基于机器学习的舆情倾向性分析研究
2018-01-29罗裕隽
罗裕隽
(同济大学 电子与信息工程学院,上海 201804)
0 引言
随着信息化的普及,互联网逐渐取代传统媒体成为信息传播的主流媒介,各大门户网站、微博和主流新闻机构都力争在第一时间发布各类新闻信息,最大限度地达到新闻传播效果,互联网上每天都有数以万计的新闻舆论出现。舆情倾向性分析在网络舆情监控中起着十分重要的作用,对于企业而言,能帮助其了解自身的经营状况和存在的问题,依据当前形势制定相应的市场战略;对于监管部门而言,能够帮助其对所辖企业进行及时的服务和监管。但现有的门户网站或搜索引擎一般不会对发布或检索到的信息提供正负面分类功能,而人工筛选的方式因为效率低、工作量大,很难满足业界的需求。因此,如何从数量庞大的新闻中快速且准确地获取倾向性信息是一个亟待解决的问题。
传统的中文舆情倾向性分析主要是基于规则和统计的方法,如肖红等人[1]提出的基于句法分析和情感词典的方法,这类方法具有一定准确率,但模型的泛化能力较弱,对于规则未覆盖到的文本信息不能准确识别,且该方法依赖语法规则和词典,需要大量专业人员对语言本身进行处理和分析,因此难以推广使用。
运用机器学习方法进行舆情倾向性分析是目前比较主流的研究方向。Pang Bo等人[2]对比了最大熵模型、贝叶斯分类器、支持向量机以及不同的特征选择方法,在IMDB影评数据集上进行测试,其实验证明基于bi-gram的特征选择并使用支持向量机模型得到的情感分析结果最好。刘志明等人[3]对比了三种机器学习算法,验证了方法在微博评论的适用性。
综合分析现有的研究成果,在中文舆情倾向性分析研究领域,仅使用基于统计的特征抽取以及基于语法规则和句法树的分类方法远不能达到理想的效果,而基于机器学习的分析方法研究还较为匮乏,因此本文提出运用词嵌入方法对词语特征进行抽取,并采用平均池化的方法构建文本特征,再将抽取的文本特征输入机器学习分类模型中进行预训练。本文综合比较了三种主流机器学习分类算法,实验结果表明,基于集成学习迭代决策树算法对舆情倾向性分析的效果最好。
1 特征抽取
机器学习算法一般不能直接处理原始文本,使用固定长度的数值特征向量表达文本是一种常见的特征抽取方式。词汇的数量往往十分庞大,如果不加选择地将所有词都用做特征,可能会造成维度灾难和特征稀疏的问题,导致分类模型的效果不佳。因此特征抽取是机器学习中非常重要的环节。
1.1 词语特征抽取
传统的词语独热表示(One-hot Representation)仅仅将词符号化,不包含任何语义信息。词嵌入(Word Embedding)是一种基于神经网络的词分布式表示,将词转化为固定长度向量的方法,通常这个长度都远小于词典的大小,在几十维到几百维之间。词分布式表示的核心是上下文的表示以及上下文与目标词之间的关系建模,因此词向量包含丰富的语义信息,在词性标注、命名实体识别等自然语言处理任务中都有出色的表现。
Word2vec[4-5]是2013年Google发布的一种基于深度学习的词向量训练工具。如图1所示,word2vec主要用到Continuous Skip-gram Model(Skip-gram)和Continuous Bag-of-Words Models(CBOW)两种简化的神经网络模型。两种模型都是由输入层、投影层和输出层组成的三层网络结构。Skip-gram模型是根据当前词w(t)预测其上下文Context(w(t)),而CBOW模型是在w(t)的上下文已知的情况下预测当前词。
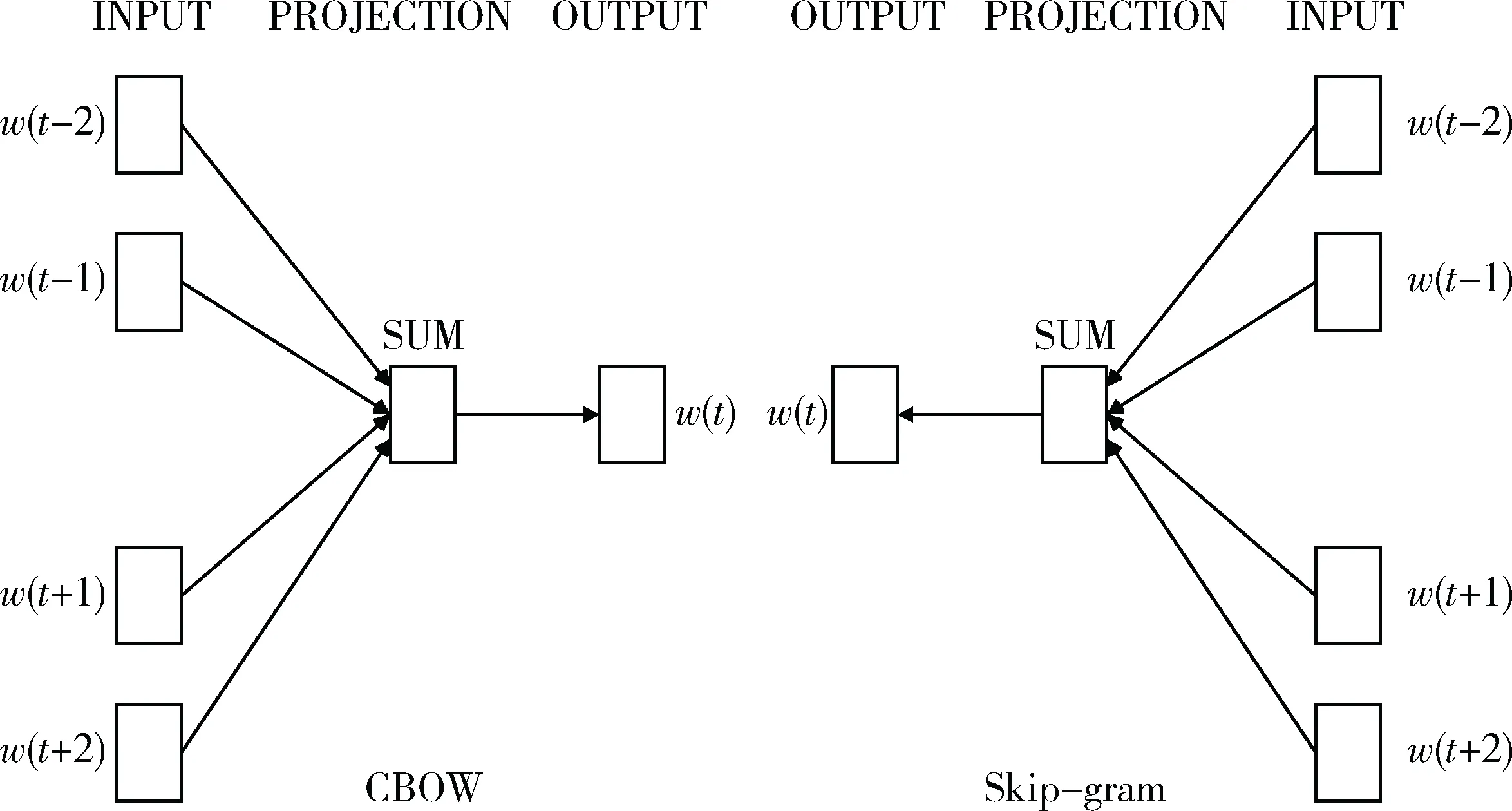
图1 word2vec中神经网络模型
1.2 文本特征构建
由于文本长度的不一致,机器学习模型不能直接处理词特征。池化(Pooling)方法能整合特征,保证输出文本特征维度的统一,同时能较好保留词向量中每个维度特征的信息。经过词向量平均池化后,c维文本特征Docc可表示为
(1)
其中,N为文本所包含的词语数目,wci为第i个词的c维词向量。
2 分类方法
支持向量机(Support Vector Machine, SVM)、决策树(Decision Tree, DT)和迭代决策树(Gradient Boosting Decision Tree, GBDT)在文本分类任务上都有良好的表现,本节对这三种方法进行简要介绍。
2.1 支持向量机
在线性可分的样本空间中,划分超平面可通过如下线性方程来描述:
wTx+b=0
(2)
其中w=(w1;w2;…;wd)为法向量,决定了超平面的方向;b为位移项,决定了超平面与原点之间的距离。样本空间中任意点x到超平面(w,b)的距离可写为:
(3)
假设超平面(w,b)能将训练样本正确分类,即对于(xi,yi)∈D,若yi=+1,则有wTx+b>0;若yi=-1,则有wTx+b<0。即:
(4)
其中,与超平面距离最近的几个训练样本使公式(4)等号成立,这些训练样本被称为“支持向量”。SVM要找到具有“最大间隔”的划分超平面,因此其目标函数为:
s.t.yi(wTxi+b)≥1,i=1,2,…,m
(5)
若原始样本空间不存在一个划分超平面,即训练样本并非线性可分的,对于这样的问题,SVM通常引入核函数(Kernel Function)来解决。核函数与样本特征的关系如下:
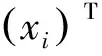
(6)
2.2 决策树
决策树是一个树结构,其中叶节点对应决策结果,非叶节点则对应一个特征属性的测试,每个分支代表特征属性在某个值域上的输出。根节点包含样本全集,每个节点包含的样本集合根据属性测试的结果被划分到子节点中。决策树生成的基本流程是一个递归的过程,在生成过程中,希望决策树的分支节点所包含的样本尽可能属于同一类别,即节点的“纯度”越来越高。“纯度”通常由信息熵来表示,若D为当前样本集合,pk(k=1,2,…,|y|)为第k类样本所占的比例,则D的信息熵的定义为:
(7)
Ent(D)的值越小,则D的纯度越高。
如何选择最优划分属性是决策树生成过程中一个关键问题。ID3决策树学习算法采用信息增益来进行决策树的划分属性选择。对于属性a对样本集D进行划分所获得的信息增益为:
(8)
而另一种常见的决策树学习算法C4.5则基于信息增益率来做划分属性选择。增益率的定义为:
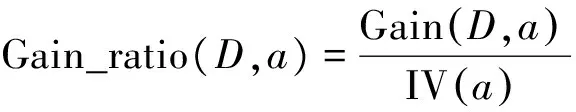
(9)
其中
(10)
2.3 迭代决策树
决策树具有模型简单、训练速度快的优点,但单棵决策树在模型训练过程中容易出现过拟合的现象,为了弥补这一缺陷,通常采用集成学习的方法。集成学习的核心思想是通过组合多个学习器,最终得到的模型比单一学习器具有显著优越的泛化性能。集成学习的示意图如图2所示。

图2 集成学习示意图
GBDT是一个基于迭代累加的决策树集成算法,它通过构造一组回归决策树,并把多棵数的结果通过Gradient Boosting的方法累加起来作为最终的预测输出。Gradient Boosting每一次训练需要在残差减少的梯度方向上训练一个新的模型,因此,通过多次训练,模型的残差不断降低。
3 实验分析
本文实验部分采用三个数据集,分别是企业新闻数据集、第三届中文倾向性分析评测(COAE2011)数据集和商品购买评论数据集。其中企业新闻数据集包含若干家大型企业相关的互联网新闻约1 889条篇章级文本,COAE2011抽取财经相关的约1 400条句子级文本,购物评论集包含电商网站用户对商品的评价约20 000条句子级文本。数据集的具体分布情况如表1所示 。
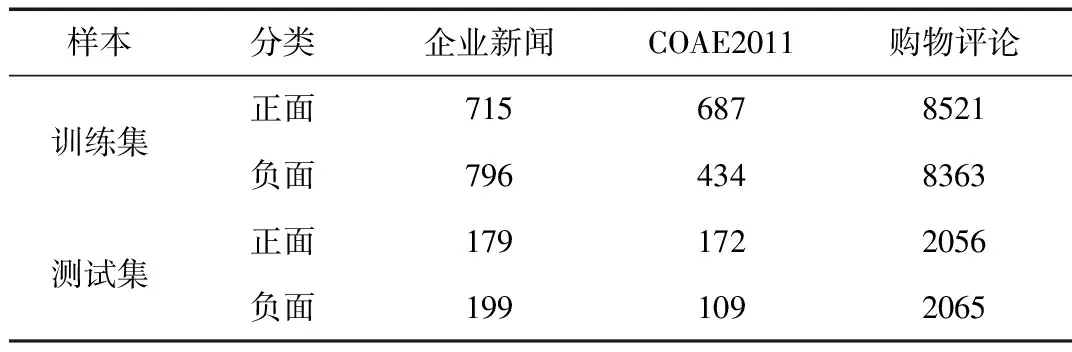
表1 实验数据集
实验首先对样本数据进行预处理,包括分词和去除停用词等,再根据第1节介绍的特征抽取方法构建样本特征,其中word2vec选用CBOW模型进行词向量的训练。实验先后使用SVM、DT和GBDT三种算法在三个数据集上分别进行模型的训练和评估,其中算法的实现采用Python的sklearn模块。主要参数为,SVM采用径向积核函数,DT采用Gini系数来做特征划分,GBDT的深度为10,并采用0.05的学习率。最终数据集的平均准确率如表2所示。
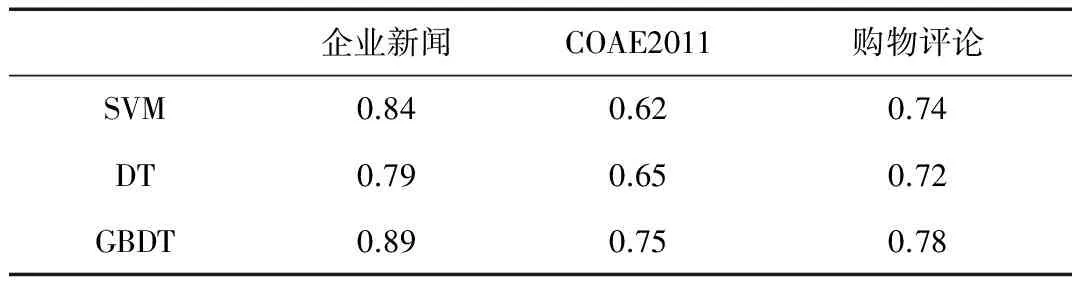
表2 倾向性分析结果
从结果来看,在三个数据集上,GBDT算法的准确率都高于其他两个方法。
4 结论
通过实验证明机器学习方法对处理中文舆情倾向性分析问题是有效的,其中又以基于集成学习的迭代决策树算法效果最佳。其原因是集成学习算法能够综合多个学习器的结果来决定最终分类,并在一定程度上避免单个学习器在训练过程中的过拟合问题。另外,在不同领域,不同篇章长度的数据集上机器学习算法都有比较好的表现,证明其具有较好的泛化能力。
[1] 肖红, 许少华. 基于句法分析和情感词典的网络舆情倾向性分析研究[J]. 小型微型计算机系统, 2014, 35(4): 811-813.
[2] Pang Bo, LEE L, VAITHYANATHAN S. Thumbs up? Sentiment classification using machine learning techniques[C].Proceedings of the ACL-02 Conference on Empirical Methods in Natural Language Processing-Volume 10. Association for Computational Linguistics, 2002: 79-86.
[3] 刘鲁, 刘志明. 基于机器学习的中文微博情感分类实证研究[J]. 计算机工程与应用, 2012,48(1): 1-4.
[4] MIKOLOV T, SUTSKEVER I, Chen Kai, et al. Distributed representations of words and phrases and their compositionality[C].Advances in Neural Information Processing Systems, 2013,26: 3111-3119.
[5] MIKOLOV T, Chen Kai, CORRADO G, et al. Efficient estimation of word representations in vector space[J]. Compater Science, 2013.
