基于本体和贝叶斯网络的Deep Web集成系统研究
2018-03-02朱国进黄琪琪
朱国进, 黄琪琪
(东华大学 计算机科学与技术学院, 上海 201620)
引言
随着互联网技术的发展,网络中出现了越来越多的在线数据库。这些数据一般不被搜索引擎通过静态链接而得到,而是需要通过HTML表单提交查询,由服务器根据请求动态生成页面。研究中通常把这些隐藏在后台的在线数据库称为是Deep Web,也称为Hidden Web。
根据Bergamn等人在2000年的研究表明,存储在Deep Web中的数据量是表层Web的500倍[1],在2014年“互联网实时统计”[2]显示,全球互联网网站的数量已经超过了10.6亿,而在2011年时,只有5.55亿,这些数据说明互联网网站的数量在急速增长,相对地Deep Web中隐藏的数据量也在大幅增加,所以业界对Deep Web的研究是极为重视的。然而这些数据隐藏在后端数据库(即Deep Web数据源)中,无法被搜素引擎所查询,只有在用户提交查询条件后通过Web服务器动态地生成结果页面返回给客户端[3]。在图1中展示了用户通过查询接口而在Web数据库中获取信息的过程。

图1 从Web数据库中获取数据库信息
Fig.1ObtainingdatabaseinformationfromtheWebdatabase
1 Deep Web查询接口集成系统构建
Deep Web研究的根本目的旨在同时访问分布在互联网中的同领域Deep Web数据库中的信息资源。本文针对Deep Web集成系统的关键问题进行了研究,从Deep Web的入口查询接口为主线,研究查询接口的特征提取、领域分类和接口模式匹配。
在本文中,提出一种语义Deep Web方法,通过使用基于程序设计者视角和基于用户视角的属性提取方法,结合WordNet确定最终属性,并通过WordNet自动构建领域语义本体树,最后通过领域语义本体树进行训练得到分类器模型和查询接口模式匹配,完成Deep Web查询接口的集成生成模块。设计流程如图2所示。
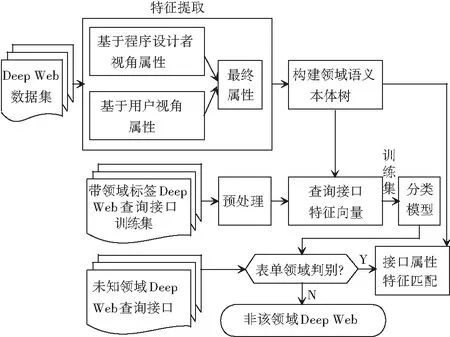
图2 Deep Web集成系统构建流程图Fig. 2 The flow chart of Deep Web integrated system construction
1.1 Deep Web查询接口属性自动抽取
在论述本文工作原理前,需要探讨解释Deep Web中属性的含义。在本文中,属性指能够表示控件的作用的特征词,因此,对查询接口属性在本文中将给出如下定义。
定义1程序设计视角属性(Programmer Viewpoint Attributes,简称PVAs): PVAs是从HTML标签中的内部标识符提取,在本文中特指表单中控件的name属性值。
定义2用户视角属性(User Viewpoint Attributes,简称UVAs): UVAs是Web表单中的文本,一般处在标签之间,用户可以在查询接口页面中直接观看的文本信息,如图3中Web网页中的User Id:。

图3DeepWeb接口示例
Fig.3DeepWebinterfaceexample
Deep Web接口HTML设计代码展开如下:
▼
本文提取Deep Web接口的正确属性方法如图4所示。在图4中,可以看到,UVA和PVA之间存在重叠区域,也就是说通过比较PVAs和UVAs的重叠部分来确定最终属性。

图4 Deep Web数据源信息处理方法Fig. 4 Deep Web data source information processing method
1.1.1 基于程序设计者视角属性提取
HTML中内部标识符和表单中文本可以轻松地使用程序提取,然而并不能直接派作选择使用,因此需要对其进行处理,进一步分成为多个独立的单词并生成备选属性(CA:candidate attributes)。算法1展示了从一个Deep Web接口中分离出一组基于内部标识符的备选属性CAi的步骤。其中,DSi是一组Web查询接口,包含HTML的表单元素{HF1,HF2, …,HFn},令IIi表示从DSi中提取的一组内部标识符,KW表示来自所在Web查询接口中提取控件对应的文本标签。算法1的基本设计代码如下。
算法1提取备选属性(CA)
for eachHFinDSi:
//从Web页面中抽取表单元素
forIIiinHFi
//从表单元素中抽取内部标识符
ifIIicontains special symbols (.,_,:,@,+,=,-,*,,?, ,et)
separateIIiinto sub-strings//如果内部标识符有特殊符号,将其分隔成多个子字符串
ifIIicontains capital letters
separate each sub-strings into several sub-strings //如果分隔后的子字符串中包含大写字母,依照大写字母分隔开
ifIIicontains word inKW
separate it into sub-strings by the word
saveIIiand sub-strings asCAi//将提取的内部标识符和分隔后的字符串作为CAi
returnCAi
从所有的Deep Web数据源中得到备选属性(CA),PVA需要通过算法2从所有的CA中进行提取。算法2的运行代码可表述如下。
算法2提取PVA
add allCAiinto PVA
for string in PVA
if string appear one time in PVA
//删除只出现一次的字符串
remove it from PVA
if string appear several many times in PVA
//删除重复项
save one and remove the duplicate ones
return PVA
图5展示了获取程序设计者视角(PVA)提取属性特征的例子。假设具有2个Deep Web数据源DS1与DS2,通过提取得到2组内部标识符属性II1和II2,通过算法1进行分隔处理,本文从2组内部标识符得到2组备选属性CA1与CA2,将2组内部标识符通过算法2进行处理,最终得到PVA。
1.1.2 基于用户视角属性提取
用户视角属性用来确定Deep Web数据源的最终属性,这是从查询接口的文本中获取的。在算法3中给出了在每个Deep Web数据源中获取UVA的过程,可将HTML标签之间的文本存储在基于文本的备选属性TCAi(text-based candidate attributes)。其中,标签之间的文本是被忽略的,因为在这之间的文本表示的是实例,而不是描述属性。
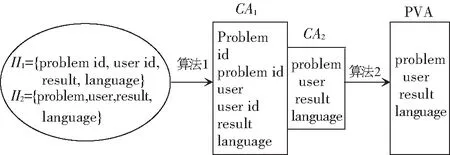
图5 获取PVA示例Fig. 5 The example of obtaining the PVA
算法3提取UVA
for eachHFi
obtain all the text asTCAi
for string inTCAi
if string is a sentence
//如果文本为句子,提取出内容关键字
extract import word asTCAi
if string contains special symbols (.,_,:,@,+,=,-,*,,?, ,et)
separate string into several sub-strings //如果文本有特殊符号,将其分隔成多个子字符串
if string contains capital letters
separate strings into several sub-strings
//如果分隔后的子字符串中包含大写字母,依照大写字母分隔开
remove the duplicated inTCAi, save it intoUVAi
returnUVAi
在算法3中提取UVA,和提取PVA的算法很相似。不过UVA中提取的基于文本的备选属性是来自于控件对应的文本。同时,在部分Deep Web查询接口控件对应的文本是一句完整的句子,需要提取出句子内容的关键字。随后对提取属性进行消除重复处理,得到UVA。
1.1.3 基于本体的属性拓展
本文通过WordNet本体来获得PVAs和UVAs的同义词,并确定最终属性。在本文只专注于名词,因此,使用2个规则来过滤候选属性:检查候选属性在WordNet中是否有名词含义,如果在WordNet中至少有一个名词含义,这个词将被保留,否则丢弃;然而,一些候选属性是由词组组成,无法在WordNet查询。为了解决这个问题,第二条规则用来保留这些重要的词:如果一个候选属性是由词组构成,且构成词组的单词在WordNet中具有名词含义,那么保留短语。
利用WordNet的词汇关系,本文通过PVA或UVA得到了其中所有的候选属性SOPVA、SOUVA,表1即为使用WordNet获得同义词的例子。

表1 获得同义词示例Tab. 1 The example of obtaining synonyms
1.1.4 最终属性提取
最终属性(Final Attribute,简称FA)必定是来自于SOUVA中的元素,相比较基于程序设计者视角提取出的属性,基于用户视角提取的属性更为规范。来自SOUVA中的元素其字符串或者其同义词之一的字符串与SOPVA中的一个元素相匹配,并且与UVA的该字符串元素的所有连续字符串块的占有率大于α %(0<α<100),α是影响最终属性总数的因素,即α越小,最终属性数越多。图6即为获取最终属性示例。
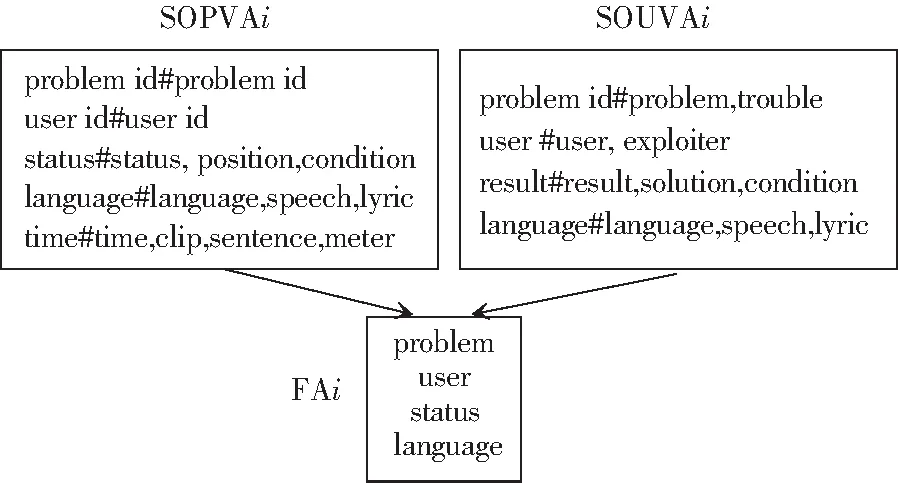
图6 获取最终属性示例Fig. 6 The example of obtaining final attribute
1.2 构建Deep Web领域本体
由于人类与程序之间的知识共享的目标,本体的构建将在语义网络和Deep Web中发挥主导作用。为了支持语义网,构建领域的特定的本体是可取的,但是,手动构建本体是十分困难的,极其耗时且容易出错[4-5]。
当下,自动构建领域本体的方面工作已经成为研究热点,并且推出了可观研究成果。OntoBuilder[6]通过将一个网站作为层次结构,在每个网站对应的本体之间进行匹配。DeepMiner[7]根据树形结构中表单元素的相对位置提取概念和实例。在OntoMiner中IS-A关系通过网页中XML树中的父子频率进行挖掘。综上方法的共同特点是研究了从Web中提取出本体的方法,但是没有提供最终的本体,无法应用在语义网络中。
本文使用WordNet的语义关系上位词(hypernym)将最后的属性组合在一起,并根据其中的最近公共上位词构成有向无环图DAGs(directed acyclic graphs)。将这些最终属性根据上位词关系组合在一起的片段称为DAG片段(small DAGs schema fragments,简称SFs)。当只有一个DAG或者达到最大迭代次数时,迭代终止。在图7中展示了在Online Judge领域中的部分最终属性通过最近公共上位词构成SF的例子。
在图7中,具有2个最终属性(author, user),通过WordNet来检索对应的上位词,最终发现,可以通过person来作为最近公共上位词,可以用person来表示这2个最终属性。在图7(a)中显示了2个最终属性;图7(b)中因为2个最终属性没有直接上下位关系,因此通过WordNet找到2个属性的上位词,虚线椭圆表示从WordNet派生出来的本体;图7(c)继续寻找上位词,发现person为2个最终属性的最近公共上位词,将person作为该SF的根节点。
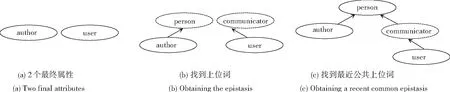
图7 基于最近公共上位词构成树示例Fig. 7 The example of a recent common epistasis tree
获得最终语义本体树的步骤如算法4所示。
算法4构建领域语义本体树
for all FA
ifFAiis a hypernym ofFAj//如果FAi是FAj的上位词,建立IS-A连接
create DAG by inserting a new IS-A link betweenFAiandFAj
deleteFAi,FAjfrom FA
else ifFAjis a hypernym ofFAi
//如果FAj是FAi的上位词,建立IS-A连接
create DAG by inserting a new IS-A link betweenFAiandFAj
deleteFAi,FAjfrom FA
While(just has only one DAG or iteration has been reached )
//到只有一个DAG时候或者迭代次数超过限制
for each DAG //对每个DAG的root节点在WordNet中寻找上位词
add new root by inserting the IS-A link between DAG's old root and it's hypernym;
for all DAG //对DAG根节点寻找在其它DAG中节点是否有其上位词
if find an IS-A link betweenDAGi's root andDAGj's node
inserting a new IS-A link betweenDAGi's andDAGj's node
领域本体树构建完成后,对最终属性进行拓展,寻找其同义词集,添加进语义本体树中,进一步消除查询接口中属性的词形异构性。在WordNet中,所有名词的最终祖先皆为entity,因此如果在算法3,最终只有一个DAG,可以将根结点替换成该领域名称,如果有多个DAG,可以将该领域名称作为最终根结点,并将各个DAG与该节点连接起来。图8则为通过该方法得到的经过简化的Online Judge领域语义树。
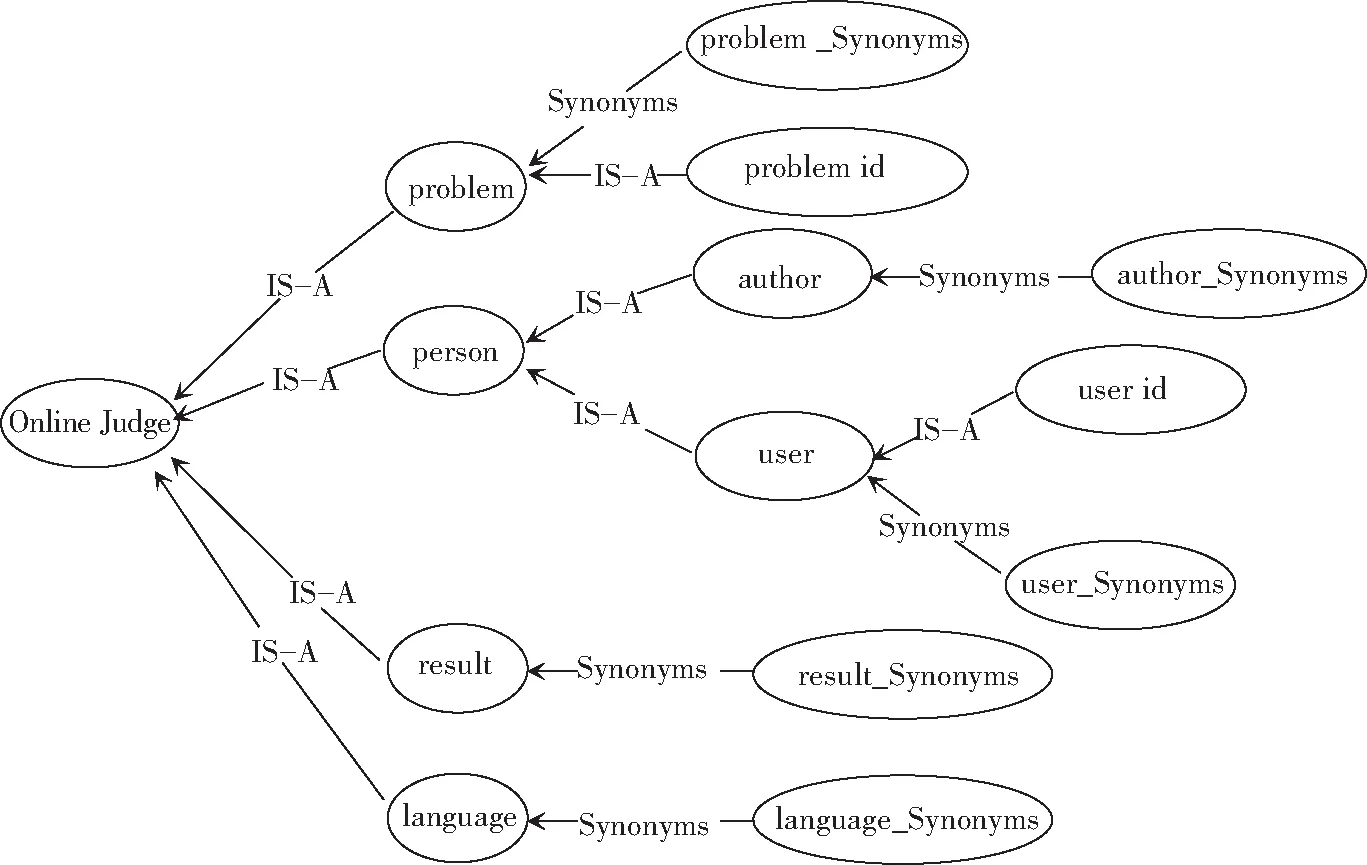
图8 Online Judge领域简化语义树Fig. 8 Online Judge domain simplified semantic tree
在得到Deep Web领域本体树的时候,可以根据领域语义本体树生成该领域Deep Web集成查询接口。例如图8的Online Judge领域语义本体树,可以得到problem、person、result、language四个本体,生成如图9所示集成查询接口。

图9OnlineJudge领域集成查询接口
Fig.9OnlineJudgedomainintegratedqueryinterface
1.3 贝叶斯网络分类器
本文在使用贝叶斯网络算法时,通过领域语义本体树,将测试集Deep Web查询接口转换成特征向量,进行训练得到贝叶斯网络分类器,如图10所示。
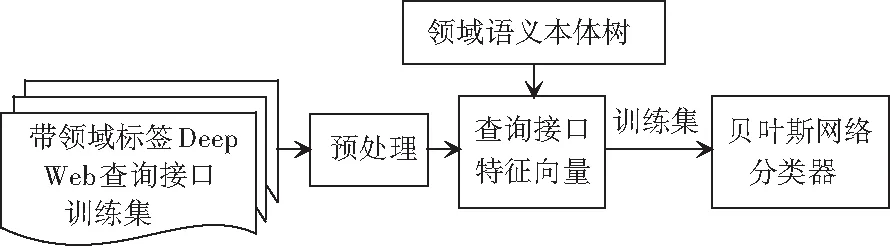
图10 贝叶斯网络分类器训练Fig. 10 Training of Bayesian network classifier
通过语义本体树将每一个Deep Web数据样本使用一个n维特征向量X= {x1,x2,x3,…,xn}(n的维度来自于各个语义树根节点的直接相连节点数)表示,分别描述该Deep Web样本具有的特征属性:A1,A2,A3,…,An。研究步骤内容如下。
(1)对训练样本进行特征提取,将得到的特征与该领域语义本体树进行匹配,通过统计,可以得到该领域贝叶斯网络的条件概率表;
(2)贝叶斯网络拓扑结构和条件概率表构成贝叶斯网络分类器Hn;
(3)通过贝叶斯网络分类器Hn对测试样本进行分类,得到分类结果。
1.4 接口模式匹配
由于每一个查询接口都具有自己的命名规则,导致查询接口的属性特征具备多样性、异构性和欠完备性,因此需要进行预处理过程,根据一些规则将其标准化,获得统一的表达方式再进行匹配。
根据查询接口中表单模式信息的情况,通过2种匹配方式来进行模式匹配:直接模式匹配和间接模式匹配。其中,直接匹配是将表单的属性和领域语义本体树中的本体信息使用基于字符串的方式进行匹配,该字符串元素的连续字符串块的占有率大于α% (0<α<100),则匹配成功。而由于本体信息是有限的,有些可匹配的查询接口属性特征无法通过基于关键词匹配的方法进行匹配,此时通过查询接口属性特征和领域语义本体树中的本体进行语义相似度计算,来寻找匹配的本体信息,这就是间接匹配。模式匹配的整体流程如图11所示。
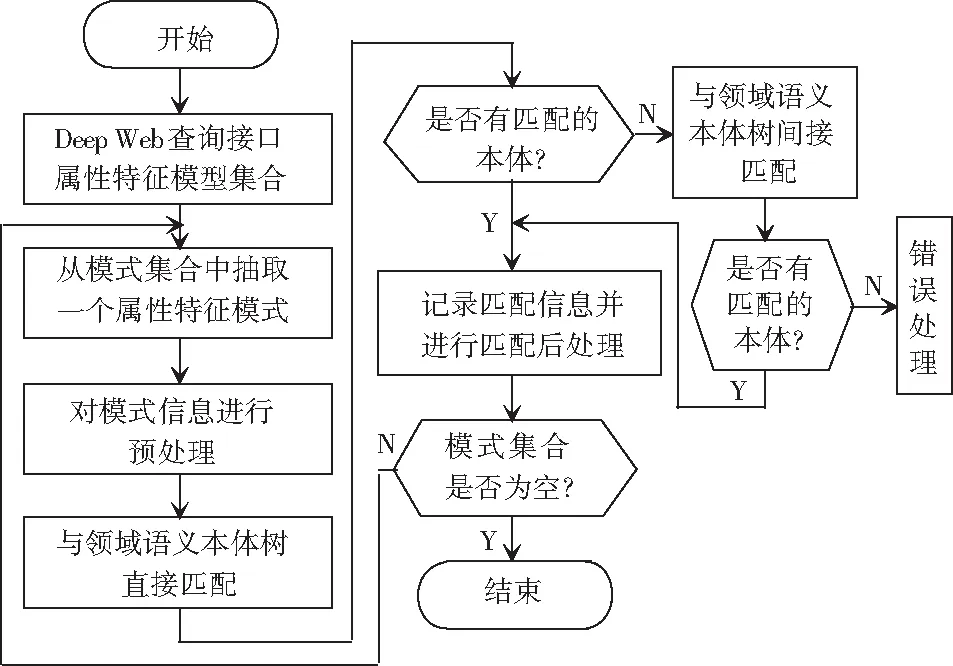
图11 模式匹配流程图Fig. 11 The flow chart of pattern matching
本文中的领域的集成查询接口是根据构建的领域语义本体树的结构得到的,当匹配到处于领域语义本体树中的相应本体后,可以通过领域语义本体树找到集成查询接口对应的本体,直至查询接口模式集合匹配中为空,就完成一个该领域Deep Web查询接口与集成查询接口的模式匹配。
2 实验与结果分析
本实验采用了UIUC大学的Deep Web数据集合TEL-8数据集,分为8个领域: Airfare、Automobile、Book、Car Rentals、Hotels、Jobs、Movie、Music。考虑到TEL-8数据集中网页信息年限较久,因此,本文在每个领域添加了20个通过手工收集的该领域的Deep Web网页,并添加一个新领域Online Judge,总计9个领域,613个Deep Web查询接口。
数据集分布如表2所示。本文采用随机在其它领域查询接口与非查询接口中抽取400个样本作为反例。

表2 Deep Web查询接口数据集分布Tab. 2 Deep Web query interface data set distribution
在本节,展示了在特征属性提取结果、贝叶斯分类判别、接口模式匹配的3个实验结果,通过这3个实验结果进行分析,证明了本文提出的方法的可行性。
2.1 特征属性提取结果
一个特征属性是包括其控件的属性标签和该控件对应的文本信息确定的。实验结果如表3所示。

表3 属性特征提取实验结果Tab. 3 Experimental results of attribute feature extraction
在表3中详细列出在各个领域中提取的最终属性、DAG数量和通过WordNet得到的拓展词。但是目前并没有确定对本体构建的统一评价标准,因此无法对本文所得到的各个领域语义本体树进行客观评价。在本文中,根据应用在贝叶斯网络分类和模式匹配实验的结果来表现本文领域语义本体树的性能。
2.2 贝叶斯网络分类实验结果
为了保证分类模型的准确性,同时也考虑到数据集规模偏小,因此采用5折交叉验证方法来选择和评估模型,将训练结果取平均值作为最终结果。实验结果如表4所示。
表4贝叶斯网络分类实验结果
Tab.4ExperimentalresultsofBayesiannetworkclassification%

将表4以直方图形式展现,最终效果如图12所示。可以发现,Online Judge领域表现结果最好,达到100%,其他领域的准确率、召回率和F1-measure基本保持在90%以上,说明本文提出的方法具有较好的可行性和适用性。
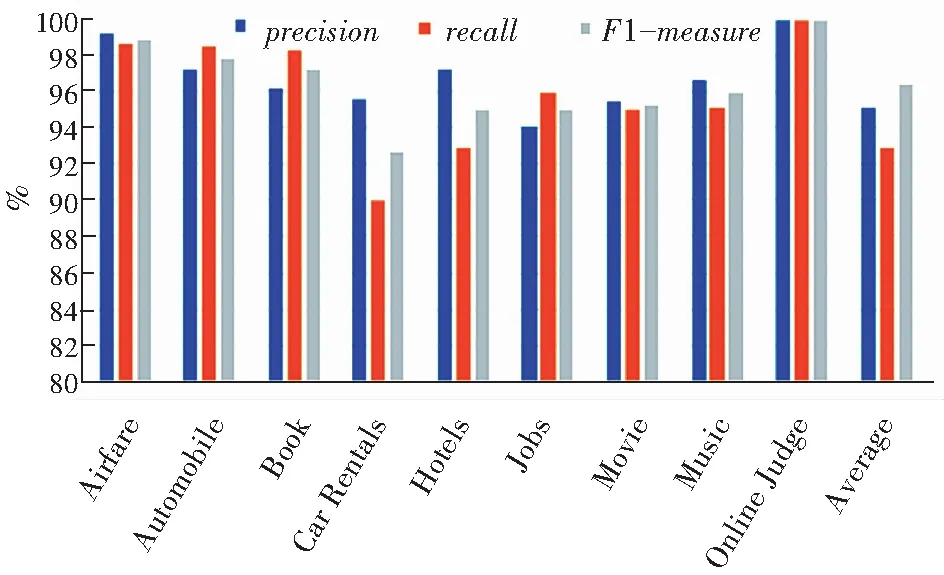
图12 贝叶斯分类实验结果Fig. 12 Experimental results of Bayesian classification
通过对比其它采用手工构建领域本体方法进行分类[8-9]得出的实验结果再经讨论总结和综合分析后发现,采用数据集相同,试验结果在查全率和准确率方面相差不大,证明了本文自动构建的领域语义本体树的的合理性以及分类算法的适用性。
2.3 接口模式匹配结果
在接口模式匹配阶段,采用的数据集为已经划分好领域的Deep Web数据集,且所有查询接口中属性特征的匹配都是视作1∶1型匹配。各领域的匹配结果,如表5所示。
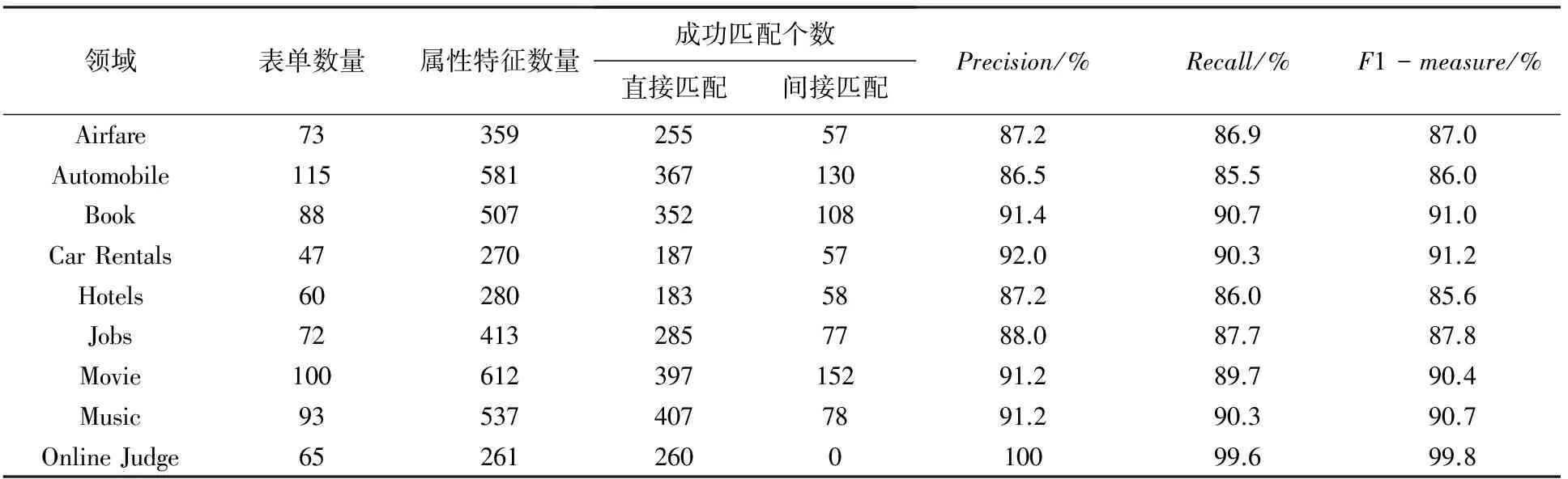
表5 模式匹配结果Tab. 5 Pattern matching results
将表5匹配结果以直方图表示,可得结果如图13所示。通过模式匹配过程,各个领域大部分的查询接口特征属性都可以成功完成匹配,通过对比其它通过手工或半手工构建领域语义本体方法进行模式匹配的结果[10-11],在匹配准确度上相差不大,可以确定自动构建的领域语义本体树的合理性和在查询接口模式匹配方面的可行性与有效性。

图13 模式匹配结果Fig. 13 Pattern matching results
3 结束语
随着互联网的高速进步,动态网站的技术的不断进步,隐藏在这些Web中的Deep Web数据库中的资源必定日益增加。但是Deep Web具有隐蔽性、动态性和异构性等特征,为获取Deep Web中的海量资源带来了严峻挑战。本文中提出的方法提供了自动构建Deep Web查询接口集成系统的解决方案,但是由于Deep Web自身具备特点,依旧需要更多工作的探索完善。在下一步工作中,将会在这方面继续改进,提高查询接口分类和模式匹配的准确性。互联网的高速发展,必定使Deep Web数据集成收获更多的研究和关注。在未来,Deep Web数据集成会如同传统搜索引擎一般使用户自由访问Web数据库中的数据,给信息检索带来飞跃的提升。
[1] Bergman M K. White paper: The deep web: Surfacing hidden value[J/OL]. Journal of electronic publishing, 2001, 7(1)[2001-09-24]. http://dx.doi.org/10.3998/3336451.0007.104.
[2] 中商情报网. 2013-2014年中国互联网产业发展研究年度总报告[EB/OL]. [2014-03-03]. http://www.askci.com.
[3] 刘伟, 孟小峰. Deep Web 数据集成问题研究 [R]. 北京:WAMDM, 2006.
[4] 袁柳, 李战怀, 陈世亮. 基于本体的 Deep Web 数据标注[J]. 软件学报,2008, 19(2): 237-245.
[5] LIN Ling, ZHOU Lizhu. Web database schema identification through simple query interface[M]//LACROIX Z. RED 2009. Berlin/ Heidelberg: Springer·Verlag,2010,6162: 18-34.
[6] DOU D, MCDERMOTT D V, QI P. Ontology and translation on the semantic Web[M]//SPACCAPIETRA S. Journal on Data Semantics II. Berlin/ Heidelberg: Springer·Verlag,2004,3360: 35-57.
[7] ROITMAN H, GAL A. OntoBuilder: Fully automatic extraction and consolidation of ontologies from Web sources using sequence semantics[M]//GRUST T, et al. Current trends in database technology-EDBT 2006. EDBT 2006. Lecture Notes in Computer Science. Berlin/ Heidelberg: Springer, 2006,4254:573-576.
[8] 黄黎. 基于知识模型推理的 Deep Web 数据源分类研究[D]. 苏州:苏州大学, 2009.
[9] 牟晓伟. Deep Web 数据源发现与分类技术研究[D]. 长春:长春工业大学, 2015.
[10]苏晓珂, 张勇敢, 黄青松. Deep Web 查询接口的复杂模式匹配[J]. 石河子大学学报( 自然科学版), 2007, 25(1): 122-124.
[11]龚桂芬. 基于查询接口的 Deep Web 模式匹配方法研究[D]. 苏州:苏州大学, 2011.
