基于A*算法的足球机器人路径规划①
2018-02-07朱卫东
王 陈,朱卫东
1(北京交通大学 计算机与信息技术学院,北京 100044)2(北京交通大学信息中心,北京 100044)
机器人足球世界杯Robot Soccer World Cup,简称RoboCup,是当前国际上级别最高、规模最大、影响最广泛的机器人赛事.RoboCup机器人足球比赛分为仿真组、小型组、中型组、标准平台组,类人组,其中仿真组又分为2D和3D[1].本文的研究正是以机器人足球仿真2D为平台.足球机器人路径规划是指正在带球的足球机器人根据球场信息计算出一条以球为起点,以对方球门为终点的路径,同时这条路径还应该满足不与对方防守球员发生碰撞、尽量远离对方防守球员、路径距离尽可能短、耗费时间尽可能少等条件.对于路径规划问题,目前已经有多种解决方案,例如栅格法[2]、人工势场法[3,4]、蚁群算法[5,6]、遗传算法[7,8]等.
栅格法是地图建模的一种方法.采用栅格法进行路径规划的过程是用大小相等的正方形方块分割球场,并假设对方防守球员所在的栅格是危险区域,其他栅格为安全区域,然后计算出一条从球所处的栅格到球门所处的栅格的最优安全路径.对于栅格大小的选取是非常重要的.如果栅格较小,球场会被划分的非常精确,这会导致要存储的信息将会增多,且计算量也会变大.反之栅格较大将导致球场划分的不够精确,路径规划不严谨,不利于有效路径的规划.
人工势场法将机器人在周围环境中的运动,设计成一种抽象的人造引力场中的运动,目标点对移动机器人产生“引力”,障碍物对移动机器人产生“斥力”,最后通过求合力来控制移动机器人的运动.传统的人工势场法是从静态避障研究中得出,适应能力较差,不能够满足足球机器人动态环境中实时规划路径的要求.此外其内在的局限性主要表现在,当目标附近有障碍物时,移动机器人将永远到达不了目的地.
蚁群算法是通过模拟自然界蚂蚁觅食行为提出的一种仿生进化算法.由于蚂蚁觅食过程中会在所经过路径上释放一种被称为信息素的物质,因而其他经过该路径的蚂蚁可以通过感知这种物质,并根据其残留量确定行进的方向.这样,蚂蚁选择越多的路径上所留下的信息素浓度会越大,而浓度大的路径会吸引更多的蚂蚁,这样就形成一种正反馈.在这种正反馈机制作用下,蚁群最终可以找到一条巢穴到食物源之间的最短路径.该算法需要设置参数,如果设置不当,就会导致求解速度慢且所得解的质量特别差.此外该算法计算量大、收敛速度慢、求解所需时间较长,不适合实时规划,易陷入局部最优.
遗传算法使用种群进行寻优,在每一代的进化过程中,执行同样的复制、交叉、变异、操作,利用适应度函数进行进化.遗传算法的缺点是随着种群的增加,计算量很大,很难满足实时规划的要求.而且遗传算法只适合静态环境下复杂障碍物环境的路径规划,不能满足动态环境的要求.
尽管以上算法都有着各自的缺点,但它们以及其它的路径规划算法都很少考虑到障碍物是移动的的特点,也没有考虑到障碍物移动性对其周围区域的影响,因此规划出的路径的安全性较低.参考文献[9]介绍了反向K邻近(RkNN)的概念,并通过实验对多种解决RkNN问题的算法的性能进行了比较.本文受到RkNN的概念以及其中一个解决RkNN问题的TPL算法的启发,提出了一种基于A*算法的足球机器人路径规划方法.实验证明,本文提出的方法考虑了障碍物的移动对其周围区域的影响,规划出的路径更加安全可靠.
1 基于球员影响力的区域划分
在人类的足球比赛中,带球球员为了在带球过程中防止对方防守球员截球,在带球时总是会往对方防守球员比较少的区域跑,这样能够减少被包围的概率.为了实现上述人类的这种行为,需要分析对方防守球员的影响区域.如果规划出的路径受影响的程度越小,路径越安全.然而目前的路径规划算法并没有考虑上述人类的这种行为,这些算法要么不考虑障碍物的影响区域[5,10,11],要么以障碍物为中心,以r为半径的圆作为该障碍物的影响区域[2].这样,圆以外的区域的影响程度就被忽略了,考虑得不够全面,这就导致规划出的路径不够安全.鉴于此,本文借鉴了TPL算法的思想,设计了一种划分球员影响区域并根据区域受到的影响程度为其赋上风险值的方法,关于TPL算法的具体介绍请参考文献[9].
1.1 划分原理
设防守球员f是对方防守球员集F中的一个元素,q为带球球员,设B(f:q)是f和q的中垂线,那么这个中垂线将球场分成了两部分.H(f:q)表示包含了f的半平面,H(q:f)表示包含了q的半平面.任意位于H(q:f)的点p都满足dist(p,f)>dist(p,q),其中dist(p,q)表示p到q的距离.这表明如果q直接将球踢入H(f:q),球有很大的可能性会被f抢走.这也表明如果f在H(f:q)上的影响比在H(q:f)上的影响大,若q试图带球经过H(f:q),容易被f截球.如图1所示,点q表示正在带球的球员,点a,b,c表示对方的防守球员.我们可以发现当对a、b同时运用TPL算法时会得到H(a:q)与H(b:q)的公共部分,即区域①、②.所以如果q在区域④将球踢入或带球接近区域①、②时,将会承担较高的风险.特别指出区域②比区域①的风险更高,因为区域②是H(a:q)、H(b:q)和H(c:q)的公共部分.同时我们也能够发现区域④是安全的,因为位于此区域上的位置到q的距离是最近的.
由此可见,当带球球员对多个对方防守球员运用TPL算法进行区域划分时,球场将会被分成多个区域.划分出的区域分为安全区域和受影响的区域.包含带球球员的区域即为安全区域,带球球员到该区域上的任意位置的距离比对方防守球员到该位置的距离更近,因此球在此区域内是安全的.其他区域为受影响的区域.若某个区域是k个不同的H(fi:q)的一部分,则该区域的风险等级为k,风险值为k*δ,其中fi为对方防守球员,q为带球球员,0<k≤N,N为对方防守球员个数,δ为风险系数.因此当对球场进行区域划分后,我们可以根据区域受到的影响程度为其赋上风险值,从而规划路径.

图1 TPL算法的图解
1.2 具体方法
在每一个周期,带球球员收集到球场上的信息后,都要运用TPL算法对球场进行分割,评估区域的风险性,受影响的程度越大,风险性越大.区域由区域的边界线表示,边界线的信息包括边界线的方程、边界线的端点信息.TPL算法对球场进行划分的过程如下.

算法1.区域划分算法1)设球场左下角为原点,球场左边界为Y轴,正方向向上.下边界为X轴,正方向向右.初始安全区域为整个球场.设N为对方防守球员的数量,令i=0;2)若i<N,则计算第i个对方防守球员P[i]和带球球员q的垂直平分线Mi并执行3),否则算法结束;3)对Mi穿过的区域进行分割,并更新分割后的区域的相关信息.执行2).
如图2所示,假设B4在收集到当前周期的信息后,通过计算与分析,此时最佳的决策是带球.通过对A2、A3、A4、A7和A8这几个对B4有较大影响的防守球员运用TPL算法可以将球场划分成多个区域,并求出每个区域受到的影响程度,即风险等级,如图3所示.当确定了球场上每个栅格的风险等级之后,B4可以再结合栅格法或其他路径规划算法规划出最优安全路径.
1.3 风险值的设置
对栅格的风险值的设置要考虑的因素有两个,一是对方防守球员的位置,二是安全区域的风险等级.对于防守球员所在的栅格要赋一个风险值,防守球员周围的栅格的风险值以递减的方式对其赋值,其他栅格按其所在区域的风险等级赋值,防守球员附近的栅格的风险值要高于其他栅格的风险值.受多种因素影响的栅格,其风险值是多种风险值的叠加.如图4所示,对方防守球员所在的栅格的风险值为100,周围栅格的风险值逐渐减小.其他区域栅格的风险值根据该栅格的风险等级对其赋值,风险等级越高风险值越大.

图2 TPL算法对球场的划分
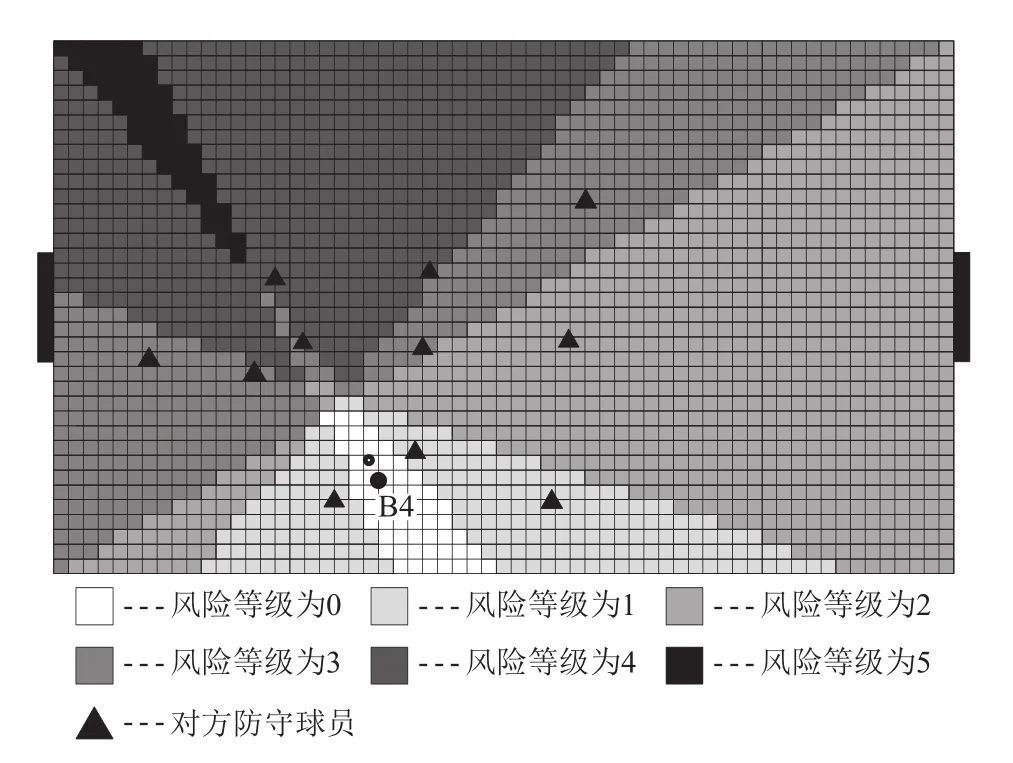
图3 TPL算法计算区域风险等级

图4 防守球员所在栅格的风险值设置方法示例
2 基于A*算法的路径规划
传统的A*算法[12-14]通常仅仅考虑路径的长度,很少考虑路径经过的结点的权重.这导致在某些情况下规划出的路径效果不够好.通过之前对各个栅格的风险值的设置,此处将探讨在路径结点具有权重的情况下的基于A*算法的路径规划.
2.1 A*算法
A*算法是一种静态路网中求解最短路径最有效的直接搜索方法.A*方法对状态空间中的每一个搜索位置进行评估,得到最好的位置,再从这个位置进行搜索直到搜索到目标位置.这样可以避免大量无谓的路径搜索,提高了效率.该方法对位置的评估是十分重要的,路径的代价估计函数为f(n)=g(n)+h(n),其中f(n)是从初始状态经由状态n到目标状态的代价估计,g(n)是在状态空间中从初始状态到状态n的实际代价,h(n)是从状态n到目标状态的最佳路径的估计代价.
2.2 搜索空间的优化
为了提高计算的效率,可以对搜索空间进行优化,避免不必要的计算,此外在估计路径代价时,需要考虑搜索空间的大小.通常最优的安全路径存在于以起点栅格和目的栅格为对角顶点的矩形中.因此,对于该矩形以外的栅格可以不用考虑.但是在有些情况下,带球球员会受到安全性因素的影响,选择一条较长的路径,从而走出了矩形区域.如图5所示,带球球员位于点S处,D为目的地.如果路径被包含在矩形中,该路径将是危险的.例如,如果带球球员沿路径path1走,将被防对方守球员A、B包围;如果从A的上方通过将会被A、B、C包围.如果沿path2走,路径相对安全.因此需要设计一个合适的方法来解决这个问题优化搜索空间.
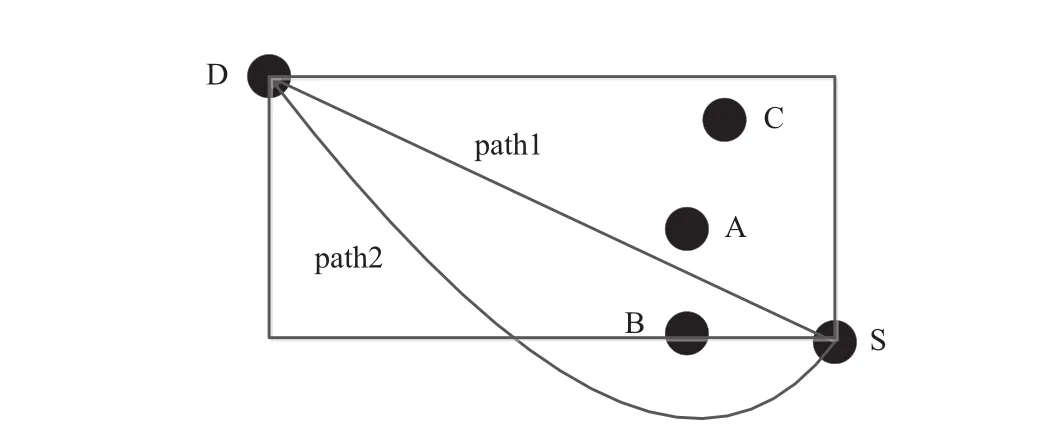
图5 规划路径示例
搜索空间的优化算法如算法2.

算法2.搜索空间的优化算法1)设D为目的栅格,S为带球球员所在栅格.初始搜索空间为以D和S为对角顶点的矩形R.获取矩形R中的对方防守球员的信息,将该球员加入球员数组PlayerTemp[]中;2)如果PlayerTemp[]为空,则算法结束.否则依次遍历PlayerTemp

[]中的球员,计算对方防守球员影响的栅格是否在垂直方向超出矩形R,若超出,则将矩形向垂直方向扩大至将该栅格包括在内,并满足该栅格与R的上边界或下边界相隔两个栅格,若矩形的上(下)边界到达了球场的上(下)边界,则矩形的上(下)边界即为球场的上(下)边界;3)获取矩形外的对方防守球员的信息,如果矩形外没有对方防守球员则搜空空间为矩形R,算法结束.否则依次遍历矩形外的对方防守球员.如果对方防守球员影响的栅格位于矩形R内,则将该球员加入球员数组PlayerTemp[]中.遍历结束后执行2).
2.3 改进的 A*算法
A*算法最关键的是确定路径的代价估计函数f(n),代价估计函数f(n)又包括实际代价g(n)和估计代价h(n).由于实际代价g(n)是对确定路径的代价计算,可以得出准确的值,而估计代价h(n)是对不确定路径的代价估计,只能得到估计值.因此两者的计算是不同的.本文从两个方面进行对路径代价进行了考虑,一是路径的长度,二是路径的安全性.
(1)实际代价g(n)的计算
在本文中,计算路径的长度是通过计算路径经过的栅格的长度实现的.路径长度的计算公式如下所示:

其中L(S,n)表示从起点栅格S到栅格n的长度,n1表示该路径的栅格总数,n2表示该路径中位置是对角关系的栅格对数,dis表示相邻栅格的中心点的距离.
路径的安全性指路径经过的栅格的风险值的和.路径的安全性计算公式如下:

其中W(S,n)表示从起点栅格S到栅格n的风险值,n1表示该路径的栅格总数,wj表示该路径的第j个栅格的风险值.因此实际代价g(n)为:
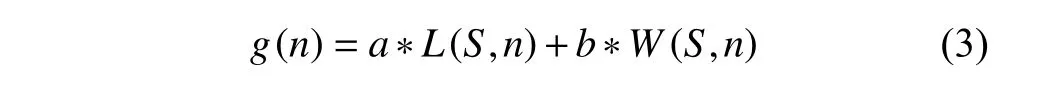
其中a、b分别表示路径长度和路径风险等级所占的比重,具体大小根据实际情况设置.
(2)估计代价h(n)的计算
对于估计代价的计算通常有两种方法,第一种为曼哈顿预估方法,第二种为欧几里得预估方法.但是这两种方法通常仅仅是路径长度的计算,没有考虑到路径各结点的权重.为了提高计算效率,本文的估计代价计算均值.设搜索空间的风险值有k种,分别为w1,w2,…wk,风险值为wi的个数为ni,L为栅格n到目标栅格D的曼哈顿距离,N为搜索空间包含的栅格数,a、b为路径长度和路径风险等级所占的比重,则估计代价为:

(3)优缺点分析
A*算法是常用的启发式算法,它通过代价估计函数f(n)引导算法的搜索方向,不用将所有可能的路径都遍历一遍,大大减少了计算量,提高了计算效率.以往的基于A*算法的足球机器人路径规划几乎都没有考虑所经过的栅格的权重,而本文改进的A*算法是在对栅格合理赋予风险值并对搜索空间优化了的基础上进行路径规划的,不仅具备了传统的A*算法的优点,还对路径的长度和安全性综合考虑,使规划出的路径在动态障碍物环境下更加安全.然而,改进后的A*算法同样继承了传统A*算法的不足,即估计代价h(n)与实际值存在差异,不能保证得到最优解.
3 实验分析
为了验证本文所提出的算法的有效性以及优越性,进行了仿真实验.球场被分成了61*36个栅格,试验中球员和球的位置由实际比赛中随机选取的某个时刻球员和球所在的位置确定.设dis为30,栅格的风险值为r*5,其中r为该栅格的风险等级.对方防守球员所在的栅格及其周围的栅格的风险值的设置如图4所示.为了确定a,b的值,设a=0,b=1-a,进行路径规划试验.试验结束后令a=a+0.1,再次进行试验;直至a>1时本轮实验结束.本轮试验结束后,更新球场球员及球的位置信息,重新进行确定a、b的试验.试验结果表明当a=0.4,b=0.6时,有最大的可能性得到最好的路径.
可以发现当a、b分别设置为1和0时,即可得到传统A*算法规划出的最短路径.如图6所示,该路径的长度虽然是最短的,但没有考虑路径结点的风险值,安全性非常低.当a、b分别设置为0和1时,得到的是风险值最低的安全路径.如图7所示,该路径仅考虑了安全性,没有考虑路径长度,考虑的不够全面.当a、b分别设置为0.4和0.6时,效果最好,得到的是改进后的A*算法规划的安全路径.如图8所示,该路径既考虑了安全性,又考虑了路径长度.对比传统的A*算法,改进后的A*算法规划出的路径更好.
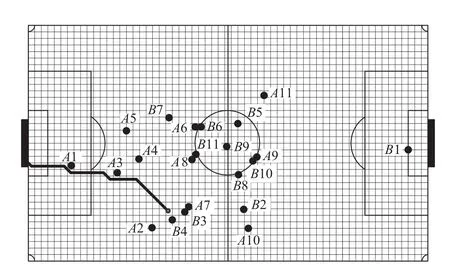
图6 传统A*算法规划的最短路径
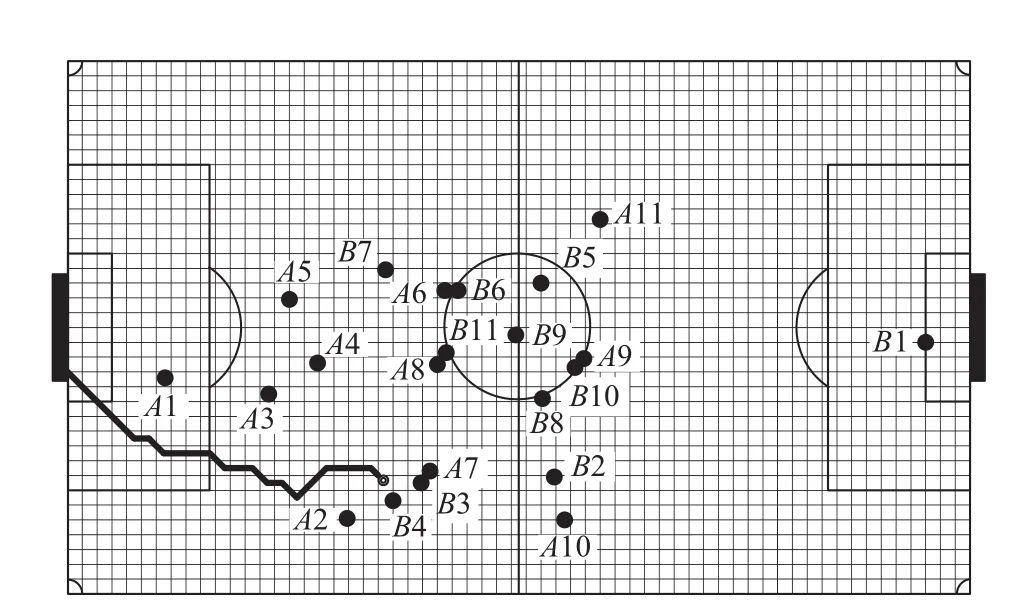
图7 风险值最低的路径

图8 改进后的A*算法规划的最优安全路径
4 结束语
本文首次全面的对球员影响区域进行了分析,通过对球场进行区域划分并设置风险值,再进行路径规划,模拟了人类足球运动员的突破行为,这是以往的路径规划方法都没有考虑到的.
此外,传统的A*算法都只是求解最短路径,对于移动障碍物的避障路径规划效果不佳.而本文的A*算法不仅考虑了路径的长度,还考虑了路径上每个结点的权重,仿真对比结果表明改进后的A*算法计算出的路径更加安全可靠.
1 方宝富,王浩.机器人足球仿真.合肥:合肥工业大学出版社,2011.
2 祁晓钰.机器人足球路径规划的一种改进算法.计算机仿真,2014,31(5):373–377.
3 Mabrouk MH,Mcinnes CR.Solving the potential field local minimum problem using internal agent states.Robotics and Autonomous Systems,2008,56(12):1050–1060.[doi:10.1016/j.robot.2008.09.006]
4 Masoud AA.Managing the dynamics of a harmonic potential field-guided robot in a cluttered environment.IEEE Transactions on Industrial Electronics,2009,56(2):488–496.[doi:10.1109/TIE.2008.2002720]
5 潘攀.足球机器人路径规划算法的研究及其仿真.计算机仿真,2012,29(4):181–184.
6 Garcia MAP,Montiel O,Castillo O,et al.Path planning for autonomous mobile robot navigation with ant colony optimization and fuzzy cost function evaluation.Applied Soft Computing,2009,9(3):1102–1110.[doi:10.1016/j.asoc.2009.02.014]
7 丁彪.基于改进遗传算法的移动机器人路径规划.自动化应用,2014,(1):1–3.
8 Kala R.Multi-robot path planning using co-evolutionary genetic programming.Expert Systems with Applications,2012,39(3):3817–3831.[doi:10.1016/j.eswa.2011.09.090]
9 Yang SY,Cheema MA,Lin XM,et al.Reverse k nearest neighbors query processing:Experiments and analysis.Proceedings of the VLDB Endowment,2015,8(5):605–616.[doi:10.14778/2735479]
10 林志雄,张莉.基于神经模糊势场法的足球机器人路径规划.计算机仿真,2014,31(1):416–420,437.
11 刘成菊,韩俊强,安康.基于改进RRT算法的RoboCup机器人动态路径规划.机器人,2017,39(1):8–15.
12 王红卫,马勇,谢勇,等.基于平滑A*算法的移动机器人路径规划.同济大学学报(自然科学版),2010,38(11):1647–1650,1655.[doi:10.3969/j.issn.0253-374x.2010.11.016]
13 辛煜,梁华为,杜明博,等.一种可搜索无限个邻域的改进A*算法.机器人,2014,36(5):627–633.
14 赵奇,赵阿群.一种基于A*算法的多径寻由算法.电子与信息学报,2013,35(4):952–957.
