一种基于近邻关系的新型离群评估算法
2018-01-29
(福建江夏学院 电子信息与科学学院, 福建 福州 350108)
离群点数据被认为是与其他观测值有较大差别、怀疑由不同机制产生的异常观测值,这些异常数据可能来源于不同的类、自然变异,以及数据测量或收集误差。现实生活中,由于异常事例常常隐藏着有价值和出乎意料的知识,挖掘异常事例及离群数据往往比常规情况更加令人关注。离群点的检测作为目前数据挖掘技术中重要的研究领域,广泛应用于包括信用卡欺诈发现、网络安全入侵检测、生态系统失调预测、犯罪行为发现及预防医疗检查等众多行业领域研究[1]。此外,离群点检测也常用于检测数据集中的异常样本,剔除“脏数据”以提高如聚类和分类计算的数据分析质量。
目前异常检测数据挖掘主要包含基于模型、密度、聚类和距离等技术。基于模型(distribution-based)的检测技术通过估计概率分布的参数来创建数据分布模型,不能很好地与模型相拟合的对象则被判别为异常数据。该技术不适用于数据的统计分布事先未知或没有训练数据可用的情况。基于密度(density-based)的检测技术通过计算每个数据对象的密度评估值,将低密度区域中的数据对象检测为离群点,如LOF算法[2]、MDEF[3]、COF[4]和NLOF[5]等算法,这些算法可适用于具有不同密度区域的数据集,但对初始参数的选择非常敏感。基于聚类(clustering-based)的检测技术通过执行聚类操作,将远离其他簇的小簇标识为离群对象,或使用目标函数来评估对象属于簇的程度,根据离群点评估值隔离异常数据。基于距离即邻近性度量(distance-based)的技术,不需要事先了解数据分布模式,将远离大部分其他对象的对象判定为异常数据,最常见的方法是Ramaswamy等人[6]提出的k-近邻(k-th nearest neighber)离群挖掘算法,当某个数据对象与其近邻数据对象的距离很大时,则认为该数据对象位于稀疏区域并成为离群对象。该算法通过构造KNN图,依据每个数据点到kth最近邻数据点的距离进行排序,将排序列表中距离数值较大的若干数据点视为离群点。
在众多离群挖掘算法中,基于距离和密度的离群点挖掘算法是最有代表性和最有效的挖掘方法。
1 问题的提出
使用KNN算法对图1所示数据集进行离群点检测,当参数k取值为7时,数据点A和B将获得相同的离群评估值,A、B数据点的k近邻距离均为p,则被视作相同等级的离群点;而当k取值为8时,该方法误将A视作比B更强的离群点。从直观角度上不难看出,B比A更趋向于成为离群点。若离群检测算法仅从距离角度考虑离群评估,存在着明显的缺陷。
文献[7]提出的算法将数据点与其k个最近邻数据点的距离之和作为判别离群对象的评估值以实现KNN算法的改进。由于数据点B远离于其他数据点,其与k近邻距离之和即离群评估值大于数据点A的离群评估值,此改进算法虽然可以解决KNN算法对于图1所示数据集存在的离群检测问题,然而对于图2所示的密度差异较大的簇集,无论采用k-近邻距离或是求距离之和的方法,都只能检测出全局离群点D,而无法识别密集簇附近的局部离群点C,且很可能误将稀疏簇中的大部分数据判定为离群对象。因此,基于距离的离群检测算法适用于密度相近的簇集,对于稀疏各异的簇集,检测错误率将大幅提高。

图1 具有相同离群评估值的两个数据对象A和B(k=7)Fig.1 Data A and B with equal outlier evaluation values

图2 密度差异较大的两个簇集Fig.2 Two clusters with great differences in density
Breaunig等人[2]提出的LOF(local outlier factor)算法通过引入局部离群因子来评估对象相对于邻域的孤立程度,对分布密度相差较大的簇集有较好的检测结果。该算法不从全局的角度考虑数据对象的离群特性,而是计算各数据对象与其最近的k个邻居的局部密度比,以获取离群系数。局部密度较大的数据对象具有较小的LOF评估值,LOF评估值较大的数据对象则被判别为离群点。如图2所示的数据集中,由于离群点C和D都与其邻近的数据点有较大的密度差异,若参数选择得当,使用LOF算法可以有效识别这两个离群点。然而,对于数据点G和C来说,由于他们的最近邻密度对象均属于密集簇(近邻数据点的密度相近),且数据对象C比G更靠近密集簇,根据LOF算法,数据对象G将获得比C更高的离群评估值,即算法认为G将比C更有可能成为离群点,很明显地,G只是与密集簇相近的一个稀疏簇中的正常数据对象。与基于距离的离群检测算法对比,LOF算法虽然能够有效检测出局部离群点,但当两个密度各异的簇集相互靠近时,该算法很容易将稀疏簇与密集簇交界的数据对象误判为离群点。
综上所述,本文提出一种新的数据对象离群评估算法,使得在密度差异大的簇集中,也能实现正确的离群评估。
2 基于密度和距离相结合的新型离群检测算法CDD算法
数据对象成为离群点的概率大小不仅与周围邻居数据点的密度相关,还与其偏离其它数据点的距离大小相关,数据对象周围邻居密度越小、偏离邻居数据点的距离越大,则成为离群点的可能性就越大。综合考虑这两方面因素,提出一种基于密度和距离相结合的新型的离群检测算法CDD(combination of density based and distance based outlier detection algorithm),过程描述如下:
首先基于k-近邻构造有向近邻图,其中,对邻域的选择沿用传统经典k-最近邻域理论[8]。将各数据点作为图的顶点,指向与自己最相近的k个邻居数据点,如图3所示,然后结合该数据点与近邻数据点的距离以及该数据点与周围数据的密切关系来综合衡量其孤立的程度,获取离群评估值,具体描述如下:
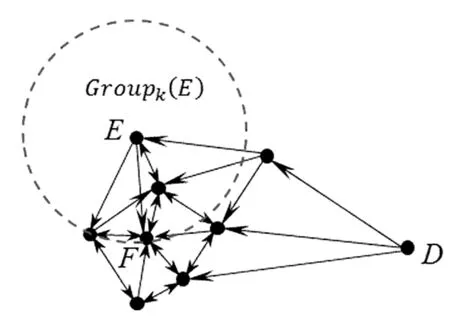
图3 数据对象指向最邻近的k个邻居(k=3)Fig.3 Data pointing to k nearest neighbors (k=3)

1.2.2 观察组 在上述服药基础下,给予患者自拟补肾活血方。方剂成分如下:熟地黄15 g,山茱萸15 g,山药(炒)15 g,茯苓 15 g,薏以仁 12 g,车前草 10 g,续断 12 g,菟丝子 15 g, 杜仲(盐炒)20 g,党参 15 g,玉米须 15 g,生黄芪 20 g,红花 12 g,紫丹参 12 g,白术(炒)20 g,陈皮10 g,白茅根 20 g,川芎(酒炙)8 g。 1 剂/d,分早晚服用。共服用2个月。
k_Dist(xi)}.
当k=3时,图3显示出数据集X中各数据对象与其k-最近邻居的关系。其中,每个顶点xi代表一个数据矢量,每条边都指向该对象最近的k个邻居,即Groupk(xi)中包含的k个数据对象。
定义2令Neighk(xi)为数据集X中所有指向xi(xi∈X)的矢量对象的数量。对于∀xi∈X,若xi∈Groupk(xp)(p∈[1,n]),则Neighk(xi)=Neighk(xi)+1。
Neighk(xi)从全局角度考虑数据对象xi的邻域关系,从很大程度上评估出数据点xi与邻近对象关系的密切程度。其数值越大,xi数据对象成为其它数据对象的k-近邻的情况越多,则表示数据对象xi存在于高密度区域的概率越大,其成为离群点的可能性则越低;反之,对于某数据对象来说,若没有或者极少其他数据对象的k-近邻指向它,那么该数据对象很可能是离群点。如图3所示的数据集中,对于周围数据点密集的F点来说,其Neighk(F)值为6,而H点远离大部分数据点使其不属于任何对象的k-近邻集合,Neighk(H)值为0。
定义3|Groupk(xi)|表示包含数据对象xi的k-近邻的集合的大小,那么数据点xi与其k个最近邻数据对象的平均距离为:
定义4对于给定对象的数据集X={x1,x2,…,xn},则每个数据对象的离群评估得分可表示为:

3 实验分析
3.1 模拟数据的离群检测对比
为了较好地展现新算法的优点,实验生成如图4所示的一组模拟数据,在3个不同密度的簇集(方点)中加入若干离群数据(圆点),采用KNN、LOF和CDD 3种算法实现离群数据的挖掘计算,最近邻个数k取值范围为2~8,数据挖掘的结果如图5-图7所示,分别显示了在不同的k近邻取值情况下3种算法获得的离群评估值。图5-图7按离群评估值从高到低显示出前8个数据对象,其中,横坐标表示k的取值,纵坐标表示相应的离群评估值。

图4 仿真数据集Fig.4 Simulation dataset

图5 KNN算法离群计算结果Fig.5 Outlier detection results of KNN algorithm
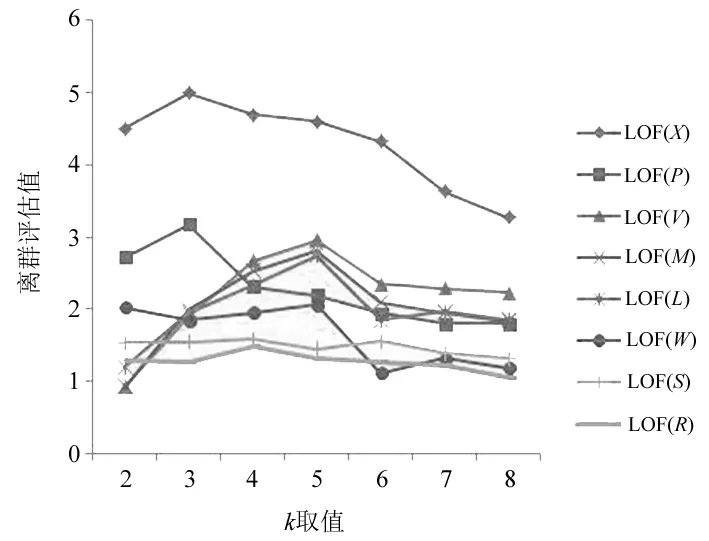
图6 LOF算法的离群计算结果Fig.6 Outlier detection results of LOF algorithm

图7 CDD算法离群计算结果Fig.7 Outlier detection results of CDD algorithm
从图5可以看出,离群点W和R并未被KNN算法检测出来,由于稀疏簇中的正常数据点(如O、T和N)的离群评估值均大于距离密集簇较近的离群点W和R,KNN算法并不能很好对密度差异较大的簇集进行离群点的识别,实验结果表明稀疏簇中的所有数据的离群值都高于离群点W和R,仅考虑距离因素的KNN算法,错检率较高。图6中,由于数据点R和S的邻近簇相同,而数据点R比S更靠近邻近簇,LOF算法则作出了错误的判断,认为正常数据点S的离群程度高于独立数据点R。当疏密差距较大的两个簇集相近时,稀疏簇边界上的数据点通常会被LOF算法误判为离群数据,而新算法CDD则解决了由于互相靠近的簇集密度不均衡所带来的边缘数据点离群值错误评估的问题,图7的检测结果显示,由CDD算法获得的前7位数据对象已准确涵盖本实验所有离群点,且它们的离群评估值也客观地体现出了各数据点的离群程度。
另一方面,k-近邻算法、LOF算法对参数k的取值具有较大的依赖性,为了获取高质量的离群检测结果,需要多次调整参数k的取值,并根据现实经验来判断最佳的离群检测结果。如图6所示,随着k值的变化,LOF算法下的各数据点的离群评估值也有较大的波动,k值的选定在一定程度上影响了离群检测结果的准确性和稳定性,而CDD算法得出的各数据点的离群评估值的大小排序则相对稳定(见图7),离群值走势不随k值的变化剧烈波动,说明CDD算法有效弱化了参数k对离群检测结果的影响,提高离了群点检测的稳定性和准确率。
3.2 真实数据集离群检测对比
3.2.1 Lymphography数据集
Lymphography数据集包含了来源于前南斯拉夫肿瘤学研究所的148条淋巴系造影术数据,每个数据包含18个分类属性。数据被划分为4个簇,其中两个簇分别包含了81和61个数据对象,而另外两个小簇分别包含2个和4个数据对象,本实验将占比较小的两个小簇中的6个数据对象作为歧异值进行离群检测,使用KNN、LOF和CDD 3种算法分别对该数据集实现数据挖掘并进行离群检测结果对比。各算法检测出的离群点中,正确的离群点所占比率越高,则表示该算法性能越好[9]。
表1列出了当最近邻居个数k取值为5~10时,3种算法获取的离群评估平均值排名前n位的离群数据的检测率对比,其中,检测率指检测到正确的离群数据量与离群数据总量的比值。从表1可以看出,CDD算法检测获取的前6个离群数据对象中已包含5个正确的离群对象,检测获取的前8个数据对象即涵盖了出所有离群对象,而KNN算法和LOF算法获取的前8个离群对象中,离群检测率仅为66.7%和88.3%;LOF算法须提取前10个离群数据才能找出所有离群点,KNN算法离群检测率更低,需要提取前12个离群数据。由此可见,在Lymphography数据集上,CDD算法在离群检测率方面明显优于其他两种算法。
3.2.2 Wisconsin breast Cancer数据集
Wisconsin breastCancer乳腺癌数据集包含569组数据,每个数据对象包含32个分类属性,其中良性肿瘤细胞特征有357例,恶性肿瘤细胞特征有212例,本实验将选取357个数据对象良性肿瘤细胞和部分恶性肿瘤细胞(32个数据对象),共389个数据对象作为检测样本,使用3种算法分别对其进行离群数据对象(恶性肿瘤特征数据)的检测,算法选取k值为10~15,测试对比结果如表2所示。

表1 3种算法在Lymphography数据集中的运行结果对比Tab.1 Comparison of results of three algorithms in Lymphography dataset
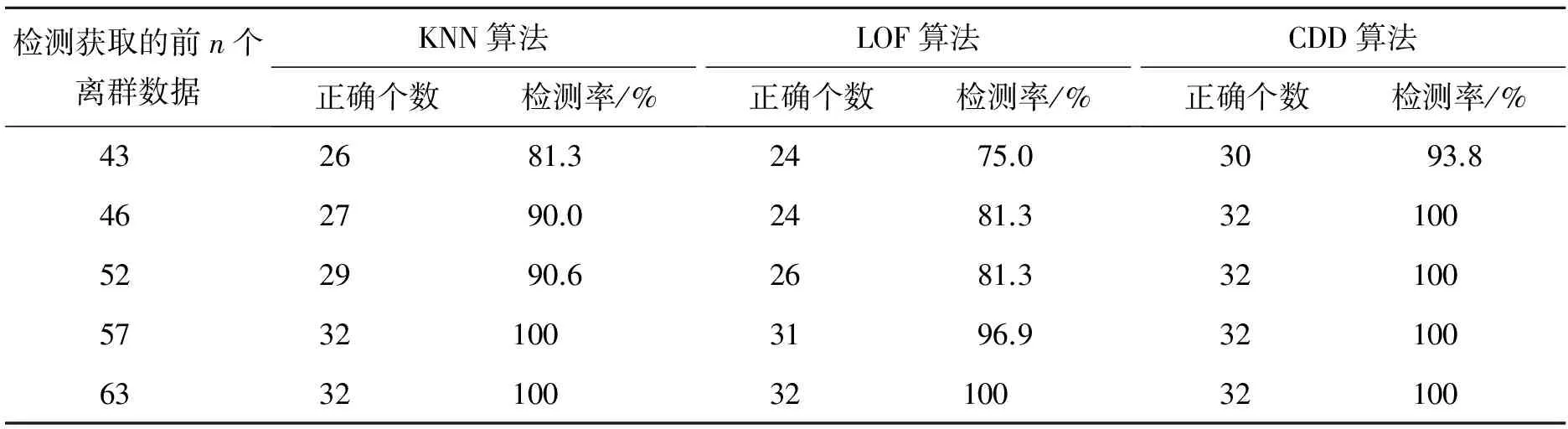
表2 3种算法在Wisconsin breast Cancer数据集中的运行结果对比Tab.1 Comparison of results of three algorithms in Wisconsin breast cancer dataset
分析实验结果可以看出,KNN算法和LOF算法分别需要检测出前57个和63个离群评估值较大的数据对象,才能找到所有恶性肿瘤离群数据。算法CDD检测出的前46个数据对象中已经包含所有32个离群数据,而KNN和LOF算法检测到的前46个数据中,仅分别包含27个和24个正确离群数据。因此,对于Wisconsin breast Cancer数据集,CDD算法的离群检测有效性还是优于KNN和LOF算法。
4 结语
本文提出的改进算法CDD通过构造有向邻近图,从簇中各数据对象的近邻密度疏密以及分布距离大小两方面进行综合考量,有效量化各数据对象的离群强弱程度并获得离群对象队列。通过在不同的数据集上的实验对比,结果表明新型算法的离群点检测准确度明显高于k-近邻算法及LOF算法,且有效弱化了离群算法对初始参数k取值的依赖性。
在此改进基础上,针对不同数据集的特征,进一步研究算法以降低时间复杂度、提高算法运行的效率,是今后要继续研究的方向。
[1] He Zengyou, Xu Xiaofei, Deng Shengchun. Discovering cluster-based local outliers[J]. Pattern Recognition Letters,2003,24(9):1641-1650.
[2] Breunig M, Kriegel H P, Ng R, et a1. LOF:Identilying densityhased local outliers[C]∥. Proc of the ACM SIGMOD International Conference on Management of Data,2000:93-104.
[3] Papadimitrious S, Kitawaga H, Gibbons P B, et al. LOCI: Fast outlier detection using the local correlation integral[C]∥. Proc of the 19thInternational Conference on Data Engineering,2002:315-326.
[4] Tang J, Chen Z, Fu A, et al. Enhancing effectiveness of outlier detections for low-density pattern[J]. Proceedings of the 6thPAKDD,2002,2236:535-548.
[5] 王敬华,赵新想,张国燕,等.NLOF:一种新的基于密度的局部离群点检测算法[J].计算机科学,2013,40(8):181-185.
[6] Ramaswamy S, Rastogi R, Kyuseok S. Efficient algorithms for mining outliers from large data sets[C]∥. Proc of the ACM SIGMOD International Conference on Management of Data,2000:427-438.
[7] Angiulli F, Pizzuti C. Outlier mining in large high-dimensional data sets[J]. IEEE Trans. Knowledge and Data Eng,2005,2(17):203-215.
[8] 范小刚,朱庆生,万家强.基于K-近邻树的离群检测算法[J].计算机应用研究,2015,32(3):669-673.
[9] 周世波,徐维祥.一种基于偏离的局部离群点检测算法[J].仪器仪表学报,2014,35(10): 2293-2297.
