深度科技的anything快速检索技术研究
2018-02-07张木梁
张木梁 张 磊 秦 娣
1(武汉深之度科技有限公司技术部 北京 100080) 2(武汉深之度科技有限公司研发中心 北京 100080) 3(武汉深之度科技有限公司市场部 北京 100080) (zhangmuliang@deepin.com)
为了能够向用户提供一个高速的、基于文件名搜索的离线文件搜索功能,我们引入了“anything快速检索”技术.对于“anything”的定义是Something like everything, but nothing is really like anything….
而anything之所以叫anything,是受到了Windows下everything软件的启发[1].原来在Linux中有一个类似的rlocate程序[2],但是那个程序有点太老了,效率低下,效率方面的设计与当前时代不相称.主要是出于与Linux传统桌面结合得比较紧密,优化起来对系统其他组件影响都很大,很多发行版就不会在这方面进行优化.
1 基础索引设计
1.1 简要分析
在Linux下,最常用的文件搜索软件是find,它会递归遍历每个目录,针对每个目录与文件按照用户给出的参数过滤出符合条件的目录与文件,并打印出来.
在命令行模式下,find使用很广,功能强大,不仅可以根据文件名查找文件,还可以根据文件类型、权限、修改时间、大小,甚至与其他软件配合对文件进行过滤.但是在图形界面下,用户最常用的仍是根据文件名对文件进行查找,这是anything面向的核心问题.
使用find搜索时,如果已经搜索过,则对应的文件与目录信息将会被缓存在内存中,可以大大加速搜索.当然,root用户可以运行sysctl -w vm.drop_caches=3来清除这些缓存.但是,即使使用了缓存,在仅使用文件名搜索的前提下,find的搜索速度仍然是不理想的.
find搜索会通过系统调用遍历每个目录的内容,读取其中的文件列表,再根据文件列表中的inode号找到对应的inode信息,接着读取inode类型为目录中的文件内容……如此递归查找.可以看到这个查找过程经过多重递归,会不断打开目录(需要系统调用与内存复制),而且文件名在其中与inode信息夹杂在一起,会严重减缓纯粹基于文件名的查找[3].
anything设计是与find完全不同的,不同之处在其内部仅保存了文件(目录)名以及必要的归属关系,以便进行双向的查找.所有的数据都存放在用户态空间,没有额外的系统调用开销与内存复制开销.此外,考虑到数据访问的最大可能性,相邻数据是最有可能被一起访问的数据,因此anything可以最大限度利用处理器的高速缓存,使得软件的运行性能更好.
总的来说,anything的设计理论上快速的主要原因是:
1) 相比于find,它不依赖于额外的系统调用与函数调用,减少了大量的系统调用开销与内存复制开销;
2) 它使用的文件系统存储结构的设计针对性极强,内容非常紧凑,使用也很高效.
1.2 内部存储设计
在经典设计中,文件系统应该使用数据结构中的树来存储.树中的每个节点有一个字符串作为名称,有N个指针指向其N个子节点,还有一个指针指向其父节点,以支持从上至下以及从下至上的双向树遍历.这种结构的优点是修改很方便,不管是删除、添加还是重命名每个节点都很快.但是在遍历读取时却因为需要不停的指针跳转,会导致处理器的高速缓存频频失效,从而使得访问速度降低,而又因为各个节点都是分散的,无法体现出相邻节点的访问相关性,所以也难以进行有效的内存访问优化.
下面是上述树型设计数据结构内存消耗的分析.为简单起见,先假设文件系统是一棵深度为D、分叉为N(N>1)的完全树,这样,在整棵树中一共有叶节点ND-1个、非叶节点N0+N1+N2+…+ND-2=(ND-1-1)(N-1)个.对于每个叶节点而言,忽略其文件名,其他部分的内存仅包括一个指向其自身上一级的指针;对于每个非叶节点而言,忽略其文件名,其他部分的内存也包含一个指向其自身上一级的指针(假设根节点也有一个父节点指针,但是其值为空),以及N个指向子节点的指针,指针数一共是P=ND-1+(N+1)(ND-1-1)(N-1)=(2×ND-N-1)(N-1)个,对于64 b系统而言,需要的内存是8×P个字节.
在anything内部存储结构设计的早期阶段,使用树来保存文件系统结构也曾被考虑过,但是顾及高速缓存失效与指针过大的问题,显然在此处使用线性存储设计更好.所以就有了下面anything的数据结构来保存文件系统数据的内部存储结构.
从表1可以看出,anything内部文件系统存储头部为4 B的MAGIC和4 B的缓存区,之所以使用4 B,而不是64 b系统上的8 B是因为对于1 000万个文件与目录的文件系统而言,使用上述结构仅需约250 MB内存,因此不需要8 B的长度与偏移量,从而可以节约一半的指针长度.在8 B之后是一个C语言风格的字符串,对应的是此文件系统树的根目录名,例如“”或者“homedeepin”,这个根目录要求“”开头,“”结尾,整个字符串以空字符结尾.
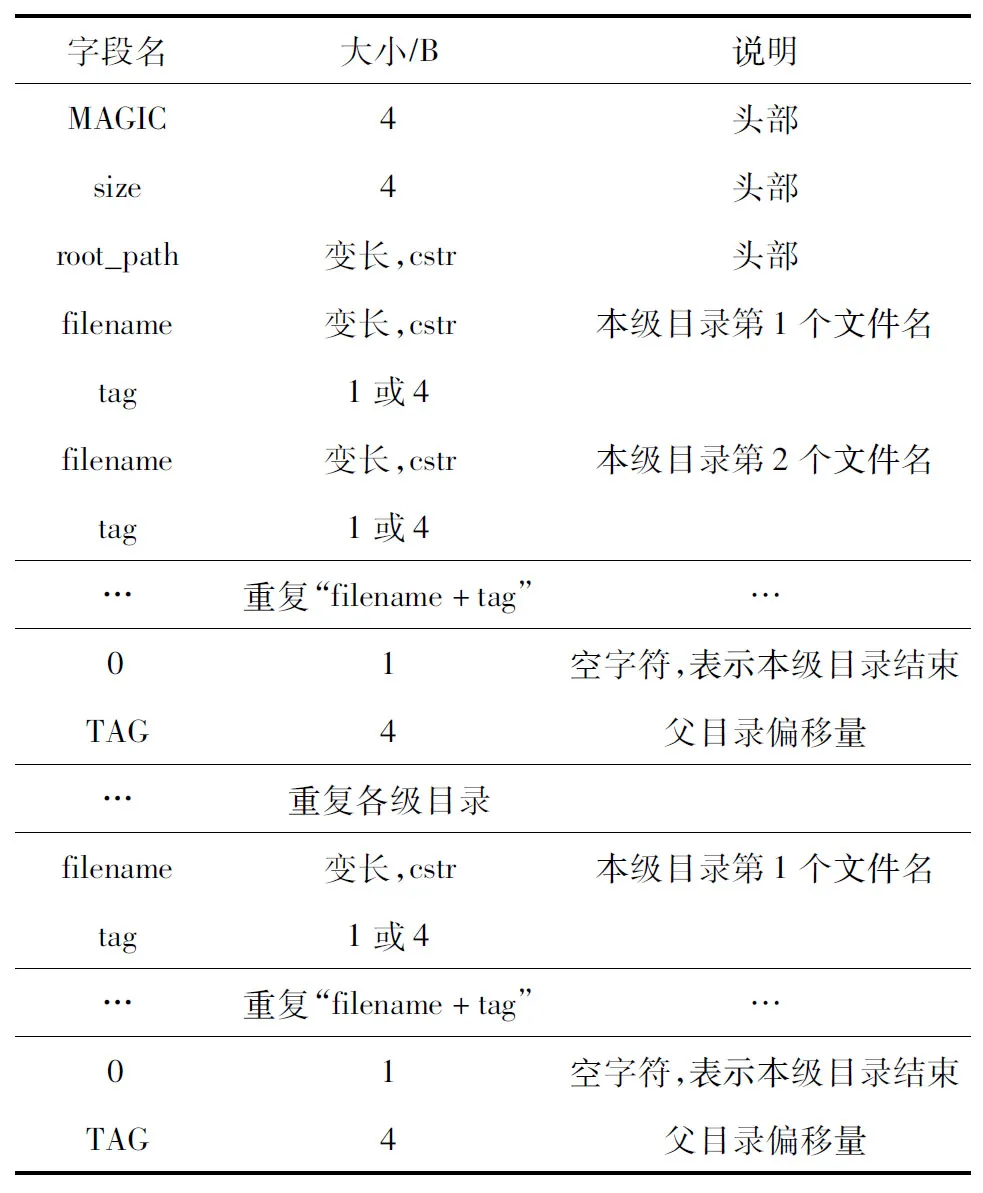
表1 anything的数据结构
在上述头部数据之后即为正式的文件树结构,每个文件或者目录名均是一个C语言风格的、以空字符结尾的字符串.表1中大写的TAG标签代表一个目录的结束,并且包含了自身父目录节点的偏移量;小写的tag标签代表一个文件信息的结束,并且以标签长度代表自身是文件还是目录.在每个字符串之后是一个标签(tag),对于文件来说,此标签占据1 B,标识这是一个文件.对于目录而言,此标签占据4 B,标识这是一个目录,而且记录了这个目录中第1个文件的偏移量,按照之前的分析,这个偏移量仅需要4 B就够了,通过目录的这个4 B标签就可以向下遍历.如此反复,直到此目录结束,将是一个单独的值为0的字节,其后又是一个4 B的标签(TAG),此标签除了标识目录结束之外,还记录了本级目录的父节点的偏移量,如此,就可以通过这个标签支持向上遍历.此外,当本级目录结束之后将开始下级目录的存储,这样即可以使得1棵目录树的数据是紧紧相邻的,在读取时非常高效,在删除时也非常方便.
上述结构不断重复,直到整个文件树结束.
由上述结构可以看出,相邻的节点,即同级目录下的文件都存储在一起,这样有利于内存访问优化.而且将8 B指针优化为4 B偏移量,也节省了存储空间,减少了无效数据的存储与无效内存的访问,此外,线性存储也便于数据文件的存盘与读盘.
对于每个叶节点,需要耗费1 B存储标签,对于每个非叶节点需要消耗4 B存储子节点的偏移量,还有4 B用来存储其所有子节点指向其本身的偏移量,则一共需要ND-1+8×(ND-1-1)(N-1)=(ND+7×ND-1-8)(N-1)个字节,对比之前树需要耗费的8×P=8×(2×ND-N-1)(N-1)个字节,易知在最好情况下是其内存的116,在最差情况下是其内存的13.
当使用此结构进行搜索时不需要再通过树状搜索,而可以使用线性搜索,从前至后进行字符串匹配,并跳过数据量较小的标签即可,这样也方便进行搜索分页.
当搜索到某个名称符合要求时,即可使用目录结尾的标签定位到父目录的偏移量,继而构成完整的路径,返回给调用者.
在这里也可以发现,其实对于搜索而言,程序并不需要保存子节点的偏移量,只需要父节点的偏移量即可,这样还可以把额外的内存再节省约一半,但是这会导致文件系统更改(文件与目录删除、添加、重命名)时变更速度较慢.若仅需使用离线搜索,即不考虑文件系统改动的问题,则内存消耗确实还可通过使用上述方法进一步减少.
此外,由于需要至少1位来标识文件或者目录,因此最大的偏移量不可能是232,即最多能存储231或2 GB内存的数据.为了可扩展性考虑,在内部其实保留了2位数据以进行文件标识,因此,最多可以使用1 GB内存作为内部存储.根据之前的测试估算,大约能保存4 000万个文件或目录,在目前看来是足够的.
1.3 理论对比与实际测试
在进行实际测试验证之前,首先作理论对比.
在预估为包含38.7万个文件(目录)、其中有大约4万个目录的情况下:
2) 若使用树进行数据存储与搜索,在遍历过程中需要持续生成节点,在搜索过程中需要递归遍历(递归函数调用)各个节点,然后对每个节点调用strstr函数,即需要有4万次递归函数调用以及38.7万次strstr函数调用.当然,在此期间高速缓存也会频频失效.在搜索过程中,由于不再需要系统调用,以及额外的从内核态到用户态的内存复制(这个开销相对较小),这种搜索方法应该会至少比find快一个数量级.
3) 使用anything也首先需要进行目录树遍历,但是在搜索过程中需要从前向后,反复在线性存储空间中调用strstr即可,即大约需要38.7万次strstr调用.没有系统调用开销,没有内存复制开销,而且由于内存紧凑,又是单向内存顺序访问,因此内存访问进入高速缓存浪费极少,非常自然,使用也很流畅,比目录树状递归跳转显然要高效很多.
可以看出,从理论设计来看,anything的效率要明显优于前2种设计方案.
为了进一步确定上述猜测是否正确,我们开发了3个程序来实际验证我们的理论设计.
程序2:遍历目录时建立树状结构后,再基于内存树存储进行搜索.
程序3:遍历目录时构建基础索引完成后,再基于基础索引进行搜索.
这3个程序的关键源码分别参见程序1~3.
程序1. 递归遍历直接搜索文件名.
void walkdir (const char* path, const char* query, int* count)
{
DIR* dir=opendir(path);
if (0==dir)
return;
struct dirent* de=0;
while ((de=readdir(dir))!=0) {
if (strcmp(de->d_name, ″.″)==0‖strcmp(de->d_name, ″..″)==0)
continue;
if (de->d_type!=DT_DIR &&
de->d_type!=DT_REG &&
de->d_type!=DT_LNK)
continue;
if (strstr(de->d_name, query)!=0) {
if (*count<10)
*count, path, de->d_name);
*count=*count+1;
}
if (de->d_type==DT_DIR) {
char fullpath[PATH_MAX];
de->d_name);
walkdir(fullpath, query, count);
}
}
closedir(dir);
}
程序2. 递归遍历建立树后再搜索.
typedef struct __fs_tree_item__ {
char* name;
int kids_count;
struct __fs_tree_item__* parent;
struct __fs_tree_item__** kids;
} fs_tree_item;
void walkdir(const char* path, fs_tree_item* fti)
{
DIR* dir=opendir(path);
if (0==dir)
return;
struct dirent* de=0;
while ((de=readdir(dir))!=0) {
if (strcmp(de->d_name, ″.″)==0‖strcmp(de->d_name, ″..″)==0)
continue;
if (de->d_type!=DT_DIR && de->
d_type!=DT_REG && de->d_type
!=DT_LNK)
continue;
fs_tree_item*kid=calloc(1, sizeof(
fs_tree_item));
if (kid==0) {
printf(″kid malloc error, path: %s,
name: %s, count: %d ″, path,
de->d_name, fti->kids_count);
continue;
}
kid->name=strdup(de->d_name);
if (kid->name==0) {
free(kid);
printf(″kid strdup error, path: %s,
name: %s, count: %d ″, path,
de->d_name, fti->kids_count);
continue;
}
kid->parent=fti;
fs_tree_item** kids=realloc(
fti->kids, (fti->kids_count+1)*
sizeof(void*));
if (kids==0) {
free(kid->name);
free(kid);
printf(″kids realloc error, path: %s,
name: %s, count: %d ″, path,
de->d_name, fti->kids_count);
continue;
}
fti->kids=kids;
fti->kids[fti->kids_count]=kid;
fti->kids_count++;
if (de->d_type==DT_DIR) {
char fullpath[PATH_MAX];
de->d_name);
walkdir(fullpath, kid);
}
}
closedir(dir);
}
void search_tree(const char* path, fs_tree_item* root, const char* query, int* count)
{
if (strstr(root->name, query)!=0) {
if (*count<10)
path, root->name);
*count=*count+1;
}
char fullpath[PATH_MAX];
root->name);
for (int i=0;i
search_tree(fullpath, root->kids[i],
query, count);
}
程序3. 递归遍历构建好基础索引后再搜索 (需使用anything库与头文件).
static int walkdir(const char* name, fs_buf* fsbuf, uint32_t parent_off)
{
DIR* dir=opendir(name);
if (0==dir)
return EMPTY_DIR;
uint32_t start=get_tail(fsbuf);
struct dirent* de=0;
while ((de=readdir(dir))!=0) {
if (strcmp(de->d_name, ″.″)==0‖strcmp(de->d_name, ″..″)==0)
continue;
if (de->d_type!=DT_DIR &&
de->d_type!=DT_REG &&
de->d_type!=DT_LNK)
continue;
append_new_name(fsbuf, de->
d_name, de->d_type==
DT_DIR);
}
closedir(dir);
if (start==get_tail(fsbuf))
return EMPTY_DIR;
uint32_t end=get_tail(fsbuf);
append_parent(fsbuf, parent_off);
uint32_t off=start;
while (off if (is_file(fsbuf, off)) { off=next_name(fsbuf, off); continue; } set_kids_off(fsbuf, off, get_tail(fsbuf)); char path[PATH_MAX]; get_name(fsbuf, off)); if (walkdir(path, fsbuf, off)== EMPTY_DIR) set_kids_off(fsbuf, off, 0); off=next_name(fsbuf, off); } return NONEMPTY_DIR; } #define MAX_RESULTS 10 static uint32_t search_by_fsbuf(fs_buf*fsbuf, const char* query) { uint32_t name_offs[MAX_RESULTS], end_off=get_tail(fsbuf); uint32_t count=MAX_RESULTS, start_off=first_name(fsbuf); search_files(fsbuf, &start_off, end_off, query, name_offs, &count); char path[PATH_MAX]; for (uint32_t i=0; i char *p=get_path_by_name_off(fsbuf, name_offs[i], path, sizeof(path)); printf(″%’u: %c %s
″, i+1, is_file(fsbuf, name_offs[i]) ? ′F′ : ′D′, p); } uint32_t total=count; while(count==MAX_RESULTS) { search_files(fsbuf,&start_off, end_off, query, name_offs,&count); total+=count; } return total; } 在程序里单独在搜索前后调用gettimeofday获取时间戳,进行差分比较,在有缓存的情况下,3种方法搜索的耗时分别为: 1) 边递归遍历目录边匹配(类find),10.1 s; 2) 递归遍历目录后用树存储目录结构再搜索,77 ms; 3) 递归遍历目录后用基础索引存储目录结构再搜索,8 ms. 如果使用perf,strace与google perftools进行性能剖析,可以看出在第1个程序里主要的程序耗时(88%)都花在了opendir()的调用上.第2、第3个程序在搜索阶段运行没有与内核交互,而且时间过短,采样过少,因此没有有意义的数据产生,但是可以看出使用基础索引技术比使用树的方法快了接近10倍. 上述基础索引的设计已经大大提高了基于文件名的搜索速度(相对于find而言),但这种搜索方法仍然需要从前至后遍历每个文件名进行搜索[4].从表面上看,因为需要对每个文件名进行检查,以得知其是否匹配搜索串,理论上不会有更快的方法了.但事实上,我们还可以做得更好,那就是使用倒排索引(inverted index)实现二级索引. 倒排索引的原理是对目标字符串进行切割,得到其所有的子字符串,然后将这些子字符串存放到对应的索引数据结构中,当用户输入对应的子字符串时能立刻找到相应的原始字符串[5]. 例如原始字符串为china,则可以得到c,h,i,n,a,ch,hi,in,na,chi,hin,ina,chin,hina与china,一共5+4+3+2+1=15个子字符串,假设china这个字符串的偏移量(或者指针)是100,则可以得到{“c”→100}, {“h”→100}, …, {“china”→100}等25个索引.当用户输入hi时,即可以立刻得到{“hi”→100}这个索引,然后将100返回给调用者,由调用者通过这个偏移量或者指针得到“china”这个字符串. 在简单的倒排索引设计中,一般使用Hash链表或者Trie树作为索引数据结构[6].anything使用的是Hash链表,其工作原理是,当用户输入某个查询字符串(如hi)时,anything将首先对字符串进行一次Hash运算,得到Hash数组中的下标值,然后根据下标值即可得到对应的索引数组,在索引数组里顺序查找即可得到对应的索引(即hi),从而可以获取到所有的包含hi字符串的原始字符串的偏移量,将其返回给调用者. 对于38.7万个文件与目录遍历的实测表明,其索引内存占用将超过2 GB,这完全是不可接受的.而对anything在对二级索引进行优化后,内存消耗可以大幅度减少.在对上述含有38.7万个文件与目录的遍历表明,其索引大约有600万个,索引占用内存约230 MB,程序占据内存不超过500 MB(因为动态内存分配需要大量的额外内存空间),基本可以接受. 在基础索引中,如果是38.7万文件与目录,则一共需要进行38.7万次strstr的调用以完成一次完整的查找.在二级索引中,如果使用了Hash链表,每次查找时就可以大大减少strcmp的次数.在这里,anything采用了质数模的方法作为Hash函数.对比基础索引搜索需要的38.7万个strstr调用,可以提高数10倍的性能. 测试环境中4个搜索方法的对比如下: 1) find——10.1 s,系统缓存增加260 MB; 2) 树搜索——77 ms,存储数据内存需要30 MB; 3) 基础索引搜索——8 ms,存储数据程序内存需要7 MB; 4) 二级索引搜索——0.4 ms,存储数据程序内存需要230 MB. 当然,二级索引的问题仍然是其占用内存实在太大,对于38.7万个文件与目录的文件数来说,基础索引约占用7 MB内存,而二级索引则需要占用约230 MB内存.其次,当发生文件系统变更时,基础索引的变更比较容易实现,但是二级索引的更新就相当繁复了,需要遍历所有的索引,找到对应的原始字符串偏移量进行修改.此外,二级索引的文件保存与载入也较为麻烦,因为需要将整个Hash链表序列化与反序列化,而且当文件系统变更时,一旦变更了索引,则需要进行数百兆甚至上吉数据的重新序列化,也会增大磁盘压力. 因此,除非是在对文件名搜索速度非常关键的场所或者离线搜索的场景下,不然使用基础索引进行文件名搜索即可满足要求.这将是anything应用于其他场景的扩展能力,不在本文介绍. 从以上可以看出,搜索提速最重要的原因是省去系统调用,但是文件系统是会不停变化的.因此anything需要对文件系统进行监控,在变化时及时对内部的基础索引进行修改才能保证搜索的正确性与实时性. everything对于文件系统变更的追踪相对简单一些,因为它直接依赖于Windows下NTFS文件系统的日志[7].但是在Linux下,首先文件系统繁多,例如RHEL 7CentOS 7采用的缺省文件系统是XFS,但是Debian与RHEL 6CentOS 6使用的缺省文件系统却是ext4,而且这两者的文件系统日志都没有NTFS信息完全[8].除此之外还有btrfs等一系列的其他文件系统.其次是在Linux下,管理员或者用户对于文件系统的选择较多,并且可以深入调整文件系统的参数,例如去掉日志,因此仅依赖于文件系统日志检查文件系统的变更是不太可靠的. 另外,由于Linux本身没有全局的文件创建、删除与重命名的用户态接口(比较接近的inotify无法递归监控目录)[9],因此要解决此问题,只能使用独立的模块监听文件的创建、删除与重命名,并通知相应的用户态程序更新文件系统数据与索引数据. 在Linux下,监控整个文件系统的变化可以采用下列方法: 1) 使用preload库,监控glibc对应函数的参数与返回值,包括open,fopen,creat,mkdir,rmdir,rename等.这种方式的优点是不依赖于内核,但是它会对所有依赖于glibc库的程序都造成影响,影响面大,工作量也不小(函数较多,参数处理较多),而且具有较大的安全隐患,此外,对于静态编译libc库的程序以及不依赖于libc库的程序(虽然这种程序很少)无法监控. 2) 使用审计系统,加入对相应系统调用(open,creat,mkdir等)的审计,通过审计日志检查系统调用的结果,根据结果更新文件系统数据.其优点是不依赖于内核,系统调用数量较少,但是缺点是需要依赖于审计系统,而且事后处理日志的方式会缺少关键的场景信息,例如之前的文件或者目录是否存在. 4) 编写内核模块,使用内核热补丁技术(livepatch)替换内核函数.与上述技术路线类似,不需要自己考虑替换内核函数指针的问题,缺点是需要重新实现或者调用原始函数,以保证功能的正确,而且热补丁技术对内核特性要求较高,龙芯申威内核现在并没有实现相应的功能.此外,如果相应的函数由于出现了问题需要使用热补丁修复,将会带来一些维护上的问题,虽然可能性较小. 5) 编写内核模块,使用内核tracepoint特性对系统调用入口与出口进行事件跟踪,并记录处理结果,缺点是会对所有的系统调用进行跟踪,因此需要自己过滤,而且系统调用路径较长,可能会导致较多的资源占用. 6) 编写内核模块,通过kprobes对内核函数进行挂钩,在函数入口和出口处进行参数与返回值的检查,当发现满足要求的文件事件时将事件信息记录下来,其缺点是对比tracepoint来说,kprobes从理论上依赖的函数变化的可能性更大一些,当内核升级时可能会带来维护的问题[10]. anything选择了最后一种解决方法,虽然它要求内核支持kprobes特性,但这是一个较容易实现的特性,而且anything要监控的内核函数也相对稳定. 具体到需要跟踪的内核函数,主要就是VFS的文件系统变更函数,包括vfs_create等.为了确保只有当函数成功返回时才进行记录,anything需要使用kretprobes进行函数跟踪. 需要注意的是,使用kretprobes有一个与架构相关的问题,那就是要在函数入口处得到函数各参数的值,而在这里,kretprobes没有给开发者提供很多便利,需要根据不同CPU架构的内核寄存器结构体(pt_regs)制定的函数调用规约才能获取相关的参数值.例如对于X86来说,其64 b系统的函数调用规约是从第1个参数开始,分别使用rdi,rsi,rdx,rcx,r8与r9寄存器保存参数,从第7个参数开始使用栈来保存剩余的参数.这些代码都被封装到源码的kernelmodarg_extractor.c中.因此,当需要扩展架构支持时,主要在这里进行修改即可.此外,在实际使用中,anything现在仅用到前4个参数,因此只要处理n等于1~4的情况即可. 本文使用一个简单但仍有典型意义的文件搜索来完成以下对比测试: 首先是测试环境.测试环境物理机为ThinkPad x230(8 GB内存+机械硬盘).虚拟机为运行在VirtualBox里完整安装的Deepin 15.4(分配虚拟单核处理器2.9 GHz,虚拟内存2 GB). 测试方法如下: 1) 使用sysctl -w vm.drop_caches=3清空缓存,然后运行find-name ″*hellfire*,耗时约39.9 s. 3) 使用anything的基础索引搜索hellfire,耗时约6 ms,基础索引占用内存约7 MB,测试程序占用内存约14 MB. 4) 使用anything的二级索引搜索hellfire,耗时0 ms,二级索引占用内存约230 MB,测试程序占用内存约500 MB. 通过多次测试的结果表明,使用基础索引比使用带缓存的find搜索要快大约500倍甚至更多.若在忽略内存等附加消耗的情况下,使用全内存式的二级索引,anything的搜索速度会比使用基础索引搜索速度再快20倍以上(但是占用内存将增长35倍).是否引入二级索引需要根据实际的应用场景来取舍,这是典型的时间空间复杂度互换的问题. 在处理器支持上,已经验证anything能完全支持X86和自主可控CPU平台,包括龙芯和ARM处理器,支持较新的申威(对部分扩展指令集有要求). anything是一个小巧的软件,其功能很单一.但是它达到了为文件名搜索提供一个高效快速实现的目标,而且对现有的系统侵入很小.同时,anything开源,希望有兴趣的人能为它提交补丁,特别是对其他文件系统以及架构的支持,当然也包括对程序本身的修正和改进. [1]万立夫. 让Everything支持网盘目录搜索[J]. 电脑迷: 技巧与实践Software, 2012 (2): 77 [2]Rasto L. About rlocate官方文档[OL]. [2017-12-15]. http://rlocate.sourceforge.net/ [3]Wbruce C, Donald M, Trevor S. 计算机科学丛书:搜索引擎信息检索实践[M]. 刘挺, 秦冰, 张宇, 等译. 1版. 北京: 机械工业出版社, 2010 [4]周磊. 十五个经典算法研究与总结[OL]. [2017-12-15]. http://blog.csdn.net/v_JULY_v [5]沈东良. Linux内核中链表和散列表的实现原理揭秘[OL]. [2017-12-15]. http://blog.csdn.net/shendl [6]严浪. 倒排文件技术设计[J]. 计算机与数字工程, 2011 (3): 168-170 [7]Zhao J. 探索Everything背后的技术[OL]. [2017-12-15]. https://wenku.baidu.com/view/76bb29da80eb6294dd886cb7.html [8]Harley Q. Linux和Windows的遍历目录下所有文件的方法[OL]. [2017-12-15]. https://www.cnblogs.com/Harley-Quinn/p/6367425.html [9]Zhang S. Linux文件系统变化通知机制—inotify[OL]. [2017-12-15]. http://blog.csdn.net/zhangskd/article/details/7572320 [10]潘风云. Linux内核kprobe机制[OL]. [2017-12-15]. http://blog.csdn.net/panfengyun12345/article/details/194805672 二级索引设计
3 文件系统监控
4 测试验证与结论
