一种安全可靠大数据存储平台的设计
2018-02-07谭炜波
蒋 旭 孙 磊 谭炜波
1(天津市海量数据处理技术实验室 天津 300384)2 (天津神舟通用数据技术有限公司 北京 100094) (jiangxu@bjsasc.com)
大数据时代已经到来,数据库中存储的数据越来越多,这对原有的传统关系型数据库体系结构[1]提出了非常大的挑战.传统关系数据库在联机事务处理领域具有丰富的理论研究成果,但随着大数据的到来,数据分析需求显得越发强烈,传统关系数据库原有的行式存储引擎、B-Tree索引结构[2]、行级并发访问控制机制等方面都不能够满足大数据分析的需求.同时在扩展性方面,传统的基于单机的垂直扩展模式,已经无法满足目前大数据环境下计算复杂度的要求,因此要设计一种更加合理的水平扩展机制满足计算性能扩展的需求.
此外,大数据安全问题已成为制约大数据发展的关键因素之一,从安全的角度考虑,大数据的到来会产生新的挑战:由于将所有的数据都存储在分布式环境中,大数据对于现有的存储和防范措施可能提出新的挑战;另一方面大数据更加容易成为网络攻击的显著目标,大数据中数据量比较大,它的信息量也比较大,而且成本比较低,所以黑客更加乐意去攻击;大数据加大了隐私泄露的风险.
本文从深入分析和提炼大数据场景下的真实需求,探索能够满足大数据存储需要的工程解决方案,满足我国对数据库国产化进程中的需要.
1 现有技术路线分析
目前,国外大数据存储领域主要包括两大研究方向:以互联网公司为代表的基于非关系型的NoSQL存储平台(代表产品为Hadoop[3-5],Cassandra等);以传统数据库厂商为代表的并行分布式数据库存储平台(代表产品为Exadata[6-9],Greenplum[10],Vertical,Netezza等).
1.1 宏观分析
大数据存储方案的宏观分析重点关注的设计指标是存储结构、并行架构、普适性3个方面.
1.1.1存储结构分析
1.1.2并行架构分析
国外数据库巨头的多机MPP并行计算发展脉络,是基于传统的数据库中的各种查询优化理论发展而来的,其理论积累和延续性优于以Hadoop为代表的开源体系.以Hadoop为代表的开源体系的多机并行处于如何进行复杂业务并行的阶段,而数据库体系下的商业运营公司在经过几年的培育期之后,目前已经处于如何设计更加友好的用户体验和如何让多机并行对用户更透明的阶段.
单主机内的处理能力越来越强,如何能够更好地利用单机的性能,这也是系统垂直扩展能力的体现.这一点也是在当前多机并行浪潮下,单机SMP并行非常容易被大家忽略的,在单机上的处理性能差别达到5倍甚至10倍,多机的扩展就会显得苍白无力.
1.1.3普适性分析
无论是大数据的应用还是传统的中小型应用系统,数据存储系统的普适性都是非常重要的非技术指标.互联网公司的需求是确定且单一的,对于大数据中心,数据存储平台的需求是纷繁复杂的,因此存储系统的普适性十分重要,要能够适应“海量存储、高速装载、检索、统计、分析、更新等”各种需求,其本质是具备自管理特性的复杂存储体系.当前开源阵营中的任何产品均是为满足特定需求而设计,难以满足大数据中心的建设需求.传统数据库厂商在存储普适性设计中具有多年商业运营经验,以Oracle Exadata为代表的产品中的混合存储结构就说明了这一点.
1.2 微观分析
大数据存储方案微观分析,重点关注的技术指标是精确查询、统计查询、复杂查询3方面.
1.2.1精确查询分析
精确查询方面,索引是最为重要的性能提升手段,对于精确查询性能问题主要集中在3个方面:索引模型、缓存模型和代价评估模型.
索引模型:静态索引模型较易处理,带有更新机制和并发控制的非静态索引,开源引擎目前的支持大多存在设计缺陷,难以保证事务完整性.传统数据库厂商在这方面的处理具有较大的技术优势,且Oracle等厂商也在分析型应用方面取得了突破.
缓存模型:开源引擎一般都是依赖于底层文件系统的缓存模型进行缓存管理.而在软件架构层面上,缓存设计应更贴近计算层,其对数据热点的判定更为准确,传统数据库在这方面已经取得了丰硕的研究成果.
代价评估模型:开源引擎还基本没有涉及,其大多基于规则优化引擎进行优化,优化器设计较为简陋,传统数据库在代价优化方面已经积累了丰富的理论和实践经验,在代价评估方面开源引擎也必然要经历传统数据库漫长的历史演进过程.
对于将来TB级大内存大行其道的时候,更加精细化的索引模型和缓存策略必然成为主要的技术难点,而开源产品在这方面的积累十分有限,因此给后续的研发工作带来一定的困难.
1.2.2统计查询分析
统计查询方面,存储平台的吞吐量十分关键,提升吞吐量主要有2种技术手段:水平扩展性和垂直扩展性.
水平扩展性:原来Hadoop等开源平台的发展初期,在水平扩展性方面优于传统数据库,也是其主要优势所在,但经过这么多年的发展,以Share-Nothing为代表的MPP并行数据库产品的出现,已经吞噬了这一优势.
垂直扩展性:开源平台要远差于传统数据库,我们曾经做过一个实际测试,对比了当前Hadoop平台中使用较广的一种存储引擎Lucene和国内数据库厂商的HCC压缩存储引擎.在影响统计查询性能十分关键的表扫描操作性能中,单线程Lucene的扫描性能不到100万行秒,而HCC压缩存储引擎的扫描性能为550万行秒.这种性能的差距是无法利用水平扩展和廉价设备所能弥补的.
1.2.3复杂查询分析
面向复杂查询,当前开源阵营中最为出色的当属Hive和Pig,但其计算性能也被业界所诟病.由于其优化器简陋,缺乏合理的理论支撑,仅能满足复杂查询分析的功能需求,在性能表现方面不尽人意.在开源阵营内部也出现了各种声讨Hive的声音,但对于传统数据库几十年发展而来的复杂查询优化经验,不是开源阵营几年时间可以达到的,其道路还是十分漫长的.
综上所述,传统数据库厂商的技术发展路线更加符合国产数据库的技术脉络,同时其在接口标准化程度、产品通用性、性能优化技术的理论成熟度和产品发展的集约型程度等方面都要优于互联网公司的NoSQL相关产品,因此本次大数据存储平台将主要依托于此技术路线进行设计与实现.
2 平台设计
依据技术路线分析,大数据存储平台采用国外商用数据库厂商的技术路线进行顶层设计,将大数据存储平台划分为4个系统,分别为:平台中心服务系统、平台元数据存储系统、平台代理服务系统和平台存储访问系统.
2.1 平台软件架构
平台软件架构设计时,充分利用传统关系数据库已有的基于代价的查询优化技术、SMP优化技术、缓存优化技术,设计并实现基于Share-Nothing的MPP平台架构.在存储引擎层面采用了行列混合存储模型对原有的行式存储引擎进行改造,整个平台的总体软件架构如图1所示.
在大数据平台的总体架构中,平台中心服务系统相当于平台的“大脑”.通过多机并行优化引擎,实现MPP并行流水线计划的生成与下发,并通过异步高速通信引擎实现对执行状态的统一控制和管理.其通过统一的元数据管理策略,实现了外部应用透明化.对外提供统一的单一接入点,实现对分布式表的各种存储模型管理.图2所示为平台中心服务的系统架构.
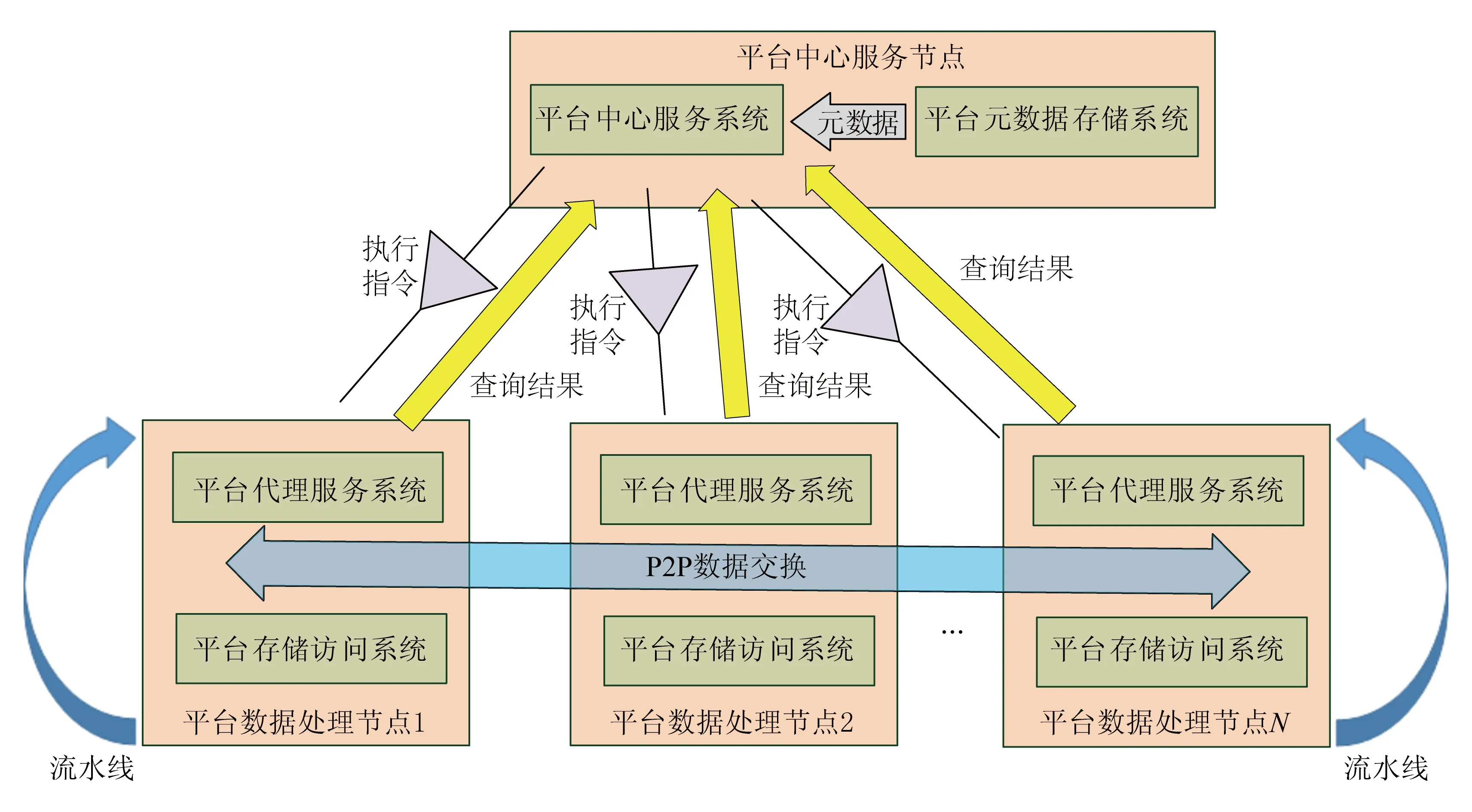
图1 大数据存储平台总体架构
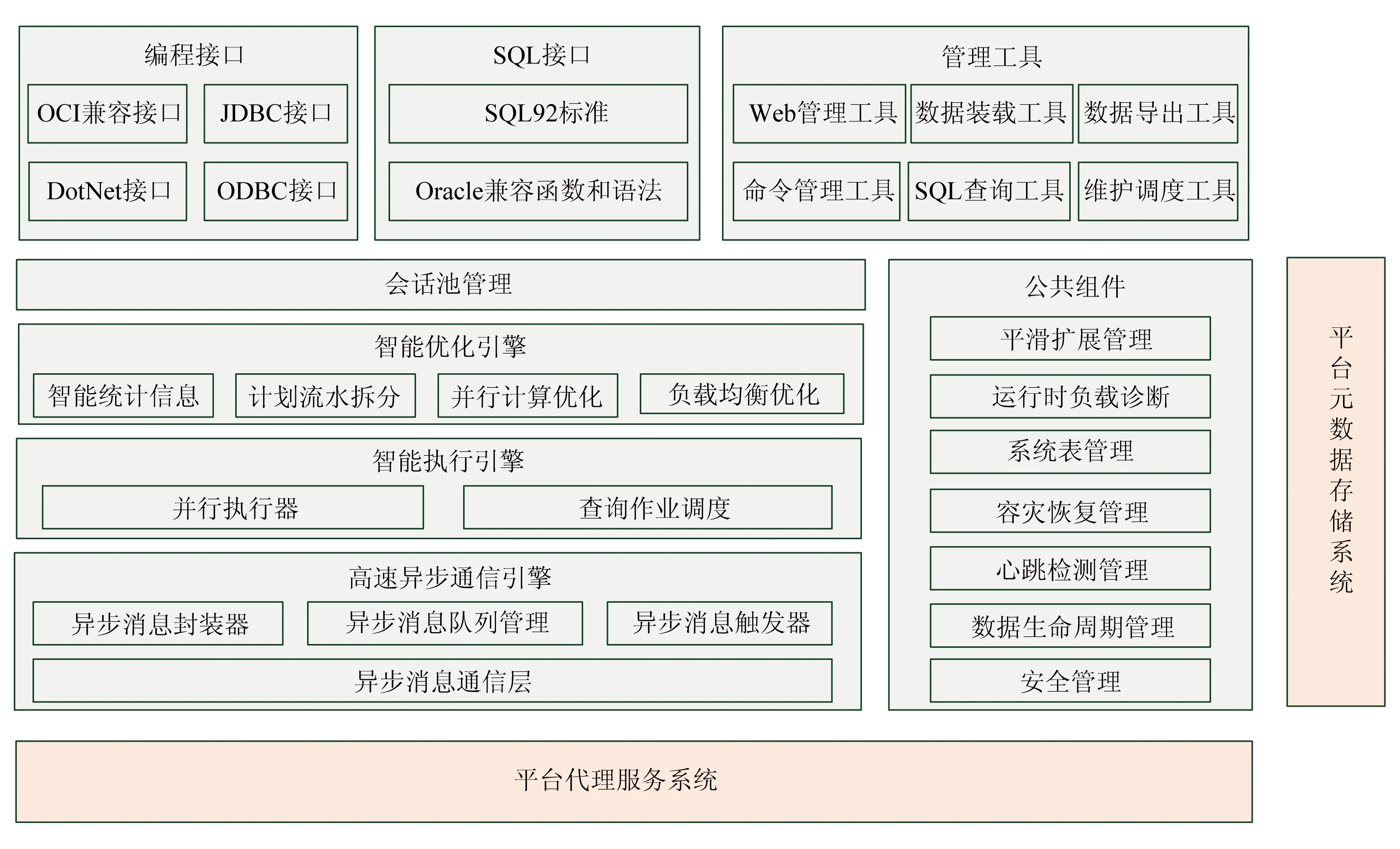
图2 平台中心服务系统架构
代理服务系统主要完成对平台中心服务系统下发任务的执行,设计平台代理服务系统的目的主要是为了分解平台中心服务系统的压力,使其不负责任务执行,避免单一主节点成为性能瓶颈点.平台代理服务系统采用在每个处理节点内独立部署的模式,其功能也较为简单,主要包括任务执行、资源管理、数据交换、心跳检测和网络管理几个部分,具体总体系统架构图如图3所示:

图3 平台代理服务系统架构

图4 平台存储访问系统架构
平台存储访问系统负责执行平台代理服务系统下发的所有任务,是大数据平台中唯一具有真实运算能力的系统.大数据具有静态半静态的特征,并且其查询需求混合了检索类和统计类2种不同需求,因此需要在存储、检索和统计方面的性能和建设成本方面进行重点设计.
本文针对大数据实际应用场景的实际需求,提出的改进点[11-13]主要包括:
1) 大数据存储优化技术.采用行列混合压缩(HCC)技术,对数据进行压缩存储,降低数据存储成本,同时提升IO为主要瓶颈的统计分析类查询的执行性能.
2) 大数据索引优化技术.针对面向大数据场景设计的HCC压缩引擎,建立智能索引、Hash索引等特有索引优化手段,使得压缩态数据可以达到与非压缩态数据同样的查询响应时间.
3) 大数据检索优化技术.设计针对在大数据场景下,高并发类精确检索查询的优化手段(例如:电信网上营业厅的清单查询等).
4) 节点内多核SMP并行计算技术.主要用来解决统计分析类查询执行效率低下的问题.
根据上述改进策略,基于传统关系数据库系统进行改造后的平台存储访问系统的系统架构如图4所示:
2.2 平台拓扑架构
大数据存储平台采用了基于MPP的Share-Nothing架构,因此在拓扑架构中也同样具备这一特点.平台内的各系统部署在每个独立存储服务器内,并通过千兆或万兆网络进行点对点连通.每个存储节点具有自己独立计算和存储资源,最大限度地发挥多机并行的处理优势,图5所示为平台拓扑架构:

图5 平台拓扑架构
2.3 关键技术及解决思路
2.3.1MPP多机并行查询技术
本文所使用的是基于Share-Nothing的无共享分布式设计架构,无共享架构的优点在于可以充分利用每个计算和存储单元的性能,实现吞吐量的最大化.同时无共享架构在全数据分析中不可避免地需要进行数据分发操作,降低数据分发流量是多机并行计算架构设计的重点.本文的大数据存储平台的设计方案如图6所示.
该设计方案采用MOVE CODE TO DATA的优化策略,即将计算放到各数据存储节点,实现低网络负载设计,通过顶层设计,在算子级别对计算进行分解,形成更细粒度的可下降多节点的并行执行算子;MPP并行的分布式计算规则较为复杂,下面以分组统计为样例,描述一下本方案中设计的分布式计算过程,具体计算过程如图7所示.

图6 MPP并行计算设计思想

图7 多机并行分组计算流程图
首先,将查询请求分发到每个数据处理节点上,并在每个处理节点执行查询,生成中间统计结果;
其次,每个数据节点的代理服务,将各节点的统计结果,按照分组列Hash并进行P2P分发,使得相同分组间的中间统计结果分布到同一节点内;
最后,在每个节点内完成最终的分组统计计算.
2.3.2多租户的数据隔离
图8为神通安全数据库集群系统在多租户环境下实现数据隔离的组件模块,包括2个在特权域Domain0中的软件模块:1个针对数据隔离;另1个针对网络隔离;此外包括1个标记服务(labeling service)部署在底层共享存储设备上;另外针对每个用户部署1个系统内核级信息流追踪组件,安装在所有愿意使用用户实例上.

图8 集群系统的安全隔离框架
通过Domain0来管理系统,云租户可以指定安全策略并运用部署在云服务提供商那里的标记服务来自动分配标记到他们的数据,这样,就可以追踪所有在租户实例内进程和文件之间的信息流,如果租户的数据不符合规定地流向了另一个租户的虚拟机或是云外的网络,Domain0里的执行组件就会终止类似的数据交换.网络隔离组件主要干扰对共享硬件资源的多租户探测:通过中央数据库重写租户虚拟实例的IP地址,首先阻止攻击者探测租户的真实IP地址,同时调节ping值返回时间,使得同一台物理主机上虚拟机之间的ping时间值和不同物理主机之间的ping时间值是相同的.
2.3.3稀疏索引技术
本文在大数据索引技术上,扬弃了传统关系数据库的行级索引机制,而是设计并使用了基于压缩包级别的稀疏索引技术.基于稀疏索引技术,可以最大限度地降低索引的大小,从而使得检索操作更多地利用内存进行.本文设计了智能索引,用于解决近似有序列检索问题,其设计原理如图9所示.
在此基础上进一步发展,设计了基于包级别的Hash,其主要目的是替代传统B-Tree索引,具体设计原理如图10所示.

图9 智能索引设计原理
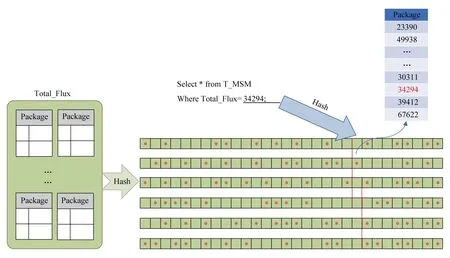
图10 稀疏Sparse Bitmap哈希索引原理图
通过此改进设计,使得基于K-V检索的索引大小降低90%以上,有效地提高了内存利用率和大数据检索性能.
2.3.4基于负载均衡调整的在线扩展技术
本文设计了基于二级数据分发映射的数据分布架构,以保证大数据存储平台中的各种数据分布模型均可实现不移动数据的在线平滑扩展模式,二级分发的设计原理如图11所示:

图11 二级分发映射设计原理图
3 应用测试验证
以某电信集团公司无线网络优化平台实际应用场景为基础测试支撑,在数据装载、压缩比、数据统计、精确查询和DML等主要指标对基于本方案实现的大数据平台和国外同类产品进行了较为全面的测试对比验证.如表1~8所示.

表1 数据装载性能对比

表2 压缩比对比
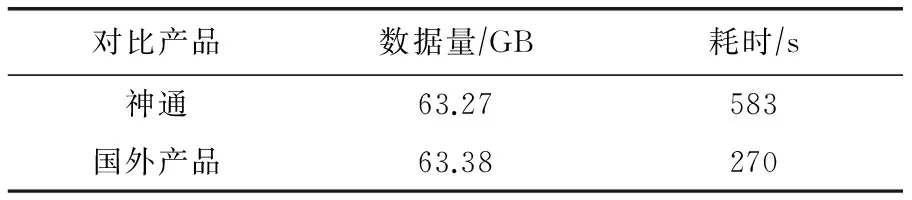
表3 小时级汇总统计性能对比

表4 天级汇总统计性能对比

表5 周级汇总统计性能对比

表6 精确查询性能对比

表7 数据删除性能对比

表8 数据更改性能对比
4 结 论
本文针对通用关系数据库发展阶段,提出了一种实现大数据存储平台的衍生设计方案,通过应用测试验证表明:
1) 基于低网络负载优化技术的MPP架构,使得平台具备多机并行计算能力;
2) 设计了一种在多机环境下基于多租户的安全机制;
3) 基于稀疏索引技术,提升了平台在大数据场景下的精确查询性能;
4) 基于负载均衡调整的在线扩展技术,使得平台具备在线水平扩展能力.
因此本文所提出的大数据存储平台,能够适应目前大数据中心建设需求,具有一定工程应用价值,在一定程度上提升了国产大数据产品的竞争力.
[1]Garcia-Molina H, Ullman J D, Widom J. Database System Implementation[M]. Englewood Cliffs, NJ: Prentice Hall, 2000
[2]Bitmap Index vs. B-tree Index: Which and When[EB/OL]. [2017-12-15]. http://www.oracle.com/technetwork/articles/sharma-indexes-093638.html
[3]Chang F, Dean J, Ghemawat S, et al. Bigtable: A distributed storage system for structured data[J]. ACM Trans on Computer Systems, 2008, 26(2): 4-6
[4]Ghemawat S, Gobioff H, Leung S T. The Google file system[J]. Communications of the ACM, 2003, 37(5): 29-43
[5]Dean J, Ghemawat S. MapReduce: Simplified data processing on large clusters[J]. Communications of the ACM, 2008, 51(1): 107-113
[6]Osborne K, Johnson R, Põder T. Expert Oracle Exadata[M]. Apress, 2011
[7]张瑞. Oracle Exadata技术浅析[EB/OL]. [2017-12-15]. http://www.hellodb.net/2010/02/oracle_exadata.html
[8]Oracle, Oracle Exadata Database Machine Technical Whitepaper[EB/OL]. [2017-12-15]. http://www.oracle.com/technetwork/server-storage/engineered-systems/exadata/exadata-technical-whitepaper-134575.pdf
[9]Oracle Exadata Database Machine [EB/OL]. [2017-12-15]. http://www.oracle.com/us/products/database/exadata/overview/index.html
[10]EMC. Greenplum数据库技术白皮书[EB/OL]. [2017-12-15]. http://www.greenplum.com/products/greenplum-database
[11]冯柯. 迈向100TB:电信业海量数据存储中的数据库实践[EB/OL]. [2017-12-15]. http://wenku.it168.com/d_00000700.shtml
[12]北京寰信通科技有限公司. SYBASE IQ红宝书[M]. 北京: 中国水利水电出版社, 2008
[13]System Administration Guide: Volume 1 [EB/OL]. [2017-12-15]. http://infocenter.sybase.com/help/topic/com.sybase.infocenter.dc00170.1540/doc/html/title.html
