基于标签扩展的协同过滤算法在音乐推荐中的应用
2018-02-01章宗杰陈玮
章宗杰+陈玮
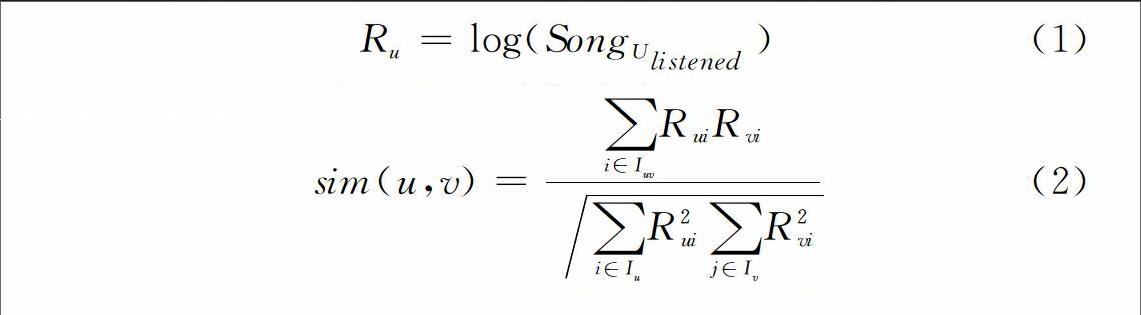


摘要:
推荐技术作为过滤海量信息的手段,在音乐领域也给人们带来了便利。但音乐推荐与传统的电商推荐相比存在显式反馈不宜获取、内容特征提取代价大等缺陷。针对上述情况,提出一种基于标签扩展的协同过滤算法,将社会化标签内容作为物品内容,基于内容计算对用户未收听的物品进行评分,在此基础上利用协同过滤为用户提供推荐列表。实验结果表明,该算法可以有效改善推荐结果的准确性,提高推荐质量。
关键词:
推荐技术;音乐推荐;协同过滤;社会化标签
DOIDOI:10.11907/rjdk.172220
中图分类号:TP312
文献标识码:A文章编号文章编号:16727800(2018)001009903
Abstract:Recommended technology is a means of filtering large amounts of information, bringing convenience to people in the music field. But music recommendation is different from traditional electricity recommendation. There exist drawbacks in the music field, like difficult acquiring explicit feedback, costly extracting content features and so on.In view of the above situation, a collaborative filtering algorithm based on label extension is proposed. The content of socialized label is taken as the content of the item, and the score of the nonlistened item is calculated based on the content. The user will get a recommended list by this way.The experimental results show that the algorithm can improve the accuracy of recommendation results and the recommended quality.
Key Words:recommended technology;music recommendation;collaborative filtering; socialized label
0引言
随着互联网尤其是移动互联网的兴起,如何在海量的信息和数据中挖掘有价值的信息呈现给用户,成为电商、社交、新闻、影音等各大主流应用的当务之急,而推荐技术可为这些领域提供解决问题的方法。推荐技术根据用户的兴趣、行为等信息,给用户推送最可能感兴趣的物品,使用户得到更好的体验[1]。如今推荐技术得到了长足进步,不仅是学术界的研究热点,更在电商、社交平台、在线广告等领域发挥重要作用。本文着眼于音乐推荐领域,结合社会化标签与协同过滤算法,以期提升推荐准确率。
1音乐推荐研究现状
早期的音乐推荐主要采用基于内容的推荐算法,通过音频信号分析歌曲的底层特征,进而将内容相似的歌曲放入推荐列表。如牛滨等[2]提出基于MFCC与GMM的个性推荐模型提取歌曲语音特征,但是声学元数据的提取非常耗时,而现今音乐产品更新快速,每天都会推出新的数以万计的音乐,所以纯粹基于音频特征的音乐推荐已逐渐被淘汰。
自从Tapestry系统为解决信息过量问题采用协同过滤技术以后,协同过滤即迅速被应用于其它领域的推荐[3]。著名的国外音乐平台Last.fm即是采用协同过滤技术推荐的代表。Last.fm将用户行为记录放入服务器中,据此找出若干兴趣偏好相似的“最近邻”,最后将最近邻喜好,但目标用户未听过的歌曲推荐给目标用户。而在国内的最新研究中,王君等[4]提出了层次音乐推荐系统概念,一方面采取用户间音乐偏好相似度进行协同过滤的音乐推荐,另一方面,音乐内容的相似包括情感、节奏、音色、旋律、歌词等多个维度,将两方面联系起来,充分发挥两者优势,从而提高推荐满意度。
2音乐推荐相关技术
2.1音乐推荐特点
与其它领域的推荐不同,用户在使用音乐产品时仅将其用于娱乐或辅助工作学习的用途,因而造成了音乐推荐与主流电商推荐的差异。在电商、电影推荐中,因为用户要付出更大的经济或时间代价(如要付费购买物品,花两小时观看电影),用户更愿意主动向系统作出反馈,收集显式评分任务会相对容易。而音乐产品本身只有几分钟的时间耗费代价,用户并不会特意对其进行评分行为,系统只能对用户语境信息[5](如用户播放歌曲行为、用户注册信息等)进行记录。
2.2社會化标签应用
标签是一种无层次化结构、用来描述信息的关键词,可以用来描述物品的语义[6]。根据给物品贴标签的人的不同,标签分为两种:一种是让相关领域的从业者给物品贴标签,在音乐推荐领域中,这种标签一般称为“音乐基因”;另一种则是让普通用户给物品贴标签,也即是社会化标签。由于让相关领域专家对物品进行标签行为的代价远高于用户自己进行标签行为,主流推荐领域主要采纳社会化标签系统,以提高推荐效果。
2.3基于协同过滤的音乐推荐算法
由于音乐推荐领域难以获得用户的显式评分,Hu等[7]提出将用户播放歌曲次数转化成用户评分的概念;Firan等[8]采用对数函数将用户播放行为转化为(0~10)分的用户评分集,然后进行协同过滤推荐。endprint
Frian提出的基于协同过滤的音乐推荐算法流程为:
(1)获取用户播放行为数据,将用户播放歌曲次数(Song_U_listened)按式(1)转化成用户评分Ru:
(2)建立用户-物品评分矩阵。
(3)根据余弦相似性式(2)计算用户u和v之间的相似性,找到与目标用户兴趣最相似的k个用户评分集合:
式中,Iuv为被用户u和v同时评分的物品。
(4)选取出k个用户收听过且目标用户未收听过的歌曲,根据式(3)计算目标用户对这些歌曲的预测评分ui,根据预测评分排序,选取评分高的前N首歌曲进行推荐。
式中,物品i为目标用户未收听过的歌曲,Ni(u)为近邻用户中收听过物品i的集合。
3基于标签扩展的协同过滤算法
RobinBurke[9]在2002年发表了一篇关于不同推荐算法混合设计的方案调研报告。报告中提出了7种不同的混合推荐策略,大致分为3种基本设计思路:整体式、并行式和流水式[10]。本文采用整体式混合设计,提出基于标签扩展的协同过滤算法。利用社会化标签,将其作为物品内容,得到物品间的相似度,利用基于内容的方法得到用户未评分物品的预测评分,得到更完整的用户评分矩阵后,再进行协同过滤推荐。
3.1标签处理
通常,基于内容的推荐系统被用来推荐基于文本的物品,如新闻、电子邮件等。本文将社会化标签作为物品内容,对其进行文本挖掘,得到物品相似度。首先,将音乐物品视为单个文档,对用户标签行为进行处理,得到一个基于TFIDF(词频—逆文档频率)权重的n维向量空间模型(Vector Space Model, VSM)。每首歌曲被表示成一个文档dj,让D={d1,d2,…,dN}表示一个文档集合,T={t1,t2,…,tN}表示词典,即文档集合中的标签集合,从而使dj={ω1j,ω2j,…,ωnj},其中ωkj是文档dj中标签tk的权重。根据式(4)计算文档相似度(即音乐物品相似度):
3.2基于标签扩展的协同过滤算法
加入对用户标签行为的分析可以扩大单一基于协同过滤的推荐系统的特征空间,也能为推荐结果提出更为合理的解释理由。本文将标签作为物品内容,得到物品相似度,基于内容对未评分的物品进行预测评分,得到的结果能有效补充原有的评分矩阵。然后,在所得的更为完整的用户评分矩阵上利用协同过滤算法计算用户实际未评分物品的预测结果。最后根据评分排序,给目标用户提供一个含有前N首高评分歌曲的推荐列表。为此,本文构造了一个虚拟的用户评分向量vui用来表示用户u对物品i的评分,如式(5)所示:
当用户u收听歌曲i时,用户评分vui则由用户u收听歌曲i的次数进行直接转换,采用的是Firan在实验中所用的转换函数;若用户u未收听过歌曲i,将利用上述标签信息基于内容进行评分预测,如式(6)所示:
式(6)中,k为与歌曲i最相似的k个项目,引入ωt是为了对热门歌曲进行惩罚。这里将被贴标签数nt多于每首歌曲被贴标签数nta的歌曲视为热门歌曲,根据式(7)可得到权重ωt:
同样,引入ωur适当惩罚活跃用户,这里将用户行为记录数nu大于用户平均行为记录nua的用户视为活跃用户,根据式(8)可得到权重ωr:
从而得到用户u对物品i的预测评分ui:
根据最终预测评分的高低进行排序,给目标用户提供长度为N的推荐列表。
4算法实现与结果分析
4.1数据集
本文采用的是grouplens.org站点提供的last.fm音乐网站的真实用户数据。该数据包含1 892个用户、17 632位艺术家及用户的收听行为和标签行为记录。
本文使用10折交叉验证方法,将每个用户已进行收听行为的项目分成10个互不相交的集合。进行10次实验,每次实验选择其中一个集合作为测试集,其余集合为训练集。
4.2评测指标
进行推荐的目的是为了找到用户最可能感兴趣的物品,因此本文采用的推薦方式是更符合现实要求的TopN推荐,即给用户提供一个长度为N的推荐列表。TopN推荐中常用的评测指标是准确率(Precision)。通过选取不同长度N的推荐列表,可以全面评测实验算法的准确率,Precision定义为:
式(10)中,R(u)为算法生成的长度为N的推荐列表,T(u)为用户在测试集上的行为列表。
4.3结果分析
本文选取Frian提出的基于协同过滤的音乐推荐算法(CFTR)和基于标签的内容过滤算法(TagbasedCB)进行对照,通过选取不同长度N的推荐列表,以准确率为评测指标,然后与本文提出的基于标签扩展的协同过滤算法(TagexpandCF)作对比,实验结果如图1所示。
实验结果表明,本文提出的算法在选取不同长度N的推荐列表的情况下,相比于其它两种算法,均具有更高的准确率,明显优于传统算法。
5结语
本文在传统协同过滤算法的基础上,根据用户的标签行为对整个推荐系统的特征空间进行扩展,提出的基于标签扩展的协同过滤算法能够有效解决音乐推荐显式反馈不易获取、内容特征处理代价大的缺陷,并且对于数据稀疏问题也有一定改善,可显著提高推荐质量。
参考文献:
[1]RICCI F, ROKACH L, SHAPIRA B, et al. Recommender systems handbook:a complete guide for research scientists & practitioners[M].New York:Springer, 2010.
[2]牛滨,孔令志,罗森林,等.基于MFCC和GMM的个性音乐推荐模型[J].北京理工大学学报,2009(4):351355.
[3]GOLDBERG D, OKI B M, OKI B M, et al. Using collaborative filtering to weave an information tapestry[J].Communications of the ACM, 1992,35(12):6170.
[4]王君,许洁萍.层次音乐推荐系统的研究[C].中国计算机学会普适计算委员会, 2009: 6.
[5]陈雅茜.音乐推荐系统及相关技术研究[J].计算机工程与应用,2012,48(18):916.
[6]项亮.推荐系统实践[M].北京:人民邮电出版社,2012.
[7]HU Y, KOREN Y, VOLINSKY C. Collaborative filtering for implicit feedback datasets[C]. Eighth IEEE International Conference on Data Mining. IEEE, 2008:263272.
[8]FIRAN C S, NEJDL W, PAIU R. The benefit of using tagbased profiles[C]. Latin American Web Congress. DBLP, 2007:3241.
[9]BURKE R. Hybrid recommender systems: survey and experiments[J]. User Modeling and UserAdapted Interaction, 2002,12(4):331370.
[10]JANNACH D, ZANKER M, FELFERNIG A, et al. Recommender systems:an introduction[M].Oxford:Cambridge University Press, 2010.
(责任编辑:黄健)endprint
