NV-Shuffle:基于非易失内存的Shuffle机制
2018-03-13潘锋烽
潘锋烽 熊 劲
(计算机体系结构国家重点实验室(中国科学院计算技术研究所) 北京 100190)(中国科学院大学 北京 100049)(panfengfeng@ict.ac.cn)
非易失性内存(non-volatile memory, NVM)的出现为解决磁盘性能瓶颈问题提供了新的机会,本文中的NVM指的是基于内存总线接口、字节寻址的非易失内存.在内存计算的场景下,非易失性内存有着非常广泛的应用场景.与磁盘和DRAM相比,NVM的主要优势有:1)NVM有着与DRAM相接近的读写延迟和吞吐率,有望用来消除磁盘IO开销,提升系统的IO性能;2)NVM的存储密度比DRAM更大,与NAND Flash SSD相似,它能存放更多的数据;3)相比于内存,NVM具备非易失、可持久化的优势.随着工业界大力发展非易失内存,其进展相当迅速,2013年Micro公司推出了搭载Flash与DRAM的Hybrid DIMM[1].2014年,AgigA Tech公司推出了DDR接口的 NVDIMM[2-4].Intel与Micro联合推出的DDR接口的3D XPoint[5]产品预计2018年面市,3D XPoint闪存速度堪比内存,因此解决磁盘性能问题的一个较为直接的方式是替换存储介质,将传统的磁盘替换成NVM,这样使得内存计算中的数据读写能够获得NVM的性能,与此同时也保证了数据的持久化.
众所周知,Shuffle的性能是决定大数据处理性能的关键因素之一[6-9].由于传统Shuffle阶段的数据一般是通过磁盘文件系统进行持久化,所以影响Shuffle性能的一个重要因素是IO开销[7,10-11],NVM有助于解决内存计算在Shuffle阶段由于持久化所带来的IO开销.因此本文将NVM引入到Shuffle阶段中,但是由于NVM的性能接近DRAM,有研究工作表明,对于NVM现有的系统软件(NVM文件系统)开销过高,不能充分发挥NVM的性能[12-15].表1展示了在压缩[16]过程中文件系统各个部分的开销比例[17].
从表1可以看出,大约60.5%的时间花费在了文件系统上,其中关于元数据的开销依然占据着较大的比例.上述结果表明,即使使用最新的NVM文件系统,其开销也是非常大的.如何高效使用NVM来提升Shuffle阶段的IO性能是当前内存计算使用NVM所面临的一个重要问题与挑战.
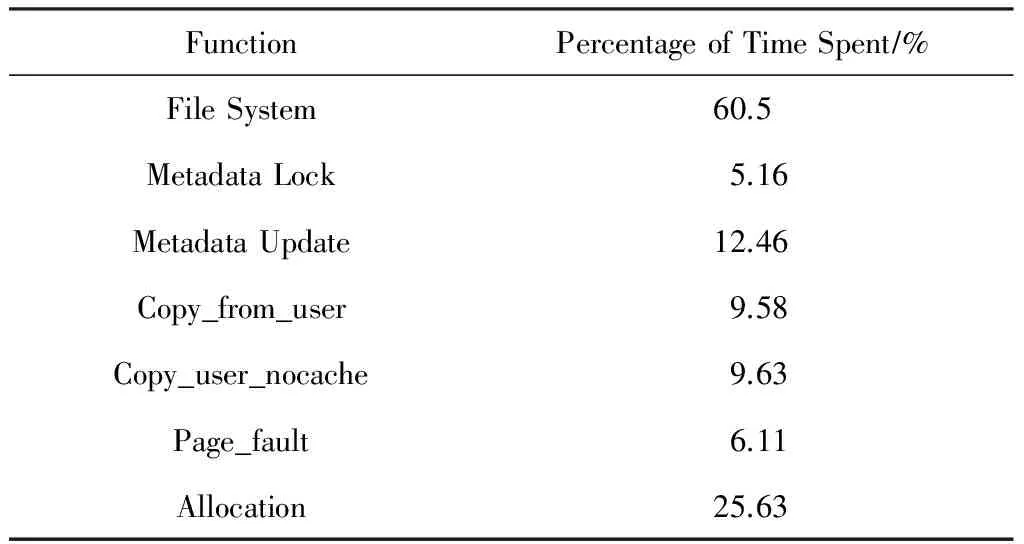
Table 1 Percentage of Time Spent in File System表1 文件系统中各个部分的开销比例[17]
在本文中,我们提出了一种基于NVM的Shuffle优化策略——NV-Shuffle.为了最大化发挥NVM的性能优势,NV-Shuffle摒弃了以文件系统进行Shuffle数据存取的方式,而是采用持久化内存的方式,直接在用户态访问持久化内存,避免了传统存储系统中的冗长的IO路径,例如文件系统、设备驱动等.
本文的主要贡献如下:
1) 利用pVM构建Java的持久化内存访问接口——NV-Shuffle接口,使大数据平台能够直接使用与访问NVM;
2) 针对NVM提出了一种Shuffle数据的组织方式——基于Hash的私有持久化缓冲区,从而能够高效处理并发、故障、网络传输等方面的问题;
3) 针对传统Shuffle阶段预先创建文件的问题,提出一种符合NVM空间自身的分配策略——延迟分配,从而能够提升NVM的空间利用率;
4) 对于Shuffle数据的读取与恢复,通过使用映射表方式来管理,使其能够快速定位、读取数据以及在出现失效之后进行快速的数据恢复.
1 相关工作
本节主要分为2个部分:传统计算框架关于Shuffle的优化以及NVM的相关工作.
1.1 Shuffle优化
传统大数据处理平台中的Shuffle阶段都是使用单一类型的存储设备(Disk或者SSD),以文件系统的方式进行数据的存取,并没有涉及到异构存储的使用.因此关于该部分的优化主要围绕的是在使用磁盘的场景下,如何减少磁盘的IO开销,主要涉及2个问题:
1) 数据重复读写引起的磁盘IO开销;
2) 数据拉取过程中随机、小粒度的IO模式引起的磁盘IO开销.
根据不同的优化方法,分为内存加速、磁盘IO聚合和高速网络加速.
1.1.1 内存加速
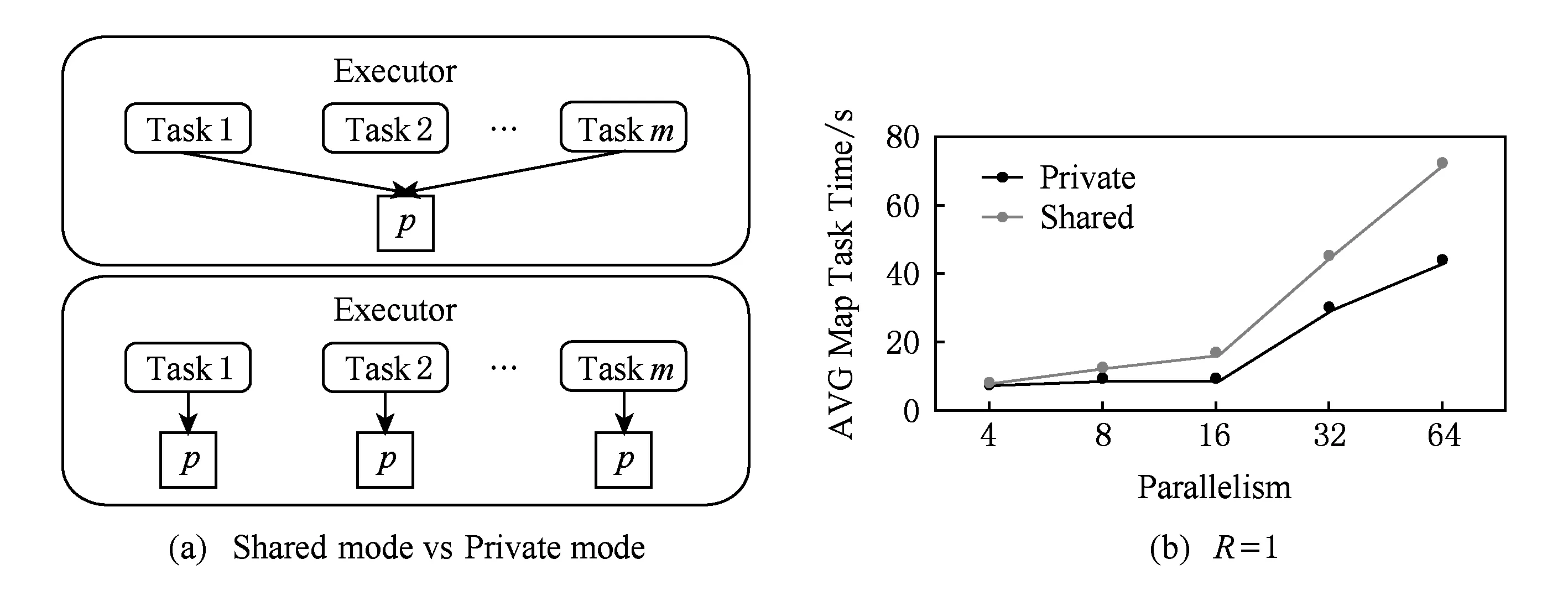
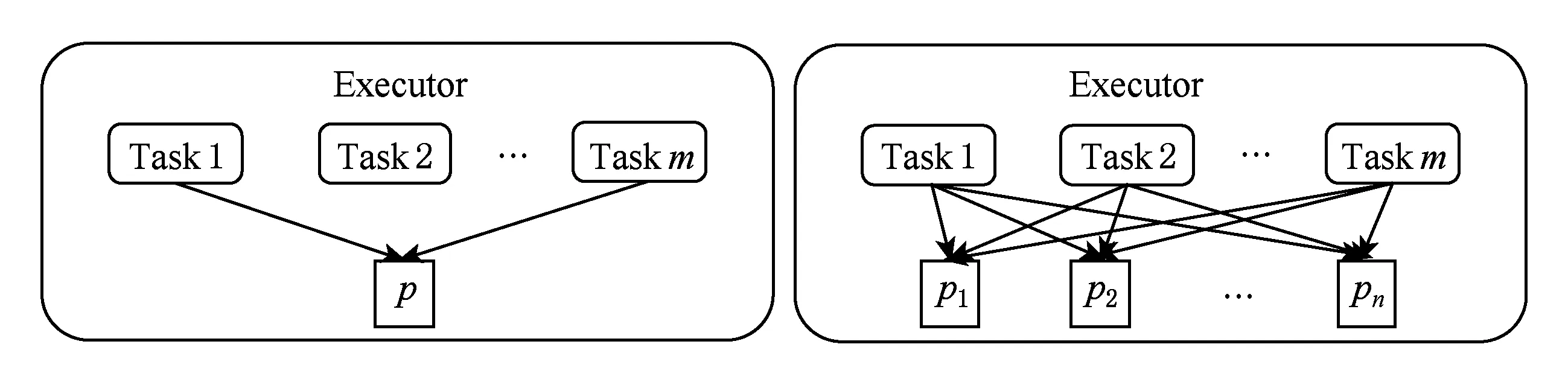
在Shuffle阶段,都会存在数据重复读写的问题,由于节点分配给每个Task的内存是有限的,使得数据多次从磁盘中读取出来之后写回,例如Map端可能会使数据重复2次读写,Reduce端则可能会更多,这无疑引起较多的磁盘IO开销,影响作业的执行效率.针对该问题,Themis系统[18]提出了“2-IO property”,即作业在处理数据的过程中,数据从磁盘的读写次数只有2次(HDFS和中间结果各一次),其余过程都不会与磁盘交互.为了达到该目标,Themis系统在Shuffle阶段使用了动态内存分配策略对该过程中的数据进行存储,从而大幅度减少磁盘IO开销,降低了作业时间.类似地,SpongeFiles[19]发现由于某些作业存在数据倾斜的问题,引发的一个现象是某些Task的内存空间已经用完且触发了Spill,而某些Task的内存空间还有剩余,如图1(a).基于该现象,SpongeFiles通过共享Task中未使用的内存空间,如图1(b),减少Spill的次数,从而降低了磁盘IO开销.
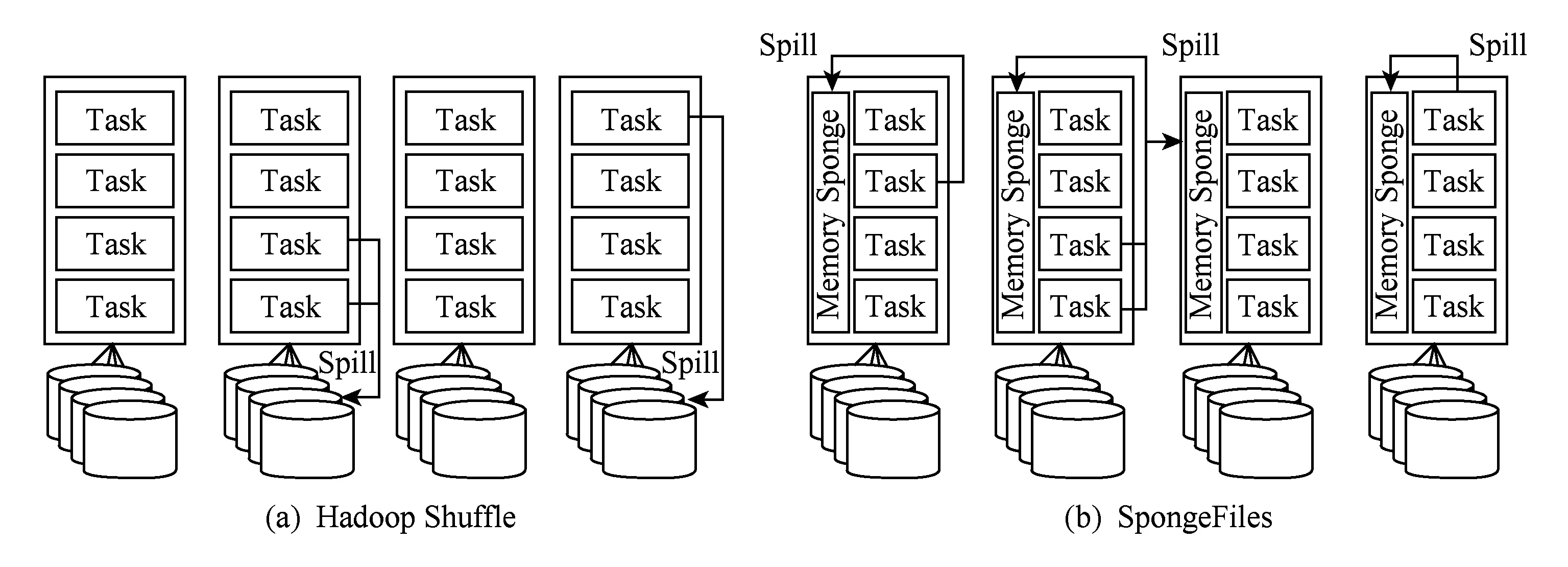
Fig. 1 The way how task organizes memory图1 Task内存的使用方式
1.1.2 聚合磁盘IO
在Shuffle阶段过程中,Reduce端在读取过程中会存在大量的小粒度、随机读,从而引起磁盘的大量寻道,降低IO性能,延长作业执行时间,对于磁盘而言,适用的IO模式是大粒度、顺序的.因此当中间结果的数据量较大时,磁盘会出现性能瓶颈.为了解决该问题,Sailfish系统[20]采用了“Batching Data IO”的技术来避免Shuffle读取时产生的大量寻道问题,即写Shuffle数据时,聚集每个Map Task相对应的分区的数据,利用分布式文件系统来存储相应的数据,从而在读取中间结果时,原先的随机、小粒度的读转换成了顺序、大粒度的读,加速了中间结果的数据读取,如图2所示,但是存在的问题是将中间结果写入到分布式文件系统中,需要涉及到2次网络IO:前期写入和后期读取,而原始Shuffle将中间结果写入到本地磁盘时,网络IO只涉及到了“后期读取”,因此在考虑使用分布式文件系统存储中间结果时,还需要考虑当前集群的网络环境.
1.1.3 高速网络加速
Shuffle过程中,Reduce端拉取数据会引起重复数据的读写,重复数据的读写意味着大量的磁盘操作,并且以小粒度、随机为主,因此当中间结果的数据量较大时,该阶段可能会存在磁盘性能瓶颈.
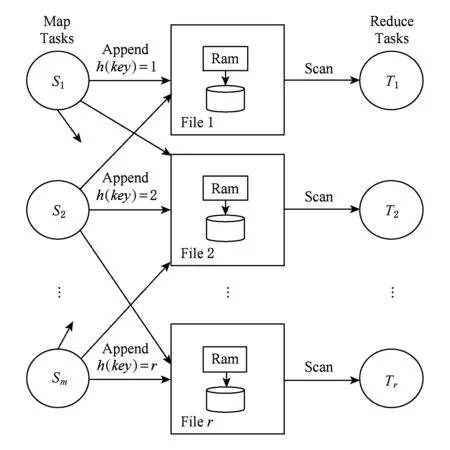
Fig. 2 Batching data IO图2 聚合磁盘IO
Hadoop-A[21]和Hadoop-IB[22]利用高速网络(RDMA[23-24])的特性,通过高效的算法,避免了重复数据的读写.大致流程:首先建立关于key的优先队列;然后Reduce根据优先队列中key的顺序,进行数据的Shuffle,Merge,Reduce操作.优先队列的主要作用是使得Shuffle,Merge,Reduce三阶段进行pipeline:由于key是有序排列的,因此根据key的顺序从Map端进行读取,从而避免了Reduce端的重复数据读写.
1.2 非易失内存相关工作
随着非易失内存NVM(主要指的是持久化内存)的发展,一部分研究工作集中于如何对该存储介质上的数据进行访问和管理,大致可以分为2类:1)提供文件系统抽象,即基于NVM的文件系统(NVM file system);2)提供持久化内存抽象,上层应用可通过新的接口或者编程模型来直接使用NVM(persistent regionsheaps).
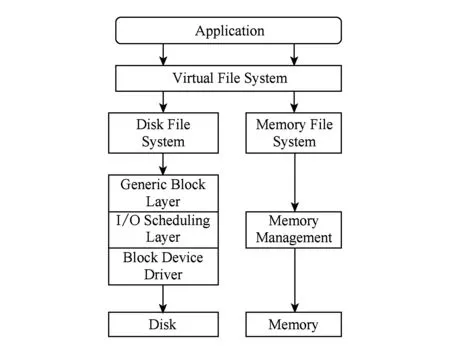
Fig. 3 The stack of Linux file system图3 Linux IO软件栈
1.2.1 基于NVM的文件系统
传统文件系统主要是针对慢速块设备(例如磁盘)而设计的,如图3所示,应用程序关于文件的读写请求发出之后,通过虚拟文件系统到达文件所在的文件系统,例如EXT4,并且需要经过通用块层、IO调度层和块设备驱动等软件层次才能最终到达存储设备,而对于内存文件系统而言,其访问层次就明显减少,它主要利用高度优化的内存管理来访问内存.
典型的工作,例如BPFS[25],SCMFS[26],PMFS[27]等.BPFS是由Condit等人在2009年提出的一种关于字节寻址的持久化内存文件系统,它主要利用了NVM的两大特性,即字节寻址和原地更新.BPFS以内存的方式来管理持久化内存,并在其上构建文件系统的数据结构,避免了数据拷贝,通过short-circuit shadow paging技术来支持数据的原子性、细粒度、一致的更新,从而使得机器重启之后仍能正确访问其中的数据[25].Wu等人在2011年提出了一个在虚拟地址空间中实现的文件系统SCMFS,该系统利用内存管理单元实现虚拟地址到物理地址的转换,并且利用现有的内存管理模块进行块管理,使得每个文件的虚拟地址空间都是连续的,简化了文件操作,减少了CPU开销,另外它还采用了空间预分配机制以及相应的垃圾回收机制[26].Intel在2014年提出了基于NVM的文件系统——PMFS,它绕开了传统文件系统的缓存层,而直接对持久化内存进行访问,通过该种方式能够有效避免数据拷贝,大幅提升文件系统的性能[27].
基于NVM的文件系统主要设计目标是降低传统文件系统软件栈的开销,并且利用NVM的特性来提升文件系统的性能,如字节寻址、原子更新、高性能的随机访问,但是这些文件系统都是基于虚拟文件系统,文件系统本身的开销还是存在的,例如元数据的管理、名字空间的维护,这些对于文件系统而言也是一个较大的开销,无法最大化发挥NVM的性能优势,因此有一部分研究工作集中于为上层应用程序提供用户态的编程接口,程序能够在用户态访问NVM.
1.2.2 持久化内存的编程模型与接口
传统存储系统中,数据结构存储2种格式:内存格式和磁盘格式.这2种格式之间的转换只有在数据持久化的过程中进行.而在持久化内存中,数据结构可以直接持久化在内存中,无需进行格式的转换.一些研究工作[13,15,28-29]利用该特性简化了NVM的使用,例如,Volos等人提出的轻量级主存系统Mnemosyne[15]在PCM设备能保证64 b原子写的假设下修改系统库函数,为程序员设计了一个直接访问非易失存储器的接口,对于开发过程中想要持久化的数据, 只需用特定的数据类型pstatic声明即可.Coburn等人提出了一个轻量级高性能持久化对象系统——NV-heaps(non-volatile memory heaps)[13],它是基于BPFS[25]的硬件设计结构,为程序员提供了包括对象、指针、主存分配等接口,实现指针安全(防止非易失存储上的指针指向易失性存储介质的情况发生)、ACID事务处理、传统API服务、高性能以及可靠的功能,以便在系统崩溃、断电或其他常见失效发生时保护非易失存储设备上数据的正确性.另外,NV-Tree[30],CDDS[31]等工作提出了一个基于NVM的一致性、可持久化的数据结构,使得应用可以直接使用相应的数据结构,而不需要关心数据结构在持久化内存上的具体实现细节.上述工作主要还是在基于文件系统之上(粗粒度的空间管理)提供了细粒度的数据管理、空间分配与释放、持久化以及事务管理,而pVM[17],它是基于VM(virtual memory),而不是文件系统,因此在性能上,pVM更胜一筹.
2 NV-Shuffle设计与实现
NV-Shuffle的主要设计目标是高效利用NVM加速Shuffle阶段,其核心思想是基于持久化内存的访问接口进行NV-Buffer的分配与数据读写,通过Hash-based Private NV-Buffer进行Shuffle数据的组织,使用KeyValue方式进行NV-Buffer的管理.
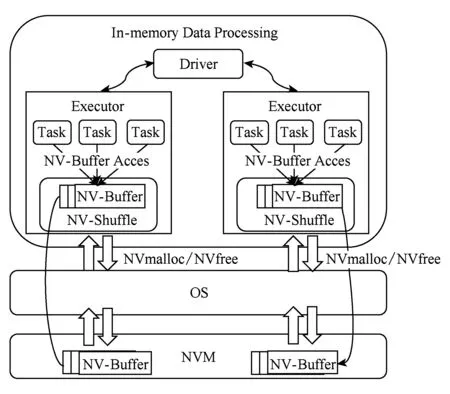
Fig. 4 The architecture of NV-Shuffle图4 NV-Shuffle架构图
图4展示了NV-Shuffle的总体框架.从图4中可以看出,NV-Buffer是Shuffle数据存储的基本单位,在Shuffle过程中,通过NVmalloc和NVfree接口进行NV-Buffer的分配与释放,而对于NV-Buffer的访问与传统的Memory访问类似.至于Shuffle过程中数据如何组织、NV-Buffer如何分配与管理都将在下面几节进行详细描述.
2.1 NV-Shuffle接口
传统文件系统主要是为了磁盘而设计的,而对于NVM而言,其性能接近于DRAM,而且CPU可直接通过指令访问,导致文件系统自身的开销过大,例如元数据的管理、名字空间的维护等,而针对这些问题,现有的一些研究针对NVM重新设计了新的文件系统,例如BPFS[25],SCMFS[26],PMFS[27]等,使其避免或者简化了文件系统的设计,从而获取较高的性能.
NVM内存除了用于外存储(文件系统)和易失性内存外,利用其非易失特性,还可以实现持久化内存,比如,近年来的Mnemosyne[28],NV-Heaps[29],pVM[17]等工作,它们提供了用户态的编程接口,使程序能够在用户态访问非易失主存, 避免了传统存储系统中的冗长路径,包括文件系统、设备驱动等.在持久化内存中实现持久化的数据结构,保证系统掉电后数据的一致性和可访问性,从而使得程序可直接在用户态进行持久化数据结构的高效访问.而pVM与Mnemosyne,NV-Heap的区别在于前者是基于VM(virtual memory)实现的,而后者是基于VFS(virtual file system).相比于Mnemosyne,NV-Heap,pVM在扩容、性能等方面存在优势.
对于Shuffle数据而言,只需要保证它们在作业运行期间可靠地、持久化地存储,持久化内存比文件系统有更小的额外开销,因此,我们采用基于持久化内存的Shuffle数据存储.NV-Shuffle接口需要满足以下3个特征.
1) 基于持久化内存的接口访问NVM.①提供类似于Posix mallocfree的接口;②摒弃传统文件系统的方式来存储Shuffle数据;③应用程序可以通过接口直接使用或者获取NVM空间.
2) 数据可持久化.当操作系统或者应用由于故障等原因崩溃并重新启动时,NVM中的数据可以进行恢复,以便后续进行数据的读取.
3) 接口的适用性.能够在大数据平台上使用.当前大多数的大数据平台都是基于JavaScala而编写的,因此能够提供基于Java的接口以适应大数据的场景.
NV-Shuffle使用持久化内存分配和回收接口:NVmalloc和NVfree,其实现主要借鉴了pVM,由于pVM本身提供的是C++的接口,我们在JVM中添加了NVmalloc和NVfree接口,即用其封装了pVM相应的接口,以供大数据平台上的应用使用.但是在性能评测中,我们利用内存来模拟 NVM,并且使用Java自带的分配堆外内存接口进行内存的分配与使用.
2.2 基于NVM的Shuffle数据组织方式
传统基于文件系统的Shuffle数据的组织方式有2种:Sort-based组织方式和Hash-based组织方式.对于Sort-based Shuffle,每个Task最终产生一个文件,且在该文件中的数据是根据partition ID排序的.在最终文件形成的过程中,可能会存在多个文件,而最终文件是通过将这几个文件合并而成.因此Sort-based Shuffle的主要开销在于Sort,Spill,Merge,并且在合并的过程中数据需要进行序列化和反序列化,增加了开销;而对于Hash-based Shuffle,每个partition ID都会对应一个文件,优势在于不需要进行Sort,Spill,但是劣势在于可能会存在大量的小文件,并且小文件同时打开,会占用较多的内存空间.
对于基于NVM的Shuffle数据的组织方式,主要从2个方面考虑.
1) Shuffle数据本身的特征:①Shuffle数据通过partition ID划分成多个分区,每个分区的数据存储在一起,分区之间按partition ID的顺序进行存储;②多个Task同时进行各自Shuffle数据的读写,即多个Map Task之间不共享Shuffle数据;
2) NVM与磁盘之间的区别:NVM与磁盘的最大区别在于小粒度、随机IO的性能,其中磁盘性能受小粒度、随机IO的影响较大,而NVM的小粒度、随机IO的性能基本上与顺序IO性能相同.
综上所述,对于NVM而言,Shuffle数据的组织方式采用Hash-based更为合适:可以减少Sort,Spill,Merge的性能开销;而且对于NVM而言没有小文件和随机IO的问题.
根据Task,Partition,NV-Buffer三者之间的关系,又可以将Hash-based NV-Buffer分成2种形式:基于Hash的共享持久化缓冲区(Hash-based Shared NV-Buffer)和基于Hash的私有持久化缓冲区(Hash-based Private NV-Buffer).
2.2.1 基于Hash的共享持久化缓冲区
Shared NV-Buffer是通过partition ID进行区分的,也就是,不同Task上具有相同partition ID的keyvalue存储在同一个NV-Buffer上,如图5所示:
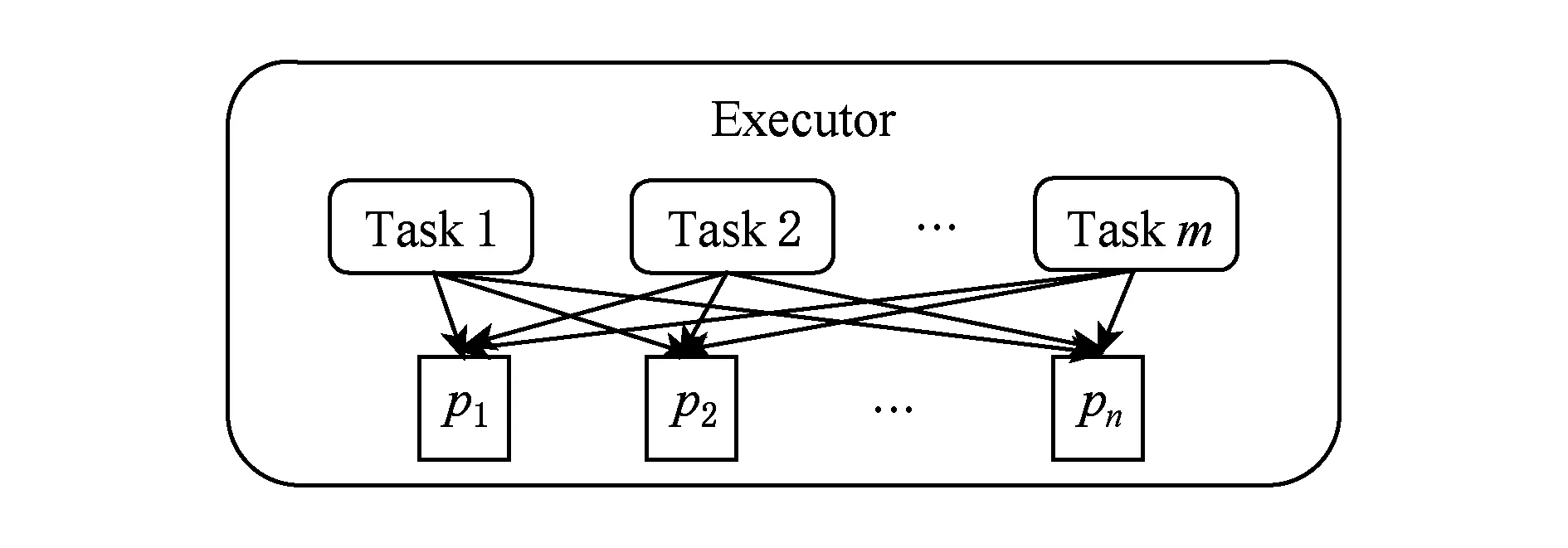
Fig. 5 Hash-based Shared NV-Buffer图5 基于Hash的共享持久化缓存
使用Hash-based Shared NV-Buffer的优势在于:1)NV-Buffer的空间利用率较高;2)申请NV-Buffer的开销较小.但是该种方式的劣势在于:
1) 多个Task可能并发地往同一个NV-Buffer中写数据,这时会由于并发写而带来锁开销;
2) 由于所有Task中相同partition ID的数据都聚集在同一个NV-Buffer中,假设其中一个Task执行失败了,或者某一个Task执行较慢,此时系统会在其他节点上同时启动一个Task处理相同的数据,此时就需要对失败的或者执行较慢的Task所产生的数据进行清理与删除.
2.2.2 基于Hash的私有持久化缓冲区
Private NV-Buffer是通过partition ID和Task进行区分,也就是,每个Task的每个partition ID都会对应一个NV-Buffer,这种方式与传统Hash-based的方式是类似的,如图6所示:
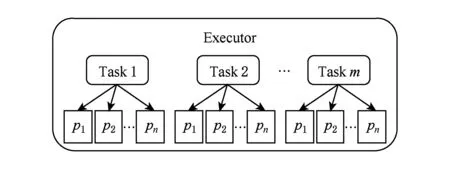
Fig. 6 Hash-based Private NV-Buffer图6 基于Hash的私有化持久化缓存
而使用Hash-based Private NV-Buffer的优势在于:1)Task并发写时没有锁竞争开销;2)Task之间的数据是通过各自的NV-Buffer完全隔离,因此失效Task的数据直接进行删除即可,但是这种方式的劣势在于:
1) 空间利用率低.每个Task上不同partition ID的数据量是不相同的,可能差异非常大,统一进行分配NV-Buffer则会造成某些NV-Buffer空间利用率低,导致NVM空间的浪费.
2) 申请NV-Buffer的次数较多.每个Task的每个partition ID都会申请一个NV-Buffer,申请的次数是Shared NV-Buffer的M倍,其中M表示Map Task的个数,因此可能会在一定程度上存在性能开销.
2.2.3 设计抉择
通过对Hash-based Shared NV-Buffer和Hash-based Private NV-Buffer的优缺点分析,我们采用Hash-based Private NV-Buffer的方式对Shuffle数据进行组织,其原因主要有以下2点:
1) Hash-based Shared NV-Buffer的问题主要来自于“多个Task共享一个NV-Buffer”,共享NV-Buffer带来2个方面的问题:并发带来的开销和失效处理时带来的开销.另外,根据第2.2节对于Shuffle阶段特征的描述,Hash-based Shared NV-Buffer与Shuffle阶段的特征(Task之间互不影响)不匹配;
2) Hash-based Private NV-Buffer基本上与Shuffle阶段的特征匹配.不过,它有2个方面的劣势:空间利用率和性能开销,但是相比于共享NV-Buffer所带来的2个问题,Hash-based Private NV-Buffer所面临的上述2个劣势更易解决.
2.3 NVM空间(NV-Buffer)的分配策略
在2.2.3小节中,我们通过Hash-based Private NV-Buffer的方式来组织Shuffle数据,但是Hash-based Private NV-Buffer存在2个问题:空间利用率低和性能开销大.而影响空间利用率和性能开销的一个重要因素在于空间分配粒度——NV-Buffer粒度.一方面,NV-Buffer的粒度较小,则会引发高频率的空间分配,从而影响性能;另一方面,NV-Buffer的粒度较大,则会降低空间利用率,从而造成NVM空间的浪费.因此,NV-Buffer粒度的选取是空间和性能上的一种权衡.
2.3.1 NV-Buffer粒度的选取
首先,我们通过实验来观察不同NV-Buffer粒度下的性能开销问题.该实验主要集中在Map Task端,即事先为Map Task中的每个partition分配NV-Buffer,而partition的个数等于Reduce Task的个数,分配完成之后进行Map Task的计算.在实验中,我们假设负载的数据分布是均匀的,即Map Task中每个partition的数据量基本上是相同的,因此partition数据量的计算公式如下所示:
(1)
其中Map Task所处理的数据量一般为Block Size的大小B,而partition个数为Reduce Task的个数R.因此在执行过程中,一个Map Task需要执行R次NV-Buffer的空间分配,且每次分配的空间大小约为BR,对于不同Reduce Task个数的结果如图7所示:

Fig. 7 The time of malloc in Map Task图7 Map Task中malloc所花费的时间
从图7中可以看出:1)malloc的开销随着Reduce个数逐渐增加而上升,其主要原因在于Reduce个数增多,malloc执行的次数也就相应的增加,从而增加了总的malloc的开销;2)malloc所花费的时间较小,以Reduce个数为215为例,一个map task执行了215次malloc所所花费的时间不到1 s,因此从总体上看malloc的开销较小,因此即使malloc次数较多(控制在一定范围之内),对于job整体上的性能影响也是有限的,所以在NV-Buffer粒度的选取上,由于malloc的开销比较小,为了能够保证NVM空间较高的利用率,NV-Buffer粒度以小粒度为基准进行分配(默认为8 KB).
2.3.2 延迟分配策略
选取了NV-Buffer粒度之后,需要解决如何进行NV-Buffer的申请与分配.在Hash-based Private NV-Buffer中,按照之前的流程需要进行M×R次NV-Buffer的申请与分配,然而,在一些场景下,可能某些partition并不存在数据,例如,
1) 工作负载的数据本身存在倾斜,导致某些partition的数据多,而某些partition的数据少甚至没有;
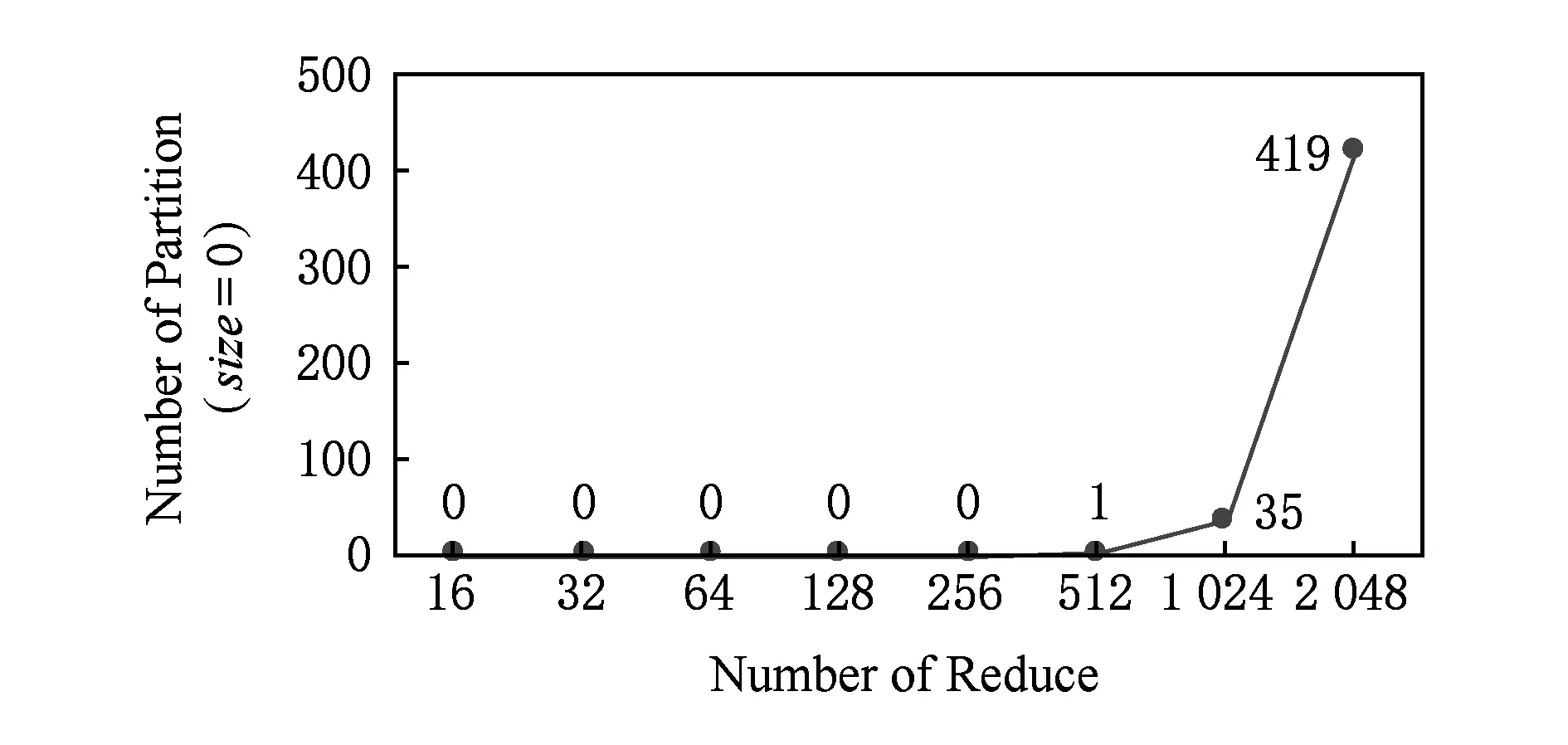
Fig. 8 The impact of partition size on data distribution图8 partition粒度对于数据分布的影响
2) partition粒度过细,即Reduce个数较多.从图8中可以看出,当Reduce个数较少时,基本上不存在size=0的partition,而当Reduce个数较多是,size=0的partition个数上升,例如当Reduce个数为2 048时,size=0的个数占到了约20%,而一般地,Reduce个数设置较大的作业在集群规模较大(成百上千个节点)、输入数据量较大(TB级)的场景下是常见的[20].
因此,对于这些没有数据的partition而言,并不需要进行NV-Buffer的分配,而在原始流程中.会根据partition的个数首先创建好相应个数的文件,然后进行数据的写入,那么相对应的,对于NV-Shuffle而言,首先会分配一定大小的NV-Buffer(8 KB),然后往NV-Buffer中写数据,当NV-Buffer写满时,会继续申请新的NV-Buffer来存储Shuffle数据,如图9所示:
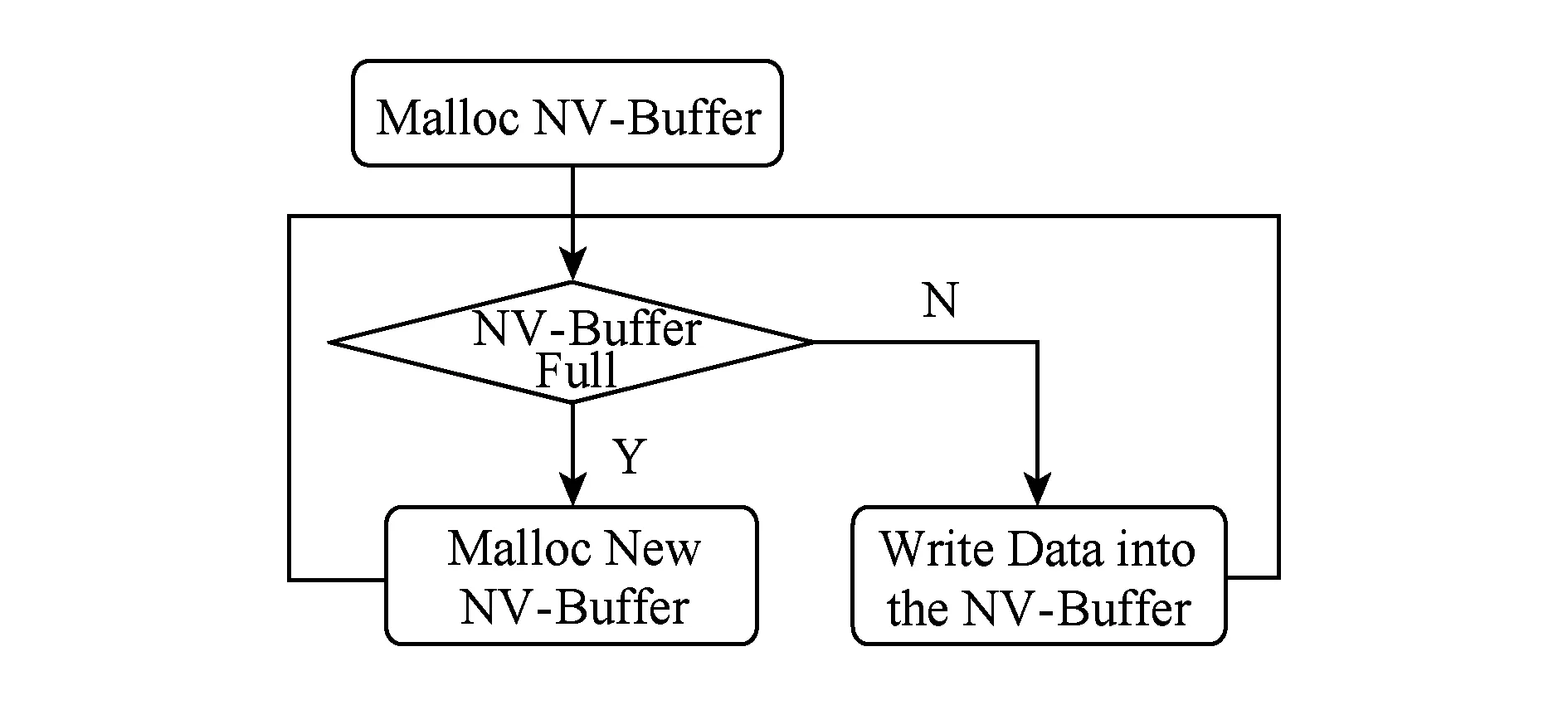
Fig. 9 Original procedure图9 原始流程(预先分配)
对于文件而言,没有数据的写入时,只会存在少量的元数据;而对于NV-Buffer而言,事先分配了相应粒度的NV-Buffer,如果没有数据的写入,虽然NV-Buffer以小粒度分配,但还是会造成空间上的浪费,因此,我们将原始的预先分配流程进行优化,采用延迟分配的方式,即只有当partition有数据时,才会申请相应的NV-Buffer,如果没有数据则始终不进行申请,具体流程如图10所示:

Fig. 10 Late allocation policy图10 延迟分配策略
从图10可以看出,通过延迟分配能够避免预先分配中为没有数据的partition而分配的NV-Buffer.
2.4 NV-Buffer管理
NV-Shuffle摒弃了文件系统,而采用NV-Buffer的方式来使用NVM,并且由于NV-Shuffle采用Hash-based Private NV-Buffer的方式,会生成非常多的NV-Buffer,如何对这些NV-Buffer进行管理是一个非常重要的问题.
首先,我们需要了解Shuffle阶段对于NV-Buffer的访问模式,如图11所示:
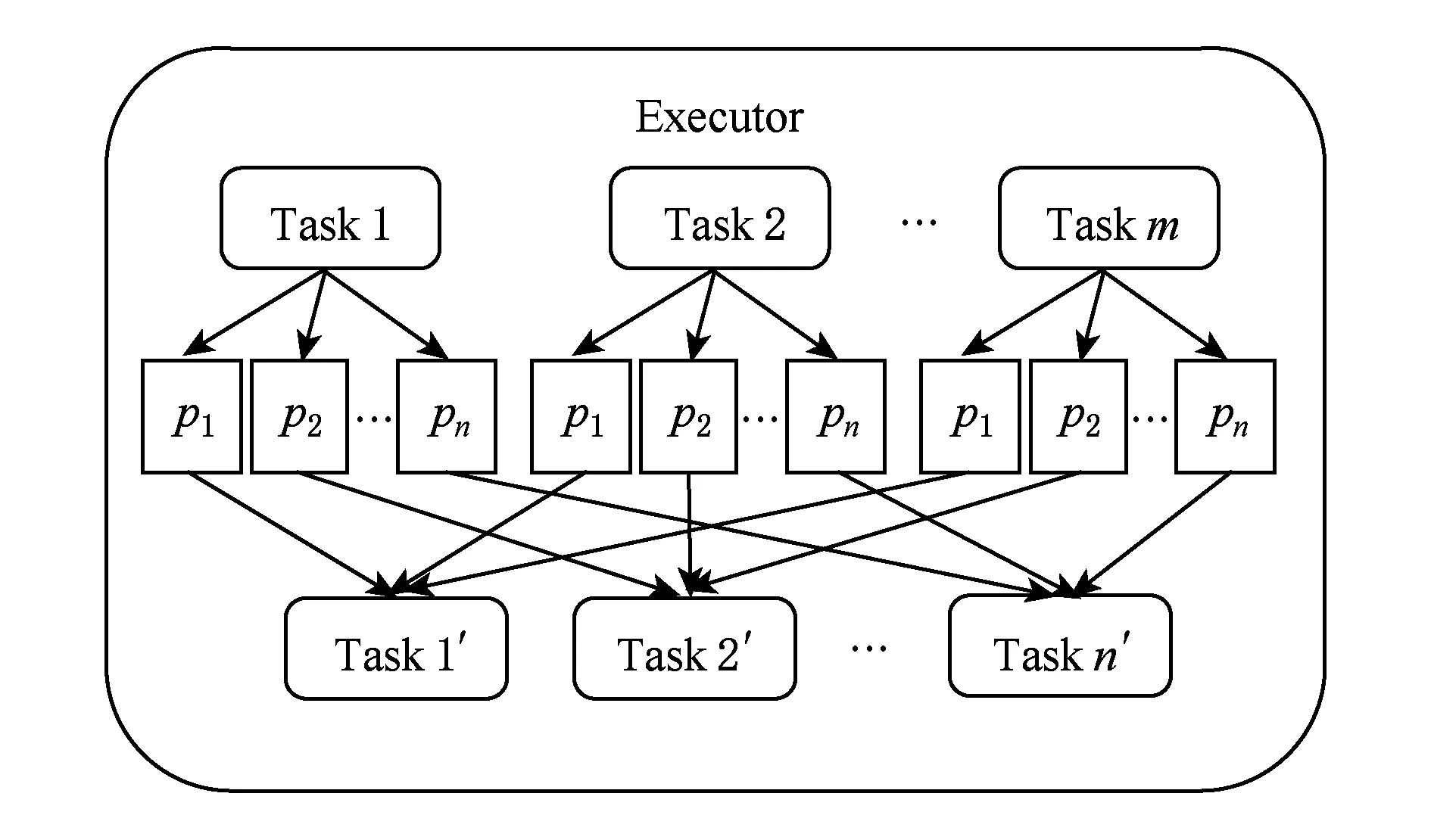
Fig. 11 NV-Buffer access pattern图11 NV-Buffer访问模式
从图11可以看出,NV-Buffer的访问模式较为简单,当进行读取时,不同Task需要读取与之对应的数据,而这些数据是根据partition ID进行区分的.在读取的过程中,一个partition ID会对应多个NV-Buffer,因此需要一个数据结构来存放partition ID与NV-Buffer之间的关系,综上所述,对于NV-Buffer组织与管理需求分为以下3个方面.
1) 简单.
2) 快速查询.直接通过partition ID查询NV-Buffer.
3) 数据聚合.相同partition ID的NV-Buffer聚合.
根据上述特征,我们采用映射表的方式来存储partition ID与NV-Buffer之间的关系,并且需要考虑的是一个partition ID会对应多个NV-Buffer的场景.
当一个Task写满一个NV-Buffer,会将相应的〈partition ID,NV-Buffer〉插入到映射表中,而当一个Task执行完成之后,会将该映射表中的内容上传到Driver中,由Driver来维护映射表,主要有3个作用:
1) 信息只有在执行完成后才能上传,失效的Task不上传,保证了后续的Task所读到的内容都是正确的;
2) Reduce Task会根据Driver中记录的信息,到相应的节点上去拉取数据,如图12所示;
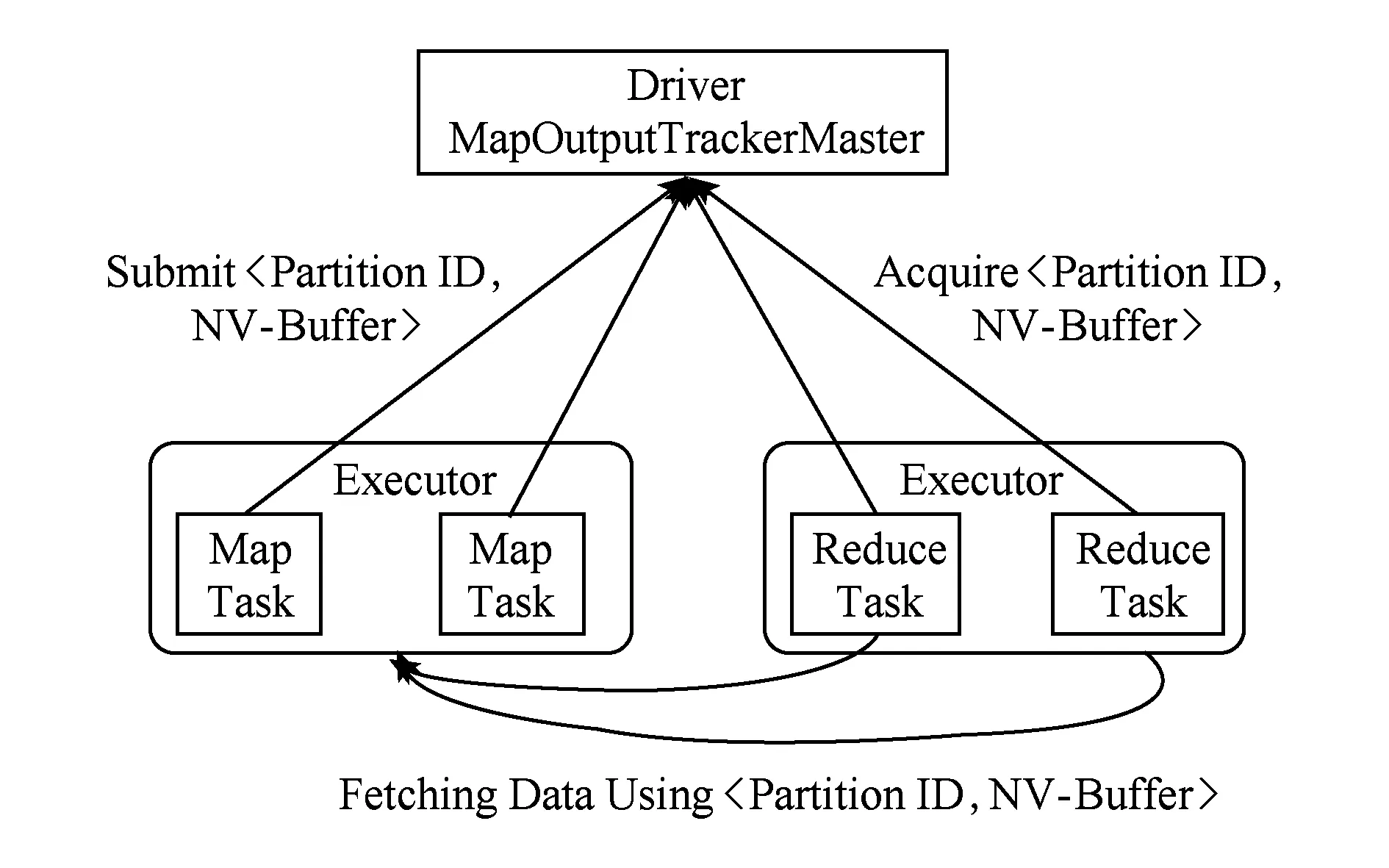
Fig. 12 Shuffle数据位置信息的获取图12 Access to the address of shuffle data
3) 当数据所在的Executor由于某些原因崩溃而重新启动一个新的Executor,Reduce Task还是能够通过Driver中记录的NV-Buffer信息进行数据的拉取,从而避免了重计算的开销.原始Spark中,Reduce Task也是按照上述流程进行数据的读取,但是从第3.5节中关于失效恢复的测试中可以看出,原始Spark中Shuffle数据是与Executor绑定的(Executor ID),当一个Executor崩溃后,重启的Executor不复用原来Executor的ID,所以,即便原来的Executor崩溃前已运行结束的Task的Shuffle数据已完好保存下来,在失效恢复后也无法利用,需要重新计算.而对于NV-Shuffle而言,我们对于NV-Buffer的管理与组织不依赖于Executor ID,从而使得在失效恢复时,能够快速找到崩溃Executor的Shuffle数据.
3 实验与结果
3.1 实验环境
3.1.1 测试平台以及Spark集群配置信息
由于在评测中,我们直接使用内存来模拟NVM,所以服务器上的内存主要有2个用途:Spark自身使用以及Shuffle阶段的数据存储.因此关于Spark主要参数的设置,如表2所示.
3.1.2 测试负载
根据Shuffle阶段数据量的不同,我们将负载大体分为2类:Shuffle-heavy和Shuffle-light.其中Shuffle-heavy的负载指Shuffle阶段的数据量较大(通常与输入数据量相同,或者远大于输入数据量),而Shuffle-light的负载指Shuffle阶段的数据量较小(通常要远小于输入数据量).因此在本次实验中我们使用了3种不同类型的负载:1)Sort(Shuffle-heavy,即中间结果数据量≈输入数据量);2)Word-count(Shuffle-light,即中间结果数据量≪输入数据量);3)TPC-H[32]的22条查询语句,每一条语句所执行的操作不同,因此为了得到其输入数据量与中间结果数据量之间的关系,我们使用TPC-H官方的数据生成器,生成了160 GB的原始数据,并将其导入到HDFS中.TPC-H的数据是由8张不同的表构成,在160 GB的原始数据量中,每张表的数据量分为是:lineitem 120 GB, orders 27 GB, partsupp 19 GB, customer 3.7 GB, part 3.7 GB, supplier 219 MB, nation 2.2 KB, region 389 B.通过Spark SQL执行22条TPC-H查询语句,执行结果如表3所示.
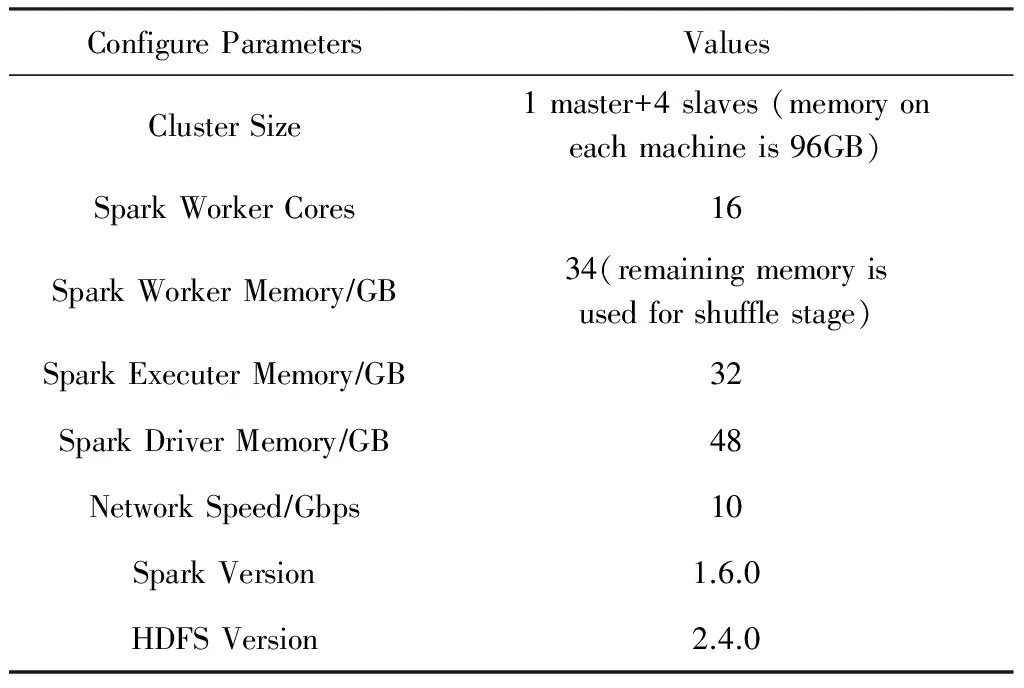
Table 2 The Configuration of Spark表2 Spark配置信息
从输入数据量和中间结果数据量来看,22条查询语句有不同的特征,主要可以分为以下3类:
1) Shuffle数据量≫输入数据量,例如Q8,Q9,Q21等;
2) Shuffle数据量≈输入数据量,例如Q4,Q12,Q20等;
3) Shuffle数据量≪输入数据量,例如Q1,Q6,Q14等.
而对于NV-Shuffle而言,其有利的场景应该包含2个方面:1)输入数据量较大;2)中间结果数据量≈输入数据量或者 Shuffle数据量≫输入数据量.由于节点的内存是有限,因此我们在选取数据集大小时,需要考虑集群内存是否能够存储中间结果数据,集群内存与Shuffle数据量之间的关系需要满足式(2):
集群剩余总内存>2×Shuffle数据量,
(2)
其中,集群剩余总内存表示的是集群留给Shuffle数据的存储空间,Shuffle数据在job的过程中会存储2份,即Map端1份,Reduce端1份.因此在条件中Shuffle数据所占用的空间需要是原先的2倍,只有当集群剩余总内存大于2倍Shuffle数据量,该job才能顺利执行,否则失败.当然,该限制条件主要是由于当前的测试环境造成的.所以,对于上述负载所采取的数据量:1)Sort:~100 GB;2)Wordcount:~256 GB;3)TPC-H:~160 GB.
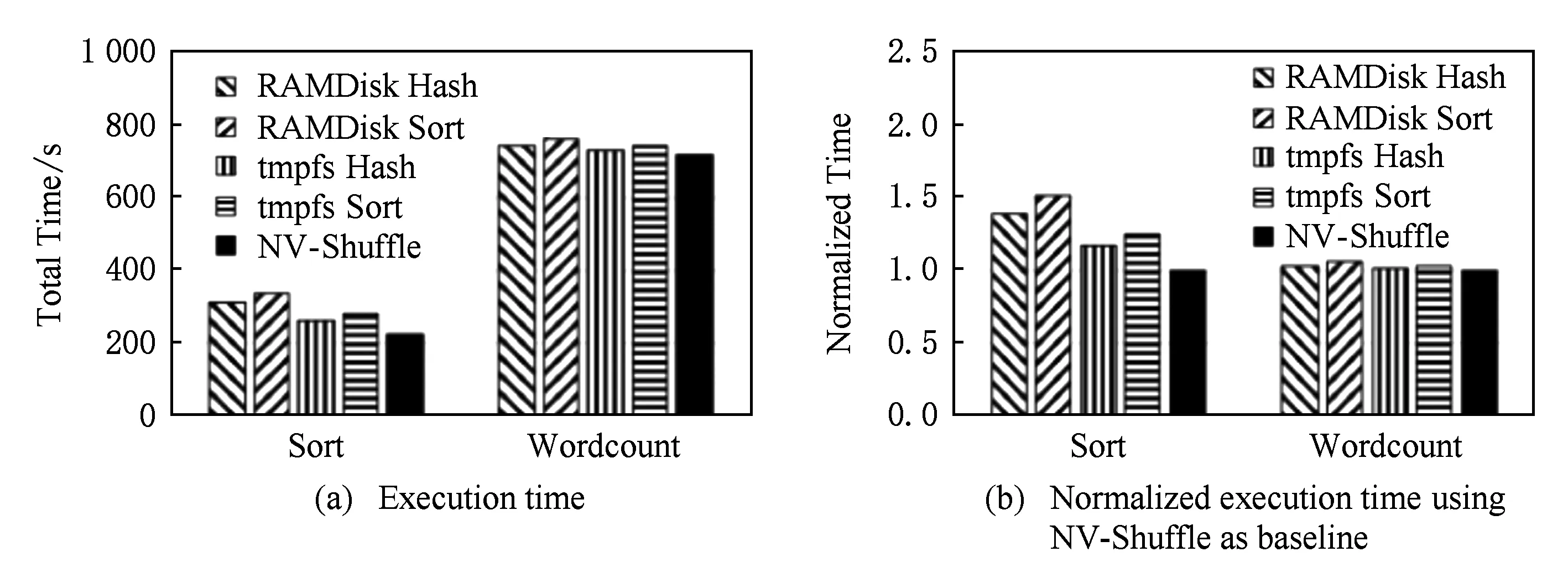
Fig. 13 The execution time of Sort and Wordcount图13 Sort和Wordcount的执行时间
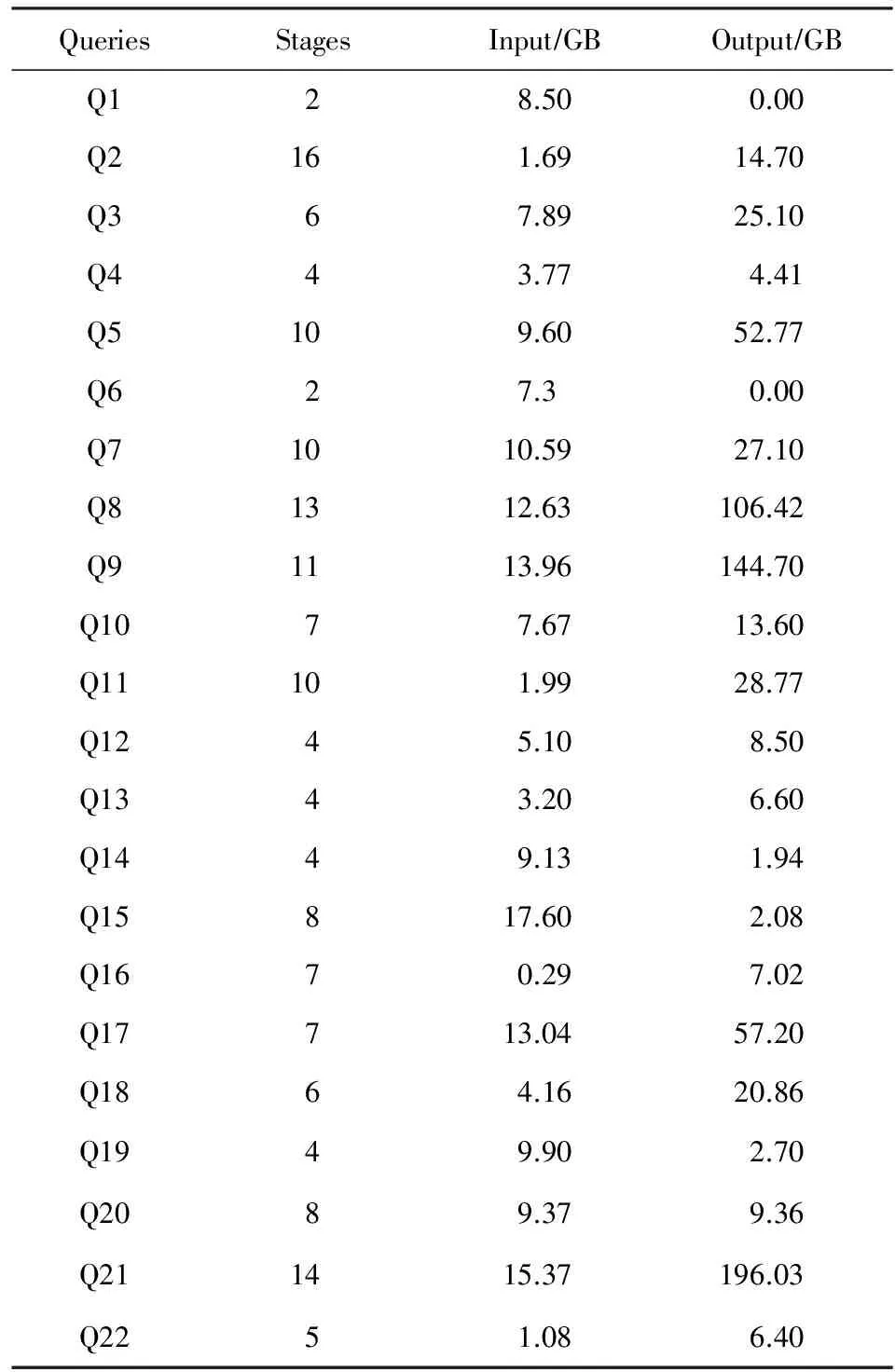
Table 3 The Basic Characters of TPC-H Queries表3 TPC-H Queries的基本特征
3.1.3 对比对象
原始的Shuffle是使用文件系统存储Shuffle数据,如果想将NVM应用于原始Shuffle,一种简单的办法是在NVM上创建一个本地文件系统.由于我们是用内存模拟NVM,因此可以在NVM上先创建块设备(用RAMDisk),再在RAMDisk上创建Ext4.此外,专门针对内存设计的文件系统(如tmpfs),也可以在NVM上直接使用,但它没有持久化保存数据的功能,所以其性能优势在于消除了持久化数据带来的开销.因此,我们选择了基于RAMDisk的Ext4和tmpfs做对比对象.

Table 4 Shuffle Data Storage表4 Shuffle数据的存储方式
根据Shuffle模式不同,我们使用了常见的模式Hash-based和sort-based.因此,NV-Shuffle的对比对象如表5所示:

Table 5 Compared System表5 对比对象
3.2 性能测试
图13展示了Sort和Wordcount在各种对比系统中的执行时间以及归一化执行时间(以NV-Shuffle的执行时间为基准),从图13中可以看出,NV-Shuffle对Shuffle-heavy类型和Shuffle-light类型负载的影响是不同的:
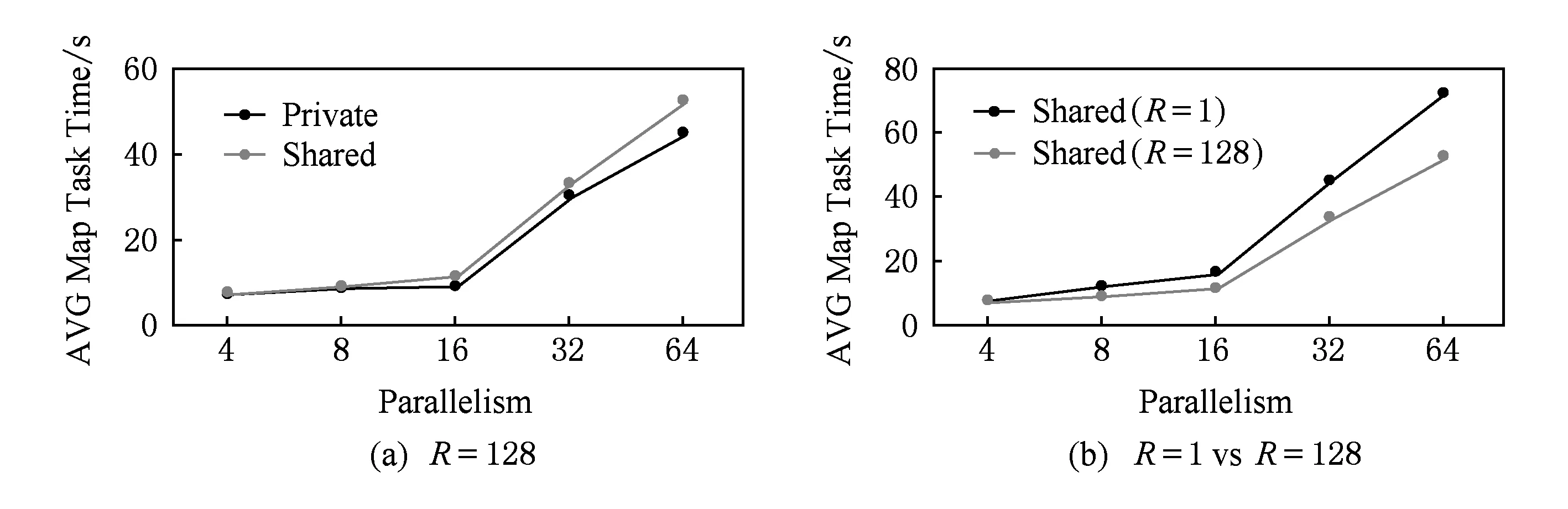
1) Shuffle-heavy类型.相比于其他模式,NV-Shuffle有较为明显的优势.以Sort为例,图13(b)显示了Sort以NV-Shuffle为基准的执行时间比例,分别是1.4,1.52,1.18,1.26.由于Sort负载是Shuffle-heavy类型的负载,输入的数据量约为100 GB,且中间结果的数据量也为100 GB左右,因此在Shuffle阶段读写数据量较大,此时NV-Shuffle的性能优势得以体现;
2) Shuffle-light类型.各种模式的执行时间基本上相同.以Wordcount为例,从图13(b)可以看出,其执行时间比例大致都为1.其主要原因在于,Wordcount在Input,Shuffle,Output这3个阶段的数据量分别是244.5 GB,15 GB,5.8 GB.中间结果的数据量太小,导致发挥不了NV-Shuffle的性能优势,因此对于Wordcount负载而言,5种对比系统的执行时间基本上相同.
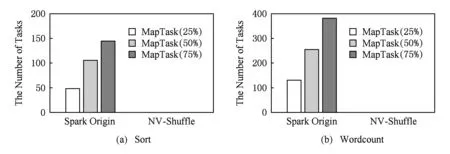
为了更加清楚地观察Sort和Wordcount在5种不同模式下的执行时间,我们统计了Sort和Wordcount在Map stage和Reduce stage的执行时间,如图14所示:
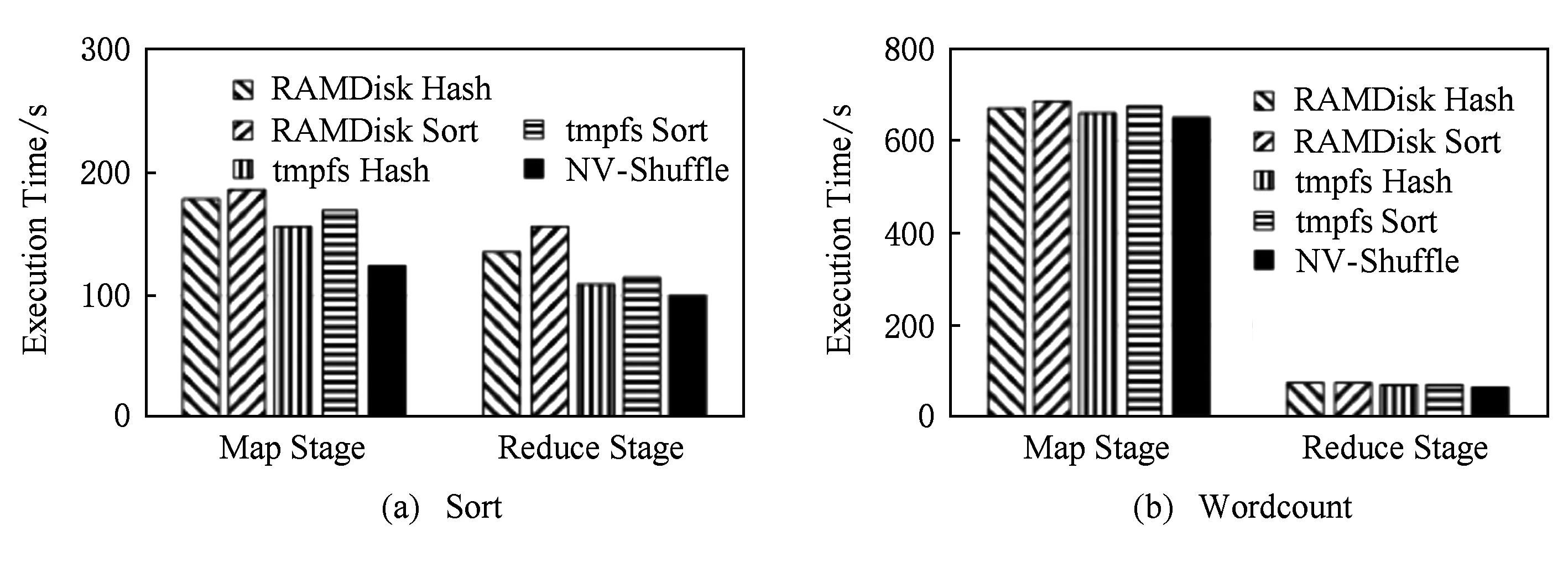
Fig. 14 The execution time of different stages图14 不同负载的Map Stage和Reduce Stage的执行时间
图14展示了Sort和Wordcount在Map Stage和Reduce Stage的执行时间.从图14中也可以看出,Shuffle阶段的数据量是决定NV-Shuffle性能优势的重要因素.另外,通过比较不同存储方式和Shuffle模式,我们也可以看出:
1) tmpfs与RAMDisk在性能上的差异.由于tmpfs是内存文件系统,而RAMDisk则是使用内存来模拟块设备,并且在其上格式化一个普通的文件系统,例如在本次实验中使用的Ext4,因此在性能上,本身tmpfs是要优于RAMDisk.由于Shuffle数据量上的差异,Sort的差异要比Wordcount的差异更为明显.
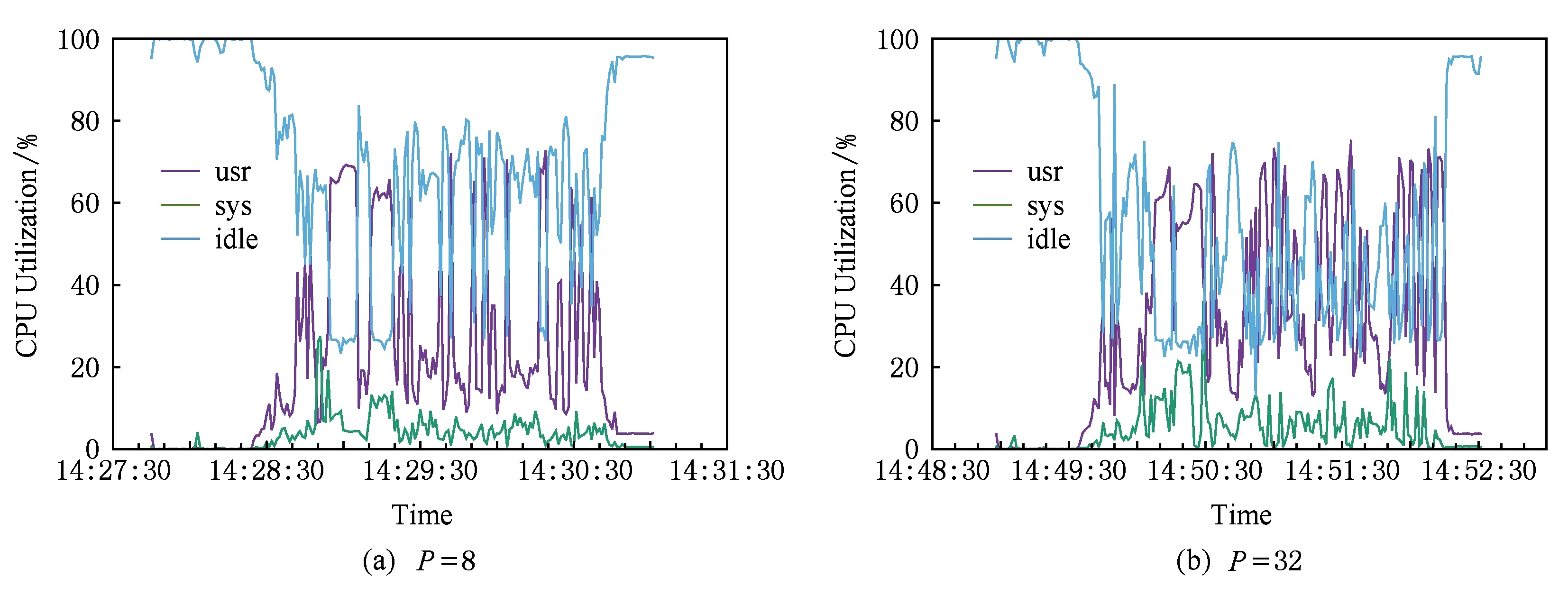
2) Hash-based Shuffle与Sort-based Shuffle在性能上的差异.在数据规模与Reduce Task个数不是特别多的场景下,Hash-based模式的性能还是要优于Sort-based模式,但是当Reduce Task个数较大时,Hash-based模式的局限性就会体现出来:小文件对系统性能的影响.我们使用RAMDisk模式测试了不同Reduce Task个数对于Sort负载的影响,其结果如图15所示.
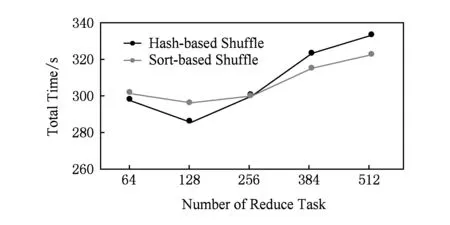
Fig. 15 The executing time of different configuration图15 不同配置下的执行时间
图15展示了在不同Reduce Task个数的场景下,Sort执行时间的变化情况.从图15中可以看出,当Reduce Task设置得较小时,Hash-based模式在性能上还是存在优势的;当Reduce Task个数较大时,由于本身的局限性,Hash-based的性能不如Sort-based.这也是为什么在原始Spark中,会存在一个参数“spark.shuffle.sort.bypassMergeThreshold”的原因.当然,由于NV-Shuffle摒弃了文件系统的存储方式,因此小文件问题不会影响NV-Shuffle的性能,从而NV-Shuffle仍旧采用类似于Hash-based的数据组织方式.
同样地,我们使用TPC-H的22条查询语句对比了上述5种对比系统的执行时间,为了能够更好地展现22条查询语句的执行时间,我们根据RAMDisk上Sort的执行时间进行分类:
1) 执行时间T≫200 s;
2) 执行时间T>200 s;
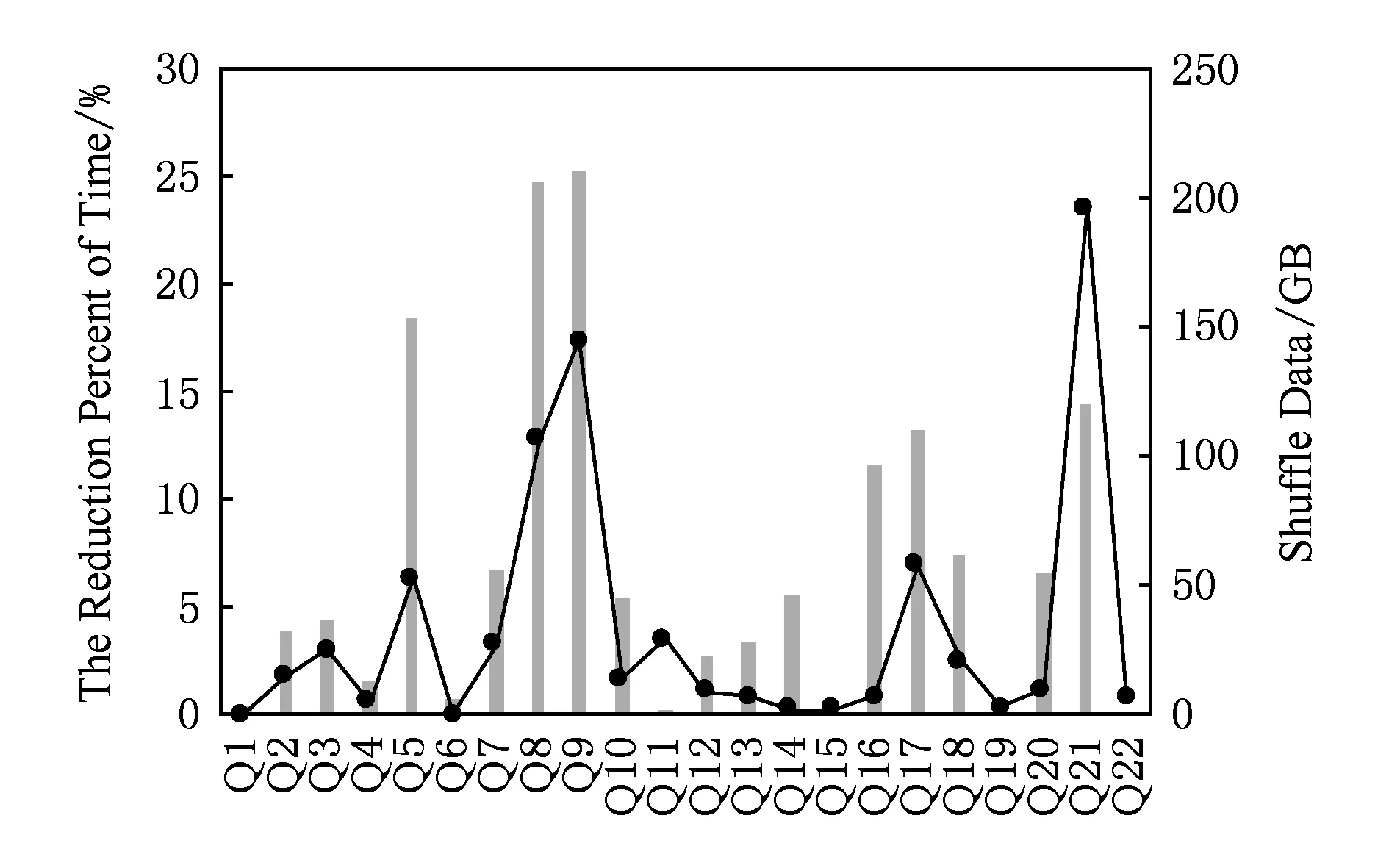
3) 执行时间100 s 4) 执行时间T<100 s. 图16展示了TPC-H中查询语句的执行时间和Shuffle数据量,图16中左坐标表示的是查询的执行时间,右坐标表示的是该查询语句执行过程中Shuffle的数据总量.为了能够更好地展现NV-Shuffle与其他4种对比对象在TPC-H负载中的差异,我们选择了每条查询语句在RAMDisk Hash,tmpfs Hash,RAMDisk Sort,tmpfs Sort这4种方式下执行时间最少的方式,与NV-Shuffle进行对比,对比的结果如图17所示: Fig. 16 The results of TPC-H图16 TPC-H的测试结果 图17展示了相比于MinTime(RAMDisk Hash,tmpfs Hash,RAMDisk Sort,tmpfs Sort),NV-Shuffle降低的百分比.从图17中可以看出: Fig. 17 Comparison of NV-Shuffle with Min(RAMDisk Hash, tmpfs Hash, RAMDisk Sort, tmpfs Sort)图17 NV-Shuffle与Min (RAMDisk Hash,tmpfs Hash,RAMDisk Sort,tmpfs Sort)之间的对比 1) Shuffle数据量越大,NV-Shuffle的效果越明显(10%~25%),例如Q5,Q8,Q9,Q21等; 2) 由于其Shuffle数据量少,NV-Shuffle基本上没有效果,例如Q1,Q6,Q15,Q19等; 3) 其他Query语句,虽然存在一定量的Shuffle数据,但是NV-Shuffle能够降低的执行时间非常有限(3%~8%),例如Q2,Q3,Q15等. NV-Shuffle使用了Hash-based Private NV-Buffer的方式,而与之对应的是Hash-based Shared NV-Buffer方式,在本节中,我们主要对比这2种方式的性能差异. Fig. 18 The relationship between parallelism, the number of partitions and performance overheads图18 并行度P、partition个数R、性能开销O三者之间的关系 在第2.2节中,我们提到Hash-based Shared NV-Buffer的2个缺点是并发写带来的锁开销和失效恢复(暂不评价).因此,我们来看并发写带来的锁开销对于Hash-based Shared NV-Buffer的影响.影响并发写的2个因素:节点上Task的并行度和partition个数.并行度P、partition个数R、锁竞争引发的开销O这三者之间的关系,如图18所示: 图18中的横坐标表示的是并行度与partition个数的比例,纵坐标表示的是性能开销,从图18中可以看出,当PR越小,性能开销就越小,反之,性能开销则越大.因此,我们进行了一些对比实验,该实验我们使用了一个1+1的Spark集群,且使用了Sort负载进行测试. 图19展示了Shared与Private在极端场景下的性能对比,即partition的个数为1,并行度分别为4,8,16,32,64,则PR的比例是逐渐增大.在实验中,我们统计了Map Task的平均执行时间,从图19中可以看出:1)Private的平均时间都要小于Shared的平均时间,一个主要的原因在于Shared存在锁竞争的开销;2)当并行度逐渐增大时,例如32,64,无论是Private还是Shared,平均时间都有一个明显的上升,引起该现象的主要原因在于测试节点的CPU核数为12,启用超线程之后变为24,因此当并行度为32或者64时,存在CPU资源的竞争,从而导致性能的下降.为了更加清晰地看出不同并行度下的CPU利用率,我们列举了并行度为8,32时节点在Map Stage时的CPU利用率,如图20所示. Fig. 19 The results when R=1图19 R=1的性能评测 Fig. 20 The CPU utilization under different parallelism图20 不同并行度下的CPU利用率 Fig. 21 The results when R=128图21 R=128的性能评测 从图20可以看出,当并行度超过节点本身的CPU资源限制时CPU利用率较高,也会导致系统性能的下降.但是在实际的生产环境中,partition个数为1的场景并不常见,例如Taobao的负载[33],其job的平均Reduce个数为12,而Sailfish[20]使用Yahoo的负载,它的Reduce个数为1 024~65 536之间.因此我们以R=128为测试场景,其测试结果如图21所示. 从图21可以看出,由于增加了partition个数,能够在一定程度上缓解竞争所带来的性能开销,即在同一时间内,并不是所有的Task都往一个partition上写,如图22所示: Fig. 22 The Shared mode under different partitions图22 不同partition个数下的Shared模式 虽然通过增加partition的个数能够缓解锁竞争,但是从图22的测试结果看,Private模式的性能要优于Shared模式,并且在2.2.1节中描述了Shared模式在失效处理上的劣势,因此无论从性能还是错误处理的角度,Private模式都要优于Shared模式. 在2.3.2节中,我们了解到NV-Shuffle malloc对于不同粒度NV-Buffer的开销较小,并且我们修改了原先流程中对于NV-Buffer的分配机制(预先分配变为延迟分配),因此在本节中,一方面,我们需要观察不同粒度的NV-Buffer对于负载执行时间的影响;另一方面,延迟分配对于系统的影响. 1) 不同粒度的NV-Buffer对于执行时间的影响.在该实验中,我们使用不同粒度的NV-Buffer(4 KB,8 KB,16 KB,32 KB,64 KB)对Sort和Wordcount进行测试,其结果如图23所示: Fig. 23 The impact of the NV-Buffer size on job execution图23 NV-Buffer粒度对于作业执行的影响 图23展示了不同粒度对于作业的执行时间的影响,从图23中可以看出,随着分配粒度逐渐增大,执行时间存在小幅度的降低,但是整体上对于执行时间的影响不大,但是分配粒度的选取在一定程度上会影响空间利用率,因此我们将分配粒度的默认值设置为8 KB. 2) 延迟分配的影响.延迟分配可以避免为那些不存在数据的partition进行分配NV-Buffer,从而在一定程度上节省NVM空间资源.在第2.3节中,我们统计了不同Reduce个数下size=0的partition个数,如图8所示,即当Reduce个数越大时,其size=0的partition个数就越多,例如当Reduce个数为2 048时,平均每个Map Task中size=0的partition个数为419,相比于预先分配,延迟分配不会为这个419个partition分配NV-Buffer,从而在一定程度上节省了空间资源,那么与预先分配对比能够节省的空间资源大小,如式(3)所示: 节省的空间=M×P0×NV-Buffer, (3) 其中,M表示是Map Task的总个数,P0表示Map Task中size=0的partition的平均个数,NV-Buffer则是NV-Shuffle的分配粒度.上例中,通过延迟分配可以节省大约2.6 GB的NVM空间. 该部分主要评测NV-Shuffle的Shuffle数据恢复时间与传统Spark的Shuffle数据恢复时间.我们通过人工手动的方式在“一定的时间”kill集群中某一个节点上的Executor进程,从而观察作业最终完成的时间.其中“一定的时间”包含2个部分:1)在Map Stage阶段,以完成Map Task个数为准;2)在Reduce Stage阶段,以完成Reduce Task个数为准.在该实验中,我们使用2种较为简单的负载:Sort和Wordcount,其中Map Task的个数分别为800和2 048,Reduce Task的个数都设置为256.对于Spark,我们使用了tmpfs Hash的模式来存储Shuffle数据,从而与NV-Shuffle进行对比. 图24展示了在Map阶段的不同时机进行kill Executor时,Sort与Wordcount的执行时间.从图24中可以看出:1)NV-Shuffle的执行时间不受Executor被kill的影响,其主要原因在于由于NV-Shuffle对于NV-Buffer的管理和组织不依赖于Executor ID,因此不需要重新执行之前已经完成的Map Task;2)对于Spark而言,其对Map阶段产生的数据的组织与维护是与Executor ID相关的,因此当Executor被kill时,之前所生成的数据便无效,需要进行重计算,因此在Map阶段越晚进行kill Executor,重计算的Task越多,执行时间越长.图25展示了不同时机进行kill Executor时需要重计算的Task个数. Fig. 24 The execution time when executor is killed during Map Stage图24 在Map阶段不同类型负载在Executor被kill时的执行时间 Fig. 25 The number of recomputing tasks when executor is killed during Map Stage图25 在Map阶段Executor被kill之后重计算Task的个数 Fig. 26 The execution time when executor is killed during Reduce Stage图26 在Reduce阶段不同类型负载在Executor被kill时的执行时间 图26展示了在Reduce阶段的不同时机进行kill Executor时,Sort与Wordcount的执行时间.从图26可以看出: 1) NV-Shuffle的执行时间不受Executor被kill的影响,其主要原因在于由于NV-Shuffle对于NV-Buffer的管理和组织不依赖于Executor ID,因此当Executor被kill时,Reduce Task还是能够通过Driver找回数据进行拉取; 2) 当Executor被kill后,重启的Executor的ID已经发生改变,Reduce Task无法通过新的Executor ID去获取数据,Spark需要重新计算以产生相应的数据,因此比正常Sort和Wordcount的执行时间分别超出了约36.8%和27.3%; 3) 不同kill时机对NV-Shuffle和Spark的作业执行时间都没有产生影响:①NV-Shuffle由于不需要进行重计算就能够找回数据,因此无论何时Executor被kill都不会影响最终的执行时间;②对于Spark而言,kill集群中某个节点上的Executor,则它所生成的数据就要通过重计算重新获取,即所有在该节点上执行完成的Map Task都要重新执行一遍,鉴于当前数据均匀分布在集群上,则需要重新执行的Map Task的个数分别约为200(Sort)和512(Wordcount)(如图27所示).等Map Task都执行完成之后Reduce Stage则继续执行剩余没有完成的Reduce Task,因此不同的kill时机不会影响作业的执行时间,增加的时间只是重新执行Map Task的时间. Fig. 27 The number of recomputing tasks when executor is killed during Reduce Stage图27 在Reduce阶段Executor被kill之后重计算Task的个数 Shuffle阶段由于持久化所带来的IO开销可能大大延长数据处理的时间,NVM凭借其读写速度快、非易失性以及高密度性等诸多优点,为改变大数据处理过程中对持久化IO的依赖、克服目前基于内存计算的大数据处理中的IO性能瓶颈提供了新机会.鉴于上述2点,我们提出了NV-Shuffle,一种基于NVM的Shuffle优化策略.NV-Shuffle摒弃了以文件系统进行Shuffle数据存取的方式,而是采用持久化内存的方式,直接在用户态访问持久化内存,避免了传统存储系统中的冗长的 IO 路径带来的额外开销.为此我们利用pVM构建Java的持久化内存访问接口,并针对传统大数据平台中的Shuffle阶段,提出了基于NVM的Shuffle数据组织方式、NVM空间的分配策略以及NV-Buffer的组织管理方式.我们在Spark上实现了NV-Shuffle,并进行了详细的性能评测与分析.实验结果显示,对于Shuffle-heavy类型的负载,在用内存模拟的NVM上,相比于原始的Shuffle实现,NV-Shuffle可节省10%~40%的执行时间.而且,在有节点上的Executor失效的情况下,NV-Shuffle可节省时间的百分比根据失效时间点的不同而不同,具体表现为:在Map阶段,失效越晚,节省时间的百分比越大;在Reduce阶段,节省时间的百分比与失效时间点无关. [1]Micron. Micron sdram[EB/OL]. [2017-09-29]. https://www.micron.com/products/dram/sdram [2]AgigA Tech. Agigaram®ddr2 nvdimm[EB/OL]. [2017-09-29]. http://www.agigatech.com/ddr2.php [3]AgigA Tech. Agigaram®ddr3 nvdimm[EB/OL]. [2017-09-29]. http://www.agigatech.com/ddr3.php [4]AgigA Tech. Agigaram®ddr4 nvdimm[EB/OL]. [2017-09-29]. http://www.agigatech.com/ddr4.php [5]Intel. Intel-micron memory 3d xpoint[EB/OL]. [2017-09-29]. http://intel.ly/1eicr0a, [6]Guo Y, Rao J, Zhou X. ishuffle: Improving Hadoop performance with shuffle-on-write[C] //Proc of the 10th Int Conf on Autonomic Computing (ICAC). Berkeley, CA: USENIX, 2013: 107-117 [7]Rao S, Ramakrishnan R, Silberstein A, et al. Sailfish: A framework for large scale data processing[C] //Proc of the 3rd ACM Symp on Cloud Computing (SoCC). New York: ACM, 2012: 4-16 [8]Wang Y, Que X, Yu W, et al. Hadoop acceleration through network levitated merge[C] //Proc of the 2011 Int Conf for High Performance Computing, Networking, Storage and Analysis (SC). New York: ACM, 2011: 57-70 [9]Rahman M, Islam N S, Lu X, et al. High-performance RDMA-based design of Hadoop MapReduce over infiniband[C] //Proc of the 27th IEEE Int Parallel and Distributed Processing Symp Workshops and PhD Forum (IPDPSW). Piscataway, NJ: IEEE, 2013: 1908-1917 [10]Ruan X, Chen H. Improving shuffle I/O performance for big data processing using hybrid storage[C] //Proc of the 2017 Int Conf on Computing, Networking and Communications (ICNC). Piscataway, NJ: IEEE, 2017: 476-480 [11]Hong J, Li L, Han C, et al. Optimizing Hadoop framework for solid state drives[C] //Proc of the 2016 IEEE Int Congress on Big Data (BigData Congress). Piscataway, NJ: IEEE, 2016: 9-17 [12]Arulraj J, Pavlo A, Dulloor S R. Let’s talk about storage and recovery methods for non-volatile memory database systems[C] //Proc of the 2015 ACM SIGMOD Int Conf on Management of Data. New York: ACM, 2015: 707-722 [13]Coburn J, Caulfield A M, Akel A, et al. NV-heaps: Making persistent objects fast and safe with next-generation, non-volatile memories[C] //Proc of the 16th Int Conf on Architectural Support for Programming Languages and Operating Systems (ASPLOS XVI). New York: ACM, 2011: 105-118 [14]Dulloor S R, Kumar S, Keshavamurthy A, et al. System software for persistent memory[C] //Proc of the 9th European Conf on Computer Systems. New York: ACM, 2014: 15-26 [15]Volos H, Tack A J, Swift M M. Mnemosyne: Lightweight persistent memory[C] //Proc of the 16th Int Conf on Architectural Support for Programming Languages and Operating Systems (ASPLOS XVI). New York: ACM, 2011: 91-104 [16]TinyURL. Snappy compession[EB/OL]. [2017-09-29]. http://tinyurl.com/ku899co [17]Kannan S, Gavrilovska A, Schwan K. pVM: Persistent virtual memory for efficient capacity scaling and object storage[C] //Proc of the 11th European Conf on Computer Systems. New York: ACM, 2016: 1-14 [18]Rasmussen A, Conley M, Porter G, et al. Themis: An I/O-efficient MapReduce[C] //Proc of the 3rd ACM Symp on Cloud Computing (SoCC). New York: ACM, 2012: No.13 [19]Elmeleegy K, Olston C, Reed B. SpongeFiles: Mitigating data skew in MapReduce using distributed memory[C] //Proc of the 2014 ACM SIGMOD Int Conf on Management of Data. New York: ACM, 2014: 551-562 [20]Rao S, Ramakrishnan R, Silberstein A, et al. Sailfish: A framework for large scale data processing[C] //Proc of the 3rd ACM Symp on Cloud Computing (SoCC). New York: ACM, 2012: No.4 [21]Wang Y, Que X, Yu W, et al. Hadoop acceleration through network levitated merge[C] //Proc of the 2011 Int Conf for High Performance Computing, Networking, Storage and Analysis (SC). New York: ACM, 2011: 57-70 [22]Rahman M, Islam N S, Lu X, et al. High-performance RDMA-based design of Hadoop MapReduce over infiniband[C] //Proc of the 27th IEEE Int Parallel and Distributed Processing Symp Workshops and PhD Forum (IPDPSW). Piscataway, NJ: IEEE, 2013: 1908-1917 [23] RDMA. Introduction to Remote Direct Memory Access [EB/OL]. [2017-09-29]. http://www.rdmamojo.com/2014/03/31/remote-direct-memory-access-rdma [24]IBTA. Infiniband Trade Association[EB/OL]. [2017-09-29]. http://www.infinibandta.org [25]Condit J, Nightingale E B, Frost C, et al. Better I/O through byte-addressable, persistent memory[C] //Proc of the 22nd ACM SIGOPS Sym on Operating Systems Principles. New York: ACM, 2009: 133-146 [26]Wu X, Reddy A. SCMFS: A file system for storage class memory[C] //Proc of 2011 Int Conf for High Performance Computing, Networking, Storage and Analysis. New York: ACM, 2011: 39-51 [27]Dulloor S R, Kumar S, Keshavamurthy A, et al. System software for persistent memory[C] //Proc of the 9th European Conf on Computer Systems. New York: ACM, 2014: 15-26 [28]GitHub. PMemLibrary[EB/OL]. [2017-09-29]. https://github.com/pmem/linux-examples [29]Moraru I, Andersen D G, Kaminsky M, et al. Consistent, durable, and safe memory management for byte-addressable non-volatile main memory[C] //Proc of the 1st ACM SIGOPS Conf on Timely Results in Operating Systems. New York: ACM, 2013: 1-13 [30]Yang J, Wei Q, Chen C, et al. NV-tree: Reducing consistency cost for NVM-based single level systems[C] //Proc of the 13th USENIX Conf on File and Storage Technologies (FAST). Berkeley, CA: USENIX, 2015: 167-181 [31]Venkataraman S, Tolia N, Ranganathan P, et al. Consistent and durable data structures for non-volatile byte-addressable memory[C] //Proc of the 9th USENIX Conf on File and Storage Technologies (FAST). Berkeley, CA: USENIX, 2011: 61-75 [32]TPC. TPC BenchmarkTMH: Standard Specification, Revision 2.17.3[S]. San Francisco: TPC, 2017 [33]Ren Z, Xu X, Wan J, et al. Workload characterization on a production Hadoop cluster: A case study on Taobao [C] //Proc of 2012 IEEE Int Symp on Workload Characterization (IISWC). Piscataway, NJ: IEEE, 2012: 1-11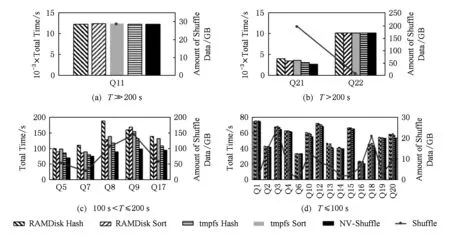
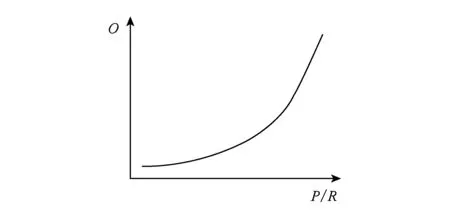
3.3 Shuffle数据的组织方式测试
3.4 NVM空间分配策略测试

3.5 失效恢复测试
4 总 结
