基于双维度云模型的协同过滤推荐算法
2018-01-29刘美博满君丰
刘美博,满君丰,彭 成,刘 鸣
(湖南工业大学 计算机与通信学院 湖南 株洲 412000)
0 引言
网络的迅速普及和通信方式的多样化给人们带来了极大的便利,同时也造成了信息量的急剧增加。如何从大量信息中筛选出人们需要的信息就需要用到推荐系统。当前,推荐系统受到了广泛关注,而找到更好的推荐算法并合理应用一直是研究热点。
现有的推荐算法中,主流应用的推荐算法就是协同过滤推荐算法。传统的推荐算法在数据比较稀疏时,不能很好的进行相似度计算,导致推荐系统质量较低。同时新用户引进时,由于数据量比较少,造成不能得到很好的推荐,这就是冷启动问题[1]。
本文针对上述问题,基于前人的研究成果,提出一种双维度的协同过滤推荐算法。该算法是基于Hadoop分布式平台来实现的,充分发挥了Hadoop集群的优势。并且该算法选取用户和项目两个维度的数据展开研究,采用基于云模型的相似度计算方法[2]计算出用户相似度和项目相似度,然后通过动态度量方法计算出权值,再根据得到的相似度和权值求得用户对项目的评分预测值。通过实验,我们发现该算法对于以上问题得到了一定的解决。
1 国内外现状及分析
国内外学者针对上面提到的问题进行了一定的改进。文献[3]提出了一种将聚类算法与SVD算法相结合的新方法,通过使用他们的属性来对用户进行分类。然后用SVD算法分解评级矩阵,并将它们重新联合到新的评级矩阵中,以计算每对用户之间的相似性。该方法不仅可以改善“冷启动”和“数据稀疏”问题,还可以提高系统的效率和可扩展性。文献[4]在[0,1]范围内基于评级矩阵分解为两个非负矩阵的分量,通过这个分解可以准确地预测用户的评级,找出相似的用户组。文献[3-4]都是通过矩阵分解来解决传统推荐算法的数据稀疏问题,但该方法还存在不足,通过矩阵分解降维会导致数据失真,之后计算出来的相似性误差较大,导致推荐系统准确性降低。
文献[5]提出了一种基于用户偏好聚类的新型有效协同过滤推荐算法,引入了用户组以区分具有不同偏好的用户。通过考虑活动用户的偏好,从相应的用户组获得最近的邻居集合。分别考虑本地和全局透视中的用户偏好,以优选地计算用户之间的相似性。文献[6]中主要是通过计算用户间对不同类型项目的评分相似度,并通过这多个相似度更加精确地得出最终的预测评分。文献[7]中主要通过计算用户间的属性相似度和互动相似度,再结合动态权值分配计算综合的用户相似度。文献[5-7]都是属于基于用户这一分支的算法,都采用的是用户—项目评分矩阵。在推荐精度方面做了很多研究,使得推荐系统精确度得到大大提高,但扩展性问题和稀疏性问题还是存在。文献[8]通过使用多个相似性度量来计算项目之间的相似性,然后使用这些相似性值来预测用户的评级,并提出了一种基于项目的CF算法的MapReduce优化。该文献很好地解决了扩展性问题,同时在效率方面也有显著提高,但数据稀疏问题还是考虑得不全面。
文献[9]运用了两维度的数据,再根据两个维度的评分矩阵进行相似度计算。该算法充分考虑了两个维度的数据,并引入了不确定近邻因子的概念,很好地解决了数据稀疏问题,推荐精度也得到了提高。但该算法对于扩展性问题还是没有很好地解决,处理稀疏数据方面也能得到改进。而本文在此基础上,在相似度计算时运用云模型,然后通过Hadoop平台来处理大数据问题。这使得处理数据稀疏的能力得到了进一步的提高,同时对于扩展性问题也提出了解决方案。
2 协同过滤推荐算法
协同过滤推荐算法其基本思想是“物以类聚,人以群分”,依据相似性而产生推荐[10-11]。
要想运用协同过滤推荐算法,其数据必须是一个矩阵形式,如表1所示,其中U是用户,I是项目,Rmn表示用户集中的用户m对项目集中的项目n的评分。
该算法的核心就是寻找最近邻居,要想找到邻居必需计算相似性,常用的度量相似性的方法有以下三种[12]。
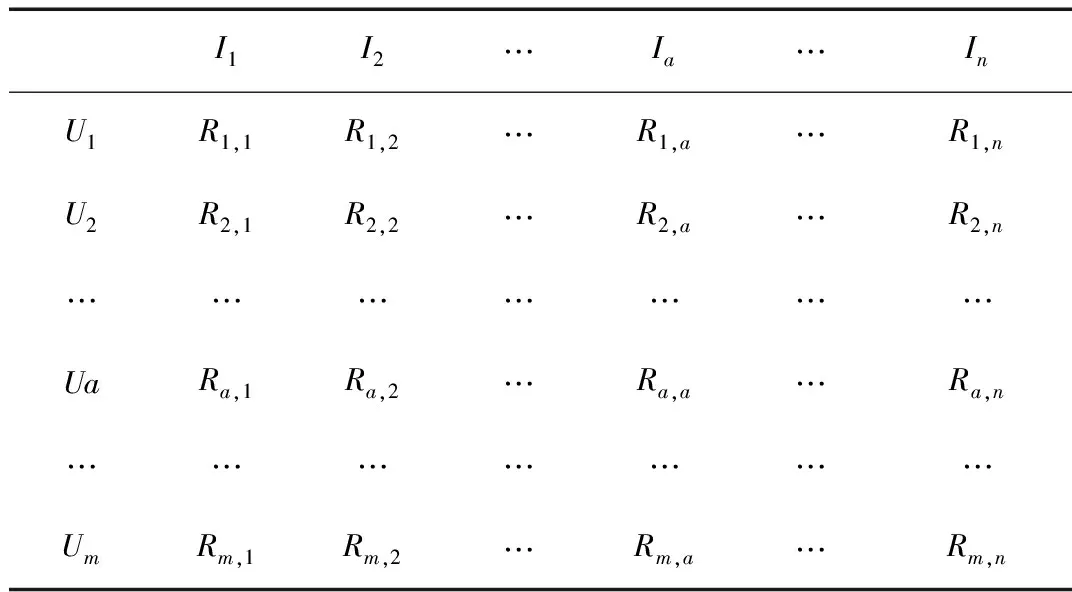
表1 用户-项目评分

(1)
(2)修正的余弦相似性:在余弦相似性基础上,考虑不同用户评分尺度不同的问题,把余弦相似性中的向量减去平均评分向量[8]如式(2)所示:
(2)
式中,Ri,d为用户i对项目d的评分;Ri为用户i对项目的平均评分;Rj为用户j对项目的平均评分;Iij为用户i与用户j都评分过的项目。
(3)相关相似性:计算Pearson相关系数来进行度量如式(3)所示:
(3)
以上三种方法为常用的相似性度量方法,而本文采用的是云模型相似性度量方法。
(4)云模型相似性:先根据评分矩阵统计得出用户或项目的评分频度向量Ui=(u1,u2,u3,u4,u5)(1≤i≤m),再通过逆向云算法计算特征向量如下:
特征向量Vi=(Exi,Eni,Eei),Vj=(Exj,Enj,Eej)。
(4)
通过上述方法计算出相似用户后,再根据公式(5)计算来产生推荐。
(5)
其中NESI表示邻居集。
算出预测评分后,再把评分值进行排序,然后再根据TOP-N算法做出推荐[13]。
3 双维度云模型协同过滤推荐算法
本文主要选取了基于项目云模型相似度和基于用户云模型相似度来综合得出最终预测评分,下面给出具体推荐示意图,如图1所示。

图1 推荐示意图
3.1 相关算法的实现
算法1 基于项目云模型相似度计算
输入:项目集合I、用户集合U、评分矩阵RU×I
输出:项目间的相似度矩阵SIMI×I
第1步:遍历项目集合I对矩阵RU×I中未评分的项目添加为0分;
第2步:统计项目的评分频度向量Iu=(i1,i2,i3,i4,i5),再通过逆向云算法计算特征向量;
第3步:参照公式(4)计算两项目间相似度sim(ix,iy)。
算法2 基于用户云模型相似度计算
输入:项目集合I、用户集合U、评分矩阵RU×I
输出:用户间的相似度矩阵SIMU×U
第1步:遍历用户集合U对矩阵RU×I中未评分的项目添加为0分;
第2步:统计用户评分频度向量Ui=(u1,u2,u3,u4,u5),再通过逆向云算法计算特征向量;
第3步:根据公示(4)计算用户ux与uy的相似度sim(ux,uy)。
3.2 推荐过程的MapReduce处理流程
(1)相似度计算的MapReduce
Map阶段:接收评分矩阵后,对每个评分数据进行提取,①基于项目这一维度以项目对(ix,iy)作为key值,项目对应的评分对(Sx,Sy)作为value值输出。②基于用户这一维度以用户对(ux,uy)作为key值,用户对应的评分对(Sx,Sy)作为value值输出
Reduce阶段:接收Map阶段的数据,① 基于项目这一维度根据算法1计算项目间的相似度;②基于用户这一维度根据算法2计算用户间的相似度;③将结果保存输出。
(2)预测评分的MapReduce
Map阶段:根据相似度的值,①基于项目这一维度得出每个项目相似度最高的N个项目定义为邻居,以项目为key值,项目邻居为value值输出。②基于用户这一维度得出每个用户相似度最高的N个项目定义为邻居,以用户为key值,用户邻居为value值输出。
Reduce阶段:接收Map阶段的数据,根据算法2计算出两个维度目标用户对未评分项目的预测评分。
3.3 综合预测评分
接收以上得出的两个预测评分,动态确定两个评分的权值分配,此处引入近邻群和信任子群:
S(Ua)={Ux|Sim′(Ua,Ux)>μ,a≠x}
(6)
S(Ij)={Ix|Sim′(Ij,Iy)>ν,j≠y}
(7)
近邻群大小|S(Ua)|=m;|S(Ij)|=n。
S′(Ua)={Ux|Sim′(Ua,Ux)>μ&|IUa∩IUx|>ε,a≠x}
(8)
S′(Ij)={Iy|Sim′(Ij,Iy)>ν&|UIj∩UIy|>δ,j≠y}
(9)
信任子群大小|S′(Ua)|=m′;|S′(Ij)|=n′;其中μ,v,ε,δ为阈值。
如果(m′+n′)>0,则
如果(m+n)>0,则
其他,a=1-a=0.5
其中φ为调和参数。
根据公式(10)计算目标用户对未评分项目的综合预测评分,然后通过对评分排列,将最终的结果推荐给目标用户。
Pay=(1-a)*P1ay+a*P2ay
(10)
式中,a为评分的权值;P1ay为基于项目相似度的目标用户对未评分项目的预测评分;P2ay为基于云模型用户相似度的目标用户对未评分项目的预测评分。
4 实验及分析
4.1 实验环境与数据度量标准
用7台普通的PC搭建Hadoop组成集群,命名为master、slave1~slave6。以Grouplens网站下载的数据MovieLens 100 K、MovieLens 1 M、MovieLens 10 M为例,如表2所示。

表2 数据集描述
对数据MovieLens 100 K的评分矩阵进行随机划分,训练集与测试集比例为4∶1。进行5次随机划分,得到5组数据dataset1~dataset5。采用平均绝对偏差(MAE)作为推荐的度量标准[14],MAE的大小与推荐质量成反比关系。假设预测的评分集为{P1,P2…Pn},对应的实际评分集{r1,r2…rn}。
(11)
采用加速比表示处理海量数据时集群节点数对性能方面的影响。加速比定义:K=T1/Tn。
T1表示单节点运行耗费的时长,Tn表示n个节点运行耗费的时长。
4.2 集群与单机实验及对比
将节点数量分别启动1~7台TaskTracker节点,构成不同规模的分布式集群,测试该算法在Hadoop平台下时效性方面是否显著提升。实验主要分析两个方面:(1)算法在海量数据时集群的节点数对性能的影响;(2)同一数据集下,算法在单机环境与集群环境的时效对比。加速比实验图如图2所示。

图2 加速比实验图
从图2可看出,当集群节点数从1加到5时,加速比几乎呈线性增长,节点5以后增速下降。说明节点增加确实能提高推荐算法效率,但是理论上增加一个节点提升1倍效率,在实际上很难达到。
单机与Hadoop集群性能对比如表3所示。从表3可看出:(1)数据集的递增,单机环境下CPU和内存消耗迅速,无法满足计算所需资源导致性能降低;(2)数据集较小时,单机用时比集群少,效率比集群高,主要由于Hadoop集群创建、启动作业都要耗时,各节点通信也需要耗时,实际计算用时占比很小;(3)随数据集增大,集群在时效方面比单机有明显提升,运行速度明显加快,并且数据集太大单机会出现溢出现象,集群仍然能高效的计算。
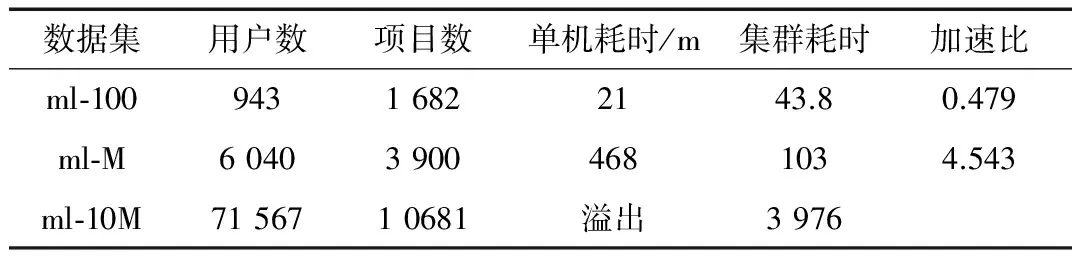
表3 单机与Hadoop集群性能对比
4.3 与其他推荐算法的对比实验
下面主要对基于双维度云模型的协同过滤推荐算法(DCCF)、基于用户的协同过滤推荐算法(UBCF)、基于项目的协同过滤推荐算法(IBCF)和不确定近邻的协调过滤推荐算法(UNCF)[10]四种算法进行实验比较,得到各个阶段的数据。选取数据MovieLens 100 K的评分矩阵,分别用100、500、900个用户进行实验。
图3、图4和图5为不同用户数时的MAE值,对比可见,DCCF算法取得了最低的MAE值,明显提高了推荐准确度,通过云模型数据稀疏问题也得到了合理解决。且用户数越多,该方法的优势越明显,推荐质量越高;同时邻居集越大,从而使推荐质量增加。

图3 各种协同过滤推荐算法与DCCF算法的比较(100个用户)

图4 各种协同过滤推荐算法与DCCF算法的比较(400个用户)

图5 各种协同过滤推荐算法与DCCF算法的比较(900个用户)
5 结论
针对越来越庞大的网络资源和以往推荐算法存在的不足,本文提出了一种基于双维度云模型的协同过滤推荐算法(DCCF)。该算法充分利用了Hadoop集群的优势,有效结合了云模型,并且通过动态确定权重,使得目标用户对目标项目的预测评分更加精确。实验数据表明,该算法能适应大数据环境,并由于利用了云模型和两个维度数据,数据稀疏性问题得到了合理的解决,推荐质量也上升了一个档次。而随着时间的变化,人们的兴趣也会发生改变,如何来衡量变化对推荐质量的影响,是下阶段的研究重点。
[1] BOBADILLA J,ORTEGA F, HERNANDO A,et al. A collaborative filtering approach to mitigate the new user cold start problem[J]. Knowledge-Based Systems,2012,26:225-238.
[2] 张光卫,李德毅,李鹏,等.基于云模型的协同过滤推荐算法[J]. 软件学报,2007,18(10):2403-2411.
[3] BA Q,LI X,BAI Z. Clustering collaborative filtering recommendation system based on SVD algorithm[C]// IEEE International Conference on Software Engineering and Service Science. IEEE,2013:963-967.
[4] HEMANDO A, BOBADILLA J, ORTEGA F.A non negative matrix factorization for collaborative filtering recommender systems based on a Bayesian probabilistic model[J]. Knowledge-Based Systems, 2016, 97(C): 188-202.
[5] ZHANG J,LIN Y,LIN M,et al. An effective collaborative filtering algorithm based on user preference clustering[J]. Applied Intelligence,2016,45(2):230-240.
[6] 范波,程久军. 用户间多相似度协调过滤推荐算法[J]. 计算机科学,2012,39(1):23-26.
[7] 荣辉桂,火生旭,胡春华,等. 基于用户相似度的协同过滤推荐算法[J]. 通信学报,2014,35(2):16-24.
[8] Li Chenyang, He Kejing. CBMR: an optimized MapReduce for item-based collaborative filtering recommendation algorithm with empirical analysis[J]. Concurrency and Computation: Practice and Experience,2017.
[9] 黄创光,印鉴,汪静, 等.不确定近邻的协调过滤推荐算法[J].计算机学报,2010,33(8):1369-1377.
[10] YAZDANFAR N, THOMO A. Link Recommender: collaborative-filtering for recommending URLs to twitter users[J].Procedia Computer Science,2013,19:412-419.
[11] PARK Y, PARK S,JUNG W, et al. Reversed CF: a fast collaborative filtering algorithm using a k -nearest neighbor graph[J]. Expert Systems with Applications,2015,42(8):4022-4028.
[12] 文俊浩,舒珊. 一种改进相似性度量的协同过滤推荐算法[J]. 计算机科学,2014, 41(5):68-71.
[13] KUMAR N P,FAN Z.Hybrid user-Item based collaborative filtering[J].Procedia Computer Science,2015, 60(1):1453-1461.
[14] DAS J, AMAN A K, GUPTA P, et al. Scalable hierarchical collaborative filtering using BSP trees[C]// International Conference on Computational Advancement in Communication Circuits and Systems, 2015:269-278.
