the DCSP (e.g., MapReduce applications provider) can access the data, there would be data leakage possibilities between the CSP and the DCSP, or among the DCSPs (cloud tenants).
The data leakage may happen under four situations as depicted ingure 1. Here we suppose that the original CSP codes on the cloud do not intentionally try to leak the data. E.g.,these codes may be on some kind of white list and are certied by third party. We discuss the data leakage problem for four situations:
1) The CSP codes are tampered with by DCSP or outside attacker before execution,and then leak data owner’s data. The CSP codes are not designed to be malicious in therst place.
2) Insider theft of data owner’s data by malicious CSP (e.g., cloud platform admin).The malicious CSP can abuse or manipulate its codes (on the white list) or tamper DCSP’s code with the intention of stealing data owner’s data. E.g., the CSP may copy the VM with data in it while maintaining, or the CSP may exploit software vulnerability to launch a ROP(Return to Programming) attack [25] during which getting the data directly from memory.Here we assume the malicious CSP do not directly execute codes with malicious purpose,since it is easy to be traced back.
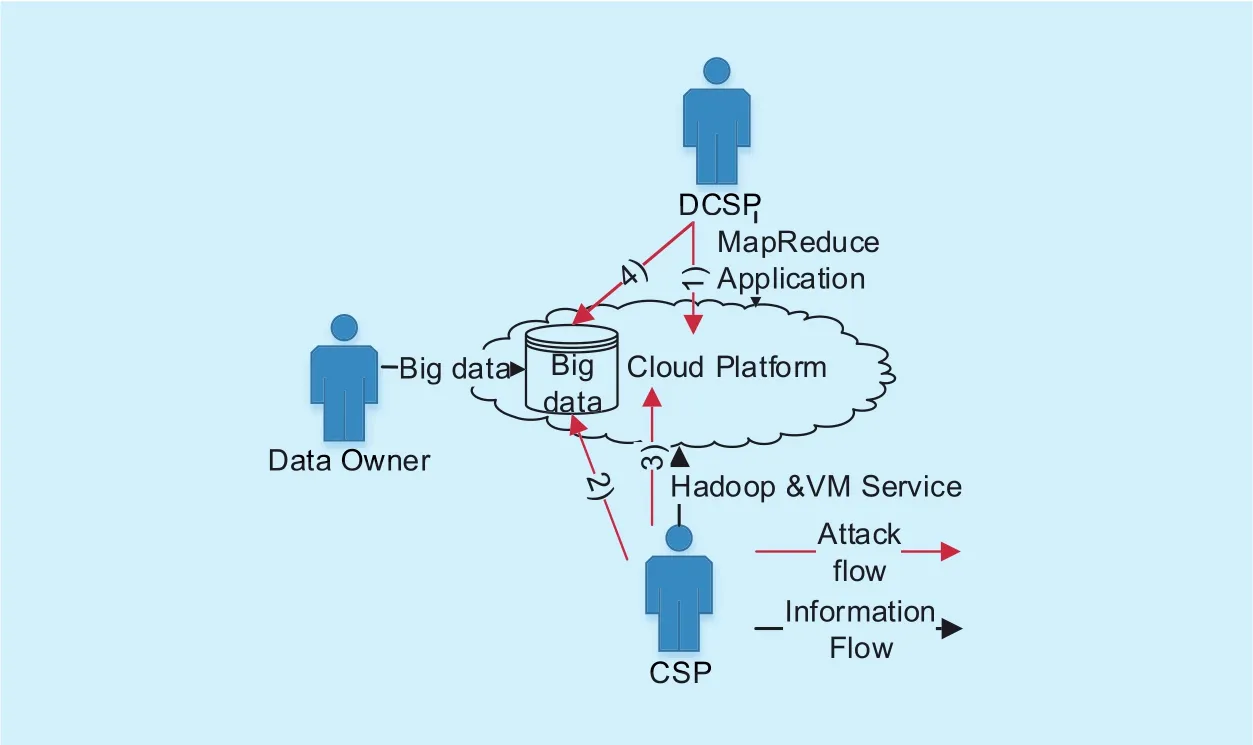
Fig. 1. Security threats to multi-layered outsourced big data system.
3) DCSP’s applications are tampered with by the CSP or outside attacker before execution, and then leak data owner’s data. This is on the premise that the original DCSP codes do not intentionally try to leak the data, which we will discuss later.
4) Insider theft of data owner’s data by malicious DCSP’s application. Since the DCSP’s applications often deal with the data directly in customized way, it is hard to have a certied white list of all the DCSP’s applications,which means censoring every DCSP code to make sure it does not pose threats to data owner’s data or cloud service and not cause data leakage. Therefore, a malicious DCSP may upload and use a malicious application intentionally try to leak the data. Here we assume the malicious DCSP will not abuse its codes or manipulate its codes from memory to leak the data owner’s data, since the DCSP can already manipulate <key, value> pairs, hdfsles and even VMles during computation process.
At last, since the outside attackers need to get the CSP’s or DCSP’s privilege to leak data owner’s data, the outside attacker can be treated as tampered or malicious CSP/DCSP.
Besides data leakage problem, a malicious CSP/DCSP can also abuse CSP/DCSP codes,which causes Denial of Data Service (e.g., Hadoop Service).
To be more clear, we take a specic example to show what multi-layered outsourced big data system is and to discuss the attacks to the data owner’s data in details, see togure 2. The data owner uses DCSP’s MapReduce application for data computation and the DCSP uses CSP’s Hadoop Service (including the YARN for resource management and the HDFS for data storage) in the virtual machines provided by Openstack service in cloud. Note that there could be many DCSPs as the cloud capacity and CSP’s policy allow,since the DCSPs are cloud tenants. Therefore,the multi-layered outsourced big data system contains the MapReduce application, Hadoop service, Openstack service and other software from cloud host platform.
This is how the multi-layered outsourced big data system works: after a data owner asks for a DCSP’s service, the data owner uploads data and the DCSP submits the computation application (e.g., MapReduce application) separately to the cloud. The DCSP then run the application as a MR job, and the CSP’s Hadoop service (e.g., YARN) assigns the job to different nodes (namely Hadoop NameNode and DataNodes as VM nodes) and run the job as Map/Reduce tasks, which process the <key,value> pairs of the data for the data owner.
Naturally, the CSP and DCSP distrust each other in the outsourced scenario.
On the one hand, since the CSP provides both IaaS service (VM) and PaaS service (Hadoop service), the CSP may be tampered with by the DCSP or outside attackers. In addition,the malicious CSP administrator can access data owner’s data through the host files, VM files, hdfs files and even memory. Malicious CSP can also launch denial of service attack by executing system codes in hosts and VMs.
On the other hand, since the DCSP provides data computation service and rents CSP’s Hadoop service, the DCSP’s application may be tampered with by the CSP or outside attackers.In addition, the malicious DCSP can access its data owner’s sensitive <key, value> pairs, hdfs files, VM files in computation process, then access other DCSP’s cache data through hdfsles and leak them. Malicious DCSP can also launch denial of Hadoop service attack by executing system codes in CSP’s VM. Here we assume that the virtualization isolation provided by the hypervisor on the host platform is strong enough for preventing the DCSP’s code from penetrating.
Beyond the above trust issues, the data owner has no means to know which part from which service provider cause potential risks for his/her data.
In summary, a big data system faces four kinds of data leakage threats from different roles:
1) Tampered CSP, which means the cloud codes are tampered with and may be used to leak data without known by the DCSP and the data owner;
2) Malicious CSP, which means big data owner’s data can be leaked in the form of hdfs files, VM files, host files and even memory without known by the DCSP and data owner;

Fig. 2. Attack points for multi-layered outsourced big data system.
3) Tampered DCSP, which means Ma-pReduce application codes are tampered with and may be used to leak data without known by the DCSP and data owner;
4) Malicious DCSP, which means data owner’s data can be leaked in the form of <key,value>, hdfs files, VM files without known by the CSP and data owner.
Therefore, in order to improve the trust and mitigate the threats above in outsourced big data system, there is strong need to provide the verification of all participants.
III. POLICY MODEL FOR TRUSTED VERIFICATION
Once the data owner uploads the data, he or she has no clue whether there is data leakage,let alone which part of which service has problem since the data computation service is outsourced. In order to provide viable and secure verification of all service providers in the data computation process, we propose a new three-level definition of the verification,and provide the policy model fulfilling the requirements of trusted verification for the threat model explained in section 2.
3.1 Trusted verification
In order to evaluate the process of verification for all participants of the big data system, we propose the definition of trusted verification. If and only if the verification is both strong and privacy-preserved, we call the verification as trusted verification.
Definition 1 Weak Verification. The data owner can only rely on the DCSP and/or the CSP to find out data leakage.
With weak verification, the data owner has no choice but to trust the DCSP and the CSP.However, the data owner cannot verify if the leakage is caused by the DCSP or the CSP.
Definition 2 Strong Verification.In addition to weak verification, the data owner, the DCSP and the CSP should be able to find out which part of which outsourced service is responsible for the data leakage. This is strong verification.
We use trusted third party (TTP) to make sure of strong verification. The TTP needs to make standards about which property the service provider must have and the TTP must be able to verify it, so that data owner, the DCSP and the CSP can all find out whether there is the data leakage threat since some properties are not satisfied through the TTP.
Definition 3 Privacy-preserved Verification. In addition to strong verification, the verification process should not leak all participants’ privacy information.
As mentioned in section 2, the CSP provides Hadoop services for multiple tenants;but traditional binary-based attestation measurement log contains lots of security state related information for the tenant’s verification. Therefore, we make a few improvements to preserve the privacy of service providers during the process of verification.
3.2 Policy model
We propose three kinds of policies to mitigate the threats analyzed by section 2.
1) For threat 1 and 3, extended trusted measurement policy can be used for finding tampered CSP and DCSP. For the CSP with complicated software stack, trusted measurement policy can also tell which part is exposed to the threats.
Since the CSP has total control on Hadoop service and host platform, and the DCSP provides the MapReduce application. If any of the CSP and DCSP codes is tampered with by outside attacker or each other, data leakage may happen without known by the data owner.
We define extended trusted measurement policy as following for these threats: the integrity of all executable files and related configuration files (namely white list), which should not be changed, need to be verified by the TTP. The integrity of these files are protected by Trusted Platform Module (TPM).
2) For threat 4, MapReduce behavior measurement policy can be used for malicious DCSP.
The malicious DCSP has total control of the MapReduce application, and is capable of stealing data on the cloud from data owner.
We propose AOP based MapReduce behavior measurement policy for this threat, including:
(1) Prohibiting unwanted reading/writing of data owner’s data to local filesystem through JAVA filesystem API, and prohibiting unwanted reading/writing of hdfs filesystem and<key, value> data through Hadoop API, which can prevent the data leakage from current MapReduce application to the CSP or other DCSP who shares the same Hadoop service with current DCSP;
(2) Prohibiting unwanted writing to local system files through JAVA filesystem API,which can prevent the CSP codes from being tampered with by the DCSP. These local system files, including Hadoop service related executable files and configuration files, might be changed by Hadoop admin for maintenance needs, which means these files may not be protected by the extended trusted measurement policy. In addition, if a DCSP is mistakenly assigned with Hadoop admin privilege,the DCSP can tamper underlying CSP Hadoop service and cause data leakage or denial of data service.
(3) Prohibiting executing unexpected local system codes, which can prevent malicious MapReduce application from harming the CSP platform. These files include Hadoop service and system service related scripts/binaries and configurations. Even if these files are protected by the extended trusted measurement policy, a malicious DCSP can start/stop these codes and therefore cause denial of data/system service.
3) For threat 2, the mandatory access control (MAC) policy may be not enough but can be used to mitigate it.
The problem is malicious CSPs can do everything since they already have all the privileges one can possibly get. One way to limit their power is MAC policy enforced by secure OS. E.g., Airavat [7] has used SELinux to enforce MAC policy for local system root.Here, in addition to the extended trusted measurement policy preventing the CSP from executing possible malicious codes that are not on the white list, we suggest configuring SELinux MAC policy to prevent the CSP from accessing the data owner’s data in the form of host files, VM files, hdfs files. However, this MAC policy can only be useful if the codes on the white list behave well, which is not true since the running code may have vulnerabilities and be manipulated in memory to steal sensitive data (e.g., with a ROP attack). We will discuss it later in section VI since it is out of scope for this paper.
In this paper, we mainly focus on the former two kinds of policies and them. The extended trusted measurement policy makes sure that the only files on the white list can be executed, while the MapReduce behavior measurement policy makes sure that the DCSP codes on the white list have no malicious intention for the CSP or data owner.
We use XACML to describe these two policies. We use <Subject> to describe the subject who takes a security related action,<Resource> for the object, which the policy is enforced on, <Action> for the operation that the subject takes, <Effect>for the policy decision made for this action.
Table 1 lists the former two trusted policies we provides. The policies 1-2 belongs to the extended trusted measurement policy, while the rest belongs to the MapReduce behavior measurement policy, which we explain as the following.
Policy 1 is the traditional trusted measurement policy, which permit/deny CSP local files’ execution according to the white list,which can be enforced by the OS kernel (e.g.,the IMA kernel module).
Policy 2 extends the trusted measurement policy by permitting/denying the MapReduce job’s execution according to the DCSP’s and the data owner’s expectation, which can be enforced by the Hadoop service.
Policy 3 prohibits the MapReduce application from accessing other applications’file cache data on the Hadoop DataNode and MapReduce node. The cache data contain all Hadoop service tenants’ application data.
Policy 4 prohibits the MapReduce application from accessing sensitive Hadoop HDFS data. These data contains all MapReduce job related files (e.g., hdfs://tmp/*) and all MapReduce job related input and output files(e.g., hdfs://user/$username/*).

Table I. Extended trusted measurement policy and MapReduce behavior measurement policy.
Policy 3-4 can prevent one DCSP’s application data from leaking to another DCSP or the CSP.
Policy 5 requires the MapReduce application to filter the <key, value> pair according to data owner’s filtering requirements. With this policy, the data owner can make sure that the DCSP deals the data according to the data owner’s expectation in case the DCSP manipulates the content of the data. For example,the data owner can make sure the DCSP filter sensitive keywords from the input or output.
Policy 6 prohibits the MapReduce application from tampering Hadoop service, which only happens if the DCSP application has the Hadoop admin privilege and should be avoided by assigning every DCSP with normal Hadoop user privilege.
Policy 7 permit/deny the MapReduce application from tampering CSP’s IaaS and Hadoop service by executing unexpected codes according to the white list.
IV. SYSTEM DESIGN
4.1 Architecture
We propose TPTVer, a TtP based Trusted Verifier for multi-layered outsourced big data system in cloud environment, as depicted in Figure 3. The red modules consist of the TPTVer.
The TPTVer are divided into the TTP-end and CSP-end components. While the TTP-end component receives verification requests from the DCSP, the data owner and the CSP, and provides corresponding reports for TTP-end,the CSP-end components collect the measurement of cloud platforms and Hadoop service for the CSP-end component.

Fig. 3. TPTVer architecture.
The CSP-end components consist of CSP-end daemons, trusted measurements collector and IMA, trusted resource manager, and trusted MR program/task. All measurements are extended into the TPM in physical host platform or virtual TPM (vTPM) in the Hadoop VMs to make sure the measurements are tamper-proof, which we’ll explain later in this sub-section.
The CSP-end daemons in Hadoop master node and cloud control node collect measurements logs from the cloud and communicate with the TTP-end TPTVer.
The trusted measurements collector in every Hadoop VM and cloud host platform collects the trusted measurement logs generated by the IMA for the Hadoop VMs and cloud host platforms. In addition, the TPTVer uses the trusted resource manager and trusted MapReduce program to collect its trusted and behavior measurement logs separately.
While all the measurement logs form the Hadoop VM collected by trusted measurements collector, resource manager and MapReduce tasks are written into HDFS and sent to the CSP-end daemon in the master node, all the measurement logs in the cloud hosts from trusted measurements collector are sent to the CSP-end daemon in the cloud control node.
The security (tamper-proof) of the TPTVer relies on the TPM, the IMA Linux kernel security module and vTPM, which protect the TPTVer from being tampered with and guarantee integrity of the PCR values for future verification and integrity of the logs for the data owner, the DCSP and the CSP. This is how it works:
1) When a platform boots with the TPM,the BIOS and firmware codes’ binary values are calculated and written to different TPM PCR in order, just before it is to be loaded.
2) The code’s detailed information (e.g.,the name, version and the hash of the binary value) are recorded to event log stored in hard disk.
3) The hash value of the binary is extended into TPM PCR in this way:
PCR new value=hash (PCR old value ||
hash of the code’s binary value).
4) The TPM cumulatively computes all loaded codes’ hash value and stores the final value in PCR, which cannot be tampered with since it is in the tamper-proof hardware.
5) When a verifier needs to verify if only trusted (not tampered) codes are loaded, the verifier uses the event log to re-compute the PCR value. If verifier’s value equals the value inside the TPM PCR, it means the integrity of all codes in event log are not tampered with.
With the help of the trusted boot loader and the IMA, the chain of trust is extended from booting firmware to OS loader, OS, and the applications, even VM images. After the VM image is running, the vTPM and the IMA in the VM can work as the TPM and the IMA in the host. Note that the vTPM is actually software emulator of the TPM, so the integrity of vTPM itself can only be protected by lower layer software and hardware, such as the IMA and TPM on the host platform. Every time when the OS loads an application, the IMA will call the TPM/vTPM to extend the application’s binary hash value into the PCR. In this way, the TPTVer itself (in both the host and VM) is measured by the IMA, and the integrity of measurement is guaranteed by the TPM/vTPM PCR.

Table II. Extended trusted measurement algorithm for MapReduce application.
4.2 Extended trusted measurement for MapReduce application
The Hadoop resource manager (RM) is in charge of managing and assigning resources of the Hadoop cluster. One of the important job of the RM is to launch the MapReduce job, which makes the RM is the perfect entity to measure all newly submitted MapReduce Applications.
The RM itself is a part of Hadoop service and its integrity is already protected by the IMA. Therefore, we extend the original RM to trusted RM, which takes integrity measurements of submitted MapReduce job and data,whose measurements can be used against the DSCP and data owner to verify if it is the same job that the DCSP submitted and the same data that the data owner uploaded. The MapReduce job related files includes jar package, input data and job configuration files.
The expected extended trusted measurement policy for MapReduce application is described in XACML in table 1 policy 2. Our corresponding trusted measurement algorithm is presented in table 2 as following. We suppose the log information is extended into the platform configuration register (PCR) with the index t (9<t<24) in vTPM.
4.3 MapReduce behavior measurement policy enforcement
The behavior of a MapReduce application is determined by security related APIs. We use AOP, a programming paradigm, to generate security related API policy enforcement logics for the MapReduce applications, which is weaved into the original MapReduce applications, so the new combined application, denoted as the trusted MapReduce application will run as the policy tells.
The expected behavior policies are de-scribed in XACML in table 1 policy 3-7. We implemented the policy enforcement logics as the AOP pointcut() and around() functions.The pointcut() codes shows the API behavior that need to be monitored, while the around()codes shows what to do with monitored behavior according to the XACML policy.
First, take the data leakage scenario as the example for monitored API choosing.Since we monitor three kinds of malicious MapReduce behaviors: reading/writing VM files, hdfs files, and <key, value> data, the monitored API can be chosen as: 1) JAVA io.FileReader/FileWriter, 2) Hadoop fs.FSDataInpuStream.read/write, 3) MapReduce Mapper/Reducer/RecordReader. These three kinds of API monitoring are used for the enforcement of policies 3-5 listed in table 1.
Besides the data leakage scenario, the MapReduce application may also try to tamper Hadoop service or underlying cloud platform by changing or executing codes related files of Hadoop or system. For example, if the DCSP application is mistakenly assigned with Hadoop administrator privilege, it can tamper Hadoop service (e.g., changing Hadoop executable files, configuration files). Furthermore, the DCSP application can also tamper the Hadoop or system by executing unexpected codes. We check these misbehaviors by monitoring the following APIs: 1) JAVA io.FileReader/FileWriter, 2) JAVA Runtime.getRuntime().exec(..). These two kinds of API monitoring are used for the enforcement of policies 6-7 listed in table 1.
We use the around() function in AOP to enforce the expected policy to MapReduce application, extend the behavior log into the vTPM PCR with the index t+1 in Hadoop master node and record the events in behavior measurement log, which is presented in table 3. Note t is already used in trusted measurement algorithm.
4.4 Privacy-preserved Log Verification
There are two kinds of events logs in the TPTVer, which are trusted measurements log and MapReduce behavior measurements log. Both of them have privacy problems.
Trusted measurements logs of all host and VM platforms contain lots of log entries with sensitive vulnerabilities related information(e.g., software name, version and binary hash value, which can lead to vulnerability based attack), and therefore should not be exposed to the public[21].
In addition, as mentioned in section 4.3,the Hadoop service in the cloud is provided to multiple cloud tenants. Nevertheless, all MapReduce behavior measurements are stored in Hadoop master node’s PCR, which are definitely not sufficient if we try to assign one PCR to one tenant. Therefore, it is reasonable to extend all tenants’ MapReduce behavior measurements into one PCR. In this case, one tenant’s private event log would be exposed to other tenants who should only verify his own behaviors.

Table III. Behavior measurement policy enforcement algorithm for MapReduce application.
This means our goal is to prevent the sensitive software information leakage in the event logs without affecting the verification process.We can use either the TTP-end TPTVer or CSP-end TPTVer to convert the original logs containing the privacy information to the privacy-preserved log (denoted as PP log) sent to the challenging user, who tries to verify if the log conforms to expected policy. Here we chose to strip the privacy information by the CSP-end TPTVer for possible future TTP based audit.However, stripping by the CSP-end TPTVer is good enough for user’s verification.

Table IV. PCR setting and original log generation algorithm

Table V. Privacy-preserved log generation algorithm.
In order to solve the privacy problem, the original log generation process in the cloud needs a few changes as the algorithm in table 4 describes. The idea is to add a random number (RN) for the original event’s hash calculation. The final hash value of the event is denoted as RH. In this way, even the identical measurement event can get different hash value of log entry in the event log, which delinks the specific hash value from the unique software or behavior.
On the request of the challenging user, the TTP needs to convert the sensitive entries in the original log into RH values for the privacy-preserved log, as the table 5 shows.
For the extended trusted measurement and verification, we hide the sensitive software’s information other than the software-id and RH in the log. Now the verifier cannot relate specific sensitive software to RH, since RH is different every time and cannot be linked to the real software or its binary value.
However, the user also wants to know if the software is untampered. We ask the platform administrator to give the log (including all the RNs) to the TTP to verify it. If the verification is successful, the TTP clears all sensitive software information in the log, only leaves general information (e.g., software id) and the RH. TTP then issues property certificate to all sensitive software in the log. With the property certificate and the PP log, the user can then verify the system for himself/herself.
Note that the original log should not be public, otherwise the linkage between the binary values to the software will also become public.
As for the MapReduce behavior measurement and verification, namely the multitenant case, there is only one difference. The user does not need to know any information about other tenants, so the TTP can clear all other tenants’ behavior information in the log on the verification request of a challenging user. When verified by the challenger, the TTP shows the PP log, and the challenger can verify it for himself/herself.
Figure 4 shows the original log sent to TTP and the privacy-preserved logs sent to challenging user “zj”. In privacy-preserved logs,user1 and user2’s log entries are replaced with RH, which contain RN and cannot leak sensitive information.
V. EVALUATION AND ANALYSIS
5.1 Setup
We set up a three-node OpenStack environ-ment for our experiments: one node acting as both the controller and network node, the other two acting as compute nodes. Table 6 shows the hardware configuration of these three nodes.

Fig. 4. Privacy-preserved log verification for MapReduce application trusted measurement and behavior measurement.
5.2 Overhead of Extended Trusted Measurements
We use the IMA and swtpm [19] as vTPM and run the extended trusted measurements for the Hadoop VM platform. Furthermore, we run Wordcount MapReduce application with the
input file size of 1Gb for 5 times. As table 7 shows, the average MapReduce measurement overhead time caused by trusted resource manager is 6.11s, which is mainly determined by the size of input file.
5.3 Performance of MapReduce behavior measurements
We run a Wordcount MapReduce sample with combined malicious behaviors described in section 4.3 under different input data sizes and user numbers for the evaluation. Overhead of behavior measurements mainly comes from policy analysis and enforcement.
Table VI. Setup congurations.

Table VII. Overhead of extended trusted measurements.
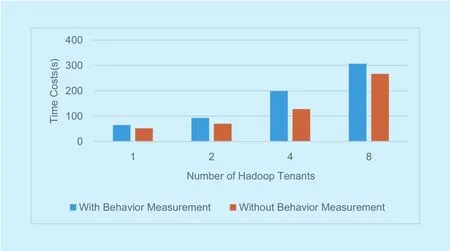
Fig. 5. Data size impact on MapReduce behavior measurements.
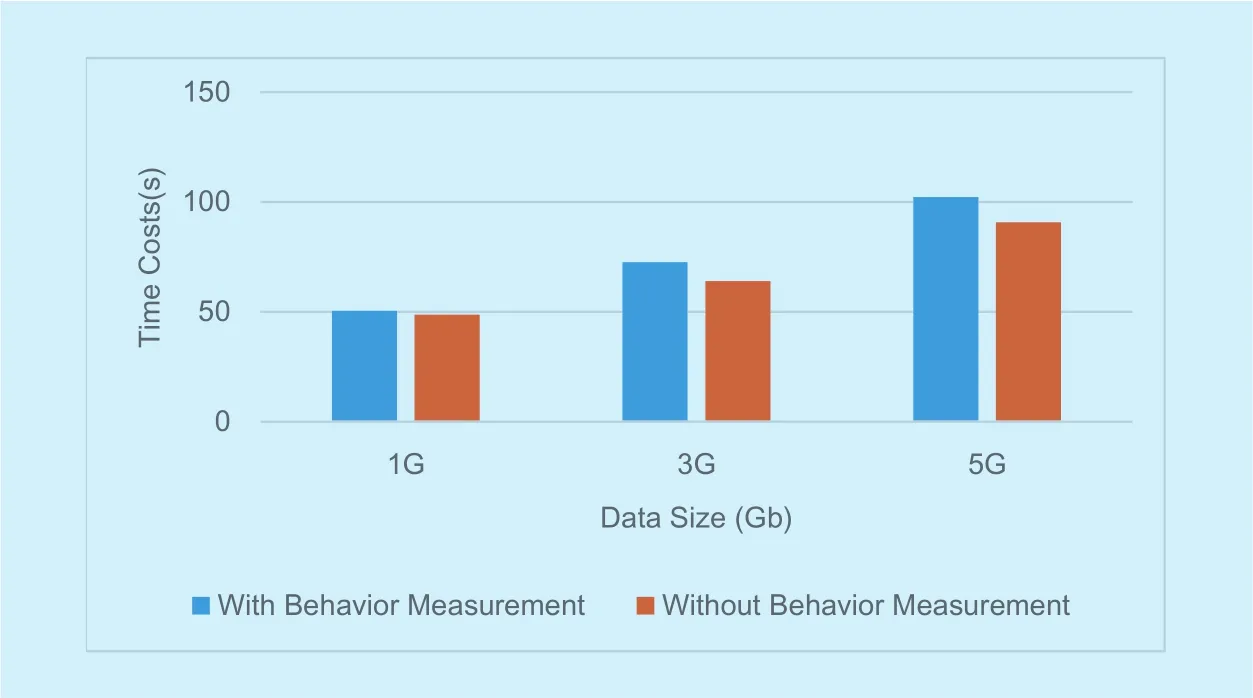
Fig. 6. End user impact on MapReduce behavior measurements.
With the data size growing from 1G, 3G to 5G, we run the sample with and without behavior measurement each for 5 times. The average overhead of the sample with the measurement to the original sample is 3.6%,13.3%, 12.7%.
With the Hadoop tenants numbers growing from 1, 2, 4 to 8 with 1G input data, we run the same sample with and without behavior measurement each for 3 times. The average overhead of the sample with the measurement to the original sample is 25%, 32.9%, 55.5%,14.9%.
Note that both performances get much better when the workloads get heavier, which means the overheads we cause do not affect the original MapReduce job.
5.4 Performance of privacy preserved log verication for the challenger
We compare the time costs of privacy-preserved log verification to traditional log verification for challenging user. After the challenger requests the event log for verication,the TPTVer generates the privacy-preserved log from the original one, sends the log and the PCR value to the challenger for verification, while in the traditional log verification process, the challenger verifies the original event log containing all privacy information.The log generation time from the cloud server side and the original log verication time from TTP server side are not included since we assume that the cloud and TTP has much more resources than challenging user so that these time costs are negligible for the challenger.
We setup two users for verification, and each of them contributes 50% percent for the original event log, with the log entry number growing from 500, 1000, 1500 to 2000. As figure 7 shows, compared to the traditional log verification, the ratio of the time costs of privacy-preserved log verification for the challenger to time costs of traditional log verification in percentage are 98.2%, 89.1%,88.3%, 86.8%. This is because in the privacy-preserved log, the challenger does not need to verify other users’ measurement log entries.
VI. DISCUSSION
As defined in section 3.1, we define trusted verication for outsourced big data system in cloud environment as both strong and privacy-preserved verication.
For strong verification, the TPTVer monitors all hosts and VM platforms’ executable files belonging to the CSP and the DCSP on the white list. In this way, the TPTVer can verify which part of CSP or DCSP service or application is tampered with according to policies 1-2 (extended trusted measurement policy). Furthermore, the TPTVer uses MapReduce behavior measurement logs to verify if malicious DCSP is trying to leak data owner’s data or to tamper the CSP services according to policies 3-7 (MapReduce behavior measurement policy).
However, the TPTVer cannot find out if a malicious CSP with host or VM root privilege accesses data owner’s data with the code on the white list. E.g., the CSP can open and copy the data in the form of VM and/or hostle resources. It can happen because it breaks the principle of least privilege, which can be restricted by designing a more secure OS [21]or by using secure OS like SELinux as Airavat [7] with strict mandatary access control(MAC).
Although strict MAC policy enforced by the OS can be helpful, it is not enough. Even if the privilege is restricted, the CSP or DCSP codes probably have vulnerabilities. When loaded into memory, the code can be exploited and manipulated to steal the data (e.g., with 0-day vulnerability and ROP attack). One way to mitigate the threat is to use SGX to reduce target code’s TCB (Trusted Computing Base)as VC3[18], by putting the security-sensitive part code into isolated and certiable computing environment (SGX enclave). In this way,attacks due to unsafe memory reads and writes can be mitigated. However, VC3 does not deal with the threat caused by malicious DCSP code that may intentionally leak the data,which is mitigated by our MapReduce behavior measurement policy, which means we can combine VC3 and our work to get safer computing environment for the data owner and the CSP/DCSP.
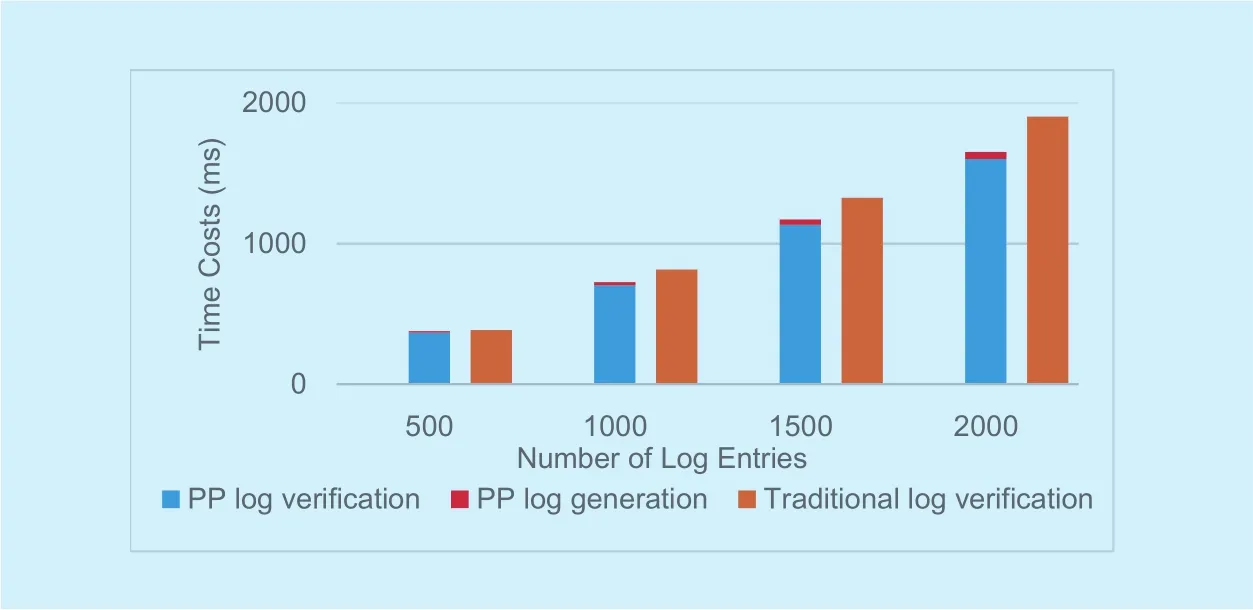
Fig. 7. Time costs of privacy-preserved log verication compared to the traditional log verication for the challenger.
For privacy-preserved verification, the TPTVer converts measurements log of host and VM platforms and all tenant’s behavior measurement log into PP log without sensitive information. In this way, the challengers gain both the veriability and privacy by accessing and verifying only self-related log information.
Note the original logs containing all privacy information about CSP’s hardware and software, DCSP applications and behaviors should be protected. On the one hand, the original logs can be sent to TTP-end TPTVer for privacy information stripping, so the logs may be useful for TTP based future audit. On the other hand, the CSP-end TPTVer can do privacy information stripping so that the TTP only has partial logs which is good enough for challenger’s verification request. Either way,the original or partial logs sent to TTP contain challenger’s privacy information and need to be protected from unauthorized access. One possible solution is using trusted computing technology to protect the TTP-end or CSP-end’s server integrity and restrict the access of the logs to only trusted process.
VII. CONCLUSION
In this paper, we present the TPTVer for trusted verification in outsourced big data computation context. We propose a new three-level definition of the verification and threat model based on different roles in multi-layered outsourced big data system. We also propose three kinds of corresponding trusted policies based on the threats. In TPTVer, we presents two policy enforcement methods, providing trusted data computation environment by extending the chain of trust to MapReduce application, and MapReduce application’s behavior measurement based on AOP. Finally, to prevent privacy information leakage from verification logs of service providers, we provide a privacy-preserved verification method for measurement log. Our evaluation and analysis show that the TPTVer can provide trusted verification for multi-layered outsourced big data system with low overhead.
ACKNOWLEDGMENT
This work is partially supported by grants from the China 863 High-tech Program (Grant No.2015AA016002), the Specialized Research Fund for the Doctoral Program of Higher Education (Grant No. 20131103120001), the National Key Research and Development Program of China (Grant No. 2016YFB0800204),the National Science Foundation of China(No. 61502017), and the Scientific Research Common Program of Beijing Municipal Commission of Education (KM201710005024).
[1] J. Dean, and S. Ghemawat, “MapReduce: simplified data processing on large clusters,” Communications of the ACM, vol. 51, no. 1, 2008, pp.107-112.
[2] T. White, “Hadoop, The definitive guide.” O’Reilly Media, Inc., 2012.
[3] The Apache Software Foundation, “Service Level Authorization Guide,” 2015, http://hadoop.apache.org/docs/r2.7.0/hadoop-project-dist/hadoop-common/ServiceLevelAuth.html,
[4] Trusted Computing Group, “TCG Specification Architecture Overview Specification Revision 1.4,” 2007, www.trustedcomputinggroup.org.
[5] R. Sailer, et al, “Design and Implementation of a TCG-based Integrity Measurement Architecture,” Proc. USENIX Security Symposium, 2004,pp. 223-238.
[6] W. Liu, “Research on cloud computing security problem and strategy,” Proc. IEEE 2nd International Conference on Consumer Electronics,Communications and Networks (CECNet), 2012,pp. 1216-1219.
[7] I. Roy, S. T.V. Setty, A. Kilzer, et al, “Security and Privacy for MapReduce,” Proc. NSDI, 2010, pp.297-312.
[8] H. Ulusoy, P. Colombo, E. Ferrari, et al, “Guard-MR: fine-grained security policy enforcement for MapReduce systems,” Proc. the 10th ACM Symposium on Information, Computer and Communications Security, 2015, pp. 285-296.
[9] A. Ruan, A. Martin, “TMR: Towards a trusted mapreduce infrastructure,” Proc. IEEE Eighth World Congress on Services (SERVICES), 2012,pp. 141-148.
[10] K. Zhang, X. Zhou, Y. Chen, X. Wang, Y. Ruan,“Sedic: privacy-aware data intensive computing on hybrid clouds,” Proc. the 18th ACM Conference on Computer and Communications Security, CCS, 2011, pp. 515-526.
[11] S. Saklikar, “Embedding Security and Trust Primitives within Map Reduce,” 2012, http://www.emc-china.com/rsaconference/2012/en/download.php?pdf_file=TC-2003_EN.pdf
[12] J. Ren, L. Liu, D. Zhang, Q. Zhang, H. Ba, “Tenants Attested Trusted Cloud Service,” Proc. IEEE 9th International Conference on Cloud Computing,2016, pp. 600-607.
[13] N. Santos, K. P. Gummadi, and R. Rodrigues,“Towards trusted cloud computing”, Proc. Conference on Hot Topics in Cloud Computing,HotCloud’09, 2009, pp. .
[14] H. Li, M. Zhang, D. Feng, Z. Hui, “Research on Access Control of Big Data,” Chines Journal of Computers (In chinese), vol. 40, no. 1, 2017, pp.72-91.
[15] W. Wei, J. Du, T. Yu, “SecureMR: A Service Integrity Assurance Framework for MapReduce,”Proc. Computer Security Applications Conference, 2010, pp. 73-82.
[16] Trusted grub. GRUB TCG Patch to support Trusted Boot. 2015, http://trousers.sourceforge.net/grub.html.
[17] B. Kauer, “OSLO: Improving the Security of Trusted Computing,” Proc. USENIX Security,2007, pp.229-237 .
[18] F. Schuster, M. Costa, C. Fournet, C. Gkantsidis,M. Peinado, G. Mainar-Ruiz, and M. Russinovich,“VC3: Trustworthy Data Analytics in the Cloud Using SGX,” Proc. IEEE Symposium on Security and Privacy (SP ‘15), 2015, pp. 38-54.
[19] S. Berger. “swtpm,” 2017, https://github.com/stefanberger/swtpm.
[20] C. Shen, H. Zhang, H. Wang, et al, “Research on Trusted Computing and Its Development,”Science in China Series E: Information Sciences,vol. 53, no. 3, 2010, pp. 405-433.
[21] J. Liao, Y. Zhao, J. Zhan, “Trust Model Based on Structured Protection for High Level Security System,” China Communications, vol. 9, no. 11,2012, pp. 70-77.
[22] R. Korthaus, A. Sadeghi, C. Stüble, and J. Zhan,“A practical property-based bootstrap architecture,” Proc. ACM workshop on Scalable trusted computing (STC ‘09). 2009, pp. 29-38.
[23] Z. Yan, J. Zhan, “Big Data Application Mode and Security Risk Analysis,” Computer and Modernization (In chinese), vol. 228, no. 8, 2014, pp 58-61.
[24] I. Anati, S. Gueron, S. Johnson, and V. Scarlata,“Innovative technology for CPU based attestation and sealing,” Proc. Workshop on Hardware and Architectural Support for Security and Privacy (HASP), 2013, pp. 1-6.
[25] R.Roemer, E.Buchanan, H.Shacham, and S.Savage, “Return-Oriented Programming: Systems,Languages, and Applications,” ACM Trans. Information System Security, vol. 15, no. 1, 2012,pp.1-36.
[26] J. Wang, Y. Shi, H. Zhang, B. Zhao, F. Yan, F. Yu,L. Zhang, “Survey on Key Technology Development and Application in Trusted Computing,”China Communications, vol.13, no.11, 2016,pp.70-90.
杂志排行

China Communications的其它文章
- CYBERSPACE SECURITY: FOR A BETTER LIFE AND WORK
- A Cloud-Assisted Malware Detection and Suppression Framework for Wireless Multimedia System in IoT Based on Dynamic Differential Game
- An Integration Testing Framework and Evaluation Metric for Vulnerability Mining Methods
- Powermitter: Data Exfiltration from Air-Gapped Computer through Switching Power Supply
- CAPT: Context-Aware Provenance Tracing for Attack Investigation
- Decentralized Attribute-Based Encryption and Data Sharing Scheme in Cloud Storage