HASG: Security and Effcient Frame for Accessing Cloud Storage
2018-03-12ShenlingLiuChunyuanZhangYujiaoChenComputerSchoolNationalUniversityofDefenceTechnologyChangShaHuNan40073ChinaInformationCentreNationalUniversityofDefenceTechnologyChangShaHuNan40073China
Shenling Liu, Chunyuan Zhang, Yujiao Chen Computer School, National University of Defence Technology, ChangSha, HuNan 40073, China Information Centre, National University of Defence Technology, ChangSha, HuNan 40073, China
I. INTRODUCTION
Cloud computing, a large-scale distributed and virtual machine computing infrastructure,developed rapidly in last decade. Meanwhile,the increasing network bandwidth and reliable yetexible network connections make it even possible that clients can now subscribe high quality services of data and software that reside solely on remote data centers. Increased flexibility and budgetary savings driving companies to store data on Cloud storage for archiving, backup, and even primary storage of files[1,2]. With increasing of data on remote Servers, where the management of the data and services may not be fully trustworthy,user pay more attention on data security. Some Data leakage events, such as iCloud data interception, downtime of Amazon’s S3[3], aggravate the concerning to protect privacy stored on Cloud Storage.
To restore security assurances eroded by cloud environments, several basic approaches have been proposed to verifyle security,these methods can be divided into two categories according to the realization of the principle. 1) Security auditing based on identification, user delegates identity and data verication to a trusted audit platform to ensure data access and modification, third party auditors(TPA)[3~8] is the most widely used authentication scheme. Though these schemes can almost guarantee the simultaneous localization of data error, the data may be misappropriated by administrator of untrusted remote server.2) Implicit storage security to data in online,part of researcher present data encryption to guarantee data security and availability[9~14],reconstruction of the data usually requires more computational capabilities, meanwhile,data corruption and downtime of cloud server still cause inevitable data loss. File redundancy[15], which need mass more storage space,has raised to guarantee data availability.
Network speed fluctuation is another important factor affecting the use of cloud storage, to solve this problem, Cirtas, TwinStrata,Amazon and some other enterprise launches cloud storage gateway, which provides basic protocol conversion that makes incompatible technologies communicate with each other simply and makes cloud storage works as a local disk[16]. In addition, cloud storage gateway provides a certain size of cache, in which users can store frequently accessed data and accelerate cloud storage accessing. Though cloud storage gateway includes other features such as data compression, data encryption and de-duplication, data security and availability still based on cloud storage providers[17~19].
(1) HASG is a metadata and data separation architecture, which store fragmented data and metadata separately. Compared to third-party verification program, the user has more data Strong ability to control, only the data owner can get the meta-info and reinforces the ownership of the data.
(2) The security of cloud storage is enhanced by implicit storage in our design,le is divided into redundant partitions by File Fragment Algorithm and stored on different cloud storage, Compared with the existing encryption strategy, HASG presented in this paper enhances the data reliability and fault tolerance by redundant blocks and scatter storage. When a portion of cloud storage services cannot be accessed or part of blocks lost, as long as sufficient number of partitions are available, File Fragment Algorithm can be used to reconstruct originalle.
(3) We design a intelligence agent to deal with data transmission between gateway and cloud storage, the agent can dynamic select different could services according to current network speed.
(4) In this paper, We design a micro data updating algorithm. When small part of file modified, instead of replace all blocks, additional redundant partitions is used for storing data modification and reducing storage and bandwidth usage.
II. ARCHITECTURE
High Available cloud Storage Gateway(HASG) presented in this paper works as a proxy for hybrid cloud storage. It provided a set of uniform API, which is REST, for user to access data stored on various remote public cloud storage or private cloud storage. Additionally, HASG includes three main features such as data fragment, dynamic service provider selection and redundant block mechanism for file block updating. Meanwhile, the presented model possesses strong scalability that it can run as large scale webservice or local applications.
As the figure 1 shows, we design a distribute architecture of High Available cloud Storage Gateway, which comprise of Interface layer, Data Security processing Layer, Data Access layer and storage layer.
2.1 Interface layer
This layer is comprised of Data Access API for users and Application API for third part application. Unlike Traditional file storage access methods that use NFS (networkles system)or CIFS (Common Internet File System) [20],the kind of HASG’s interface that we designed is REST, we use URLs dening the resources and the format of the representations. For easing use, we implement Data Access API via HTTP protocol, meanwhile, Application API is designed via UDP protocol.
The API integrate various remote public cloud storage API and private cloud storage API, meanwhile, data users do not need connect to every remote server for data access,HASG API provide the interface managing remote data just as managing local data.
2.2 Data process layer
This layer is the key of HASG, the major objective of this layer is processing data stream and providing security content scheme. Data Security Processing layer has the following functional components.
a) Data Manage Queues: The message queue is a buffer of users’ requests, all file streams and operation orders come from storage API will push into the queue, it cooperate with Task Dispatcher and launch requests in order. In HASG, we divide requests into two parts: one part is the requests that store data on cloud, and the other part is the requests that fetch data from cloud. All incoming requests received through the interface are distinguished and cataloged. The storing requests are signed by the Meta-information of thele,the preorder storing request, which wait for executing, in the queue will be replaced by the new storing request which update the samele, this will decreasele operations on cloud.Fetching requests will be processed by Task Dispatcher directly and handled preferentially.
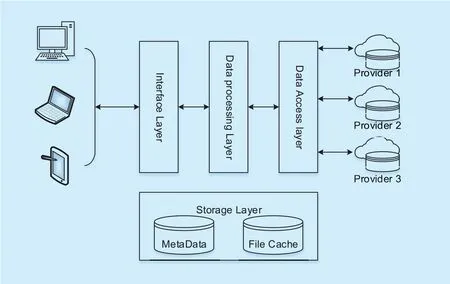
Fig. 1. Components of HASG.
b) Distribute Task Dispatcher: This component assigns a request to a Task Node based on type of operation and priority level for further processing. A Task Node, which includes a request processing logic, cooperates with Data Access layer, localle system, cache and virtual storage to handle given message. A Task Node runs as a thread, and it is deployed on distribute computing node. Every computing node contains several Task Nodes. We can adjust the number to improve the parallelism for performance. For different operation, there are two kinds of Task Node on cluster, one kind of Task Node is Fragment Task Node, which used to transformles into partitions and store on remote cloud server. Another kind of Task Node is Reconstruct Task Node, it used to fetch all partitions from cloud server and reconstructle by partitions.
Result Processor: We use a uniform data layout for presenting calculation of all Task Nodes. The result should be transformed to readable format for the end users and third part application. UDP Message transformle into UDP stream which can be read by third part application. HTTP message processor generates page or makes a further forwarding for the end users.
Data process layer provides a complete data fragmentation and data reconstruction model,providing a basis for remote secure storage of data. It is stateless, the metadata in data processing is stored in the Storage layer.
2.3 Storage layer
This component consist of NoSQL database and File Cache. A NoSQL database provides a mechanism for storage and retrieval of Meta-Info that is modeled in means other than the tabular relations used in relational databases,Meta-Info is the key of data storage, it contains the relationship between file partitions and cloud server. File Cache utilize Localle system to set up a buffer for files that read most frequently.
The Storage layer is based on scalable and lightweight storage service, so it has aexible deployment approach that can be deployed in user-specified security zones, such as trusted security servers, or even local storage. This security strategy will give user the highest priority of data possession. No one else but user himself can get or share his data.
2.4 Data Access layer
This layer is in charge of connection between HASG and remote cloud servers, and it is responsible for auto-selecting best available server for storage. This layer contains functional components as follow:
a) Cloud Storage Register: Register Agent is a catalog of cloud server which used by platform. Each cloud, which user want to store data on, has to register in Cloud Storage Register with whole cloud information include IP,user name and password by users.
b) Cloud Storage Monitor: This component connect to every cloud server, which has been register, to test if it is available and detective the bandwidth. When storing or fetching data from cloud server, it will choose the optimum provider automatically.
c) Cloud Storage API: The main objective is calling services of various cloud storage. It is designed as a plug-in components, all interface of cloud which register on HASG are implemented as a plug-in. It is easy to support new cloud by implementing its interface.
III. KERNEL ALGORITHM AND IMPLEMENTATION
In Section 2 we presented the detailed design of each component, as described before, Data process layer and Data Access layer are nucleus modules. This section we discuss the design specication of these modules.
3.1 Information Dispersal Algorithm
Information Dispersal Algorithm (IDA), a sort of Secret sharing technologies, proposed by Michael O. Rabin in 1989, is a communication protocol that uses redundancy to achieve both timeliness and reliability.
The (n, m) Information Dispersal Algorithm’s principle is converting a digital source into n small digital files (shadows), and the receipt of any m out of the n shadows can losslessly reconstruct the source Data[21~22].
3.2 FFA (File Fragment Algorithm)
In our design, implicit storage is certain strategy to protect cloud storage against known malicious programs that could have hacker to steal personal information. This section we discuss the principle and implement of FFA,an efcient algorithm based on IDA, and explain how it improve security and availability of cloud storage.
There are two kind of file operations in FFA, one part we called itle encoding, and anotherle decoding.
1)File encoding: We assume for convenience that platform supply a set of systematic code (n, m) which is free to choose by user,the user specied code (n, m) would be the parameters of the dispersal code.
Two of this number are round number, and the relationship of them is1<m<n.The variablenstand for the number ofle fragments,which is partitioned by the original file F.Another variablemis lowest effective number of reconstruction, it means if the number of damaged file fragments less thank(k=n-m),we can recover the originalle.
The first step of transform of the file F is partition it into distinct blocks and convert the originalle to a matrix.
A graphical representation of transforming fromle to matrix shows ingure 2.
Secondly, we construct a Vandermonde Matrix A(n*m), and rank


In result matrix R
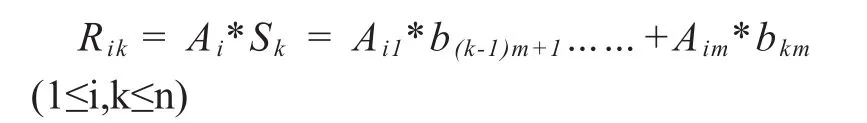
We combine one row of matrix R as a dispersal encoding partitions, which total number is n, each partition can be write as
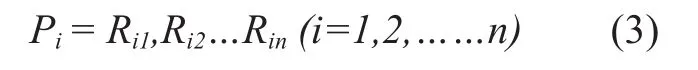
2)File decoding: Firstly, we fetch file partitions from remote cloud server fromP1toPnpiece by piece, characteristic value is used to verify data integrity of every partition. The fragment which is verified we called itP’iaccording to priority, then we get a set of partitions R’.
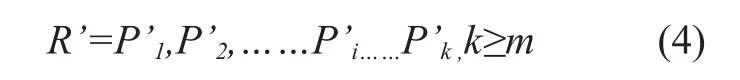
Ifk≥m,thele is resumable, we sequentially select m pieces from R’, we call it R’m

A s Equation 5 repr esents,P’jis the multiple of correspo nding row of A(n*m)and S(m*n),for everyP’j (1≤j≤m),we take the corresponding row from A(n*m)and compose a new matrix A’(m*m).It’s easy to get Equation bellow from Equation 2.
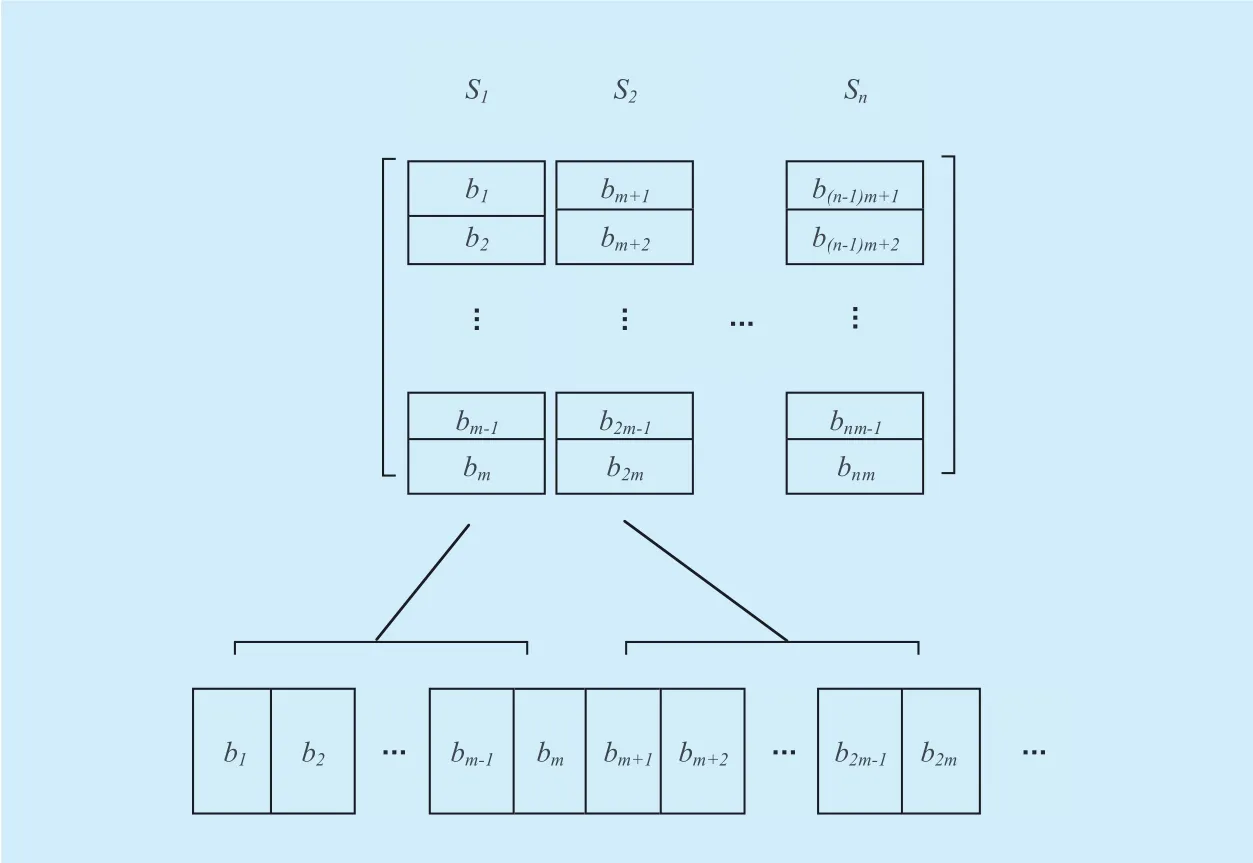
Fig. 2. Original le F represented as a matrix.

Because rank of A is m (Equation 1), A’(m*m)is a square Vandermonde matrix, which is invertible, we obtain our main result
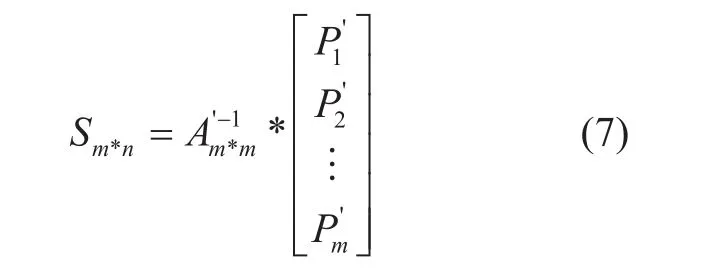
As mentioned above,Sm*nis a kind of anther represent of originalle F, So we reconstruct the originalle formmpieces of partitions.
By means of the dispersal code, file is transformed into cryptographic block before storing on multi clouds, which prevent private data from misusing by malicious administrator and stealing by hackers.
With this scheme, it is possible to use cross-server redundancy to guarantee integrity of F. Contrast to duplicate method, it reduce the overall storage cost fromn|F | to (n/m)|F |.
3.3 Dynamic service provider selection
1)Data storing: As presented in section 2,Data Access layer comprise Cloud Storage Monitor which detect transmission speed periodically. Suppose the number of registered provider isK, define transmission speed of providerPiisSi(1≤i≤k).Parameters in FFA is(N, M),Nis the total number of partitions,Mis the lowest number of valid fragments for reconstruction.
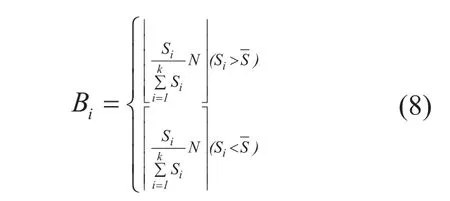
Instead of randomly allocating data slices to various remote cloud server,Biis proportional to speed of each server. For ensuringle blocks are distributed on different servers,Biis rounding up when speed below average.
2)Data downloading: According to FFA, at least M blocks are essential to rebuild originalle, suppose the current speed of providerPiWe definepresented in Formula ,expresses the number of blocks should be downloaded from corresponding storage provider.
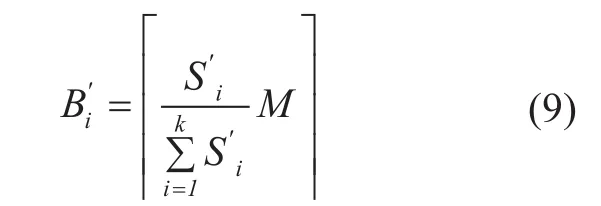
When network speed fluctuation dramatically, there may appear a contradict thatwhenthis means providerPidid not maintain enoughle blocks for downloading.If this problem appears, we use the following algorithm to correct the results. BecauseM<N,there must exit aggregate j (1<j<k,j≠i) thatexpandfrom high to low according to
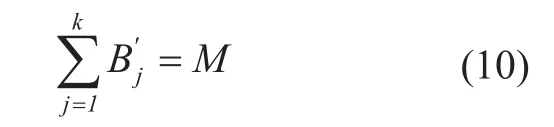
Then we obtain parametersBj’(1<j<k) to download the file blocks and reform originalle.
3.4 Redundant block mechanism forle updating
As described in 3.1, assume the parameter of FFA is (n,m). Originalle can be represented as a matrixS=(S1,S2,S3...Sn), actual data block stored on cloud server isR=(R1,R2,R3...Rn),relationships ofRandScan be expressed asR=A(n*m)*S.
When part of blocks of S is altered, we useS’to represent Modied data,S’=(S1,S2,..Si’...Sn),Si’is dirty data block. According to computational formula,the new dispersal resultR’can be represented as Formula
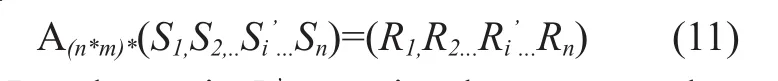
Result matrixR’comprise the same number and position of dirty blocks. If number of dirty blocksbmeet the conditionsb≤n-m, instead of replacing all blocks, an additional blockstored. When reforming the originalle,rst downloadRand then replacewith thenmodiedS’can be reconstruct by FFA. If specic block modify frequently, storing the last blockimprove the efciency of the algorithm.
This solution conduct network band cost signicantly, the data transfer quantity reduces frommoreover,has the same security as the original storage blocks.
IV. IMPLEMENTATION AND EXPERIMENTAL RESULTS
Previous sections present the detailed design of kernel algorithms, this section we discuss the implement specification and performance of our prototype.
4.1 Implementation
In order to implement a scalable, robust and distributed platform, HASG is developed as a standard Three-layered services application based on Java EE, We apply open source framework to facilitate the implementation[23~24].
Interface Layer is implement as presentation layer, we use JSP to develop man machine interface which gather and respond to user actions.
In implement of Data process layer, we implement a FIFO queue to guarantee that all instructions are executed in sequence. Distribute Task Dispatcher and Task executer are implemented based on Taobao Fourinone (a 4-in-1 distributed framework and easy-to-use programming API to use CPU, memory, hard drives of multi-machine together). For local storage, we use NoSQL database MangoDB, a cross-platform document-oriented database, to store meta-Info and user conguration.
Data Access layer is designed as a data access framework adopting a plug-in system of open platform. Each implement of cloud storage’s interface is developed as a plug-in.
4.2 Experimental Results
In this section, the performance of data access in our prototype is evaluated experimentally.
HASG is deployed as service on a machine with Quad-core Intel Core i7 CPU running at 2.3 GHz and 16 GB of RAM, the operation system of that is Win 10 and bandwidth is 20M, instead of deploying Task Node on cluster, we deploy it on same machine and make distribute platform running in local pattern.
Table I. Time cost of different type le storing.
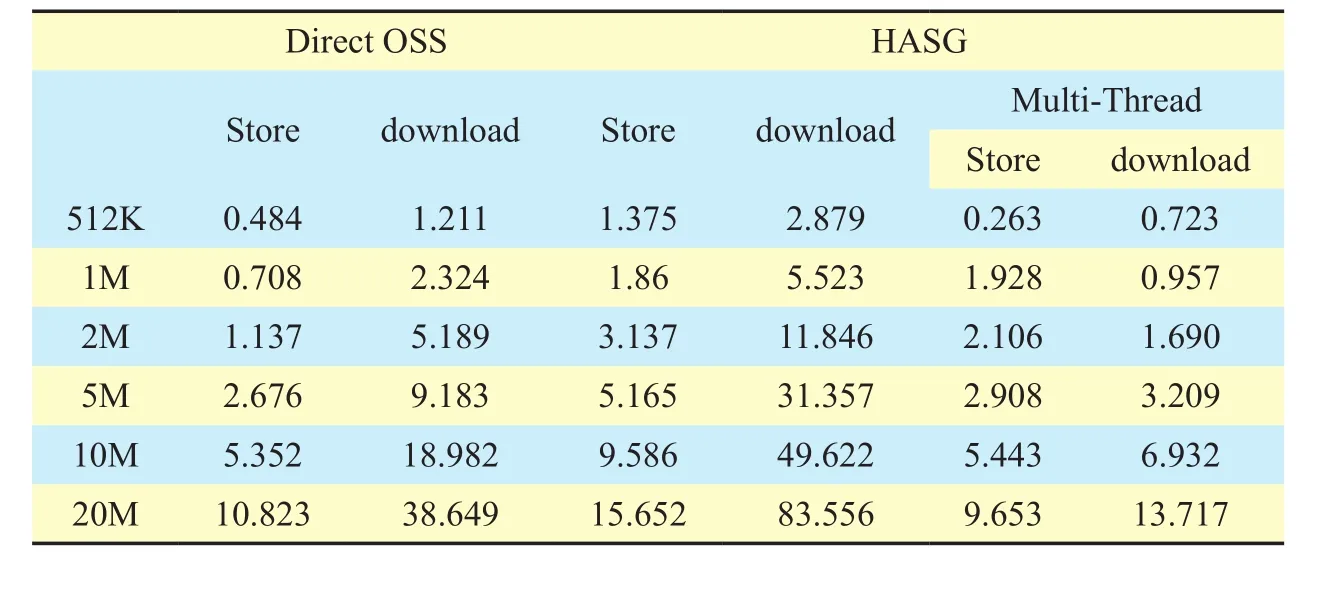
Table I. Time cost of different type le storing.
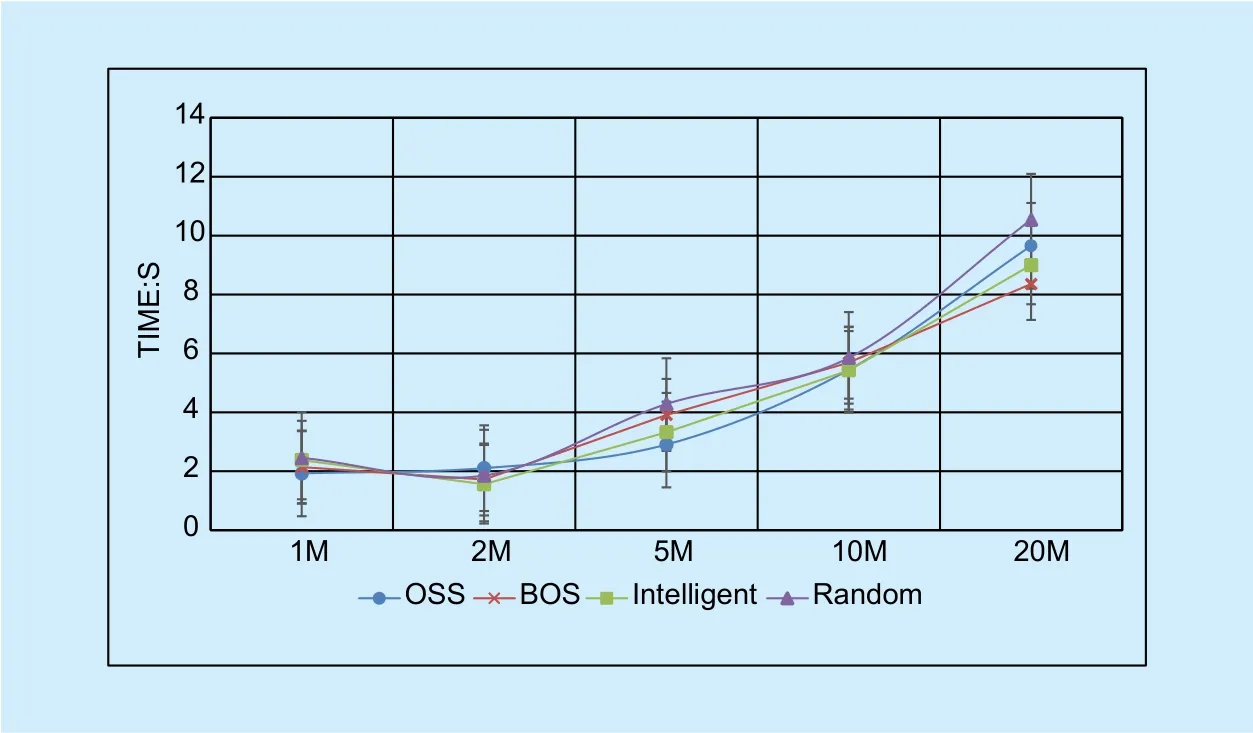
Fig. 3. Time cost of different service selection strategies.
In our experiment scenario, Three commonly used cloud storage, OSS (Alibaba Object Storage Service) , COS (Tencent Cloud Object Service) and BOS (Baidu Object Service), are connected as service providers. This paper focuses on the security of document data in cloud storage environments, such as research materials, papers, pictures, etc., users usually pay more attention about the storage security of such data, which size does not exceed 20M according to experience, so the size of the experimental objects in this article is also selected by practical experience. Universal privateles, such as documents, pictures and so on, are divided into six types by size, and generate simulation file for each type of file to perform this experiment. Then we perform benchmarking of HASG to test its storing and downloading efciency.
Table 1 presents the time cost of storing and downloadingles through different methods. The top two columns shows performance ofle storing by using OSS API directly, the handling speed of storing is stable at 2M/s,meanwhile, the speed of downloading is nearly 517K/s. When we stored files by using HASG,speed of storing and downloading decreased, the main reason for performance degradation is that HASG store and fetchle partitions one by one in a single-threaded,each procedure need authentication on remote cloud.
We ameliorate the prototype using multithread to parallel process file partitions storing and downloading, with this scheme,the performance of HASG has been greatly improved. The speed of storing and downloading increase to 2.2M/s and 1.4M/s. Contrast to calling OSS API directly, using improved HASG to storing files is more efficient, the main reason of this phenomenon is that multithreads can maximize the utilization of bandwidth.
Figure 3 shows the time cost of four kinds of service selection strategies. Compared to storing data blocks on fixed cloud storage or randomly selected cloud storage, intelligent selection strategy provided by HASG avoid network speed fluctuation effectively, the transmission speed is stable in the vicinity of the fastest speed. The curve has manifest HASG is one of ideal methods to improve the performance of multiple cloud storage.
The performance of original HASG and upgrade HASG with redundant block in data accessing is presented in Figure 4. As the picture shows, adopting redundant block technique can accelerate the data modication dramatically, on the other side,le reconstruction cost more time for additionalle blocks and computation.
V. CONCLUSION
We have present a new architecture of security,efcient distribute cloud storage gateway. The scheme provide a uniform storage interface for end users and third party applications to visit public and private cloud storage service. The method makes full use of the Information Dispersal Algorithm to designle fragment algorithm, which is used forle encoding and decoding. Not only didle dispersal signicantly improve the data security in cloud storage environment, but also did it offer a data recovery method by file partitions redundancy, it cost less storage space and internet bandwidth to solve Single Point of Failures and data faults thanle duplication. Moreover, to enhance the data reliability and accelerate data accessing,We design Dynamic service provider selection and Redundant block mechanism for network fluctuation. As illustrate by experiment results of prototype, HASG achieves the design objectives, meanwhile, file partition storage can improve traditional cloud storage access efficiency. The result shows that we propose a simple, efficient scheme to cloud storage.Next, we will conduct more experiments of HASG and constantly improve the application prototype, let HASG become the best choice for using cloud storage.
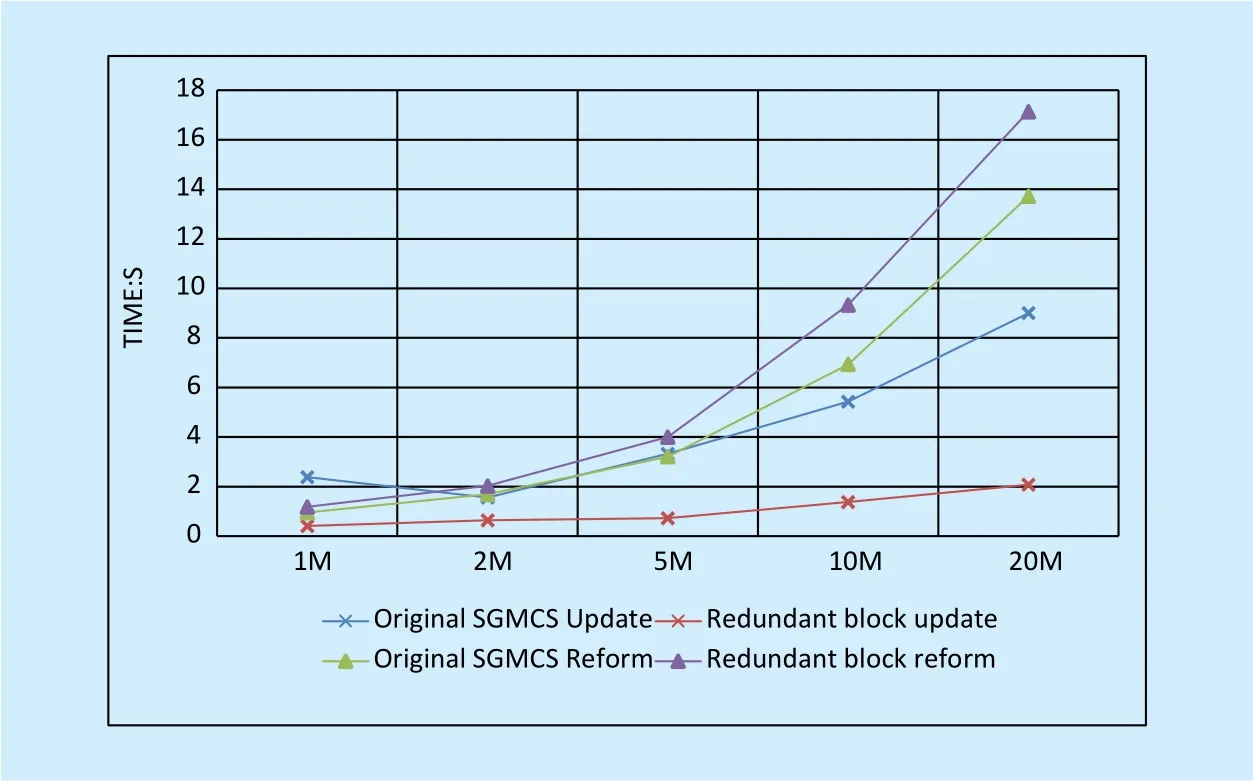
Fig. 4. Performance of different data updating strategies.
[1] Godhankar, Pradnya B, and D. Gupta, “Review of Cloud Storage Security and Cloud Computing Challenges,”International Journal of Computer Science & Information Technolo.vol. 5, no. 1,2014, pp. 528-533.
[2] Vrable M D, “Migrating Enterprise Storage Applications to the Cloud,”Dissertations & Theses- Gradworks, vol. 12, no. 5, 2011, pp. 507-584.
[3] Wang Q, Wang C, Ren K, et al, “Enabling Public Auditability and Data Dynamics for Storage Security in Cloud Computing,”IEEE Transactions on Parallel & Distributed Systems, vol. 22, no. 5,2010, pp. 847-859.
[4] Trupti V. Junghare, M.Tech Student, “Enhancing Data Dynamic Security & Trust for Cloud Computing Storage System,”International Journal on Recent and Innovation Trends in Computing and Communication, vol. 7, 2014, pp. 1851 – 1854
[5] Yuchuan, Shaojing, Ming, et al, “Enable Data Dynamics for Algebraic Signatures Based Remote Data Possession Checking in the Cloud Storage,”Communications China, vol. 11, no.11, 2014, pp. 114-124.
[6] Song N, Sun Y, “The cloud storage ciphertext retrieval scheme based on ORAM,”Communications China, vol. 11, no. S2, 2014, pp. 156-165.
[7] Tiwari, D, and G. R, Gangadharan. “A novel secure cloud storage architecture combining proof of retrievability and revocation,”International Conference on Advances in Computing,Communications and Informatics IEEE, 2015, pp.438-445..
[8] Talib A M, Atan R, Abdullah R, et al, “Towards a Comprehensive Security Framework of Cloud Data Storage Based on Multi-Agent System Architecture,”Journal of Information Security, vol.03, no. 4, 2012, pp. 175-186.
[9] W. Feng, Y. Wang, N. Ge, J. Lu, and J. Zhang,“Virtual MIMO in multi-cell distributed antenna systems: coordinated transmissions with large-scale CSIT,”IEEE Journal on Selected Areas in Communications, vol. 31, no. 10, 2013, pp.2067-2081.
[10] Zhang, Jing, S. Li, and X. Liao, “REDU: reducing redundancy and duplication for multi-failure recovery in erasure-coded storages,”Journal of Supercomputing, vol. 72, no. 9, 2015, pp. 1-16.
[11] Li X, Li J, Huang F, “A secure cloud storage system supporting privacy-preserving fuzzy deduplication,”Soft Computing,vol. 20, no. 4, 2016,pp. 1437-1448.
[12] Bestavros A, “An Adaptive Information Dispersal Algorithm For Time-Critical Reliable Communication,”Network Management and Control.1997, pp. 423-438.
[13] Oh K, Chandra A, Weissman J, “Wiera: Towards Flexible Multi-Tiered Geo-Distributed Cloud Storage Instances,”The ACM International Symposium.2016, pp. 156-176.
[14] Parakh A, Kak S, “Online data storage using implicit security,”Information Sciences,vol. 179, no.19, 2009, pp. 3323-3331.
[15] Zhang, Jing, S. Li, and X. Liao, “REDU: reducing redundancy and duplication for multi-failure recovery in erasure-coded storages,”Journal of Supercomputing,vol. 72, no. 9, 2015, pp. 1-16.
[16] Gary Orenstein, “Show Me the Gateway — Taking Storage to the Cloud,” 2010, https://gigaom.com/2010/06/22/show-me-the-gateway-taking-storage-to-the-cloud/.
[17] Lin S J, Chung W H. “An Effcient (n, k) Information Dispersal Algorithm for High Code Rate System over Fermat Fields,”IEEE Communications Letters, vol. 16, no. 12, 2012, pp. 2036-2039.
[18] Spoorthy V, Mamatha M, Kumar B S, “A Survey on Data Storage and Security in Cloud Computing,”International Journal of Computer Science& Mobile Computing, vol. 3, no. 6, 2014.
[19] Li L, Li D, Su Z, et al, “Performance Analysis and Framework Optimization of Open Source Cloud Storage System,”China Communications, vol.13, no. 6, 2016, pp. 110-122.
[20] Gonçalves, Glauber D., et al, "Workload models and performance evaluation of cloud storage services,"Computer Networks, vol. 109, 2016,pp. 183-199.
[21] Bestavros, Azer, “An Adaptive Information Dispersal Algorithm for Time-Critical Reliable Communication,”Network Management and Control,1994, pp. 423-438.
[22] Lin S J, Chung W H, “An Effcient (n, k) Information Dispersal Algorithm for High Code Rate System over Fermat Fields,”IEEE Communications Letters, vol. 16, no. 12, 2012, pp. 2036-2039.
[23] Bowers, Kevin D., A. Juels, and A. Oprea., “HAIL:a high-availability and integrity layer for cloud storage,”Proceedings of the 16th ACM Conference on Computer and Communications Security,2010, pp. 187-198.
[24] RT Fielding,RN Taylor, “Principled Design of the ModernWeb Architecture,”International Conference on Software Engineering, 2000, pp.407-416.
杂志排行

China Communications的其它文章
- Smart Caching for QoS-Guaranteed Device-to-Device Content Delivery
- An SDN-Based Publish/Subscribe-Enabled Communication Platform for IoT Services
- Energy Effcient Modelling of a Network
- Probabilistic Model Checking-Based Survivability Analysis in Vehicle-to-Vehicle Networks
- A Survey of Multimedia Big Data
- CAICT Symposium on ICT In-Depth Observation Report and White Paper Release Announcing “Ten Development Trends of ICT Industry for 2018-2020”