一种Zynq SoC片内硬件加速的二维傅里叶变换*
2018-03-01,
,
(南京航空航天大学 民航学院,南京 211106)
引 言
二维离散傅里叶变换作为频域分析的重要工具之一,广泛应用于数字图像处理的各个领域。随着数字图像数据量的增长,传统基于处理器实现的软件算法逐渐遇到实时性不足的问题,尤其是在一些对体积与功耗有严格限制的嵌入式应用场合中,处理器的性能大幅受限。
近年来人们不断尝试使用新的硬件结构来加速这一算法的实现过程。例如,参考文献[2]针对GPU多核处理器架构,分析合并内存访问事务大小与占用率之间的关系,优化使用GPU存储器资源,对小数据量2次幂二维复数FFT在GPU上的实现进行改进[2]。而相对于GPU的高功耗,低主频低功耗的FPGA加速具有更大的实用价值,参考文献[3-4]分别尝试使用FPGA逻辑资源独立完成二维FFT[3]与卷积神经网络算法的实现[4],并将结果与GPU、DSP等方式进行了对比,验证了显著的加速效果。为了便于在利用逻辑资源加速后引入复杂算法,人们也逐渐尝试在使用FPGA加速的同时结合CPU来进行任务调度,如在大邻域图像加速设计中使用NIOS II软核处理器[5],在结合片内硬核ARM处理器与FPGA的SoC器件上分别尝试对阈值分割[6]、LS-SVM[7]或车辆识别[8]等算法进行加速,均取得了一定成效。
综上,纯粹利用专用集成电路(ASIC)或可编程逻辑门阵列(FPGA)来实现算法的方式虽然能满足速度需求,但也存在着开发周期长,且不利于后期动态调整的缺点。针对这一问题,本文基于近年来流行的集成高性能ARM与FPGA的片上系统(System on Chip, SoC)平台,尝试一种同时兼顾软件开发灵活与硬件实现效率高的二维傅里叶变换新方法。考虑到二维傅里叶变换的可拆分性质,在FPGA侧通过搭建多路流水线形式的一维快速傅里叶变换IP核来实现并行计算加速,在处理器系统一侧通过搭载嵌入式Linux系统来快速实现GUI显示等人机交互的接口,并借助于Linux系统丰富的软件开发生态环境,后续更加复杂的图像算法可以方便地借助于流行的(诸如OpenCV,OpenGL等)软件库加快开发周期。
1 二维傅里叶变换拆解
离散傅里叶变换(Discrete Fourier Transform, DFT)是将离散时域信号转换为频域信号的经典工具,对于常见的一维信号,其计算公式如下:
(1)
其中,x(n)为信号的离散时域序列(n=0,1,2,…,N-1),X[k]为其变换后的离散频域序列(k=0,1,2,…,N-1)。
而对一幅N×N大小的数字图像进行二维离散傅里叶变换为:
(2)
其中,g(u, v)为原图像在第u行,第v列的像素灰度大小,G(m,n)为原图像变换后在横向和纵向两个方向上对应的频域离散分布。
分解上式的指数项得到:
(3)
结合式(3)与式(1)可以将二维离散傅里叶变换分解为水平和垂直两部分运算,上式中方括号内的项表示在图像的行上计算实数序列的DFT,方括号外的求和项则表示在计算完所有行DFT的基础上,对所得结果进行列方向上的复数序列的DFT。这样的分解也表明可以用一维的快速傅里叶变换(Fast Fourier Transform, FFT)来快速实现二维离散傅里叶变换。而且,由上式可以看出在行方向(或列方向)上对各行(或各列)进行的变换计算是独立的,因此结合FPGA的特点,可以设置多个的一维快速傅里叶变换IP核来加速完成两个方向上的计算过程。
2 系统设计介绍
2.1 总体设计及功能划分
由于Zynq平台内的处理器系统包含浮点处理单元,又考虑到运算精度对后续算法扩展的影响,因此选用符合IEEE754标准的32位浮点数作为整个运算过程中的数据格式。由上文介绍可以得知,利用两个方向上的一维傅里叶变换来完成二维傅里叶变换过程中需要对前一个方向的变换结果进行缓存,然后在此基础上完成另一个方向上的计算。由于缓存的中间结果是一组双通道(分为实、虚部)二维浮点数组,对于某些分辨率较高的图像,其消耗的存储空间是巨大的,例如对于一幅1024×1024大小的图像,经过一维傅里叶变换后得到一组大小为1024×1024×2×4=8 MB的二维数组,这对于XC7Z020可编程逻辑侧有限的片内存储逻辑资源是一个巨大且不必要的消耗(注:XC7Z020的PL侧存储资源主要有140个大小为36 KB的Block RAM,合计总容量为4.9 MB)。因此,结合Zynq的互联结构优势,可以利用直接存储器访问(Direct Memory Access, DMA)将中间结果存入PS侧的大小为512 MB的DDR3外扩RAM,这样既大量降低了片内存储资源的消耗,也便于PL侧与PS侧进行大规模的数据共享。
整个系统的结构设计如图1所示,主要工作流程如下:PS侧的程序将待处理的图像数据与多路一维快速傅里叶变换模块的配置信息写入DDR3存储器,然后利用PL侧的Xillybus总线先后将配置信息与图像数据分别传入设计好的复位配置模块与多路FFT计算模块,完成配置与单方向上的一维傅里叶变换后,再由Xillybus总线将中间结果写回到DDR3存储器中,然后由PS侧的程序对中间结果完成二维矩阵转置后,再控制Xillybus将数据传输至多路FFT计算模块完成另一方向上的一维傅里叶变换,并将最终结果写回进DDR3存储器供PS侧的程序读取。
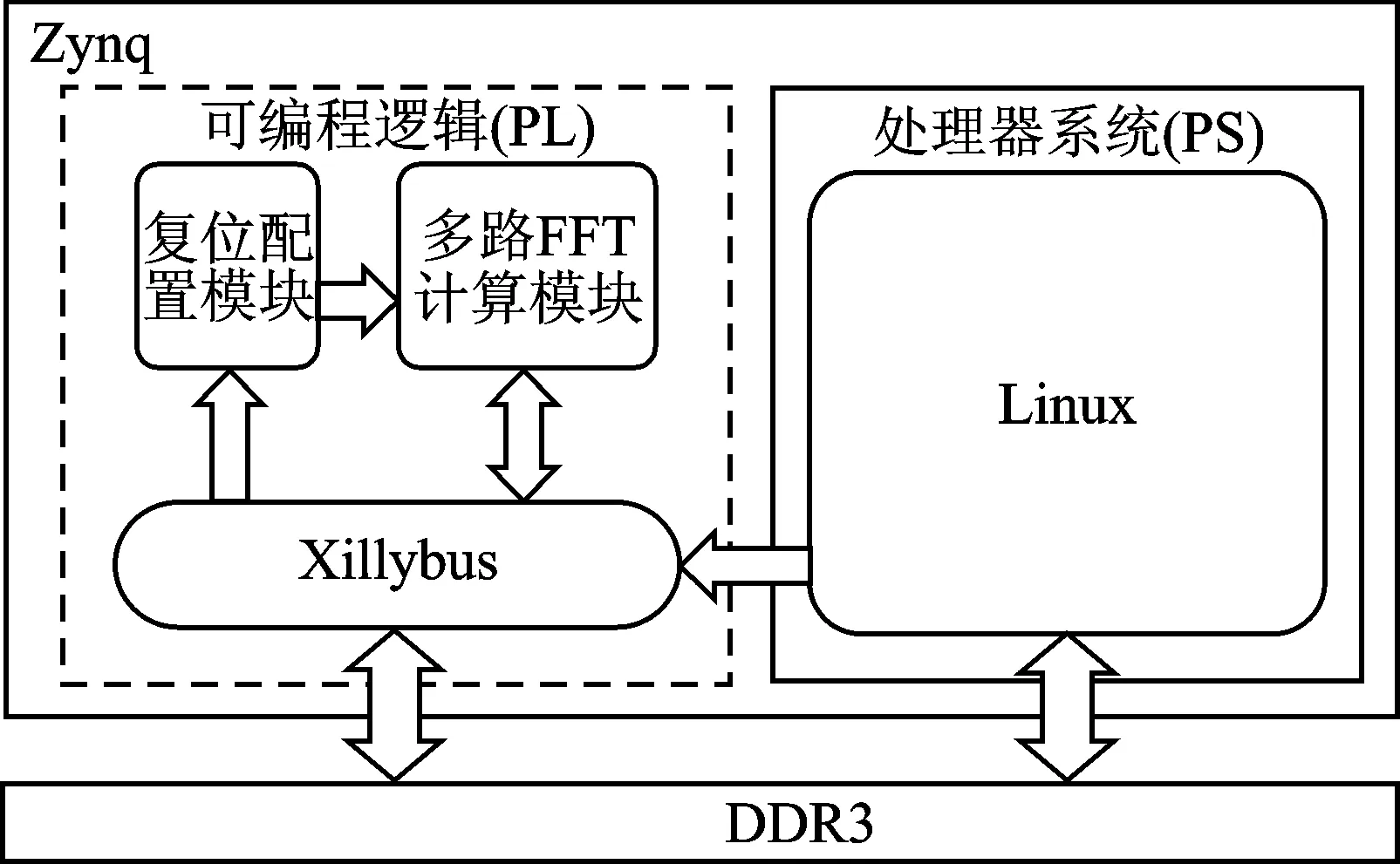
图1 系统总体结构框图
2.2 硬件计算模块设计
由图1可以看出,PL侧的硬件系统主要由三部分组成:Xillybus、复位配置模块、多路FFT计算模块,接下来将分别对它们进行介绍。
Xillybus是一个基于DMA或者PCIe总线的IP核,主要用于完成FPGA与Linux或Windows系统之间的数据通信任务,由Xillybus公司开发并提供驱动。传统的DMA在完成数据传输时要求内存中待传输数据的物理地址连续,而常见操作系统(如Linux)则通过地址映射的方式为用户空间的程序分配内存空间(通常无法保证数据的物理地址连续),因此,需要在操作系统启动时就预留固定大小的内存空间用来进行DMA传输。这样的方式在需要传输大量数据时会大幅缩减系统的可用内存,而Xillybus驱动通过将待传输的大量数据分批次拷贝至特定的缓冲区完成后续的数据传输,在一定程度上提高了内存的使用效率。
复位配置模块的主要功能是:经由Xillybus总线接收用户程序的配置信息,并根据收到的信息对多路FFT计算模块中的所有子模块进行相应的复位和配置(如傅里叶变换的长度与方向设置),并在完成后向PS侧返回应答信号。
多路FFT计算模块的主要功能是:将经由Xillybus总线传入的串行数据依次送入多个一维快速傅里叶变换的IP核(由Xilinx的开发套件提供),分别独立完成计算,再将计算结果按顺序送回。其主要结构如图2所示,其中FIFO除了起到缓冲数据的作用,还负责将串行传输的32位宽的虚数与实数数据转为并行64位宽的复数数据。图中的4个FFT计算模块是由Xilinx公司提供的IP核,可以在开发软件Vivado附带的文档库中获取其相关参数。其中每个IP核计算序列点数与待处理图像数据的每行(或每列)包含的像素数目相同。而IP核的数量,即FFT的通道数目可以根据实际需求结合资源使用状况灵活选择,图中只画出了4路通道的设计方案以便于展示工作流程。需要注意的是图中虚线框内的两个状态检测及切换模块,它们有着相似的功能:统计输入或输出数据的数目,并根据统计结果选择合适的计算通道。但在具体实现时,输入状态检测模块被设计为时序逻辑电路,输出状态检查模块被设计为组合逻辑电路。这样设计的主要原因是FFT模块的输入输出数据所采用的AXI-Stream总线时序与FIFO的写入读出时序不一致。
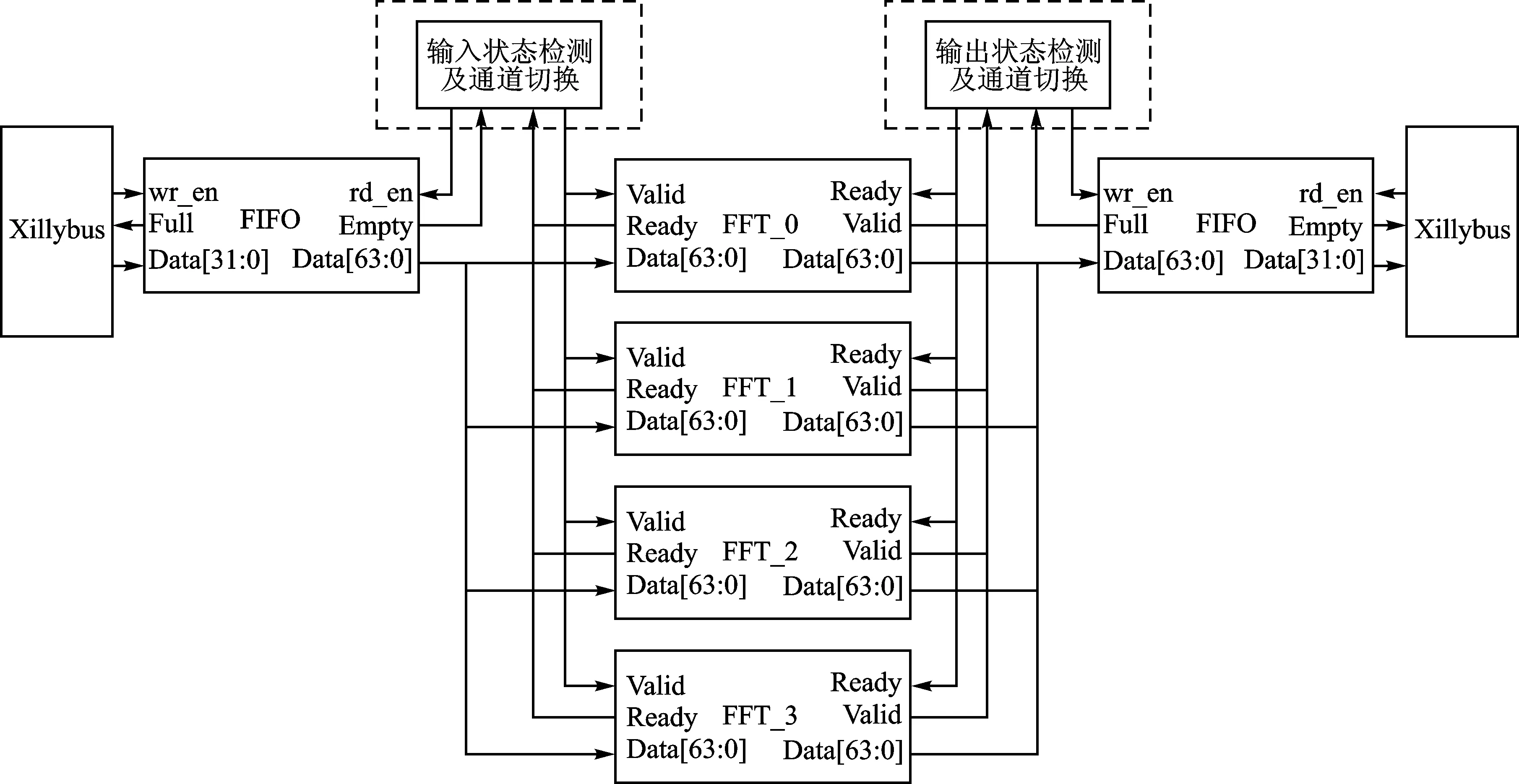
图2 多路FFT计算模块结构框图
AXI-Stream总线的读写时序都是同步的,即如图2中的FFT模块端口所示,当Valid与Ready信号同时为高时,数据在每一次时钟信号的上升沿被写入或读出。而FIFO的读出数据时序是异步的,即当Empty信号为低且在第一个时钟上升沿检测到读使能信号为高后,对应的数据将在第二个时钟上升沿被读出。这一个时钟周期的滞后正好符合常见的同步状态机设计需求,因此输入状态检测模块采用时序逻辑电路设计。而FIFO的写入时序是同步的,即当Full信号为低且在检测到写使能信号为高的同一个周期内,数据将会被写入FIFO。而按照时序逻辑电路的设计方式,状态检测与通道切换至少将消耗掉一个时钟周期,这与同步读写的时序相冲突。为了避免数据丢失,在输出状态检测模块使用触发式的组合逻辑设计来避免额外的时钟消耗。
2.3 软件调度功能
由于单个方向上的傅里叶变换计算由PL侧的硬件完成,因此程序主要功能如图3所示。首先读取SD卡中的图像信息,然后将图像数据格式转为灰度并用浮点数表示,创建同等大小的全为零的图像数据作为虚数图像,并与之前的转换结果进行复数图像数据的拼接。然后通过Xillybus总线配置PL侧的多路FFT计算模块,并随后将复数图像数据按一次多行的形式依次传入多路FFT计算模块,并按顺序接收变换结果。对得到的复数形式的中间图像数据进行矩阵转置排序,完成后再按顺序将转置后的数据传入多路FFT计算模块完成另一个方向的傅里叶变换,并得到最终的结果。
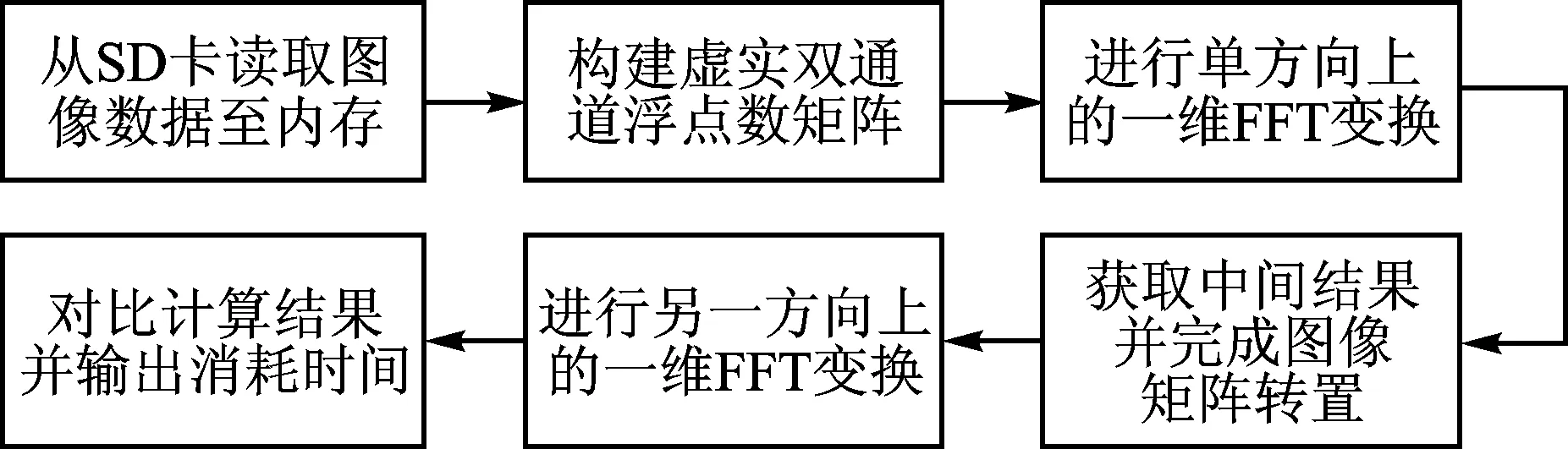
图3 软件功能图
3 实验测试与结果分析
本文采用Xilinx公司推出的Zynq-7000全可编程SoC系列器件中的XC7Z020芯片提供的异构平台完成整个方案的设计。其主要特点是在芯片内集成了一颗双核ARM Cortex-A9嵌入式处理器与一块性能等同于Xilinx Artix-7系列的FPGA,且两者经由片内AXI高速总线紧密互联[9]。其中处理器系统部分的CPU主频为667 MHz,基于ARMv7架构。每个CPU都分别带有支持单指令多数据功能的多媒体协处理器,独立的存储管理单元,32 KB的一级指令缓存与数据缓存,独立计时器与看门狗定时器。两个CPU共享有512 KB大小的二级缓存。可编程逻辑部分的资源主要由85k个逻辑单元,220个DSP48E1 Slice,140个大小为36 KB的双端口BRAM,53 200个查找表(LUT)构成。
实验测试平台采用了Digilent公司推出的ZedBoard。ZedBoard是基于Xilinx Zynq-7000的低成本开发板设计,同时也是一个开源硬件平台,所有设计资料完全公开,可以在ZedBoard社区获取。该平台主要由型号为XC7Z020CLG484的SoC器件为核心,外扩容量为512 MB的DDR3内存,以及JTAG、VGA、USB-OTG、串口及SD卡等常用外设构成。
实验测试的主要目的是获取完成计算所需要的时间。因此,在软件设计部分利用Linux系统提供的函数gettimeofday()来获取计算所消耗的实际时间,其精度为1 μs。实验具体过程是:利用串口终端软件Putty访问ZedBoard上电启动后的Linux系统并运行程序,得到输出结果并进行统计。部分测试结果如图4所示,图中运行的程序功能是:对一幅分辨率为1024×1024的图像利用双通道FFT计算模块进行二维快速傅里叶变换并输出计算时间与部分计算结果。由图可知,两次消耗时间分别为497 927 μs与504 322 μs。同时将上述计算结果分别与使用双精度浮点数作为数据类型的MATLAB二维傅里叶变换程序运行结果、使用单精度浮点数作为数据类型的基于OpenCV库的C++程序运行结果进行对比,得出结果基本一致,误差在可接受范围内的结论。
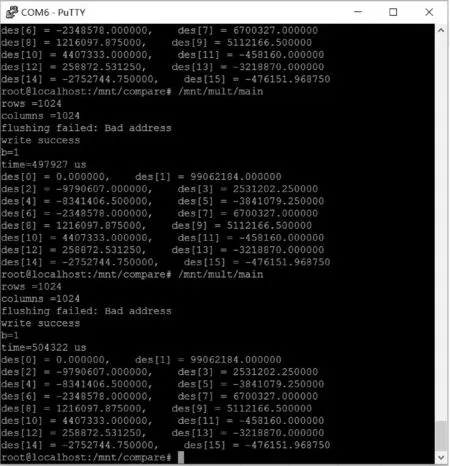
图4 实验测试部分结果截图
分别对不同分辨率的图像以及不同通道数目的硬件系统进行实验测试,并将其结果与OpenCV提供的二维傅里叶变换的软件实现在ZedBoard上的测试结果进行对比,得到表1的数据。
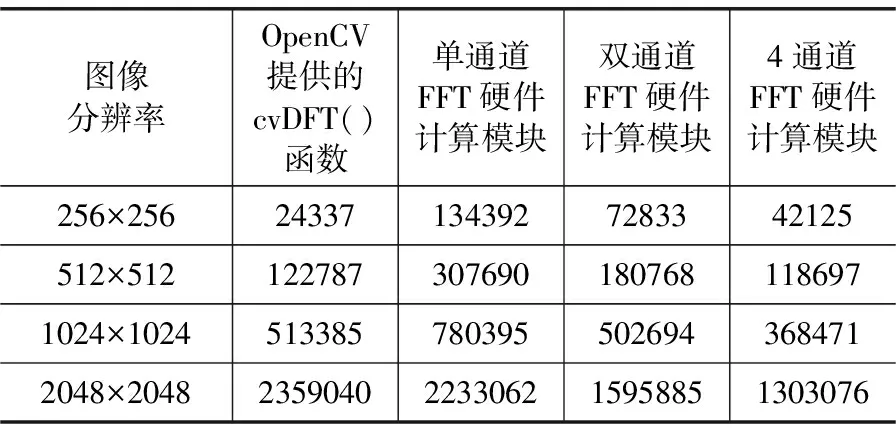
表1 不同分辨率下多种计算方式消耗时间统计(单位:μs)
由表1中的数据可以看出,通道数的增加提高了使用FPGA完成计算的速度。随着图像分辨率的增大,利用FPGA完成计算所消耗的时间接近线性增长,显著低于软件计算所消耗时间的增长率。
因此,对高分辨率图像的处理过程中增加硬件计算部分的并行通道数,可以显著提升计算速度。而对于低分辨率图像,由于数据量小,变换所需的计算时间远小于数据传输的时间,在这种情况下利用多通道硬件加速的效果不明显。所以对于低分辨率的图像,可以通过增大缓存容量来减少传输次数,进而减少不必要的传输时间损耗。例如,对于一幅分辨率为256×256的图像,使用单通道FFT硬件计算模块进行变换时,通过增大PL侧数据输入输出的FIFO深度至8 192或者更大,并提高每次传输数据数量至16行,可以将整个计算所需的数据传输次数从512次降低至8次,改进后实验结果如图5所示,消耗时间约为13 566 μs,由表1中的数据对比可知,这不仅远低于4通道FFT硬件模块计算的时间花费,也低于流行的开源视觉库OpenCV提供的软件计算消耗时间,起到了明显的硬件加速效果。值得一提的是:对于高分辨率图像,由于计算时间远高于数据传输时间,因此增大缓存并不能有效地提升整个系统的处理速度,而且由于其数据量过大,减少同样的传输次数将带来更大的资源消耗。
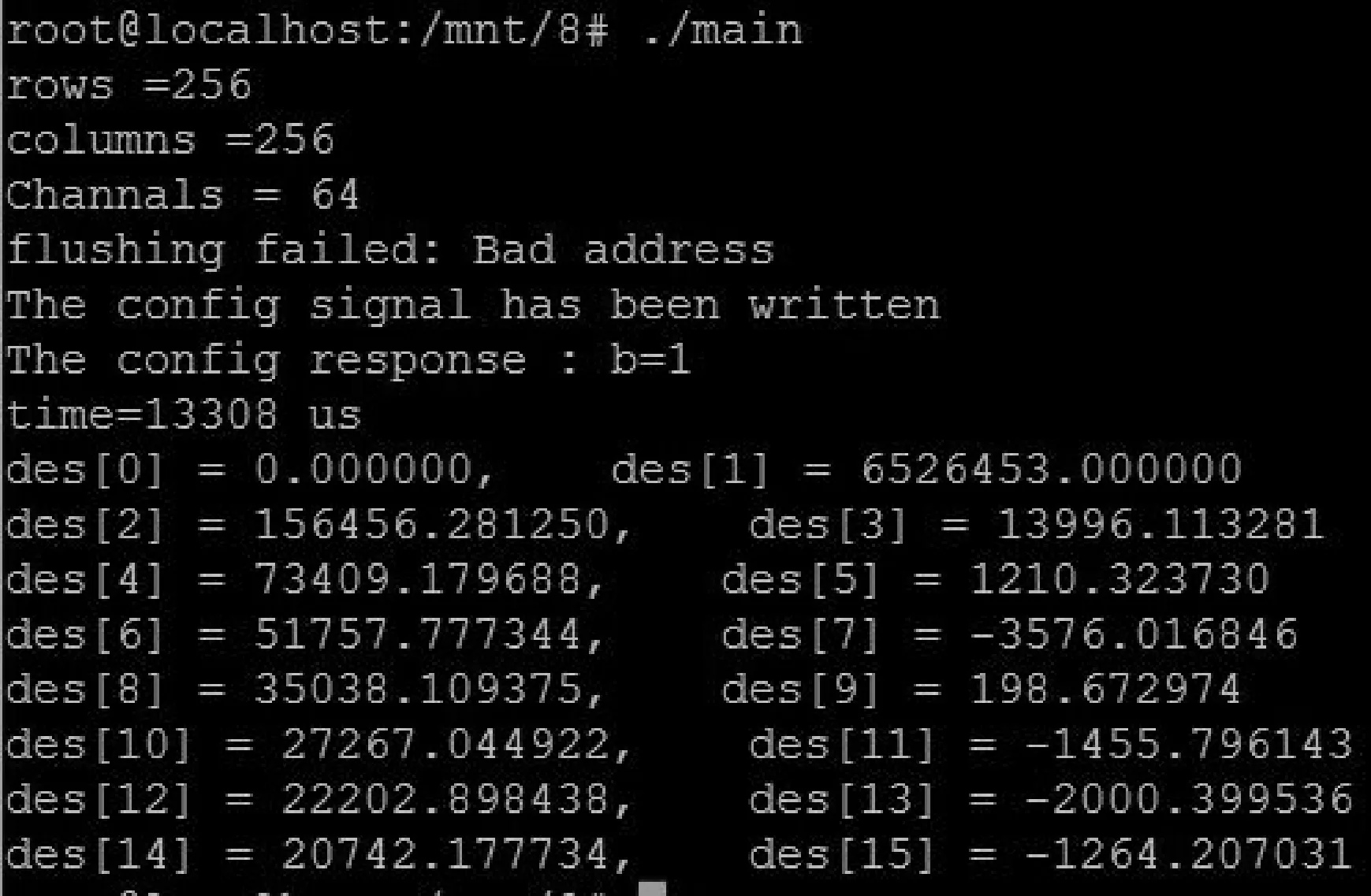
图5 提高缓存后的实验测试结果
结 语

[1] Russell M,Fischaber S.OpenCV based road sign recognition on Zynq[C]//IEEE International Conference on Industrial Informatics.IEEE,2013:596-601.
[2] 张全,鲍华,饶长辉,等.GPU平台二维快速傅里叶变换算法实现及应用[J].光电工程,2016(2):69-75.
[3] 李硕,王茜蒨.基于FPGA的二维FFT实现[C]//中国电子学会青年学术年会, 2012.
[4] 方睿,刘加贺,薛志辉,等.卷积神经网络的FPGA并行加速方案设计[J].计算机工程与应用,2015,51(8):32-36.
[5] 陈实.大邻域图像处理硬件加速的研究[D].北京:清华大学,2009.
[6] 吴良晶,曹云峰,丁萌,等.SoC FPGA的视觉算法加速系统设计[J].单片机与嵌入式系统应用,2016,16(11):58-62.
[7] 王晓璐.基于Zynq的LS-SVM算法加速器设计[D].哈尔滨:哈尔滨工业大学,2015.
[8] Kryjak T,Komorkiewicz M,Gorgon M.Real-time hardware-software embedded vision system for ITS smart camera implemented in Zynq SoC[J].Journal of Real-Time Image Processing,2016:1-37.
[9] Crockett L H,Elliot R A,Enderwitz M A,et al.The Zynq Book:Embedded Processing with the Arm Cortex-A9 on the Xilinx Zynq-7000 All Programmable Soc[M].Strathclyde Academic Media,2014.
[10] Hunter T M,Denisenko D,Kannan S,et al.FPGA Acceleration of Multifunction Printer Image Processing using OpenCL,2014.
陈龙(硕士研究生),主要研究方向为嵌入式应用开发;曹力(教授),主要研究方向为导航与控制、计算机视觉。
