基于Spark的三支聚类集成方法
2018-03-07于洪,陈云
于 洪, 陈 云
(重庆邮电大学 计算机科学与技术学院 重庆 400065)
0 引言
聚类分析为人们从数据中获取有用的信息、知识、规则和决策等提供了有效的方法. 近年来,由于大数据数据量增大,使得传统串行聚类算法不能有效地解决问题.
分布式计算系统Spark[1]的出现,为实现超大数据集处理提供了有效的集群计算平台.由美国加州大学伯克利分校AMP实验室开发的Spark,核心是弹性分布式数据集(RDD),是分布于各个计算节点且存储于内存中的数据对象集合.它使得Spark立足于内存计算,省去了Hadoop各个中间计算保存环节,因此大大减少了计算时间,提高了运行效率.
1 相关工作
聚类集成能够将一个对象集合的多个划分组合成为一个统一的聚类结果.聚类集成主要分为聚类成员生成阶段和一致性函数的设计阶段.一致性函数的设计,对于聚类结果的质量有很大的影响.目前,一致性函数主要分为投票法、超图方法、概率累积方法、混合模型方法、证据积累方法以及基于互信息理论的方法[2].本文一致性函数采用投票法[3],根据聚类成员对数据对象的划分进行投票,统计数据对象被划分到每个类簇的投票票数,再根据票数超过设定阈值来将其划分到类簇中.投票法的优点在于简单易行,提高分类准确度同时大大减少算法的计算复杂度.
文献[4]提出一个并行的聚类集成算法,通过使用KDDCup99的数据集对系统测试,结果显示算法有效改善了系统运行时间和效率.文献[5]提出基于MapReduce的分布式近邻传播聚类算法,针对海量数据进行处理,对数据集随机划分,并行使用AP聚类算法然后融合子集再次进行AP聚类,得到实验结果.文献[6]利用神经网络算法结合多数投票的聚类集成算法,构建了一个新的算法模型.文献[7]将AP聚类算法结合关联矩阵进行基于RDD的分布式改进,提出一种基于RDD的分布式聚类集成算法(DisCE).
2009年,姚一豫教授首次提出了三支决策的概念[8].研究者们将三支决策思想转换为一个理论体系,在多个领域存在三支现象[9-11].2015年,于洪等在文献[12]中,详细介绍了三支决策思想与理论、多种问题求解模型以及在多个领域的相关应用.三支聚类不同于其他使用两个域来表示类簇的方法,三支聚类将结果中每个类簇分为核心域、边缘域和琐碎域.核心域表示对象确定属于该类簇,边缘域表示对象可能属于该类簇,琐碎域表示对象确定不属于该类簇.针对大规模不确定数据集,使用三支聚类结果可以更合理、更直观地刻画边缘域中对象.
本文提出的基于Spark的三支聚类集成方法,对真实的大规模数据进行分析;利用overlap矩阵对聚类成员进行标签对齐;结合三支决策聚类方法,对大规模不确定性数据进行划分,进一步提高本文聚类结果的精确度.
2 本文方法
2.1 聚类框架
图1给出了基于Spark的三支聚类集成(CE-TWD)框架.令待考查的数据对象集合为U={x1,x2,…,xn,…,xN},其中有N个数据点.基聚类器由m个不同的聚类算法构成,如分布式近邻传播算法[13]、基于Spark的层次聚类算法[14]、基于Spark的自组织映射聚类[15]、基于Spark平台的k-means聚类[16]等.m个聚类结果的集合表示为R={R(1),R(2),…,R(i),…,R(m)}.
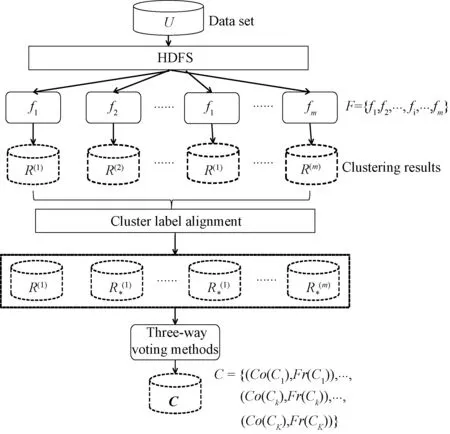
图1 基于Spark的三支聚类集成框架Fig.1 Three-way clustering ensemble framework based on Spark
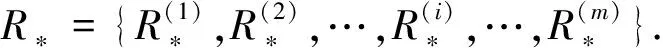
2.2 三支聚类
以往聚类结果中,每个类簇通常用一个集合表示,从决策的角度来看,单一集合意味着集合中的对象确定属于这个类簇,集合外的对象确定不属于这个类簇.这是典型的二支决策的结果.这种表示不能够表现出哪些对象可能属于这个类簇,而且也不能直观地表现出对象对构建类簇的影响程度.因此,使用3个域来表示一个类簇比使用明确集合要更为合理,由此得到基于三支决策的类簇表示.
相比于一般明确表示每个类簇的方法,我们提出用一对集合来表示类簇C:
C=(Co(C),Fr(C)),
(1)
在这里,Co(C)⊆U,Fr(C)⊆U且Tr(C)=U-Co(C)-Fr(C).Co(C),Fr(C)和Tr(C)分别构成了类簇的3个域,即核心域、边缘域和琐碎域.也就是:
CoreRegion(C)=Co(C),FringeRegion(C)=Fr(C),TrivialRegion(C)=U-Co(C)-Fr(C).
(2)
如果x∈CoreRegion(C),对象x确定属于类簇C;如果x∈FringeRegion(C),对象x可能属于C;如果x∈TrivialRegion(C),对象x确定不属于C.
如果Fr(C)=∅,公式(1)中的类簇C变为C=Co(C).这是一个单一集合而且Tr(C)=U-Co(C),表示为二支决策结果.换而言之,单一集合表示是三支决策聚类表示的特例.
针对类簇集合C,每个聚类结果通过三支决策表示为:
C={(Co(C1),Fr(C1)),…,(Co(Ck),Fr(Ck)),…,(Co(CK),Fr(CK))}.
(3)
明显地,每个聚类结果也可以通过二支决策表示为:C={Co(C1),…,Co(Ck),…,Co(CK)}.
3 分布式近邻传播算法
与众多聚类算法不同,AP聚类[19]不需要指定初始聚类个数K,或者是其他描述聚类个数的参数,聚类中心是原始数据中确切存在的一个数据对象.算法通过消息不断地传播来寻找高质量的聚类中心点,即通过不断迭代更新吸引度矩阵R=[r(i,k)]N×N以及归属度矩阵A=[a(i,k)]N×N.其中,吸引度r(i,k)反映了数据对象xk作为数据对象xi的聚类中心的程度,归属度a(i,k)反映了数据对象xi选择数据对象xk作为其聚类中心的适合程度.
为了能够处理大规模不确定性数据,本文将传统的AP聚类算法在Spark的平台上进行了分布式的改进,DisAP聚类算法步骤如下.
1) 数据并行阶段
将数据集加载到HDFS文件系统中,从HDFS上读取数据,通过HashPartitoner分区策略,对数据集进行分区,得到p个数据片.
2) 算法并行阶段
输入:U,包含N个数据对象的数据集.
输出:若干个簇的集合.
步骤如下.
① 初始化相似度矩阵S,吸引度矩阵R和归属度矩阵A均为0,设置迭代次数l以及阻尼系数λ,分区个数p;
② 初始化环境变量SparkContext;
③ 通过函数textFile()加载数据;
④ 计算任意样本点xi和xj之间的相似度,得到一个N×N的相似度矩阵S,将相似度矩阵S广播至每一个worker节点上;
⑤ 每个worker节点循环⑥和⑦,直到达到迭代次数;
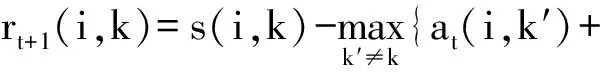
⑦ 更新归属度矩阵,at+1(i,k)←(1-λ)at+1(i,k)+λat(i,k),其中:
if(i≠k)
else
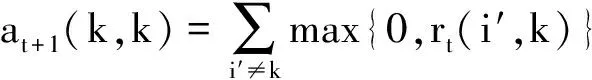
⑧ 将所有节点上得到的吸引度矩阵和归属度矩阵reduce到master节点,分别合并得到一个N×N的吸引度矩阵R和一个N×N的归属度矩阵A;
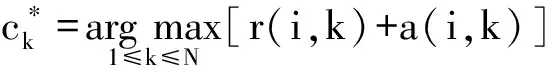
AP聚类中,相似度矩阵S=[s(i,j)]N×N,其中s(i,j)=-‖xi-xj‖2,刻画了任意数据对象xi和xj的距离,距离越近,相似度越高.参考度p(i)(或者s(i,i))是数据对象xi的参考度,指数据对象xi作为聚类中心的参考度.本文取p(i)=median(s),其中median(s)表示相似度矩阵的中值,将相似度矩阵中对应对角线的值替换成对应参考度的值,参考度的主要作用是调节类簇个数.更新吸引度矩阵和归属度矩阵时,加入阻尼系数λ,主要是起收敛作用,防止AP聚类过程产生震荡.
DisAP聚类算法流程见图2.
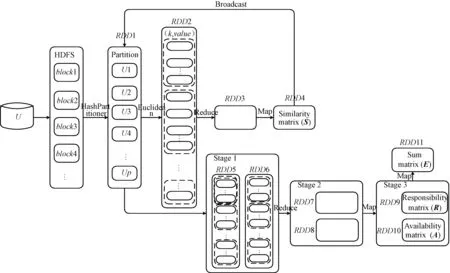
图2 DisAP用RDDs描述示意图Fig.2 The schematic diagram of DisAP described with RDDs
对数据集U进行HashPartitioner分区,得到p个数据片,每个数据片存在以下关系:①U1∪U2…∪Up=U; ②任意Ui∩Uj=∅,i,j∈(1,2,…,p),i≠j.
根据图2,并行化相似度矩阵步骤如下:
1) 从HDFS文件系统中读取数据,将数据集U广播至每个节点上,然后生成具有p个分区的RDD1;
2) 对RDD1中的每个分区中的样本数据计算欧氏距离,以(k,value)的形式存储在RDD2中,其中,k表示数据对象,value为欧氏距离值;
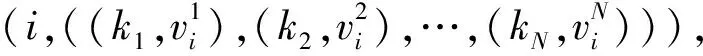
4) 对RDD3中的数据进行map操作,形成相似度矩阵S存储在RDD4中;
5) 将相似度矩阵广播至每个节点;
6) 并行化吸引度矩阵和归属度矩阵的RDD转化过程同相似度矩阵类似,对RDD9的吸引度矩阵和RDD10的归属度矩阵进行求和计算,得到求和矩阵E,其中e(k,k)>0的数据对象xk作为聚类中心,再利用公式(5)对非聚类中心数据对象进行划分,得到聚类结果.
算法首先要对每个分区的数据进行相似度矩阵的计算,时间复杂度为O(N2/p),然后迭代计算吸引度矩阵和归属度矩阵,直到达到最大迭代次数,时间复杂度也为O(Nl/p),遍历对角线寻找聚类中心,时间复杂度为O(N/p).
4 三支投票过程
三支投票过程分为3个阶段,首先,将聚类成员的类簇标签对齐,然后利用m个标签对齐后的聚类成员构造一个投票矩阵,最后根据三支决策规则,确定类簇划分阈值,依次对各个数据对象进行类簇归属划分.
标签对齐阶段.首先,我们将第一个聚类成员作为参照划分,然后将其分别与剩余的聚类成员构造m-1个K×K的overlap矩阵,矩阵记录了两个划分中每一个类簇所覆盖的相同对象的个数.最后,选择矩阵每行覆盖对象个数最大的类簇标签建立对应关系,如果存在两个或两个以上的类簇标签对应时,我们随机选择一个类簇标签进行标签对齐.
投票矩阵构造阶段.将每一个聚类成员看作一个投票者,对于每个数据对象,统计其被划分到不同类簇的票数,从而得到一个N×K的投票矩阵.
三支划分阶段.对于每一个数据对象,根据得到的投票矩阵以及三支决策规则,依次进行类簇归属划分,具体步骤如下:
① 若数据对象在每个类簇的得票数中,存在≥m/2的类簇,就将该数据对象划分在该类簇的核心域部分,如果不存在,进行②;
② 判断数据对象得到的票数是否存在≥m/4的类簇,如果存在,将该数据对象划分在该类簇的边缘域部分;如果不存在,则进行③;
③ 找到该数据对象得票数大于0的类簇,将该数据对象划分到该类簇的边缘域部分.
5 实验与结果
5.1 数据集及评价指标
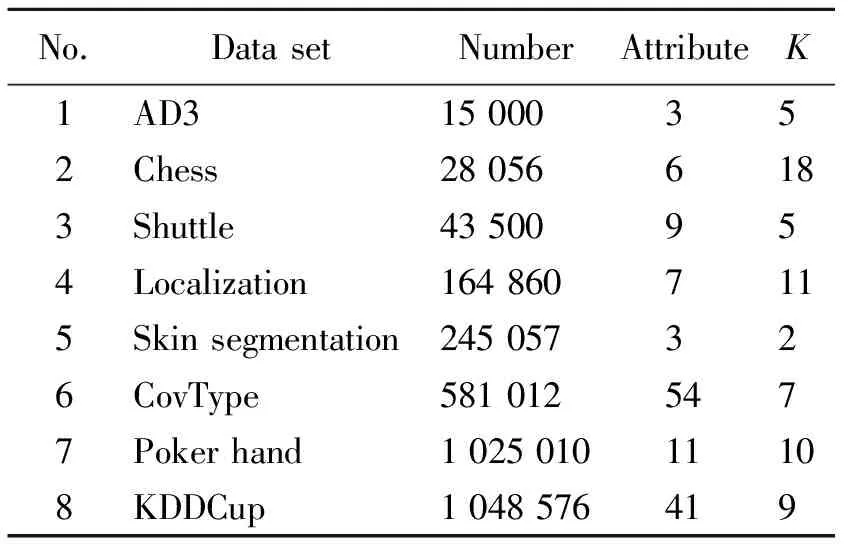
表1 实验测试数据集
本文实验采用8个规模小、中、大的数据集进行测试,AD3为人工数据集,Chess、Shuttle、Localization、Skin segmentation、CovType、Poker hand和KDDCup为UCI数据集,具体信息如表1所示.
本文评价采用准确度(ACC)和标准互信息(NMI),用以衡量两个数据分布的吻合程度.具体公式分别如式(4)~(5).
(4)
其中:N为数据对象总数,αk为类簇Ck中被正确分类的数据对象个数.ACC统计聚类结果中被正确分类的数据对象在整个数据集中所占比例.ACC的值越大,则表示聚类结果的聚类质量越好.
(5)
其中:P(i)表示真实类簇i中样本数和样本总数N的比例,P(j)表示划分类簇j中样本数与样本总数N的比例,P(i,j)则表示真实类簇和划分类簇中共同样本数与样本总数N的比例.NMI的取值范围为[0,1],NMI取值越大意味着聚类结果与真实分布情况越吻合.
5.2 实验和结果
本文实验均在Spark集群上完成,该集群服务器包括384个线程、缓存容量为240 MB,内存容量为1 024 GB.实验一主要测试不同算法的准确度和标准互信息值,将不同规模的数据集在不同算法下运行,计算聚类结果的准确度和标准互信息,同时记录本文算法不同数据集的运行时间.
实验过程中,设置基聚类器算法均迭代100次,阻尼系数λ分别为0.2、0.3、0.4、0.5、0.6、0.7、0.8,得到聚类成员.由表2可以看出本文算法在不同规模数据集上的准确度和标准互信息.其中,Localization数据集的准确度最高,AD3的NMI值最大.本文算法相比另外两个单一的分布式聚类算法,大部分数据集的准确度和标准互信息是更高的.算法的运行时间随着数据集的增大呈现平稳增加的趋势,其中KDDCup数据集的运行时间最长.
实验二通过分布式处理的两类标准speedup(加速比)以及scalaup(扩展比)分析本文算法在Spark平台的大规模数据的处理能力.其中,加速比是指在数据集大小不变的情况下,算法在一台机器的处理时间与在n台机器上的处理时间之比.扩展比是由加速比与节点个数之比,是检验一个并行化算法实用性的重要指标.图3和图4分别展示了本文算法的加速比和扩展比.
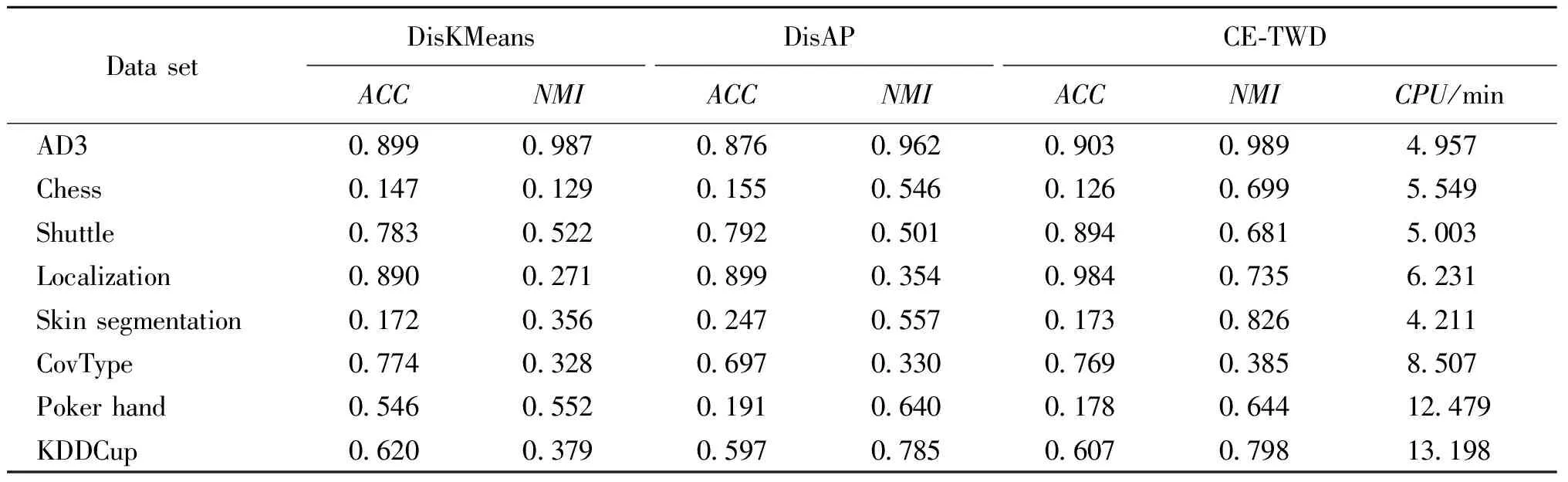
表2 不同算法的ACC、NMI值和运行时间
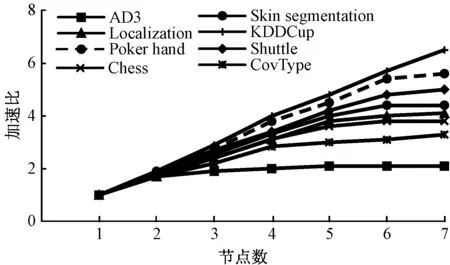
图3 本文算法加速比Fig.3 The speedup of our algorithm
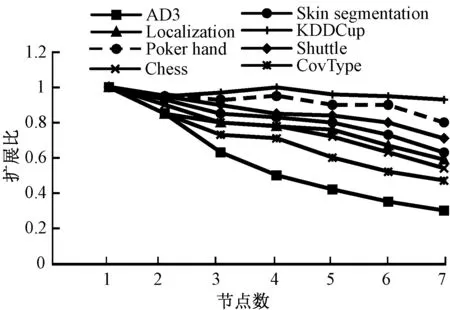
图4 本文算法扩展比Fig.4 The scalaup of our algorithm
由图3可以看出,不同数据集的加速比随着节点个数的增加逐渐呈线性增加趋势,数据集曲线增长率越高,说明数据集的加速比性能越好,由图可见数据集KDDCup的加速比是最好的.
图4是本文算法在8个不同数据集上扩展比的实验结果.扩展比值在1.0附近或者更低,则表示该算法对数据集的大小有很好的适应性.从图中可以看出数据集的扩展比随着节点的增加,逐渐趋于稳定,说明随着数据集规模的增大,算法的扩展比性能越来越好.
6 总结
信息时代的出现使得数据规模急剧增加,如何从这些大规模数据中挖掘出有用信息成为各界研究热点.本文提出一种新的基于Spark的三支聚类集成框架,能够对大规模不确定性数据进行有效处理,同时得到较高的聚类质量.利用改进的分布式AP聚类算法构造聚类成员,对大规模数据集进行了初步聚类;使用基于投票的三支聚类方法,得到了三支聚类结果.实验结果表明,本文算法具有较好的性能.在下一步工作中,我们将进一步完善算法框架,并利用“选择集成”思想,优化算法在大数据上的性能和计算复杂度,进一步提高聚类质量.
[1] ZAHARIA M, CHOWDHURY M, FRANKLIN M J, et al. Spark: cluster computing with working sets [J]. Hot cloud, 2010, 10(10): 95.
[2] VEGA-PONS S, RUIZ-SHULCLOPER J. A survey of clustering ensemble algorithms [J]. International journal of pattern recognition and artificial intelligence, 2011, 25(3): 337-372.
[3] STREHL A, GHOSH J. Cluster ensembles: a knowledge reuse framework for combining multiple partitions [J]. Journal of machine learning research, 2002, 3: 583-617.
[4] GAO H, ZHU D, WANG X. A parallel clustering ensemble algorithm for intrusion detection system[C]//Distributed Computing and Applications to Business Engineering and Science (DCABES). Hong Kong, 2010: 450-453.
[5] 鲁伟明, 杜晨阳, 魏宝刚, 等. 基于 MapReduce 的分布式近邻传播聚类算法[J]. 计算机研究与发展, 2012, 49(8): 1762-1772.
[6] LIU Y, XU L, LI M. The parallelization of back propagation neural network in MapReduce and Spark [J]. International journal of parallel programming, 2017, 45(4): 760-779.
[7] 王韬, 杨燕, 滕飞, 等. 基于RDDs的分布式聚类集成算法[J]. 小型微型计算机系统, 2016, 37(7): 1434-1439.
[8] YAO Y. Three-way decision: an interpretation of rules in rough set theory[C]//International Conference on Rough Sets and Knowledge Technology. Gold Coast, 2009:642-649.
[9] PINKER S. How the mind works [J]. Annals of the New York academy of sciences, 1999, 882(1): 119-127.
[10] LURIE J D, SOX H C. Principles of medical decision making [J]. Spine, 1999, 24(5): 493-498.
[11] GOUDEY R. Do statistical inferences allowing three alternative decisions give better feedback for environmentally precautionary decision-making? [J]. Journal of environmental management, 2007, 85(2): 338-344.
[12] 于洪, 王国胤, 李天瑞, 等. 三支决策:复杂问题求解方法与实践[M]. 北京:科学出版社, 2015.
[13] LU W, CAO P. Clustering large scale data set based on distributed local affinity propagation on Spark [J]. International journal of database theory and application, 2016, 9(10): 241-250.
[14] JIN C, LIU R, CHEN Z, et al. A scalable hierarchical clustering algorithm using Spark[C]//Big Data Computing Service and Applications (Big Data Service). San Francisco, 2015: 418-426.
[15] SARAZIN T, AZZAG H, LEBBAH M. SOM clustering using Spark-map reduce[C]//Parallel & Distributed Processing Symposium Workshops (IPDPSW). Phoenix, 2014: 1727-1734.
[16] GOPALANI S, ARORA R. Comparing apache Spark and map reduce with performance analysis usingk-means [J]. International journal of computer applications, 2015, 113(1):8-11.
[17] STEPENOSKY N, GREEN D, KOUNIOS J, et al. Majority vote and decision template based ensemble classifiers trained on event related potentials for early diagnosis of Alzheimer′s disease[C]//IEEE International Conference on Acoustics Speech and Signal Processing Proceedings. Toulouse, 2006:901-904.
[18] 胡凌超, 于洪. 一种基于投票的三支决策聚类集成方法[J]. 小型微型计算机系统, 2016, 37(8): 1741-1745.
[19] FREY B J, DUECK D. Clustering by passing messages between data points [J]. Science, 2007, 315(5814): 972-976.
