基于遗传算法的Vivado HLS硬件加速①
2018-02-07陈宝林郭升挺吴家飞苏浩明
陈宝林,黄 晞,张 仕,郭升挺,吴家飞,苏浩明
1(福建师范大学 医学光电科学与技术教育部重点实验室 福建省光子技术重点实验室,福州 350007)2(福建师范大学 数学与计算机科学学院,福州 350117)
过去几年,机器学习在各个领域和商业应用已经变得非常普遍.2016年3月,基于深度学习的人工智能程序与世界围棋冠军、职业九段选手李世石进行人机大战,同年12月,百度研发的人工智能机器人又与世界记忆大师王峰进行了人脸识别挑战.至此,深度学习的热潮再次加速了机器学习和人工智能的发展.然而,深度学习模型对精度要求和计算能力也越来越高,神经网络的大小也发生了爆炸式的膨胀,例如:有着1000亿神经元连接的百度大脑和10亿神经元连接的谷歌猫脸识别[1].在如此巨大的数据与规模,只能靠更好的硬件来加速才能适应其需求.通常来说,硬件在执行诸如复杂的算法,需要将数据进行转移,以及重复执行各种操作等都比软件操作快得多[2].
到目前为止,硬件加速主要是使用图形处理单元(GPU)集群作为通用的计算图形处理单元(GPGPU)[3].此外,开放型并行程序设计标准(OpenCL)对FPGA、DSP和GPU等一些硬件均支持,并且对开发人员来说是免费、开源的,因此作为异构硬件编程的工具也深受吸引.除了GPU外,FPGA由于硬件配置灵活,具有可编程、高可靠性、高集成度和高速等优点[4],且在单位能耗下与GPU相比有更好的性能,在功耗、性能和实时性方面显著优于其他处理器.2015年,Intel以167亿美元收购 了Altera、Xilinx和IBM正式联手,都充分说明了FPGA在这个充满竞争的大数据市场的重要性.当前FPGA的主要厂商是Xilinx和Altera,这两家公司在全球市场中占据着近90%的市场份额.因此无论是在未来深度学习领域里,还是其他相关领域,FPGA将更受广大科研人员和业界的关注.
目前FPGA的设计主要采用Verilog HDL和VHDL两种硬件描述语言.硬件描述语言是属于并行结构,而且需要有一定的硬件基础才能进行仿真、综合和布局布线.一般开发人员所熟知的C/C++语言是属于顺序执行,硬件描述语言与C/C++语言还是存在着一定差距,文献[5]提到,一百万门的数字逻辑的时序设计需要三百万行RTL代码,这就使得一些软件工程师望而却步.
本文将采用Xilinx公司所提供的Vivado HLS工具套件,HLS (High Level Synthesis)为高层次综合,它能将软件开发人员所编写C/C++等高级语言代码转到可编程逻辑设计中,用户无需事先了解相关硬件知识就可实现RTL级的硬件功能.利用Vivado套件可以缩短1/3的RTL仿真时间,提高超过100倍的算法验证速度[6],这不仅仅受益于软件工程师,而且大大加速了IP创建,缩短了开发周期,提高了开发效率.目前国内外学者大多针对特定算法进行优化加速或只是对HLS进行粗糙应用,并没有具体的指令优化策略和依据,拓展性不好,缺乏通用性.比如:文献[7]想到了对缓冲区进行管理以及对带宽进行优化,提出了一种roofline模型的设计方法,通过数据重用减少外部数据获取的延时,从而找到了最优性能和最低FPGA资源消耗.但此种方法只是针对特定情形,缺乏通用性,也没法找到最优全局性能.文献[8]提出了基于HLS开发方式的线性方程组求解数据通路设计,当中只是对HLS工具进行粗糙应用,并没有具体的指令优化依据和策略,而且拓展性不好.文献[9]利用软硬件协同设计方法,针对深度学习不同拓扑结构下的预测过程和训练过程的通用计算部分进行加速,但在精确度和性能权衡上并没有说服力,通用性不好.文献[10]提出了首个开源程序优化器来自动重写给定程序以便优化延时,实验结果显示,生成的程序可享有12倍的加速,同时增加 了7倍的精度,但消耗了4倍多的LUT,此方法适合HLS内部自动优化.文献[11]提出了两种对于HLS自适应GA方法:自适应GA算子概率(AGAOP)和自适应算子选择(AOS),AGAOP和AOS展现了比SGA更好的鲁棒性,文中表明自适应方法来解决HLS领域具有很大优势.
综合国内外对于HLS算法加速的研究,可以得到:传统的编程语言(硬件描述语言Verilog HDL或VHDL)由于开发周期长,开发难度大,需要有一定硬件知识,很难适应日益复杂的大数据时代,而基于高层次综合HLS的提出完美地解决了此类问题.
1 遗传算法分析
Vivado HLS工具中提供了20来种优化指令,添加这些优化指令能使计算速度提升,但同时也会大幅度增加FPGA的资源消耗.主要的优化指令如表1,每条指令产生的优化效果可参考官方手册.

表1 VivadoHLS优化指令
通常来说,一段复杂程序的函数、循环、数组和接口是非常多的,经排列组合后将迅速剧增.例如对DCT源程序,若采取9个主要优化点,进行排列编码后将产生:8X8X9X9X9X9X9X6X6=136048896种组合(其中8表示对函数进行优化的7种优化指令加上一种默认不添加指令情况,9和6则分别对应循环和数组的情形),如果把一条指令下的不同参数也进行编码(本实验采取一定策略的随机生成,暂不进行编码),将产生不可估计的组合,如此巨大的搜索空间单从人工尝试的手段是不可能完成的.假定产生一种解决方案进行分析将花费35s的时间,在不考虑参数设置的情形下,1亿多种组合将花费超过25年的时间,这个还是由机器运行搜索的时间.倘若采用人工不断尝试的方法来寻找较优的解决方案,所需的时间至少是这个的几十倍.这就非常有必要找到一种策略来快速搜索有用的优化点,附加考虑到时延与资源利用的权衡问题.因此,本实验采用遗传算法来快速搜索全局较优解.
遗传算法是源自生物界中的“物竞天择,适者生存”,模拟生物体在自然选择和遗传过程中所发生的繁殖、交叉和基因突变现象[12].一个种群经过漫长的繁衍,种群中的基因会逐步向能更好适应环境的方向发展,优胜劣汰,后代留下来的基本是适应度较强的优良个体.本实验利用GA从随机产生的初始种群(这里的种群指初始随机产生染色体条数的总数)开始搜索,通过一定的选择,交叉和变异操作,逐步迭代产生新的种群.
实验中具体的整个流程框架如图1,首先进行优化点的随机选择,自动生成.tcl文件后,调用Vivado HLS工具进行仿真分析生成初始种群.然后,提取生成报表中的XML数据进行分析,其中图2和图3为FIR程序中未添加任何指令情况下所产生的性能评估与资源评估数据.接着在进行染色体的编码与适应度的计算.最后在利用遗传算法进行染色体的选择、交叉、变异等一系列迭代重新生成更优的种群.
1.1 染色体编码
以下代码为DCT中读数据的一小段程序,其中read_data为函数名,RD_Loop_R、RD_Loop_C为循环的语句标号,buf、input数组名.



图1 流程框架图
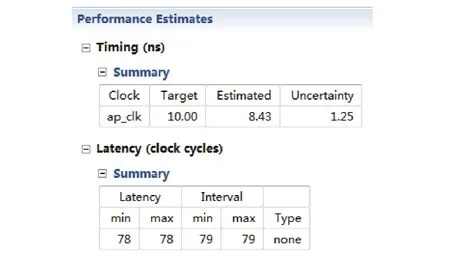
图2 性能评估图

图3 资源利用评估图
实验中主要是针对程序中的函数、循环、数组、接口进行指令的选择性优化.如表2为按照表3的染色体编码自动生成的一条染色体,其中前6位的评估指标分别表示Fitness(适应度)、Latency(时延)、DSP48E、FF(寄存器)、LUT(查找表)、BRAM_18K,后面部分(第7位到第16位)以4个字段为一组,按照表2进行编码,例如:0 dct_2d 2 7,0表示函数,dct_2d表示函数名,2表示子函数,7表示所添加的指令.其中Deep1有两个取值:1(表示顶层函数)、2(表示子函数);Deep2表示共有几层循环嵌套,如1表示一层嵌套,2表示两层嵌套;Deep3表示数组维数,如1表示一维数组,2表示两维数组;Deep4表示接口数组维数,表示方法与Deep3相同.Directive1到Directive4分别对应表1中的函数、循环、数组和接口的优化指令编号.

表3 染色体编码
1.2 适应度计算
本实验的目的是寻找最少时延与面积,选择适应度值尽可能大的染色体,因为适应度值越大,表示的染色体越优质.以下为所求的适应度公式[11]:

说明.Latency表示时钟周期延迟,即要得到输出结果得花费的时钟个数.DSP48E、FF、LUT和BRAM表示添加某种优化指令后所产生的资源利用个数,具体可参考图3中的资源利用评估图.
1.3 选择操作
本实验中首先根据提取到的适应度值大小进行染色体排序,在以一定概率从中选择优良的个体,剔除劣质染色体,按照轮盘赌选择法对优良个体进行重插入.比如表3中的三条染色体,先对Fitness进行排序,然后在择优选取适应度高的(如第一条),剔除适应度低的(如第二条).最后在将第一条染色体重新插入到第二条中.
1.4 交叉操作
本实验采用的是部分映射杂交,将父代的样本两两分组,随机确定两个位置进行两两交叉.交叉过程中为防止适应度高的染色体产生突变,对高适应度个体采取不参与交叉和变异操作.如表4中为交叉前的3组染色体,第一组适应度较高,暂不进行任何操作,第二组和第三组分为一组进行交叉操作,依次类推.然后随机在染色体中确定两个位置,比如R1和R2,再对其进行交叉操作(即进行指令的交换):
0 dct 1 7 <---> 0 dct 1 0
2 row_outbuf 2 4 <---> 2 row_outbuf 2 5
如表5为染色体交叉后又重新生成的数据,此时产生的适应度均高于交叉前的,具体生成的情况并不固定,也可能会偏低.
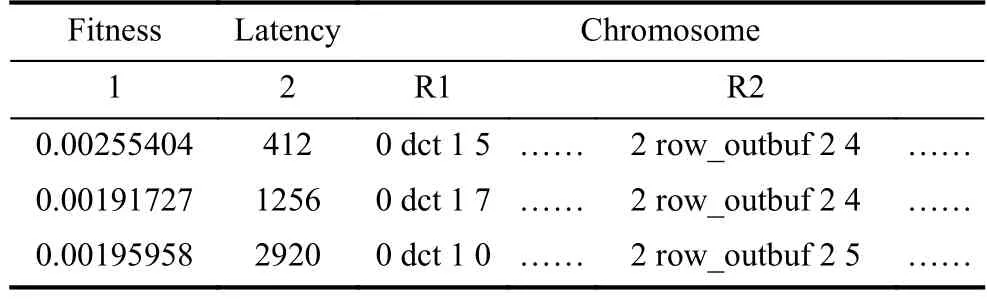
表4 染色体交叉前
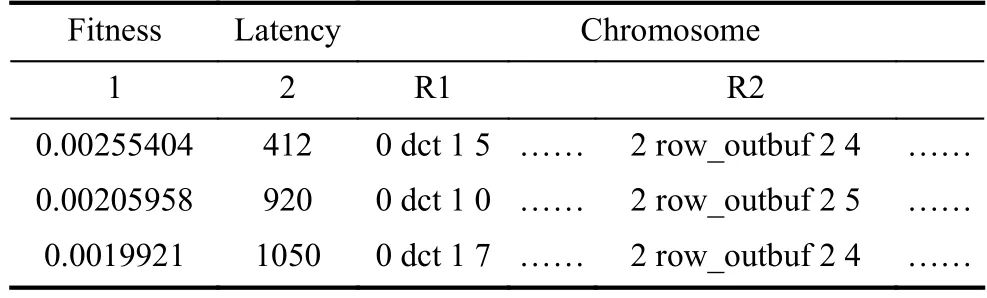
表5 染色体交叉后
1.5 变异操作
随机确定两个点进行变异操作.变异是个小概率事件,因此使用中所设置的参数要较小.如表6所示,随机确定R1、R2两个变异点,对其进行变异操作:
0 dct 1 0 <---> 0 dct 1 3
2 row_outbuf 2 5 <---> 2 row_outbuf 2 1

表6 染色体变异前
表7为变异后重新产生的结果,可见比变异前的效果更好,但这种操作具有偶然性的、不确定性,也可能变得更差.

表7 染色体变异后
2 GA的参数设置
实验中主要针对程序中的函数、循环、数组和接口进行指令选择优化,同一条指令下的不同参数采用一定策略的随机自动生成.实验对象选取了Xilinx主要的3个案例进行分析,其中GA的具体参数设置如表8.

表8 遗传算法参数设置
说明.种群大小、最大遗传迭代、交叉率和变异率对实验结果和运行速度都有一定影响,但现无理论依据对其选取,唯有通过不断尝试才能确定其合理的大小.表中数据是经过数十次尝试(包括增大迭代次数、种群数等)而得到的结果,由于实验对象不是特别复杂,最优解收敛快,因此迭代次数没有设置太大.
3 实验结果与性能评估
3.1 实验环境
本实验采用的处理器为:Intel(R)Core(TM)i5-3210M CPU @2.50GHz,采用的FPGA为Xilinx kintex7,xc7k160tfbg484-1.利用Vivado HLS工具进行各种算法的初始仿真验证.编译器采用VS2013进行主程序的大量仿真实验与遗传算法的测试分析,MATLAB作为最后实验结果的数据图表分析.
3.2 实验结果与性能评估
如图4为FIR基于遗传算法寻找最优解的进化过程,图中各点为每50个样本(共1050个)中选取的最优适应度,包含初始解总共有21个点,因此图像波动性不大,为观察方便而绘制成连续图像.如图,经20次迭代后,子代的适应度值已明显趋于稳定,此时的适应度值为0.33442982,其中当种群迭代到第6代后,优质染色体发生了突变,适应度降低,但由于在逐代进化中保留了父代的优良品质,因此适应度又迅速提升.

图4 FIR最优解的进化过程
图5为FIR初始产生的样本数据与经过遗传算法最终产生的样本数据的适应度对比图,由图显然可以看出其后代基本稳定在0.05以上,其中个别经过GA后的种群样本适应度偏低以及有大范围波动是由于染色体底层参数(即一条指令下参数设置不同)随机变化而产生,但这并不会影响整个种群中的最优解.为了探讨参数变化的影响,实验中特意选取了复杂度较为简单的Matrixmul (矩阵相乘)来进行分析,其中实验条件将一条指令下的参数固定(即不人为进行随机数生成,而是采取HLS工具中的默认参数).如图6、图7为Matrixmul产生的适应度分析图,其中图6,由于Matrixmul复杂度不高,后代在第7代的种群中就发现存在较优的解,因此其后很快就稳定下来.由图7可显然看出,在没有参数影响下,后代适应度全部稳定在0.251675中,当然如果FIR也将参数固定也会产生类似结果.

图5 FIR初始与GA后的样本适应度分布图
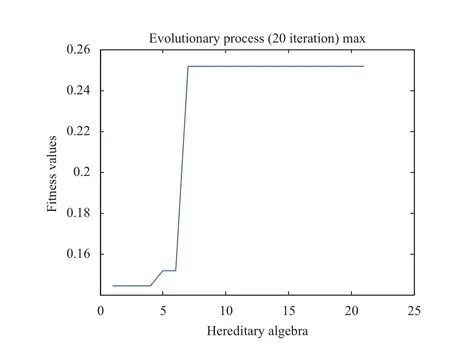
图6 Matrixmul最优解的进化过程

图7 Matrixmul初始与GA后的样本适应度分布图
表9、表10为FIR和Matrixmul的性能与资源利用的各自对比,第一行表示不添加任何优化指令的情况下所产生的结果,第二行表示Xilinx公司例程中所给的最好方案(实验条件相同下),第三行表示本文中利用GA寻求最优解产生的结果,对比三种方案易知,在资源充足下,权衡时延与面积,第三种方案是最优的,而且在资源比Xilinx公司提供的方案还少下,却有较大的适应度,在此也表明了利用GA寻求最优解的有效性.

表9 Performance and utilization comparison to FIR

表10 Performance and utilization comparison to Matrixmul
同理,利用本软件架构对DCT进行寻优,运行结果与所得数据如图8、图9和表9,具体的分析类似前面所述.由于硬件条件的限制,实验中减少了解空间的复杂度,指令下的参数采用默认生成,数组固定采用ArrayPartition的优化指令,共设置11个优化点.如图8、图9,后代在第13次迭代中稳定下来,寻优期间只有一次波动,经过20迭代后基本在适应度为0.00743396中稳定下来.值得注意的是,从表11可以看出此时的资源消耗也非常大,但在资源充足情况下,以空间换时间也未尝不是一种不错的措施.

图8 DCT最优解的进化过程

图9 DCT初始与GA后的样本适应度分布图

表11 Performance and utilization comparison to DCT
4 结束语
为适应目前的大数据时代,将各种算法在硬件上进行加速是非常有必要的.传统的硬件描述语言因其开发周期难,开发难度大等因素而无法满足当前需求.通常情况下,各种算法源代码中的函数、数组、循环和接口是非常之多,这就造成了优化点的解空间剧增,因此本文提出了一种基于遗传算法利用Vivado HLS工具进行快速寻找最优解.通过对Xilinx公司所提供的FIR、DCT和Matrixmul三个主要案例进行详细分析,运用本人所写的一套程序架构对其仿真实验,寻找到了较优的可行方案,此程序架构也可适用于其他需要硬件算法加速的程序,一定程度上满足了通用性.实验过程中也发现了对于复杂程序,由于优化点较多将产生组合爆炸,使得想在庞大的解空间中寻找最优解变得很难,因此必须采取一定策略来降低这个天文数字,比如只针对其中的关键程序做优化,这些都将是今后研究的重点.
1 Wang C,Gong L,Yu Q,et al.DLAU:A scalable deep learning accelerator unit on FPGA.IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems,2017,36(3):513–517.
2 http://blog.chinaunix.net/uid-20361370-id-1962845.html.
3 http://www.codesec.net/view/410065.html.
4 Slimane-Kadi M,Brasen D,Saucier G.A fast-FPGA prototyping system that uses inexpensive high-performance FPIC.Proceedings of 2nd Annual Workshop on FPGAs.Berkeley,CA,USA.1994.147–156.
5 O’Loughlin D,Coffey A,Callaly F,et al.Xilinx vivado high level synthesis:Case studies.Irish Signals &Systems Conference 2014 and 2014 China-Ireland International Conference on Information and Communications Technologies.Limerick,Ireland.2013.352–356.
6 思文.Vivado设计套件将速度提高四倍.中国电子报,2013-06-18(007).
7 Zhang C,Li P,Sun G,et al.Optimizing FPGA-based accelerator design for deep convolutional neural networks.Proceedings of the 2015 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays.Monterey,CA,USA.2015.161–170.
8 王晓璐.基于Zynq的LS-SVM算法加速器设计[硕士学位论文].哈尔滨:哈尔滨工业大学,2015.
9 余奇.基于FPGA的深度学习加速器设计与实现[硕士学位论文].合肥:中国科学技术大学,2016.
10 Gao X,Wickerson J,Constantinides GA.Automatically optimizing the latency,area,and accuracy of C programs for high-level synthesis.Proceedings of the 2016 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays.Monterey,CA,USA.2016.234–243.
11 Mei FCC,Phon-Amnuaisuk S,Alias MY,et al.Adaptive GA:An essential ingredient in high-level synthesis.Proceedings of the 2008 IEEE Congress on Evolutionary Computation.Hong Kong,China.2008.3837–3844.
12 马永杰,云文霞.遗传算法研究进展.计算机应用研究,2012,29(4):1201–1206,1210.
