CPU和DRAM加速任务划分方法:大数据处理中Hash Joins的加速实例
2018-03-13吴林阳郭雪婷
吴林阳 罗 蓉 郭雪婷 郭 崎
(中国科学院计算技术研究所 北京 100190)(wulinyang@ict.ac.cn)
在设计现代计算机系统时首先要考虑的因素是能效.为了提高系统能效,诸如FPGA,GPU和定制加速器等硬件加速器已被广泛应用于工业领域.使用硬件加速器的典型案例有:微软组建FPGA服务器用于加速大规模的数据中心服务[1];亚马逊于2010年开始部署GPU云服务器;惠普实验室为Memcached定制加速器[2].通常,硬件加速器集成在处理器芯片中(例如SIMD单元、卷积引擎[3]、IBM的PowerEN[4]),或部署为一个独立的芯片(例如GPU显卡、FPGA板卡和Xeon Phi协处理器),通过PCI-E与主处理器进行通信.
随着靠近数据的处理(near-data processing)技术的出现,将硬件加速器集成到DRAM堆栈中以降低数据移动的成本成为一种新的系统设计思路.其基本思想是利用3D堆叠技术,将一些包含加速器的逻辑die和多个DRAM die垂直集成到一个芯片中[5-7].然而,由于3D堆叠DRAM在面积、功耗、散热和制造等方面的限制,能够集成到DRAM中的加速器的数量和类型是有限的.因此,给定一个需要加速的目标应用,确定其中哪些部分最适合在DRAM中加速是至关重要的.
理想的加速目标应该是内存带宽受限的,因为3D堆叠DRAM具有比现有系统高一个数量级的高内存带宽.一个最典型的例子是数据重组操作,它是许多应用领域的关键组成部分,如高性能计算、信号处理和生物信息学.数据重组只包含CPU和DRAM之间的往返数据移动,它不消耗浮点运算周期.因此,在DRAM中加速数据重组是很自然的想法,文献[8]中论证了这项工作.但是对于大多数真实应用程序来说,它们混合了计算和数据移动,情况更为复杂.
在本文中,我们进行了一个hash joins的案例研究,探索如何将它在CPU和DRAM之间进行合适的加速任务划分.选择hash joins有3个原因:1)hash joins不仅是传统数据库系统的基本操作,还是诸如Spark[9]等主流大数据系统的关键操作;2)很多文献都对hash joins做了充分研究[10-15],因此加速的baseline已经高度优化;3)最先进的hash joins: optimized version of radix join algorithm(PRO)[11,15]是带宽资源受限的,它可能会从内存加速中受益.我们对PRO以及PARSEC benchmark suite中具有代表性的多线程应用程序分别进行了带宽分析,如图1所示.平均来看,PRO对带宽的需求比使用8线程的PARSEC benchmark高3.6倍.与PARSEC benchmark suite中带宽资源受限最严重的streamcluster相比,在2,4和8线程下,PRO仍多消耗143%,117%和18%的带宽资源.
为了研究在PRO中内存访问对总能耗的贡献,我们对PRO的3个不同阶段:partition,build和probe,进行了详细的能耗分析.虽然所有阶段的内存带宽都趋于饱和,但各个阶段中计算所消耗的能量差异是很大的.在partition阶段,计算消耗的能量还不到该阶段总能量的50%;而在build和probe阶段,计算消耗的能量占总能量的85%以上.换句话说,数据移动消耗的能量是partition阶段能耗的主要部分.主要的原因是在partition阶段有许多高代价的非规则内存访问,而其他2个阶段只有常规的内存访问.因此,仅在DRAM端加速partition阶段,在CPU端加速其余阶段是有意义的.为了加速partition阶段,我们构建了适合于3D堆叠结构的hash分区加速器(hash partition accelerator, HPA).为了加快build和probe阶段,我们采用传统的SIMD加速单元来提高计算效率.
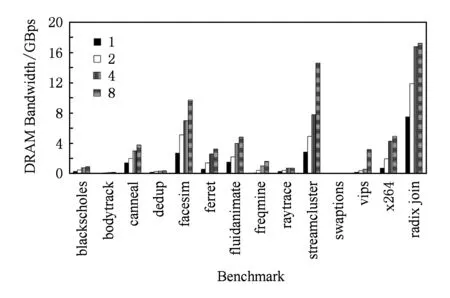
Fig. 1 Memory bandwidth of PARSEC benchmarks and Radix hash join图1 PARSEC benchmarks和Radix hash join的内存带宽分析
本文的创新点和贡献可以概括如下:
1) 以数据移动为驱动的加速任务划分方法.我们提出了一种以数据移动为驱动的方法来划分CPU和DRAM之间的加速任务,使得我们能够在满足3D堆叠DRAM面积、功耗、发热的严格限制条件下,充分挖掘其加速性能.
2) 最先进的hash joins的详细分析.我们对最先进的hash joins算法进行了详细的性能和能耗分析.性能分析结果显示,最先进的hash joins(PRO)本质上是内存受限的.我们的能耗分析结果显示,在partition阶段,总能量的50%以上被数据移动和流水线阻塞所消耗,这可以通过在内存端进行加速得到显著缓解.在build和probe阶段,只有大约15%的能量被数据移动和流水线阻塞所消耗,这仍然可以利用现有的CPU端加速单元(如SIMD单元)进行加速.
3) hash分区加速器的设计.我们设计了一个hash分区加速器(HPA),并将其集成到3D堆叠DRAM的逻辑层中.HPA包含3个主要的部件:hash unit, histogram unit和shuffle unit.此外,我们探索了设计空间,使得我们能够在多种3D堆叠DRAM配置中找到HPA的最佳设计方案.实验结果表明,与现有系统相比,HPA提高了3个数量级的能效.
4) 针对hash joins的混合加速系统.我们建立了一个混合加速系统,该系统包含内存端定制的加速器和处理器端SIMD加速器,这个系统能提高hash joins的整体能效.实验结果表明,平均而言,该系统在英特尔Haswell和Xeon Phi处理器上分别提高了48倍和20倍的能效.
1 背景介绍
1.1 hash joins
join操作是将2个或多个关系表中的元组组合起来的基本数据库操作,hash joins被认为是内存数据库管理系统中最流行的join算法之一.此外,hash joins也被广泛应用在Spark等大数据平台中.现有的hash joins算法大致可以分为2类,即不考虑硬件结构的hash joins和考虑硬件结构的hash joins[11].
1) 不考虑硬件结构的join.该类join算法不关心运行算法的底层硬件结构.简单hash joins算法(SHJ)就是一种典型的不考虑硬件结构join算法,它包括2个阶段:build和probe.在build阶段,扫描较小的关系表R,建立一个hash表;然后在probe阶段,遍历S关系表中的每个元组,在hash表中找到与之匹配的R关系表中的元组.文献[10]提出了SHJ的并行版本:no partition algorithm (NPO),用以挖掘多核架构的并行性.NPO的关键是把输入关系表R和S分成相等大小的部分,每个部分被分配到一个工作线程进行处理.然而,由于NPO的hash过程中存在大量的随机内存访问,可能导致大量的cache miss,使得能效下降.这就是不考虑硬件结构的join算法的缺点.
2) 考虑硬件结构的join.为了更好地利用高速缓存的层次结构,考虑硬件结构的join算法被大量研究.文献[16]提出了一种新的可以充分利用高速缓存的磁盘连接算法DBCC-join.它将执行过程分成了2个阶段:JPIPT构建阶段和结果输出阶段,并在JPIPT构建阶段构建索引时充分考虑了高速缓存的特性.此外,为了充分利用高速缓存和TLB的局部性,radix partition被广泛采用[17].PRO[11,15]是目前最先进的一种hash joins算法.PRO算法分为3个阶段:partition,build和probe.
① partition.图2给出了PRO的partition阶段.该阶段可以进一步分为4个阶段:local histogram, prefix sum, output addressing, data shuffling.其中,local histogram和data shuffling阶段占总执行时间的99%以上.在local histogram阶段,扫描分块的输入关系表(R或S)rel,建立一个histogram数组my_hist;在data shuffling阶段,rel中的元组根据存储在dst数组中的位置被复制到目标分组tmp,完成对关系表rel的划分.

Fig. 2 The partition phase of PRO
图2 PRO的partition阶段
② build.图3给出了PRO的build阶段.在这一阶段中扫描较小的关系表R,建立next和bucket数组.next数组用于追踪被hash到同一个簇中的上一个R元组;而bucket数组用于追踪被hash到当前簇的最后一个R元组.

Fig. 3 The build phase of PRO
图3 PRO的build阶段
③ probe.图4给出了PRO的probe阶段.关系表S中的每一个元组hash成一个bucket数组的索引.然后检索bucket和next,尝试找到与该S元组匹配的R元组.

Fig. 4 The probe phase of PRO
图4 PRO的probe阶段
1.2 内存端加速
作为减少计算单元与内存之间通信开销的一种有前景的技术,内存中处理(PIM)在过去几十年受到了广泛关注.PIM的基本思想是将简单的处理逻辑集成到传统的DRAM或嵌入式DRAM(eDRAM)阵列中[18].比如,可以将SIMD加速单元集成到DRAM die中[19-20];还可以将可重构计算逻辑集成到DRAM die中,构建ActivePage[21].然而,PIM技术的实现面临一个主要障碍:内存加工工艺与逻辑单元加工工艺有很大的不同.用同样的工艺制造出单个芯片不能充分发挥出PIM的优势.
垂直3D die堆叠技术允许将多个存储器die直接叠加在处理器die上,从而提高内存带宽[22-25].这些 die与短、快速、密集的TSV集成在一起,提供了非常高的内部带宽.虽然发热问题是异构die堆叠的一个主要问题,但是仍然出现了一些3D堆叠内存产品,比如三星、Tezzaron、Micron生产的3D堆叠内存.以Micro的Hybrid Memory Cube(HMC)为例,它在逻辑层之上堆叠多个DRAM die,逻辑层中包含能够访问垂直bank的vault controller,以及与其他处理单元和stack通信的link controller.通过在HMC的逻辑层直接集成加速器来获得极高的内部带宽,可以避免在计算单元和内存之间进行来回的数据搬运.
虽然有一些关于集成加速单元的文献,如高能效处理器核[26]、可编程GPU[5]、SIMD单元[7]和定制的加速器[6,27],但当给定一个应用程序时,CPU和DRAM之间的执行任务的划分仍旧是一个值得研究的问题,因为CPU在这些系统中仍然是不可或缺的.
2 hash joins分析
这一部分,我们在商用多核处理器上对hash joins操作的访存和能耗进行了详尽的分析.
2.1 分析方法
我们对最先进的hash joins算法PRO进行了详细的性能分析和能耗分析,该算法针对现代多核系统进行了特殊的优化.我们建立了如表1所示的多核评测系统.为了收集如访存带宽、cache miss和功耗等执行细节,我们使用了Intel的Performance Counter Monitor(PCM)2.8提供的编程接口.在该评测平台上,我们可以收集L1L2缓存未命中率、内存控制器的读写字节数等关键信息.此外,通过查看Intel的RAPL(Runtime Average Power Limit)[28]提供的计数器,我们也可以获得处理器和DRAM的能耗信息.

Table 1 The Hardware System Used for Evaluation表1 用作评估的硬件系统
2.2 访存分析
虽然hash joins算法的性能瓶颈已经得到了很好的研究,但是在分析hash joins访存行为细节方面仍然缺乏研究工作.
如图1所示,虽然PRO整体的内存带宽要求高于传统的多线程应用程序(比如PARSEC benchmark),但我们将进一步研究PRO是否受限于可用的内存带宽.如表2所示,根据内存设备的物理特性计算,系统的理论最大带宽为21.2 GBps,但是在实际应用中理论带宽是难以达到的.对于实际应用来说,一种充分挖掘内存带宽的方法是采用流式(stream)访存.在高性能计算领域中,STREAM benchmark[29]被广泛用于测量系统的可持续内存带宽.使用STREAM benchmark对我们的评测平台进行测试,发现平台的可持续内存带宽约为18.49 GBps.在运行8线程的PRO中,我们测得实际内存带宽为17.24 GBps,约为可持续带宽的93.2%.换句话说,PRO几乎使评测平台的可持续内存带宽达到饱和.

Table 2 Bandwidth Measurement表2 带宽评估
PRO包含partition,build和probe这3个主要执行阶段,我们进一步测量每个阶段的访存带宽.如图5(a)所示,在8个线程下,partition阶段的内存带宽为17.2 GBps,其余2个阶段的内存带宽约为15.6 GBps.这一观察结果表明,在PRO的整个执行过程中,内存带宽利用率始终很高.但是,如表3所示,partition阶段的最后一级cache未命中率远远高于其他2个阶段.从内存带宽利用率和cache miss两个不同角度观察,我们发现导致PRO不同阶段都有如此高的带宽利用率的根本原因是不同的.由于partition阶段中data shuffling过程(参见图2)存在大量随机访存行为,导致大量cache miss,从而使得带宽利用率看起来很高,但实际的数据移动效率却较低;而build和probe阶段是流式访存,所以带宽利用率和数据移动效率都较高.
我们进一步研究partition阶段,其中local histogram(LH)和data shuffling(DS)的执行时间占总执行时间的99%以上.如图5(b)显示,当使用4个线程运行时,LH阶段受到可用内存带宽的限制,原因是关系表的顺序访存容易使内存带宽达到饱和.对于DS的阶段,在运行8个线程时内存带宽达到峰值.我们可以看到,DS阶段内存带宽低于LH阶段.究其原因,是由于键(key)在各自位置上的分布性,在DS阶段存在很多不规则的访存.
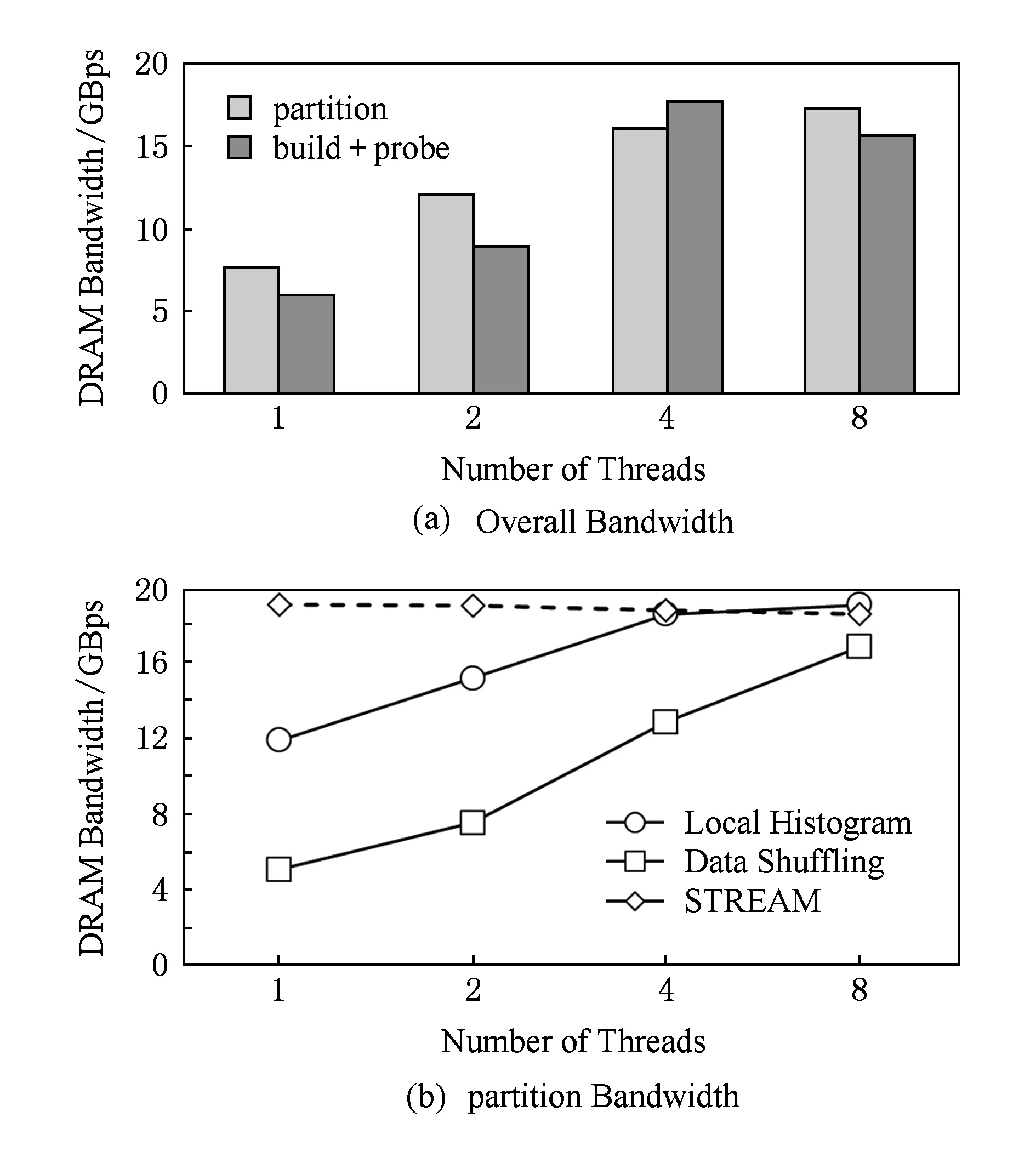
Fig. 5 Detailed bandwidth analysis of PRO图5 PRO的详细带宽分析
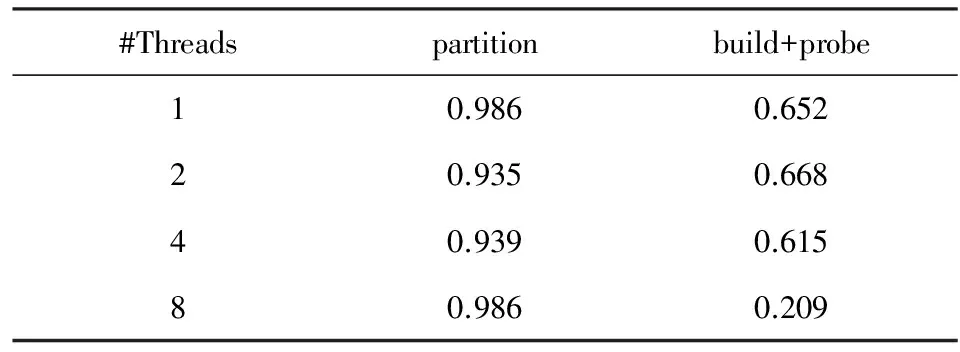
Table 3 L3 Cache Miss Ratio of PRO表3 PRO的cache miss率
基于以上分析,我们认为由于密集的访存行为(规则的和不规则的),最先进的hash joins算法在商用多核结构上被可用带宽所限制.这种密集的访存行为不仅会导致性能下降,而且具有较高的能耗.在hash joins算法中,计算部分相对简单,比如位操作、hash(如图2中的行③)、数组索引(如图2中的行)和整数增量(如图2中的行).因此,预计移动数据产生的能耗比计算本身更为严重.为了验证这一假设,我们进行进一步的实验来确定hash joins算法的能耗瓶颈.
2.3 能耗分析
我们从2个级别来进行能耗分析:粗粒度级别和细粒度级别.在粗粒度级别,我们分析了partition,build+probe阶段的能耗.在细粒度级别,我们将能消耗分为3类:数据移动、流水线阻塞和计算能耗,我们采用了文献[30-31]中提出的评测方法.
1) 粗粒度级别分析结果.图6给出了在不同输入大小(32~256 M)和线程数(1~4)情况下,partition和build+probe阶段的能耗比较.平均来看,partition阶段能耗约占总能耗的86.4%.因此,对于CPU和DRAM来说,有必要降低partition阶段的能耗.
2) 细粒度级别分析结果.图7展示了整个hash joins过程的细粒度能耗分解.我们测量由数据移动和流水线阻塞带来的能耗,流水线阻塞主要是由数据移动操作和功能单元的争抢引起的,剩余的能耗是由计算和其他原因导致的.
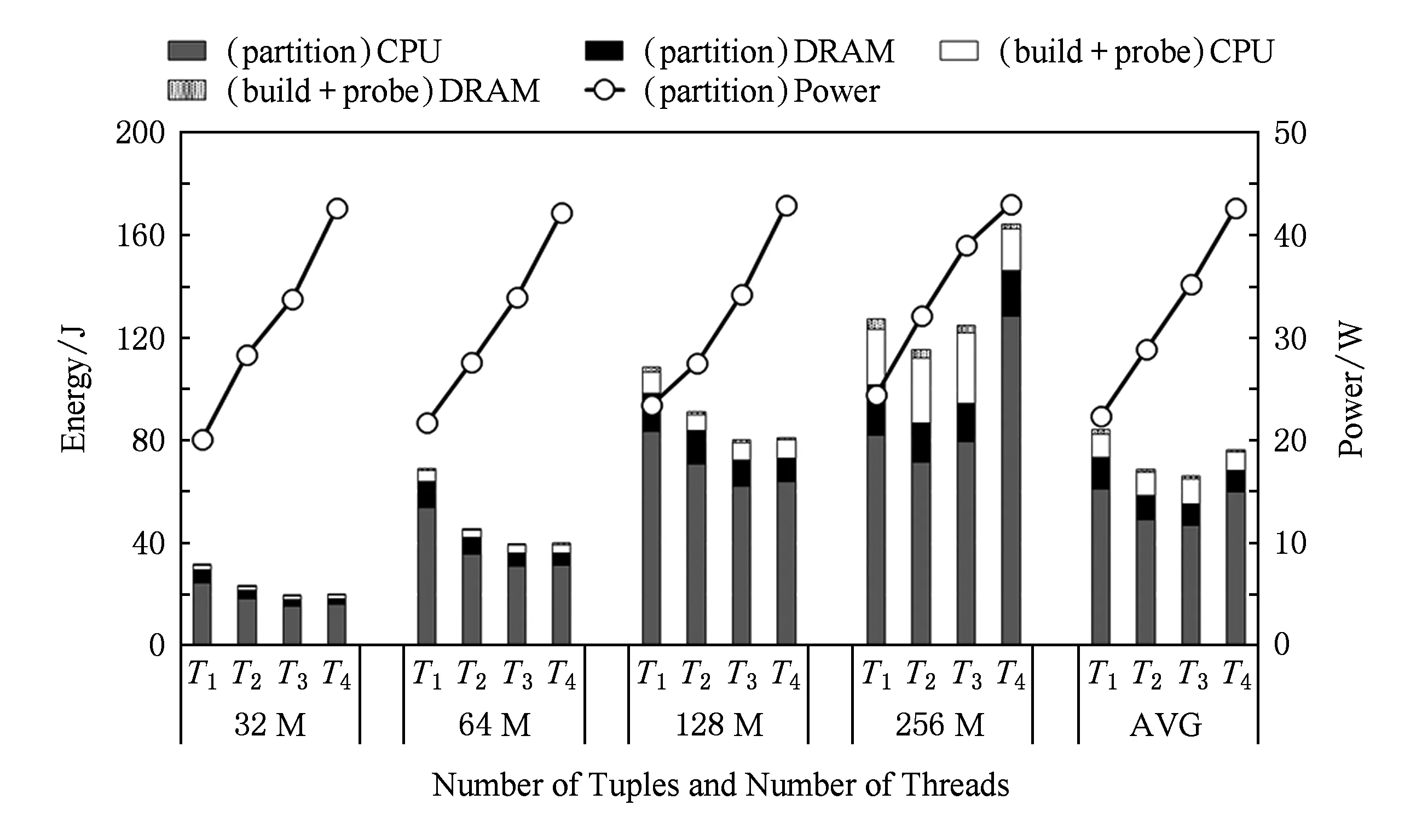
Fig. 6 Energy of the partition and build+probe图6 partition阶段和build+probe阶段的能耗
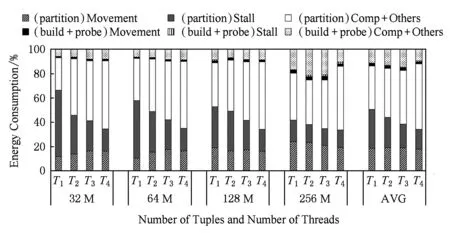
Fig. 7 Energy breakdown of the hash joins operation图7 hash joins操作的能耗分解
对于build+probe阶段,由数据移动引起的能耗相对较小,仅占总能耗的1.8%.相比之下,计算引起的能耗约占总能耗的11%,是数据移动能耗的6.4倍.与build+probe阶段相比,partition阶段能耗情况则完全不同.
在运行1个工作线程时,在数据移动、流水线阻塞和计算+其他方面消耗的能量分别为18.6%,31.9%和35.8%.可以看出,数据移动和流水线阻塞对整体能耗有很大的贡献.
虽然hash joins的所有阶段几乎使内存带宽饱和(参考3.2节),但partition和build+probe阶段的数据移动能耗有着显著的不同.在partition阶段,数据shuffle过程存在大量高代价的不规则的访存行为,导致数据移动开销大.而在build+probe阶段,只有常规的流式访存,使得数据移动成本可以忽略不计.因此,设计DRAM中加速器的首要考虑的因素是数据移动的成本,而不是内存带宽.
现代处理器为了降低内存访问延迟,设计了多个层次的存储结构,因此数据移动操作可以进一步分为4类:L1到寄存器、L2到寄存器、L3到寄存器和内存到寄存器.这4类操作的能耗分布如图8所示.从DRAM到寄存器数据移动的能耗约占总能耗的60%,而处理器内的移动数据(包括L1到寄存器、L2到寄存器和L3到寄存器)的能耗约占总能耗的40%.因此,有必要同时从CPU和DRAM两端降低数据移动的能耗.
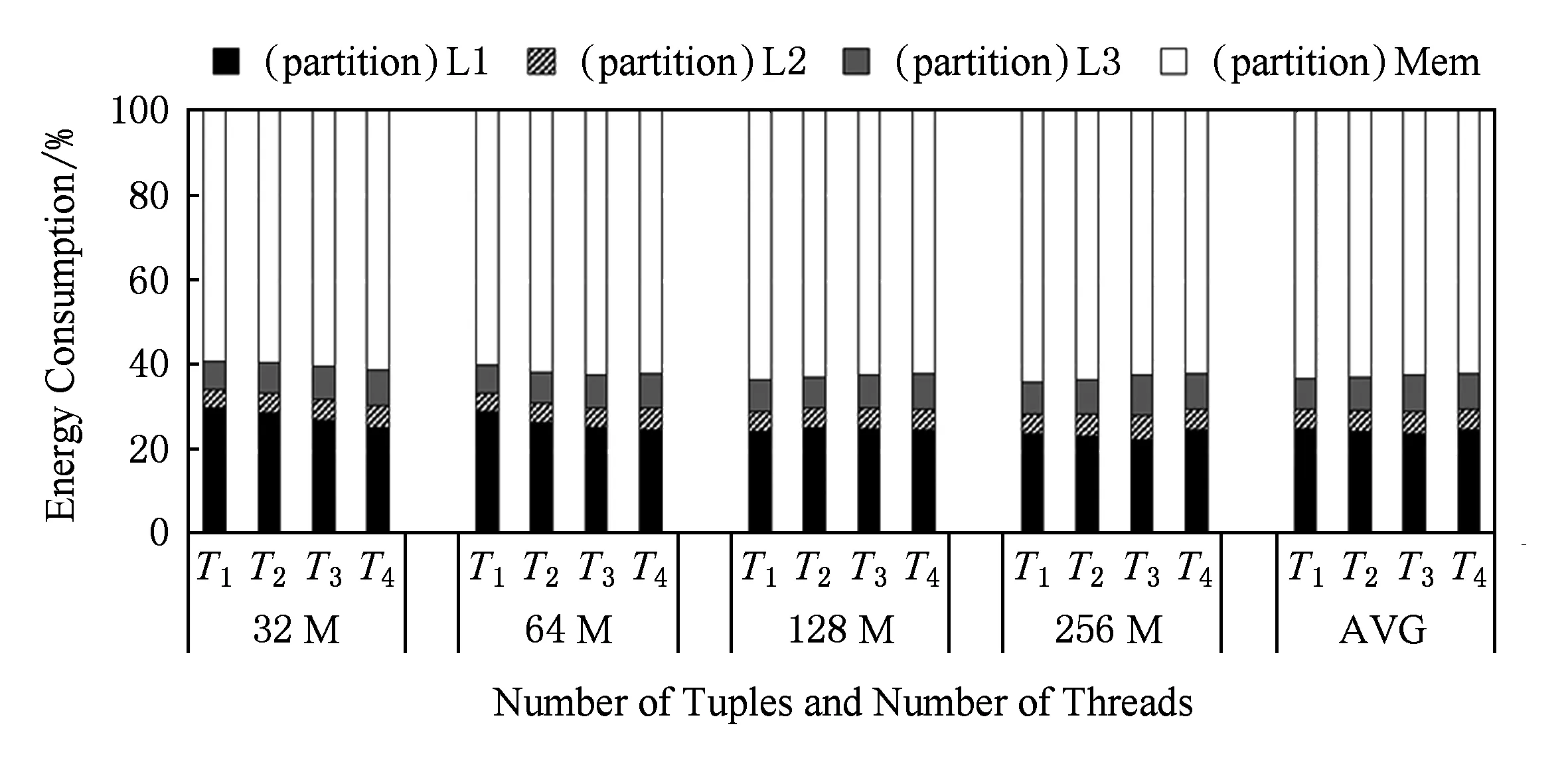
Fig. 8 Breakdown of energy caused by data movement in the partition phase图8 partition阶段数据移动带来的能耗分解
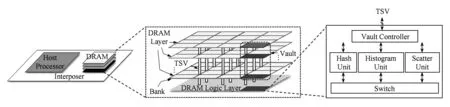
Fig. 9 The overview of proposed hybrid accelerated system图9 混合加速系统的总体架构
综上,虽然最好的hash joins算法是内存受限的,但由于partition阶段有着不规则的内存访问,大部分的能耗是由流水线阻塞和数据移动产生的;而对于访存有规律的build+probe阶段,大部分能量消耗在计算上.为了在面积、功耗、散热受限的DRAM逻辑层上提高整体的能效,我们建议只在DRAM中加速partition阶段,而把build+probe阶段的加速留给CPU.
2.4 在DRAM中加速的收益
通过将加速器集成到DRAM中,可以从各个方面减少partition阶段的能耗,从而减少总体能耗.
1) 数据移动的能耗.通过将加速器集成到DRAM中,可以避免CPU和DRAM之间高代价的往返数据传输,从而直接降低数据移动能耗.
2) 流水线阻塞的能耗.由于相当缓慢的内存访问导致了大量的流水线阻塞,因此数据访问的改进(通过将计算移动到更接近数据位置)也有助于减少流水线阻塞带来的能耗.
3) 计算的能耗.使用自定义hash分区加速器(HPA)可以显著降低计算能耗.
3 系统概览
图9展示了hash joins混合加速系统的总体结构,包括多众核的主机处理器和一个或多个3D DRAM stack.在每个DRAM stack的逻辑层中,我们将hash分区加速器(HPA)集成到每个vault controllor上,使HPA可以充分利用3D DRAM中极高的内部带宽.
1) 主机处理器.主机处理器是一个传统的多众核处理器,例如Intel的Haswell或Xeon Phi处理器.它通过高速连接(用于传统的HMC系统中)或者interposer(用于Intel的Knights Landing中)与3D DRAM stack进行通信.主机处理器可以通过引入SIMD单元、定制的加速器或GPU等加速器增强自身性能,从而提高大多数应用的性能.在我们的混合系统中,主机处理器主要侧重于利用SIMD单元来加速build和probe阶段.
2) 集成加速器的3D堆叠DRAM.针对每个3D DRAM stack,我们集成多个HPA来充分利用其高内存带宽,从而降低整体的能耗.由于每个3D DRAM stack包含多个vault,并且每个vault都由逻辑层的vault controller访问,所以我们将一个HPA集成到vault controller上.
为加速partition阶段而设计的hash分区加速器(HPA)包含3个主要部件:hash unit,histogram unit和shuffle unit.这些单元通过vault controller访问DRAM层,并且与开关电路相连.
4 hash分区加速器
在这一部分,我们首先介绍HPA的设计架构.然后,探索可能的设计空间来找到最优的设计方案.
4.1 加速器设计
每个HPA的详细架构如图10所示.HPA通过vault controller访问DRAM.
1) hash unit.如图10(a)所示,我们以一个处理并行度为4的hash unit为例,介绍hash unit的架构.它以流式访问的方式从DRAM中读取关系表中的多个元组,然后并行地处理它们的keys,以位移或者掩码的方式来产生hash索引.由于hash unit会被histogram unit和shuffle unit复用,所以加入了多路选择器(MUX)用于决定hash索引的输出目标.
2) histogram unit.图2中的原始histogram算法应该串行执行.为了增加histogram操作的并行度,我们采用本地存储器(local memory, LM)来保存my_hist的多个副本,每个副本都由单独的处理单元处理.如图10(b)所示,并行的histogram操作被分解为2个阶段:并行增量阶段(INC)和串行归约阶段(RED).在INC阶段,hash unit产生的hash索引idx用于更新对应的LM当前的histogram值.在处理完从DRAM中读取的所有键后,最后的RED阶段进行所有LM的整合,以获得一个完整且保持数据一致性的my_hist.

Fig. 10 The architecture of HPA图10 HPA的架构
histogram unit设计中需要关心的是LM的功耗和面积.LM的数量越多,处理my_hist的并行度越高,但是相应地会增加面积和功耗.同时为了减少TLB miss,LM的大小还受到TLB项数量的限制[11].具体来说,每个my_hist副本大小最好与TLB项数量相等.在现代处理器中针对L1设计的数据TLB通常是64或128项.因此,给定一个很高的并行度,比如512,LM的总大小为256 KB(512×128×4).当然,我们应该谨慎选择并行度,在性能、功耗和面积之间做设计权衡.
3) shuffle unit.与 histogram unit的并行设计思路类似,shuffle unit的设计的挑战是如何将多个元组同时写入到各自在tmp数组中的目标地址(tmp[dst[idx]]),然后更新dst数组中的目标地址(如图2所示).如果多个处理路径中具有相同目的地址的元组,还需要处理目标地址冲突问题.
我们提出的并行shuffle unit由4个阶段组成:第1阶段(DIST)是根据hash索引(idx)从dst数组中并行地读取多个目标地址(图2的第行).第2阶段(DECONF)用于检测多个处理路径之间有冲突的目的地址.DECONF阶段产生基于原始目标地址的偏移,从而确定在tmp数组中正确的目的地址.同时DECONF阶段也产生相同目的地址的计数值来更新idx数组.第3阶段(SCATTER)将元组移动到正确的位置,正确的位置根据DECONF阶段产生的偏移和DIST阶段产生的存储在tmp数组的原始目的地址联合计算得出.最后一个阶段(UPDATE)根据DECONF阶段产生的计数值更新目的地址.
DECONF本质上是一个在原始目的地址上执行XNOR操作的XNOR网络.图11给出了XNOR网络的结构示例,在此示例中,4个目的地址的数值d0,d1,d2和d3从dst数组中并行的读出.为了计算d0的总数量count(d0),首先d0分别与d1,d2和d3进行同或操作,然后所有同或的数值进行求和.同样地,通过对xnor(d1,d0), xnor(d1,d2)和xnor(d1,d3)求和计算得出count(d1).计算目标地址偏移也可以通过复用XNOR网络来实现.例如,offset(d1)是xnor(d1,d2)和xnor(d1,d3)的和.
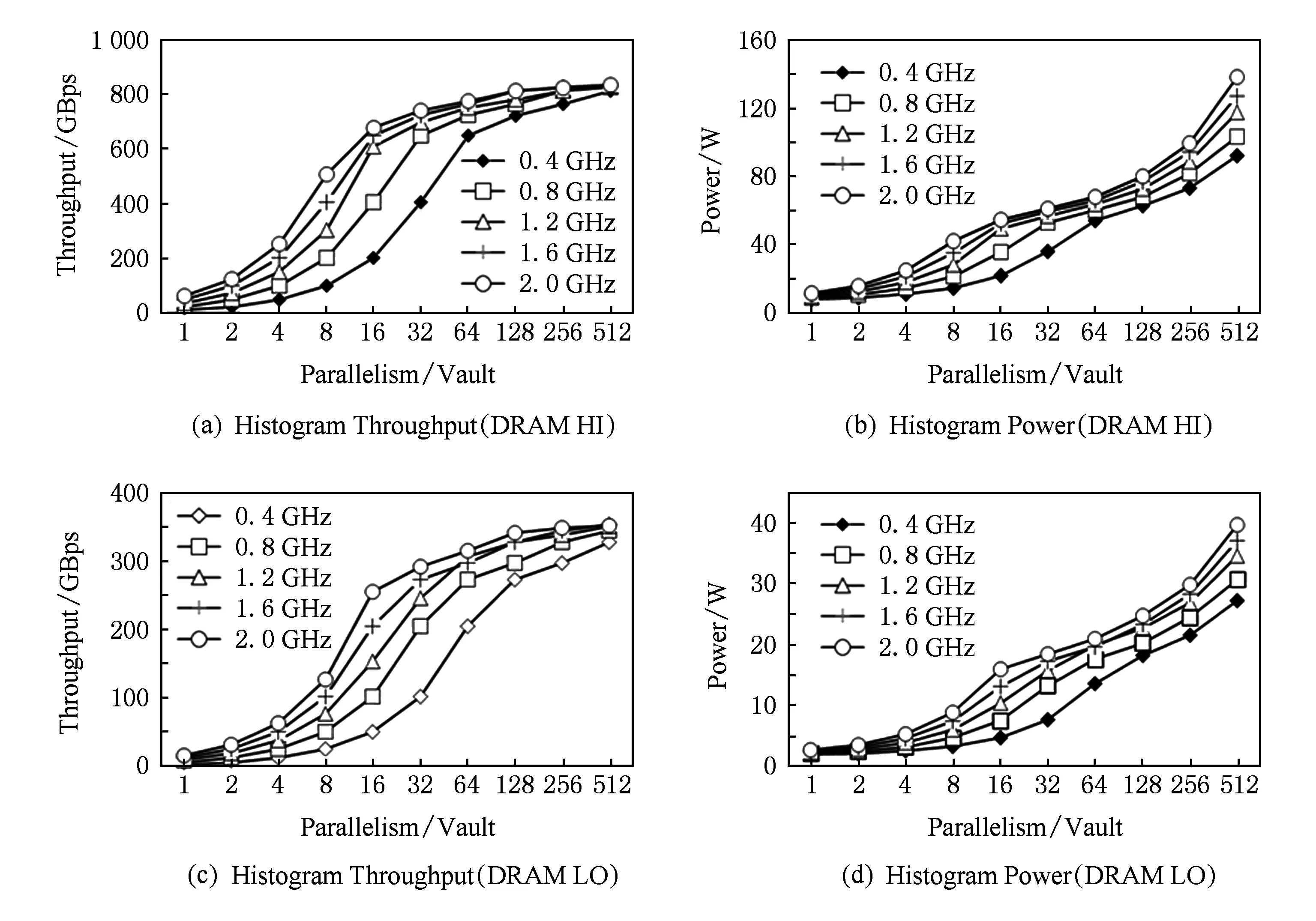
Fig. 12 The throughput and power of the histogram operation图12 histogram操作的吞吐率和功耗
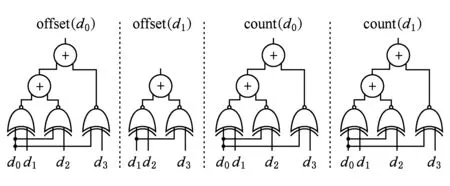
Fig. 11 XNOR network图11 XNOR网络图示
4.2 设计空间探索
在HPA的设计过程中,在并行度和频率上存在多种选择,同时3D堆叠DRAM也可以选择不同的配置.表4列出了3种可能的3D堆叠DRAM配置:HI,MD和LO,它们的内部带宽在860 GBps~360 GBps之间.我们探索了由每个vault的并行度(1~512)、操作频率(0.4~2.0 GHz)和DRAM配置组成的设计空间,尝试在在并行度和功耗之间进行设计权衡.更多的细节和评估方法论可以在第6节中找到.
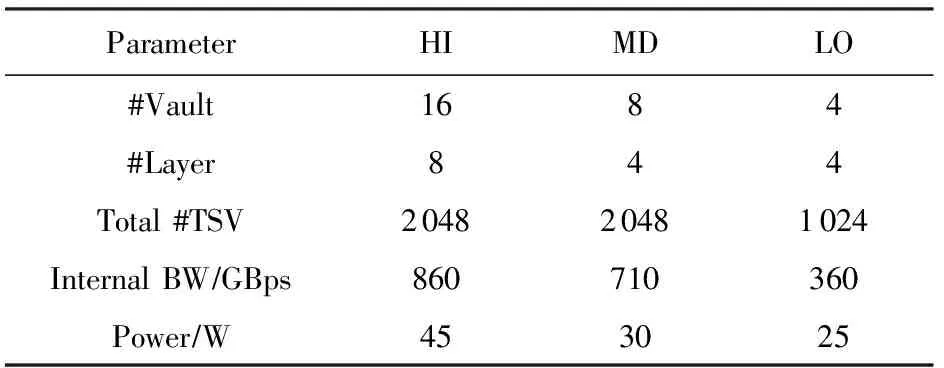
Table 4 3D-Stacked DRAM Configurations表4 3D堆叠内存配置
4.2.1 histogram操作
图12显示了使用HI和LO DRAM配置,在不同的频率和并行度下histogram操作的吞吐率和功耗.第1个观察结果是吞吐率随着并行度和频率的增加而增加,这充分说明了我们设计的可伸缩性.针对HI配置,在2 GHz下当并行度从8增加到16,相应的吞吐率也增加了约2倍.然而,随着频率和并行度的不断增加,所需的内存带宽也会增加,从而使吞吐率受到可用内存带宽的限制.在另一个例子中,给定0.4 GHz的频率,虽然并行度从32增加到64时,吞吐率增加了约2倍,但是当并行度从64增加到128时,吞吐率只有1.6倍的增加.另外,当并行度从256增加到512时,吞吐率的增益仅为1.06.针对不同的频率,在不同并行度下,HI和LO配置的吞吐率最终会分别收敛到840 GBps和450 GBps.
至于功耗,除了直观地观察到功耗随并行度和频率增加外,我们还观察到不同频率之间的功耗差距会随着并行度的变化而变化.对HI配置,当并行度是16时,最大功耗(在2 GHz时)比最小功耗(在0.4 GHz时)高2.54倍,而当并行度是64时,功耗差距只有1.26倍.这是由于DRAM在相对较小的并行度的情况下,不同频率之间的功耗有一个较大的差距.
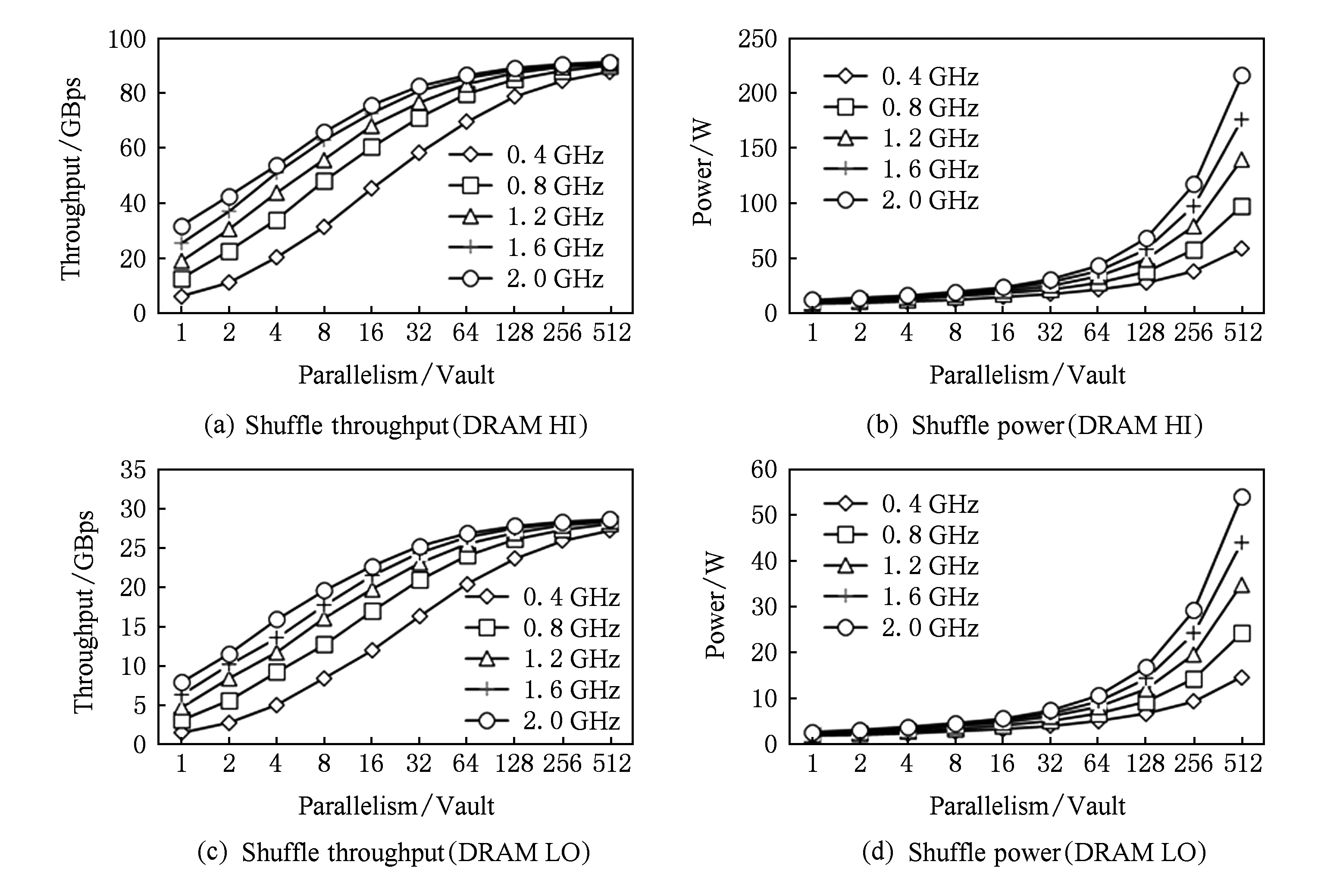
Fig. 15 The throughput and power of the shuffle operation图15 shuffle操作的吞吐率和功耗
为了详细说明功耗,图13显示了HI配置下的histogram操作的功耗分解.我们可以看到,随着并行度的增加,DRAM的功耗所占比例(例如DRAM_RD)也随之增加.然而,当并行度大于32时,DRAM功耗所占的比例减小,因为内存带宽几乎饱和,同时HASH和INC功耗显著增加.在2 GHz下,并行度是512时,HASH和INC功耗甚至高于DRAM功耗.
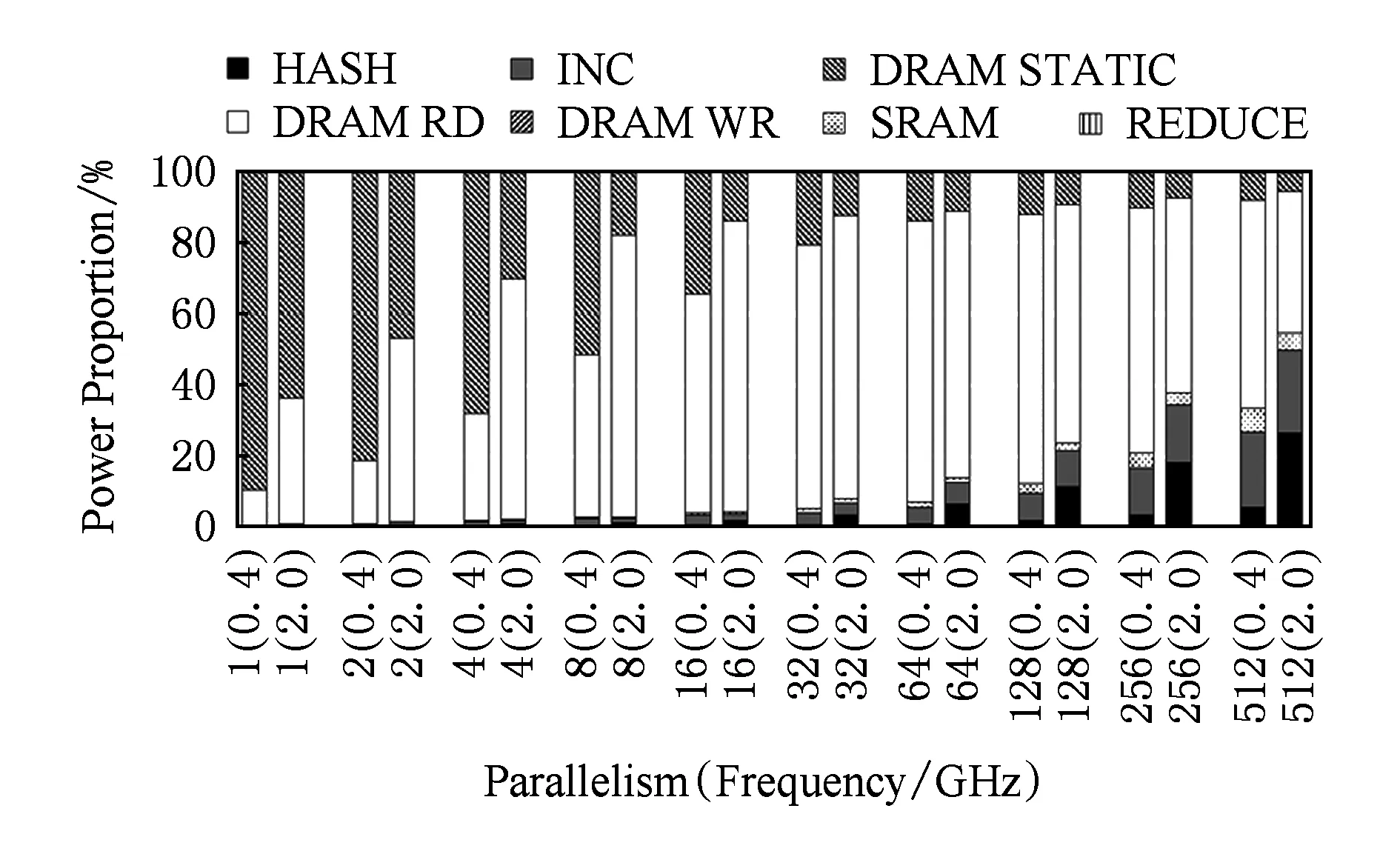
Fig. 13 The power breakdown of the histogram operation图13 histogram操作功耗分解
我们还在图14中,以能量-延迟积(EDP)为标准,展示了在不同设计方案下的每个vault的能效.在所有的DRAM配置下,随着并行度的增加,EDP并没有显示出单调下降的趋势.特别值得注意的是,在并行度在32左右时,所有DRAM配置的EDP达到了最优值.举例来说,使用HI配置,在1.2 GHz操作频率下,达到最优的EDP需要64的并行度.一般来说,相比HI配置,MD和LO DRAM配置具有更好的能效(每个vault),随着并行度的增大变得尤为明显.图14还显示了不同设计选择下的面积.可以看出,随着并行度的增加面积会显著增加.在每个vault中每一个HPA的最大面积大约为1.4 mm2,这是因为HPA需要更多的处理单元.
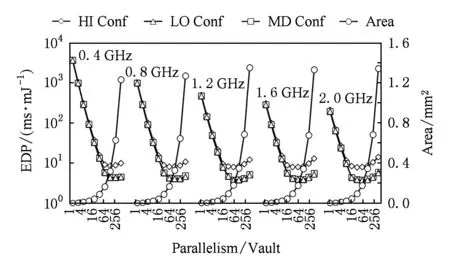
Fig. 14 Energy-delay product (EDP) of different design options for the histogram operation图14 不同设计下histogram操作的能量-延迟积
4.2.2 shuffle操作
图15展示了使用HI和LO DRAM配置,在不同的频率和并行度下shuffle操作的吞吐率和功耗.一般来说,吞吐率会随着并行度和频率的提高而增加,在HI和LO的配置下,它最终分别收敛到91 GBps和29 GBps.最大吞吐率主要受SCATTER阶段的限制,在该阶段中是以相对随机的方式进行内存访问的.随着并行度和频率的增加,功耗也会随之增长.在2 GHz下,在HI和LO配置中最大功耗分别达到了216 W和54 W.
图16展示了shuffle操作下的功耗分解.当并行度很小时,比如1~16,DRAM的静态功耗占主要部分.随着并行度的增加,HASH和SCATTER的功耗显著增加,最终超过了DRAM的静态功耗.
Fig. 16 The power breakdown of the shuffle operation图16 shuffle操作的功耗分解
图17展示了每个vault的shuffle操作能效(EDP)和面积.达到最优EDP的并行度是在32~128之间.例如,在2 GHz下,并行度为32的EDP比并行度为512的EDP好1.77倍.在所有的这些配置中,获得最优EDP的配置为并行度=64、频率=1.2 GHz和DRAM配置=LO.最优配置所需要的面积为0.18 mm2(每vault).
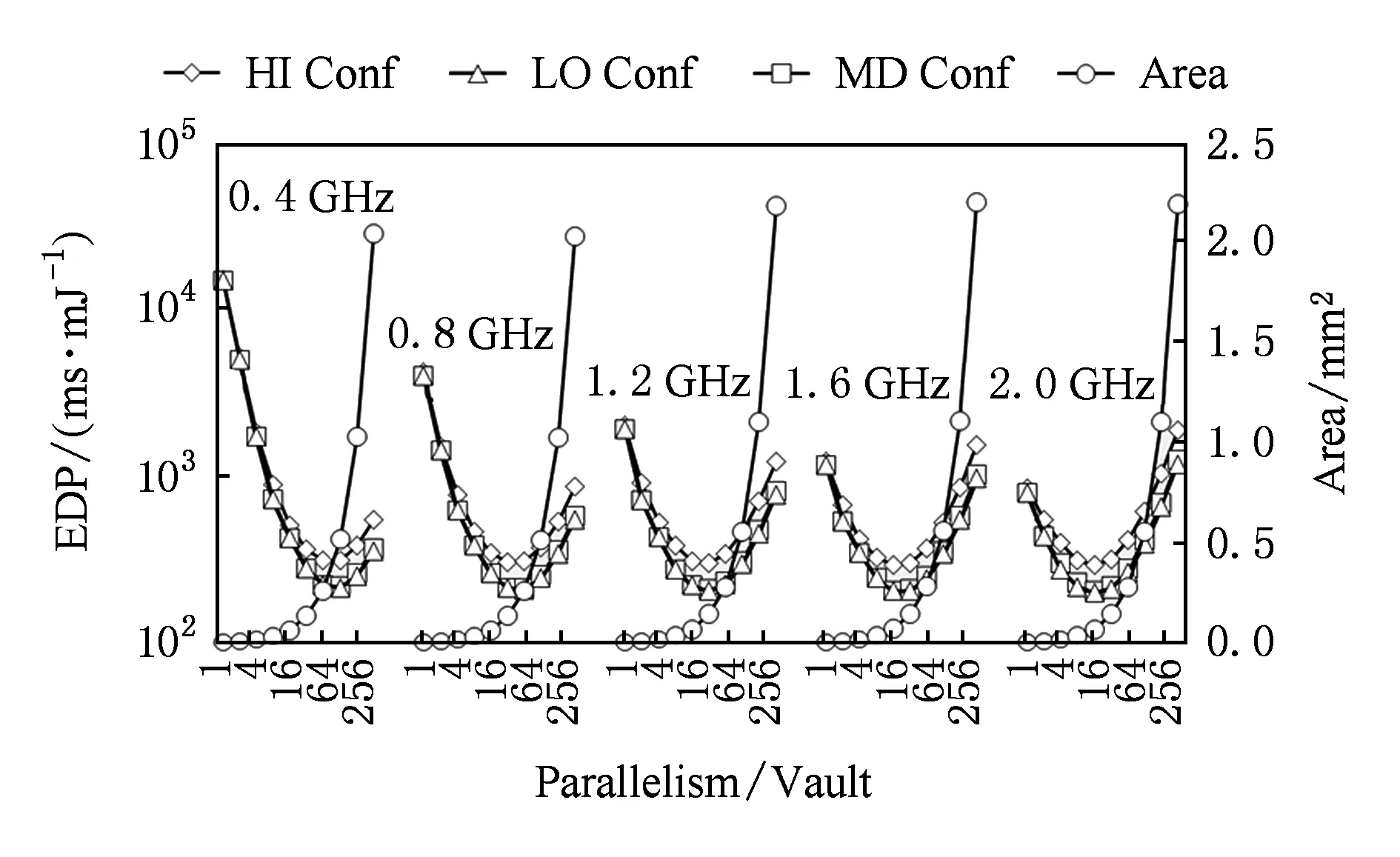
Fig. 17 Energy-delay product (EDP) of different design options for the shuffle operation图17 不同设计下shuffle操作的能量-延迟积
4.2.3 设计决策
要做出HPA的最优设计决策,我们必须综合考虑histogram和shuffle两个操作的性能、功耗和面积.我们通过对比不同配置下这2个操作的总EDP决定最优的HPA配置.我们得出结论是:当输入的大小是128 M时,HPA的最优配置是并行度=16、频率=2.0 GHz、DRAM配置=HI.相应的面积只有1.78mm2,加速器的功耗(不含DRAM功耗)只有7.52 W.
5 软件设计
软件设计包括用于调用HPA(hash分区加速器)的编程接口和用于加速build和probe阶段的SIMD指令.
5.1 HPA编程接口
我们采用的编程接口是在文献[6]中提出的编程库上进行搭建的.所使用的库函数包括内存管理库函数malloc和free,以及加速器控制库acc_plan(用于配置加速器)和acc_execute(用于调用已配置的加速器).我们对acc_plan函数进行扩展,使它支持2个新的操作:HIST和SHUF,分别用来控制HPA执行histogram和shuffle操作.在这些库函数的帮助下,程序员可以很容易地在程序中使用HPA.此外,我们使用的编程接口本质上是一个顺序编程模型,所以可以减轻异构系统的编程负担.
然而,加速代码(如histogram和shuffle操作)是一个并行执行范式,其中每个工作线程都需要处理自己的数据分块.为了缩小顺序编程模和并行编程模型之间的差距,我们在每个工作线程调用HPA之前添加barrier操作,然后只有1个线程通过acc_plan和acc_execute调用HPA,同时所有其他线程都在等待HPA执行(histogram或shuffle操作)完成.在HPA完成执行之后,每个工作线程恢复各自的执行流,进行后续操作.
5.2 针对build+probe阶段的SIMD加速
近年来,为提高hash joins的执行效率,针对SIMD和向量化有很好的研究.我们采用了在文献[13,15]中提出的SIMD算法,在多核(例如Intel Haswell)和众核(如Intel Xeon Phi)处理器上加速build和probe阶段.
图18展示了在支持512-bit SIMD的Xeon Phi处理器上用SIMD执行build阶段的基本思想.直观来看,多个hash操作可以并行执行(参考图3中的行③).在图18行④中,gather操作从元组中选择键.在行⑤中,基于SIMD的hash操作(包括SIMD按位与和移位)并行地进行多个键的hash处理.在行⑥中,将hash处理的结果写回extVector.extVector
① 单位为元组的个数,数据的总大小是0.5 GB~4 GB (256 M×8×2 B=4 GB)
中包含16个idx(参考图3),用于顺序更新bucket数组.probe阶段的SIMD执行类似于build阶段.

Fig. 18 The basic idea of 512-bit SIMD execution of the build phase
图18 512-bit SIMD执行build阶段的基本思想
6 实 验
在本节中,我们展示了混合加速系统的能效,并将其与支持SIMD的商用多众核处理器进行比较.
6.1 评测方法
1) 评测基础设施.我们采用了文献[6]中提出的混合评价方法论来评估我们的系统.这种评估方法的主要优点是真正的执行行为可以被如实地模拟.
2) 主机处理器.表5列出了用于评估的主处理器,其中Intel Haswell和Intel Xeon Phi处理器分别是商用多核和众核处理器.我们在主机处理器上运行PRO算法,并测量不包括加速部分(partition阶段的histogram和shuffle操作)程序的性能和功耗.我们还测量了使用主处理器把加速部分任务分派到HPA加速器的开销(包括加速器控制带来的开销和刷新缓存以保证数据一致性带来的开销).
3) 加速器仿真.通过各种仿真工具对hash分区加速器(HPA)的性能、功耗和面积行评估.该加速器的性能是由一个内部的、C-level、周期精准的模拟器估计的.DRAM的访存延迟是由一个周期精准的3D堆叠DRAM模拟器获得的[8].我们采用32 nm的库和编译器来评估HPA的功耗和面积.
4) Baseline.为了展现混合加速系统的优势,我们对比了Intel Haswell和Xeon Phi处理器和我们的系统.如表5所示,它们的内存带宽的峰值分别为21.2 GBps和320 GBps.我们在这2个平台上全面的测量了hash joins算法的性能和功耗.
5) HPA配置和输入数据集.如第4节所探讨的,HPA的最佳频率和并行度分别为2.0 GHz和16.3D堆叠DRAM是HI配置,它包含16个vault,最大的内部带宽为860 GBps(如表4所示).关于输入数据集,我们将输入关系表的元组数目作为可调整的变量,从32 M~256 M①进行了测试.

Table 5 The Baseline Host Processors表5 基准主处理器
6.2 实验结果
我们用不同大小的输入数据集,在性能、能耗和EDP这3个方面将我们提出的混合系统和Haswell和Xeon Phi处理器进行了比较,结果如图19所示.与Haswell处理器相比,混合系统在性能、功耗和EDP上分别优化了6.70,7.08和47.52倍.与Xeon Phi处理器相比,混合系统在性能、功耗和EDP上分别优化了4.17,4.68和19.81倍.我们观察到,Xeon Phi处理器的收益比Haswell处理器的收益要小.原因是在Xeon Phi上,build和probe阶段执行所占的比例比Haswell更大.
如图20所示,针对hash partition操作,我们比较了HPA与基准平台的性能、能耗和EDP.平均而言,与Intel Haswell处理器相比,HPA的性能、功耗和EDP分别优化了30,90和2 725倍.与Xeon Phi处理器相比,EDP优化甚至超过了6 000倍.性能和能效的显著提高主要来源于定制加速器和由3D堆叠DRAM提供的高内存带宽.
为了更详细地分析实验结果,我们在图21中给出了Intel Haswell处理器的执行过程分解.根据图21(a)中执行时间的分解,HPA只占整个执行时间的19.2%.相比之下,加速前的partition阶段的执行时间大约是整个执行时间的90%,这表明partition阶段已经被加速了大约30倍.此外,当输入数据集很小时(比如32 M),HPA的调用成本是巨大的,占总执行时间的8.6%.当输入数据的大小增加时,调用成本逐渐变得可以忽略,例如,当输入数据大小是256 M时,调用成本只是总执行时间的1%.

Fig. 19 Overall comparison with the Intel Haswell and Xeon Phi processor图19 与Intel Haswell和Xeon Phi处理器总体对比
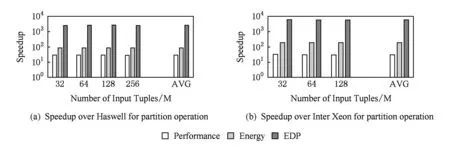
Fig. 20 Comparison with the Intel Haswell and Xeon Phi processor for the hash partition operation图20 与Intel Haswell和Xeon Phi处理器在partition操作上的对比
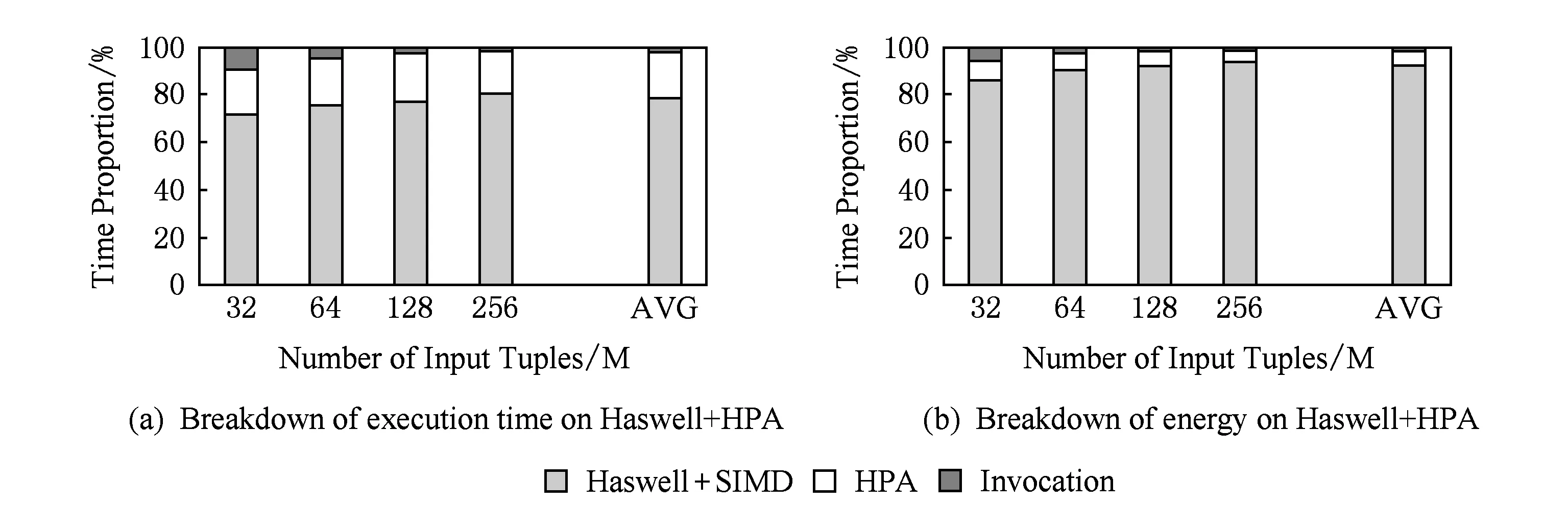
Fig. 21 Breakdown of execution time and energy on the hybrid system and Intel Haswell processor图21 混合系统以及Intel Haswell处理器的执行时间和功耗分解
在图21(b)中,功耗的分解进一步证明了HPA的优势.平均来说,HPA功耗只占总功耗的6.2%.同时,在Haswell上实际计算的功耗远远高于调用HPA的功耗.平均而言,Haswell计算和调用HPA的功耗比率分别为92.7%和1.1%.
6.3 功耗和面积总结
我们在表6中展示了混合系统的功耗和面积,该系统由HPA,DRAM和主机处理器(Haswell)组成.就面积而言,HPA(由hash、histogram和shuffle unit组成)的总面积仅为Micron的Hybrid Memory Cube (HMC)总尺寸的2.6%.因此,HMC的逻辑层很容易容纳HPA.此外,HPA的面积只占由DRAM和CPU组成的整个系统的0.72%.
在功耗方面,HMC只给3D堆叠DRAM增加了7.52 W的功耗,在DRAM中使用HPA的总功耗为28.43W.由于DRAM也被主机处理器(如Haswell)访问,我们还测量了由Haswell处理器访问引起的DRAM功耗,相应的DRAM功耗是9.79 W.由于DRAM不能被HPA和Haswell同时访问,所以DRAM的总功耗不会超过18.64 W.对于主要用来执行build和probe阶段Haswell处理器,测得其总功耗为89.75 W.
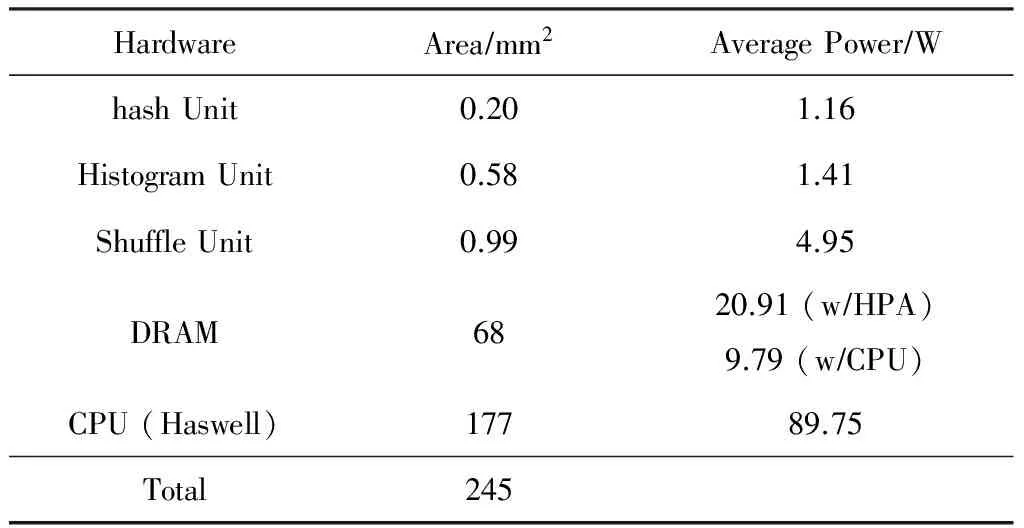
Table 6 Power and Area Consumption of the Entire System表6 整个系统的功耗和面积消耗
7 相关工作
在本节中,我们列出了针对数据库操作、算法、应用而使用新型硬件的相关工作.
1) SIMD扩展.在过去10年中,为了加速数据库的原语,已经广泛部署SIMD扩展.Zhou等人在文献[32]中首先用SIMD指令来加速基本的数据库操作,如索引扫描和嵌套循环联接.Willhalm等人在文献[33]中使用向量处理单元在数据扫描中进行解压缩.Schlegel等人在文献[34]中使用SIMD支持在Xeon Phi处理器上实现了一个可扩展的频繁项集挖掘算法.Polychroniou等人在文献[14]中使用SIMD指令重写了内存数据库操作,其中包含扫描、hash、筛选和排序.
2) FPGAs.已经有很多用FPGA加速数据库查询操作的工作.比如IBM Netezza,它是一个结合了Xeon服务器和FPGAs的商用系统,可以提高数据库查询的性能.Sukhwani等人在文献[35]中利用FPGA对传统DBMS进行数据解压和谓词评价.Chung等人在文献[36]中提出了一种框架,将查询语言LINQ映射到硬件模板,该模板可以由FPGA或ASIC实现.由ARM A9处理器和FPGA组成的SoC系统可以提高30.6倍的能效.
3) GPUs.图处理单元也被广泛用于加速通用数据查询[37]和数据库操作原语,如索引[38]、排序[39]和连接[40-41].
4) 自定义的逻辑单元.在数据库领域自定义加速器也被广泛地使用.Kocberber等人在文献[42]中为hash索引查找建立了on-chip加速器.Wu等人在文献[43]中首先提出了一种用于range partitioning的硬件加速器:HARP.为了充分利用HARP的计算能力,他们还提出了一个硬件-软件流式框架,用于CPU和HARP之间的通信.与他们的工作相比,我们更关注hash分区,并且我们在最先进的hash joins(即PRO)中发现hash分区是内存受限的.因此,将加速过程集成到DRAM中可以使hash分区获得巨大的收益.为了实现这个目标,我们设计了一个hash分区加速器(HPA),它可以适应3D堆叠DRAM架构.Wu等人在文献[44]中进一步提出了Q100数据库处理单元(DPU),以有效地处理数据库原语,如聚合、连接和排序.
随着靠近数据的处理技术出现,也有一些将自定义逻辑集成到DRAM中进行数据库处理的研究.Xi等人在文献[45]中设计了JAFAR加速器,他们将选择操作附加到DRAM中,获得了9倍的加速.Seshadri等人在文献[46]中提出在DRAM中实现位操作(AND和OR),进而加速各种数据库操作(例如索引).
8 总 结
尽管3D-die的堆叠技术使得计算单元可以集成到3D堆叠DRAM中,但由于其严格的面积、功耗、散热的限制,使得我们在架构设计时应该谨慎地考虑如何在3D堆叠DRAM中加入最合适的逻辑单元.在本文中,我们以数据移动为驱动,对CPU和DRAM之间的加速任务进行划分.基于这种方法,我们设计了一种混合加速系统,用于加速数据库和大数据系统中的基本操作hash joins.该系统包含一个内存端定制的hash分区加速器(HPA)和处理器端的SIMD单元.内存端的加速器用于加速数据移动受限的执行阶段,而处理器端SIMD加速单元则用于加速数据移动开销较低成本的执行阶段.实验结果表明,该系统与Intel Haswell和Xeon Phi处理器相比,仅仅用7.52W额外的功耗,将能效分别提升了47.52和19.81倍.同时我们的设计方法可以很容易地被应用到其他应用程序的加速设计中.
[1]Putnam A,Caulfield A M, Chung E S, et al. A reconfigurable fabric for accelerating large-scale datacenter services[C] //Proc of the 41st Annual Int Symp on Computer Architecture. Los Alamitos, CA: IEEE Computer Society, 2014: 13-24
[2]Lim K, Meisner D, Saidi A G, et al. Thin servers with smart pipes: Designing SoC accelerators for Memcached[C] //Proc of the 40th Annual Int Symp on Computer Architecture. New York: ACM, 2013: 36-47
[3]Qadeer W, Hameed R, Shacham O, et al. Convolution engine: Balancing efficiency & flexibility in specialized computing[C] //Proc of the 40th Annual Int Symp on Computer Architecture. New York: ACM, 2013: 24-35
[4]Krishna A, Heil T, Lindberg N, et al. Hardware acceleration in the IBM PowerEN processor: Architecture and performance[C] //Proc of the 21st Int Conf on Parallel Architectures and Compilation Techniques. New York: ACM, 2012: 389-400
[5]Zhang D, Jayasena N, Lyashevsky A, et al. TOP-PIM: Throughput-oriented programmable processing in memory[C] //Proc of the 23rd Int Symp on High-performance Parallel and Distributed Computing. New York: ACM, 2014: 85-98
[6]Guo Q, Alachiotis N, Akin B, et al. 3D-stacked memory-side acceleration: Accelerator and system design[C] //Proc of the 2nd Workshop on Near-Data Processing in Conjunction with the 47th IEEE/ACM Int Symp on Microarchitecture. Workshop on Near-data Processing. Piscataway, NJ: IEEE, 2014
[7]Nair R, Antao S, Bertolli C, et al. Active memory cube: A processing-in-memory architecture for exascale systems [J]. IBM Journal of Research and Development, 2015, 59(2/3): No.17
[8]Akin B, Franchetti F, Hoe J C. Data reorganization in memory using 3D-stacked DRAM[C] //Proc of the 42nd Annual Int Symp on Computer Architecture. New York: ACM, 2015: 131-143
[9]Zaharia M, Chowdhury M, Das T, et al. Resilient distributed datasets: A fault-tolerant abstraction for in-memory cluster computing[J]. USENIX Conf on Networked Systems Design and Implementation, 2012, 70(2): 2-2
[10]Blanas S, Li Y, Patel J M. Design and evaluation of main memory hash join algorithms for multi-core CPUs[C] //Proc of the 2011 ACM SIGMOD Int Conf on Management of Data. New York: ACM, 2011: 37-48
[11]Teubner J, Alonso G, Balkesen C, et al. Main-memory hash joins on multi-core CPUs: Tuning to the underlying hardware[C] //Proc of the 2013 IEEE Int Conf on Data Engineering. Piscataway, NJ: IEEE, 2013: 362-373
[12]He J, Lu M, He B. Revisiting co-processing for hash joins on the coupled CPU-GPU architecture [J]. VLDB Endowment, 2013, 6(10): 889-900
[13]Jha S, He B, Lu M, et al. Improving main memory hash joins on intel Xeon Phi processors: An experimental approach [J]. VLDB Endowment, 2015, 8(6): 642-653
[14]Polychroniou O, Raghavan A, Ross K A. Rethinking SIMD vectorization for in-memory databases[C] //Proc of the 2015 ACM SIGMOD Int Conf on Management of Data. New York: ACM, 2015: 1493-1508
[15]Balkesen C, Teubner J, Alonso G, et al. Main-memory hash joins on modern processor architectures [J]. IEEE Trans on Knowledge & Data Engineering, 2015, 27(7): 1754-1766
[16]Han Xixian, Yang donghua, Li jianzhong. DBCC-Join a novel cache-conscious disk-based join algorithm [J]. Chinese Journal of Computers, 2010, 33(8): 1501-1511 (in Chinese)(韩希先, 杨东华, 李建中. DBCC-Join:一种新的高速缓存敏感的磁盘连接算法[J]. 计算机学报, 2010, 33(8): 1501-1511)
[17]Manegold S, Boncz P, Kersten M. Optimizing main-memory join on modern hardware [J]. IEEE Trans on Knowledge & Data Engineering, 2002, 14(4): 709-730
[18]Balasubramonian R, Chang J, Manning T, et al. Near-data processing: Insights from a micro-46 workshop [J]. IEEE MICRO, 2014, 34(4): 36-42
[19]Elliott D, Snelgrove W, Stumm M. Computational RAM: A memory-SIMD hybrid and its application to DSP[C] //Proc of the IEEE Custom Integrated Circuits Conf. Piscataway, NJ: IEEE, 1992: 30.6.1-30.6.4
[20]Gokhale M, Holmes B, Iobst K. Processing in memory: The terasys massively parallel PIM array [J]. Computer, 1995, 28(4): 23-31
[21]Oskin M, Chong F T, Sherwood T. Active pages: A computation model for intelligent memory[C] //Proc of the Int Symp on Computer Architecture. Los Alamitos, CA: IEEE Computer Society, 1998: 192-203
[22]Loi G L, Agrawal B, Srivastava N, et al. A thermally-aware performance analysis of vertically integrated (3-D) processor-memory hierarchy[C] //Proc of the 43rd Annual Design Automation Conf. New York: ACM, 2006: 991-996
[23]Loh G H. 3D-stacked memory architectures for multi-core processors[C] //Proc of the 35th Annual Int Symp on Computer Architecture. Los Alamitos, CA: IEEE Computer Society, 2008: 453-464
[24]Woo D H, Seong N H, Lewis D, et al. An optimized 3D-stacked memory architecture by exploiting excessive, high-density TSV bandwidth[C] //Proc of the 16th IEEE Int Symp on High Performance Computer Architecture. Piscataway, NJ: IEEE, 2010: 1-12
[25]Kim D H, Athikulwongse K, Healy M, et al. 3D-maps: 3D massively parallel processor with stacked memory[C] //Proc of Solid-State Circuits Conf Digest of Technical Papers. ISSCC, 2012: 188-190
[26]Pugsley S H, Jestes J, Zhang H, et al. NDC: Analyzing the impact of 3D-stacked memory+logic devices on mapreduce workloads[C] //Proc of the Int Symp on Performance Analysis of Systems and Software. Piscataway, NJ: IEEE, 2014: 190-200
[27]Low T M, Guo Q, Franchetti F. Optimizing space time adaptive processing through accelerating memory-bounded operations[C] //Proc of IEEE High Performance Extreme Computing Conf. Piscataway, NJ: IEEE, 2015: 1-6
[28]Hähnel M, Döbel B, Völp M, et al. Measuring energy consumption for short code paths using RAPL [J]. ACM Sigmetrics Performance Evaluation Review, 2012, 40(3): 13-17
[29]McCalpin J D. Memory bandwidth and machine balancein current high performance computers[N]. IEEE Technical Committee on Computer Architecture Newsletter, 1995: 19-25
[30]Kestor G, Gioiosa R, Kerbyson D, et al. Quantifying the energy cost of data movement in scientific applications[C] //Proc of IEEE Int Symp on Workload Characterization. Piscataway, NJ: IEEE, 2013: 56-65
[31]Pandiyan D, Wu C J. Quantifying the energy cost of data movement for emerging smart phone workloads on mobile platforms[C] //Proc of IEEE Int Symp on Workload Characterization. Piscataway, NJ: IEEE, 2014: 171-180
[32]Zhou J, Ross K A. Implementing database operations using SIMD instructions[C] //Proc of the 2002 ACM SIGMOD Int Conf on Management of Data. New York: ACM, 2002: 145-156
[33]Willhalm T, Popovici N, Boshmaf Y, et al. SIMD-scan: Ultra fast in-memory table scan using on-chip vector processing units [J]. VLDB Endowment, 2009, 2(1): 385-394
[34]Schlegel B, Karnagel T, Kiefer T, et al. Scalable frequent itemset mining on many-core processors[C] //Proc of the 9th Int Workshop on Data Management on New Hardware. New York: ACM, 2013: 3:1-3:8
[35]Sukhwani B, Min H, Thoennes M, et al. Database analytics acceleration using FPGAs[C] //Proc of the 21st Int Conf on Parallel Architectures and Compilation Techniques. New York: ACM, 2012: 411-420
[36]Chung E S, Davis J D, Lee J. Linqits: Big data on little clients[C] //Proc of the 40th Annual Int Symp on Computer Architecture. New York: ACM, 2013: 261-272
[37]Bakkum P, Skadron K. Accelerating SQL database operations on a GPU with CUDA[C] //Proc of the 3rd Workshop on General-Purpose Computation on Graphics Processing Units. New York: ACM, 2010: 94-103
[38]Kim C, Chhugani J, Satish N, et al. Fast: Fast architecture sensitive tree search on modern CPUs and GPUs[C] //Proc of the 2010 ACM SIGMOD Int Conf on Management of Data. New York: ACM, 2010: 339-350
[39]Satish N, Kim C, Chhugani J, et al. Fast sort on CPUs and GPUs: A case for bandwidth oblivious SIMD sort[C] //Proc of the 2010 ACM SIGMOD Int Conf on Management of Data. New York: ACM, 2010: 351-362
[40]Pirk H, Manegold S, Kersten M L. Accelerating foreign-key joins using asymmetric memory channels[C] //Proc of Int Workshop on Accelerating Data Management Systems Using Modern Processor and Storage Architectures. New York: ACM, 2011: 27-35
[41]Kaldewey T, Lohman G, Mueller R, et al. GPU join processing revisited[C] //Proc of the 8th Int Workshop on Data Management on New Hardware. New York: ACM, 2012: 55-62
[42]Kocberber O, Grot B, Picorel J, et al. Meet the walkers: Accelerating index traversals for in-memory databases[C] //Proc of the 46th Annual IEEE/ACM Int Symp on Microarchitecture. New York: ACM, 2013: 468-479
[43]Wu L, Barker R J, Kim M A, et al. Navigating big datawith high-throughput, energy-efficient data partitioning[C] //Proc of the 40th Annual Int Symp on Computer Architecture. New York: ACM, 2013: 249-260
[44]Wu L, Lottarini A, Paine T K, et al. Q100: The architecture and design of a database processing unit[C] //Proc of the 19th Int Conf on Architectural Support for Programming Languages and Operating Systems. New York: ACM, 2014: 255-268
[45]Xi S L, Babarinsa O, Athanassoulis M, et al. Beyond the wall: Near-data processing for databases[C] //Proc of the Int Workshop on Data Management on New Hardware. New York: ACM, 2015: 2-2
[46]Seshadri V, Hsieh K, Boroumand A, et al. Fast bulk bitwise AND and OR in DRAM [J]. IEEE Computer Architecture Letters, 2015, 14(2): 127-131
