基于扩展词典与语义规则的中文微博情感分析
2018-03-13李继东王移芝
李继东,王移芝
(北京交通大学计算机与信息技术学院,北京 100044)
0 引 言
微型博客作为Web2.0时代新生的社会化媒体平台,是一个用于信息分享、信息传播和信息获取的平台,具有实时性、开放性与自由性的特点,用户可以通过微博自由和便捷地获得信息和表达情感。这使得微博成为近几年来国内最为热门的互联网应用之一。根据新浪微博发布的《微博2016 Q3财报》显示,新浪微博的月活跃用户达到2.97亿,年对年增长34%。
由于人们一般是通过微博表情达意,抒发自己的观点和态度,所以这些微博数据中包含了海量的情感文本信息。对这些数据加以利用,分析这些情感文本信息可以获得巨大的潜在价值:对政府来说,将网民们对新颁发制度的评价和讨论进行汇总分析可以知道人民对于政府政策的看法和意见;对于企业来说,将用户对于公司和产品的评价和反馈进行汇总分析,可以更好地促进公司的发展和产品的研发;对于消费者来说,将其他网友对于某些商品的意见和评论进行汇总分析可以为自己购买商品时提供参考依据和标准。
而且微博情感分析也涉及数据挖掘、信息检索等众多领域,具有广泛的应用价值。因此如何能自动准确地处理和分析微博文本情感信息已经成为当前的研究热点。本文从此目的出发,通过对爬取的9万条微博数据进行分析,基于扩展的情感词典和语义规则的方法对微博的情感值进行计算,实现一个面向中文微博的情感分析系统。
1 相关工作
当前文本情感分析的方法主要有基于语义的和基于机器学习的情感分析方法。所谓的基于语义,就是先统计出微博文本中的情感词,给情感词赋予情感权值,然后再通过加权求和方法得出单个语句以及整个文本的情感值。而基于机器学习的方法就是将微博看成分类问题来处理,使用机器学习的方法构造分类器,使用标注好的训练集训练分类器,将文本分为正面、负面和中性情感3类。常用的方法有支持向量机(SVM)、朴素贝叶斯法(NB)、K最近邻法(KNN)和中心向量法等。
国外的研究主要是针对Twitter的数据进行情感分析。Barbosa和Feng[1]通过将对Twitter进行情感分析的结果做为训练数据,选用特征,采用二步分类法对微博数据进行分类。Jiang和Yu等人[2]运用五折交叉的方法验证了情感词典和主题相关的特征可以提高分类效果的准确性。Go等人[3]在采用朴素贝叶斯、最大熵和支持向量机3种机器学习方法的同时,加入了表情符号这一微博特殊特征,大大提高了微博情感倾向判别的准确率。
中文微博的情感研究起步较晚,国内的研究主要是针对新浪微博的数据进行展开。肖江等人[4]针对中文微博创建了微博领域情感词典,并验证了该分析策略具有一定的可行性和准确率。梁亚伟[5]考虑到表情符号在微博情感分析中的重要性,采用加窗的方法计算表情符号的情感强度,实现了自动化的微博表情情感词典的构建。周剑锋等人[6]通过对微博语料进行分词统计,筛选情感新词,使用PMI算法计算情感新词的情感倾向和强度,构建微博情感词典,并结合规则对中文微博进行无监督情感分析。陈晓东[7]通过引入情感基准词的同义词对PMI算法进行了改进,通过实验证明对改善数据稀疏问题起到了一定作用。
基于机器学习的方法一般适用于新闻报道、论坛等长文本数据集和传统情感分析。而微博文本短小精悍、口语化,还富含表情符号,所以基于机器学习的中文微博情感分析方法存在处理过程复杂、判断准确率低等问题[8]。本文采用基于语义的方法,在现有的研究成果和分析方法的基础上,通过改进的SO-PMI算法来创建微博领域词典,并考虑语义规则对微博文本情感倾向的影响,采用扩展的情感词典加语义规则的分析策略进行微博情感计算,并利用微博表情词典对最终的结果加以修正。
2 情感词典的构建
情感词典是情感分析的基础,能否构建一个覆盖面广、质量高的情感词典会直接影响情感分析的效果。现有的情感词典使用较多的有:知网情感词典、台湾大学的简体中文情感极性词典、大连理工情感词典[9]。其中大连理工情感词典情感词汇的数量最多,而且词典中对情感词汇的词性、情感强度、情感极性都进行了标注,所以本文以该词典作为创建基础情感词典的基础。
2.1 基础情感词典
本文在大连理工情感词典的基础上,对知网情感词典和台湾大学的简体中文情感极性词典进行整合和优化,将3者整合成一部基础情感词典。考虑到不同情感词典的构建方法的不同,可能存在同一情感词在不同的情感词典中情感极性不同的情况,本文采用投票规则和优先权规则:当情感词同时出现在3部情感词典中,有2个词典中的极性是一致的,就将该情感词极性定为这2个词典的极性;如果情感词只出现在2部或者1部情感词典中,或者出现在3部词典中但是在3部词典中极性都不一样,这个时候根据权威性,设定优先权“知网情感词典>大连理工情感词典>台湾大学情感词典”[10],然后按照这个优先权来确定词汇的极性。
在通常情况下,不同的情感词具有不同的语气和情感强度,例如:“愉快”和“惊喜”,“伤心”和“绝望”等,在进行微博情感分析时,需要给情感词汇赋予不同的权值。本文采用大连理工情感词典中原有情感权值的分类,将情感词的情感权值分为5个强度,用1,3,5,7,9来表示,1位强度最小,9位强度最大[11],并且将正向情感词标注极性为1,反向情感词极性为2。基础情感词典的具体格式如表1所示。
表1 基础情感词典示例

情感词名称权值情感极性绝望92伤心52惊喜71愉快51
随着互联网的快速发展,产生了很多的网络词汇。这些词汇不同于传统的词语,它们更加的精简以及口语化,部分网络词汇也具有强烈的情感色彩。例如:“脑残”、“抓狂”、“稀饭”等,由于当前热门的输入法都会根据用户的打字习惯来识别网络新词并加入自己的词库[12],本文通过人工的方式从当前用户使用量最多的3大输入法“搜狗输入法”[13]、“百度输入法”和“QQ输入法”的词库中整理筛选出150个最常用的并且具有强烈感情色彩的网络新词,并给各个网络新词赋予不同的权值以及情感极性,然后加入基础情感词典。
2.2 领域情感词典的创建和PMI算法的拓展
基础情感词典囊括的情感词是有限的,而且由于微博文本具有明显的非正式、口语化的特点,微博中可能出现很多特殊情感词汇,这些词汇无法在传统的情感词典中找到。因此,本文构建一个专门的微博领域情感词典。首先获取情感词候选词,然后通过计算确定候选词的情感极性,最后将情感词加入到微博领域情感词典中。本文在对微博语料进行分析整理时发现,微博文本中出现的包含情感色彩的新词一般都是和程度级别词语一起使用,例如“非常给力”中的“给力”,“扎心得不得了”中的“扎心”等,所以可以通过程度级别词语来发现微博新情感词。本文选用知网的程度级别词语词典,当在微博文本中发现程度词后,将该程度词之后的2,3,4个字符划分出来作为候选情感词,一些程度词如“之极”“之至”“不得了”等,将这些程度词前面的2,3,4个字符划分出来作为候选情感词,对这些情感候选词做预处理、筛选、倾向性判断。
然后,计算候选词与基准词之间的语义相似度,这里采用的方法是PMI算法,基本思想就是统计2个词语在文本中同时出现的概率,如果概率越大,其相关性就越紧密,关联度越高。
根据式(1)计算候选词与基准词之间的语义相似度。
(1)
其中p(pwords & word)表示基准词pwords和候选词word在微博文本中同时出现的概率,p(pwords)表示基准词pwords单独出现的概率,p(word)表示候选词word单独出现的概率。
然后,通过计算候选词与褒贬基准词SO-PMI值的差值来确定候选词的情感倾向,根据式(2)计算结果确定候选词情感倾向。

(2)
式(2)中Pwords为正向基准词组,Nwords为负向基准词组,word为候选词。当SO-PMI(word)>0时,候选词word为正向词;当SO-PMI(word)<0时,候选词word为负向词;当SO-PMI(word)=0时,候选词为中性词。然后将确定了情感倾向的候选词加入到微博领域情感词典中。
关于PMI算法中基准词的选取,郭叶等人[14]论证了采用40对基准词的情况下准确率能达到81.37%,当前构建微博领域词典的研究在基准词的选取时,都是选取中文词汇作为基准词。但是使用PMI算法不可避免地会出现数据稀疏的问题[15],在一些情况下,当候选词与基准情感词共现的次数为0时,就会造成候选词的SO-PMI值为0,从而被认定为中性词。但是微博文本中含有大量的包含强烈情感色彩的微博表情,例如“真的很膈应”这条微博,候选词“膈应”并没有与其他情感词汇一起出现,但是博文中却出现了一个具有强烈情感色彩的表示“恶心”的表情。所以本文对PMI算法进行了扩展,在选取基准词时,按照词频的从高到低人工选择出20对具有强烈的情感色彩的词语,褒贬倾向的词语各10对,同时选出20对具有强烈情感色彩的微博表情,褒贬倾向的表情各10对。
2.3 微博表情符号词典
微博文本中很多表情都包含强烈的情感色彩,有时可以通过微博中的表情判断出微博的情感倾向性。本文通过对抓取的微博数据进行分词和词频统计[16],按照从高到低的顺序人工筛选出127个微博表情符号,将这些表情标注情感倾向性和情感强度之后加入微博表情词典。
2.4 程度副词词典
在对微博文本进行情感分析时需要考虑程度副词的影响,程度副词的使用会直接影响微博所表达的情感的强弱。本文采用知网的程度级别词典(中文版),词典中共有219个程度级别词语。程度级别词典如表2所示。
表2 程度级别词典
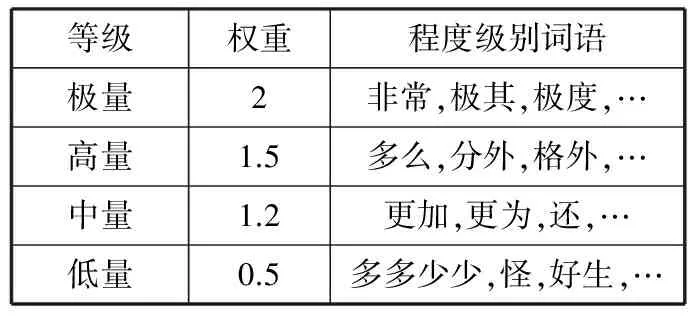
等级权重程度级别词语极量2非常,极其,极度,…高量1.5多么,分外,格外,…中量1.2更加,更为,还,…低量0.5多多少少,怪,好生,…
2.5 否定词典
否定词修饰情感词汇时,一般都会改变文本的情感极性,如果正向的情感词前面有否定词修饰,情感倾向就会变为负向,反之亦然。同时还存在双重否定词的情况,当有双重否定词修饰时,一般不会改变句子的情感倾向。所以本文构建了一个否定词典,将词典中的否定词权值设为-1,双重否定词权值设为1。否定词典如表3所示。
表3 否定词典

类型权值词语否定词-1不,没,无,非,莫,弗,勿,毋,未,否,别,無,休,…双重否定词1不是不,不可能不,无不,无非,不无,未必不,不得不,…
2.6 连词词典
连词是句子之间的连接词,连词有转折连词,递进连词、因果连词、让步连词、假设连词等,句子之间连词的不同对文本情感倾向的分析也有一定的影响。本文整理收集常用连词构建了一个连词词典,如表4所示。
表4 连词词典
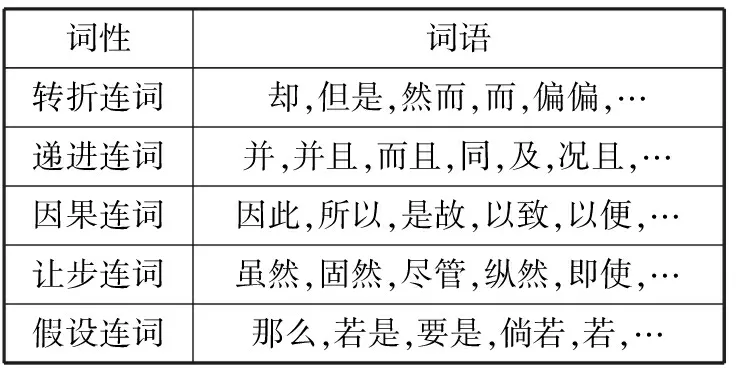
词性词语转折连词却,但是,然而,而,偏偏,…递进连词并,并且,而且,同,及,况且,…因果连词因此,所以,是故,以致,以便,…让步连词虽然,固然,尽管,纵然,即使,…假设连词那么,若是,要是,倘若,若,…
至此,微博文本情感倾向性分析所需情感词典的构建已经完成,情感词典共由基础情感词典、微博领域情感词典、微博表情符号词典、程度词典、否定词典、连词词典6部分组成。
3 微博文本语义规则
微博文本的情感分析光依靠情感词典是不够的,需要同时考虑语义规则和词语搭配对情感分析的影响。下面针对情感分析时需要考虑的词语搭配、句型规则和句间规则进行阐述。
3.1 词语搭配分析规则
主要分析程度级别词语、否定词以及双重否定词修饰情感词时对情感分析的影响。
1)程度级别词语修饰规则。当情感词前出现程度级别词语修饰时,情感倾向与情感词保持一致,但是情感强度会根据前面修饰的程度级别词语的不同有所增强或减弱。本文在创建程度级别词语词典时,对词典中每一个词语都进行了权值的标注,例如:“非常开心”,“非常”的权值是2,当前的情感强度就会在情感词“开心”的情感强度的基础上乘上2。
2)否定词语修饰规则。当情感词前面出现否定词修饰时,则当前的情感倾向与情感词前面修饰的否定词的个数有关。当出现奇数个否定词时,情感倾向与情感词相反;当出现偶数个否定词时,情感倾向与情感词一致。在实验中计算时,通过情感词的情感强度乘上(-1)的n次方来实现,n表示否定词出现的次数。如果情感词前面出现的是双重否定词,则当前的情感倾向与情感词一致,在计算时双重否定词的权值被设为1。
3)程度词否定词同时修饰规则。当情感词前面有程度级别词语和否定词同时修饰时,情感强度可能会有增强或者减弱,这个依据否定词和程度词语两者出现的位置。当否定词出现在程度词前时,例如:“今天不是很高兴”整体表达的是不高兴的倾向,但是强度较“不高兴”有所减弱;当程度词出现在否定词前时,例如:“今天很不高兴”同样表达的是不高兴的倾向,但是强度较“不高兴”有所增强。
3.2 句型分析规则
常见的中文句型有陈述句、疑问句和感叹句。其中疑问句中的反问句会使得整句的情感倾向变成相反的倾向。感叹句不会改变整句的情感倾向,但是会增强整句的情感强度。这里所分析的句型规则都是应用在一个完整的句子上的,即先将微博文本通过“?”“!”“。”和“;”分割成多个复句,可以用集合{C1,C2,C3,…,Ci}来表示微博文本划分后复句的集合,Ci表示第i个复句。这里用Wi表示当前句型规则对整个复句情感值的影响权值。在实验计算时,针对各种句型的规则如下:
1)陈述句规则。如果复句Ci是陈述句,那么Wi=1。
2)疑问句规则。如果复句Ci为疑问句,即句子以“?”结尾,并且含有反问标志词“难道”、“怎能”等,或者句子不以“?”结尾,但是也含有反问标志词时,那么Wi=-1.5。如果句子以“?”结尾但是不含有反问标志词,那么Wi=1。
3)感叹句规则。如果复句Ci为感叹句,即句子以“!”结尾,那么Wi=2。
3.3 句间分析规则
除了对整个复句的分析之外,还需要考虑在复句中各个子句之间的句间关系,这个也会对文本的情感分析造成一定的影响。会造成影响的句间关系有转折、递进、假设关系。定义集合{E1,E2,E3,…,Ei,…,Ej}为复句C中的分句集合,Si表示句间关系对分句Ei的影响权值。
1)转折关系规则。转折关系一般会发生情感倾向的翻转,后句与前句的情感倾向相反,并且情感倾向的决定一般在后句上。具体规则如下:
①如果复句C中只有单一转折后接词出现(如“但是”“但”“可是”等)且出现在分句Ek中,或者复句C中有成对的转折标志词(如“虽然……但是……”)出现,但是转折后接词出现在分句Ek中,则S1,S2,S3,…,Sk-1=0,而Sk,Sk+1,Sk+2,…,Sj=1。
②如果复句C中只有单一的转折前接词出现(如“虽然”“尽管”等)且出现在分句Ek中,则S1,S2,S3,…,Sk-1=1,而Sk,Sk+1,Sk+2,…,Sj=0。
2)递进关系规则。递进关系中,分句的情感强度后句会比前句有所增强。规则如下:
如果复句C中出现递进关系标志词(如“更有甚者”“更加”)且出现在分句Ek中,则S1,S2,S3…,Sk-1=1,而Sk,Sk+1,Sk+2,…,Sj=1.5。
3)假设关系规则。假设关系在实际的语境中,一般情感表达的重心在前句,后句的语气则有所弱化,而且如果是否定假设,则句子的情感倾向会变为相反的倾向。规则如下:
①如果复句C中没有出现否定假设标志词,而出现假设关系后接词(如“那么”)且出现在分句Ek中,则S1,S2,S3,…,Sk-1=1,而Sk,Sk+1,Sk+2,…,Sj=0.5。
②如果复句C中出现否定假设标志词(如“如果不”),而假设后接词(如“那么”)出现在分句Ek中,那么S1,S2,S3,…,Sk-1=-1,而Sk,Sk+1,Sk+2,…,Sj=-0.5。
上述3种句间关系都会对情感分析造成一定的影响,至于其他的句间关系如并列关系、因果关系、一般关系,这些关系一般并不会对前后句造成情感倾向和情感强度上的变化,所以本文不作具体规定,Si则全部设为1。
3.4 特殊语义规则
Shen等人[17]经过统计研究发现,50%以上的微博中,最后一个分句表现的情感极性能代表整条微博的情感极性,本文通过对抓取的微博数据进行整理分析发现,一般微博的最后一个分句表达的情感倾向确实最接近博主想要表达的情感倾向。基于这个结论,本文在进行微博文本情感分析时采用了如下特殊规则:
当微博的最后一条分句的情感值经过计算后不为0时,将最后一条分句的情感倾向作为整条微博的情感倾向;如果最后一条分句的情感值经计算为0,也就是最后一条分句不表达情感倾向时,再按照本文所提的基于情感词典和语义规则来对整条微博进行情感分析。
3.5 微博文本与表情加权规则
在进行微博分析时,当前的研究一般是将微博表情直接等同于情感词典中的情感词使用。王文等人[8]通过研究,提出将表情情感值与文本情感值加权作为最后的结果,这样可以为细粒度的情感数值计算提供方便且充分利用了表情符号的信息,而且文中研究当表情与文本的权值比例为0.4和0.6时,加权后微博的情感倾向性判断准确率有明显的提升。因此,本文算法也沿用0.4和0.6这一加权比例,对微博文本进行最终的情感加权计算。
4 微博综合情感计算
本文前面已经创建了情感词典,并且对文本情感分析时可能对分析结果造成影响的语义规则进行了分析并制定了规则,给出了各种规则的相关参数。本章通过这些词典、参数对微博文本进行综合的情感计算。计算过程从范围的由小到大,先计算词语的情感值,接着是分句的情感值,然后是复句的情感值,最后是整条微博的情感值。
4.1 情感词语的情感值
当通过情感词典匹配到情感词时,设置一个大小为5的滑动窗口,向情感词前匹配5个字的长度,看是否存在程度副词或者否定词。这里设程度副词权值为Deg,否定词的权值为Den(Den为多个否定词最后的综合权值,采用单个否定词的权值相乘来得到),情感词汇i的情感强度为Wi,最终情感词的情感值为E(Wi):
1)只有程度副词修饰,则E(Wi)=Deg×Wi。
只有否定词修饰,则E(Wi)=Den×Wi。
3)程度副词出现在否定词前面(如“很不高兴”),则E(Wi)=Deg×Den×Wi。
4)程度副词出现在否定词后面(如“不是很高兴”),则E(Wi)=0.5×Den×Wi。
4.2 分句的情感值
设分句Si的情感值为E(Si),则E(Si)可以表示为:
E(Si)=(∑E(Wi))×Vi
(3)
式(3)中,E(Wi)表示分句内第i个情感词语的情感值,Vi表示当前分句Si的句间关系权值。分句Si的情感值就是分句内所有情感词语的情感值之和再乘以当前分句的句间关系权值。
4.3 复句的情感值
设复句Ci的情感值为E(Ci),则E(Ci)可以表示为:
E(Ci)=(∑E(Si))×Wi
(4)
式(4)中,E(Si)为复句内第i个分句的情感值,Wi为当前复句的句型关系权值。复句Ci的情感值E(Ci)就是复句内所有分句的情感值之和再乘以当前复句的句型关系权值。
4.4 文本的综合情感值
文本的综合情感值设为Etext,则Etext可以表示为:
Etext=∑E(Ci)
(5)
式(5)中,E(Ci)表示微博文本中复句Ci的情感值,微博文本内容的情感值等于文本内复句的情感值之和。
4.5 微博表情的情感值
设微博表情符号的综合情感值为Eemotion,则Eemotion可以表示为:
Eemotion=∑Emoi
(6)
式(6)中,Emoi表示微博中第i个表情符号的情感值。微博表情的综合情感值等于当前微博内各个表情的情感值之和。
4.6 微博的最终情感值
设当前微博的最终情感值为E,当前微博的最后一条分句的情感值为E(Slast),如果E(Slast)>0,则将这条微博判定为正向微博;如果E(Slast)<0,则将这条微博判定为负向微博。如果E(Slast)=0,再接着计算整条微博的最终情感值。这时候E可以表示为:
E=0.6×Etext+0.4×Eemotion
(7)
式(7)为通过微博文本和微博表情进行加权计算后得出的微博的最终情感值。如果E>0,则当前微博情感为正向情感;如果E=0,则为中性情感;如果E<0,则为负向情感。
5 微博情感分析实验
5.1 实验数据
本文从新浪微博“社会”“娱乐”“体育”“影视”“政治”5个方面共爬取微博数据80000条。通过文中介绍的构造情感词典的方法,创建的基础情感词典中共有情感词9412个,其中正向情感词4702个,负向情感词4710个;按照文中介绍的方法创建微博领域情感词典,词典中共有新情感词3622个,其中正向情感词1978个,负向情感词1644个。测试数据集是从各个领域中平衡地选出3000条测试微博,经过人工标注后,3000条微博数据包含的正向、负向和中性情感微博数如表5所示。
表5 微博数据统计表

正向微博负向微博中性微博微博总数91286412243000
5.2 实验性能评价指标
本次实验的评估指标采用的是目前使用广泛的正确率(Precision)、召回率(Recall)和综合度量指标F值(F):
(8)
(9)
(10)
5.3 实验结果与分析
为了验证本文构建的微博领域词典的作用和基于规则集的情感分析方法的有效性,本文通过表6中的方法对测试数据进行了实验,并对结果进行分析与评价。
表6 对比实验结果

实验方法微博类别PrecisionRecallF基础词典+表情正向0.6980.6910.694负向0.6920.6690.680中性0.5840.6570.618基础词典+领域词典+表情正向0.7210.7130.717负向0.7050.6120.655中性0.5630.6680.611基础词典+领域词典+语义规则+表情正向0.7540.7230.738负向0.7410.6530.694中性0.6150.6820.647
通过以上3组实验,对实验结果进行如下分析:
1)通过实验结果看出,仅仅依靠基础情感词典和微博表情加权进行分析的准确率不是很高。一方面是由于微博中包含了很多新的领域情感词,这些情感词在基础情感词典中是没有包含的,另一方面,中文的表述比较复杂,反问、反语、欲扬先抑、欲抑先扬等语义规则如果不考虑的话,会对情感倾向的分析造成不小的影响。所以提高情感词典的覆盖面和考虑语义规则对情感分析时一个很重要的原因。
2)通过对判为正向的微博数据进行分析发现,一些判断失误的原因主要是因为微博使用了反讽的表达形式,比如“风婆婆您好厉害啊,5,6级的吹还不过瘾,还7,8级的狂欢”,可以看到本微博中包含了“厉害”“狂欢”多个正向情感词,所以被判定为正向情感微博,但是其实博主是采用了反讽的表达方式,所以在对这些特殊的表达方式方面还需要进一步的研究。
3)由上面3组的实验结果可以看出,中性情感微博判断准确率比正向和负向的都要低,通过对误判的中性微博进行分析发现,大部分误判的原因是因为这些中性微博中存在一些作为副词出现的情感形容词,比如“中国房地产和房价只能涨不能跌,不是民生问题,而是一个严肃的政治问题”,句中的“严肃”在基础情感词典中是作为反向情感词存在的,但是其实这只是博主在阐述一个事实,并没有反向的情感倾向,所以这就造成了对分析的影响。
4)通过第二组和第三组实验对比发现,在加入语义规则之后,负向微博的F值提升最大,说明加入语义规则对负向微博的情感分析效果最好。通过对测试的负向微博进行分析,发现在考虑到反问、转折等规则后,之前的一些判断错误的微博也可以判断正确,如“难道这样有意思吗?”,这条微博在之前就被错误的判定为正向微博,在加入语义规则后则可以准确判断。
5)还有一些误判的结果是由一词多义造成的,这个问题很普遍,在不同的语境下,同一个词语表达的是不同倾向的意义,比如“你真是太厉害了”和“看给你厉害的,你咋不上天呢”,2句中都有情感词“厉害”,但是2句的情感倾向确实截然相反,尽管可以对一词多义的词语进行筛选,但是由于微博语言的自由和随意性,还是不断地有一词多义的词语出现,所以这种情况也对实验的结果造成了影响。
实验表明,在对情感词典进行扩展,并加入了语义规则的考虑之后,都使得微博情感分析的效果得到提升,与加入扩展的领域词典相比,加入语义规则之后的提升效果更加明显。在考虑准确率、召回率、F值的评价标准下,本文的基于扩展的情感词典和语义规则的情感分析方法具有一定的改善效果。
6 结束语
本文对已有的微博情感分析方法进行分析研究,通过分析整合知网、台湾大学以及大连理工3部情感词典,构建范围更广的基础情感词典,并且通过输入法把网络新词加入基础情感词典中。还通过分析微博情感新词出现特征,根据程度词发现新词并通过SO-PMI算法分析语义相似度,从而构建微博领域情感词典。最后对语义规则进行分析以及考虑微博符号表情加权问题,提出基于扩展的情感词典和语义规则的微博情感分析方法,并通过实验验证了此方法的有效性。
后续的工作将着手考虑更多的特殊语法和表达形式,比如反语,还有一词多义的问题;同时可以根据微博的特殊性,在情感分析时还可以从微博话题、微博转发、用户关系等方面来考虑。总之,中文微博不断地更新发展,微博的情感分析也是一个比较热门的研究领域,还有很多方法需要进行更深入的研究。
[1] Barbosa L, Feng Junlan. Robust sentiment detection on Twitter from biased and noisy data[C]// Proceedings of the 23rd International Conference on Computational Linguistics: Posters. 2010:36-44.
[2] Jiang Long, Yu Mo, Zhou Ming, et al. Target-dependent Twitter sentiment classification[C]// Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies. 2011:151-160.
[3] Go A, Bhayani R, Huang Lei. Twitter sentiment classification using distant supervision[J]. CS224N Project Report, 2009,44(1):1-12.
[4] 肖江,丁星,何荣杰. 基于领域情感词典的中文微博情感分析[J]. 电子设计工程, 2015,23(12):18-21.
[5] 梁亚伟. 基于表情词典的中文微博情感分析模型研究[J]. 现代计算机, 2015(14):7-10.
[6] 周剑锋,阳爱民,周咏梅. 基于中文微博的情感词典构建及分类方法[J]. 计算机与数字工程, 2014,42(10):1773-1776.
[7] 陈晓东. 基于情感词典的中文微博情感倾向性分析研究[D]. 武汉:华中科技大学, 2012.
[8] 王文,王树锋,李洪华. 基于文本语义和表情倾向的微博情感分析方法[J]. 南京理工大学学报, 2014,38(6):733-738.
[9] 徐琳宏,林鸿飞,潘宇,等. 情感词汇本体的构造[J]. 情报学报, 2008,27(2):180-185.
[10] 阳爱民,林江豪,周咏梅. 中文文本情感词典构建方法[J]. 计算机科学与探索, 2013,7(11):1033-1039.
[11] 朱嫣岚,闵锦,周雅倩,等. 基于HowNet的词汇语义倾向计算[J]. 中文信息学报, 2006,20(1):14-20.
[12] 陈国兰. 基于情感词典和语义规则的微博情感分析[J]. 情报探索, 2016(2):1-6.
[13] 张昊昊,石博莹,刘栩宏. 基于权值算法的中文情感分析系统研究与实现[J]. 计算机应用研究, 2012,29(12):4571-4573.
[14] 郭叶. 中文句子情感倾向分析[D]. 北京:北京邮电大学, 2010.
[15] 王振宇,吴泽衡,胡方涛. 基于HowNet和PMI的词语情感极性计算[J]. 计算机工程, 2012,38(15):187-189.
[16] 桂斌,杨小平,张中夏,等. 基于微博表情符号的情感词典构建研究[J]. 北京理工大学学报, 2014,34(5):537-541.
[17] Shen Yang, Li Shuchen, Zheng Ling, et al. Emotion mining research on micro-blog[C]// 2009 1st IEEE Symposium on Web Society. 2009:71-75.
[18] 赵天齐,姚海鹏,方超,等. 语义规则与表情加权融合的微博情感分析方法[J]. 重庆邮电大学学报(自然科学版), 2016,28(4):503-510.
