一种改进的DFCM聚类算法及对wine数据的分类
2018-02-26叶昌伦韦霞
叶昌伦 韦霞

摘要
双模糊C均值聚类算法存在对初始聚类中心位置的敏感缺点,影响了算法的应用。本文提出了基于模拟退火(SA)和遗传算法(GA)的双模糊C均值聚类算法。SAGA-DFCM结合了模拟退火和遗传算法的优势,设置新的适应度函数,对初始聚类中心位置进行优化。在wine数据集的分类结果中看到SAGA-DFCM相对于DFCM算法大大减小了对初始聚类中心位置的敏感程度。
【关键词】仅模糊C均值聚类 遗传算法 模拟退火 初始聚类中心
1 引言
聚类分析在各个领域都得到了广泛地应用,其著名的模糊聚类算FCM,它是根据模糊理论建立的聚类算法,它是寻找一种分类,使其样本到类别的广义加权距离平方和最小,但这并不能保证类别到样本整体聚类中心的广义加权欧式距离最大,对此,引入了双模糊C均值算法(Double Fuzzy C-Means),通过建立两级FCM模型,以解决这一缺点。总所周知FCM尽管它具有很强的搜索能力,但对初始聚类中心选取、数据量大时,容易得到局部最优解。而DFCM相当于两个FCM模型的合成,必然受初值和数据量大的影响比FCM大。
为了解决DFCM这一缺点,结合遗传算法(GA)具有较强的全局寻优能力和模拟退火(SA)具有较强局部寻优的能力,设置新的适应度函数,对DFCM算法的初始聚类中心进行优化。改进后的DFCM算法对初始聚类中心的敏感性强度大大减小。
2 DFCM算法概述
DFCM算法是在经典的FCM算法上建立的,而FCM算法是寻找一种分类,使其样本到类别的广义加权距离平方和最小,但这并不能保证类别到样本整体聚类中心的广义加权欧式距离最大,为了改善这一缺陷,进而引入了DFCM算法:
在式中,表示第j个样本属于第h个类别的隶属度,β为模糊度参数,c为聚类数,n为样本数,wi表示第i个指标的权重。sih表示第h个类别的第i个指标的规格化值。①式是经典FCM算法,②式类别到样本整体的中心广义加权欧式距离,为了达到聚类效果,只要使F取最小值,即①式达到最小,②式达到最大。其中每个样本的隸属度满足以下条件:
(1)式通过拉格朗日数乘法求其最小得:
由于给定的样本的整体聚类中心是唯一的,故不需要优化,所以把所有样本指标规格化值的平均值作为样本整体聚类中心的指标值,将(6)式简化为:
通过(3),(4)建立第一级FCM模型,(5),(7)建立第二级FCM模型,将两个FCM模型合起来便是DFCM算法,我们知道尽管FCM算法有很强的搜索能力,但是也容易受聚类中心初值sih0的影响,得到局部最优解,尤其在处理数据量大的时候。必然地,由于DFCM相当于两个FCM算法的合成。也存在这样的问题。还有当初值的选取不当时(4)式可能出现负值,导致迭代失败。
3 改进的SAGA-DFCM算法步骤
为了解决DFCM存在的问题,将模拟退火和遗传算法结合(SAGA)用于DFCM算法。为评价每一个个体,结合(1)式定义了以下适应度函数:
其中,λ为常数,从上式知,F(U,S,V,S0)越小,适应函数越大,聚类效果越好。
由于遗传算法(GA)具有较强的全局寻优能力和模拟退火(SA)具有较强局部寻优的能力,因此结合遗传算法和模拟退火对聚类中心初值的优化;SAGA-DFCM算法实现如下:
(1)对数据X规格化处理;
(2)初始化控制参数;DFCM算法初始参数:W指标权重,MAXdie最大迭代次数,numF为目标函数F的精度,numS对每一个初值sih0,S的迭代精度。遗传算法初始化参数:种群个体大小popsize,最大进化次数MAXCEN,交叉概率PC,变异概率Pm,模拟退火初始化参数:退火初始温度T0,温度冷却系数ξ,终止温度Tend;
(3)随机初始化c个聚类中心,并产生初始种群c,对每个聚类中心用式(4),算出vh,再用式(2),(3)反复迭代当|Si+1-Si|j+1-Fi|F或达到最大迭代次数MAXdie时,退出整个程序,通过(1)式得到F,并运用适应度分配函数FintS0=ranking(F)求出每个个体的适应度值。当F的值越小时,个体的适应度值fi越大;
(4)设置循环计数变量indexgen=0;
(5)选择:这里采用随机遍历抽样(sus)选择个体;
(6)重组:单点交叉;
(7)变异:以概率为Pm变异;
(8)对新产生的个体使用$(4),(5),(2),(3)$循环迭代得到c个类的聚类的中心矩阵,各样本的隶属矩阵,还有每个个体的适应度值fi。
(9)替换:如果fi>fi,替换旧的个体,否则通过模拟退火以Pe((fi-fi)T)替换旧个体。
(10)计数:若indexgengen,indexgen=indexgen+1,回到第(5)步,否则到达步骤(11)。
(11)若Tiend,结束,输出全局最优解;否则,开始执行降温Ti+1=ξTi,重新回到(4)。
4 實验与分析
为了验证SAGA-DFCM的性能,使用UCI(University of California Irvine)数据集中的Wine数据和DFCM对比进行测试;其中UCI中的Wine数据样本共178个,指标值共有有13项,共三类,第一类有59个样本,第二类有72个样本,第三类有47个样本,一共有13个指标值,设置参数S的迭代精度numS=0.1,设置参数F的迭代精度numF=10-6,最大进化次数MAXGEN=150,运用MATLAB,分别调用DFCM,SAGA-DFCM结果如下:
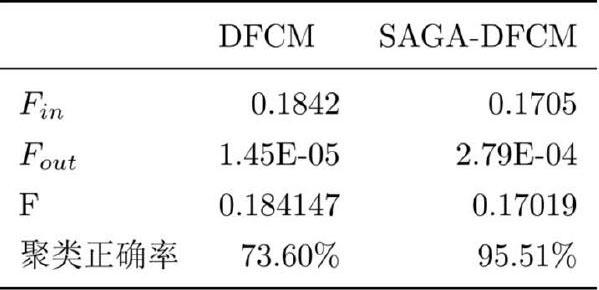
其中SSAGA-DFCM为SAGA-DFCM算法最终迭代聚类中心,SDFCM为DFCM算法最终迭代聚类中心,可以看出尽管numS=0.1,SAGD-DFCM算法的精度远大于DFCM,已经非常接近精确值。
其中Fin表示所有样本到类别的加权欧式距离之和,Fout表示所有类别到整体样本的加权欧式距离之和。从运行的结果来看,在参数设置相同的情况下,显然是SAGA-DFCM的性能好,由于S的初值不同DFCM算法F的值会在[0.18,0.19]之间波动,波动范围较大,受初始聚类中心敏感性强,而SAGD-DFCM算法F的值稳定在0.1710,波动范围很小,受初始聚类中心的影响大大降低,正确率也比DFCM很高。因此SAGA-DFCM是值得推广的。
5 结论
双模糊C均值聚类算法是一种局部收索算法,如果初始聚类中心选择不当,则会得到局部最优点。本文提出了基于模拟退火和遗传算法的双模糊C均值聚类算法(SAGA-DFCM),不仅使其类别到样本整体聚类中心的广义加权欧式距离最大,同时增强了DFCM算法的全局寻优能力。在wine数据集的分类结果中,可以看到,每次F的迭代值基本不变,SAGA-DFCM算法大大减小了初值的敏感程度,但算法的全局和局部搜索能力还需要进一步加强。
参考文献
[1]白莉媛,胡声艳,刘素华.一种基于模拟退火和遗传算法的模糊聚类方法[J].计算机工程与应用,2005,41(09):56-58.
[2]牛向阳,倪前月,高成修.基于遗传算法和模拟退火算法的混合算法[J].明理工大学学报(自然科学版),2008,33(02):25-28.
[3]夏赵建,杜友福.基于朴素贝叶斯对wine数据集分类[J].电脑知识与技术,2017,13(29):224-226.
[4]董国华.一种改进的聚类算法及其在说话人识别上的应用[J].微计算机信息,2004,20(09):134-135.
[5]郁磊.MATLAB智能算法30个案例分析(第2版)[M].北京:北京航空航天大学出版社,2015.
[6]李希灿.模糊数学方法及其应用[M].北京:化学工业出版社,2016.
[7]Li Li,Renxiang Wang,and Xican Li.Double fuzzy c-means model andits application in the technologyinnovation of china.Journal ofIntelligent and Fuzzy Systems,pages1-7.
