基于GARCH模型的VaR计算及在我国股票市场的运用
2018-01-18谢博文
谢博文


摘要:本文使用GARCH模型的条件方差来计算中国股票市场收益率的VaR,对上证指数与深证成指的风险进行了分析。得到以下结论:在我国股市,运用基于GARCH模型的VaR方法进行风险管理,是有效的;深圳股票市场的风险比上海股票市场大。
关键词:VaR GARCH模型 金融风险
一、引言
(一)VaR的定义
VaR是指在给定置信水平下,金融资产在未来一定时间内,可能发生的最大损失。用公式表示为:
p(Δp≤VaR)=1-c
其中,p( )表示事件发生的概率,Δp为在这段时间的实际损失额,c为给定的置信水平。
VaR的定义非常简单,其大小取决于三个方面:金融资产未来收益的分布特征,所选取的置信水平和持有期大小。只有这三个方面确定了,才可以接着进行VaR的计算。而其中最为困难的当属金融资产收益分布的确定,根据对该分布的推算方式不同,VaR计算方法分为三类:历史模拟法;方差-协方差法;蒙特卡洛模拟法。
VaR的方差-协方差法最为简单快捷,也最为常用的方法。因此,本文实证部分将采用方差-协方差法。现实市场中,金融资产收益率往往存在尖峰厚尾的性质,这将导致所得的VaR值实际低估了风险。但是,如果我们计算VaR值时,使用GARCH模型中的条件方差,则可以较好地满足这一特征,因此,本文将使用GARCH模型来估算两种指数的VaR值。
(二)GARCH模型
1982年,恩格尔在研究英国通货膨胀时,提出了自回归条件异方差模型,即ARCH模型,该模型有效体现出金融时间序列的时变性特点,模型的基本思路在于,在t时刻,其扰动项的条件方差依赖于t-1,t-2,……期的扰动项。但是,在金融领域,常常会出现这样一种情况,扰动项的条件方差依赖于很多期之前的扰动项,这会使待估参数数量变得很多,准确性大大降低。1986年,波勒斯列夫在恩格尔的ARCH模型基础上创立了广义自回归条件异方差模型,即GARCH模型,与ARCH(q)模型相比,GARCH(p,q)用少量的条件方差的滞后项代替大量的扰动项的滞后项,如此,我们可以用低阶GARCH模型来代表高阶ARCH模型,这样就使待估参数得数量大大减少,提高了准确性。其中,GARCH(1,1)模型是应用最为广泛的GARCH模型。
二、实证分析
样本区间为上证指数和深证成指2013.6.1至2017.5.31的数据,一共972个交易日。Pt为每日收盘价,设日收益率序列为Rt,采用对数收益率R=dlog(P)。
我们首先进行单位根检验和正态性检验,然后建立GARCH模型,进行VaR值的计算,具体步骤如下:
(一)单位根检验
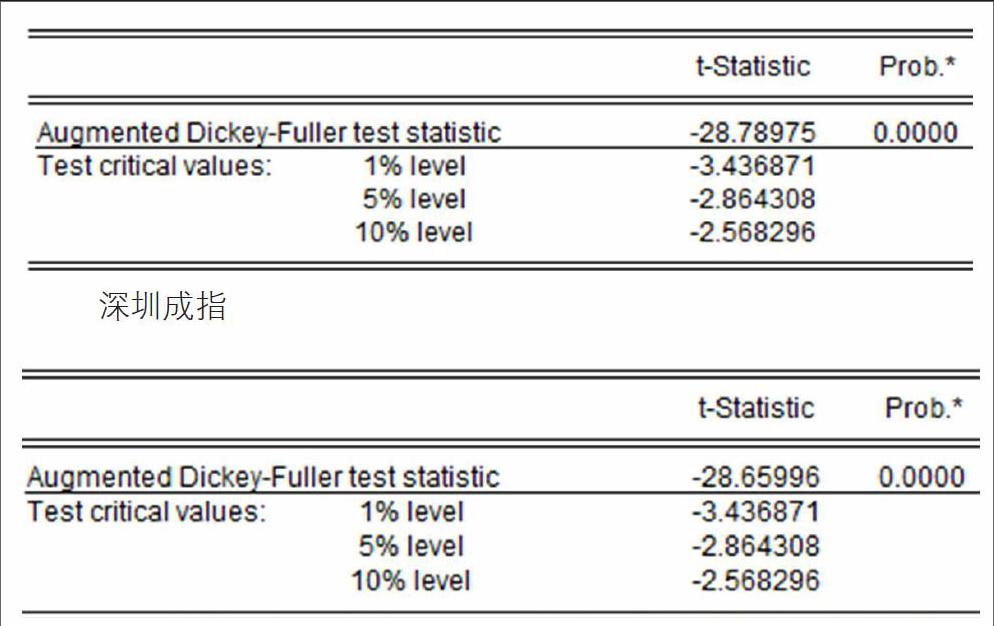
ADF单位根检验如下:
上证指数
从单位根检验结果来看,上证指数和深证成指的ADF统计值分别为-28.78975和-28.65996,小于在1%、5%、10%水平下的临界值,因此,在99%、95%、90%水平下拒绝原假设,即上证指数和深圳成指的收益率时间序列都是平稳的,不存在单位根。
(二)正态性检验
指数收益率时间序列的柱状图如下:
上证指数
在正态分布条件下,偏度为0而峰度为3,上证指数和深圳成指的收益率时间序列的偏度与峰度明显不满足此条件,所以并不是正态分布,从图形上看,尖峰厚尾特征明显。另外,JB统计量分别为1835.676和799.2861,同样拒绝原假设。
(三)建立GARCH模型
建立GARCH(1,1)模型,所得结果如下:
由表1可知,深圳市场的VaR均值要比上海市场大,因此具有更大的风险。
首先,我们计算实际的日收益损失大小,然后通过比较,我们可以得到实际损失超出VaR值的现实市场失败天数。总考察天数为972天,我们计算得出不同置信度下的期望失败天數,结果如表2所示,95%置信度下上证指数和深圳成指的VaR风险管理失败的频率接近5%,说明结果比较成功:而99%置信度下上证指数和深圳成指的实际失败天数比期望失败天数多10天左右,说明正态分布假设下计算的VaR明显低估了风险。
三、结论
通过实证分析可以得出以下结论:
第一,VaR模型的分析作用及对市场风险的测度还是有效的,但是如果不能对收益率序列的分布做出正确的假设,会造成风险高估或低估的可能,例如本文为了便于计算,简单地使用正态分布,在99%置信度下,明显低估了风险。
第二,深圳市场的风险比上海市场大。对两个市场指数分别建立GARCH(1,1)模型,通过对计算所得的VaR进行比较,可以发现,深圳市场的VaR均值比上海市场大,因此可以认为前者风险较大。endprint
