从数据到表征:人类认知对人工智能的启发*
2018-03-09徐昊骙周吉帆沈模卫
唐 宁 安 玮 徐昊骙 周吉帆 高 涛 沈模卫
(浙江大学心理与行为科学系,杭州 310028)
自AlphaGo在2016年3月以4∶1的比分击败围棋大师李世石以来,人工智能的发展获得了空前广泛的关注。作为哲学、数学、心理学、神经科学和计算机科学等学科的交叉领域,人工智能虽已取得了令人瞩目的进步,但与通用智能的目标还相距甚远。在关于实现何种智能体,以及如何实现它等核心问题上,研究者们尚存较大分歧。如果无法解决这些关乎人工智能发展方向的问题,那么其进程仍将举步维艰。
在2017年12月初刚结束的人工智能领域重要会议——神经信息处理系统大会(Conference and Workshop on Neural Information Processing Systems,简称NIPS)上,一场有关实现智能的途径的专题讨论(Symposium:Kinds of Intelligence)颇为引人关注(机器之心,2017)。其间Deepmind的首席执行官Hassabis介绍了最近大放异彩的棋类竞赛程序AlphaZero。借助深度学习和强化学习技术,AlphaZero在不利用任何人类已有棋谱的条件下,通过大量的自我对弈,在国际象棋、围棋和将棋竞赛中均完胜人类和其他棋类程序。AlphaZero那从零开始学习从而形成的强大能力令人赞叹,许多与会者觉得它距通用人工智能的目标又前进了一步,然而Tenenbaum、Marcus和Gopnik等学者却对此提出了不同见解。Tenenbaum认为智能并不仅是利用一些确定的公式或程序进行计算,还应该包括实现自身对世界的理解,并有能力为完成目标提出和解决问题。构造这样的智能系统,首先需要建立一个具备常识的“智慧”核心。该核心并不像AlphaZero那样需要大量的学习,便可“直觉”地理解世界的运作模式。Marus则指出AlphaZero只适用于“完美信息”的博弈,不具备通用智能。因为棋局可以“完美地”进行模拟,而现实生活却充满了不确定性;棋局可以通过海量数据的学习或训练找到最优解,而现实中的每个事件通常难以获取大量的重复样本。因此实现与开放世界的有效交互,先验的算法和知识是必备的,这也是AlphaZero难以应对现实世界的关键所在。此外,他还指出,就AlphaZero本身而言,也并非完全的“零知识”,即它在自我博弈时所用到的蒙特卡洛树搜索方法就源于人类认知研究的启发。
“人工智能是否需要与生俱来的认知能力”是这场专题讨论中所关注的关键问题之一。该问题在2017年10月纽约大学的研讨中曾进行过深入探讨(IEEE spectrum,2017)。LeCun和Marcus的观点分别代表了当前开发人工智能系统的两种取向。LeCun认为,现代人工智能系统在很大程度上并不需要对这个世界的运作原理建立假设和结构化概念。他倾向于最小化人工智能算法的结构,以保留算法的简单性,追求尽量减少“先天”(innate)机制的成分,强调利用可以获得的数据完成学习。Marcus则基于自己和Spelke等人的研究成果,指出儿童在早期就可以利用结构化的表征和算法处理对象、集合、位置以及时空连续性等概念。他认为现代人工智能系统不应该只是基于输入信息的基本单元(例如图像识别中图片的像素矩阵)进行处理,而需要借助人类认知的研究成果,加入更加丰富的结构化元素和表征,以及对应的算法,从而更好地理解外部世界。
这次争论演化出两个具体问题:其一为智能体的学习是借助了部分先天的机制还是纯粹源自后天的经验?其二是如果存在先天的认知成分,其表现形式是什么?以深度学习为代表的当下热门人工智能技术似乎并不支持“先天”假设。深度学习用简单统一的方法,借助计算能力和计算资源的迅猛发展,可以在诸多任务的绩效上逼近乃至超过人类。然而,在虚拟的数字世界里,需要成百上千万次的失败经验才能让智能系统学会一项技能;在现实生活中,人往往并不需要无数次滚下山坡就能掌握如何在陡峭的山岗上行走。二者对数据量和训练时间的需求相去甚远。使人工智能系统像人一样具备小样本学习的能力,是实现通用人工智能系统的重要环节。因此从人类的认知研究中探寻小样本学习的机制,可能是推进通用人工智能系统的希望所在。
1 从“大数据、小任务”到“小数据、大任务”
在“大数据”的驱动下,人工智能系统可以通过海量数据的训练,在特定的任务上超过人类专家,其特点可以概括为“大数据、小任务”。然而,人类的“智能”是在适应和理解复杂多变的物理和社会环境的过程中进化而来,并非只适用于解决具有明确规则的任务或游戏。“强认知”的观点认为,当今的人工智能系统尚未超过3岁儿童的智能水平(周吉帆等,2016)。例如常年漫雪的阿尔卑斯山和四季如春的武夷山其外观相去甚远,儿童无需太多的学习就能知晓前者是山,后者也是山,并将两者归为一类。尽管人们所面对的是一个形态各异且变化无常的外界环境,但只需要少量的数据样本,便可快速地提取知识,理解世界并做出判断或行为。而且,人们在一个任务情景中学到的知识或经验可迁移到不同的任务情境中。快速学习和灵活迁移正是人类智能的重要特点,可以被概括为“小数据、大任务”。
数据量与学习间的关系似乎是在“大数据”时代出现的新问题,实际上,对该问题的争辩可一直追溯到2000多年前的古希腊。柏拉图在《理想国》第七卷中指出,在数学家们所构建的几何体系中,他们将完美的几何图形(如正三角形、正方形等)的存在作为无须证明的假设,并以此为基点推论出相关的几何定理。然而,在那个没有计算机和精密机械的年代,世界上几乎不存在完美的几何图形——数学家头脑中的完美图形是如何在没有数据或经验的条件下被构想出来的?柏拉图在《美诺篇(Meno)》中,对这一问题做了具体的阐述。他描述了一个从未受过教育的奴隶男孩,经苏格拉底的数个简单问题的启发,如何快速地学得几何知识,即将正方形的对角线替换其边长,能使其面积增大一倍。这便成了揭示人类从少量数据中获取丰富知识的经典案例。柏拉图认为,这种知识与数据鸿沟的弥合在于奴隶男孩的“有知”状态,即在面对该几何问题的最初时刻,他并非一无所知,而是已经将正确答案锁定在了很小的范围内。此时只需少量的数据或他人的启发即可完成任务。
在过去30年中,发展心理学的研究为柏拉图的“先天论”提供了大量的证据,例如出生仅仅几个月的婴儿就具备丰富的物理知识和社会知识(Onishi & Baillargeon,2005;Hamlin,Wynn,& Bloom,2007;Gweon et al.,2010;Stahl & Feigenson,2015;Leonard,Lee,& Schulz,2017)。这些与生俱来的知识是后天学习的基础,通常被称为“核心知识”(core knowledge,Spelke & Kinzler,2007)。本文基于存在先天核心知识的观点,进一步探讨了人类“知识表征”的特点如何适应“小数据、大任务”的学习。
2 良好知识表征的特性
从认知计算的观点出发,对存在于一个集合中正确答案的搜索过程一直是认知心理学与人工智能领域的研究焦点。知识可以看作是对外界属性、规律的一个论断或假设。所有可能的假设所构成的集合被称为假设空间。学习可以描述为在这个假设空间中搜索到最优假设的过程。这个搜索过程可能同时受后天的数据(或经验)和先天的知识的影响。“知识表征”的重要性在于它的形式会直接影响假设空间的涵盖范围、复杂程度和搜索效率。
假设空间的涵盖范围取决于知识表征的形式。所有计算模型只能在其所采用的表征形式允许的范围内寻找答案。例如,一元线性回归模型是不能拟合二次曲线的。因为该模型的表征为“斜率”和“截距”,无法表达“曲线”特征。良好的表征应该涵盖广大的范围,并包容各种合理的假设。如果涵盖范围过窄,模型则会过于“天真”,无法解释复杂的情景。例如幼儿倾向于用“非黑即白”的简单二分方式去理解世界。这样的表征虽然易于操作,但不适用于表达现实世界的复杂性。钱钟书在《读伊索寓言》一文中,直言幼儿不应读寓言,因为寓言会强化幼儿对世界简单、极端的认知。
假设空间的复杂程度也与其表征形式直接相关。为了扩大涵盖范围,最直接的方式是逐条列举所有可能的假设。这种方式过于“暴力”,可能造成假设空间的混乱和无序。就像人们在一个缺乏组织和索引的图书馆中难以找到确实存在其中的所需的书籍。良好的表征形式能够在保持假设空间涵盖范围的前提下,化繁为简。假设空间的简单有序性使得小数据学习成为可能。在自然科学史上,这样的例子不胜枚举。元素周期表便是一个典型的案例。在门捷列夫之前,化学家对大量的实验结果无法进行有效的归纳总结。而门捷列夫的周期表,可以看作是一个以“周期律”为基础的精巧的知识表征。它用一个很小的假设空间涵盖了所有元素可能的属性。后人利用元素周期表成功预测了几种未被发现的元素的属性,这可作为“零数据”学习的例子。
表征形式直接影响了对假设空间的搜索效率。任何一种表征都不能无条件、无限制地应对所有情景。对某类数据的高效加工必然是以对非该类数据的低效加工为代价的,这被称为“无免费午餐”理论(Wolpert & Macready,1997)。因此,构建高效表征的核心在于尽量提高对普遍的、出现概率高的数据的加工效率,其代价是牺牲对特殊的、概率低的数据的加工效率。这与信息论中“最优编码长度”(optimal coding length)原理相一致:为了将编码的平均长度降到最低,应将短编码赋予高频信息,同时将长编码赋予低频信息。可见,良好的知识表征应该如实地反应数据在真实世界中的分布,即更好地表达、描述真实世界中的普遍、高频数据,以实现主观世界与客观世界的统一。
3 层级树表征
“层级树”作为一种可以支持“小数据”学习的人类知识表征,笔者将在下文中加以简要介绍。层级树(见图1)起始于一个根节点(root node),用以表示一个整体。该整体可以分解为一些小的组件,每个小的组件分别用根节点下的一个子节点表示。表征中任意非终止节点所表示的组件,可继续分解为其下属的多个子节点所表示的子组件,直至分解为由终止节点代表的最小基元。在通过运用“组合-分解”原则递归形成的多层级结构表征中,少量的要素可以产生大量的对象。
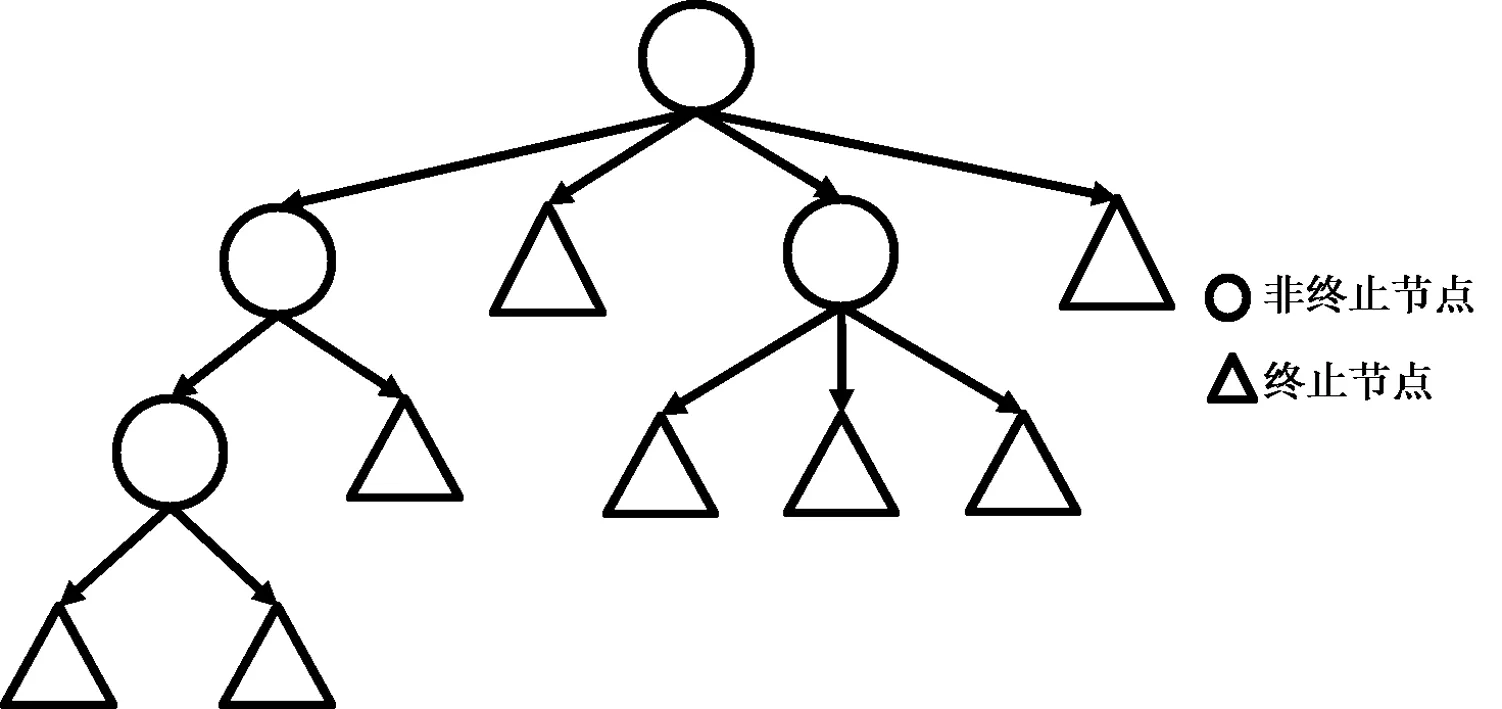
图1 层级结构表征形式的示意图
层级树的核心在于通过迭代(或递归),将“有限的组件”在“有限的规则”下层层组装,用以表达无限的知识。有限组件与层层迭代解决了“涵盖广”与“空间小”的两难问题。由于层级的作用,一个大而复杂的问题被转化为一系列小而简单的问题,从而加快了正确假设的搜索速度。
此外,层级树结构还具备以下优点:
(1)提高认知资源的使用效率。在层级树中,由于多个“子节点”共享同一个“父节点”,因此子节点的共有特征只需在上一层的父节点上做一次性表达即可。这对有限认知资源的高效利用至关重要。例如,我们最近的一项工作探索了对多客体运动的记忆和预测(Xu et al.,2017)。结果发现,当多客体的运动方向存在层级共享时,人的绩效会显著提升。
(2)表达了同一事物在不同层级的抽象程度。在层级树中,沿层级下降,表征的具体性增加;沿层级上升,表征的抽象性提高。人会根据具体的任务要求,灵活地在不同抽象层级间进行切换。例如,在观察他人的协调运动时,人可熟练地在团体、个人和身体局部三个层面提取关键信息(Ding,Gao,& Shen,2017)。对事物的“恰当抽象”有助于利用旧知识解决新问题,即实现“迁移学习”。这也是人类“比喻”“类推”能力的基础。诸多社会交往的概念是由物理世界中客体交互的概念迁移而来。例如,物理客体间的相互作用力包括“吸引力”“排斥力”等。这些物理概念也通常应用于描述人际关系(Talmy,1988)(如“他对我的吸引力很大”等)。
(3)表达了对象间的因果关系。层级树的上下层间存在“因”和“果”的关系,即上层节点的属性决定了下层节点的属性。对层级树的逐级展开过程,即为以表征为蓝图“产生”数据的因果过程。大量认知心理学的研究表明,提取因果关系是人类认知的核心特征之一(Sperber,Premack,&Premack,1995)。这与统计学所强调的“数据相关不代表因果”形成鲜明对比。在《因果》一书中,Judea Pearl系统论证了从数据中提取因果关系的数学基础(Judea Pearl,2009),并因此获得2011年图灵奖。对人类层级树表征的研究,可促进构建具备“因果”推理能力的人工智能系统。
4 语言的层级树表征
在认知科学中,层级树表征的概念最早被心理语言学领域采用,并应用于大量的研究中。语言文字作为随着文明发展而来的人类特有产物,其各类组件间存在着明显的层级关系:从最基本的笔画开始,不断组合以形成字、词、句、段落、文章等。例如,横、竖、撇、捺、勾5种笔画便可组合出约50000种的中文字符。这种现象也存在于包括希腊语、拉丁语等在内的其他语种(Lake,Salakhutdinov,& Tenenbaum,2015)。
词作为与意义直接相关的最小语料,可以通过语法组成句子,以表达一个完整的含义,包括陈述一个事实、提出一个疑问等。句子的理解,是人类智能通过符号获取知识中最为关键的部分。然而人对语言的理解同样需要解答西方哲学中的柏拉图之问:为什么人类在较少直接语言经验的条件下,能够快速地掌握语言的使用?乔姆斯基(Chomsky,1986)借此提出了“刺激贫乏”(poverty of stimulus)的语言学术语,用于指涉“极其贫乏的语言环境”与“极其具体和复杂的语言知识系统”之间存在着巨大的鸿沟。
为了解决此问题,乔姆斯基提出了转换生成语法理论(Transformational-Generative Grammar,TCG)。他(Chomsky,1964,1975)认为语言的学习存在“结构依赖性”(structure dependence),该结构具有层级关系。对句子的解析可描述为一个树状结构(见图2)。在该树状结构下,语言组件的组合关系必须符合语法规则的限制:构成整个句子的短语间的关系类型是受限制的,只能是主谓、述宾、述补、偏正等;每个部分的组件类型也是受限制的,如作为主语部分的词或者短语又必须是名词性质的。该理论揭示了如何根据有限的语法规则,使用有限的语料生成数量无限的句子。人们通常通过替换组件的内容或改变组件的关系,以产生新的句子。
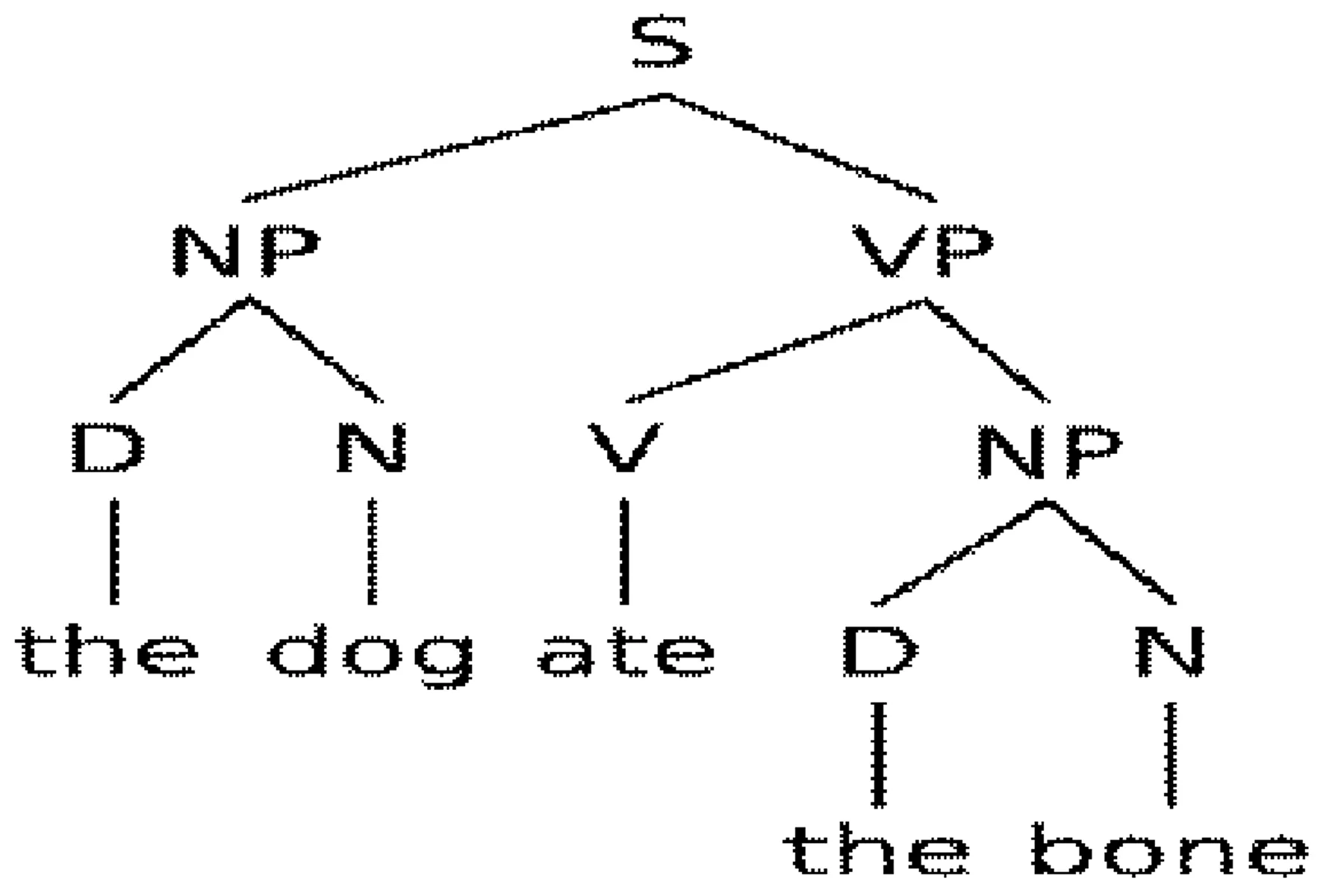
图2 转换生成语法理论中的语法解析树(Chomsky,1964)
转换-生成语法理论中的层级结构表征,在诸多层面的语言认知研究如句法分析(Chomsky,1964)、语义识别(Smith,Shoben,& Rips,1974)和语音识别(Norris & McQueen,2008)等领域中均获得了证据。最近的研究则进一步揭示了与语言密切相关的“概念学习”领域的等级表征(Hamlin et al.,2013;Johnson & Keil,2014)。语言的层级结构表征也得到了认知神经科学证据的支持。在最近一项受到乔姆斯基高度评价和多次引用的工作中,丁鼐等(2016)通过利用脑磁图(MEG)和颅内脑电(ECoG)测量,发现对于听觉通道输入的言语刺激,不同周期的神经震荡可以并行跟踪单词、短语和句子等不同层次语言结构的加工进程。
转换-生成语法理论不仅提出了语言加工的表征,并提供了对该表征相应的运算法则——“情景-独立语法”(context-free grammar,CFG)。其中“语法”是大组块分解为小组块的规则的集合。“情景独立”指语法规则本身不受其出现位置的上下文情景的影响。语法所制定的分解过程用符号“->”表达。“S->ABC”代表大组块“S”依据规则被分解为了小组块“A”“B”“C”。转换-生成的过程同时包含了“且”(And)与“或”这两类最基本的逻辑推理类型。“且”表现为分解规则的具体内容。例如规则“S->ABC”指定,对S的分解要求小组块“A”“B”“C”同时出现,缺一不可。“或”体现在对同一组块,可存在多种不同的分割规则。例如对组块S,可以设定另外一条分解法则“S->ADE”。“且”的约束,使表征的结构具有稳定性,“或”的选择,使表征具有灵活性。
对构成“或”关系的多种合法规则的选择,很自然地可交由概率论决定。二者结合的产物被称为“概率化情景-独立语法”(probabilistic context-free grammars),简称“PCFG”(Chi & Geman,1988)。概率论的引入解决了两个问题。第一,当面对多种可选规则时,概率论提供了简单、通用的选取方法。将每一条规则赋予一个概率值,则多条规则就构成了一个“多项分布”。对规则的选择即为从该多项分布中完成一次“取样”。第二,概率论提供了对多种不同层级树进行比较的客观、定量标准。当每一条规则的概率确定后,只需进一步记录每条规则在某个层级树中出现的次数,便可导出该层级树出现的概率。最优的层级树可由“最大概率原则”获得。正如前文所述,层级树可将一个大的复杂的问题转化为一系列小的简单的问题。公式(1)是这一原则在数学上的表达,体现为树的整体概率被拆分为一系列局部规则概率的连乘。
p(α)∝∏g∈Gp(g)c(g;α)
(1)
公式中,α代表某个层级树;p(α)代表该树的出现的概率。G代表所有的语法,g代表某条具体的语法。C(g;α)代表在树α中,语法g出现的次数。
语法层级树不仅广泛应用于语言学研究,也在相隔甚远的计算机图形学领域中得到应用。例如,程序模型可通过有限的示例图形,学习到古代东亚的建筑风格,并据此生成了大量类似的建筑(Talton et al.,2012,见图3)。PCFG也应用于基因组功能识别(Knudsen & Hein,2003),网页设计(Talton et al.,2012)等领域。

图3 通过语法归纳学习建筑风格(Talton et al.,2012)
5 视觉语义
与人工智能所关注的对有限视觉物体的分类不同,人类视觉的最终输出可涵盖大量丰富的内容和意义,包括视觉场景的结构,物体在场景中的作用,物体与物体间的关系,人与物的关系,人与人的关系,以及人与环境的关系等。
视觉的语义属性对社会生活具有重大影响,也是摄影能成为一个独立的艺术门类的基础。大量出色的摄影图片成为经典,并非仅仅是构图精美、内容新颖,而是以它们特有的语言,讲述了一个个生动的故事,这可借用一句英文的谚语概括为“一图抵千言”(A picture is worth a thousand words)(Stevenson,1949)。例如在Charles Ebbets 1932年的作品《摩天大楼顶上的午餐》中(见图4),城市的繁华、钢梁的危险和工人有说有笑的午餐构成了强烈的对比,精准地描述了那个时代的精神。
由此推论,视觉表征必须支持对“视觉语义”灵活、高效的表达(即便以牺牲对杂乱、无语义图像的低效表达为代价)。众所周知,视觉的加工起始于对基本特征的加工,包括颜色、朝向以及由多种Gabor滤波器定义的特征(Julesz,1981)。然而视觉如何从这些有限、固定的特征出发,最终表达大量的语义呢?显而易见,“语义输出”与“特征输入”间存在着巨大的落差,被称为“语义鸿沟”(semantic gap)(Smeulders et al.,2000)。
视觉语义的存在得到了少许实验研究的支持。人具有快速的将一个动态视觉事件描述为一个故事的能力(Heider & Simmel,1944),并且也能将语言中的概念落实到一个视觉场景中的某一个具体部分(Gorniak & Roy,2004;Jackendoff,1996;Talmy,1988)。著名的“图片-句子”匹配范式要求被试判断图片的内容与句子的语义(如“十字在星形之上”的语句)是否一致(Clark & Chase,1972)。结果发现当图片中客体间的关系与句子中介词的描述一致时,被试的反应更快。另有研究要求被试在听故事的同时观察一组图片(Cooper,1974)。结果发现,被试的眼动轨迹与故事的语义存在对应关系,表现为被试会快速眼跳至与故事语义相关的图片上。

图4 摩天大楼顶上的午餐
遗憾的是,视觉语义研究并未纳入视觉研究的主流。当前的视知觉研究主要聚焦于“特征”和“客体”,而忽视了场景的语义。这种局限在视知觉领域经典的“特征整合理论”(Treisman & Gelade,1980)中也有所体现。该理论指出,视觉加工始于对基本特征的并行加工,每个特征都被表达于各自的特征地图。在空间上重叠的特征可由“注意”的参与加以整合。该理论对特征加工的描述简洁明了,同时极大地推动了视知觉过程中“注意”作用的研究(程少哲等,2017)。然而一个完美的理论,并不局限于其与已知证据是否相符,也应体现为其能否启发、引领新的实证研究。就这一视角而言,由于缺乏语义层面的解释,特征整合理论对“整合”的贡献并不充分。在其框架下,涉及整合的视觉刺激最复杂也不过为三或四重基本特征(例如倾斜的大个红色长方形),与日常生活中最常见的物体(例如桌椅)相比,都过于简单,以致很多现象都不在它所描述的整合范围内,例如,对在空间上不重叠的特征是否存在整合?构成一个动物的身体和四肢是否为并列、独立的特征?整合是一个单一的过程还是逐级递进的?场景不同部分间的共变关系如何表达?
6 视觉的层级树表征
由视觉语法生成的层级树表征是解决视觉“语义鸿沟”问题的有效方案。心理学研究中最接近这一思路的,是由Biderman提出的成分识别(Recognition By Component)理论,也称几何子(geons)理论(1987,1995)。该理论认为,客体的表征由其所含的基本组件(几何子,geons)及其关系加以表达。例如,杯子由杯柄和杯身组成,杯身又由杯环和杯底组成。其中,杯柄是圆弧体,杯环是圆台体,杯底是圆柱体。根据“每个三维的几何子都在二维的视网膜上产生独特的刺激模式”这一原则,可以确定36个几何子,包括方块(block)、圆柱(cylinder)、球面(sphere)、圆弧(arc)、楔子(wedge)等。这些几何子在进行二维投影时具有共线性、对称性等非偶发特性(nonaccidental property)。这些特性并不会因观察客体视角的切换而改变。因此透过二维图像中的非偶发特性来判断组成客体的几何子及几何子之间的空间关系,便可形成对客体的结构描述,从而完成对该客体所属种类的识别。
新近的视知觉研究通常采用“聚类”这一较为成熟的统计方法来创建层级表征(Froyen,Feldman,& Singh,2015;Lew & Vul,2015;Cain,Dobkins,& Vul,2016)。该方法可将一组没有标签的数据,根据它们的特征相似性自下而上地聚合为不同类别。这类方法的优点在于借助统计方法成功地处理了底层视觉输入的噪音,其局限性在于依赖刺激间的特征相似性,无法表达视觉场景不同部分间更为丰富的相互依存关系。
对视觉中复杂关系的表达需要明确的语法规则。笔者以“向量叠加”这一特殊规则为例,尝试性地进行了采用视觉层级树的认知研究(Xu,et al.,2017)。根据刚体力学原理,物体的运动都是针对特定坐标系的,且不同坐标系间的相对运动可线性叠加。例如,月球在太阳系中的运动,可由月球相对地球的运动与地球相对太阳的运动叠加而得。心理学家很早就发现运动知觉是有层级的(Duncker,1929)。例如,同时呈现一个做正弦运动的点和一个匀速直线运动的点,人将知觉到前一个点在围绕后一个点做圆周运动,就如同车轮边缘的点在环绕一个运动的车轴。最近有研究者借用机器学习领域的层级贝叶斯算法,建立了基于“运动叠加”的认知模型(Gershman,Tenenbaum,& Jakel,2015)。笔者利用该模型构建了多客体运动的物理刺激(见图5),完成了一项有关运动记忆的研究,结果发现层级树表征的三个关键属性直接影响认知绩效:(1)层级结构,表现为树结构的存在提高认知绩效;(2)距离,表现为对两物体知觉组织的强度随它们在树表征上距离的增加而减弱;(3)朝向,表现为对父、子两节点对应物体在知觉组织上的不对称性(Xu,et al.,2017)。
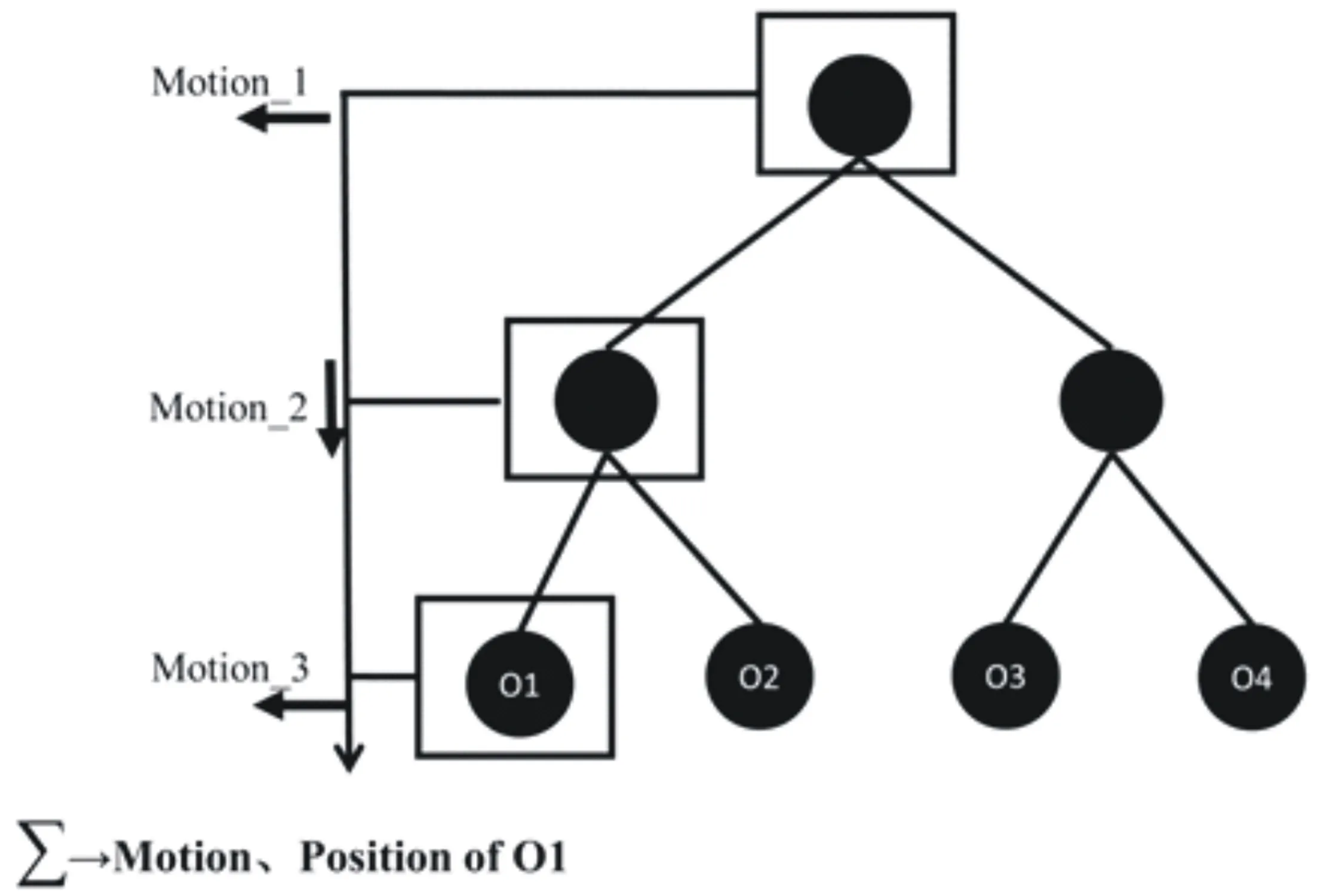
图5 “运动向量叠加”层级树
此外,另有研究融合了认知语言学与计算机视觉的相关理论,取得了对认知科学与人工智能都极具启发性的成果(Zhu,1999;Zhu & Mumford,2007)。研究者创造性地采用“概率情景语法”表达视觉语义,提出了统一语言与视觉的理论框架,并以其实现语义、概念在语言与视觉间的双向转换。在他们的一系列工作中,视觉图像被由代表整个场景的“根节点”开始逐层分解为各个组块,直至抵达由基本特征构成的终止节点,此过程生成的层级树称为“且-或图表征”。该表征兼具视觉概念的稳定性与灵活性。例如,“桌子”必须具备一个平坦的面和四条垂直的腿。这种对结构的限制被表达为一个语法规则,是“且”的关系。同时,桌面、桌腿的颜色,纹理、大小和形状,都可以有不同的选择。这种设计上的灵活性表达为“或”的关系。
然而视觉加工存在其独特的挑战,其表征不能机械地照搬语言的规则。语言与视觉的不同在于:(1)语音信息在时间一个维度上展开,而静止的图像具有两个维度,因此定义视觉的语法规则变得更加复杂;(2)语言认知加工可直接从文字入手,其输入已经是离散的符号,而对真实视觉场景的处理必须从包含噪音的、稠密的像素入手,因此后者由离散的符号构成的层级树还必须与对底层像素信息进行处理的统计方法(如前所述的聚类)相整合。
7 小 结
本文详细论证了人类的良好知识表征对快速学习、灵活迁移的重要性。良好的表征应该同时具备假设空间涵盖范围广,复杂程度低和搜索速度快的特点。层级树表征通过迭代,可以用“有限的组件”和“有限的规则”表达无限的知识。此外,它还拥有提高认知资源的利用效率、表达不同的抽象程度和表达因果关系等方面的优势。基于语言规则的语言层级树表征可解释人类通过语言符号理解含义和获取知识的认知过程。由于人类通常通过提取语义以实现对现实视觉场景的理解,因此基于视觉语法规则的视觉层级树表征可解释人类对视觉场景的认知过程。笔者认为,对良好的知识表征(如层级树表征)的深入探讨不仅可引领有关人类“强认知”领域的研究,同时也有助于实现当前人工智能系统从“大数据、小任务”到“小数据、大任务”的转变。
程少哲,史博皓,赵阳,徐昊骙,唐宁,高涛,……沈模卫.(2017).对注意的再思考:一个注意的强化学习模型.应用心理学,23(1),3-12.
机器之心.长文回顾NIPS大会最精彩一日:AlphaZero遭受质疑;NIPS史上第一场正式辩论和LeCun的激情抗辩/据理力争;元学习&深度强化学习亮点复盘.[web log post].Retrieved from https://www.jiqizhixin.com/articles/2017-12-08-4.
周吉帆,徐昊骙,唐宁,史博皓,赵阳,高涛,&沈模卫.(2016).“强认知”的心理学研究:来自AlphaGo的启示.应用心理学,22(1),3-11.
IEEE spectrum.Will the Future of AI Learning Depend More on Nature or Nurture? [web log post].Retrieved from https://spectrum.ieee.org/tech-talk/robotics/artificial-intelligence/ai-and-psychology-researchers-debate-the-future-of-deep-learning.
Bays,P.M.,Wu,E.Y.,& Husain,M.(2011).Storage and binding of object features in visual working memory.Neuropsychologia,49(6),1622-1631.
Biederman,I.(1987).Recognition-by-components:A theory of human image understanding.Psychologicalreview,94(2),115.
Cain,S.,Dobkins,K.,& Vul,E.(2016).Texture properties bias ensemble size judgments.JournalofVision,16(12),54-54.
Chi,Z.,& Geman,S.(1998).Estimation of probabilistic context-free grammars.ComputationalLinguistics,24(2),299-305.
Chomsky,N.(1964).Aspectsofthetheoryofsyntax(Vol.11).MIT Press.
Chomsky,N.(1975).The logical structure of linguistic theory(p.573).New York:Plenum Press.
Chomsky,N.(1986).Knowledge of language:Its nature,origin,and use.Greenwood Publishing Group.
Clark,H.H.,& Chase,W.G.(1972).On the process of comparing sentences against pictures.CognitivePsychology,3(3),472-517.
Cooper,R.M.(1974).The control of eye fixation by the meaning of spoken language:A new methodology for the real-time investigation of speech perception,memory,and language processing.CognitivePsychology,6(1),84-107.
Ding,N.,Melloni,L.,Zhang,H.,Tian,X.,& Poeppel,D.(2016).Cortical tracking of hierarchical linguistic structures in connected speech.NatureNeuroscience,19(1),158-164.
Ding,X.,Gao,Z.,Shen,M.(2017).Two equals one:Social interaction groups two human actions as one unit in working memory.PsychologicalScience,28(9).1311-1320.
Duncker,K.(1929).Über induzierte Bewegung.PsychologicalResearch,12(1),180-259.
Froyen,V.,Feldman,J.,& Singh,M.(2015).Bayesian hierarchical grouping:Perceptual grouping as mixture estimation.PsychologicalReview,122(4),575.
Gershman,S.J.,Tenenbaum,J.B.,& Jäkel,F.(2016).Discovering hierarchical motion structure.VisionResearch,126,232-241.
Gorniak,P.,& Roy,D.(2004).Grounded semantic composition for visual scenes.JournalofArtificialIntelligenceResearch,21,429-470.
Gweon,H.,Tenenbaum,J.B.,& Schulz,L.E.(2010).Infants consider both the sample and the sampling process in inductive generalization.ProceedingsoftheNationalAcademyofSciences,107(20),9066-9071.
Hamlin,J.K.,Ullman,T.,Tenenbaum,J.,Goodman,N.,& Baker,C.(2013).The mentalistic basis of core social cognition:Experiments in preverbal infants and a computational model.DevelopmentalScience,16(2),209-226.
Hamlin,J.K.,Wynn,K.,& Bloom,P.(2007).Social evaluation by preverbal infants.Nature,450(7169),557-559.
Heider,F.,& Simmel,M.(1944).An experimental study of apparent behavior.TheAmericanJournalofPsychology,57(2),243-259.
Jackendoff,R.(1996).The proper treatment of measuring out,telicity,and perhaps even quantification in English.NaturalLanguage&LinguisticTheory,14(2),305-354.
Johnson,S.G.,& Keil,F.C.(2014).Causal inference and the hierarchical structure of experience.JournalofExperimentalPsychology:General,143(6),2223.
Julesz,B.(1981).Textons,the elements of texture perception,and their interactions.Nature,290(5802),91-97.
Knudsen,B.,& Hein,J.(2003).Pfold:RNA secondary structure prediction using stochastic context-free grammars.NucleicAcidsResearch,31(13),3423-3428.
Lake,B.M.,Salakhutdinov,R.,& Tenenbaum,J.B.(2015).Human-level concept learning through probabilistic program induction.Science,350(6266),1332-1338.
Leonard,J.A.,Lee,Y.,& Schulz,L.E.(2017).Infants make more attempts to achieve a goal when they see adults persist.Science,357(6357),1290-1294.
Lew,T.F.,& Vul,E.(2015).Ensemble clustering in visual working memory biases location memories and reduces the Weber noise of relative positions.JournalofVision,15(4),10-10.
Luck,S.J.,& Vogel,E.K.(1997).The capacity of visual working memory for features and conjunctions.Nature,390(6657),279-281.
Norris,D.,& McQueen,J.M.(2008).Shortlist B:A Bayesian model of continuous speech recognition.PsychologicalReview,115(2),357.
Onishi,K.H.,& Baillargeon,R.(2005).Do 15-month-old infants understand false beliefs?Science,308(5719),255-258.
Pearl,J.(2009).Causality.Cambridge University Press.
Shannon,C.E.(2001).A mathematical theory of communication.ACMSIGMOBILEMobileComputingandCommunicationsReview,5(1),3-55.
Smeulders,A.W.,Worring,M.,Santini,S.,Gupta,A.,& Jain,R.(2000).Content-based image retrieval at the end of the early years.IEEETransactionsonPatternAnalysisandMachineIntelligence,22(12),1349-1380.
Smith,E.E.,Shoben,E.J.,& Rips,L.J.(1974).Structure and process in semantic memory:A featural model for semantic decisions.PsychologicalReview,81(3),214.
Spelke,E.S.,& Kinzler,K.D.(2007).Core knowledge.DevelopmentalScience,10(1),89-96.
Sperber,D.,Premack,D.,& Premack,A.J.(Eds.).(1995).Causal cognition:A multidisciplinary debate (No.Sirsi) i9780198523147).Oxford:Clarendon Press.
Stahl,A.E.,& Feigenson,L.(2015).Observing the unexpected enhances infants’ learning and exploration.Science,348(6230),91-94.
Stevenson,B.E.(Ed.).(1949).Book of proverbs,maxims and familiar phrases.Routledge and K.Paul.
Talmy,L.(1988).Force dynamics in language and cognition.CognitiveScience,12(1),49-100.
Talton,J.,Yang,L.,Kumar,R.,Lim,M.,Goodman,N.,&Měch,R.(2012,October).Learning design patterns with bayesian grammar induction. InProceedingsofthe25thannualACMsymposiumonUserinterfacesoftwareandtechnology(pp.63-74).ACM.
Treisman,A.M.,& Gelade,G.(1980).A feature-integration theory of attention.CognitivePsychology,12(1),97-136.
Wolpert,D.H.,& Macready,W.G.(1997).No free lunch theorems for optimization.IEEETransactionsonEvolutionaryComputation,1(1),67-82.
Xu,H.,Tang,N.,Zhou,J.,Shen,M.,& Gao,T.(2017).Seeing “what” through “why”:Evidence from probing the causal structure of hierarchical motion.JournalofExperimentalPsychology:General,146(6),896.
Zhu,S.C.(1999).Embedding gestalt laws in markov random fields.IEEETransactionsonPatternAnalysisandMachineIntelligence,21(11),1170-1187.
Zhu,S.C.,& Mumford,D.(2007).A stochastic grammar of images.FoundationsandTrends?inComputerGraphicsandVision,2(4),259-362.
