基于高性能SOC FPGA阵列的NVM验证架构设计与验证
2018-03-13蔡晓军张志勇赵梦莹贾智平
刘 珂 蔡晓军 张志勇 赵梦莹 贾智平
(山东大学计算机科学与技术学院 山东青岛 262000)(sdu_liuke@outlook.com)
非易失性存储器(non-volatile memory, NVM)具有诸多显著的优点:对外界环境有更强的容错性;比通常用于主存储器的动态随机存取存储器(dynamic random access memory, DRAM)更加可靠,且静态能量消耗比DRAM小若干数量级;能够带来更快的系统启动时间,并且集成密度比DRAM至少高2倍.如今,非易失性存储器已得到工业界包括Intel,Numonyx,STMicroelectronics,Samsung,IBM及TDK等著名公司的广泛支持.由于其优良特性及潜在的市场价值,计算机系统产业迫切希望非易失性存储器能够作为主存储器(main memory)大规模投入使用.近年来,一些使用了新型非易失性存储器(相变存储器(phase-change memory, PCM)、阻变存储器(resistive random-access memory, ReRAM)、磁阻存储器(magnetic random-access memory, MRAM))的固态存储器已经成为缩小处理器与存储器之间鸿沟的最为瞩目的新一代存储器件,如图1所示[1]:

Fig. 1 Architecture of NVM图1 非易失存储应用层次
区别于传统的以块进行读写和擦除操作的flash工艺的非易失存储器,新型存储器采用字节型访问方式.新型存储器拥有高性能、低能耗和高容量的特性.传统存储系统的构建方式不仅不利于发挥非易失性存储器在性能方面的优势,还暴露了非易失性存储器在耐久性(使用寿命)、读写不对称等方面的劣势[2].如何综合各类新型存储的特性,设计高能效的存储架构,实现可应对大数据、云计算所需求的新型主存系统已经成为工业界和学术界的研究热点.
关于NVM验证平台的研究已经有很多,但大多数都是针对芯片层面或者NVM底层特性的研究.NVsim[3]是一种电路层次的NVM仿真工具,基于存储单元模型逐步构建存储芯片;支持在NVM芯片生产前实现性能、能耗以及面积等指标的估计.OpenNVM[4]是一种基于FPGA的NVM验证平台,着眼于验证常见NVM的底层参数,包括读写寿命、最大读写速度以及一些新颖的编码方式等.也有基于存储系统架构级别的仿真工具NVMain[5].
本文提出的基于高性能SOC FPGA阵列的NVM验证架构,互联多级FPGA,利用多层次FPGA结构扩展连接多片NVM.依据所提出的验证架构,设计了基于多层次FPGA的主从式NVM控制器,并完成适用于该架构的硬件原型设计.该架构可以实现测试同类型多片NVM协同工作,也可以进行混合NVM存储管理方案验证.
本文的主要贡献如下:
1) 提出了基于多层FPGA阵列的非易失存储器架构,实现高带宽和大容量的同时,也具备良好的扩展性;
2) 搭建了多层FPGA阵列的非易失存储器验证平台,并基于MRAM存储器完成多层非易失FPGA阵列的存储器架构原型验证;
3) 设计了高速大容量MRAM验证实验,通过实验数据显示,我们所设计的实验原型的读写带宽达到1.5 GBps以上,平均功耗约1.8 W.通过对比示波器测试结果和SOC FPGA输出结果,验证所提出的基于高性能SOC FPGA阵列的NVM控制架构的实用性和数据可靠性.
1 相关工作
为了进一步研究新型非易失存储器的特性,以及如何更好地利用新型非易失存储器为现代存储系统服务,各类NVM仿真验证平台被相继提出.NVM仿真验证平台主要分为仿真型验证平台和带有硬件原型系统的验证平台.
仿真验证平台主要有CACTI[6],NVsim以及NVMain等.CACTI是HP实验室提出的存储器仿真工具,不仅支持DRAM芯片,也支持NVM芯片的设计,通过内置的存储器模型提供NVM芯片的读写速度、面积以及功耗等基本参数,而且支持速度、面积和功耗的平衡设计.NVsim是类似于CACTI的芯片级仿真器,利用NVM存储单元的参数(来自ITRS[7]),按照设定的存储器结构,从subarray到Matrix直到Bank逐层设置参数构建自定义的NVM芯片.NVmain是架构级别的仿真器,支持采用NVM芯片构建存储系统;不仅支持DRAM、常规的NVM芯片以及混合存储架构,也支持MLC类型的NVM芯片以及写寿命评估等功能.
基于硬件原型的验证平台主要有OpenNVM.OpenNVM采用FPGA互联单片NVM,然后将NVM测试逻辑以及NVM控制器部署在FPGA上,实现测试NVM芯片的底层读写参数,如读写速度、读写功耗以及写入寿命等.然而,鉴于市面上的非易失存储器多数容量较小而且单片NVM芯片带宽较小,构建符合真实应用场景的内存或者外存时,需要采用多片NVM芯片构成阵列.因此,本文提出采用多层次FPGA构建NVM阵列,在提供大容量的同时,利用多片NVM并行实现高带宽;同时也可以验证混合存储结构的特性.
2 基于FPGA阵列的NVM控制器架构设计
基于FPGA阵列的NVM控制器架构如图2所示,主要包含3个部分:FPGA存储管理单元、FPGA互连结构以及NVM接口控制器单元.控制器部署在FPGA阵列上,主FPGA和从FPGA通过高速互联通道进行数据交互.主FPGA主要实现高层次的存储任务解析、调度及状态监测等;从FPGA主要实现NVM的底层接口,包括读写操作及控制操作等.

Fig. 2 FPGA arrays based architecture of NVM controller图2 基于FPGA阵列的NVM控制器架构图
基于FPGA阵列的NVM控制器采用多层阵列互联结构,具有良好的扩展性.通过改变从FPGA的数量,可以灵活改变存储容量和存储带宽.此外,从FPGA可以通过接入不同的NVM实现混合存储架构.下面将介绍NVM控制器的结构和工作原理.
2.1 主FPGA NVM控制器设计
主FPGA采用SOC架构的FPGA,如图3所示,不仅包含硬核处理器(ARM),也包含丰富的FPGA逻辑资源.此新型FPGA架构被主流FPGA厂商支持,如Xilinx的ZYNQ-7000[7]系列以及Altera的Cyclone5和Arria[8]系列等.此外,ARM和FPGA间通过高速互联总线(如AXI4总线[9])等进行高速数据交互,而且FPGA内部逻辑可以访问ARM统一编址的存储空间.FPGA管理控制器不仅用于管理存储事务,也用来监测访问带宽、底层存储器状态信息等.FPGA管理控制器接收来自SOC硬核处理器的数据传输任务,然后根据从FPGA获取的状态信息进行数据读写调度.
FPGA管理控制器内置多个FIFO单元,用于处理存储数据源头与FPGA高速互联接口的瞬时带宽差异.存储数据源头有2种实现方式:
1) 采用FPGA逻辑实现模式数据生成器,并且支持SOC硬核控制数据模式以及数据流量等.
2) SOC硬核通过网络或者其他接口获取测试数据,存储在硬核单元和FPGA共享的DDR内存存储中.FPGA实现DMA模块,接收来自SOC硬核提供的DMA地址和DMA长度参数,然后从相应DDR内存地址中获取数据.

Fig. 4 Architecture of slave FPGA NVM controller图4 从FPGA NVM控制器结构示意图
FPGA管理控制器还负责管理访存检测模块,用于记录存储带宽,并验证数据读写任务执行的准确性等.访存监测模块属于独立于FPGA管理控制器内数据传输单元的模块,与FPGA管理控制器的其他模块并行执行,不影响数据传输带宽.此外,访存监测模块提供对接FPGA内置逻辑分析仪和ADC单元的接口,便于监测运行时关键标志位的动作状态以及系统整体的电气特性,如核电压、温度等.
2.2 从FPGA NVM控制器设计
从FPGA的控制器主要实现管理底层NVM接口,NVM物理层面的读写和其他控制.如图4所示,从FPGA控制器主要包含NVM中枢管理模块、NVM底层监控单元、NVM接口控制器以及高速互联通道的从机接口.
NVM中枢管理处于从FPGA控制器的核心位置,主要负责接收来自主FPGA的数据读写任务,然后采用FIFO缓存数据,解决来自主FPGA的突发高速数据流和NVM接口控制器接口带宽差异问题:高速互联通道数据带宽通常超过400 MBps,甚至达到数 GBps,而单个普通NVM芯片接口的读写带宽为几十MBps.
接口控制器实现NVM物理层面的数据接口、地址接口以及控制接口.当NVM接口控制器接收来自NVM中枢管理的读写请求后,控制FPGA的一系列引脚按照NVM芯片所定义的读写时序进行翻转,从而实现读写操作.
基于从FPGA NVM控制器可以单独完成NVM底层参数的测试,如最大读写速度、读写功耗以及写入寿命等.针对最大读写速度以及写入寿命测试,NVM中枢管理控制FPGA内置时钟管理单元,输出所需频率的高精度时钟,然后控制NVM接口产生相应频率的接口读写时序.同时,底层监控模块记录读写次数以及对比读写数据的正确性.
2.3 主从FPGA高速互联接口设计
高速互联通道的主机接口与从FPGA中的高速互联从机接口相连接,主要实现传输FPGA管理控制分配的数据,同时接收从FPGA的工作状态等信息.高速互联通道包含2个层面:物理连接层和传输层.
物理连接层根据FPGA引脚支持的类型,可以实现基于并行总线的数据传输、基于多路LVDS串行总线数据传输以及基于GTX(Xilinx FPGA高速互联接口)或者SRIO(Altera FPGA高速互联接口)高速串行总线接口的数据传输.
传输层根据互联协议,传递数据读写地址、读写规模以及突发模式等.传输层的设计具有较大的灵活性.一方面,可以以较小的逻辑代价实现类似于底层存储器物理接口的访问协议,此时,从FPGA可以看作虚拟化的存储器;另一方面,当需要验证复杂的存储管理策略以及模拟网络化的分布式存储时,主从FPGA的高速互联接口传输层可以建立基于数据帧的复杂协议.
3 基于NVM控制器架构的硬件原型设计
本文基于第2节所描述的NVM控制器设计了硬件验证原型.验证原型由包含Zynq SOC处理器的主FPGA板卡(底板)及包含MRAM存储器的从FPGA板卡(子板)组成.其中,主FPGA板卡包括Zynq处理器芯片、DDR存储器以及4个存储板DIMM插槽,存储板DIMM插槽可同时接入4块从FPGA板卡,4块从FPGA板卡可并行访问;每块从FPGA板卡,由1片Spartan6 FPGA控制芯片以及12片并行、共享地址线的MRAM组成.硬件原型系统如图5所示:

Fig. 5 Architecture of hardware prototype图5 硬件原型实物图
3.1 硬件原型电源系统设计
电源系统有多个电源轨组成.不同的电源转换处都预留测试点,便于测试不同模块的功耗,用于进一步分析NVM控制器的功耗分布.例如,子板总电源功耗P为测试点处的电压V乘以测试点处的电流I(如图6所示).
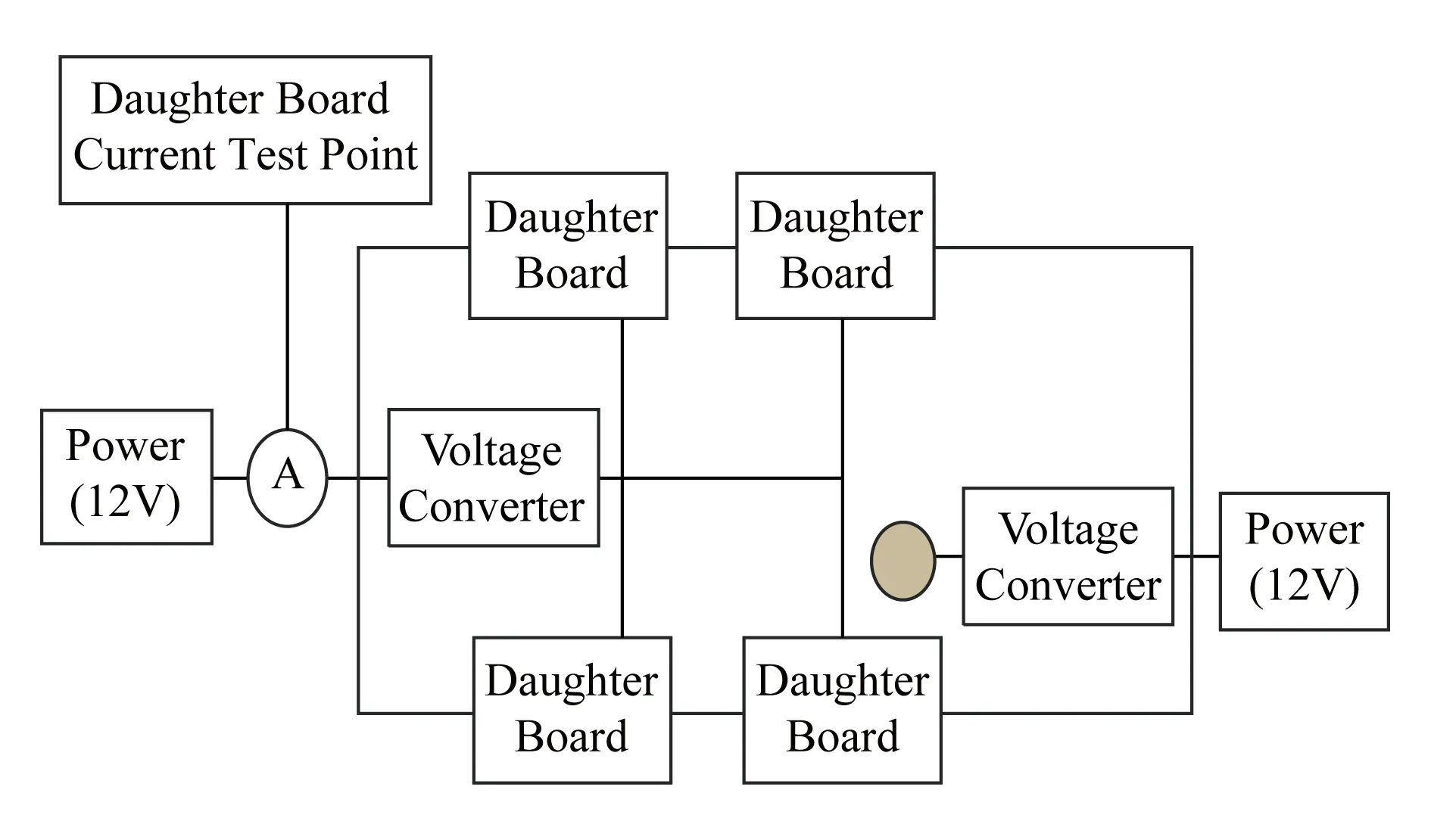
Fig. 6 Architecture of power monitor图6 功耗测试示意图
3.2 硬件原型互联接口设计
主从FPGA的互联电路主要采用差分布线方式.为了同时满足并行总线接口和串行LVDS高速接口以及确保高速通信下的数据准确性,我们采用松耦合的差分布线方式,配合接地信号线,确保参考平面的完整性.互联接口处FPGA的IO选择FAST模式,设定IO阻抗与互联线阻抗一致,实现阻抗匹配;在逻辑层面,采用输入输出引脚插入寄存器的方式,以流水线的策略降低后级逻辑的时序压力,确保FPGA内逻辑的高速运行.
3.3 硬件原型SOC系统
为提升原型系统的灵活性以及通用性,本文在Zynq SOC处理器中部署Linux系统.通过Linux系统的终端与通用计算机互联,实现通用计算机控制测试流程,并显示测试结果的目标.
此外,本文设计了运行于Linux系统的NVM控制器模块的接口程序,抽象NVM控制器的读写操作,支持配置读写操作参数和获取读写状态,如读写地址、读写规模、读写完成状态以及数据校准等,为验证复杂的访存操作模式提供支撑.
4 实验设计与实验结果
4.1 实验设计
基于硬件原型和所提出的NVM控制器架构,本文设计了针对MRAM阵列的高带宽读写验证实验.实验主要包含2部分:采用顺序方式的固定数据读写测试以及基于类IOZONE的可变规模读写测试.
在读写测试过程中,通用计算机通过终端与Linux系统通信,选择需要执行的测试程序,并在读写测试结束时显示读写数据大小以及NVM控制器读写运行的时钟数.与此同时,示波器用于监测读写起始和结束的标志信号,获取读写运行时间;高精度数字万用表用于监测从FPGA板卡电源处的电流和电压,获取系统的运行功耗.
具体方案测试流程如图7所示.读写速率测试逻辑模块作为测试核心,由读写测试控制模块、读写测试结果显示模块及测试数据产生模块3部分构成.
1) 读写测试控制模块负责接收用户配置程序的开启关闭指令,传递种子数据至数据产生模块以及获取测试结果传递给读写测试结果显示模块.
2) 数据产生模块用于根据种子数据产生固定数据量的数据块.在写速率测试时,数据通过FPGA高速互联模块传输至MRAM存储阵列;在读速率测试时产生参考数据,同FPGA高速互联模块读取的数据进行对比,验证读速率测试中的数据有效性.
3) 读写测试结果显示模块用于将读写操作过程以高低电平的方式呈现在读写测试探测点上.

Fig. 7 Flow chart of read and write test on MRAM图7 MRAM读写测试流程图
4.2 实验结果
读写速度测试方面,结合从FPGA的监测单元获取到读写速度以及表1[10].底层MRAM的读写频率为25 MHz,位宽为16 b,48片MRAM的突发读写带宽为2.4 GBps.
主FPGA内置统计单元和示波器测量结果显示,顺序读操作的数据量为240 KB,开始与结束的时间间隔约为114 μs;顺序写操作的数据量为240 KB,开始与结束时间间隔为126 μs,经计算,读速率约为2.055 GBps,写速率约为1.905 GBps,我们所设计的NVM控制器读写带宽可以超过1.8 GBps,达到理论带宽2.4 GBps的75%以上.

Table 1 Characteristics of MRAM表1 MRAM芯片参数表
功耗测试结果显示(如图8所示),包含MRAM的从FPGA系统的总功耗约为7.4 W,每个从FPGA板卡的平均功耗约为1.8 W.

Fig. 8 Power consumption test of MRAM图8 MRAM功耗测试示意图

Fig. 9 Results of readwrite test on IOZONE like benchmark图9 类IOZONE读写速率测试结果
在类IOZONE的读写验证实验中(如图9所示),读写数据的大小范围为24~1 024 KB,读速度基本达到2.0 GBps,而且随着数据规模的增大,读速度略微提升;写速度基本达到1.9 GBps,写入速度随数据规模的变化趋势与读操作类似.NVM控制器实现数据读写操作时,主从FPGA间首先要进行地址建立,然后再进行大规模的数据交换.随着数据块的增大,顺序读写时的地址建立时间在整体读写时间中所占的比例逐渐下降.
5 总 结
新型非易失存储设备的出现为传统存储系统提供了变革和发展的契机.其不同于传统存储器的非易失、低功耗、高密度特性使其具有广阔的应用前景.其低功耗特性使得日益增长的存储系统能耗获得改良;高密度特性使得存储系统的扩展变得容易,特别是主存空间的扩大不再成为瓶颈.
为充分利用新型非易失存储器的特性,构建高带宽大容量的存储器,本文提出的基于高性能SOC FPGA阵列的NVM验证架构,互联多级FPGA,利用多层次FPGA结构扩展链接多片NVM.依据所提出的验证架构,设计了基于多层次FPGA的主从式NVM控制器,并完成适用于该架构的硬件原型设计.该架构可以实现测试同类型多片NVM协同工作,也可以进行混合NVM存储管理方案验证.
[1]Cai Xiaojun, Research on the key technologies of high energy-efficient hybrid main memory based on non-volatile memory[D]. Ji’nan: Shandong University, 2016 (in Chinese)(蔡晓军. 基于非易失存储的高能效混合主存关键技术研究[D]. 济南: 山东大学, 2016)
[2]Shu Jiwu, Lu Youyou, Zhang Jiacheng, et al. Research progresses on memory system based on non-volatile memory[J]. Science & Technology Review, 2016, 34(14): 86-94 (in Chinese)(舒继武, 陆游游, 张佳程, 等. 基于非易失性存储器的存储系统技术研究进展[J]. 科技导报, 2016, 34(14): 86-94)
[3]Dong X, Xu C, Jouppi N, et al. NVSim: A circuit-level performance, energy, and area model for emerging non-volatile memory[G]. Emerging Memory Technologies. New York: Springer, 2014: 15-50
[4]Zhang J, Park G, Shihab M M, et al. OpenNVM: An open-sourced FPGA-based NVM controller for low level memory characterization[C] //Proc of the 33rd IEEE Int Conf on Computer Design. Piscataway, NJ: IEEE, 2015: 666-673
[5]Poremba M, Zhang T, Xie Y. Nvmain 2.0: A user-friendly memory simulator to model (non-) volatile memory systems[J]. IEEE Computer Architecture Letters, 2015, 14(2): 140-143
[6]Wilton S J E, Jouppi N P. CACTI: An enhanced cache access and cycle time model[J]. IEEE Journal of Solid-State Circuits, 1996, 31(5): 677-688
[7]Crockett L H, Elliot R A, Enderwitz M A, et al. The Zynq Book: Embedded Processing with the Arm Cortex-A9 on the Xilinx Zynq-7000 All Programmable Soc[M]. Glasgow: Strathclyde Academic Media, 2014.
[8]Tyhach J, Hutton M, Atsatt S, et al. ArriaTM10 device architecture[C] //Proc of Custom Integrated Circuits Conf. Piscataway, NJ: IEEE, 2015: 1-8
[9]Azarkhish E, Rossi D, Loi I, et al. High performance AXI-4.0 based interconnect for extensible smart memory cubes[C] //Proc of Design, Automation & Test in Europe Conf & Exhibition. Piscataway, NJ: IEEE, 2015: 1317-1322
[10]DeBrosse J, Maffitt T, Nakamura Y, et al. A fully-functional 90nm 8Mb STT MRAM demonstrator featuring trimmed, reference cell-based sensing[C] //Proc of Custom Integrated Circuits Conf. Piscataway, NJ: IEEE, 2015: 1-3
