基于深度学习的Android恶意软件检测系统的设计和实现
2018-02-28王涛李剑
王 涛 李 剑
(北京邮电大学计算机学院 北京 100876)
随着科技的发展,近年来手机已经成为人们日常生活的必备品.根据IDC季度手机追踪报告,在2017年第1季度各大公司全球出货量达到3.443亿部[1].自从2010年8月卡巴斯基首次发现短信特洛伊木马程序以来,Android恶意软件的数量急剧增加.从那时起,Android恶意软件不断发展,越来越复杂,也不断地增强措施避免被检测出来.正如Zhou等人[ 2 ]的研究所揭示的,恶意软件家族通过增加代码混淆、隐蔽的命令和控制通信通道等正在不断加强躲避检测.这些反分析技术不仅降低了传统基于签名检测的效果,而且显著提高了在Android应用程序中发现恶意行为和代码的难度.专门针对Android设备的恶意软件自2010年以来以惊人的速度增长.
研究表明,由于难以发现恶意行为,Android恶意软件可能在3个月内被忽视[3].大多数反病毒检测能力依赖于更新的恶意软件签名库的存在,因此,一旦发生未遇到的恶意软件传播,用户就处于危险之中.由于反病毒供应商的响应时间可能在几个小时到几天之间,来识别恶意软件,生成签名,再更新到其客户的签名数据库,黑客有一个实质性的机会去攻击中毒用户,但是基于签名的防病毒引擎平均需要48 d才能发现新的威胁.尽管谷歌推出了“Bouncer”,为其应用程序商店筛选提交恶意行为的应用程序,很多用户还是处在风险之中.
显然,我们需要改进检测方法,考虑到Android恶意软件的发展和迫切需要减少出现以前未见过的病毒所带来的威胁的机会.因此,不同于现有的Android恶意软件工作,本文提出了一种基于一般深度学习的检测模型,有效地提高了恶意代码检测的性能.
1 相关工作
近年来,随着智能手机市场的不断增加,基于Android的恶意软件检测技术得到了积极的研究.APK文件是在Android操作系统上的安装软件,每个APK必须有一个Manifest文件.该文件提供了关于Android操作系统应用程序的基本信息.它声明应用程序必须具有哪些权限,以便访问API的受保护部分,并与其他应用程序交互.为了保护Android用户,应用程序对资源的访问受到严格的权限限制.应用程序必须获得权限才可以使用,例如蓝牙或摄像机之类的敏感资源.Sanz等人[4]通过从应用程序自身提取的权限组合,开发了一种基于机器学习检测的工具.ADROIT项目[5]中通过查看和分析运行时的meta-data去检测恶意程序,建立一个高精度的分类器.
文献[6]提出了一个基于机器学习的Android恶意软件检测系统.基于离线方式的支持向量机(SVM)提取和训练了权限和控制流图(CFG)特征,然而该实验在实时检测时仍不能很好地解决问题.文献[5,7]分析了权限和其他特性,并应用各种机器学习分类器达到86%的准确率.Zhou等人[2]根据所请求的权限和行为方面的相似性,如安装方法,检测Android恶意软件.
研究的另一个方面是对系统调用的分析.Xiao等人[8]提出了一个新的方案称为人工神经网络(ANN)对共生矩阵的机器人(ANNCMDroid),利用共生矩阵挖掘相关的系统调用.他们的主要观察结果是系统调用的相关性在恶意软件和良性软件之间是显著不同的,它们可以用共生矩阵精确地表达.在DroidAPIMiner[9]中,利用良性应用程序和恶意应用程序的不同API调用频率进行分析,生成了不同的分类器来识别恶意软件.
Bartel等人[10]分析了各种应用程序,发现有些应用程序声明权限,但实际上没有使用.因此,仅通过对权限的清单文件分析并不能给出准确的结果.在Android框架中,一旦安装了应用程序,在运行时就会调用一组API.每个API调用都与特定权限相关联.当调用API时,Android操作系统检查用户是否批准了它的相关权限.只有当它匹配时,它才能继续执行某个API调用.因此API调用提供了一个信息,一个许可是否被实际使用.
动态特征指的是应用程序在移动设备上的安装行为,包括应用程序在操作系统或网络中的行为.应用程序使用系统调用来执行特定的任务,如读、写和打开,因为它们不能直接与Android操作系统交互.当在用户模式下发出系统调用时,Android操作系统切换到内核模式以执行所需的任务.此外,大多数应用程序需要网络连接.在Zhou等人[2]研究中,他们收集的Android恶意软件样本中有93%需要网络连接,以便与攻击者连接.
浅层学习无法学习到更全面的Android恶意软件的安全语义信息;本文基于深度学习研究Android恶意软件检测问题,提高了特征对Android软件的安全语义信息的表达,增加模型对安全语义信息的学习和理解能力.本系统采用基于深度学习的SDA方法研究Android恶意软件的分类问题.SDA方法是多隐层神经网络结构,可以逐层分析,优化每一层得到的特征向量表示,因此它提取的特征向量可以更准确地表达Android软件的安全语义信息,提高检测结果.
2 系统设计
本文设计并实现了一种基于深度学习算法的Android恶意软件检测的系统SDADLDroid(an Andriod malware detection based on SDA deep learning algorithm),该系统通过对爬虫爬取到的8 000个良性软件和7 000个恶意软件进行特征提取,对数据进行分析降维后将选择到的961个特征利用深度学习算法SDA(stacked denoising autoencoder)建立一个3层神经网络后,经过数据集交叉验证,确定该方法的检测正确率达到95.8%,丰富了Android恶意软件的检测方法,提高了检测效果.
2.1 系统设计
如图1所示,系统主要分为三大部分,分别是编写网络爬虫收集数据集,收集每个APK的静态代码特征和动态行为特征,特征降维后进行深度学习并建立良好的神经网络进行检测.
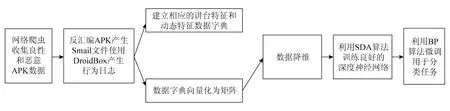
图1 系统设计图
2.2 系统实现
根据研究表明,Google Play上的应用一般被认为是良性的,所以我们编写了网络爬虫,随机地在其中选取了8 000个APK作为本次研究的良性应用数据集,并且我们已经收集了7 000多个恶意应用软件.因此本次实验中,所有的实验数据都是现实世界中发布的已知的良性和恶意应用软件,实验数据有良好的真实性.
我们对于每一个APK都利用Apktool进行了反汇编,生成了Smail文件和Manifest文件,对其中重要的静态代码特性(例如权限、IP地址等)进行抽取,然后对于每一个APK都开启一个虚拟机并使用DroidBox对生成的Log日志中一些敏感的行为信息进行抽取.将这些静态代码特征和动态行为特征作为特征库,利用PCA数据降维,对于降维后的数据集利用SDA算法构建神经网络,最后利用BP算法微调结果,这样我们构建的神经网络就可以用于分类任务了.
2.3 改进的SDA算法
2.3.1传统自编码
对于BP算法在训练多层神经网络所出现的各种问题[11],Hinton等人[12-14]提出了自动编码机(Autodencoder),为深度学习开创了新思路.自动编码机是一种无监督的算法,不需要对样本进行标注,就可以有效利用样本信息,提高模型性能.传统的自动编码机分为编码和解码2部分.编码阶段将d维输人向量x定性映射到d′维隐层表示y,映射函数通常选用Sigmoid:
y=f(x;θ)=s(Wx+b),
(1)
其中W∈d′×d,b∈d′×1.式(1)中s是非线性函数,如Sigmoid.W是输入层到中间层的连接权值,b为中间层的bias.解码阶段将得到的结果表示为y,并且定性地映射到d维重构向量z:
z=g(y;θ′)=s(W′y+b′),
(2)
其中W′∈d′×d,b′∈d′×1.式(2)中s是非线性函数,如Sigmoid.W′是输入层到中间层的连接权值,b′为中间层的bias.这样,自编码训练就在于用给定的N个样本优化重构误差,优化目标交叉熵或者均方误差L为
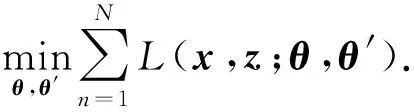
(3)
2.3.2降噪自编码
Vincent等人[15]指出,传统自编码在不加生成约束的情况下,很容易直接将输入向量复制到输出向量,或者只能产生微小的改变,此时模型只能产生较小的重构误差,表现非常差.当测试数据和训练数据相差很大,并且也不符合同一分布时,训练效果也表现得非常差.为此,Vincent等人[15-16]提出了新的自编码算法,即降噪自编码(denoising autoencoder, DAE)算法,如图2所示.该算法将样本x进行毁坏改造,以一定的概率让某些输入层节点的值置0,从而使原样本变为x′,再用x′训练隐藏层:
y=f(x′;θ)=s(Wx′+b),
(4)
其余过程采用式(2)(3),与传统AE相同.
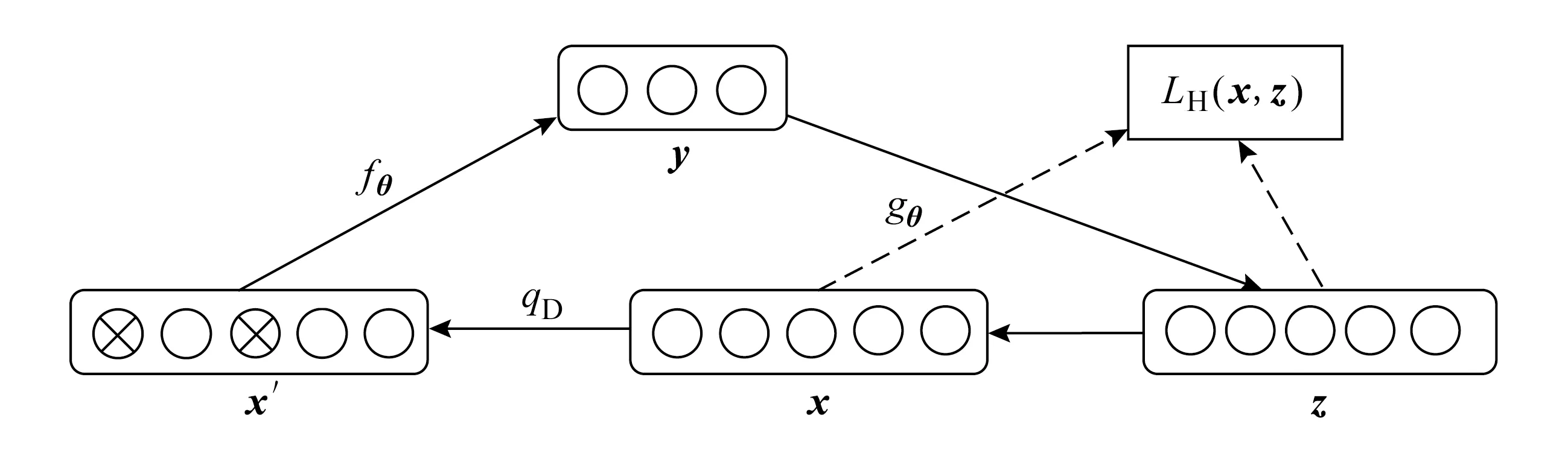
图2 降噪自编码(DAE)
2.3.3构建分类模型
使用隐层输出y作为新的输人特征,多次重复DAE,就构成了SDA深度结构.Bengio等人[17-18]指出,不同的特征表示能突显或剔除数据的某些解释因子,从而具有不同的表示能力. 因此,SDA过程的目的在于寻找到一个比原始特征更适合任务要求的特征表示方法.完成深度结构后,添加节点与类别个数相同的输出层,将最后得到的特征表示作为该输出层的输入.接下来将保存的训练得到的各层权值矩阵、偏置项等作为初始参数,用BP算法微调整个SDA神经网络,就能用于分类任务.
3 实验与分析
3.1 数据描述
在本次实验中,我们使用自己爬取的7 000个良性软件和6 000个恶意软件作为训练数据,1 000个良性软件和1 000个恶意软件作为验证数据.
3.2 实验评测标准
本实验采用准确率ACC,TPR,FPR,查准率P(precision),查全率R(recall),f-measure作为评价指标来衡量模型的效果.TP(true positive),FN(false negative),TN(true negative),FP(false positive).各个标准的计算公式和含义如下.
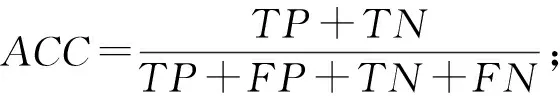
TPR:被正确分类的样本数目比率;
FPR:被错误分类的样本数目比率;
查准率:P=提取出的正确信息条数提取出的信息条数;
查全率:R=提取出的正确信息条数样本中的信息条数;
f-measure:准确率和召回率加权调和平均.
表1展示了各种算法评价指标:
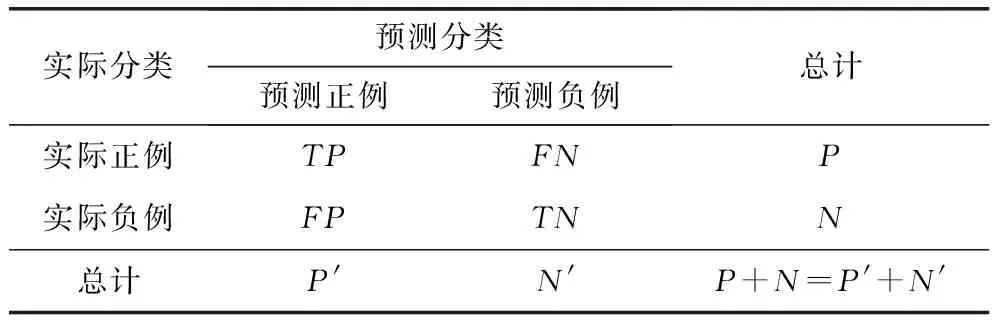
表1 算法评测指标
3.3 实验结果
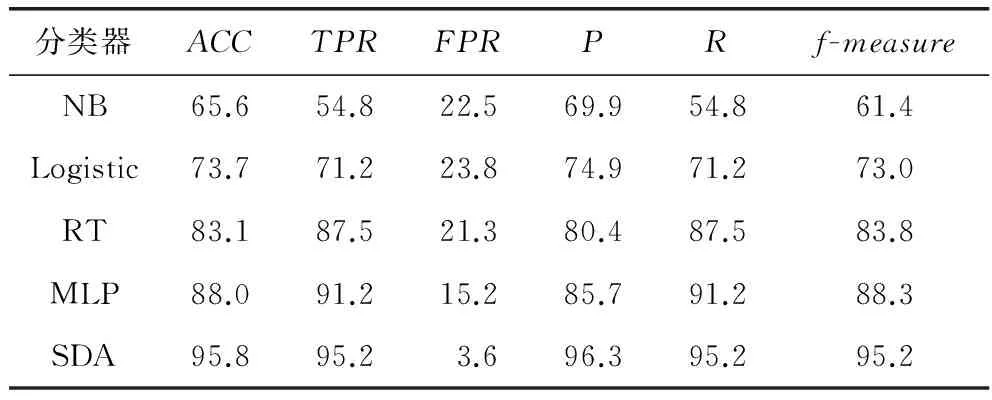
本次实验中采用了10份验证集和5个分类器,表2显示了5个分类器中不同的准确率ACC、准确肯定率TPR、错误肯定率FPR、查准率P、查全率R以及F测度f-measure.
表2实验结果
%
分类器ACCTPRFPRPRf-measureNB65.654.822.569.954.861.4Logistic73.771.223.874.971.273.0RT83.187.521.380.487.583.8MLP88.091.215.285.791.288.3SDA95.895.23.696.395.295.2
3.4 实验结果分析
从实验结果分析可以看出,我们构建的3层神经网络[700,700,700]能够达到最好的准确率,是一个良好的分类器,对比其他一般机器学习算法,深度学习能够更好地完成分类任务.深度学习作为一种特征学习方法,可以把原始数据通过一些简单的但是非线性的模型转变成为更高层次的、更加抽象的表达.通过足够多的转换的组合,非常复杂的函数也可以被学习.传统的方法是手工设计良好的特征提取器,这需要大量的工程技术和专业领域知识.但是如果通过使用通用学习过程而得到良好的特征,那么这些都是可以避免的.这就是深度学习的关键优势.而我们的系统恰好就采用深度学习的优势去避免浅层机器学习的劣势,从而解决Android安全问题.因此,本系统能达到更高的可信度和更好的效率.
4 结束语
通过全面分析Android应用软件中的安全隐患问题,提出相应的对策和建议.本文提出了基于深度学习的BP算法微调SDA神经网络的方法,通过实验表明,该模型可以调高检测精度,提升检测性能,拥有较高的准确率.
[1]IDC. Smartphone OS market share[EB/OL].[2017-04-27]. https://www.idc.com/promo/smartphone-market-share/os
[2]Zhou Y, Jiang X. Dissecting Android malware: Characteri-zation and evolution[C] //Proc of IEEE Symp on Security and Privacy. Piscataway, NJ: IEEE, 2012: 95-109
[3]Tam K, Feizollah A, Anuar N B, et al. The evolution of Android malware and Android analysis techniques[J]. ACM Computing Surveys, 2017, 49(4): 76
[4]Sanz B, Santos I, Laorden C, et al. PUMA: Permission usage to detect malware in Android[C] //Proc of Int Joint Conf on CISIS’12-ICEUTE’12-SOCO’12 Special Sessions. Berlin: Springer, 2013: 289-298
[5]Martín A, Calleja A, Menéndez H D, et al. ADROIT: Android malware detection using meta-information[C] //Computational Intelligence. Piscataway, NJ: IEEE, 2017: 1-8
[6]Sahs J, Khan L. A machine learning approach to Android malware detection[C] //Proc of European Intelligence and Security Informatics Conf. Los Alamitos, CA: IEEE Computer Society, 2012: 141-147
[7]Sanz B, Santos I, Laorden C, et al. MAMA: Manifest analysis for Malware Detection in Android[J]. Cybernetics & Systems, 2013, 44(6/7): 469-488
[8]Xiao X, Wang Z, Li Q, et al. ANNs on co-occurrence matrices for mobile malware detection[J]. KSII Trans on Internet & Information Systems, 2015, 9(7): 2736-2754
[9]Aafer Y, Du W, Yin H. DroidAPIMiner: Mining API-level features for robust malware detection in Android[M] //Security and Privacy in Communication Networks. Berlin: Springer, 2013: 86-103
[10]Bartel A, Klein J, Traon Y L, et al. Automatically securing permission-based software by reducing the attack surface: An application to Android[C] // Proc of IEEE/ACM Int Conf on Automated Software Engineering. Piscataway, NJ: IEEE, 2012: 274-277
[11]Bengio Y. Learning deep architectures for AI[J]. Foundations and Trends in Machine Learning, 2009, 2(1): 1-127
[12]Hinton G E, Osindero S, Teh Y W. A fast learning algorithm for deep belief nets[J]. Neural Computation, 2006, 18(7): 1527-1554
[13]Bengio Y, Lamblin P, Popovici D, et al. Greedy layer-wise training of deep networks[C] //Advances in Neural Information Processing Systems 19. Cambridge: MIT Press, 2007: 153-160
[14]Lecun Y, Bottou L, Bengio Y, et al. Gradient-based learning applied to document recognition[J]. Proceedings of the IEEE, 1998, 86(11): 2278-2324
[15]Vincent P, Larochelle H, Lajoie I, et al. Stacked denoising autoencoders: Learning useful representations in a deep network with a local denoising criterion[J]. Journal of Machine Learning Research, 2010, 11(6): 3371-3408
[16]Vincent P, Larochelle H, Bengio Y, et al. Extracting and composing robust features with denoising autoencoders[C] //Proc of the 25th Int Conf on Machine Learning. New York: ACM, 2008: 1096-1103
[17]Bengio Y, Delalleau O. On the expressive power of deep architectures[C] //Proc of Int Conf on Discovery Science. Berlin: Springer, 2011: 18-36
[18]Bengio Y, Courville A, Vincent P. Representation learning: A review and new perspectives[J]. IEEE Trans on Software Engineering, 2013, 35(8): 1798-1828
