多支持度下用户行为序列模式挖掘方法研究
2018-02-27徐启寒徐开勇戴乐育
徐启寒 徐开勇 郭 松 戴乐育
(信息工程大学 河南 郑州 450001)
0 引 言
用户行为序列模式挖掘是指挖掘出所有满足指定最小支持度的用户所有频繁行为序列的过程,在用户行为模式分析与用户轮廓刻画等方面均具有突出的模式表达能力。
序列模式挖掘最早于1995年由Agrawal等[1]提出。区别于关联规则挖掘,序列模式挖掘引入时间属性,具备更强的数据表达能力。除Apriori算法[2]、GSP算法[3]、Prefixspan[4]以及SPAM算法[5]等经典算法外,近几年以来,一些扩展性更强、挖掘效率更高的方法不断被提出。Le等[6]通过对候选序列提前剪枝来缩小搜索空间,提出一种高效的挖掘算法STATE-SPADE;Zihayat等[7]提出一种基于内存自适应的HUSP算法MAHUSP,解决数据流更新引起的内存资源限制问题;Kemmar等[8]提出一种前缀投影全局约束方法,压缩子序列关联以及频率约束,解决现有模型约束规模过大问题。
现有研究虽在算法性能和挖掘效果上具有一定的优势,但由于采用基于单一支持度的支持度阈值设置方式,未考虑用户自身行为之间的差异性,无法满足用户行为模式分析的实际应用需求。在模式挖掘过程中,若支持度阈值设置过高,将导致遗漏发生频率低但重要性高的操作,影响挖掘结果的准确性。若支持度阈值设置过低,则将导致待挖掘数据规模过大,严重影响挖掘效率,同时产生大量对分析无用的冗余信息。所以在用户行为模式分析中需要采用基于多支持度的模式挖掘方法。
多支持度是指为不同项分别设置不同的最小支持度。该概念最早由Liu等[9]提出,并提出了基于Apriori算法的扩展算法MSApriori。该算法利用向下封闭性来缩减搜索空间,但是很容易导致组合爆炸。文献[10]提出一种基于MIS-Tree结构的条件频繁模式增长算法CFP-growth,它通过递归地创建条件树来生成频繁模式;文献[11]提出了一种CFP-growth算法的增强算法CFP-growth++,采用压缩树结构挖掘频繁模式;文献[12]提出一种多最小支持度下基于MapReduce的频繁模式挖掘框架,挖掘效率更高。
目前现有的基于多支持度的模式挖掘研究多集中在频繁项集的挖掘上,针对带有时序属性的序列模式挖掘研究较少。Liu[13]首次将多最小支持度概念引入序列模式挖掘中,并提出MS-GSP算法。但该算法采用候选序列生成测试的方式,导致运行时间以及内存消耗急剧增加;Huang[14]在挖掘模糊量级序列模式(FQSP)问题中引入多支持度概念及可调整的隶属度函数,以此来解决单一支持度阈值及单一隶属度函数所致的实际不可用性问题。
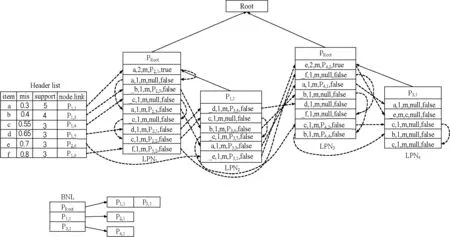
本文以LP-tree结构[15]为基础,提出一种基于多最小支持度的前缀树结构MSLP-tree,并进一步提出基于MSLP-tree的序列模式增长算法MSLP-growth。LP-tree是一种线性前缀树,本文在此基础上引入多最小支持度等属性,来解决用户行为序列模式挖掘中敏感稀有项的问题。在树的构成上,采用相同前缀序列分枝整合的方法压缩结构,节约内存空间,并且该结构能够存储所有的序列模式,便于序列模式的分析和增量更新的需求。同时,本文所提出的算法无需多次扫描数据库,不产生候选序列,挖掘效率较高,空间资源消耗较小。
1 用户行为序列模式相关定义
设I={i1,i2,…,in}为项目的非空集合,集合t⊆I为项集,项集内各项间无先后顺序。序列数据库S中序列s可记为(sid,s),其中sid为s在S中的标识符。序列s由项集有序排列而成,s可记为s=

表1 示例序列数据库
给定序列s1=<α1,α2,…,αn>,序列s2=<β1,β2,…,βm>,n≤m,如果存在1≤j1 定义1支持度。对于序列数据库S中序列s,s的支持度为S中包含序列s的个数占S中序列总数的比值,记为sup(s)。给定支持度阈值min_sup,如果序列s在S中的支持度不低于min_sup,即sup(s)≥min_sup,则称序列s为频繁序列模式。 定义2项集最小支持度。设项目集合I中数据项ij的最小支持度为mis(ij),则I中所有项的最小支持度可记为{mis(i1),mis(i2),…,mis(in)}。对于项集t={i1,i2,…,ik},t⊆I,项集t的最小支持度记为MIS(t)=min{mis(i1),mis(i2),…,mis(ik)}。表1中各数据项最小支持度如表2所示。 表2 最小支持度表 定义3序列最小支持度。给定序列s= 定义4极小最小支持度。设LMS(least minimum support)为项目集合I中所有项目最小支持度的最小值,则LMS可记为min{mis(i1),mis(i2),…,mis(in)}。 定义5对于任意序列s,如果sup(s)≥MIS(s),则s为频繁序列或者说s是频繁的;如果sup(s) 性质1在多支持度下的序列模式中,如果一个序列是不频繁的,但它的超序列可能是频繁的。 性质2对于序列模式X和Y,X⊆Y,如果sup(X) 本节首先描述MSLP-tree的结构,然后介绍构造过程。 MSLP-tree主要由四部分构成,包括根节点Root、头表Header List、树节点LPNc以及枝节点信息表BNL: 1) 根节点标记为Root,值为空。 2) 头表(Header List)中主要包括四个属性:数据项名称item.name、支持度support、数据项最小支持度mis、连接具有相同名称数据项节点之间的连接点node.link。 3) 树节点LPN(Liner Prefix Node)内节点存储频繁项信息,包括数据项名称item.name、该项支持度support、序列当前最小支持度值mis、连接点node.link以及枝节点信息branch information。其中,各LPN内首节点为该LPN表头,用以连接其父节点;LPN结构组成可表示为LPN={ 4) 枝节点表BNL(Branch Node List)包括各枝节点及其对应各子节点信息。BNL表示为BNL={{B1→C1,1,C1,2,…,C1,j},{B2→C2,1,C2,2,…,C2,j},…,{Bi→Ci,1,Ci,2,…,Ci,j}},Bi为第i个枝节点指针,Ci,j为Bi第j个子节点指针。设Pc,k为LPN内某一节点的指针,它表示LPNc第k个节点的指针,PRoot为指向根节点的指针。 综上,MSLP-tree可记为MSLP-tree={Header List,BNL,LPN1,LPN2,…,LPNc}形式,其中c为树中LPN的总个数。MSLP-tree的结构示例如图1所示。 图1 MSLP-tree结构 MSLP-tree构造流程如算法1。具体构造过程如下: Step1扫描序列数据库S(其中所有序列已按最小支持度值升序排列),找出所有数据项i,并对其进行支持度计数,将支持度小于LMS的项删除,所有满足LMS模式的项记入头表中,并按mis升序排列。 Step2在树中插入第一个序列,序列首项记为ik,长度为1。若某一项i为项集扩展项,则在该项前添加符号“_”,记为_i。各项按序列中顺序依次记入LPN中,各项支持度计数+1,记为LPN1。LPN1内部节点的个数为序列长度+1,即包括LPN1表头。将LPN1与根节点相连,LPN1内首节点指针指向根节点Root,P1,1→PRoot。此时生成BNL,BNL(PRoot)→BNL(Pc,1)。 Step3继续将数据库其他序列插入树中,数据处理同Step2。此时分三种情况,若新序列与树中已插入序列LPNc前k项相同,则将前k项插入LPNc中,其余n-k项生成新LPN,LPNc前k项支持度+1,LPNnew首项即原序列第k+1项,且Pnew,k+1→Pc,k,BNL(Pc,k)→BNL(Pnew,k+1);若新插入序列与树中已插入序列首项均不同,则将序列所有项记入新LPN中,此时根节点产生新子节点,Pnew,1→PRoot,BNL(PRoot)→BNL(Pnew,1);若新序列所有项与已插入序列前k项相同,则将原序列前k项支持度+1,自第k+1项移出生成新LPN,Pnew,1→Pc,k,BNL(Pc,k)→BNL(Pnew,1)。 Step4记LPN内节点为qc,k,将所有LPN中具有子节点的内节点的“branch information”记为“true”,否则记为“false”。将所有同名称项节点自node.link起始链接,若无节点间连接信息node.link位记为null,BNL信息依据LPN连接情况补充完整。 至此,MSLP-tree构造完毕。 算法1MSLP-tree构造算法 输入:序列数据库S,数据项集合I,项目最小支持度表,极小最小支持度LMS 输出:MSLP-tree Step1 1) 扫描序列数据库S,找出所有数据项i; 2) Generate Root; //创建树的根节点 3) For each itemiinI; 4) Count the support ofi; //对i进行支持度计数; 5) If sup(ij) //删除非LMS模式项 6) end if; 7) Create Header List; //生成头表,数据项按MIS升序排列; 8) end for; Step2 9) For each itemiins; 10)ik←first item,l←the length; //ik为s首项,l为s长度 11) end for; 12) 在树中插入序列s,记为LPNc; 13) If i is an extension item,i=_i; //i为项集扩展,在i前添加“_” 14)Pc,kS++; //各项支持度+1 15) Link theLPNcwith Root; 16)PRoot←Pc,1; 17) Generate BNL; //生成BNL; 18)BNL(PRoot)→BNL(Pc,1); //将PRoot记入branch node list中,Pc,1记入child node list中; 19) end if; Step3 20) Insert next sequence; //继续将剩余序列插入树中 21) Ifik=Pc,k,ik⊆Snew,Pc,1⊆BNL(PRoot), //新序列中前k项与LPNc中前k项相同 22) ThenPc,kS++; //LPNc前k项支持度各+1 23) GenerateLPNnew,ik+1=Pnew,1; //序列第k+1项为LPN首项,序列长度为l=n-k+1 24)Pc,k←Pnew,1; 25)BNL(Pc,k)→BNL(Pnew,1); 26) Else ifi1≠Pc,1,i1⊆Snew,Pc,1⊆BNL(PRoot); //新序列的第1项和Root所有子节点均不等 27) GenerateLPNnew; //生成新LPN 28)Pnew,kS++; 29)PRoot←Pnew,1; 30)BNL(Pc,k)→BNL(Pnew,1); 31) Else ifin=Pc,k,k≠n,in⊆Snew,Pc,k⊆BNL(PRoot); //如果新序列的所有项与LPNc前k项相同 32)Pc,kS++; //LPNc前k项支持度+1 33) Remove the restn-kitem ofLPNcas the newLPN; 34)Pnew,kS++; 35)Pc,k←Pnew,1; 36)BNL(Pc,k)→BNL(Pnew,1); 37) end if; 38) Go to line 17 for next sequence ; Step4 39) ifqc,k有子节点,thenb=true; 40) elseb=false; 41) link all nodes with same name; //将相同名称节点相连 42) Ifqhas no link, then node.link=null; 43) end if; 44) Return tree 对于表1中序列,其MSLP-tree构建过程如下: 1) 扫描数据库S,找出所有项并对各项支持度进行计数,其中a=4,b=4,c=3,d=3,e=3,f=3,g=1;根据表2中各项最小支持度值,LMS=0.3,sup(g) 2) 构建树的根节点Root,将序列s1= 3) 将序列s2=<(ad)c(bc)(ae)>插入树中,检查序列中各项均在头表中,其与s1具有相同前缀a,故将”_d”作为a的子节点,构造新的LPN,新的LPN首节点为”_d”,其指针指向LPN1中节点a,同时节点a支持度加1,将所有项按在序列中的顺序依次记入LPN2中,LPN2中各节点支持度记为1;在BNL中,将P1,1记录到枝节点表中,P2,1记录到子节点表中,BNL(P1,1)→BNL(P2,1),LPN2表头记为P1,1。 4) 将序列s3=<(ef)(ab)(df)cb>插入树中,s3中各项均在头表项中,s3与s1具有不同前缀,创建新的LPN,将各项按顺序记入LPN中,新LPN3内首节点项为e,其指针P3,1指向根节点Root,LPN3中所有节点支持度记为1;在BNL中,将P3,1添加到PRoot对应的子节点表中,BNL(PRoot)→BNL(P3,1),LPN3表头记为PRoot。 5) 将序列s4= 6)S中所有序列插入完毕,头表中自node.Link起始,链接所有名称相同项,各LPN内节点属性信息node.link及branch information补充完整,至此,MSLP-tree构造完毕。前缀树的最终结构如图2所示。 图2 示例前缀树 基于MSLP-tree结构,序列数据库中所有序列都可以在树中找到其唯一路径,且树中只存在所有满足mis和LMS模式的项。对于所有满足最小支持度条件的序列模式,根据头表node.link链接信息,遍历整个MSLP-tree,即可得到所有符合支持度要求的模式。在MSLP-tree的构建过程中,将序列重合部分进行分枝整合,能够压缩树的结构,减少路径遍历次数。同时可以提前过滤不可能成为频繁项的信息,从而减少中间冗余信息。 树的遍历过程采用深度优先方式,从根节点开始依次遍历所有节点。首先,找到当前节点的所有子节点,以及所有与其同名项;然后,通过子节点以及相同项找到该路径下在树中最后一个节点;最后,遍历所有的子节点及其兄弟节点,直到不再有未遍历的节点。 算法主要思想是将不同前缀项下的所有路径划分于不同搜索空间进行挖掘。由于该项条件下的前缀树结构已包含所有该项的条件序列,故可挖掘出所有符合最小支持度条件的完整的序列模式的集合。挖掘过程如算法2。 记K={k1,k2,…,kn}为频繁序列模式集合,ki(1≤i≤n)为频繁模式,ki= 首先,从头表中第一项开始,由node.link信息找到所有同名项进行支持度计数,其中,i与_i分别计数,同一序列中具有相同前缀项不重复计数。根据当前计数以及当前最小支持度值与模式判断条件相比较,满足sup≥LMS且sup≥mis的输出到K中,并以i为条件前缀继续在i的前缀树中挖掘;满足sup≥LMS但不满足sup≥mis条件的予以保留以待继续挖掘其可能存在的频繁超序列模式;对于不满足sup≥LMS的,不再继续挖掘。 其次,对于存在后缀以及子节点的模式,记i′为i在附加某一i之后的超序列,记R为前缀集合,将i′记入R中。对i′继续挖掘,对所有i′模式进行支持度计数,计数方式同i。根据当前计数及最小支持度值,判断是否为频繁模式,若当前i′模式仍有后缀模式存在,则照此法继续挖掘;若已无超序列模式,则对当前前缀项终止挖掘。 最后,将头表中所有项按以上步骤递归挖掘。 算法2MSLP-growth算法 输入:MSLP-tree结构,Header List,LMS 输出:频繁序列模式集K Step1 1) For each i in Header List; 2) For each node q,q.name=i.name; //q为i的node.link链接同名项 3) Count support of q; 4) If同一序列中有多个q,then只做一次计数; 5) Count q and _q separately; 6) If sup(q)≥LMS and sup(q)≥mis, //mis为当前m值 7) Then output q; 8) If q有后缀节点或子节点; 9) Put q into R; //R为前缀根节点集合 10) If sup(q)≥LMS,but sup(q)≥mis,then retain q; 11) If sup(q) Step2 12) For q in R; 13) Append i after q as q′; 14) Count support of q′; 15) If sup(q′)≥LMS and sup(q′)≥mis; 16) Then output q′ into K; 17) If q′有后缀节点或子节点; 18) Put q′ into R; 19) If sup(q′)≥LMS but sup(q′)≥mis,then retain q′; 20) If sup(q′) 21) If q′没有超序列,then stop mining; 22) Output q′ into K; Step3 23) Loop until there is no prefix node exist; 24) End; 本文的实验平台为Intel(R)Core(TM)i7-4790处理器,CPU3.6 GHz,2.0 GB运行内存,64位windows 7操作系统。算法采用C++语言实现,编译环境Visual C++6.0。实验数据采用IBM公司数据生成器生成的标准数据集[1]。数据集相关参数设置如下:D为客户数;T为客户平均事务数;I为事务平均项数,设为2.5;N为项数,设为10 000;L为最大频繁序列平均长度,设为4。 本文采用文献[9]中提出的多最小支持度设置方法,定义各项mis值取为: mis(ij)=max{βf(ij),LMS} 式中:β为常量,取值范围为[0,1];f(ij)为各项的频率函数,即各项的支持度;LMS为设定的极小最小支持度。当β=0时,mis(ij)=LMS,即所有项最小支持度相同,皆为LMS;当β=1时,由于f(ij)≥LMS,所以mis(ij)=f(ij)。 实验首先对LMS值固定、β值改变的情况下,MSLP-growth算法和MS-GSP算法的性能进行比较。两算法的执行时间与内存消耗对比结果分别如图3及图4所示。 图3 算法执行时间比较(LMS=0.015,D=100×103,T=10) 图4 算法空间消耗比较(LMS=0.015,D=100×103,T=10) 如图3所示,MSLP-growth算法的执行时间明显低于MS-GSP算法。这是因为MS-GSP算法在执行过程中产生大量的候选序列,导致算法的执行时间更长。MSLP-growth算法由于不需要生成候选序列,而是采用“边挖掘边检验”的策略,在挖掘中即生成频繁模式,而且对于那些不会产生频繁超序列的前缀模式不再继续挖掘,节省了大量不必要的运算时间。随着β值的增大,满足条件的模式数量逐渐减少,MSLP-growth算法和MS-GSP算法的执行时间都相对缩短,但MSLP-growth算法性能仍然高于MS-GSP算法。 图4描述了MSLP-growth算法和MS-GSP算法的内存消耗对比结果。从图4中可以看出,本文所提出的MSLP-growth算法具有较小的内存消耗。这是因为MSLP-growth算法采用线性结构,并且采用分枝整合策略实现MSLP-tree的最大化压缩。同时在挖掘前删除大量的非频繁项,从而有效降低内存使用量。 在算法可扩展性测试中,设定LMS与β为0.025和0.5,客户数量D从100×103到500×103,每次增加100×103,两算法的执行时间对比结果如图5所示。可以发现,随着数据集容量逐渐变大,MSLP-growth算法的运算时间趋于稳定,而MS-GSP算法的执行时间则显著增加。由以上分析可知,MSLP-growth算法具有良好的可扩展性。 图5 算法执行时间比较(LMS=0.025,β=0.5,T=10) 综上分析,无论是在以支持度阈值为条件变量,还是在不同容量数据集环境下,本文所提出的MSLP-growth算法都表现出优越的性能。 本文针对现有主流序列模式挖掘算法无法有效满足用户行为模式挖掘的应用需求,提出一种基于前缀树结构的多支持度序列模式挖掘方法。通过为序列中各项设置不同最小支持度,解决了单一支持度阈值下行为模式挖掘的准确度和效率过低的问题。实验结果表明了本文所提算法的高效性和良好的可扩展性。下一步工作将进一步讨论多最小支持度下算法优化问题以及不同项目权重对用户行为模式生成结果的影响。 [1] Agrawal R,Srikant R.Mining sequential patterns[C]//Eleventh International Conference on Data Engineering.IEEE Xplore,1995:3-14. [2] Srikant R,Agrawal R.Mining Sequential Patterns:Generalizations and Performance Improvements[C]//International Conference on Extending Database Technology:Advances in Database Technology.Springer-Verlag,1996:3-17. [3] Zaki M J.SPADE:an efficient algorithm for mining frequent sequences[J].Machine Learning,2001,42(1):31-60. [4] Pei J,Han J,Mortazavi-Asl B,et al.PrefixSpan:Mining Sequential Patterns Efficiently by Prefix-Projected Pattern Growth[C]//International Conference on Data Engineering.IEEE Computer Society,2001:215. [5] Ayres J,Flannick J,Gehrke J,et al.Sequential PAttern mining using a bitmap representation[C]//Eighth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.ACM,2002:429-435. [6] Le B,Tran MT,Tran D.A method for early pruning a branch of candidates in the process of mining sequential patterns[C]//Intelligent Information and Database Systems.ACIIDS 2017.Lecture Notes in Computer Science,Springer,2017,vol 10191. [7] Zihayat M,Chen Y,An A.Memory-adaptive high utility sequential pattern mining over data streams[J].Machine Learning,2017,106(6):799-836. [8] Kemmar A,Lebbah Y,Loudni S,et al.Prefix-projection global constraint and top- k,approach for sequential pattern mining[J].Constraints,2017,22(2):265-306. [9] Liu B,Hsu W,Ma Y.Mining association rules with multiple minimum supports[C]//Proceeding of the 5th International Conference on Knowledge Discovery and Data Mining,San Diego,CA,USA.1999. [10] Hu Y H,Chen Y L.Mining association rules with multiple minimum supports:a new mining algorithm and a support tuning mechanism[J].Decision Support Systems,2006,42(1):1-24. [11] Kiran R U,Reddy P K.Novel techniques to reduce search space in multiple minimum supports-based frequent pattern mining algorithms[C]//International Conference on Extending Database Technology.ACM,2011:11-20. [12] Wang C S,Lin S L,Chang J Y.MapReduce-Based frequent pattern mining framework with multiple item support[C]//Intelligent Information and Database Systems.ACIIDS 2017.Lecture Notes in Computer Science,Springer,2017,vol 10192. [13] Liu B.Web data mining:exploring hyperlinks,Contents,and Usage Data[M].Springer-Verlag Berlin Heidelberg,2007:41-45. [14] Huang C K.Discovery of fuzzy quantitative sequential patterns with multiple minimum supports and adjustable membership functions[J].Information Sciences,2013,222(3):126-146. [15] Pyun G,Yun U,Ryu K H.Efficient frequent pattern mining based on Linear Prefix tree[J].Knowledge-Based Systems,2014,55:125-139.
2 MSLP-tree
2.1 MSLP-tree结构

2.2 构造MSLP-tree
3 MSLP-growth算法
4 仿真实验及结果分析
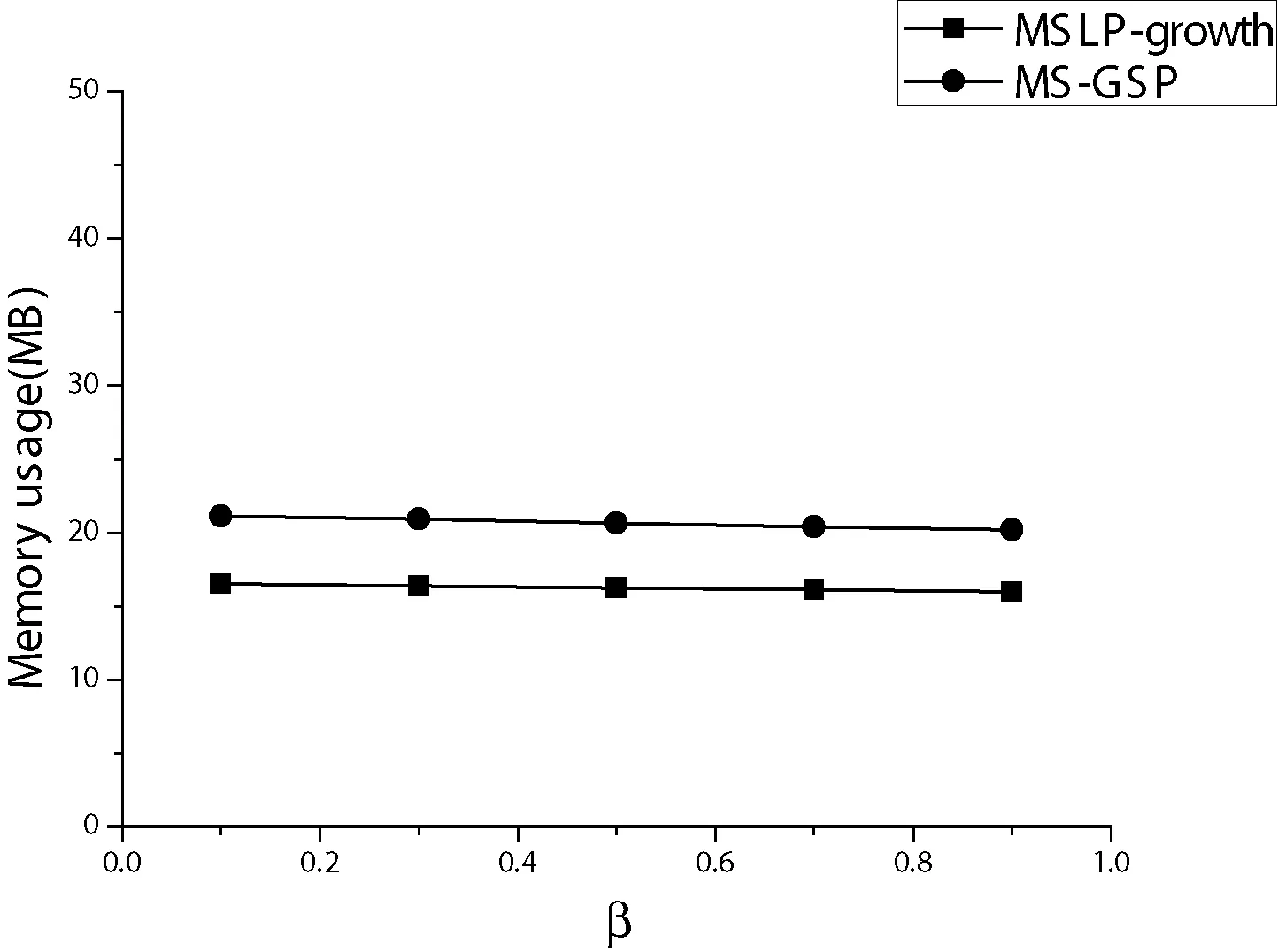
4.1 性能测试

4.2 可扩展性测试

5 结 语
