基于MR的高可靠分布式数据流统计模型
2018-01-23朱蔚林木伟民金宗泽王伟平
朱蔚林,木伟民,金宗泽,王伟平
(1.中国科学院 信息工程研究所,北京 100093;2.中国科学院大学,北京 100049)
0 引 言
数据的价值随着时间推移会慢慢降低,在社会生活中,特别是商业场景中这一现象更加显著。流处理系统的出现让用户能够快速地从庞杂的数据流中提炼出数据蕴含的价值。由于数据流的持续产生且体积庞大,给系统的存储能力带来了巨大挑战。由此导致数据流统计具有one-pass访问、有限内存和实时等特点,也为统计带来了极大的挑战。
现如今,大数据时代涌现了如S4[1-2]、Storm[3]、Spark Streaming[4]等一系列数据流处理平台[5-6],这些平台由于面向的应用场景不同而各有特点。S4由Yahoo在2010年提出,S4为了保证良好的可扩展性,采用去中心化结构,但是S4消息路由仅支持按照Key值进行分布,而且没有提供消息处理的反馈机制,使得容错成为了很大的问题。Storm面向纯流式处理,以低延迟为核心设计目标,将数据流处理任务抽象为有向无环图,称作Topology,同时在at-least-once语义的基础上实现了exactly-once语义,但是其弱中心化的结构也没有彻底解决单点的问题。Spark Streaming构建在Spark的基础上,沿用了Spark中创新性的存储结构RDD(弹性分布式数据集),将数据流切分为一个个RDD,增大了处理粒度以提高吞吐量,但是也因此增加了延迟。
在数据流上有一种普遍的应用场景是在数据流上进行数据统计[7],例如对于电信网络、社交网络数据流等等。在这些数据流上的实时统计无论对于舆情控制,还是提供更高质量的服务都有重要意义。然而上述平台并不能完美契合此类应用场景。
数据流统计场景下一个很典型的处理是分组统计。以社交网络数据流为例,假设数据流S中每个元组包含uid,topic,time三个字段,uid唯一标识一个用户个体,topic为用户参与的话题,time为该条信息产生的时间分片,现在需要统计各个时间分片的热点话题。如果将数据流类比为传统的关系数据库,会提交以下SQL语句:
SELECT topic, time, count(1)
FROM S GROUP BY topic, time
而对于数据流而言,数据流具有快速流动、易失的特性,绝不可能像数据库一样在一个时刻看到整个数据流的全部数据,而且热点话题具有很强的时效性,统计结果延迟要尽量做到最小。同时,电信网络、社交网络由于用户众多,数据量往往很大,因此对流统计平台的性能要求很高,如流统计的吞吐率和延迟等。
面对这样的应用场景,系统主要的需求在于高吞吐率和低延迟。目前流行的通用分布式流处理平台如Spark Streaming和Storm等,系统结构较复杂,在这种高吞吐量的实时连续统计场景上性能有所局限。对此,面向基于窗口的连续查询需求,提出了一个高吞吐、低延迟的分布式数据流统计模型Mars,同时提供了强大的容错性。
1 关键技术
数据流可以理解为一个不断增长的数据集合[8-9],将其定义如下:
定义1:设t表示任意时间戳,t时刻到来的数据集为dt,称{…dt-1,dt,dt+1}为数据d的数据流。
数据流具有实时性、易失性、突发性、无序性、无限性等特征。在数据流上的统计查询处理由于这些特征,划分为不同的模型。
1.1 数据流统计时序模型
按照统计的时序范围来划分,数据流上的统计处理分为界标模型[10]、滑动窗口模型[11]以及跳动窗口模型[12]。
1.1.1 界标模型
设当前时间戳为t,s为一个指定的在t之前的时间戳,称作界标,界标模型统计的是从界标时间戳s开始一直到当前时间戳t范围内数据流{ds…dt}上的统计结果。
1.1.2 滑动窗口模型
设当前时间戳为t,滑动窗口模型统计的是当前时间戳之前一定时间范围内的数据流,设滑动窗口大小为n,即时间范围为n,滑动窗口模型所处理的数据流为{dt-n…dt}。
除了上述基于时间戳的滑动窗口模型,另外还有基于元组数量的滑动窗口,即在内存中保存一定数量的元组。
1.1.3 跳动窗口模型
跳动窗口是滑动窗口的一个延伸。在滑动窗口模型中,窗口以一定时间范围或者元组数量为单位向前滑动,两次连续的处理的数据集有重叠,而跳动窗口模型相邻两次处理数据集无重叠,这一次处理时间范围的起点是上一次处理时间范围的终点(以基于时间的窗口为例)。因此,每个跳动窗口的处理结果之间无交集,同时它们的并集就是整个数据集上全量的处理结果。
1.2 数据流统计查询类型
根据统计查询提交形式的不同,查询类型分为Ad-hoc查询[13]和连续查询[14]。
1.2.1 Ad-hoc查询
Ad-hoc查询也称即席查询,Ad-hoc查询请求可以在统计系统运行时的任一时刻提交,统计系统接收到查询请求后立即处理该查询并在产生结果后立即返回查询结果。目前处理Ad-hoc查询的数据流处理平台较少。
1.2.2 连续查询
连续查询请求在查询统计系统启动时或某一特定时间戳提交,在这一时间戳之后,直到用户主动取消查询请求,系统一直处理该查询,每隔一定时间间隔输出查询结果。Mars面向的查询类型即是连续查询。
1.3 数据流统计语义模型
对数据流做统计处理时,最小的单位是元组。理想状态下,数据流中的每一个元组都应该被处理一次,且仅仅处理一次。但是在系统层面,由于分布式系统本身的复杂性和不确定性,以及在某些应用场景下对系统需求的不同,往往会对精度做一定程度上的牺牲。根据对每一元组处理次数的保证,统计模型的语义分为三种。
1.3.1 至多一次(at most once)
至多一次语义是最松的约束,该语义模型尽力使得每一元组被处理到,但不保证对任意元组处理的必然性。由于约束宽松,实现这样的模型系统开销往往是最小的,由于这样的特性,该语义适合对吞吐量要求较高、但不要求统计精确度的应用场景。
1.3.2 至少一次(at least once)
至少一次语义保证数据流中每一元组都至少被处理一次,但是在一些特殊情况发生时,有可能会造成重复处理某些元组。在这样的语义约束下,统计模型实现时需要设计严格的容错机制,确保在任何可控故障发生时,每个元组都会被处理,但是容错性会带来不菲的系统开销。
1.3.3 精确一次(exactly once)
精确一次语义是理想状态下的语义,也是最严格的语义约束。这一语义一般是在至少一次语义的模型基础上,对统计结果进行去重而得到的。因此,系统实现时,精确一次语义比至少一次语义又多了一重开销,只有在精确度要求极其苛刻的应用场景下会使用这一语义约束,例如银行系统或证券系统。
2 Mars设计与实现
2.1 系统架构
Mars的系统架构如图1所示。

图1 Mars系统架构
由图1可见,Mars依赖的外部组件有四个:分布式消息中间件提供消息服务,Mars的输入和输出都通过分布式消息中间件完成,统计任务数据库储存用户的统计需求,分布式协调系统提供对分布式集群运行时的状态管理等等,分布式缓存负责异步解耦和临时缓存中间数据。
Mapper集群、Reducer集群是Mars的核心组件。Mapper集群从消息中间件拉取消息并处理,将中间结果顺序缓存在分布式缓存中;Reducer集群从分布式缓存中顺序读取分布式缓存中的中间数据,处理后将最终的统计结果再发送回消息队列。
Mapper和Reducer的灵感来自于MapReduce编程模型,尽管MapReduce编程模型是为了批处理场景而提出的,但是它将大规模数据处理过程抽象为Map和Reduce两个阶段,对于数据流统计问题同样具有重要的指导意义。Mars将MapReduce模型扩展到了集群概念上,每一个Mapper或者Reducer计算单元都是分布式集群中的一个节点,分别称作Mapper或Reducer。所有的Mapper节点组成Mapper集群,所有的Reducer节点组成Reducer集群。
Mapper集群采用去中心化结构,集群内各个节点是对等关系,使用去中心化结构的核心目标是将计算粒度切分,在进行较大窗口下的统计时,如果使用集中式结构,缓存窗口内的全部数据将造成极大的内存开销和时间开销。而Mars将这样的大窗口切分为小窗口分布到集群上并行处理,有效解决了该问题。同时这一设计保证了Mapper集群良好的可扩展性,使得Mars的计算能力随着集群规模的扩大可以得到近似于线性的增加。
Reducer集群的统计功能是将经过Mapper切分的细粒度统计结果合并为任务需求窗口大小的结果,因此Reducer集群采用主从架构。集群启动时,各个节点首先借助分布式协调系统选举出一个领导者,该领导者负责给各个节点分配任务,并监听节点状态,当集群规模发生改变时重新分配任务。同时,各个从节点也监听主节点的状态,当主节点发生故障时重新选举领导者。
2.2 数据传输协议
Mapper和Reducer通过分布式缓存传递数据[15]的协议设计是Mars的一个关键点。Mars使用了一种特殊的序号机制保证Mapper和Reducer协作步进,同时保证两个阶段异步运行。
初始状态时,首先针对每个处理任务在分布式缓存中为Mapper集群和Reducer集群初始化一个序号,称为SEQ。当Mapper节点处理完输入的原始数据集后,将缓存中的SEQ自增1,使用自增操作的主要目的是使得多节点并行处理统一统计任务时不会得到统一SEQ,造成数据覆盖。
而Reducer集群出于容错性考虑,使用了延迟更新SEQ的策略。
2.3 容错设计
容错是所有分布式流处理系统应当关注的问题,虽然集群中每个节点发生故障的概率很小,但是一旦发生,由于数据流不断流动的特点,丢失的数据便很难找回。大多数现有的故障恢复策略都是通过冗余备份策略实现的[16],Mars所采用的策略也类似。
在Mapper端,每一个节点拉取数据后都首先将数据存一份本地文件,同时将文件名与需要该数据的统计任务id列表的对应关系注册到分布式缓存中,每当某一任务处理完该数据时,从列表中删去该任务id,直到列表为空时删除本地文件,最后向分布式消息中间件反馈ack消息。假如在ack之前该节点发生了宕机,由于消息中间件未接收到ack消息,当发生超时后,消息中间件会向其他节点重发该消息。这一机制保证了每一条元组都会被处理至少一次。
在Reducer端,采用延迟更新SEQ的方式来保证容错性。以一个统计任务的处理过程为例,如图2所示。Reducer集群有两个节点,R1正在处理数据,初始R1从缓存中得到序号1,于是从缓存中得到序号为1的数据集并处理,处理完成后在内存中序号加1变为2,并不更新到缓存中。接着在缓存中读取序号为2的数据集,假如在处理过程中,归并后的统计结果尚未输出之前R1节点发生宕机,经过新一轮的领导者选举以及任务分配,该任务迁移到R2节点。这时R2节点从缓存中获取到的序号依然为1,不会造成数据丢失。
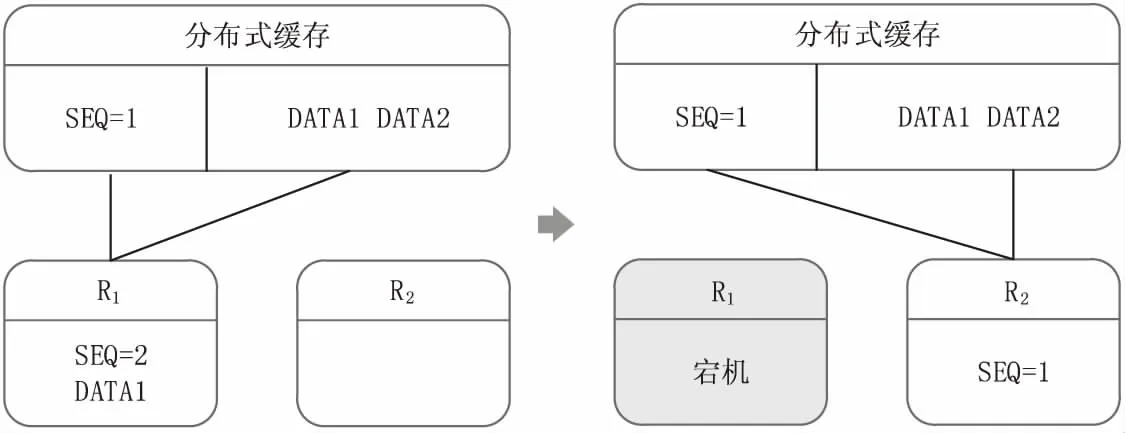
图2 Reducer容错机制示意图
综上,Mars强大的容错机制保证了Mars的at-least-once语义。
3 性能评估与分析
使用Java语言实现了Mars,并在典型的分组统计使用场景下对Mars进行了测试,同时与Storm和Spark Streaming进行对比。
3.1 实验环境
实验采用由30台服务器组成的集群。其中,消息中间件拥有3个服务节点和30个数据节点,分布式缓存为15节点的主备集群,分布式协调服务拥有7个服务节点。
3.2 数据流
实验的数据源选用了模拟的网络数据流S,数据流的每个元组包含20个字段,其中关键字段有timestamp、type、sip、dip、port、location等。
每个字段的内容根据一个已知的集合中以均匀概率随机生成,生成后每个元组的平均大小为150字节。共生成元组10亿条,整个数据集大小140 G。在每个单元实验前,提前将数据集加载到分布式消息中间件中。
3.3 统计需求
在上述数据流上,构建了如下的统计场景:
SELECT sip, type, timestamp, count(*)
FROM S
GROUP BY sip, type, timestamp
WINDOWING 60 s
其中,WINDOWING关键字表示以60 s大小的跳动窗口进行统计。需要特别说明的是,对时间戳进行分组统计是为了使统计结果具有应用价值,Mapper会对时间戳以窗口大小,即60 s为单位进行归一化。
3.4 性能实验
性能一般以吞吐量为表征,吞吐量计算公式如下:
T=tps×bs×ts
其中,T表示吞吐量;tps表示消息中间件每秒处理的事务数,实验中Mapper集群作为消息中间件的消费者,tps相当于每秒消费的数据集个数;bs表示每个数据集包含的元组数;ts表示每个元组的大小(平均)。
分别在不同的数据集大小和不同的集群规模下对上述统计需求进行实验,结果如下所述。
3.4.1 集群规模固定,数据集大小不同
实验在20个节点的集群上完成,吞吐量取统计过程中整个集群吞吐量的平均值。由图3可见,随着每个数据集所包含的元组数量的增长,一开始吞吐量上升很快,当数据及大小达到5 000时,吞吐量达到峰值,随着数据及大小继续增加,吞吐量呈缓慢下降的趋势。不难分析出,当数据集大小为1这种极端情况时,每次网络开销只传输一个元组,效率极低;当数据集大小增大到5 000个元组时,网络开销和解包开销达到一个平衡点,故性能达到最优;当数据集大小继续增大时,虽然每次网络开销得到的数量足够大,但是反序列化数据流会占用大量的CPU资源,导致用于统计的系统资源减少,从而吞吐量下降。
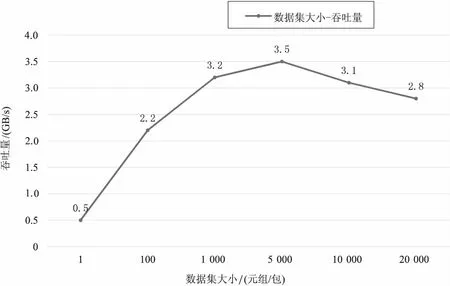
图3 不同数据集大小时的吞吐量变化曲线
3.4.2 数据集大小固定,集群规模变化
在上述实验得出的最优数据集大小下,吞吐量取统计过程中整个集群吞吐量的平均值。由图4可见,吞吐量随着集群规模的逐步增大,几乎呈线性增长,当集群规模增大到20个节点时,性能达到最优,此时整个集群吞吐量达到3.5 GB/s,可以计算得单节点吞吐量为179 MB/s。
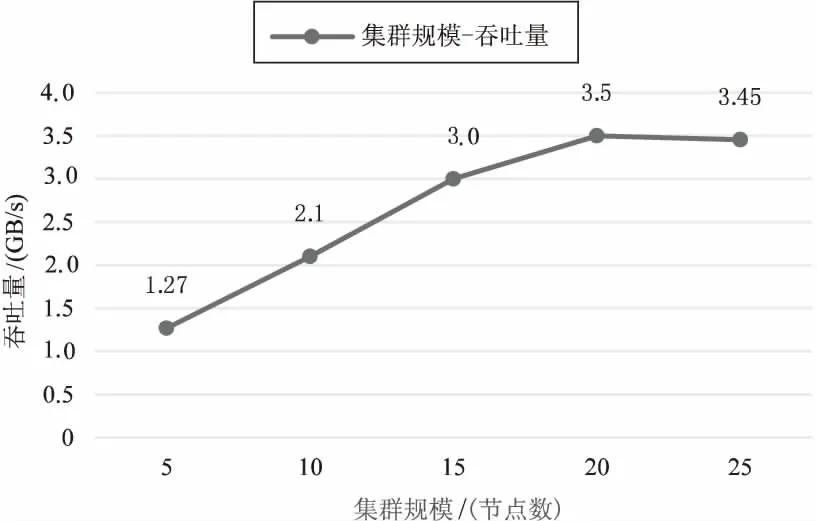
图4 不同集群规模时的吞吐量变化曲线
当集群规模继续扩大时,吞吐量并未继续增加,这是由于从分布式消息中间件消费数据时是读盘操作。
测试数据中使用的数据是提前发送并缓存在消息队列上的。系统从消息队列中消费数据时,消息队列会从磁盘上读取数据。由于消息队列特性,每个消息队列节点只会从一块磁盘上读取数据。一共有35个消息队列节点,磁盘读取速度上限大约是100 Mbps,因此整个消息队列所能提供的最大消费速率约为3.5 G。当集群规模大于20时,由于消息队列磁盘读取速度已达上限,速度无法继续增加。
3.5 对比实验
同时,将上述的统计需求分别使用Spark Streaming和Storm的编程接口进行了实现,二者同样使用Mars的分布式消息中间件作为输入和输出。
3.5.1 性能对比
由于Spark Streaming和Storm本身已经对数据集进行了抽象,故无需在不同数据集大小的情况下进行对比。在不同的集群规模下,实验结果如图5所示。

图5 Mars,Spark Streaming,Storm性能对比曲线
由图5可见,与Storm和Spark Streaming相比,Mars在分组统计需求下具有较明显的性能优势。在集群规模为20时,Mars的吞吐量是Spark Streaming的1.46倍,是Storm的2.82倍。
3.5.2 实时性对比
实时性方面,实验计算了部分处理日志中记录的每个元组的平均延迟。Storm专门为了流处理场景设计,平均延迟最小,为653 ms;Spark Streaming由于需要“攒”数据,平均延迟达到了2 383 ms;Mars介于两者之间,平均延迟为1 372 ms。
3.5.3 语义准确性对比
由于统计需求是在连续跳动窗口上的分组统计,没有过滤对数据量产生变化的计算,因此如果统计过程保证了exactly-once语义,那么统计结果中分组统计量的和应与原始记录数量保持一致。
该实验使用上述实验数据中一个4 000万数据量的子集完成,实验集群在实验过程中分别将其中三个节点断网以模拟故障,实验结果如表1所示。
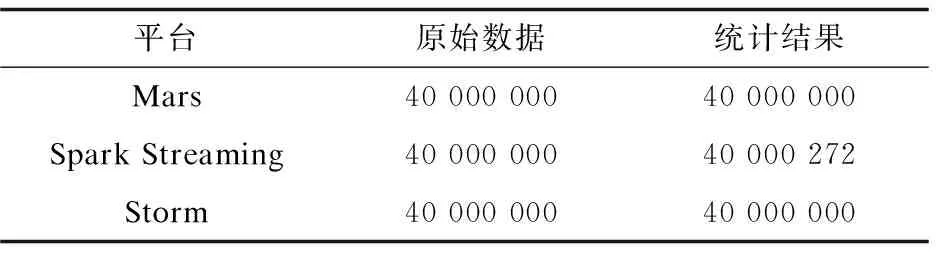
表1 Mars Spark Streaming,Storm语义准确性对比
由表1可见,Mars虽然仅实现了at-least-once语义,但由于其良好的容错性,在发生节点故障时并没有造成数据丢失或重复,实现了与Storm相同级别的语义限制。
4 结束语
提出了一个面向基于窗口的连续查询需求的分布式数据流统计模型。该模型在保证at-least-once语义的前提下,实现了优异的性能,尤其在基于窗口的分组统计这一统计场景下,相比目前流行的分布式数据流处理平台具有较明显的优势。同时,Mars具有良好的可扩展性,使其在面对不同规模的数据场景时有良好的适应性。
与此同时,由于该统计模型是面向大规模实时流统计场景的,因此对于需要进行迭代计算、复杂计算的流处理场景支持并不完善。该模型的下一步发展和完善应当是面对更多流处理场景,进行通用化拓展。
[1] CHAUHAN J, CHOWDHURY S A, MAKAROFF D. Performance evaluation of Yahoo! S4:a first look[C]//Seventh international conference on P2P,parallel,grid,cloud and internet computing.[s.l.]:IEEE,2012:58-65.
[2] NEUMEYER L,ROBBINS B,NAIR A,et al.S4:distributed stream computing platform[C]//Proceedings of the 10th IEEE international conference on data mining workshops.Sydney:IEEE Press,2010:170-177.
[3] SIMONCELLI D,DUSI M,GRINGOLI F,et al.Scaling out the performance of service monitoring applications with BlockMon[C]//Proceedings of the 14th international conference on passive and active measurement.Hong Kong:IEEE Press,2013:253-255.
[4] ZAHARIA M,DAS T,LI H,et al.Discretized streams:an efficient and fault-tolerant model for stream processing on large clusters[C]//USENIX conference on hot topics in cloud computing.[s.l.]:USENIX,2012.
[5] 张 鹏,李鹏霄,任 彦,等.面向大数据的分布式流处理技术综述[J].计算机研究与发展,2014,51:1-9.
[6] 崔星灿,禹晓辉,刘 洋,等.分布式流处理技术综述[J].计算机研究与发展,2015,52(2):318-332.
[7] GÜNDÜZ S,ÖZSU M T.A web page prediction model based on click-stream tree representation of user behavior[C]//Proceedings of the ninth ACM SIGKDD international conference on knowledge discovery and data mining.[s.l.]:ACM,2003:535-540.
[8] BABCOCK B,BABU S,DATAR M,et al.Models and issues in data stream systems[C]//Proceedings of the twenty-first ACM SIGMOD-SIGACT-SIGART symposium on principles of database systems.[s.l.]:ACM,2002:1-16.
[9] 孙大为,张广艳,郑纬民.大数据流式计算:关键技术及系统实例[J].软件学报,2014,25(4):839-862.
[10] PERNG C S,WANG H,ZHANG S R,et al.Landmarks:a new model for similarity-based pattern querying in time series databases[C]//16th international conference on data engineering.[s.l.]:IEEE,2000:33-42.
[11] BABCOCK B,DATAR M,MOTWANI R.Sampling from a moving window over streaming data[C]//Proceedings of the thirteenth annual ACM-SIAM symposium on discrete algorithms.[s.l.]:[s.n.],2002:633-634.
[12] ZHU Y,SHASHA D.Statstream:statistical monitoring of thousands of data streams in real time[C]//Proceedings of the 28th international conference on very large data bases.[s.l.]:[s.n.],2002:358-369.
[13] 熊全洪,魏 娟,刘 武.即席查询研究[J].现代商贸工业,2008,20(12):345-346.
[14] CHANDRASEKARAN S,FRANKLIN M J.Streaming queries over streaming data[C]//Proceedings of the 28th international conference on very large data bases.[s.l.]:[s.n.],2002:203-214.
[15] 何小东,尹海波.基于共享缓冲区的数据流处理框架设计与实现[J].计算机工程与设计,2012,33(11):4398-4401.
[16] 陈晗鸣,罗 威,李明辉.分布式系统中基于主/副版本的实时容错调度综述[J].计算机应用研究,2012,29(11):4017-4022.
